kubernetes 容器网络
cni 网络
cni0 is a Linux network bridge device, all veth devices will connect to this bridge, so all Pods on the same node can communicate with each other, as explained in Kubernetes Network Model and the hotel analogy above.
cni(Container Network Interface)
CNI 全称为 Container Network Interface,是用来定义容器网络的一个 规范。containernetworking/cni 是一个 CNCF 的 CNI 实现项目,包括基本额 bridge,macvlan等基本网络插件。
一般将cni各种网络插件的可执行文件二进制放到 /opt/cni/bin ,在 /etc/cni/net.d/ 下创建配置文件,剩下的就交给 K8s 或者 containerd 了,我们不关心也不了解其实现。
比如:
1 | #ls -lh /opt/cni/bin/ |
CNI 插件都是直接通过 exec 的方式调用,而不是通过 socket 这样 C/S 方式,所有参数都是通过环境变量、标准输入输出来实现的。
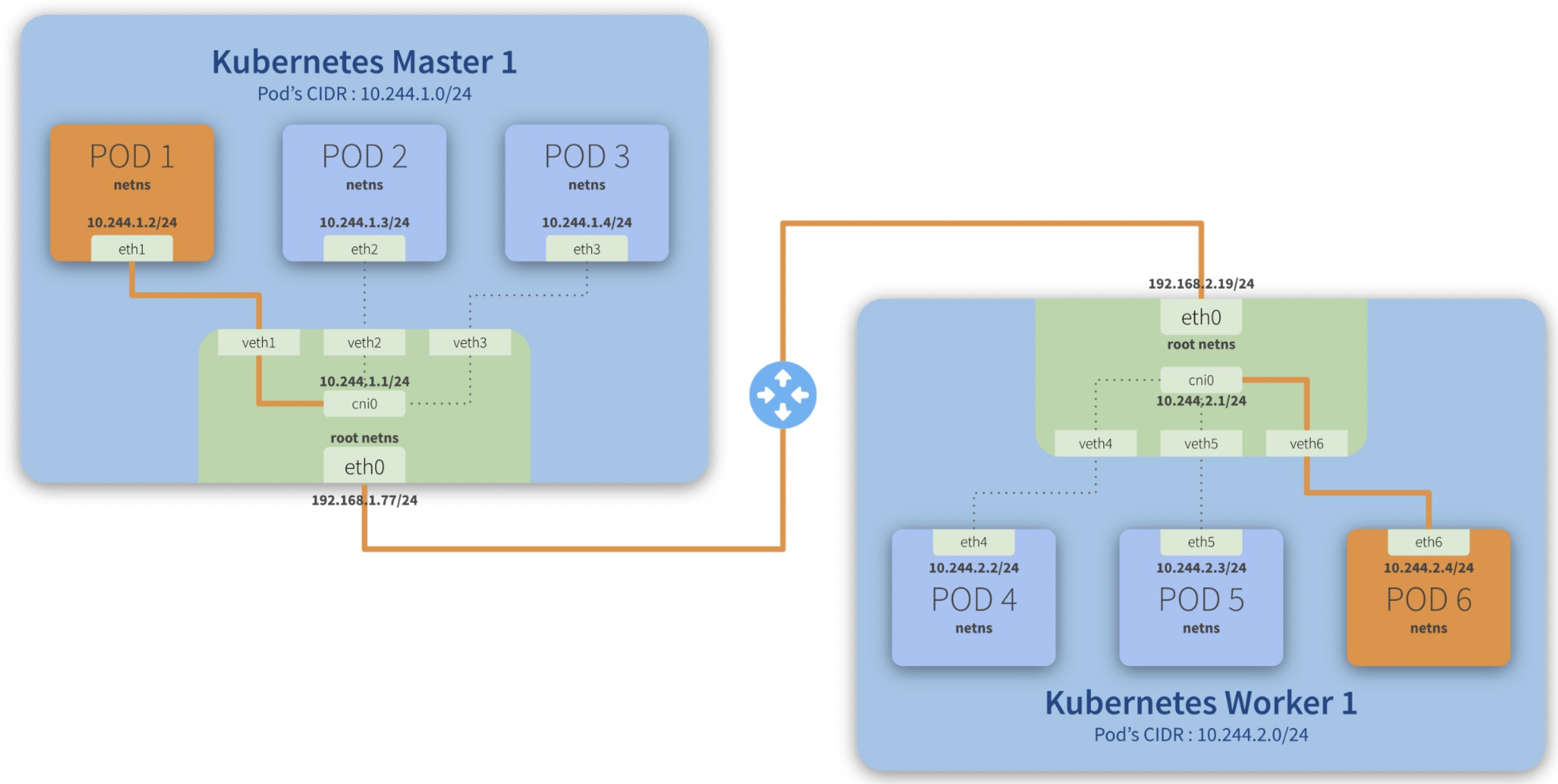
Step-by-step communication from Pod 1 to Pod 6:
- Package leaves *Pod 1 netns* through the *eth1* interface and reaches the root netns* through the virtual interface veth1*;
- Package leaves veth1* and reaches cni0*, looking for ***Pod 6***’s address;
- Package leaves cni0* and is redirected to eth0*;
