Jan 22 17:21:43 l57f12112.sqa.nu8 dockerd[68317]: time="2021-01-22T17:21:43.991179104+08:00" level=warning msg="failed to load plugin io.containerd.snapshotter.v1.aufs" error="modprobe aufs failed: "modprobe: FATAL: Module aufs not found.\n": exit status 1" Jan 22 17:21:43 l57f12112.sqa.nu8 dockerd[68317]: time="2021-01-22T17:21:43.991371956+08:00" level=warning msg="could not use snapshotter btrfs in metadata plugin" error="path /var/lib/docker/containerd/daemon/io.containerd.snapshotter.v1.btrfs must be a btrfs filesystem to be used with the btrfs snapshotter" Jan 22 17:21:43 l57f12112.sqa.nu8 dockerd[68317]: time="2021-01-22T17:21:43.991381620+08:00" level=warning msg="could not use snapshotter aufs in metadata plugin" error="modprobe aufs failed: "modprobe: FATAL: Module aufs not found.\n": exit status 1" Jan 22 17:21:43 l57f12112.sqa.nu8 dockerd[68317]: time="2021-01-22T17:21:43.991388991+08:00" level=warning msg="could not use snapshotter zfs in metadata plugin" error="path /var/lib/docker/containerd/daemon/io.containerd.snapshotter.v1.zfs must be a zfs filesystem to be used with the zfs snapshotter: skip plugin" Jan 22 17:21:44 l57f12112.sqa.nu8 systemd[1]: Stopping Docker Application Container Engine... Jan 22 17:21:45 l57f12112.sqa.nu8 dockerd[68317]: failed to start daemon: Error initializing network controller: list bridge addresses failed: PredefinedLocalScopeDefaultNetworks List: [172.17.0.0/16 172.18.0.0/16 172.19.0.0/16 172.20.0.0/16 172.21.0.0/16 172.22.0.0/16 172.23.0.0/16 172.24.0.0/16 172.25.0.0/16 172.26.0.0/16 172.27.0.0/16 172.28.0.0/16 172.29.0.0/16 172.30.0.0/16 172.31.0.0/16 192.168.0.0/20 192.168.16.0/20 192.168.32.0/20 192.168.48.0/20 192.168.64.0/20 192.168.80.0/20 192.168.96.0/20 192.168.112.0/20 192.168.128.0/20 192.168.144.0/20 192.168.160.0/20 192.168.176.0/20 192.168.192.0/20 192.168.208.0/20 192.168.224.0/20 192.168.240.0/20]: no available network Jan 22 17:21:45 l57f12112.sqa.nu8 systemd[1]: docker.service: main process exited, code=exited, status=1/FAILURE Jan 22 17:21:45 l57f12112.sqa.nu8 systemd[1]: Stopped Docker Application Container Engine. Jan 22 17:21:45 l57f12112.sqa.nu8 systemd[1]: Unit docker.service entered failed state. Jan 22 17:21:45 l57f12112.sqa.nu8 systemd[1]: docker.service failed.
where the 192.168.y.x is the MAIN machine IP and /24 that ip netmask. Docker will use this network range for building the bridge and firewall riles. The –debug is not really needed, but might help if something else fails.
After starting once, you can kill the docker and start as usual. AFAIK, docker have created a cache config for that –bip and should work now without it. Of course, if you clean the docker cache, you may need to do this again.
UNIT LOAD PATH Unit files are loaded from a set of paths determined during compilation, described in the two tables below. Unit files found in directories listed earlier override files with the same name in directories lower in the list.
