疑难问题汇总
疑难问题汇总
一网通客户 vxlan 网络始终不通,宿主机能抓到发出去的包,但是抓不到回复包。对端容器所在的宿主机抓不到进来的包
一定是网络上把这个包扔掉了
证明问题
- 先选择两台宿主机,停掉上面的 ovs 容器(腾出4789端口)
- 一台宿主机上执行: nc -l -u 4789 //在4789端口上启动udp服务
- 另外一台主机上执行: nc -u 第一台宿主机的IP 4789 //从第二台宿主机连第一台的4789端口
- 从两边都发送一些内容看看,看是否能到达对方
如果通过nc发送的东西也无法到达对方(跟方舟没有关系了)那么就是链路上的问题
一网通客户 vxlan 网络能通,但是pca容器初始化的时候失败
通过报错信息发现pca容器访问数据库SocketTimeout,同时看到异常信息都是Timeout大于15分钟以上了。
需找问题
- 先在 pca容器和数据库容器互相 ping 证明网络没有问题,能够互通
- 在 pca 容器中通过mysql 命令行连上 mysql,并创建table,insert一些记录,结果也没有问题
- 抓包发现pca容器访问数据库的时候在重传包(以往经验)

细化证明问题
- ping -s -M 尝试发送1460大小的包
- 检查宿主机、容器MTU设置
确认问题在宿主机网卡MTU设置为1350,从而导致容器发出的包被宿主机网卡丢掉