- Package leaves *eth0* from Master 1* and reaches the gateway*;
- Package leaves the *gateway* and reaches the *root netns* through the eth0* interface on Worker 1*;
- Package leaves eth0* and reaches cni0*, looking for ***Pod 6***’s address;
- Package leaves *cni0* and is redirected to the *veth6* virtual interface;
- Package leaves the *root netns* through *veth6* and reaches the *Pod 6 netns* though the *eth6* interface;
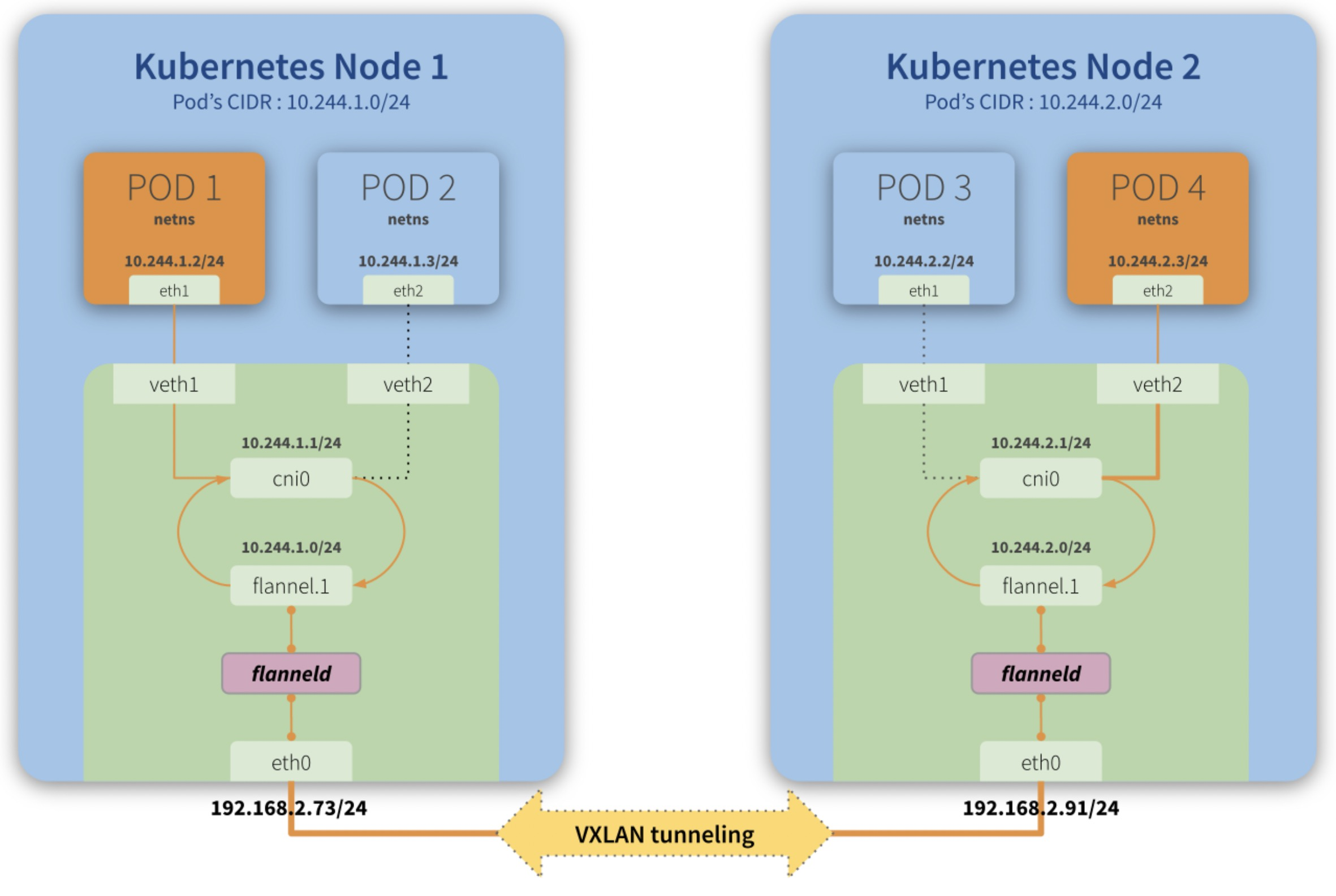
flannel 网络
假如POD1访问POD4:
- 从POD1中出来的包先到Bridge cni0上(因为POD1对应的veth挂在了cni0上)
- 然后进入到宿主机网络,宿主机有路由 10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink ,也就是目标ip 10.244.2.3的包交由 flannel.1 来处理
- flanneld 进程将包封装成vxlan 丢到eth0从宿主机1离开(封装后的目标ip是192.168.2.91)
- 这个封装后的vxlan udp包正确路由到宿主机2
- 然后经由 flanneld 解包成 10.244.2.3 ,命中宿主机2上的路由:10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1 ,交给cni0(这里会过宿主机iptables)
- cni0将包送给POD4
