性能优化,从老中医到科学理论指导
性能优化,从老中医到科学理论指导
简单原理:
追着RT去优化,哪个环节、节点RT高,哪里就值得优化,CPU、GC等等只是导致RT高的因素,RT才是结果;
QPS=并发/RT
利特尔法则[[编辑](https://zh.wikipedia.org/w/index.php?title=利特爾法則&action=edit§ion=0&summary=/* top */ )]
利特尔法则(英语:Little’s law),基于等候理论,由约翰·利特尔在1954年提出。利特尔法则可用于一个稳定的、非占先式的系统中。其内容为:
在一个稳定的系统中,长期的平均顾客人数(L),等于长期的有效抵达率(λ),乘以顾客在这个系统中平均的等待时间(W)
或者,我们可以用一个代数式来表达:
L=λW
利特尔法则可用来确定在途存货的数量。此法则认为,系统中的平均存货等于存货单位离开系统的比率(亦即平均需求率)与存货单位在系统中平均时间的乘积。
虽然此公式看起来直觉性的合理,它依然是个非常杰出的推导结果,因为此一关系式“不受到货流程分配、服务分配、服务顺序,或任何其他因素影响”。
此一理论适用于所有系统,而且它甚至更适合用于系统中的系统。举例来说,在一间银行里,顾客等待的队伍就是一个子系统,而每一位柜员也可以被视为一个等待的子系统,而利特尔法则可以套用到任何一个子系统,也可以套用到整个银行的等待队伍之母系统。
唯一的条件就是,这个系统必须是长期稳定的,而且不能有插队抢先的情况发生,这样才能排除换场状况的可能性,例如开业或是关厂。
案例:
需要的线程数 = qps * latency(单位秒)。 依据是little’s law,类似的应用是tcp中的bandwidth-delay product。如果这个数目远大于核心数量,应该考虑用异步接口。
举例:
- qps = 2000,latency = 10ms,计算结果 = 2000 * 0.01s = 20。和常见核数在同一个数量级,用同步。
- qps = 100, latency = 5s, 计算结果 = 100 * 5s = 500。和常见核数不在同一个数量级,用异步。
- qps = 500, latency = 100ms,计算结果 = 500 * 0.1s = 50。和常见核数在同一个数量级,可用同步。如果未来延时继续增长,考虑异步。

RT
什么是 RT ?是概念还是名词还是理论?
RT其实也没那么玄乎,就是 Response Time,只不过看你目前在什么场景下,也许你是c端(app、pc等)的用户,响应时间是你请求服务器到服务器响应你的时间间隔,对于我们后端优化来说,就是接受到请求到响应用户的时间间隔。这听起来怎么感觉这不是在说废话吗?这说的不都是服务端的处理时间吗?不同在哪里?其实这里有个容易被忽略的因素,叫做网络开销。
所以客户端RT ≈ 网络开销 + 服务端RT。也就是说,一个差的网络环境会导致两个RT差距的悬殊(比如,从深圳访问上海的请求RT,远大于上海本地内的请求RT)
客户端的RT则会直接影响客户体验,要降低客户端RT,提升用户的体验,必须考虑两点,第一点是服务端的RT,第二点是网络。对于网络来说常见的有CDN、AND、专线等等,分别适用于不同的场景,有机会写个blog聊一下这个话题。
对于服务端RT来说,主要看服务端的做法。
有个公式:RT = Thread CPU Time + Thread Wait Time
从公式中可以看出,要想降低RT,就要降低 Thread CPU Time 或者 Thread Wait Time。这也是马上要重点深挖的一个知识点。
Thread CPU Time(简称CPU Time)
Thread Wait Time(简称Wait Time)
单线程QPS
我们都知道 RT 是由两部分组成 CPU Time + Wait Time 。那如果系统里只有一个线程或者一个进程并且进程中只有一个线程的时候,那么最大的 QPS 是多少呢?
