如何徒手撕Bug
如何徒手撕Bug
经常碰到bug,如果有源代码,或者源代码比较简单一般通过bug现象结合读源代码,基本能比较快解决掉。但是有些时候源代码过于复杂,比如linux kernel,比如 docker,复杂的另一方面是没法比较清晰地去理清源代码的结构。
所以不到万不得已不要碰复杂的源代码
问题
docker daemon重启,上面有几十个容器,重启后daemon基本上卡死不动了。 docker ps/exec 都没有任何响应,同时能看到很多这样的进程:
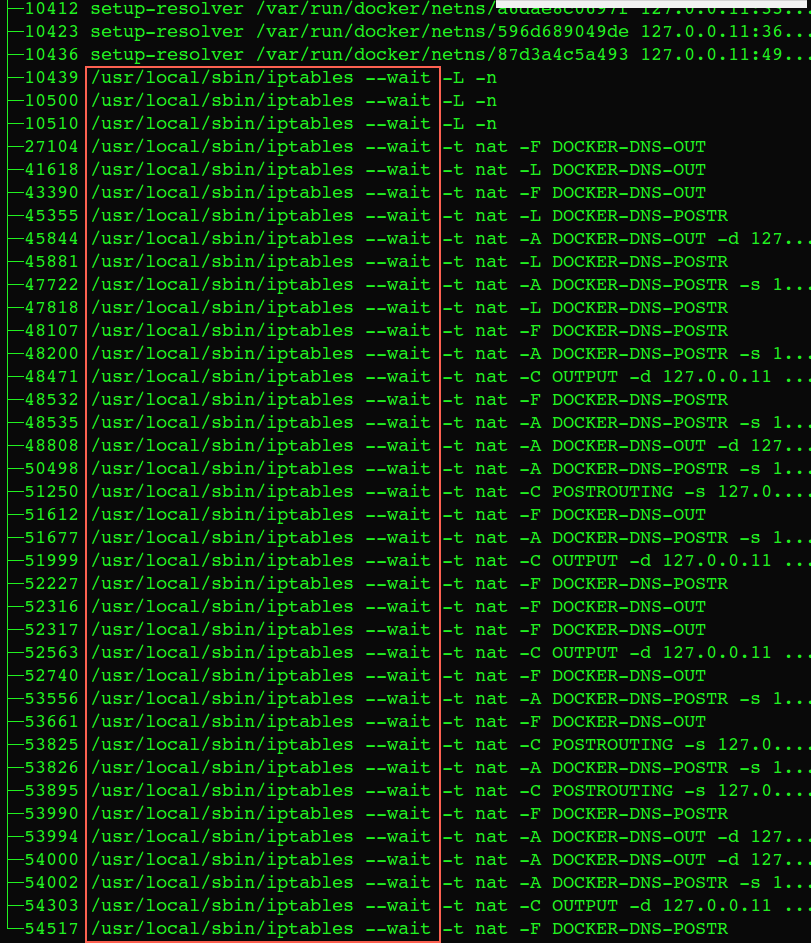
这个进程是docker daemon在启动的时候去设置每个容器的iptables,来实现dns解析。
这个时候执行 sudo iptables -L 也告诉你有其他应用锁死iptables了:
$sudo fuser /run/xtables.lock
/run/xtables.lock:1203 5544 10161 14451 14482 14503 14511 14530 14576 14602 14617 14637 14659 14664 14680 14698 14706 14752 14757 14777 14807 14815 14826 14834 14858 14872 14889 14915 14972 14973 14979 14991 15006 15031 15067 15076 15104 15127 15155 15176 15178 15179 15180 16506 17656 17657 17660 21904 21910 24174 28424 29741 29839 29847 30018 32418 32424 32743 33056 33335 59949 64006
通过上面的命令基本可以看到哪些进程在等iptables这个锁,之所以有这么多进程在等这个锁,应该是拿到锁的进程执行比较慢所以导致后面的进程拿不到锁,卡在这里
跟踪具体拿到锁的进程
$sudo lsof /run/xtables.lock | grep 3rW
iptables 36057 root3rW REG 0,190 48341 /run/xtables.lock
