如何从几百万个抓包中找到一个异常的包
这篇算是对抓包定位原因在哪里的落地篇,没什么高深的技术,都是很low但是你一定可以照着操作的,算是星球内必须学会和带走的内容
场景
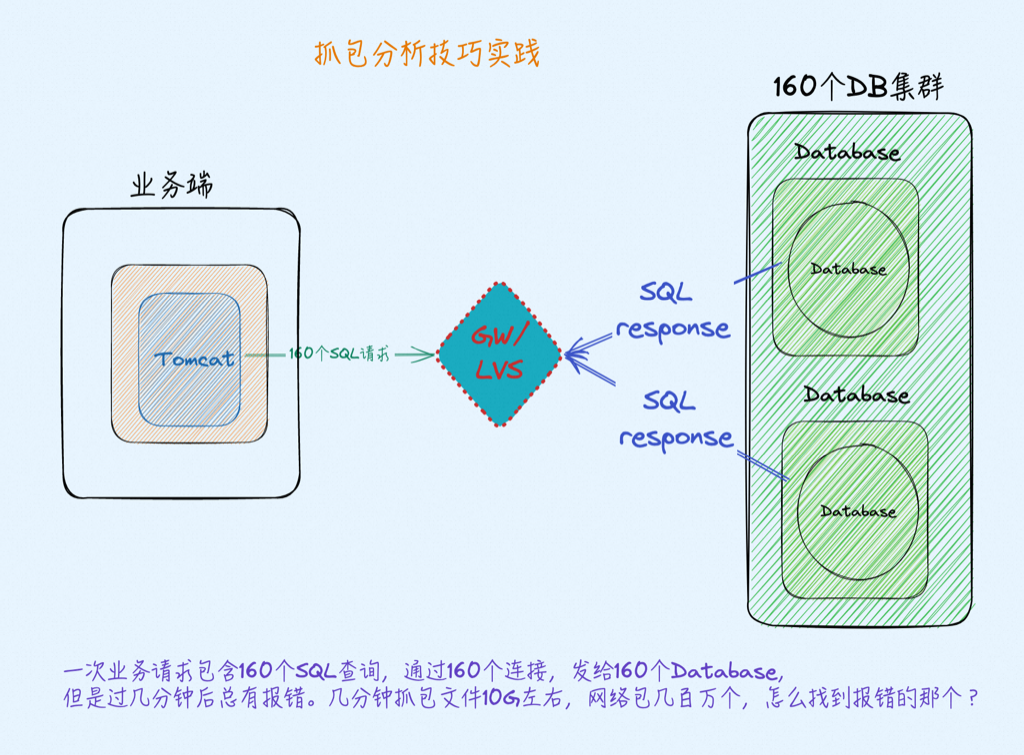
问题
一次业务请求包含160个拖数据的SQL查询,通过160个连接,发给160个Database,但是过几分钟后总有报错。几分钟抓包文件10G左右,网络包几百万个,怎么找到报错的那个?
几个麻烦的地方
- 虽然问题每次稳定重现,但是每次重现的Database不是固定的;
- 从开始拖到出现问题需要几分钟不等,抓包量巨大
- 有一个连接报错后剩下的其它连接也会断开
- 这么多端口怎么解析成MySQL协议,请看:https://t.zsxq.com/0f7nMlKax
问题发生条件
- 一个Client同时开160条连接,发160个类似的SQL去160个MySQL Database上拖数据时必现
- 如果将拖数据的SQL拖取数量改小一点就不再出现——拖取少执行更快,没达到触发bug条件
- 网络传输得慢一点、JDBC streaming 模式下发生,比如streaming流模式拖数据是几MB每秒,去掉流模式拖数据是几十MB每秒且不报错。这里可以通过设置内核 tcp rmem/加大rtt延时来模拟重现——和我们的必做实验callback一下,无时不刻不展示下我们必做实验的用途。
分析过程
分析技巧和步骤:
- 抓包,从握手到报错断开全抓下来,时间跨度3分多钟,抓下来10个G左右,怎么分析?
- editcap -c 200000 把抓包切小,每个文件20万个包,保证wireshark打开不太慢(editcap 是安装wireshark附带的小命令,附带的还有tshark、capinfos等)
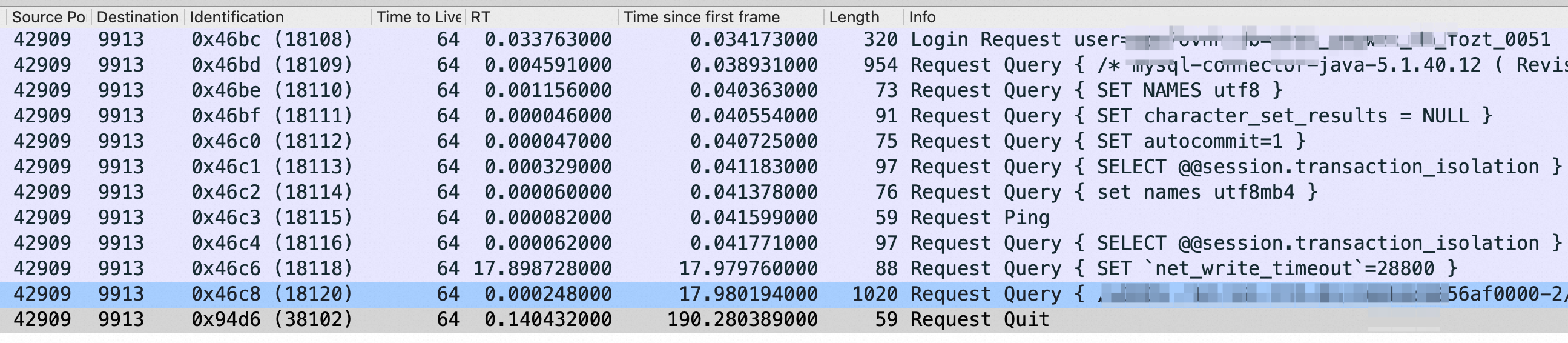
- wireshark打开切小后的最后一个文件,搜reset/fin 找到第一个断开的连接(如下图),找到9913/42909这对连接端口
- 回到10个G的抓包中,用 tshark -r ./big.pcap -Y “tcp.port==42909” -w 42909.pcap 把42909这条连接所有包过滤出来,-r 读,-w 写
- wireshark 打开42909.pcap 傻子也能看到问题在哪里了
切完后的包,切完后的文件会加时间戳,时间戳可以和报错时间对应:
|
|
搜reset/fin 找到第一个断开的连接,第一个断开的连接才是罪魁祸首:

