就是要你懂TCP--握手和挥手
就是要你懂TCP–握手和挥手
看过太多tcp相关文章,但是看完总是不过瘾,似懂非懂,反复考虑过后,我觉得是那些文章太过理论,看起来没有体感,所以吸收不了。
希望这篇文章能做到言简意赅,帮助大家透过案例来理解原理
tcp的特点
这个大家基本都能说几句,面试的时候候选人也肯定会告诉你这些:
- 三次握手
- 四次挥手
- 可靠连接
- 丢包重传
- 速度自我调整
但是我只希望大家记住一个核心的:tcp是可靠传输协议,它的所有特点都为这个可靠传输服务。
那么tcp是怎么样来保障可靠传输呢?
tcp在传输过程中都有一个ack,接收方通过ack告诉发送方收到那些包了。这样发送方能知道有没有丢包,进而确定重传
tcp建连接的三次握手
来看一个java代码连接数据库的三次握手过程

三个红框表示建立连接的三次握手:
- 第一步:client 发送 syn 到server 发起握手;
- 第二步:server 收到 syn后回复syn+ack给client;
- 第三步:client 收到syn+ack后,回复server一个ack表示收到了server的syn+ack(此时client的48287端口的连接已经是established)
握手的核心目的是告知对方seq(绿框是client的初始seq,蓝色框是server 的初始seq),对方回复ack(收到的seq+包的大小),这样发送端就知道有没有丢包了
握手的次要目的是告知和协商一些信息,图中黄框。
- MSS–最大传输包
- SACK_PERM–是否支持Selective ack(用户优化重传效率)
- WS–窗口计算指数(有点复杂的话先不用管)
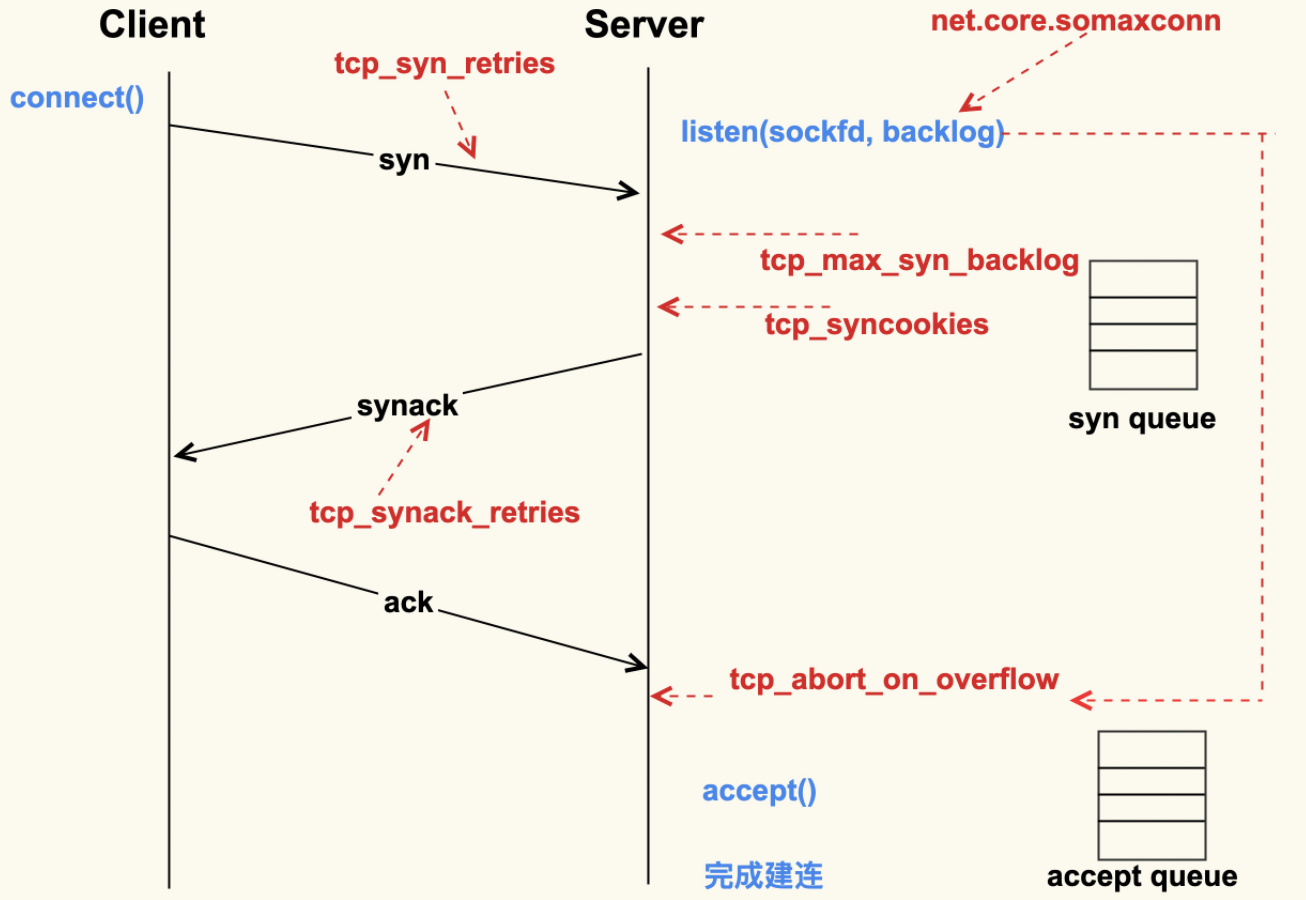
