kubernetes 集群部署
部署
系统参数修改
docker部署
kubeadm install
https://www.kubernetes.org.cn/4256.html
https://github.com/opsnull/follow-me-install-kubernetes-cluster
镜像源被墙,可以用阿里云镜像源
1 | # 配置源 |
初始化集群
多网卡情况下有必要指定网卡:–apiserver-advertise-address=192.168.0.80
1 | 使用本地 image repository |
将一个node设置为不可调度,隔离出来,比如master 默认是不可调度的
1 | kubectl cordon <node-name> |
kubectl 管理多集群
一个kubectl可以管理多个集群,主要是 ~/.kube/config 里面的配置,比如:
1 | clusters: |
多个集群中切换的话 : kubectl config use-context az3
快速合并两个cluster
简单来讲就是把两个集群的 .kube/config 文件合并,注意context、cluster name别重复了。
1 | # 必须提前保证两个config文件中的cluster、context名字不能重复 |
背后的原理类似于这个流程:
1 | # 添加集群 集群地址上一步有获取 ,需要指定ca文件,上一步有获取 |
apiserver高可用
默认只有一个apiserver,可以考虑用haproxy和keepalive来做一组apiserver的负载均衡:
1 | docker run -d --name kube-haproxy \ |
haproxy配置
1 | #cat /etc/haproxy/haproxy.cfg |
网络
1 | kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml |
默认calico用的是ipip封包(这个性能跟原生网络差多少有待验证,本质也是overlay网络,比flannel那种要好很多吗?)
在所有node节点都在一个二层网络时候,flannel提供hostgw实现,避免vxlan实现的udp封装开销,估计是目前最高效的;calico也针对L3 Fabric,推出了IPinIP的选项,利用了GRE隧道封装;因此这些插件都能适合很多实际应用场景。
Service cluster IP尽可在集群内部访问,外部请求需要通过NodePort、LoadBalance或者Ingress来访问
网络插件由 containernetworking-plugins rpm包来提供,一般里面会有flannel、vlan等,安装在 /usr/libexec/cni/ 下(老版本没有带calico)
kubelet启动参数会配置 KUBELET_NETWORK_ARGS=–network-plugin=cni –cni-conf-dir=/etc/cni/net.d –cni-bin-dir=/usr/libexec/cni
kubectl 启动容器
1 | kubectl run -i --tty busybox --image=registry:5000/busybox -- sh |
dashboard
1 | kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc7/aio/deploy/recommented.yaml |
dashboard login token:
1 | #kubectl describe secrets -n kubernetes-dashboard | grep token | awk 'NR==3{print $2}' |