新零售客户通过vpn部署好中间件后,修改笔记本的dns设置后通过浏览器来访问中间件的console,但是报找不到server。同时在cmd中ping 这个域名能通,但是nslookup解析不了这个域名
ping 这个域名能通,但是nslookup不行,基本可以确认网络没有大问题,之所以ping可以nslookup不行,是因为他们底层取dns server的逻辑不一样。
先检查dns设置:
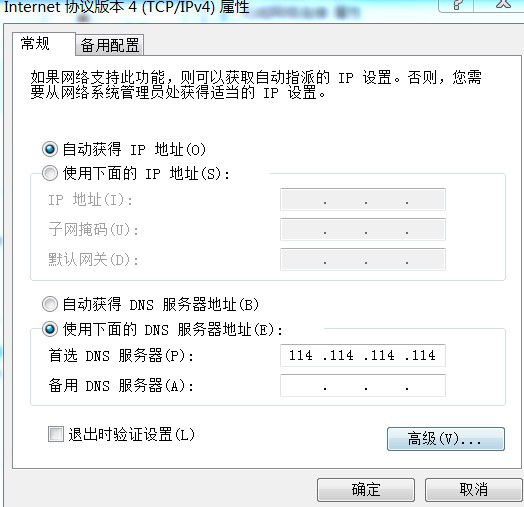
如上图,配置的填写
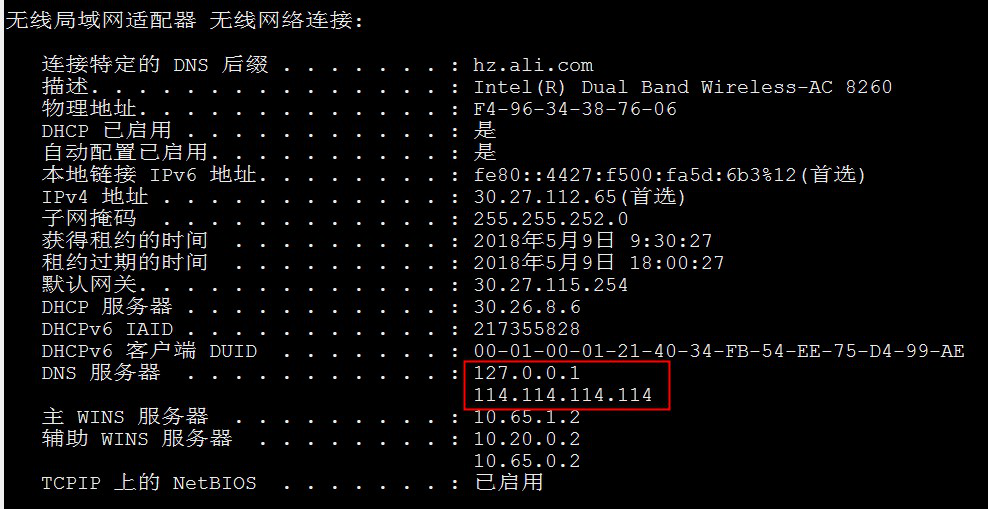
多出来一个127.0.0.1肯定有问题,明明配置的时候只填了114.114.114.114. nslookup、浏览器默认把域名解析丢给了127.0.0.1,但是 ping丢给了114.114.114.114,所以看到如上描述的结果。
经过思考发现应该是本机同时运行了easyconnect(vpn软件),127.0.0.1 是他强行塞进来的。马上停掉easyconnect再ipconfig /all 验证一下这个时候的dns server,果然127.0.0.1不见了, nslookup 也正常了。
某航空客户 windows下通过方舟dns域名解析不了方舟域名,但是宿主机上可以。windows机器能ping通dns server ip, 但是nslookup 解析不了域名,显示request time out