全连接队列(accept queue)的长度是由 listen(sockfd, backlog) 这个函数里的 backlog 控制的,而该 backlog 的最大值则是 somaxconn。somaxconn 在 5.4 之前的内核中,默认都是 128(5.4 开始调整为了默认 4096)
当服务器中积压的全连接个数超过该值后,新的全连接就会被丢弃掉。Server 在将新连接丢弃时,有的时候需要发送 reset 来通知 Client,这样 Client 就不会再次重试了。不过,默认行为是直接丢弃不去通知 Client。至于是否需要给 Client 发送 reset,是由 tcp_abort_on_overflow 这个配置项来控制的,该值默认为 0,即不发送 reset 给 Client。推荐也是将该值配置为 0
net.ipv4.tcp_abort_on_overflow = 0
这就是tcp为什么要握手建立连接,就是为了解决tcp的可靠传输
物理上没有一个连接的东西在这里,udp也类似会占用端口、ip,但是大家都没说过udp的连接。而本质上我们说tcp的连接是指tcp是拥有和维护一些状态信息的,这个状态信息就包含seq、ack、窗口/buffer,tcp握手就是协商出来这些初始值。这些状态才是我们平时所说的tcp连接的本质。
unres_qlen 和 握手
tcp connect 的本地流程是这样的:
1、tcp发出SYN建链报文后,报文到ip层需要进行路由查询
2、路由查询完成后,报文到arp层查询下一跳mac地址
3、如果本地没有对应网关的arp缓存,就需要缓存住这个报文,发起arp报文请求
4、arp层收到arp回应报文之后,从缓存中取出SYN报文,完成mac头填写并发送给驱动。
问题在于,arp层报文缓存队列长度默认为3。如果你运气不好,刚好赶上缓存已满,这个报文就会被丢弃。
TCP层发现SYN报文发出去3s(默认值)还没有回应,就会重发一个SYN。这就是为什么少数连接会3s后才能建链。