通过strace这个拿到锁的进程可以看到:
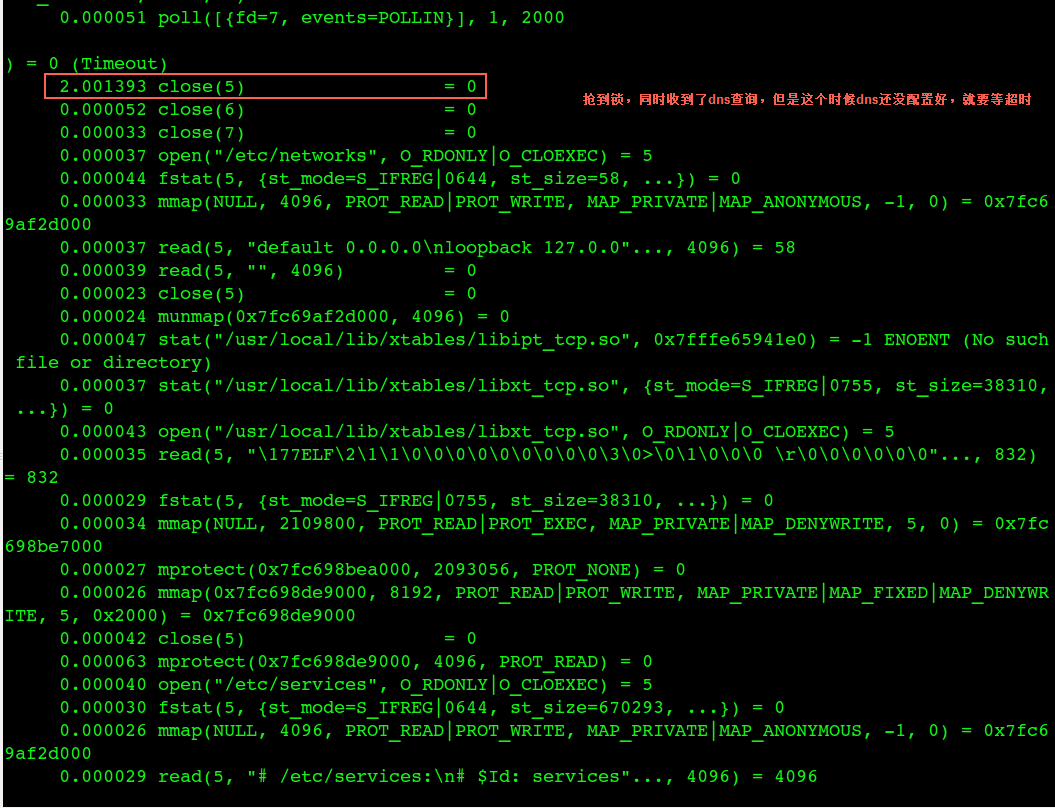
发现在这个配置容器dns的进程同时还在执行一些dns查询任务(容器发起了dns查询),但是这个时候dns还没配置好,所以这个查询会超时
看看物理机上的dns服务器配置:
$cat /etc/resolv.conf
options timeout:2 attempts:2
nameserver 10.0.0.1
nameserver 10.0.0.2
nameserver 10.0.0.3
尝试将 timeout 改到20秒、1秒分别验证一下,发现如果timeout改到20秒strace这里也会卡20秒,如果是1秒(这个时候attempts改成1,后面两个dns去掉),那么整体没有感知到任何卡顿,就是所有iptables修改的进程都很快执行完毕了
strace某个等锁的进程,拿到锁后非常快
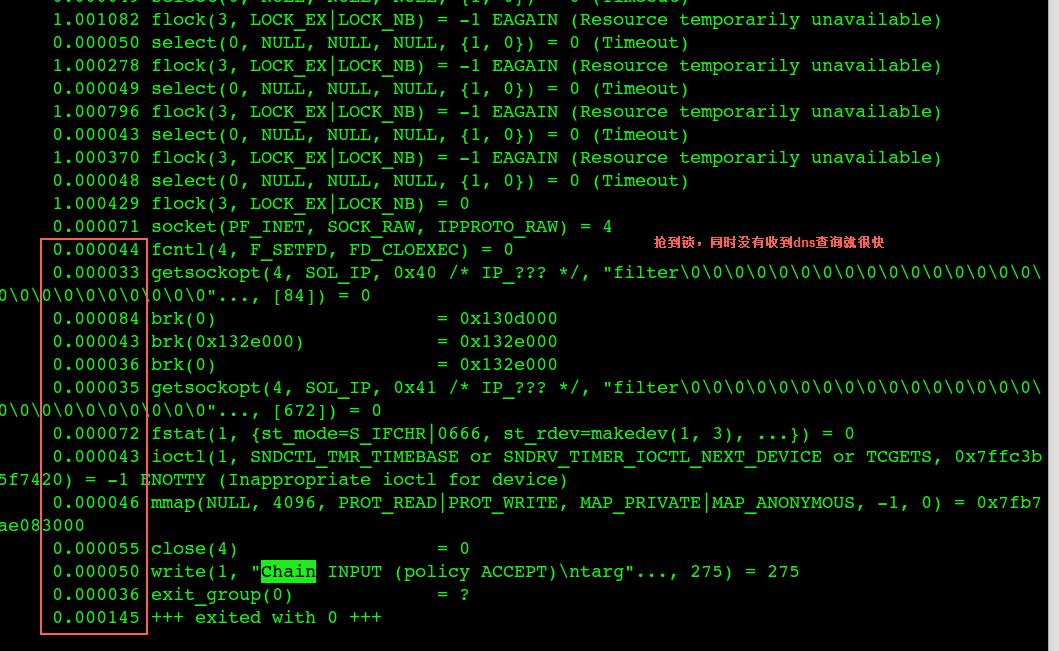
拿到锁后如果这个时候没有收到 dns 查询,那么很快iptables修改完毕,也不会导致卡住
strace工作原理
strace -T -tt -ff -p pid -o strace.out
注意:对于多进线程序需要加-f 参数,这样会trace 进程下的所有线程,-t 表示打印时间精度默认为秒,-tt -ttt 分别表示ms us 的时间精度。
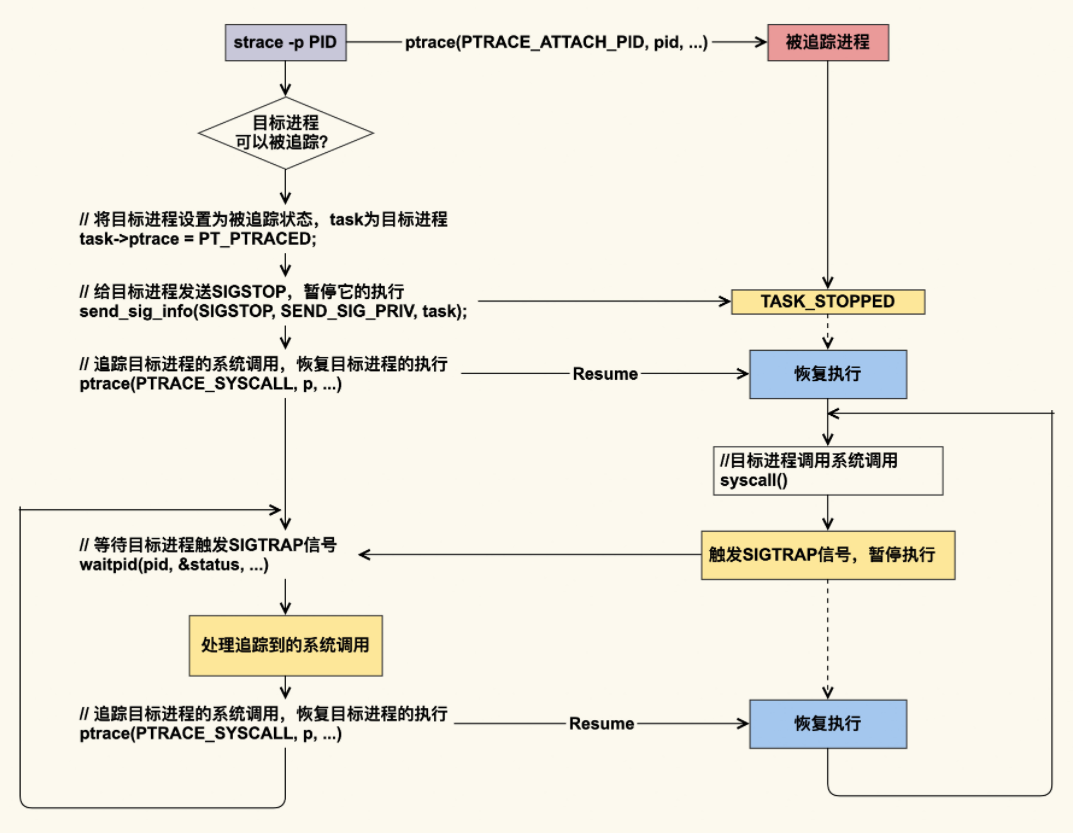
我们从图中可以看到,对于正在运行的进程而言,strace 可以 attach 到目标进程上,这是通过 ptrace 这个系统调用实现的(gdb 工具也是如此)。ptrace 的 PTRACE_SYSCALL 会去追踪目标进程的系统调用;目标进程被追踪后,每次进入 syscall,都会产生 SIGTRAP 信号并暂停执行;追踪者通过目标进程触发的 SIGTRAP 信号,就可以知道目标进程进入了系统调用,然后追踪者会去处理该系统调用,我们用 strace 命令观察到的信息输出就是该处理的结果;追踪者处理完该系统调用后,就会恢复目标进程的执行。被恢复的目标进程会一直执行下去,直到下一个系统调用。