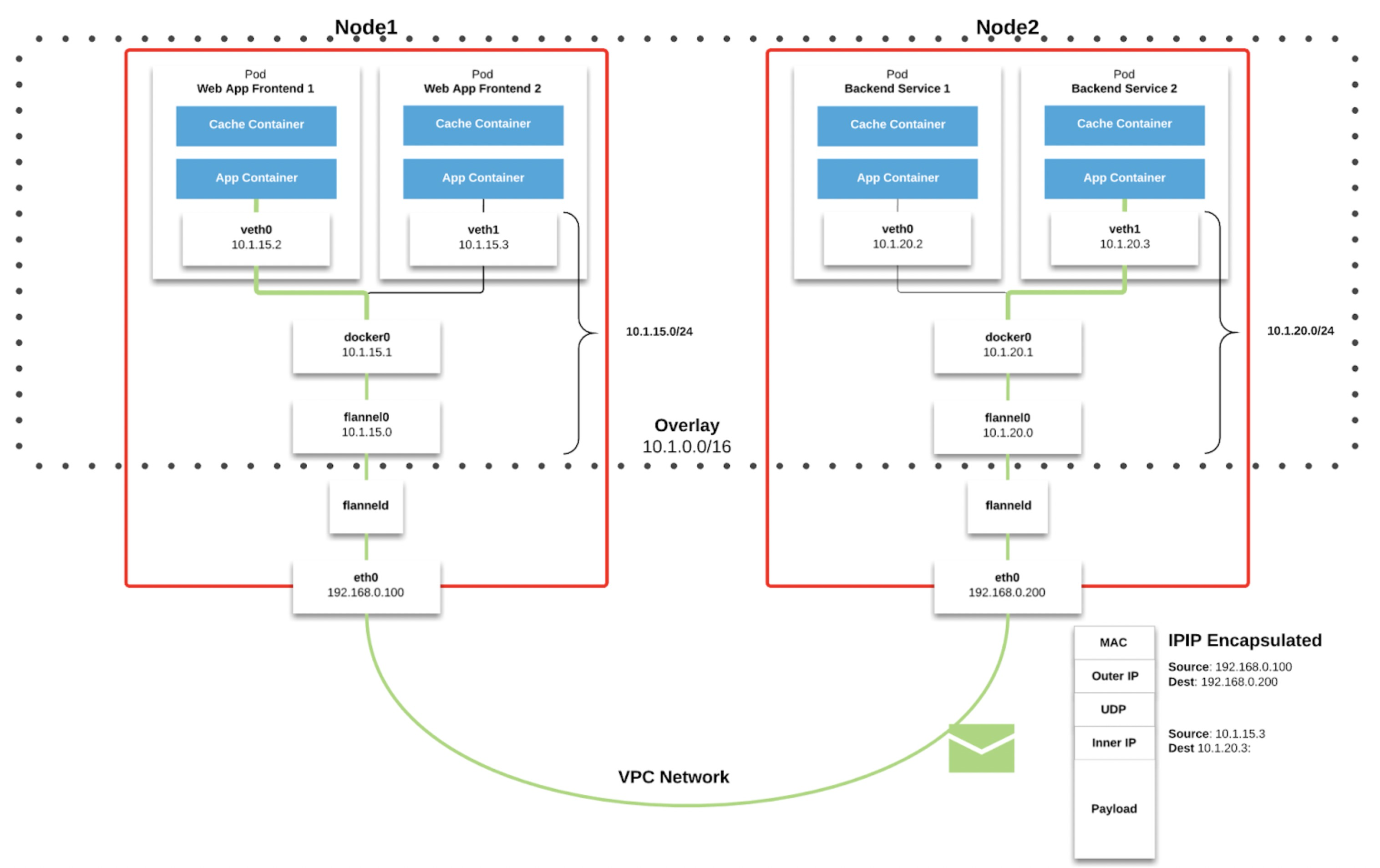
对应宿主机查询到的ip、路由信息(和上图不是对应的)
1 | #ip -d -4 addr show cni0 |
kubernetes calico 网络
1 | kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml |
默认calico用的是ipip封包(这个性能跟原生网络差多少有待验证,本质也是overlay网络,比flannel那种要好很多吗?)
跨宿主机的两个容器之间的流量链路是:
cali-容器eth0->宿主机cali27dce37c0e8->tunl0->内核ipip模块封包->物理网卡(ipip封包后)—远程–> 物理网卡->内核ipip模块解包->tunl0->cali-容器
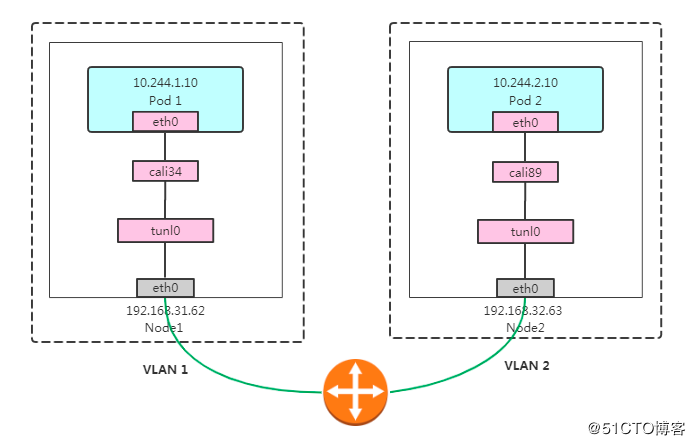
Calico IPIP模式对物理网络无侵入,符合云原生容器网络要求;使用IPIP封包,性能略低于Calico BGP模式;无法使用传统防火墙管理、也无法和存量网络直接打通。Pod在Node做SNAT访问外部,Pod流量不易被监控。
calico ipip网络不通
集群有五台机器192.168.0.110-114, 同时每个node都有另外一个ip:192.168.3.110-114,部分节点之间不通。每台机器部署好calico网络后,会分配一个 /26 CIRD 子网(64个ip)。
案例1
目标机是10.122.127.128(宿主机ip 192.168.3.112),如果从10.122.17.64(宿主机ip 192.168.3.110) ping 10.122.127.128不通,查看10.122.127.128路由表:
1 | [root@az3-k8s-13 ~]# ip route |grep tunl0 |
在10.122.127.128抓包如下,明显可以看到icmp request到了 tunl0网卡,tunl0网卡也回复了,但是回复包没有经过kernel ipip模块封装后发到eth1上:
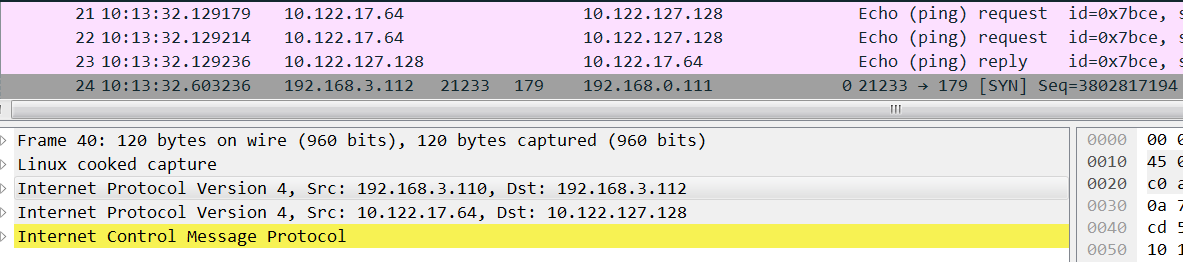