幸运的是,arp层缓存队列长度是可配置的,用 sysctl -a | grep unres_qlen 就能看到,默认值为3。
建连接失败经常碰到的问题
内核扔掉syn的情况(握手失败,建不上连接):
- rp_filter 命中(rp_filter=1, 多网卡环境), troubleshooting: netstat -s | grep -i filter ;
- snat/dnat的时候宿主机port冲突,内核会扔掉 syn包。 troubleshooting: sudo conntrack -S | grep insert_failed //有不为0的
- 全连接队列满的情况
- syn flood攻击
- 若远端服务器的内核参数 net.ipv4.tcp_tw_recycle 和 net.ipv4.tcp_timestamps 的值都为 1,则远端服务器会检查每一个报文中的时间戳(Timestamp),若 Timestamp 不是递增的关系,不会响应这个报文。配置 NAT 后,远端服务器看到来自不同的客户端的源 IP 相同,但 NAT 前每一台客户端的时间可能会有偏差,报文中的 Timestamp 就不是递增的情况。nat后的连接,开启timestamp。因为快速回收time_wait的需要,会校验时间该ip上次tcp通讯的timestamp大于本次tcp(nat后的不同机器经过nat后ip一样,保证不了timestamp递增)
- NAT 哈希表满导致 ECS 实例丢包 nf_conntrack full
tcp断开连接的四次挥手
再来看java连上mysql后,执行了一个SQL: select sleep(2); 然后就断开了连接
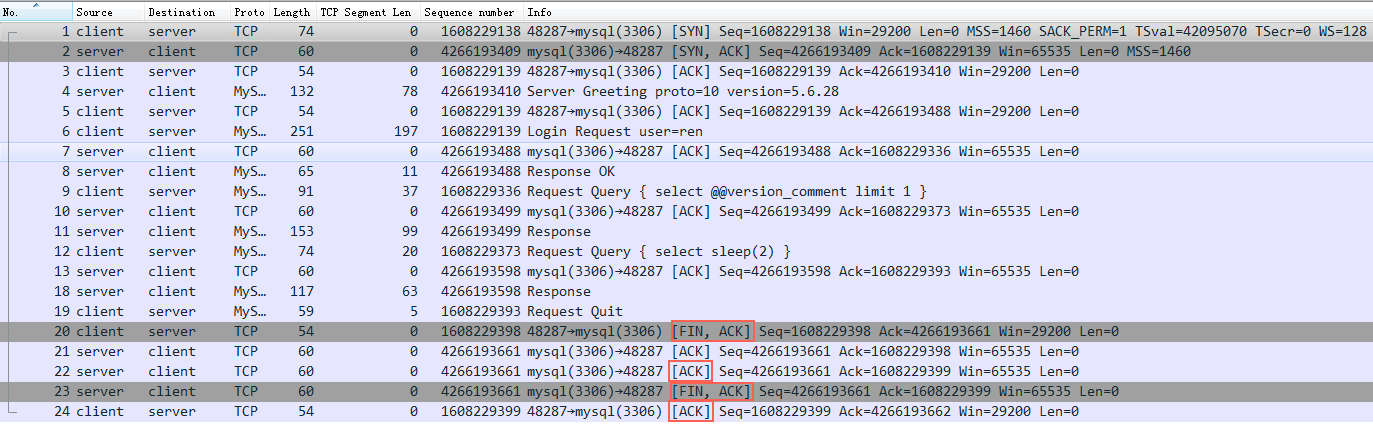
四个红框表示断开连接的四次挥手:
- 第一步: client主动发送fin包给server