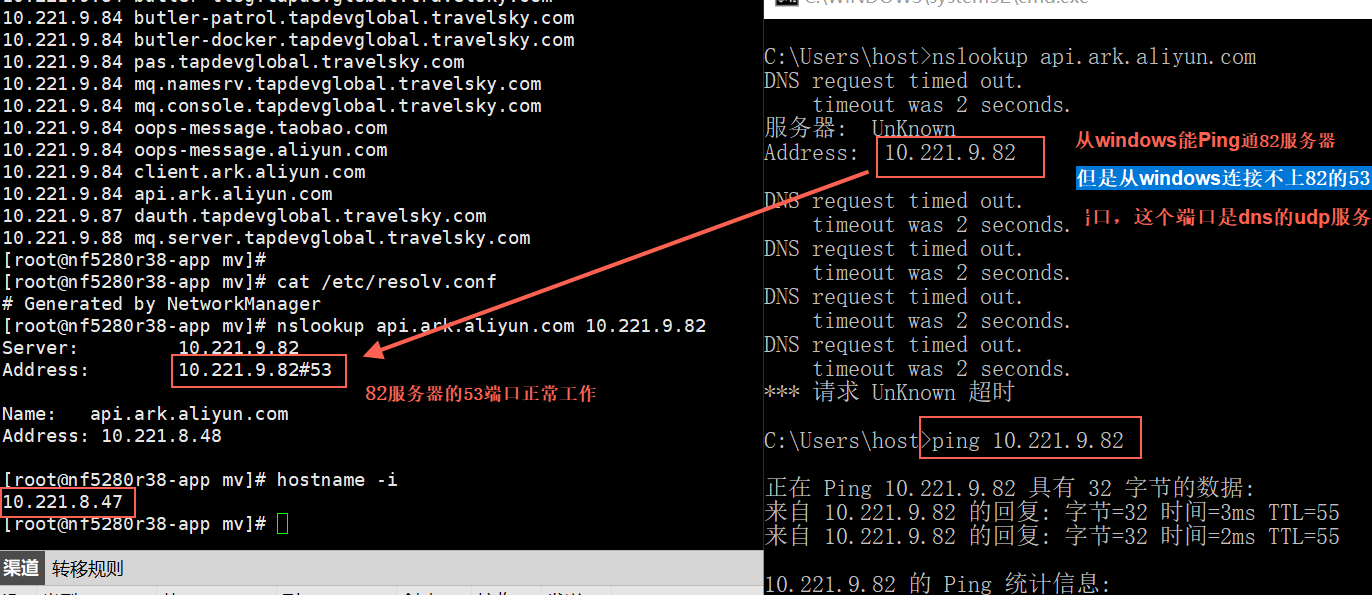
能ping通说明网络能通,但是dns域名要能解析依赖于:
- 网络能通
- dns server上有dns服务(53udp端口)
- 中间的防火墙对这个udp53端口限制了
如上图,这里的问题非常明显是中间的防火墙没放行 udp 53端口
方舟环境在ECS底座上DNS会继承rotate模式,导致域名解析不正常,ping 域名不通,但是nslookup能通
某银行 POC 环境物理机搬迁到新机房后网络不通,通过在物理机上抓包,抓不到任何容器的包
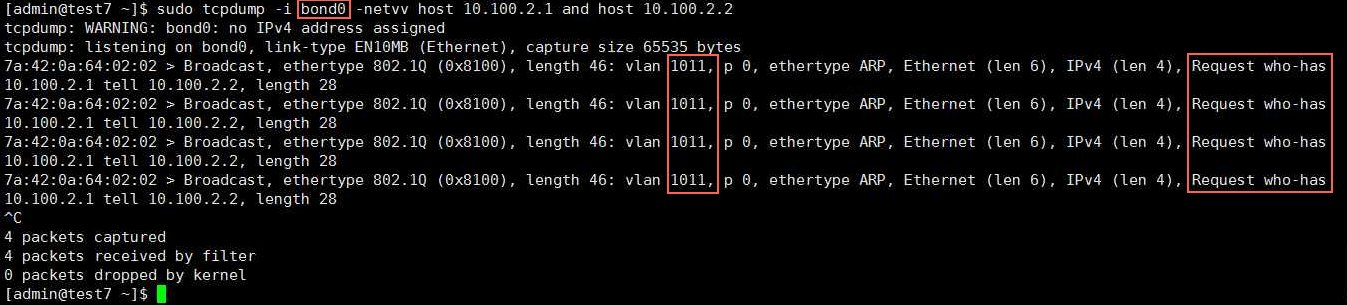
如图所示容器中发了 arp包(IP 10.100.2.2 寻找10.100.2.1 的mac地址),这个包从bond0 网卡发出去了,也是带的正确的 vlanid 1011,但是交换机没有回复,那么就一定是交换机上vlan配置不对,需要找分配这个vlan的网工来检查交换机的配置
能抓到进出的容器包–外部环境正确,方舟底座的问题
不能抓到出去的容器包–方舟底座的问题
能抓到出去的容器包,抓不到回来的包–外部环境的问题
所以这里是方舟底座的问题。检查ovs、vlan插件一切都正常,见鬼了
检查宿主机网卡状态,发现没插网线,如果容器所用的宿主机网卡没有插网线,那么ovs就不会转发任何包到宿主机网卡。