正常机器应该是这样,上图不正常的时候缺少红框中的reply:
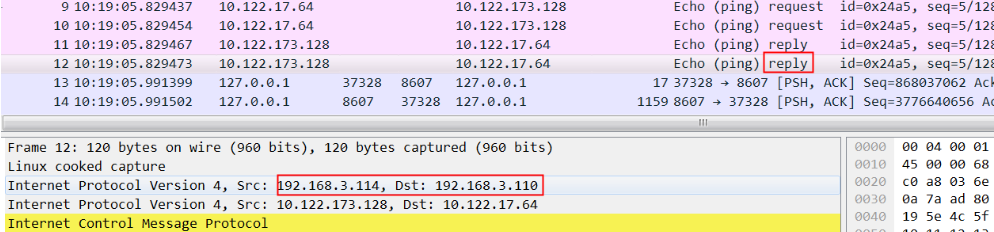
解决:
1 | ip route del 10.122.17.64/26 via 10.122.127.128 dev tunl0 ; |
删除错误路由增加新的路由就可以了,新增路由的意思是从tunl0发给10.122.17.64/26的包下一跳是 192.168.3.110。
via 192.168.3.110 表示下一跳的ip
onlink参数的作用:
使用这个参数将会告诉内核,不必检查网关是否可达。因为在linux内核中,网关与本地的网段不同是被认为不可达的,从而拒绝执行添加路由的操作。
因为tunl0网卡ip的 CIDR 是32,也就是不属于任何子网,那么这个网卡上的路由没有网关,配置路由的话必须是onlink, 内核存也没法根据子网来选择到这块网卡,所以还会加上 dev 指定网卡。
案例2
集群有五台机器192.168.0.110-114, 同时每个node都有另外一个ip:192.168.3.110-114,只有node2没有192.168.3.111这个ip,结果node2跟其他节点都不通:
1 | #calicoctl node status |
从node4 ping node2,然后在node2上抓包,可以看到 icmp request都发到了node2上,但是node2收到后没有发给tunl0:
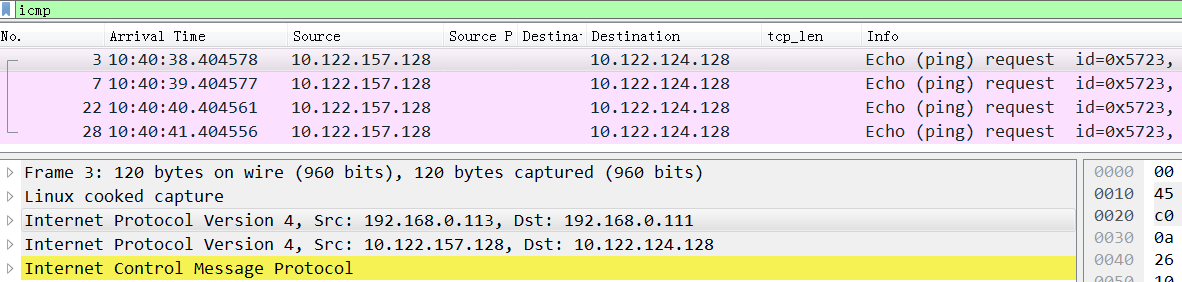
所以icmp没有回复,这里的问题在于kernel收到包后为什么不给tunl0
同样,在node2上ping node4,同时在node2上抓包,可以看到发给node4的request包和reply包:
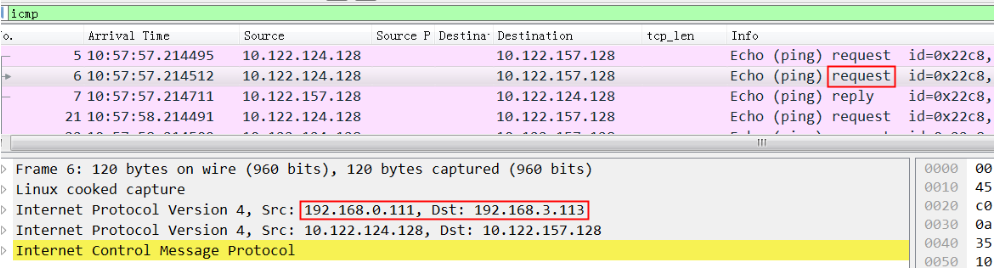
从request包可以看到src ip 是0.111, dest ip是 3.113,因为 node2 没有192.168.3.111这个ip
