vxlan网络性能测试
vxlan网络性能测试
缘起
Docker集群中需要给每个容器分配一个独立的IP,同时在不同宿主机环境上的容器IP又要能够互相联通,所以需要一个overlay的网络(vlan也可以解决这个问题)
overlay网络就是把容器之间的网络包重新打包在宿主机的IP包里面,传到目的容器所在的宿主机后,再把这个overlay的网络包还原成容器包交给容器
这里多了一次封包解包的过程,所以性能上必然有些损耗
封包解包可以在应用层(比如Flannel的UDP封装),但是需要将每个网络包从内核态复制到应用态进行封包,所以性能非常差
比较新的Linux内核带了vxlan功能,也就是将网络包直接在内核态完成封包,所以性能要好很多,本文vxlan指的就是这种方式
本文主要是比较通过vxlan实现的overlay网络之间的性能(相对宿主机之间而言)
iperf3 下载和安装
- wget http://downloads.es.net/pub/iperf/iperf-3.9.tar.gz (https://downloads.es.net/pub/iperf/)
- tar zxvf iperf-3.0.6.tar.gz
- cd iperf-3.0.6
- ./configure
- make install
测试环境宿主机的基本配置情况
conf:
loc_node = e12174.bja
loc_cpu= 2 Cores: Intel Xeon E5-2430 0 @ 2.20GHz
loc_os = Linux 3.10.0-327.ali2010.alios7.x86_64
loc_qperf = 0.4.9
rem_node = e26108.bja
rem_cpu= 2 Cores: Intel Xeon E5-2430 0 @ 2.20GHz
rem_os = Linux 3.10.0-327.ali2010.alios7.x86_64
rem_qperf = 0.4.9
容器到自身宿主机之间, 跟两容器在同一宿主机,速度差不多
$iperf3 -c 192.168.6.6
Connecting to host 192.168.6.6, port 5201
[ 4] local 192.168.6.1 port 21112 connected to 192.168.6.6 port 5201
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 13.9 GBytes 11.9 Gbits/sec1 sender
[ 4] 0.00-10.00 sec 13.9 GBytes 11.9 Gbits/sec receiver
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 14.2 GBytes 12.2 Gbits/sec 139 sender
[ 4] 0.00-10.00 sec 14.2 GBytes 12.2 Gbits/sec receiver
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 13.9 GBytes 11.9 Gbits/sec 96 sender
[ 4] 0.00-10.00 sec 13.9 GBytes 11.9 Gbits/sec receiver
从宿主机A到宿主机B上的容器
$iperf3 -c 192.168.6.6
Connecting to host 192.168.6.6, port 5201
[ 4] local 192.168.6.1 port 47940 connected to 192.168.6.6 port 5201
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 409 MBytes 343 Mbits/sec0 sender
[ 4] 0.00-10.00 sec 405 MBytes 340 Mbits/sec receiver
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 389 MBytes 326 Mbits/sec 14 sender
[ 4] 0.00-10.00 sec 386 MBytes 324 Mbits/sec receiver
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 460 MBytes 386 Mbits/sec7 sender
[ 4] 0.00-10.00 sec 458 MBytes 384 Mbits/sec receiver
两宿主机之间测试
$iperf3 -c 10.125.26.108
Connecting to host 10.125.26.108, port 5201
[ 4] local 10.125.12.174 port 24309 connected to 10.125.26.108 port 5201