Table 1. Load path when running in system mode (--system). ┌────────────────────────┬─────────────────────────────┐ │Path │ Description │ ├────────────────────────┼─────────────────────────────┤ │/etc/systemd/system │ Local configuration │ ├────────────────────────┼─────────────────────────────┤ │/run/systemd/system │ Runtime units │ ├────────────────────────┼─────────────────────────────┤ │/usr/lib/systemd/system │ Units of installed packages │ └────────────────────────┴─────────────────────────────┘
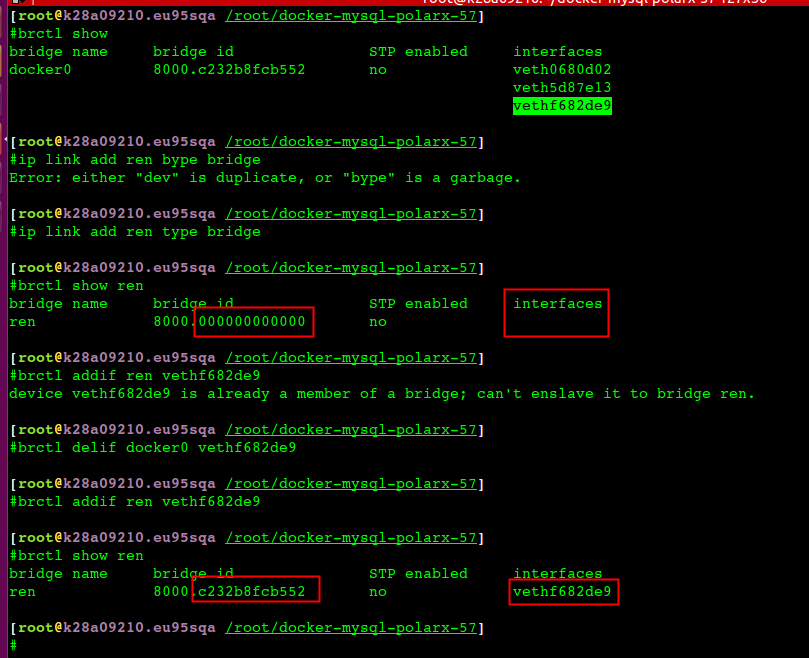
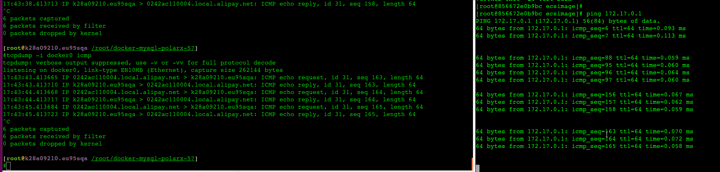
// ip netns 获取容器网络信息 1022 [2021-04-14 15:53:06] docker inspect -f '{{.State.Pid}}' ab4e471edf50 //获取容器进程id 1023 [2021-04-14 15:53:30] ls /proc/79828/ns/net 1024 [2021-04-14 15:53:57] ln -sfT /proc/79828/ns/net /var/run/netns/ab4e471edf50 //link 以便ip netns List能访问 // 宿主机上查看容器ip 1026 [2021-04-14 15:54:11] ip netns list 1028 [2021-04-14 15:55:19] ip netns exec ab4e471edf50 ifconfig //nsenter调试网络 Get the pause container's sandboxkey: root@worker01:~# docker inspect k8s_POD_ubuntu-5846f86795-bcbqv_default_ea44489d-3dd4-11e8-bb37-02ecc586c8d5_0 | grep SandboxKey "SandboxKey": "/var/run/docker/netns/82ec9e32d486", root@worker01:~# Now, using nsenter you can see the container's information. root@worker01:~# nsenter --net=/var/run/docker/netns/82ec9e32d486 ip addr show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 3: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default link/ether 0a:58:0a:f4:01:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.244.1.2/24 scope global eth0 valid_lft forever preferred_lft forever Identify the peer_ifindex, and finally you can see the veth pair endpoint in root namespace. root@worker01:~# nsenter --net=/var/run/docker/netns/82ec9e32d486 ethtool -S eth0 NIC statistics: peer_ifindex: 7 root@worker01:~# root@worker01:~# ip -d link show | grep '7: veth' 7: veth5e43ca47@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default root@worker01:~#
To make this interface you'd first need to make sure that you have the dummy kernel module loaded. You can do this like so: $ sudo lsmod | grep dummy $ sudo modprobe dummy $ sudo lsmod | grep dummy dummy 12960 0 With the driver now loaded you can create what ever dummy network interfaces you like:
$ sudo ip link add eth10 type dummy
修改网卡名字
1 2 3 4 5 6 7 8 9
ip link set ens33 down ip link set ens33 name eth0 ip link set eth0 up
mv /etc/sysconfig/network-scripts/ifcfg-{ens33,eth0} sed -ire "s/NAME=\"ens33\"/NAME=\"eth0\"/" /etc/sysconfig/network-scripts/ifcfg-eth0 sed -ire "s/DEVICE=\"ens33\"/DEVICE=\"eth0\"/" /etc/sysconfig/network-scripts/ifcfg-eth0 MAC=$(cat /sys/class/net/eth0/address) echo -n 'HWADDR="'$MAC\" >> /etc/sysconfig/network-scripts/ifcfg-eth0
OS版本
搞Docker就得上el7, 6的性能太差了 Docker 对 Linux 内核版本的最低要求是3.10,如果内核版本低于 3.10 会缺少一些运行 Docker 容器的功能。这些比较旧的内核,在一定条件下会导致数据丢失和频繁恐慌错误。
[13155344.231942] EXT4-fs warning (device sdd): ext4_dx_add_entry:2461: Directory (ino: 3145729) index full, reach max htree level :2 [13155344.231944] EXT4-fs warning (device sdd): ext4_dx_add_entry:2465: Large directory feature is not enabled on this filesystem