- 第二步: server回复ack(对应第一步fin包的ack)给client,表示server知道client要断开了
- 第三步: server发送fin包给client,表示server也可以断开了
- 第四部: client回复ack给server,表示既然双发都发送fin包表示断开,那么就真的断开吧
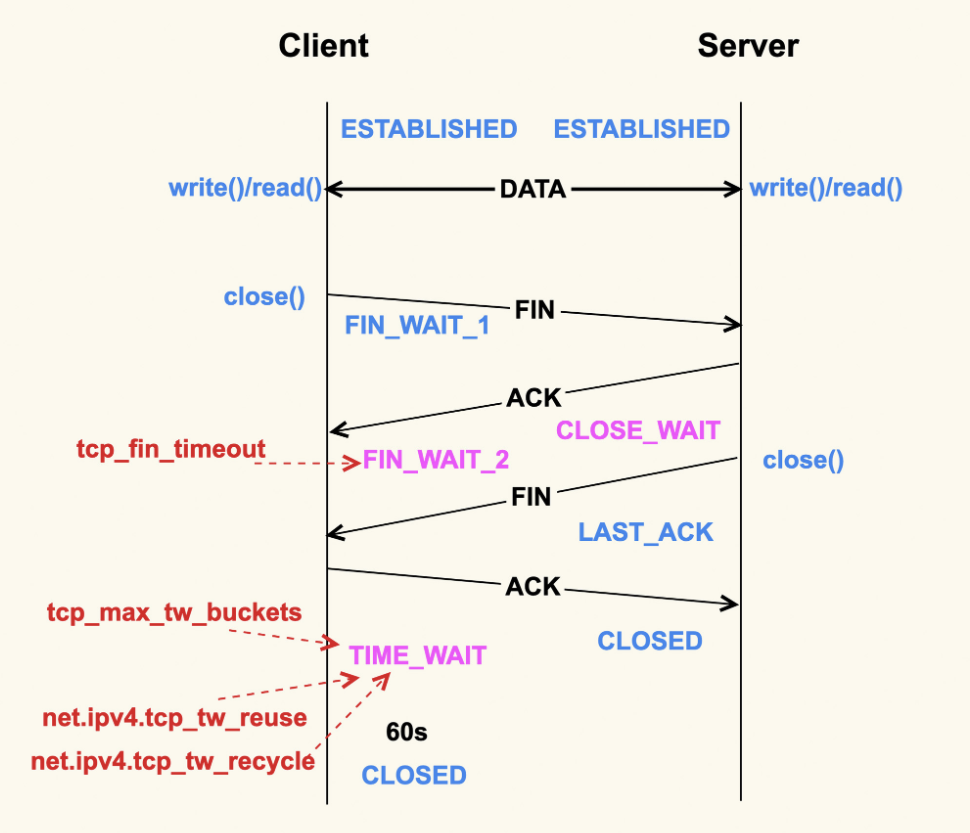
除了 CLOSE_WAIT 状态外,其余两个状态都有对应的系统配置项来控制。
我们首先来看 FIN_WAIT_2 状态,TCP 进入到这个状态后,如果本端迟迟收不到对端的 FIN 包,那就会一直处于这个状态,于是就会一直消耗系统资源。Linux 为了防止这种资源的开销,设置了这个状态的超时时间 tcp_fin_timeout,默认为 60s,超过这个时间后就会自动销毁该连接。
至于本端为何迟迟收不到对端的 FIN 包,通常情况下都是因为对端机器出了问题,或者是因为太繁忙而不能及时 close()。所以,通常我们都建议将 tcp_fin_timeout 调小一些,以尽量避免这种状态下的资源开销。对于数据中心内部的机器而言,将它调整为 2s 足以:
net.ipv4.tcp_fin_timeout = 2
TIME_WAIT 状态存在的意义是:最后发送的这个 ACK 包可能会被丢弃掉或者有延迟,这样对端就会再次发送 FIN 包。如果不维持 TIME_WAIT 这个状态,那么再次收到对端的 FIN 包后,本端就会回一个 Reset 包,这可能会产生一些异常。

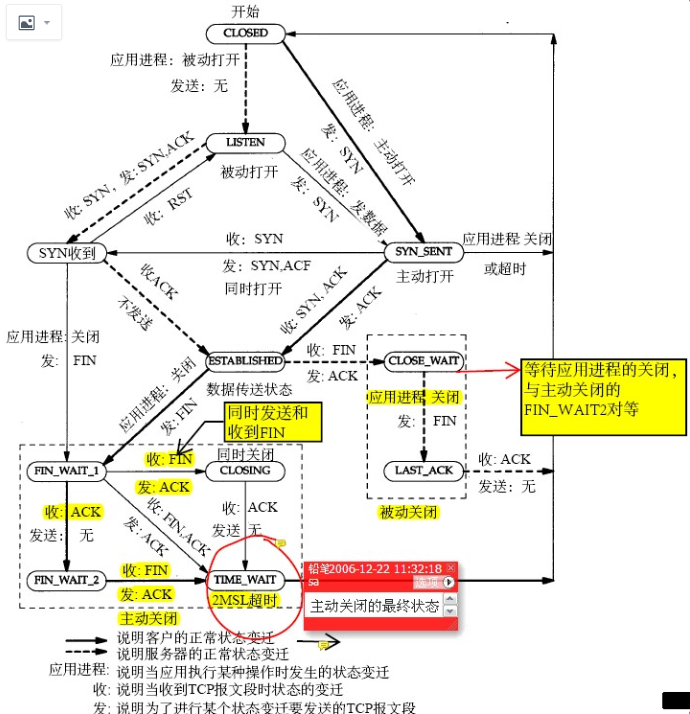
为什么握手三次、挥手四次
这个问题太恶心,面试官太喜欢问,其实大部分面试官只会背诵:因为TCP是双向的,所以关闭需要四次挥手……。
你要是想怼面试官的话可以问他握手也是双向的但是只需要三次呢?