dashboard 显示为空的话(留意报错信息,一般是用户权限,重新授权即可)
1 | kubectl delete clusterrolebinding kubernetes-dashboard |
其中:system:serviceaccount:kubernetes-dashboard:default 来自于报错信息中的用户名
默认dashboard login很快expired,可以设置不过期:
1 | $ kubectl -n kubernetes-dashboard edit deployments kubernetes-dashboard |
kubectl proxy –address 0.0.0.0 –accept-hosts ‘.*’
node管理调度
1 | //如何优雅删除node |
地址
这些字段的用法取决于你的云服务商或者物理机配置。
- HostName:由节点的内核设置。可以通过 kubelet 的
--hostname-override参数覆盖。 - ExternalIP:通常是节点的可外部路由(从集群外可访问)的 IP 地址。
- InternalIP:通常是节点的仅可在集群内部路由的 IP 地址。
状况
1 | # kubectl get node -o wide |
如果 Ready 条件处于 Unknown 或者 False 状态的时间超过了 pod-eviction-timeout 值, (一个传递给 kube-controller-manager 的参数), 节点上的所有 Pod 都会被节点控制器计划删除。默认的逐出超时时长为 5 分钟。 某些情况下,当节点不可达时,API 服务器不能和其上的 kubelet 通信。 删除 Pod 的决定不能传达给 kubelet,直到它重新建立和 API 服务器的连接为止。 与此同时,被计划删除的 Pod 可能会继续在游离的节点上运行。
node cidr 缺失
flannel pod 运行正常,pod无法创建,检查flannel日志发现该node cidr缺失
1 | I0818 08:06:38.951132 1 main.go:733] Defaulting external v6 address to interface address (<nil>) |
正常来说describe node会看到如下的cidr信息
1 | Kube-Proxy Version: v1.15.8-beta.0 |
可以手工给node添加cidr
1 | kubectl patch node ky3 -p '{"spec":{"podCIDR":"172.19.3.0/24"}}' |
prometheus
1 | git clone https://github.com/coreos/kube-prometheus.git |
暴露grafana端口:
1 | kubectl port-forward --address 0.0.0.0 svc/grafana -n monitoring 3000:3000 |
部署应用
DRDS deployment
1 | apiVersion: v1 |
DRDS Service
每个 drds 容器会通过8507提供服务,service通过3306来为一组8507做负载均衡,这个service的3306是在cluster-ip上,外部无法访问
1 | apiVersion: v1 |
通过node port来访问 drds service(同时会有负载均衡):
1 | kubectl port-forward --address 0.0.0.0 svc/drds-service -n drds 3306:3306 |
部署mysql statefulset应用