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 471 MBytes 395 Mbits/sec0 sender
[ 4] 0.00-10.00 sec 469 MBytes 393 Mbits/sec receiver
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 428 MBytes 359 Mbits/sec0 sender
[ 4] 0.00-10.00 sec 426 MBytes 357 Mbits/sec receiver
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 430 MBytes 360 Mbits/sec0 sender
[ 4] 0.00-10.00 sec 427 MBytes 358 Mbits/sec receiver
两容器之间(跨宿主机)
$iperf3 -c 192.168.6.6
Connecting to host 192.168.6.6, port 5201
[ 4] local 192.168.6.5 port 37719 connected to 192.168.6.6 port 5201
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 403 MBytes 338 Mbits/sec 18 sender
[ 4] 0.00-10.00 sec 401 MBytes 336 Mbits/sec receiver
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 428 MBytes 359 Mbits/sec 15 sender
[ 4] 0.00-10.00 sec 425 MBytes 356 Mbits/sec receiver
[ ID] Interval Transfer Bandwidth Retr
[ 4] 0.00-10.00 sec 508 MBytes 426 Mbits/sec 11 sender
[ 4] 0.00-10.00 sec 506 MBytes 424 Mbits/sec receiver
PPS 压测
必须到这里下载最新版的iperf2 才有增强的 pps 测试能力
购买的 ECS PPS为 600 万
1 | iperf -c 10.0.1.2 -t 600 -u -i 1 -l 16 -b 500kpps -P 16 //实际outgoing 有丢包 |
压测机器内核 3.10,故意不打满,160万pps
server收包端的top,几乎看不到si 和ksoftirq:

对应的tsar pps 监控:

client端的iperf 数据:

在如上基础上加大压力,可以看到si% 快速被打爆,和流量不成正比,大量丢包



实际流量只是从160万pps 增加到320万pps,但是si CPU的增加可不是翻倍,而是出现了踩踏,丢包也大量出现(因为si% 达到100%)
在4.19/5.10的内核上进行如上验证,也是一样出现了软中断CPU踩踏
带宽压测
netperf 安装依赖 automake-1.14, 环境无法升级,放弃
qperf 测试工具
- sudo yum install qperf -y
两台宿主机之间
$qperf -t 10 10.125.26.108 tcp_bw tcp_lat
tcp_bw:
bw = 50.5 MB/sec
tcp_lat:
latency = 332 us
包的大小分别为1和128
$qperf -oo msg_size:1 10.125.26.108 tcp_bw tcp_lat
tcp_bw:
bw = 1.75 MB/sec
tcp_lat:
latency = 428 us
$qperf -oo msg_size:128 10.125.26.108 tcp_bw tcp_lat
tcp_bw:
bw = 57.8 MB/sec
tcp_lat:
latency = 504 us
两台宿主机之间,包的大小从一个字节每次翻倍测试
$qperf -oo msg_size:1:4K:*2 -vu 10.125.26.108 tcp_bw tcp_lat
tcp_bw:
bw= 1.86 MB/sec
msg_size = 1 bytes
tcp_bw:
bw= 3.54 MB/sec
msg_size = 2 bytes
tcp_bw:
bw= 6.43 MB/sec
msg_size = 4 bytes
tcp_bw:
bw= 14.3 MB/sec
msg_size = 8 bytes
tcp_bw:
bw= 27.1 MB/sec
msg_size =16 bytes
tcp_bw:
bw= 42.3 MB/sec
msg_size =32 bytes
tcp_bw:
bw= 51.8 MB/sec
msg_size =64 bytes
tcp_bw:
bw= 49.7 MB/sec
msg_size = 128 bytes
tcp_bw:
bw= 48.2 MB/sec
msg_size = 256 bytes
tcp_bw:
bw= 58 MB/sec
msg_size = 512 bytes
tcp_bw:
bw= 54.6 MB/sec
msg_size = 1 KiB (1,024)
tcp_bw:
bw= 48.7 MB/sec
msg_size = 2 KiB (2,048)
tcp_bw:
bw= 53.6 MB/sec
msg_size = 4 KiB (4,096)
tcp_lat:
latency = 432 us
msg_size =1 bytes
tcp_lat:
latency = 480 us
msg_size =2 bytes
tcp_lat:
latency = 441 us
msg_size =4 bytes
tcp_lat:
latency = 487 us
msg_size =8 bytes
tcp_lat:
latency = 404 us
msg_size = 16 bytes
tcp_lat:
latency = 335 us
msg_size = 32 bytes
tcp_lat:
latency = 338 us
msg_size = 64 bytes
tcp_lat:
latency = 401 us
msg_size = 128 bytes
tcp_lat:
latency = 496 us
msg_size = 256 bytes
tcp_lat:
latency = 684 us
msg_size = 512 bytes
tcp_lat:
latency = 534 us
msg_size =1 KiB (1,024)
tcp_lat:
latency = 681 us
msg_size =2 KiB (2,048)
tcp_lat:
latency = 701 us
msg_size =4 KiB (4,096)
两个容器之间(分别在两台宿主机上)
$qperf -t 10 192.168.6.6 tcp_bw tcp_lat
tcp_bw:
bw = 44.4 MB/sec
tcp_lat:
latency = 512 us
包的大小分别为1和128
$qperf -oo msg_size:1 192.168.6.6 tcp_bw tcp_lat
tcp_bw:
bw = 1.13 MB/sec
tcp_lat:
latency = 630 us
$qperf -oo msg_size:128 192.168.6.6 tcp_bw tcp_lat
tcp_bw:
bw = 44.2 MB/sec
tcp_lat:
latency = 526 us
两个容器之间,包的大小从一个字节每次翻倍测试
$qperf -oo msg_size:1:4K:*2 192.168.6.6 -vu tcp_bw tcp_lat
tcp_bw:
bw= 1.06 MB/sec
msg_size = 1 bytes
tcp_bw:
bw= 2.29 MB/sec
msg_size = 2 bytes
tcp_bw:
bw= 3.79 MB/sec
msg_size = 4 bytes
tcp_bw:
bw= 7.66 MB/sec
msg_size = 8 bytes
tcp_bw:
bw= 14 MB/sec
msg_size = 16 bytes
tcp_bw:
bw= 24.4 MB/sec
msg_size =32 bytes
tcp_bw:
bw= 36 MB/sec
msg_size = 64 bytes
tcp_bw:
bw= 46.7 MB/sec
msg_size = 128 bytes
tcp_bw:
bw= 56 MB/sec
msg_size = 256 bytes
tcp_bw:
bw= 42.2 MB/sec
msg_size = 512 bytes
tcp_bw:
bw= 57.6 MB/sec
msg_size = 1 KiB (1,024)
tcp_bw:
bw= 52.3 MB/sec
msg_size = 2 KiB (2,048)
tcp_bw:
bw= 41.7 MB/sec
msg_size = 4 KiB (4,096)
tcp_lat:
latency = 447 us
msg_size =1 bytes
tcp_lat:
latency = 417 us
msg_size =2 bytes
tcp_lat:
latency = 503 us
msg_size =4 bytes
tcp_lat:
latency = 488 us
msg_size =8 bytes
tcp_lat:
latency = 452 us
msg_size = 16 bytes
tcp_lat:
latency = 537 us
msg_size = 32 bytes