我也不知道怎么回答。网上都说tcp是双向的,所以断开要四次。但是我认为建连接也是双向的(双向都协调告知对方自己的seq号),为什么不需要四次握手呢,所以网上说的不一定精准。
你再看三次握手的第二步发 syn+ack,如果拆分成两步先发ack再发syn完全也是可以的(效率略低),这样三次握手也变成四次握手了。
看起来挥手的时候多一次,主要是收到第一个fin包后单独回复了一个ack包,如果能回复fin+ack那么四次挥手也就变成三次了。 来看一个案例:

图中第二个红框就是回复的fin+ack,这样四次挥手变成三次了(如果一个包就是一次的话)。
我的理解:之所以绝大数时候我们看到的都是四次挥手,是因为收到fin后,知道对方要关闭了,然后OS通知应用层要关闭,这里应用层可能需要做些准备工作,可能还有数据没发送完,所以内核先回ack,等应用准备好了主动调close时再发fin 。 握手过程没有这个准备过程所以可以立即发送syn+ack(把这里的两步合成一步了)。 内核收到对方的fin后,只能ack,不能主动替应用来fin,因为他不清楚应用能不能关闭。
ack=seq+len
ack总是seq+len(包的大小),这样发送方明确知道server收到那些东西了
但是特例是三次握手和四次挥手,虽然len都是0,但是syn和fin都要占用一个seq号,所以这里的ack都是seq+1
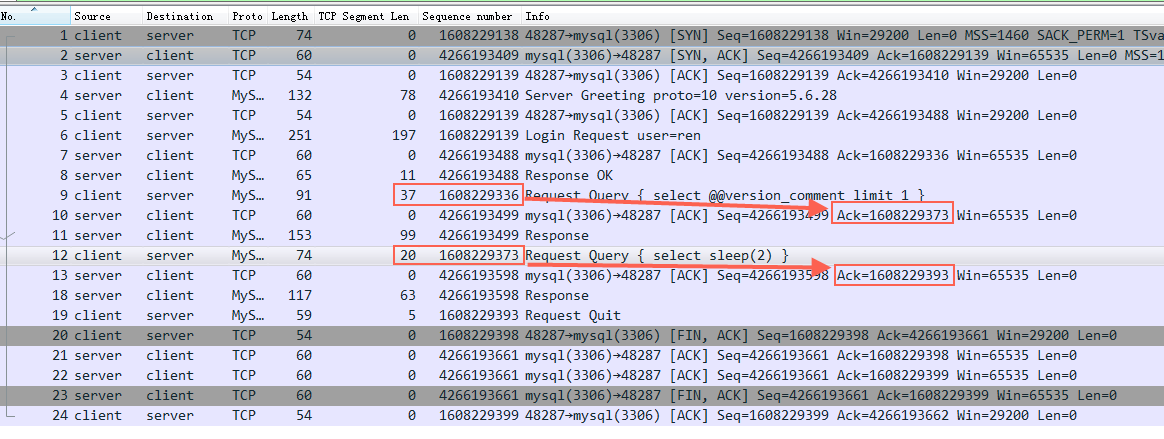
看图中左边红框里的len+seq就是接收方回复的ack的数字,表示这个包接收方收到了。然后下一个包的seq就是前一个包的len+seq,依次增加,一旦中间发出去的东西没有收到ack就是丢包了,过一段时间(或者其他方式)触发重传,保障了tcp传输的可靠性。
三次握手中协商的其它信息
MSS 最大一个包中能传输的信息(不含tcp、ip包头),MSS+包头就是MTU(最大传输单元),如果MTU过大可能在传输的过程中被卡住过不去造成卡死(这个大小的包一直传输不过去),跟丢包还不一样
MSS的问题具体可以看我这篇文章: scp某个文件的时候卡死问题的解决过程
SACK_PERM 用于丢包的话提升重传效率,比如client一次发了1、2、3、4、5 这5个包给server,实际server收到了 1、3、4、5这四个包,中间2丢掉了。这个时候server回复ack的时候,都只能回复2,表示2前面所有的包都收到了,给我发第二个包吧,如果server 收到3、4、5还是没有收到2的话,也是回复ack 2而不是回复ack 3、4、5、6的,表示快点发2过来。