非常关键的我们看到node4的回复包 src ip 不是3.113,而是0.113(根据node4的路由就应该是0.113)
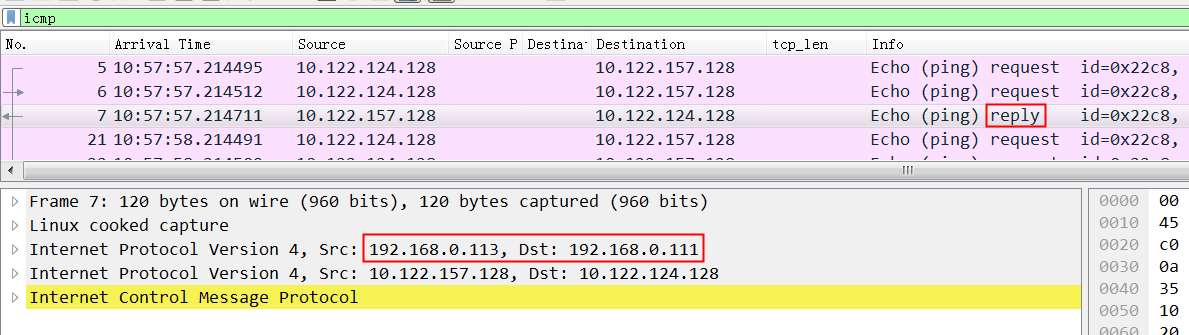
这就是问题所在,从node4过来的ipip包src ip都是0.113,实际这里ipip能认识的只是3.113.
如果这个时候在3.113机器上把0.113网卡down掉,那么3.113上的:
10.122.124.128/26 via 192.168.0.111 dev tunl0 proto bird onlink 路由被自动删除,3.113将不再回复request。这是因为calico记录的node2的ip是192.168.0.111,所以会自动增加
解决办法,在node4上删除这条路由记录,也就是强制让回复包走3.113网卡,这样收发的ip就能对应上了
1 | ip route del 192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.113 |
最终OK后,node4上的ip route是这样的:
1 | [root@az3-k8s-14 ~]# ip route |
正常后的抓包, 注意这里drequest的est ip 和reply的 src ip终于一致了:
1 | //request |
总结下来这两个案例都还是对路由不够了解,特别是案例2,因为有了多个网卡后导致路由更复杂。calico ipip的基本原理就是利用内核进行ipip封包,然后修改路由来保证网络的畅通。
flannel网络不通
firewalld
在麒麟系统的物理机上通过kubeadm setup集群,发现有的环境flannel网络不通,在宿主机上ping 其它物理机flannel.0网卡的ip,通过在对端宿主机抓包发现icmp收到后被防火墙扔掉了,抓包中可以看到错误信息:icmp unreachable - admin prohibited
下图中正常的icmp是直接ping 物理机ip
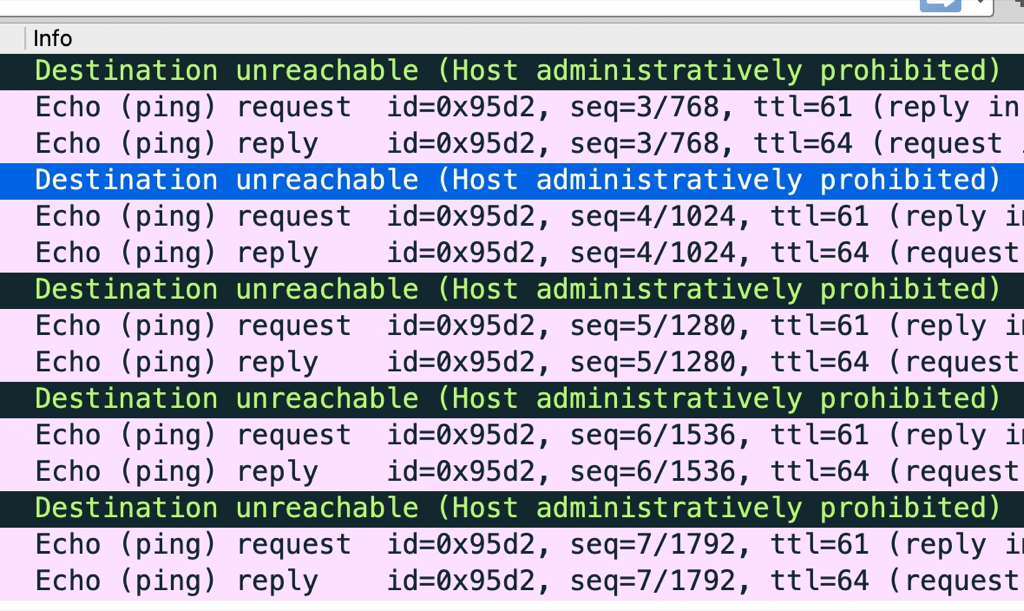
