通过分析tcp包来确认服务调用的响应时间
通过分析tcp包来确认服务调用的响应时间
不需要在应用中打点,不限定于具体语言(php、cpp、java都可以), 分析服务调用的响应时间
案例
1 | 当时的问题,客户现场不管怎么样增加应用机器,tps就是上不去,同时增加应用机器后,增加的机器CPU还都能被用完,但是tps没有变化(这点比较奇怪,也就是cpu用的更多了,tps没变化),客户感觉 整体服务调用慢,数据库没有慢查询,不知道到具体时间花在哪里,各个环节都尝试过增加服务器(或提升配置),但是问题一直得不到解决 |
原因
数据库服务器网卡中断瓶颈导致rtt非常高,进一步导致每个Query的ResponseTime非常高(图中左边都是出问题、右边都是问题解决后的响应时间)
通过程序把每个请求、响应时间等数据分析出来并存入数据库中(缺一个图形展示界面,有图形展示界面后会更直观)
图一中是每一秒中的平均 rtt 时间(round trip time)
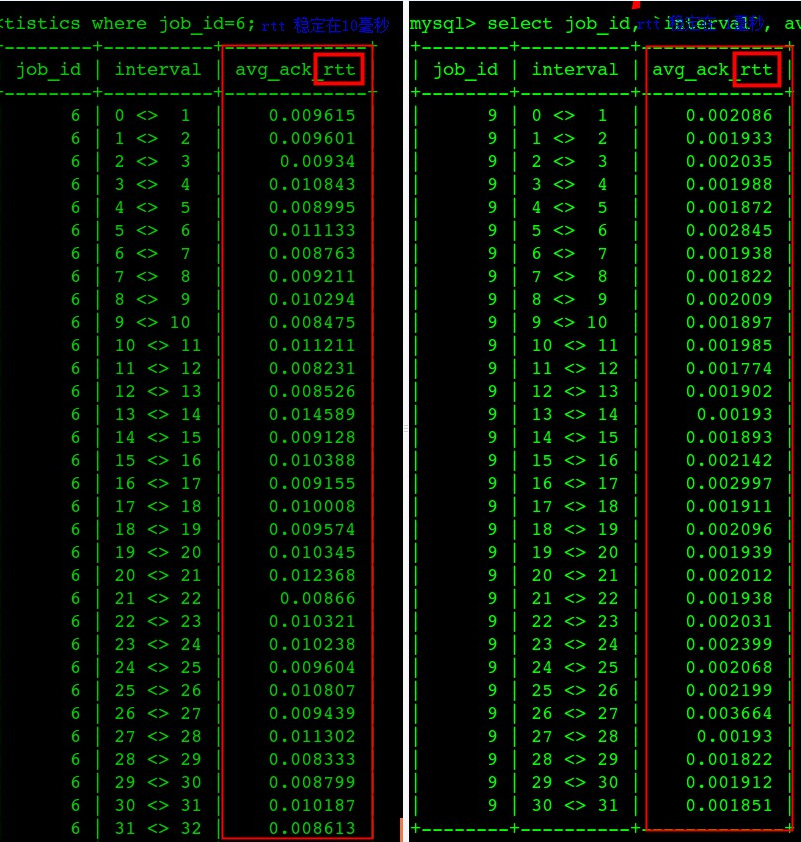
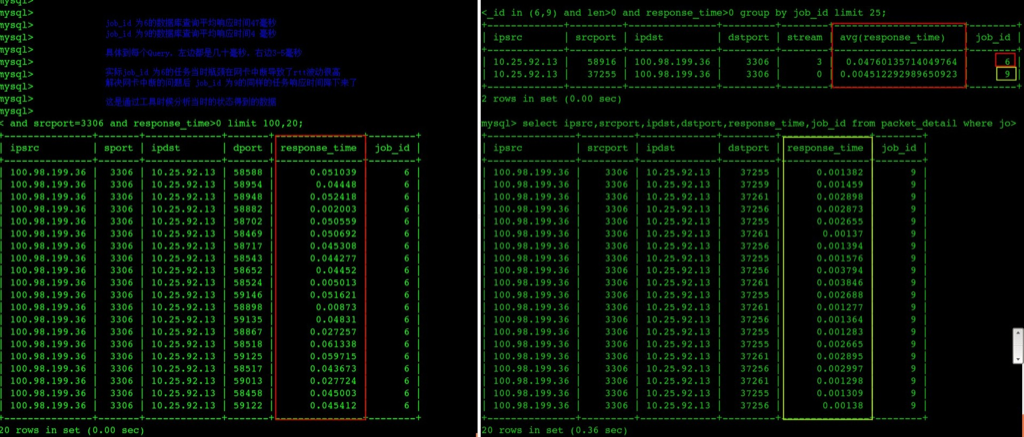
问题修复后数据库每个查询的平均响应时间从47毫秒下降到了4.5毫秒