你可以发现,目标进程每执行一次系统调用都会被打断,等 strace 处理完后,目标进程才能继续执行,这就会给目标进程带来比较明显的延迟。因此,在生产环境中我不建议使用该命令,如果你要使用该命令来追踪生产环境的问题,那就一定要做好预案。
假设我们使用 strace 跟踪到,线程延迟抖动是由某一个系统调用耗时长导致的,那么接下来我们该怎么继续追踪呢?这就到了应用开发者和运维人员需要拓展分析边界的时刻了,对内核开发者来说,这才算是分析问题的开始。
两个术语:
- tracer:跟踪(其他程序的)程序
- tracee:被跟踪程序
tracer 跟踪 tracee 的过程:
首先,attach 到 tracee 进程:调用 ptrace,带 PTRACE_ATTACH 及 tracee 进程 ID 作为参数。
之后当 tracee 运行到系统调用函数时就会被内核暂停;对 tracer 来说,就像 tracee 收到了 SIGTRAP 信号而停下来一样。接下来 tracer 就可以查看这次系统调 用的参数,打印相关的信息。
然后,恢复 tracee 执行:再次调用 ptrace,带 PTRACE_SYSCALL 和 tracee 进程 ID。 tracee 会继续运行,进入到系统调用;在退出系统调用之前,再次被内核暂停。
以上“暂停-采集-恢复执行”过程不断重复,tracer 就可以获取每次系统调用的信息,打印 出参数、返回值、时间等等。
strace 常用用法
sudo strace -tt -e poll,select,connect,recvfrom,sendto nc www.baidu.com 80 //网络连接不上,卡在哪里
如何确认一个程序为什么卡住和停止在什么地方?
有些时候,某个进程看似不在做什么事情,也许它被停止在某个地方。
$ strace -p 22067 Process 22067 attached - interrupt to quit flock(3, LOCK_EX
这里我们看到,该进程在处理一个独占锁(LOCK_EX),且它的文件描述符为3,so 这是一个什么文件呢?