The “admin prohibited filter” seen in the tcpdump output means there is a firewall blocking a connection. It does it by sending back an ICMP packet meaning precisely that: the admin of that firewall doesn’t want those packets to get through. It could be a firewall at the destination site. It could be a firewall in between. It could be iptables on the Linux system.
发现有问题的环境中宿主机的防火墙设置报错了:
1 | 12月 28 23:35:08 hygon253 firewalld[10493]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -t filter -X DOCKER-ISOLATION-STAGE-1' failed: iptables: No chain/target/match by that name. |
应该是因为启动docker的时候 firewalld 是运行着的
Do you have firewalld enabled, and was it (re)started after docker was started? If so, then it’s likely that firewalld wiped docker’s IPTables rules. Restarting the docker daemon should re-create those rules.
停掉 firewalld 服务可以解决这个问题
掉电重启后flannel网络不通
flannel能收到包,但是cni0收不到包,说明包进到了目标宿主机,但是从flannel解开udp转送到cni的时候出了问题,大概率是iptables 拦截了包
1 | It seems docker version >=1.13 will add iptables rule like below,and it make this issue happen: |
清理
cni信息
1 | /etc/cni/net.d/* |
calico创建的tunl0网卡是个tunnel,可以通过 ip tunnel show来查看,清理不掉(重启可以清理掉tunl0)
1 | ip link set dev tunl0 name tunl0_fallback |
flannel
1 | ip link delete flannel.1 |
netns
以下case创建一个名为 ren 的netns,然后在里面增加一对虚拟网卡veth1 veth1_p, veth1放置在ren里面,veth1_p 放在物理机上,给他们配置上ip并up就能通了。
1 | 1004 [2021-10-27 10:49:08] ip netns add ren |
Linux 上存在一个默认的网络命名空间,Linux 中的 1 号进程初始使用该默认空间。Linux 上其它所有进程都是由 1 号进程派生出来的,在派生 clone 的时候如果没有额外特别指定,所有的进程都将共享这个默认网络空间。
所有的网络设备刚创建出来都是在宿主机默认网络空间下的。可以通过 ip link set 设备名 netns 网络空间名 将设备移动到另外一个空间里去,socket也是归属在某一个网络命名空间下的,由创建socket进程所在的netns来决定socket所在的netns
1 | //file: net/socket.c |
内核提供了三种操作命名空间的方式,分别是 clone、setns 和 unshare。ip netns add 使用的是 unshare,原理和 clone 是类似的。
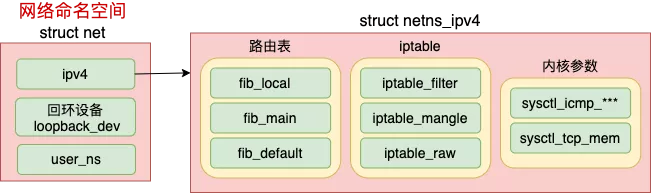
每个 net 下都包含了自己的路由表、iptable 以及内核参数配置等等
参考资料
https://morven.life/notes/networking-3-ipip/