但是这个时候client虽然知道2丢了,然后会重发2,但是不知道3、4、5有没有丢啊,实际3、4、5 server都收到了,如果支持sack,那么可以ack 2的时候同时告诉client 3、4、5都收到了,这样client重传的时候只重传2就可以,如果没有sack的话那么可能会重传2、3、4、5,这样效率就低了。
来看一个例子:
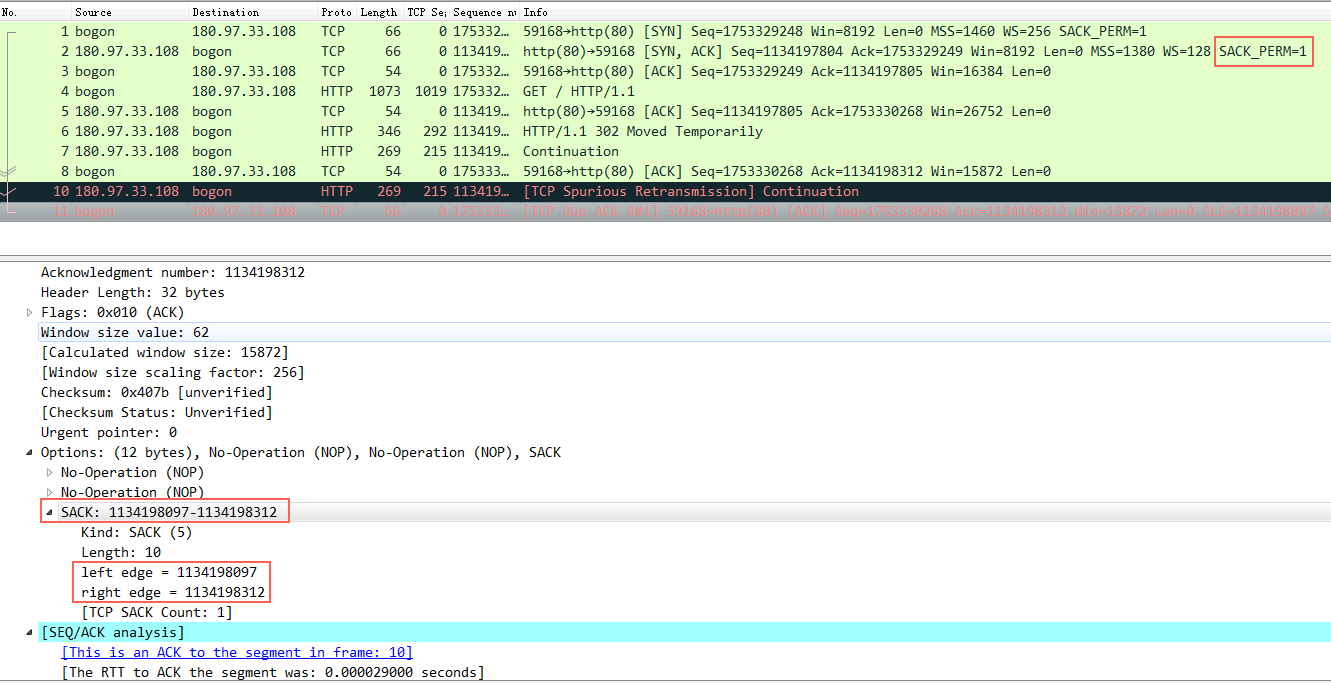
图中的红框就是SACK。
知识点:ack数字表示这个数字前面的数据都收到了
TIME_WAIT 和 CLOSE_WAIT
假设服务端和客户端跑在同一台机器上,服务端监听在 18080端口上,客户端使用18089端口建立连接。
如果client主动断开连接那么就会看到client端的连接在 TIME_WAIT:
1 | # netstat -ant |grep 1808 |
如果Server主动断开连接(也就是18080)那么就会看到client端的连接在CLOSE_WAIT 而Server在FIN_WAIT2:
1 | # netstat -ant |grep 1808 |
TIME_WAIT是主动断连方出现的状态( 2MSL)
被动关闭方收到fin后有两种选择
如下描述是server端主动关闭的情况
1 如果client也立即断开,那么Server的这个连接会进入 TIME_WAIT状态
1 | # netstat -ant |grep 1808 |
2 client 坚持不断开过 Server 一段时间后(3.10:net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120, 4.19:net.ipv4.tcp_fin_timeout = 15)会结束这个连接但是client还是会 在CLOSE_WAIT 直到client进程退出
1 | # netstat -ant |grep 1808 |
CLOSE_WAIT
CLOSE_WAIT是被动关闭端在等待应用进程的关闭
通常,CLOSE_WAIT 状态在服务器停留时间很短,如果你发现大量的 CLOSE_WAIT 状态,那么就意味着被动关闭的一方没有及时发出 FIN 包,一般有如下几种可能:
- 程序问题:如果代码层面忘记了 close 相应的 socket 连接,那么自然不会发出 FIN 包,从而导致 CLOSE_WAIT 累积;或者代码不严谨,出现死循环之类的问题,导致即便后面写了 close 也永远执行不到。