进一步分析发生问题的连接
知识点:
MySQL 协议是一来一回,也就是client发查询然后等查询结果全部返回,然后再发下一个
按协议在一个SQL查询的数据传输完毕前client不能再发任何请求,MySQL Server负责一直发送查询结果直到发送完毕。
如下两个截图是从42909.pcap文件中过滤到的抓包从握手到断开的全过程,图1过滤条件:tcp.srcport eq 42909 and tcp.len>0 (42909是客户端,9913是MySQL端口),可以看到客户端 login(连数据库肯定得要user、password认证),然后是client查了MySQL的一堆服务端参数(下图第二行),再然后是client设置了几个参数(set 那些)。关键的是倒数第二行client发了一个SQL给MySQL需要拉取大量数据(建立连接17.98秒的时候),然后是数据传数据过程,第190秒的时候client发了 Quit断开连接
上图因为加了过滤条件,只看client端并去掉ack后的所有包,没看到全貌,这个过程9913的MySQL 服务端又做了啥呢?因为太长前面漫长的传数据就不截图了,只看最后连接的断开。
但是下图红框所示的地方可以看到MySQL Server 传着传着居然带了个 fin 包在里面,表示MySQL Server要断开连接了,无奈Client只能也发送quit 断开连接。红框告诉我们一个无比有力的证据MySQL Server 在不应该断开的地方断开了连接,问题在 MySQL Server 端

结论
就抓包结论来看是 MySQL 在不应该断开的时候发送了 fin 主动断开连接,可能是MySQL的bug
题外话,这个包证据抓了有一周了,但是MySQL研发同学始终绕来绕去(比如我的代码没记录下这个SQL就是没收到,我的代码没问题——熟悉的味道)跟我打了一周太极(异地),我一查发现我和他老板认识且在一层楼,赶紧面对面找他老板讲清楚这个问题,且签字画押承认是MySQL的问题,然后继续推进排查,最终结果是为啥我跟你们一起期待吧,有了结果我再来update。
练习
找个MySQL,然后开始抓包,用mysql-client连一下MySQL Server随便发几个SQL,然后看看一来一回的响应
如果哪怕在星球一年你只要好好掌握这一篇用到的技能也能帮助你在日常工作中互相扯皮的时候快速给出精准定位和分析,值回星球票价,加油
比如这个案例我同时打开了5/6个wireshark分析不同的流、整体搜索等
其它
这些技巧不只是用在MySQL 上,其它微服务、redis等涉及网络调用场景的扯皮的地方都可以用
capinfos rsb2.cap
tshark -q -n -r rsb2.cap -z “conv,ip” 分析流量总况
tshark -q -n -r rsb2.cap -z “conv,tcp” 分析每一个连接的流量、rtt、响应时间、丢包率、重传率等等
editcap -c 100000 ./rsb2.cap rsb00.cap //把大文件rsb2.cap按每个文件100000个package切成小文件
存放在这里:
|
|
net_write_timeout 报错
最后回答一下上一篇中提到的流模式下 net_write_timeout 报错
如下图,JDBC 在 streaming 模式下,不断读取下一行,如果这个过程只要报错抛出的异常就是 StreamingNotifiable 异常

错误信息定义如下,这个报错误导太严重,从以上JDBC 代码可以看到只要读取下一行报错了就会报调大 net_write_timeout 错误,但是实际原因却是连接异常断开,和 timeout 没有一点关系,你看久经考验的 JDBC 代码也不是那么完善还得你会 Debug
|
|
这个报错误导了排查分析方向,不知道坑了多少人了!当然如果MySQL 因为net_write_timeout 超时断开连接当然应该报如上错误,但是 JDBC 搞不清楚MySQL 为啥断开,就瞎猜是 timeout 了,然后只要是连接异常读数据错误(包含断开)就报这个错误。希望你们不要被坑
记住这个坑人的报错堆栈:
|
|
不过你要仔细看的话,它还是有caused by,如下,但是绝大部分工程师看到这个堆栈会忽视,上面都有 net_write_timeout 我还管个屁 Can not read response from server, 不过要是结合抓包的话就能理解:at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:3186) 这个根本的原因是 JDBC 从服务端读取数据的时候报错了
|
|
最后希望你没被绕晕,再去看看上一篇中推荐的流模式原理,把代码和网络应用层完美地结合起来
完整堆栈也可以参考网络上别人碰到的:https://github.com/brettwooldridge/HikariCP/issues/1771
下次在你们的业务代码里如果出现查询结果太大导致JVM OOM的话你可以站出来说把拉取数据改成 流 模式会有奇效 :) , 当然随之而来的是会有 net_write_timeout 报错,嗯,你的机会来了,业务技术上按照你的指引发展,出了问题你能顶得上