tcp_lat:
latency = 712 us
msg_size = 64 bytes
tcp_lat:
latency = 521 us
msg_size = 128 bytes
tcp_lat:
latency = 450 us
msg_size = 256 bytes
tcp_lat:
latency = 442 us
msg_size = 512 bytes
tcp_lat:
latency = 630 us
msg_size =1 KiB (1,024)
tcp_lat:
latency = 519 us
msg_size =2 KiB (2,048)
tcp_lat:
latency = 621 us
msg_size =4 KiB (4,096)
结论
- iperf3测试带宽方面vxlan网络基本和宿主机一样,没有什么损失
- qperf测试vxlan的带宽只相当于宿主机的60-80%
- qperf测试一个字节的小包vxlan的带宽只相当于宿主机的60-65%
- 由上面的结论猜测:物理带宽更大的情况下vxlan跟宿主机的差别会扩大
qperf安装更容易; iperf3 可以多连接并发测试,可以控制包的大小、nodelay等等
网络方案性能
| OS | Host | Docker_Host | Docker_NAT_IPTABLES | Docker_NAT_PROXY | Docker_BRIDGE_VLAN | Docker_OVS_VLAN | Docker_HAVS_VLAN | |
|---|---|---|---|---|---|---|---|---|
| TPS | 6U | 118727.5 | 115962.5 | 83281.08 | 29104.33 | 57327.15 | 55606.37 | 54686.88 |
| TPS | 7U | 117501.4 | 110010.7 | 101131.2 | 34795.39 | 108857.7 | 107554.3 | 105021 |
| 6U | BASE | -2.38% | -42.56% | -307.94% | -107.11% | -113.51% | -117.10% | |
| 7U | BASE | -6.81% | -16.19% | -237.69% | -7.94% | -9.25% | -11.88% | |
| RT | 6U(ms) | 0.330633 | 0.362042 | 0.505125 | 1.423767 | 0.799308 | 0.763842 | 0.840458 |
| RT | 7U(ms) | 0.3028 | 0.321267 | 0.346325 | 1.183225 | 0.325333 | 0.335708 | 0.33535 |
| 6U(us) | BASE | 31.40833 | 174.4917 | 1093.133 | 468.675 | 433.2083 | 509.825 | |
| 7U(us) | BASE | 18.46667 | 43.525 | 880.425 | 22.53333 | 32.90833 | 32.55 |
- Host:是指没有隔离的情况下,D13物理机;
- Docker_Host:是指Docker采用Host网络模式;
- Docker_NAT_IPTABLES:是指Docker采用NAT网络模式,通过IPTABLES进行网络转发。
- Docker_NAT_PROXY:是指Docker采用NAT网络模式,通过docker-proxy进行网络转发。
- Docker_BRIDGE:是指Docker采用Bridge网络模式,并且配置静态IP和VLAN701,这里使用VLAN。
- Docker_OVS_VLAN:是指Docker采用VSwitch网络模式,通过OpenVSwitch进行网络通信,使用ACS VLAN Driver。
- Docker_HAVS_VLAN:是指Docker采用VSwitch网络模式,通过HAVS进行网络通信,使用VLAN。
通过测试,汇总测试结论如下
Docker_Host网络模式在6U和7U环境下,性能比物理机方案上性能降低了2
6%左右,RT增加了1830us左右。Docker_NAT_IPTABLES网络模式在6U环境下,性能比物理机方案上性能降低了43%左右,RT增加了174us;在7U环境下,性能比物理机方案上性能降低了16%左右,RT增加了44us;此外,可以明显看出,7U环境比6U环境性能上优化了20%,RT上减少了130us左右。
Docker_NAT_PROXY网络模式在6U环境下,性能比物理机方案性能降低了300%,RT增加了1ms以上;在7U环境下,性能比物理机方案性能降低了237%,RT增加了880us以上;此外,可以明显看出,7U环境比6U环境性能上优化了20%,RT上减少了200us左右。