$ readlink /proc/22067/fd/3 /tmp/foobar.lock
aha, 原来是 /tmp/foobar.lock。可是为什么程序会被停止在这里呢?
$ lsof | grep /tmp/foobar.lock command 21856 price 3uW REG 253,88 0 34443743 /tmp/foobar.lock command 22067 price 3u REG 253,88 0 34443743 /tmp/foobar.lock
原来是进程 21856 hold住了锁。此时,真相大白 21856 和 22067 读到了相同的锁。
strace -cp // strace 可以按操作汇总时间
我的分析
docker启动的时候要修改每个容器的dns(iptables规则),如果这个时候又收到了dns查询,但是查询的时候dns还没配置好,所以只能等待dns默认超时,等到超时完了再往后执行修改dns动作然后释放iptables锁。这里会发生恶性循环,导致dns修改时占用iptables的时间非常长,进而看着像把物理机iptables锁死,同时docker daemon不响应任何请求。
这应该是docker daemon实现上的小bug,也就是改iptables这里没加锁,如果修改dns的时候同时收到了dns查询,要是让查询等锁的话就不至于出现这种恶性循环
总结
其实这个问题还是挺容易出现的,daemon重启,上面有很多容器,容器里面的任务启动的时候都要做dns解析,这个时候daemon还在修改dns,冲进来很多dns查询的话会导致修改进程变慢
这也跟物理机的 /etc/resolv.conf 配置有关
暂时先只留一个dns server,同时把timeout改成1秒(似乎没法改成比1秒更小),同时 attempts:1 ,也就是加快dns查询的失败,当然这会导致应用启动的时候dns解析失败,最终还是需要从docker的源代码修复这个问题。
解决过程中无数次想放弃,但是反复在那里strace,正是看到了有dns和没有dns查询的两个strace才想清楚这个问题,感谢自己的坚持和很多同事的帮助,手撕的过程中必然有很多不理解的东西,需要请教同事