drds-pv-mysql-0 后面的mysql 会用来做存储,下面用到了三个mysql(需要三个pvc)
1 | #cat mysql-deployment.yaml |
清理:
1 | kubectl delete deployment,svc mysql |
查看所有pod ip以及node ip:
1 | kubectl get pods -o wide |
配置 Pod 使用 ConfigMap
ConfigMap 允许你将配置文件与镜像文件分离,以使容器化的应用程序具有可移植性。
1 | # cat mysql-configmap.yaml //mysql配置文件放入: configmap |
将mysql root密码放入secret并查看 secret密码:
1 | cat mysql-secret.yaml |
在mysql容器中使用以上configmap中的参数:
1 | spec: |
通过挂载方式进入到容器里的 Secret,一旦其对应的 Etcd 里的数据被更新,这些 Volume 里的文件内容,同样也会被更新。其实,这是 kubelet 组件在定时维护这些 Volume。
集群会自动创建一个 default-token-**** 的secret,然后所有pod都会自动将这个 secret通过 Porjected Volume挂载到容器,也叫 ServiceAccountToken,是一种特殊的Secret
1 | Environment: <none> |
apply create操作
先 kubectl create,再 replace 的操作,我们称为命令式配置文件操作
kubectl apply 命令才是“声明式 API”
kubectl replace 的执行过程,是使用新的 YAML 文件中的 API 对象,替换原有的 API 对象;
而 kubectl apply,则是执行了一个对原有 API 对象的 PATCH 操作。
kubectl set image 和 kubectl edit 也是对已有 API 对象的修改
kube-apiserver 在响应命令式请求(比如,kubectl replace)的时候,一次只能处理一个写请求,否则会有产生冲突的可能。而对于声明式请求(比如,kubectl apply),一次能处理多个写操作,并且具备 Merge 能力
声明式 API,相当于对外界所有操作(并发接收)串行merge,才是 Kubernetes 项目编排能力“赖以生存”的核心所在
如何使用控制器模式,同 Kubernetes 里 API 对象的“增、删、改、查”进行协作,进而完成用户业务逻辑的编写过程。
label
给多个节点加标签
1 | kubectl label --overwrite=true nodes 10.0.0.172 10.0.1.192 10.0.2.48 topology.kubernetes.io/region=cn-hangzhou |
helm
Helm 是 Kubernetes 的包管理器。包管理器类似于我们在 Ubuntu 中使用的apt、Centos中使用的yum 或者Python中的 pip 一样,能快速查找、下载和安装软件包。Helm 由客户端组件 helm 和服务端组件 Tiller 组成, 能够将一组K8S资源打包统一管理, 是查找、共享和使用为Kubernetes构建的软件的最佳方式。
建立local repo index:
1 | helm repo index [DIR] [flags] |
仓库只能index 到 helm package 发布后的tgz包,意义不大。每次index后需要 helm repo update
然后可以启动一个http服务:
1 | nohup python -m SimpleHTTPServer 8089 & |