图中的每一行都是是一个查询的数据库执行时间
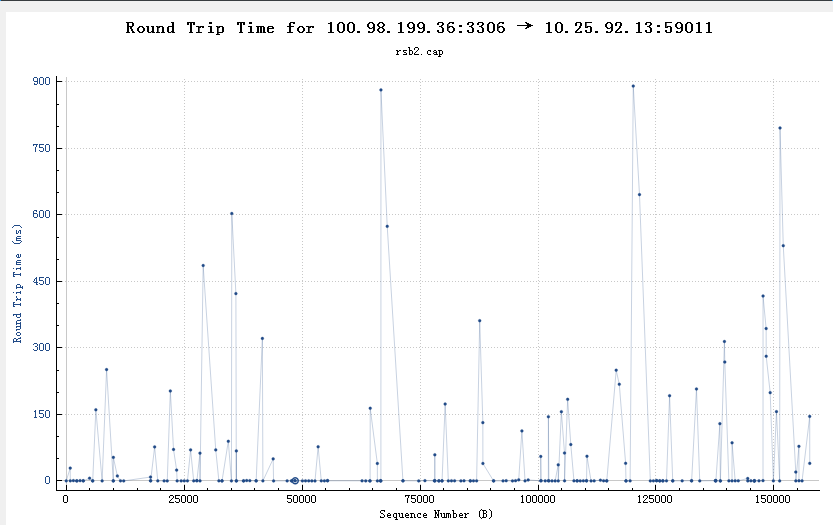
从wireshark中也可以看到类似的rtt不正常(超过150ms的比较多)
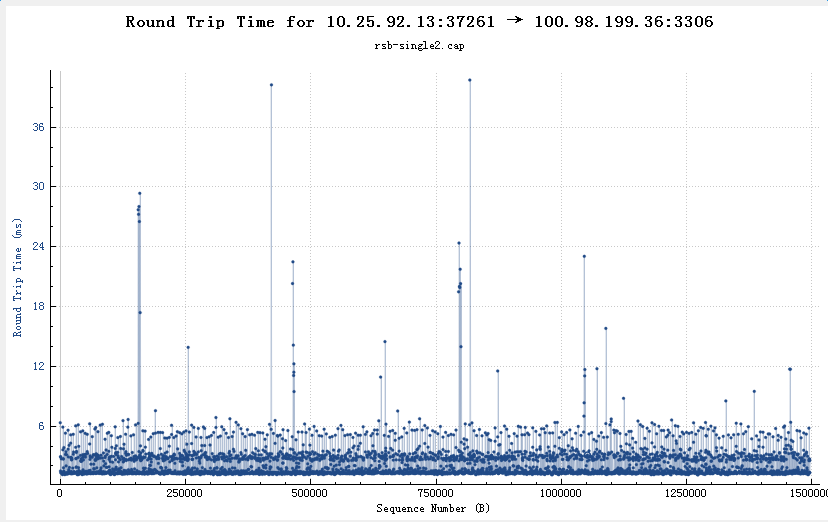
从wireshark中也可以看到类似的rtt正常(99%都在10ms以内)
总结
实际上通过抓包发现所有发往后面的SQL查询(请求链路:app -> slb -> drds -> slb ->rds) ,在app上抓包发现每个请求发出去到收到结果平均需要差不多100ms(无论SQL复杂与否),通过统计网络往返时间(rtt)发现rtt非常高,好多都是50ms以上。
降低压力比较rtt,发现rtt降到了20ms以内,同时SQL响应时间也相应地减短了。
已经排除了drds到rds响应慢的问题,问题应该在slb或者drds上,进一步发现drds(16Core 16GMem)绑定网卡中断的cpu用到了95%以上,尝试绑定到多个cpu内核,似乎ecs不支持,接下来将配置,增加多个低配置的drds来解决问题。
简单来说ecs默认网卡中断只能用到一个核,如果ecs配置太高,网卡中断会成为瓶颈,导致rtt变高、不稳定