- 响应太慢或者超时设置过小:如果连接双方不和谐,一方不耐烦直接 timeout,另一方却还在忙于耗时逻辑,就会导致 close 被延后。响应太慢是首要问题,不过换个角度看,也可能是 timeout 设置过小。
- BACKLOG 太大:此处的 backlog 不是 syn backlog,而是 accept 的 backlog,如果 backlog 太大的话,设想突然遭遇大访问量的话,即便响应速度不慢,也可能出现来不及消费的情况,导致多余的请求还在队列里就被对方关闭了。
如果你通过「netstat -ant」或者「ss -ant」命令发现了很多 CLOSE_WAIT 连接,请注意结果中的「Recv-Q」和「Local Address」字段,通常「Recv-Q」会不为空,它表示应用还没来得及接收数据,而「Local Address」表示哪个地址和端口有问题,我们可以通过「lsof -i:
如果是我们自己写的一些程序,比如用 HttpClient 自定义的蜘蛛,那么八九不离十是程序问题,如果是一些使用广泛的程序,比如 Tomcat 之类的,那么更可能是响应速度太慢或者 timeout 设置太小或者 BACKLOG 设置过大导致的故障。
server端大量close_wait案例
看了这么多理论,下面用个案例来检查自己对close_wait理论(tcp握手本质)的掌握。同时也可以看看自己从知识到问题的推理能力(跟文章最后的知识效率呼应一下)。
问题描述:
服务端出现大量CLOSE_WAIT 个数正好 等于somaxconn(调整somaxconn后 CLOSE_WAIT 也会跟着变成一样的值)
根据这个描述先不要往下看,自己推理分析下可能的原因。
我的推理如下:
从这里看起来,client跟server成功建立了somaxconn个连接(somaxconn小于backlog,所以accept queue只有这么大),但是应用没有accept这个连接,导致这些连接一直在accept queue中。但是这些连接的状态已经是ESTABLISHED了,也就是client可以发送数据了,数据发送到server后OS ack了,并放在os的tcp buffer中,应用一直没有accept也就没法读取数据。client于是发送fin(可能是超时、也可能是简单发送数据任务完成了得结束连接),这时Server上这个连接变成了CLOSE_WAIT .