将local repo加入到仓库:
1 | helm repo add local http://127.0.0.1:8089 |
install chart:
1 | //helm3 默认不自动创建namespace,不带参数就报没有 ame 的namespace错误 |
quote是一个模板方法,可以将输入的参数添加双引号
模板片段
之前我们看到有个文件叫做_helpers.tpl,我们介绍是说存储模板片段的地方。
模板片段其实也可以在文件中定义,但是为了更好管理,可以在_helpers.tpl中定义,使用时直接调用即可。
自动补全
kubernetes自动补全:
1 | source <(kubectl completion bash) |
helm自动补全:
1 | cd ~ |
两者都需要依赖 auto-completion,所以得先:
1 | # yum install -y bash-completion |
kubectl -s polarx-test-ackk8s-atp-3826.adbgw.alibabacloud.test exec -it bushu016polarx282bc7216f-5161 bash
启动时间排序
1 | 532 [2021-08-24 18:37:19] kubectl get po --sort-by=.status.startTime -ndrds |
kubeadm
初始化集群的时候第一看kubelet能否起来(cgroup配置),第二就是看kubelet静态起pod,kubelet参数指定yaml目录,然后kubelet拉起这个目录下的所有yaml。
kubeadm启动集群就是如此。kubeadm生成证书、etcd.yaml等yaml、然后拉起kubelet,kubelet拉起etcd、apiserver等pod,kubeadm init 的时候主要是在轮询等待apiserver的起来。
可以通过kubelet –v 256来看详细日志,kubeadm本身所做的事情并不多,所以日志没有太多的信息,主要是等待轮询apiserver的拉起。
Kubeadm config
Init 可以指定仓库以及版本
1 | kubeadm init --image-repository=registry:5000/registry.aliyuncs.com/google_containers --kubernetes-version=v1.14.6 --pod-network-cidr=10.244.0.0/16 |
查看并修改配置
1 | sudo kubeadm config view > kubeadm-config.yaml |
pod镜像拉取不到的话可以在kebelet启动参数中写死pod镜像(pod_infra_container_image)
1 | cat /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf |
构建离线镜像库
1 | kubeadm config images list >1.24.list |
cni 报x509: certificate signed by unknown authority
一个集群下反复部署calico/flannel插件后,在 /etc/cni/net.d/ 下会有cni 网络配置文件残留,导致 flannel 创建容器网络的时候报证书错误。其实这不只是证书错误,还可能报其它cni配置错误,总之这是因为 10-calico.conflist 不符合 flannel要求所导致的。
1 | # find /etc/cni/net.d/ |