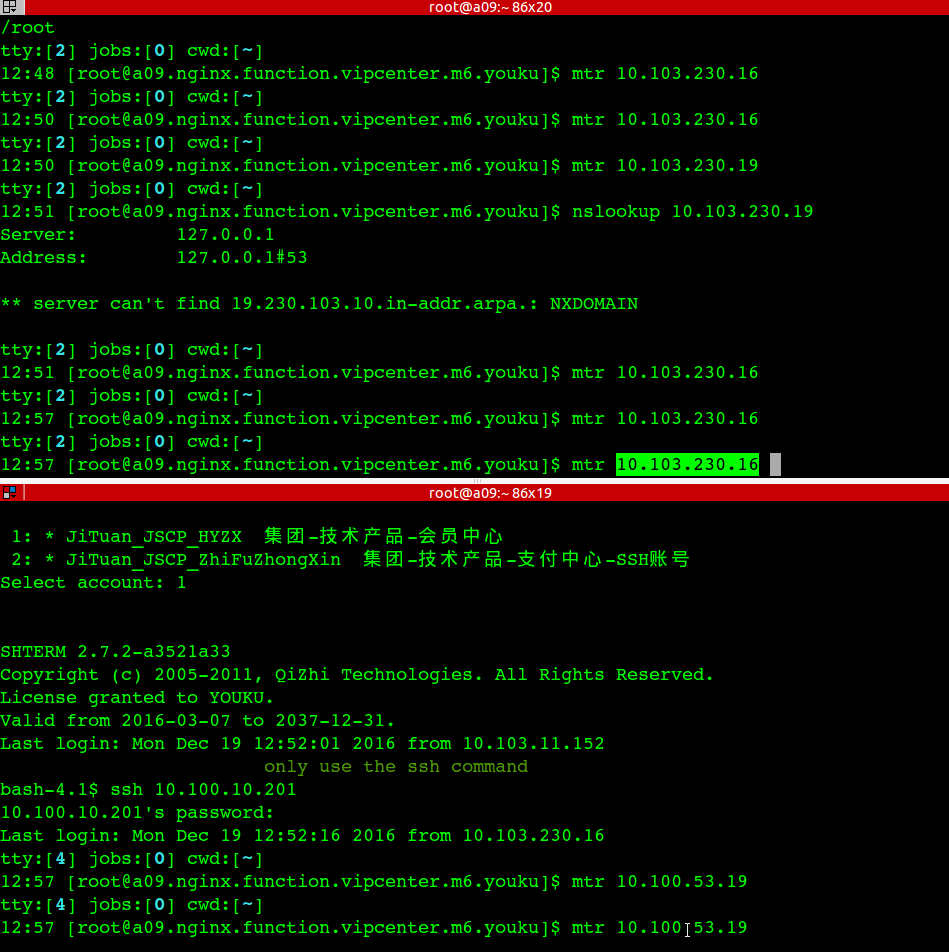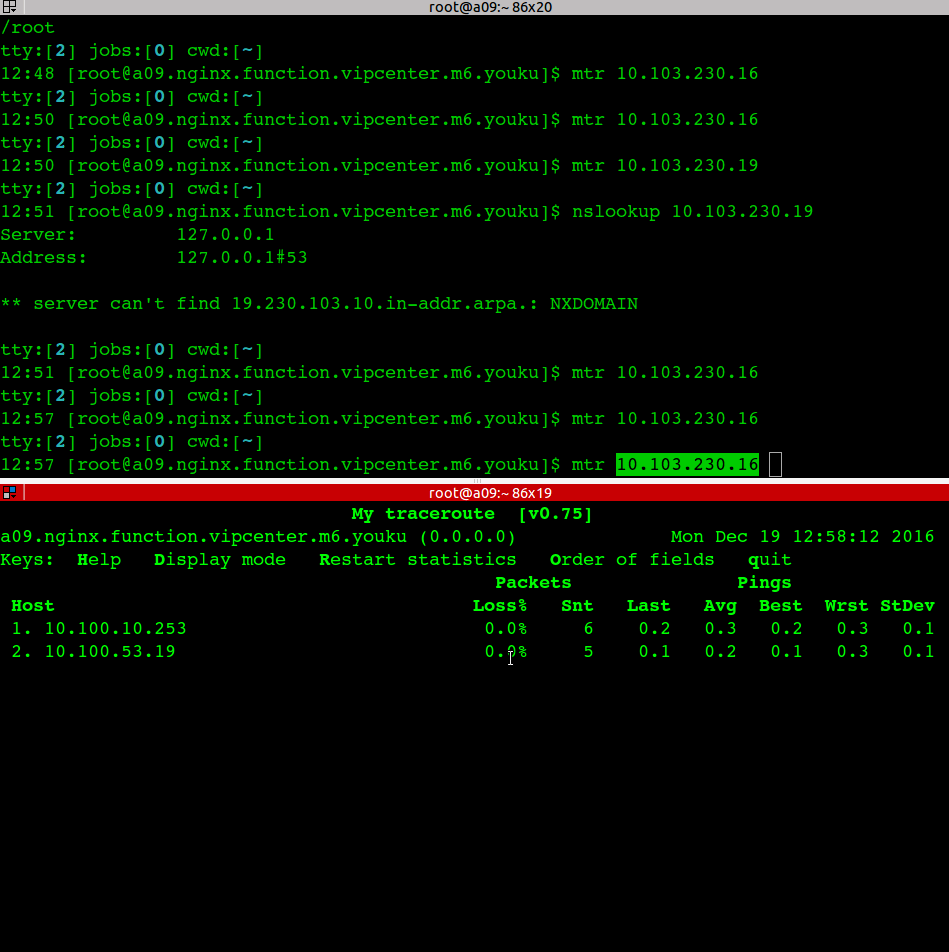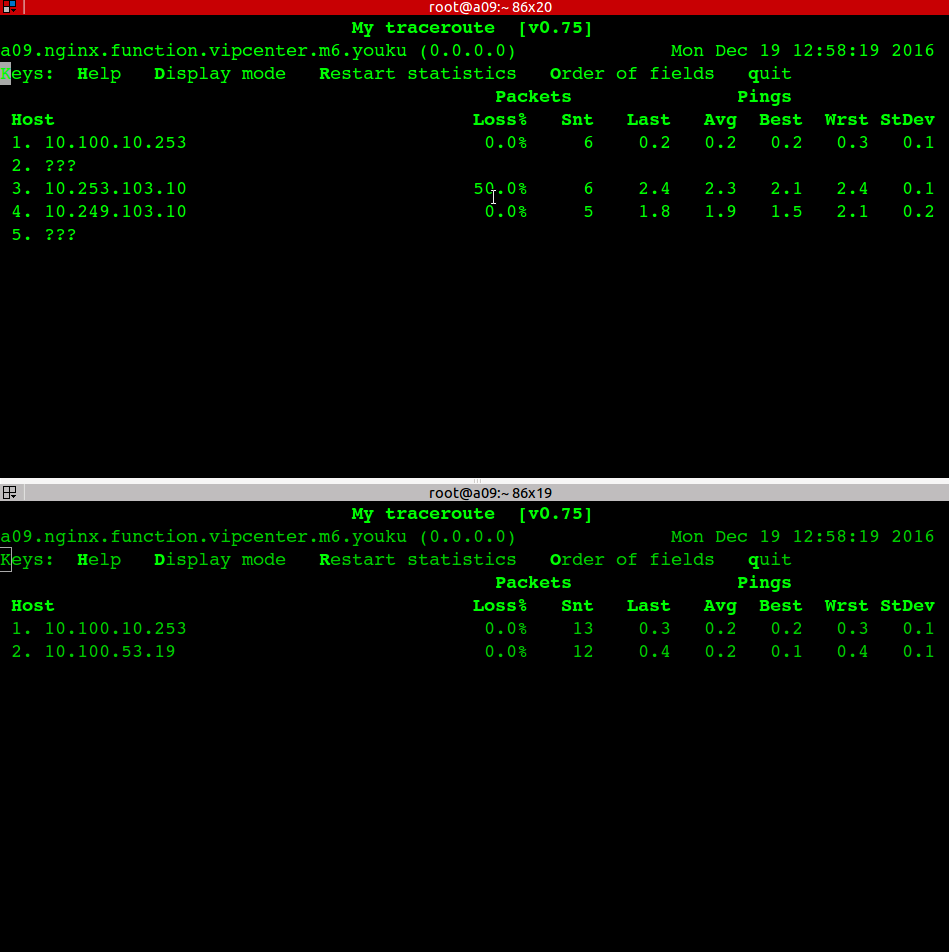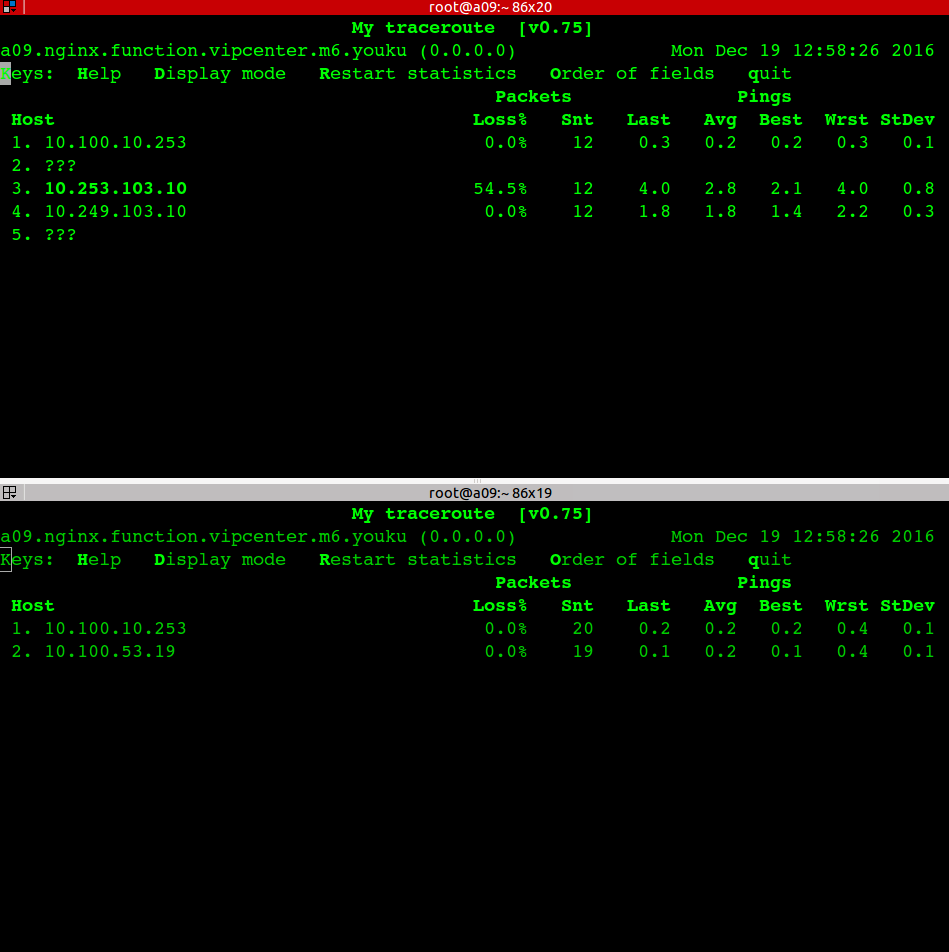
一台应用服务器无法访问部分drds-server
应用机器: 10.100.10.201 这台机器抛502异常比较多,进一步诊断发现 ping youku.tddl.tbsite.net 的时候解析到 10.100.53.15/16就不通
直接ping 10.100.53.15/16 也不通,经过诊断发现是交换机上记录了两个 10.100.10.201的mac地址导致网络不通。
上图是不通的IP,下图是正常IP
经过调查发现是土豆业务也用了10.100.10.201这个IP导致交换机的ARP mac table冲突,土豆删除这个IP后故障就恢复了。
当时交换机上发现的两条记录:
00:18:51:38:b1:cd 10.100.10.201
8c:dc:d4:b3:af:14 10.100.10.201
某个客户默认修改了umask导致黑屏脚本权限不够,部署中途不断卡壳,直接在黑屏脚本中修复了admin这个用户的umask
- 客户环境的 umask 是 0027 会导致所有copy文件的权限都不对了
- 因为admin没权限执行 /bin/jq 导致daemon.json是空的