Docker_BRIDGE_VLAN网络模式在6U环境下,性能比物理机方案性能降低了107%,RT增加了469us;在7U环境下,性能比物理机方案性能降低了8%左右,RT增加了23us左右;此外,可以明显看出,7U环境比6U环境性能上优化了90%,RT上减少了446us。从诊断上来看,6U和7U的性能差异主要在VLAN的处理上的spin_lock,详细可以参考之前的测试验证。
Docker_OVS_VLAN网络模式在6U环境下,性能比物理机方案性能降低了114%,RT增加了433us;在7U环境下,性能比物理机方案性能降低了9%左右,RT增加了33us;此外,可以明显看出,7U环境比6U环境性能上优化了93%,RT上减少了400us。从诊断上来看,6U和7U的性能差异主要在VLAN的处理上的spin_lock。并且发现,OVS与Bridge网络模式性能上基本持平,无较大性能上的差异。
Docker_HAVS_VLAN网络模式在6U环境下,性能比物理机方案性能降低了117%,RT增加了510us;在7U环境下,性能比物理机方案性能降低了12%左右,RT增加了33us;此外,可以明显看出,7U环境比6U环境性能上优化了92%,RT上减少了477us。从诊断上来看,6U和7U的性能差异主要在VLAN的处理上的spin_lock。并且发现,HAVS与Bridge网络模式性能上基本持平,无较大性能上的差异;HAVS与OVS的性能上差异也较小,无较大性能上的差异。
SR-IOV网络模式由于存在OS、Docker、网卡等要求,非通用化方案,将作为进一步的优化方案进行探索。
网络性能结果分析(rama等同方舟vlan网络方案)
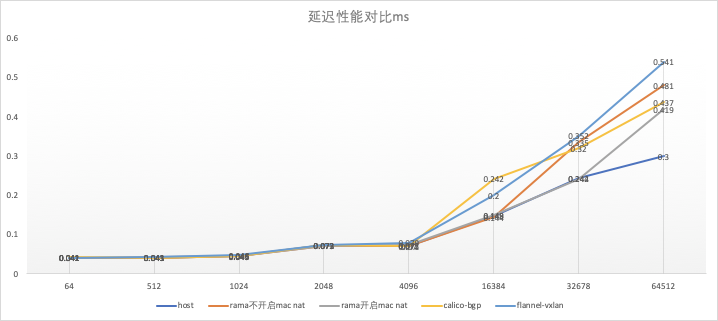
延迟数据汇总:
| host | rama不开启mac nat | rama开启mac nat | calico-bgp | flannel-vxlan | |
|---|---|---|---|---|---|
| 64 | 0.041 | 0.041 | 0.041 | 0.042 | 0.041 |
| 512 | 0.041 | 0.041 | 0.043 | 0.041 | 0.043 |
| 1024 | 0.045 | 0.045 | 0.045 | 0.046 | 0.048 |
| 2048 | 0.073 | 0.072 | 0.072 | 0.073 | 0.073 |
| 4096 | 0.072 | 0.070 | 0.073 | 0.071 | 0.079 |
| 16384 | 0.148 | 0.144 | 0.149 | 0.242 | 0.200 |
| 32678 | 0.244 | 0.335 | 0.242 | 0.320 | 0.352 |
| 64512 | 0.300 | 0.481 | 0.419 | 0.437 | 0.541 |
吞吐量数据汇总:
| host | rama不开启mac nat | rama开启mac nat | calico-bgp | flannel-vxlan | |
|---|---|---|---|---|---|
| 64 | 386 | 381 | 381 | 377 | 359 |
| 512 | 2660 | 2370 | 2530 | 2580 | 1840 |
| 1024 | 5170 | 4590 | 4880 | 4510 | 2610 |
| 2048 | 7710 | 7350 | 7040 | 7420 | 3310 |
| 4096 | 9410 | 8750 | 8220 | 8440 | 3830 |
| 16384 | 9410 | 8850 | 8460 | 8580 | 5080 |
| 32678 | 9410 | 8810 | 8580 | 8550 | 4950 |
| 65507 | 9410 | 8660 | 8410 | 8540 | 4920 |
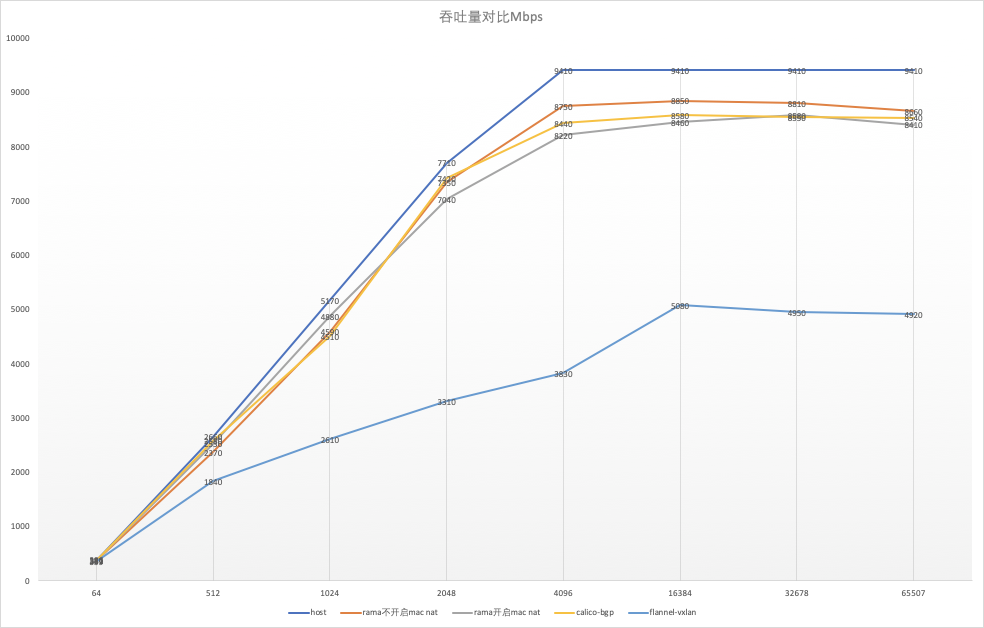
从延迟上来看,rama与calico-bgp相差不大,从数据上略低于host性能,略高于flannel-vxlan;从吞吐量上看,区别会明显一些,当报文长度大于4096 KB 时,均观察到各网络插件的吞吐量达到最大值,从最大值上来看可以初步得出以下结论:
host > rama不开启mac nat > rama开启mac nat ≈ calico-bgp > flannel-vxlan
rama不开启mac nat时性能最高,开启mac nat功能,性能与calico-bgp基本相同,并且性能大幅度高于flannel-vxlan;虽然rama开启mac nat之后的性能与每个节点上的pod数量直接相关,但由于测试 rama开启mac nat方案 的时候,取的是两个个节点上50个pod中预计性能最差的pod,基本可以反映一般情况
参考文章:
https://linoxide.com/monitoring-2/install-iperf-test-network-speed-bandwidth/