如何定位上亿次调用才出现一次的Bug
如何定位上亿次调用才出现一次的Bug
引文
对于那种出现概率非常低,很难重现的bug有时候总是感觉有力使不上,比如这个问题
正好最近也碰到一个极低概率下的异常,我介入前一大帮人花了几个月,OS、ECS、网络等等各个环节都被怀疑一遍但是又都没有实锤,所以把过程记录下。
问题背景
客户会调用我们的一个服务,正常都是client request -> server response 如此反复直到client主动完成,然后断开tcp连接。但是就是在这个过程中,有极低的概率client 端抛出连接非正常断开的异常堆栈,由于这个业务比较特殊,客户无法接受这种异常,所以要求一定要解决这个问题。
重现麻烦,只能在客户环境,让客户把他们的测试跑起来才能一天重现1-2次,每次跟客户沟通成本很高。出现问题的精确时间点不好确定
tcpdump 抓包所看到的问题表现
在client 和 server上一直进行tcpdump 抓包,然后压力测试不停地跑,一旦client抛了连接异常,根据时间点、端口信息在两边的抓包中分析当时的tcp会话
比如,通过tcpdump分析到的会话是这样的: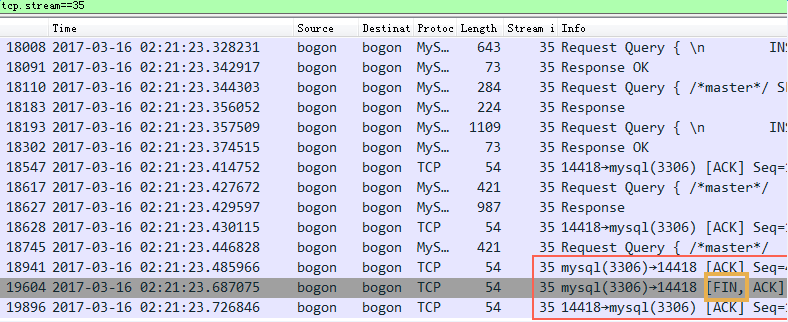
如上图所示,正常都是client发送request,server返回response,但是出问题的时候(截图红框)server收到了client的request,也回复了ack给client说收到请求了,但是很快server又回复了一个fin包(server主动发起四次挥手断开连接),这是不正常的。
到这里可以有一个明确的结论:出问题都是因为server主动发起连接断开的fin包,即使刚收到client的request请求还没有返回response
开发增加debug日志
在server端的应用中可能会调用 socket.close 的地方都增加了日志,但是实际发生异常的时候没有任何日志输出,所以到此开发认为应用代码没有问题(毕竟没有证据–实际不能排除)
怀疑ECS网络抖动(是个好背锅侠,什么锅都可以背)
申请单独的物理机资源给客户,保证没有其它应用来争抢网络和其它资源,前三天一次异常也没有发生(在ECS上一天发生1-2次),非常高兴以为找到问题了。结果第四天异常再次出现,更换物理机也只是好像偶然性地降低了发生频率而已。
去底层挖掘tcp协议,到底什么条件下会出现主动断开连接
实际也没有什么进展
用strace、pstack去监控 socket.close 这个事件
但实际可能在上亿次正常的 socket.close (查询全部结束,client主动请求断开连接)才会出现一次不正常的 socket.close .量太大,还没发在这么多事件中区分那个是不正常的close
应用被 OOM kill
调查过程中为了更快地重现异常,将客户端连接都改成长连接,这样应用不再去调 socket.close ,除非超时、异常之类的,这样一旦出现不正常的 socket.close 就更容易定位了。
实际跑了一段时间后,发现确实 tcpdump 能抓到很多 server在接收到request还没有返回response的时候主动发送 fin包来断开连接的情况,跟前面的症状是一模一样的。但是最终发现这个时候应用被杀掉了,只是说明应用被杀的情况下 server会主动去掉 socket.close关闭连接,但这只是充分条件,而不是必要条件。实际生产线上也没有被 OOM kill过。
给力的开发同学
分析了这个异常后,开发简化了整个测试,实现client上跑一行PHP代码反复调用就能够让这个bug触发,这一下把整个测试重现bug的过程简化了,终于不再需要客户配合了,让问题的定位效率快了一个数量级。
为了快速地定位到异常的具体连接,实现脚本来自动分析tcpdump结果找到异常close的连接
快速在tcpdump包中找到出问题的那个stream(这个命令行要求tshark的版本为1.12及以上,默认的阿里服务器上的版本都太低,解析不了_ws.col.Info列):
tshark -r capture.pcap135 -T fields -e frame.number -e frame.time_epoch -e ip.addr -e tcp.port -e tcp.stream -e _ws.col.Info | egrep "FIN|Request Quit" | awk '{ print $5, $6 $7 }' | sort -k1n | awk '{ print $1 }' | uniq -c | grep -v "^ 3" | less
在这一系列的工具作用下,稳定跑上一天,异常能发生3、4次,产生的日志和网络包有几百G。
出现问题的后,通过上面的脚本分析连接异常断开的client ip+port和时间,同时拿这三个信息到下面的异常堆栈中搜索匹配找到调用 socket.close()的堆栈。
上Btrace 监听所有 socket.close 事件
@OnMethod(clazz="+java.net.Socket", method="close")
public static void onSocketClose(@Self Object me) {
println("\n==== java.net.Socket#close ====");
BTraceUtils.println(BTraceUtils.timestamp() );
BTraceUtils.println(BTraceUtils.Time.millis() );
println(concat("Socket closing:", str(me)));
println(concat("thread: ", str(currentThread())));
printFields(me);
jstack();
}
终于在出现异常的时候btrace抓到了异常的堆栈,在之前代码review看来不可能的逻辑里server主动关闭了连接

图左是应用代码,图右是关闭连接的堆栈,有了这个堆栈就可以去修复问题了
实际上这里可能有几个问题:
- buffer.position 是不可能为0的;
- 即使buffer.position 等于0 也不应该直接 socket.close, 可能发送error信息给客户端更好;
总结
- 最终原因是因为NIO过程中buffer有极低的概率被两个socket重用,从而导致出现正在使用的buffer被另外一个socket拿过去并且设置了buffer.position为0,进而导致前一个socket认为数据异常赶紧close了。
- 开发简化问题的重现步骤非常关键,同时对异常进行分类分析,加快了定位效率
- 能够通过tcpdump去抓包定位到具体问题大概所在点这是比较关键的一步,同时通过btrace再去监控出问题的调用堆栈从而找到具体代码行。
- 过程看似简单,实际牵扯了一大波工程师进来,经过几个月才最终定位到出问题的代码行,确实不容易