- /etc/docker/daemon.json 文件是空的,docker启动报错
修复centos下udp和批量处理脚本因为环境变量的确实不能执行modprobe和ping等等命令的问题,同时将alios的这块修复逻辑放到了方舟安装脚本中,init的时候会先把这个问题修复
Centos系统重启后 /etc/resolv.conf总是被还原,开始以为是系统Bug,研究后发现是可以配置的,dhcp默认会每次重启后拉取DNS自动更新 /etc/resolv.conf
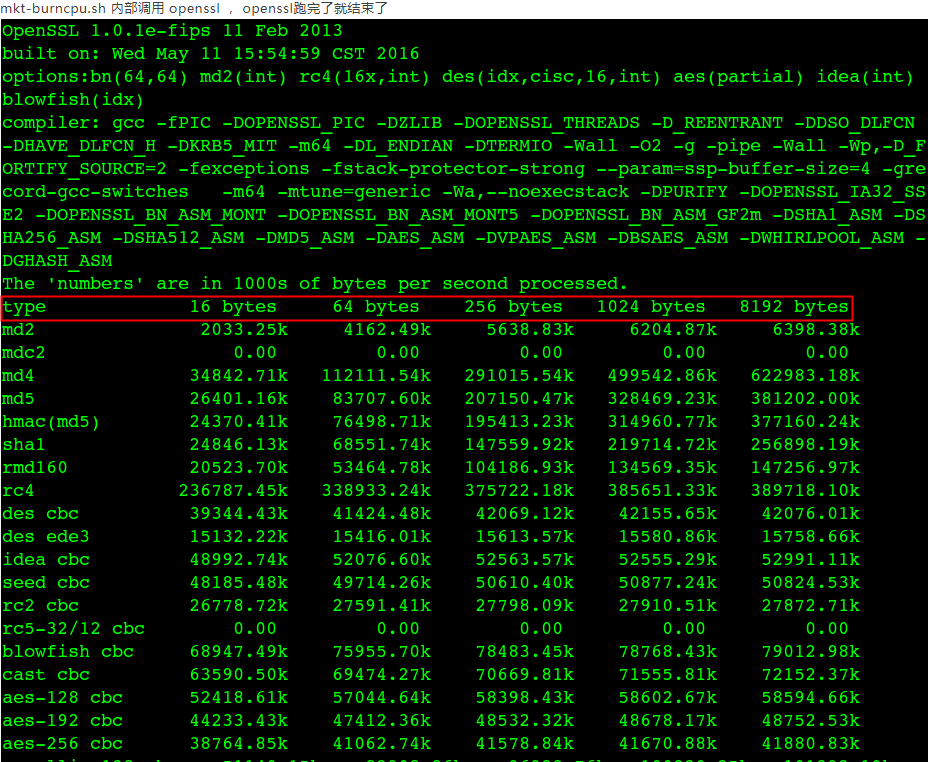
MonkeyKing burn cpu: mkt-burncpu.sh 脚本在方舟服务器上运行一段时间后,进程不见了,MK团队认为是方舟杀掉了他们。
好奇心迫使我去看代码、看openssl测试输出日志(MonkeyKing burn cpu内部调用 openssl speed 测试cpu的速度),这个测试一轮跑完了opessl就结束了,本身就不是死循环一直跑, 不是方舟杀掉的。
另外说明这个问题一直存在开发、测试MonkeyKing功能的团队就没有发现,或者之前一直只需要跑不到10分钟就自己主动把它杀掉让出CPU。
某汽车客户 部署过程中愚公不能正常启动,怀疑是依赖的zk问题,zk网络访问正常
尝试telnet zk发现不通,客户现场安装了kerberos导致telnet测试有问题(telnet被kerberos替换过),换一个其他环境的telnet 二进制文件就可以了(md5sum、telnet –help)