假设 RT 是 199ms (CPU Time 为 19ms ,Wait Time 是 180ms ),那么 1000s以内系统可以接收的最大请求就是
1000ms/(19ms+180ms)≈5.025。
所以得出单线程的QPS公式:
单线程𝑄𝑃𝑆=1000𝑚𝑠/𝑅𝑇单线程QPS=1000ms/RT
最佳线程数
还是上面的那个话题 (CPU Time 为 19ms ,Wait Time 是 180ms ),假设CPU的核数1。假设只有一个线程,这个线程在执行某个请求的时候,CPU真正花在该线程上的时间就是CPU Time,可以看做19ms,那么在整个RT的生命周期中,还有 180ms 的 Wait Time,CPU在做什么呢?抛开系统层面的问题(这里不考虑什么时间片轮循、上下文切换等等),可以认为CPU在这180ms里没做什么,至少对于当前的业务来说,确实没做什么。
- 一核的情况
由于每个请求的接收,CPU只需要工作19ms,所以在180ms的时间内,可以认为系统还可以额外接收180ms/19ms≈9个的请求。由于在同步模型中,一个请求需要一个线程来处理,因此,我们需要额外的9个线程来处理这些请求。这样,总的线程数就是:
(180𝑚𝑠+19𝑚𝑠)/19𝑚𝑠≈10个(180ms+19ms)/19ms≈10个
多线程之后,CPU Time从19ms变成了20ms,这1ms的差值代表多线程之后上下文切换、GC带来的额外开销(对于我们java来说是jvm,其他语言另外计算),这里的1ms只是代表一个概述,你也可以把它看做n。
- 两核的情况
一核的情况下可以有10个线程,那么两核呢?在理想的情况下,可以认为最佳线程数为:2 x ( 180ms + 20ms )/20ms = 20个 - CPU利用率