也就是从开始到结束这些连接都在accept queue中,没有被应用accept,很快他们又因为client 发送 fin 包变成了CLOSE_WAIT ,所以始终看到的是服务端出现大量CLOSE_WAIT 并且个数正好等于somaxconn(调整somaxconn后 CLOSE_WAIT 也会跟着变成一样的值)。
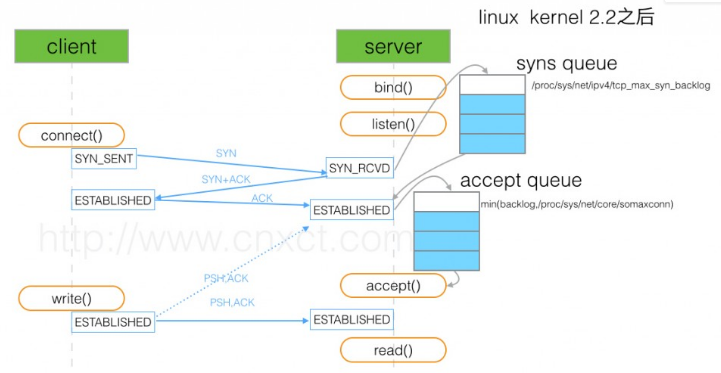
如下图所示,在连接进入accept queue后状态就是ESTABLISED了,也就是可以正常收发数据和fin了。client是感知不到server是否accept()了,只是发了数据后server的os代为保存在OS的TCP buffer中,因为应用没来取自然在CLOSE_WAIT 后应用也没有close(),所以一直维持CLOSE_WAIT 。
得检查server 应用为什么没有accept。
结论:
这个case的最终原因是因为OS的open files设置的是1024,达到了上限,进而导致server不能accept,但这个时候的tcp连接状态已经是ESTABLISHED了(这个状态变换是取决于内核收发包,跟应用是否accept()无关)。
同时从这里可以推断 netstat 即使看到一个tcp连接状态是ESTABLISHED也不能代表占用了 open files句柄。此时client可以正常发送数据了,只是应用服务在accept之前没法receive数据和close连接。
TCP连接状态图
总结下
tcp所有特性基本上核心都是为了可靠传输这个目标来服务的,然后有一些是出于优化性能的目的
三次握手建连接的详细过程可以参考我这篇: 关于TCP 半连接队列和全连接队列
后续希望再通过几个案例来深化一下上面的知识。
为什么要案例来深化一下上面的知识,说点关于学习的题外话
什么是工程效率,什么是知识效率
有些人纯看理论就能掌握好一门技能,还能举三反一,这是知识效率,这种人非常少;
大多数普通人都是看点知识然后结合实践来强化理解理论,要经过反反复复才能比较好地掌握一个知识,这就是工程效率,讲究技巧、工具来达到目的。
对于费曼(参考费曼学习法)这样的聪明人就是很容易看到一个理论知识就能理解这个理论知识背后的本质。
肯定知识效率最牛逼,但是拥有这种能力的人毕竟非常少。从小我们周边那种不怎么学的学霸型基本都是这类,这种学霸都还能触类旁通非常快地掌握一个新知识。剩下的绝大部分只能拼时间(刷题)+方法+总结等也能掌握一些知识
非常遗憾我就是工程效率型,只能羡慕那些知识效率型的学霸。但是这事又不能独立看待有些人在某些方向上是工程效率型,有些方向就又是知识效率型(有一种知识效率型是你掌握的实在太多也就比较容易触类旁通了,这算灰色知识效率型)
使劲挖掘自己在知识效率型方面的能力吧,即使灰色地带也行啊。