开发反应两个容器之间的网络不稳定,偶尔报连不上某些容器
主要是出现在tlog-console访问hbase容器的时候报连接异常
- 在 task_1114_g0_tlog-console_tlog_1(10.16.11.131) 的56789 端口上启动了一个简单的http服务,然后从 task_1114_g0_tlog-hbase_tlog(10.16.11.108) 每秒钟去访问一下10.16.11.131:56789 , 如果丢包率很高的时候服务 10.16.11.131:56789 也很慢或者访问不到就是网络问题,否则就有可能是hbase服务不响应导致的丢包、网络不通(仅仅是影响hbase服务)
- 反过来在hbase上同样启动http服务,tlog-console不停地去get
- 整个过程我的http服务响应非常迅速稳定,从没出现过异常
- 在重现问题侯,贺飞发现 是tlog线程数目先增多,retran才逐渐增高的, retran升高,并没有影响在那台机器上ping 或者telnet hbase的服务
- 通过以上方式证明跟容器、网络无关,是应用本身的问题,交由产品开发继续解决
最终开发确认网络没有问题后一门心思闷头自查得出结论:
信息更新:
问题:
tlog-console进程线程数多,卡在连接hbase上的问题
直接原因:
- tlog-console有巡检程序,每m分钟会检查运行超过n秒的线程,并且中断这个线程; 这个操作直接导致hbase客户端在等待hbaseserver返回数据的时候被中断,这种中断会经常发生,累积久了,就会打爆tlog-console服务的线程数目,这时候,tlogconsole机器的retran就会变多,连接hbaseserver就会出问题, 具体的机理不明
解决问题的有效操作:
- 停止对tlog-console的巡检程序后,问题没有发生过
其他潜在问题,这些问题是检查问题的时候,发现的其他潜在问题,已经反馈给tlog团队:
- Htable实例不是线程安全,有逻辑多线程使用相同的htable实例
- 程序中有new HTable 不close的路径
某化工私有云DRDS扩容总是报资源不足,主要是因为有些drds-server容器指定了–cpu-shares=128(相当于4Core–1024/物理核数 等于每个核对应的cpu-shares ), 导致物理机CPU不够。现场将所有容器的–cpu-shares改成2后修复这个问题,但是最终需要产品方
主要是swarm对cpu-shares的判断上有错误,swarm默认认定每台机器的总cpu-shares是1024,也就是 1024/物理核数 等于每个核对应的cpu-shares
如果需要精细化CPU控制,cpu-shares比cpu-set之类的要精确,利用率更高。但是也更容易出现问题