我们之前说的都是CPU满载下的情况,有时候由于某个瓶颈,导致CPU不得不有效利用,比如两核的CPU,因为某个资源,只能各自使用一半的能效,这样总的CPU利用率就变成了50%,再这样的情况下,最佳线程数应该是:50% x 2 x( 180ms + 20ms )/20ms = 10个
这个等式转换成公式就是:最佳线程数 = (RT/CPU Time) x CPU 核数 x CPU利用率
当然,这不是随便推测的,在收集到的很多的一些著作或者论坛的文档里都有这样的一些实验去论述这个公式或者这个说法是正确的。
最大QPS
1.最大QPS公式推导
假设我们知道了最佳线程数,同时我们还知道每个线程的QPS,那么线程数乘以每个线程的QPS既这台机器在最佳线程数下的QPS。所以我们可以得到下图的推算。
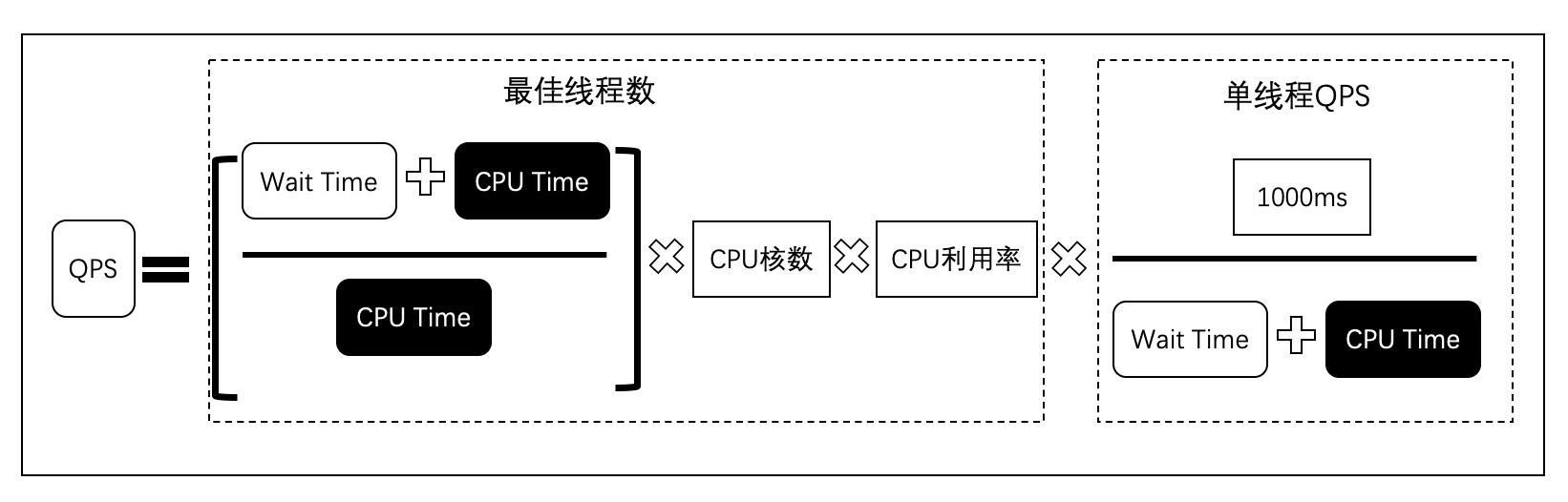
我们可以把分子和分母去约数,如下图。
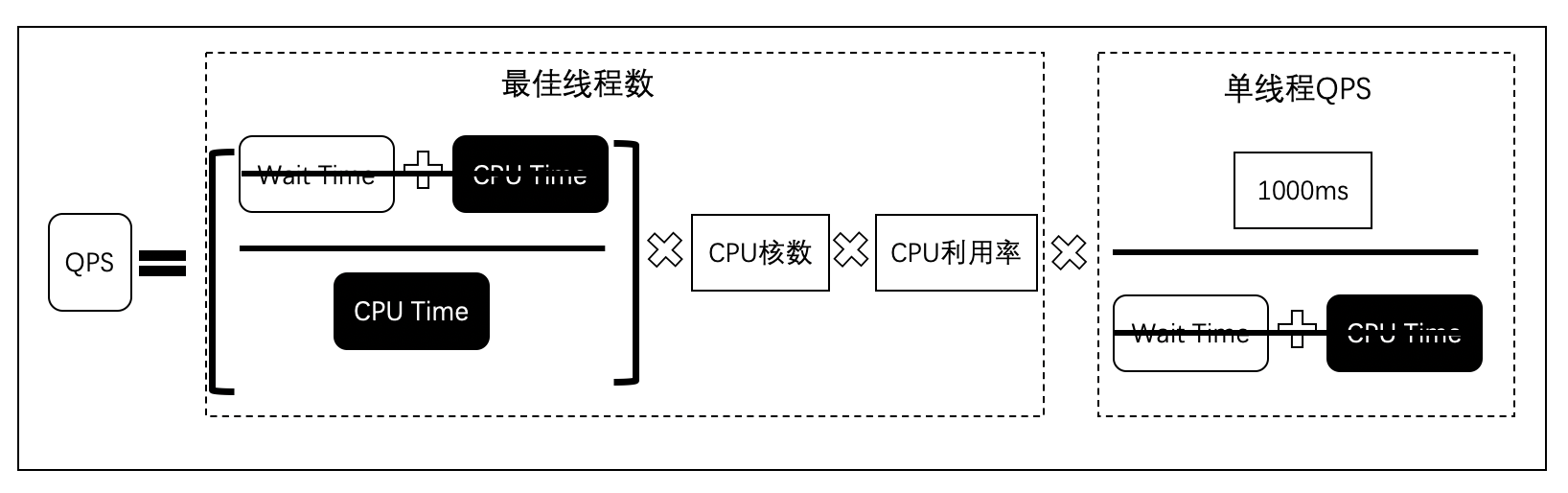
于是简化后的公式如下图.
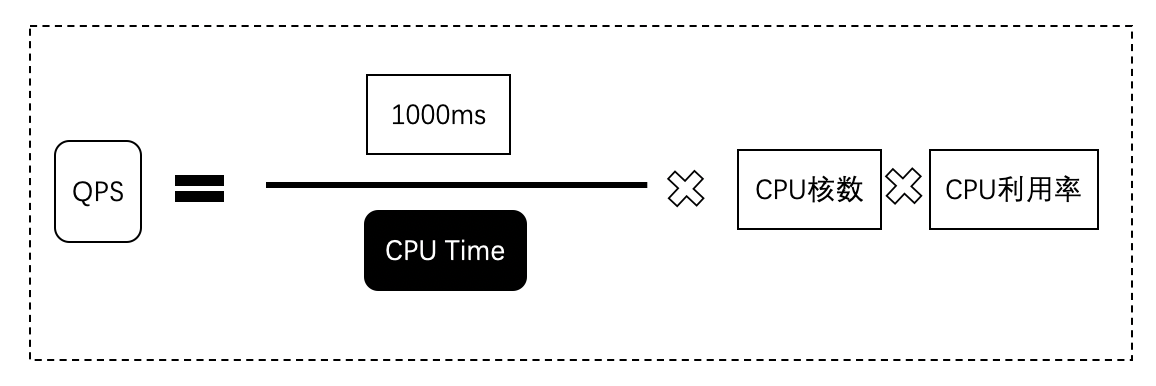
从公式可以看出,决定QPS的时CPU Time、CPU核数和CPU利用率。CPU核数是由硬件做决定的,很难操纵,但是CPU Time和CPU利用率与我们的代码息息相关。
虽然宏观上是正确的,但是推算的过程中还是有一点小小的不完美,因为多线程下的CPU Time(比如高并发下的GC次数增加消耗更多的CPU Time、线程上下文切换等等)和单线程的CPU Time是不一样的,所以会导致推算出来的结果有误差。
尤其是在同步模型下的相同业务逻辑中,单线程时的CPU Time肯定会比大量多线程的CPU Time小,但是对于异步模型来说,切换的开销会变得小很多,为什么?这里先卖个葫芦吧,看完本篇就知道了。
既然决定QPS的是CPU Time和CPU核数,那么这两个因子又是由谁来决定的呢?