因为calico 排在 flannel前面,所以即使用flannel配置文件也是用的 10-calico.conflist。每次 kubeadm reset 的时候是不会去做 cni 的reset 的:
1 | [reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf] |
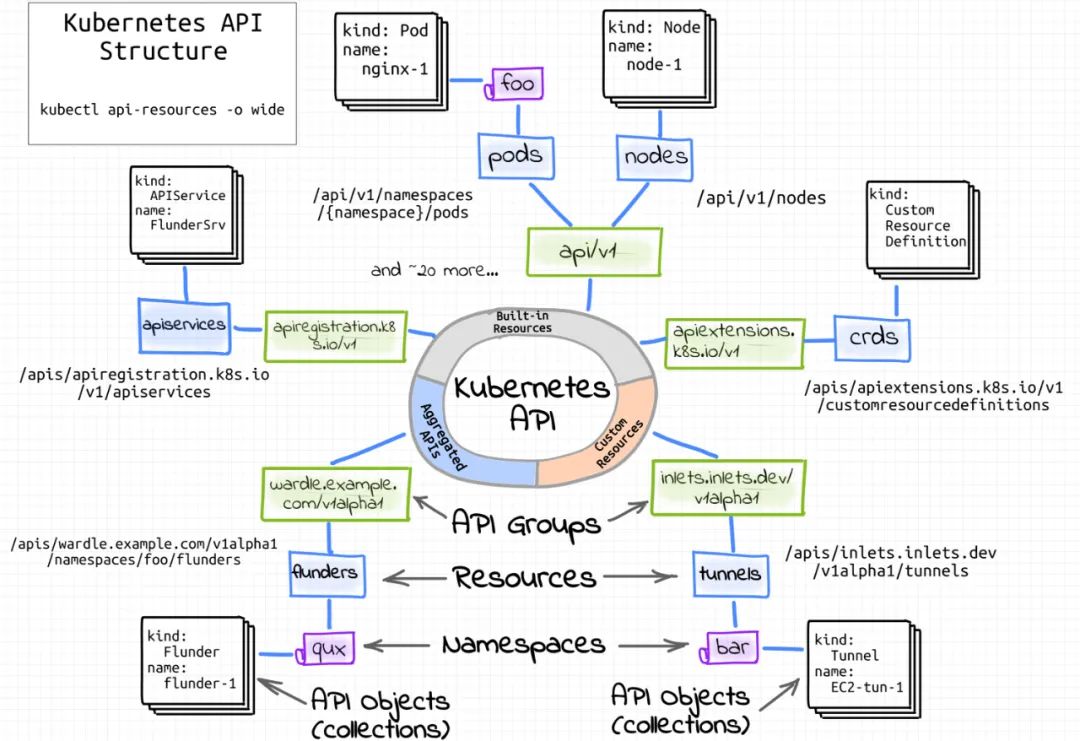
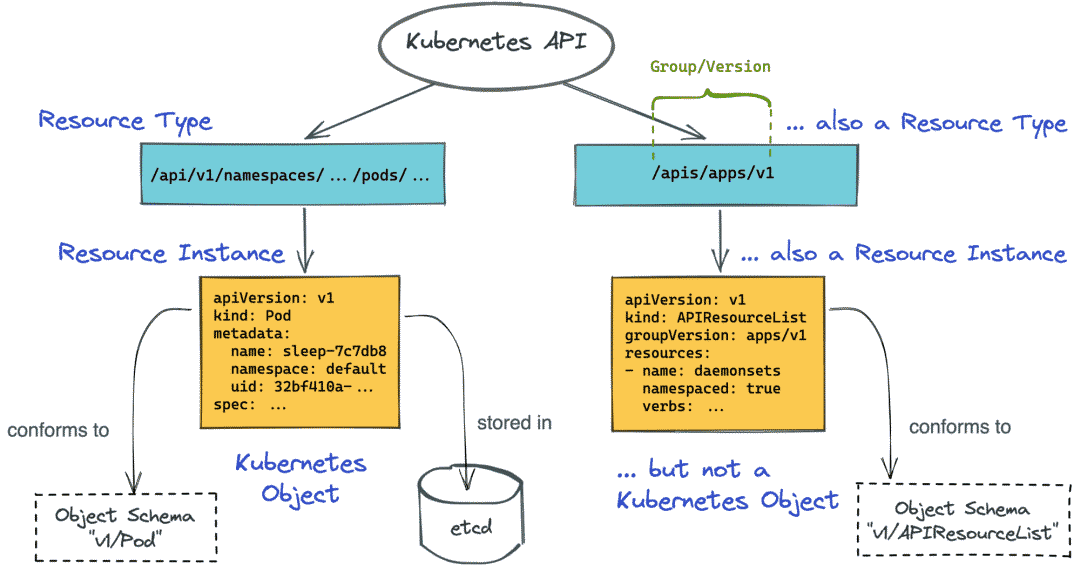
kubernetes API 案例
用kubeadm部署kubernetes集群,会生成如下证书:
1 | #ls /etc/kubernetes/pki/ |
curl访问api必须提供证书
1 | curl --cacert /etc/kubernetes/pki/ca.crt --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --key /etc/kubernetes/pki/apiserver-kubelet-client.key https://ip:6443/apis/apps/v1/deployments |
/etc/kubernetes/pki/ca.crt —- CA机构
由CA机构签发:/etc/kubernetes/pki/apiserver-kubelet-client.crt
获取default namespace下的deployment
1 | # JWT_TOKEN_DEFAULT_DEFAULT=$(kubectl get secrets \ |
对应地可以通过 kubectl -v 256 get pods 来看kubectl的处理过程,以及具体访问的api、参数、返回结果等。实际kubectl最终也是通过libcurl来访问的这些api。这样也不用对api-server抓包分析了。
或者将kube api-server 代理成普通http服务
# Make Kubernetes API available on localhost:8080
# to bypass the auth step in subsequent queries:
$ kubectl proxy –port=8080然后
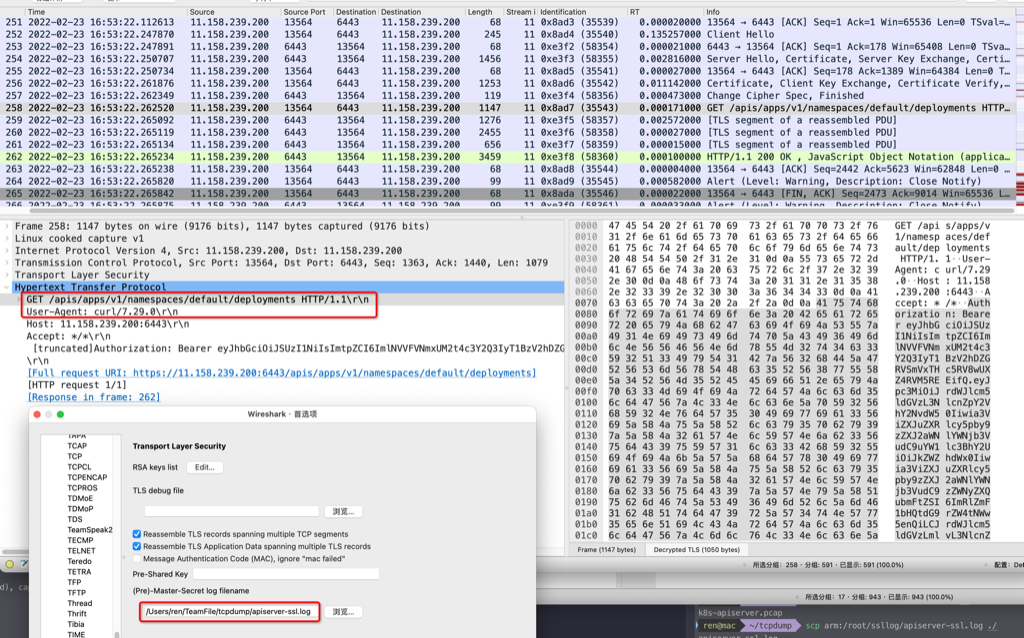
抓包
用curl调用kubernetes api-server来调试,需要抓包,先在执行curl的服务器上配置环境变量
1 | export SSLKEYLOGFILE=/root/ssllog/apiserver-ssl.log |
然后执行tcpdump对api-server的6443端口抓包,然后将/root/ssllog/apiserver-ssl.log和抓包文件下载到本地,wireshark打开抓包文件,同时配置tls。
以下是个完整case(技巧指定curl的本地端口为12345,然后tcpdump只抓12345,所得的请求、response结果都会解密–如果抓api-server的6443则只能看到请求被解密)
1 | curl --local-port 12345 --cacert /etc/kubernetes/pki/ca.crt --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --key /etc/kubernetes/pki/apiserver-kubelet-client.key https://11.158.239.200:6443/apis/apps/v1/namespaces/default/deployments --header "Authorization: Bearer $JWT_TOKEN_DEFAULT_DEFAULT" |