理解最佳线程数量
最佳线程数量 单线程压测,总rt(total),下游依赖rt(IO), rt(CPU)=rt(total)-rt(IO)
最佳线程数量 rt(total)/rt(cpu)
从单线程跑出QPS、各个环节的RT、CPU占用等数据,然后加并发直到QPS不再增加,然后看哪个环境RT增加最大,瓶颈就在哪里
IO
IO耗时增加的RT一般都不影响QPS,最终通过加并发来提升QPS
每次测试数据都是错的,我用RT、并发、TPS一计算数据就不对。现场的人基本不理解RT和TPS同时下降是因为压力不够了(前面有瓶颈,压力打不过来),电话会议讲到半夜
思路严谨
最难讲清楚
前美国国防部长拉姆斯菲尔德:
Reports that say that something hasn’t happened are always interesting to me, because as we know, there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns—the ones we don’t know we don’t know. And if one looks throughout the history of our country and other free countries, it is the latter category that tend to be the difficult ones.
这句话总结出了人们对事物认知的三种情况:
- known knowns(已知的已知)
- known unknowns(已知的未知)
- unknown unknowns(未知的未知)
这三种情况几乎应证了我学习工作以来面对的所有难题。当我们遇到一个难题的时候,首先我们对这个问题会有一定的了解(否则你都不会遇到这个问题:)),这就是已知的已知部分;在解决这个问题的时候,我们会遇到困难,困难又有两类,一类是你知道困难的点是什么,但是暂时不知道怎么解决,需要学习,这就是已知的未知;剩下的潜伏在问题里的坑,你还没遇到的,就是未知的未知。
性能调优的优先条件是,性能分析,只有分析出系统的瓶颈,才能进行调优。而分析一个系统的性能,就要面对上面提到的三种情况。计算机系统是非常庞大的,包含了计算机体系结构、操作系统、网络、存储等,单单拎出任何一个方向都值得我们去研究很久,因此,我们在分析系统性能的时候,是无法避免地会遇到很多未知的未知问题,而我们要做的事情就是要将它们变成已知的未知,再变成已知的已知。
性能的本质
IPC:insns per cycle ,每个时钟周期执行的指令数量,越大越好
一个程序固定后,指令数量就是固定的(假设同一平台,编译后),那性能之和需要多少个时钟周期才能把这一大堆指令给执行完
如果一个程序里面没必要的循环特别多,那指令总数就特别多,必然会慢;
有的指令效率很高,一个时钟周期就能执行完比如nop(不需要读写任何变量,特快),有的指令需要多个时钟周期(比如 CAS、pause),像pause需要140个时钟周期,一般的intel跑 nop IPC 可以达到4(4条流水线并行),同样的CPU跑pause可能只有 4/140, 相差巨大
但不管怎么样,绝大多时候我们都是在固定的指令下去优化,所以我们重点关注IPC够不够高
经验:一般的程序基本都是读写内存瓶颈,所以IPC大多低于1,能到0.7 以上算是比较优秀了,这种我们把它叫做内存型业务,比如数据库、比如Nginx 都是这种;还有一些是纯计算,内存访问比较少,比如加密解密,他们的IPC大多时候会高于1.
练习:写一个能把IPC跑到最高的代码(可以试试跑一段死循环行不行);写一个能把IPC跑到最低的程序。然后用perf 去看他们的 IPC,用 top 去看他们的CPU使用率
进一步同时把这样的程序跑两份,但是将他们绑到一对超线程上,然后再看他们的IPC以及 top, 然后请思考
答案:写nop将IPC 跑到4, 写 pause 将 IPC 跑到 0.03? 两个nop跑到一对超线程上IPC打折,两个pause跑到一对超线程上,IPC不受影响
老中医经验不可缺少
量变到质变
找瓶颈,先干掉瓶颈才能优化其它
没有找到瓶颈,所做的其它优化会看不出效果,误入歧途,瞎蒙
全栈能力,一文钱难倒英雄好汉
因为关键是找瓶颈,作为java程序员如果只能看jstack、jstat可能发现的不是瓶颈