mq-diamond的异常日志总是打爆磁盘。mq-diamond 容器一天输出500G日志的问题,本质是调用的依赖不可用了,导致mq-diamond 频繁输出日志,两天就用掉了1T磁盘.
这里有两个问题需要处理:
- mq-diamond 依赖的服务可用;
- mq-diamond 自身保护,不要被自己的日志把磁盘撑爆了
对于问题二修改log4j来保护;对于问题1查看异常内容,mq-diamond尝试连接server:ip1,ip2,ip3 正常这里应该是一个ip而不是三个ip放一起。判断是mq-diamond从mq-cai获取diamond iplist有问题,这个iplist应该放在三行,但是实际被放到了1行,用逗号隔开
手工修改这个文件,放到三行,问题没完,还是异常,我自己崩溃没管。最后听mq-diamond的开发讲他们取iplist的url比较特殊,是自己定义的,所以我修改的地方不起作用。反思,为什么修改不起作用的时候不去看看Nginx的access日志? 这样可以证明我修改的文件实际没有被使用,同时还能找到真正被使用的配置文件
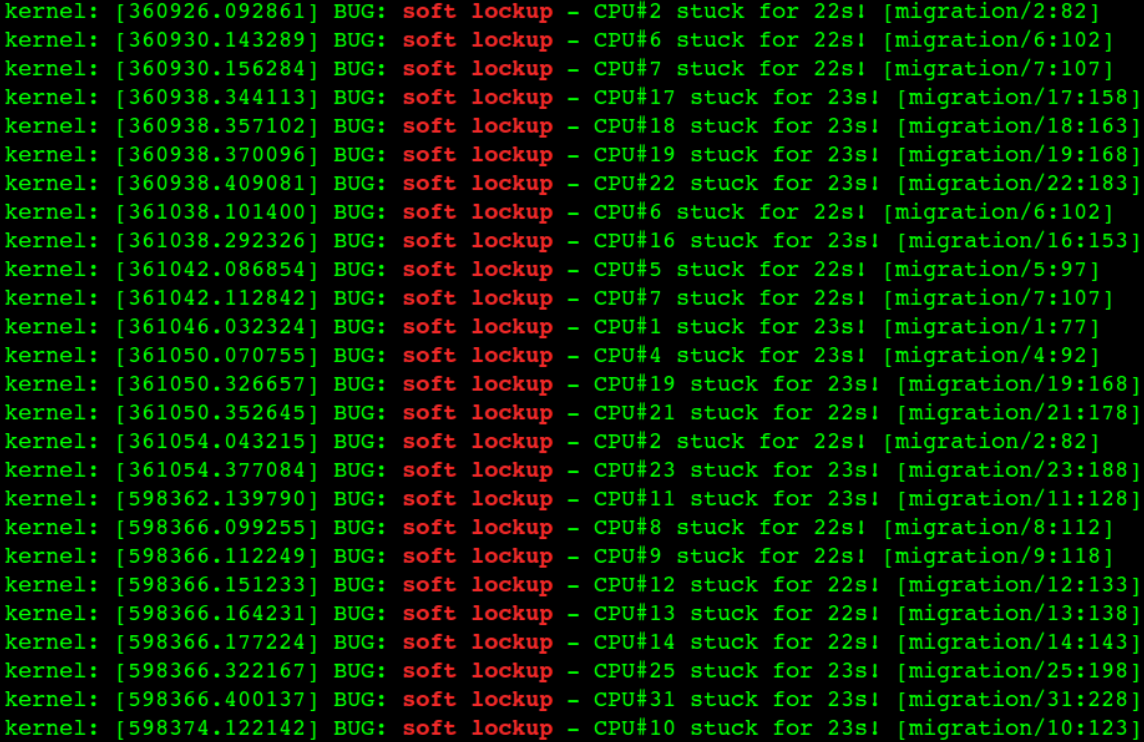
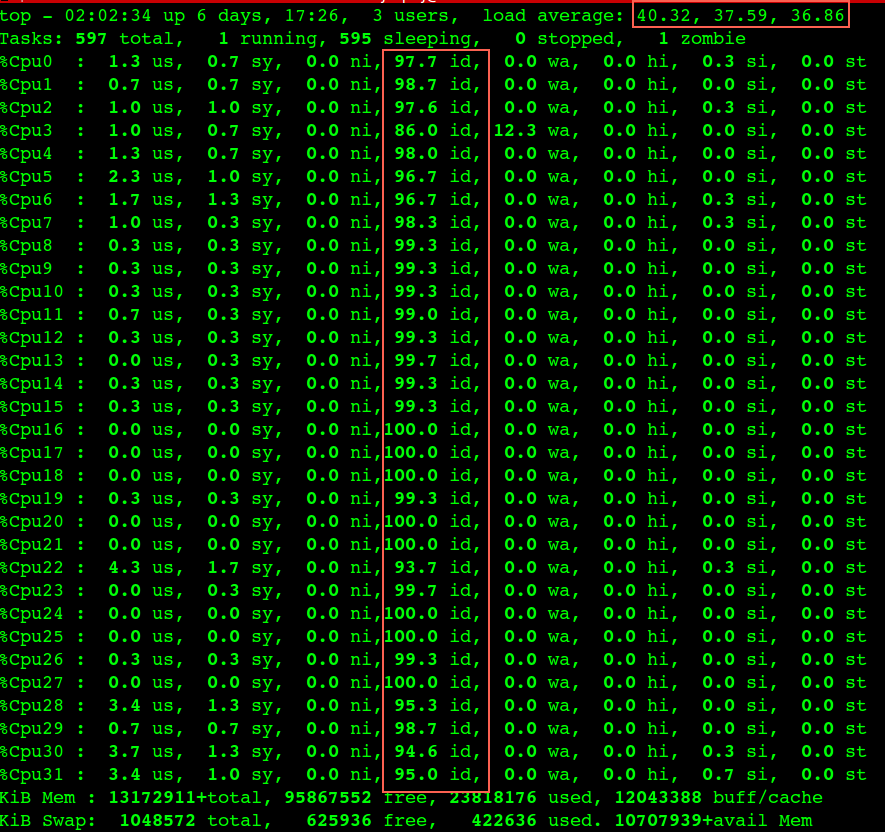
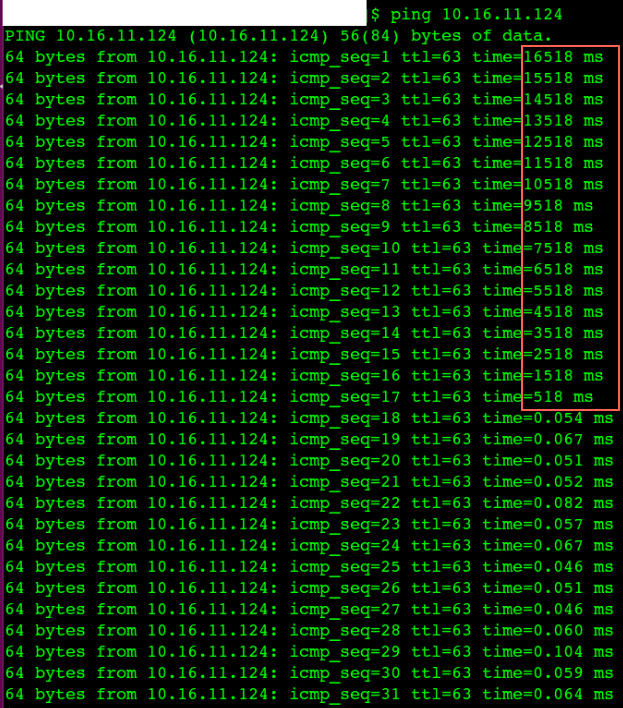
内核migration进程bug导致宿主机Load非常高,同时CPU idle也很高(两者矛盾)
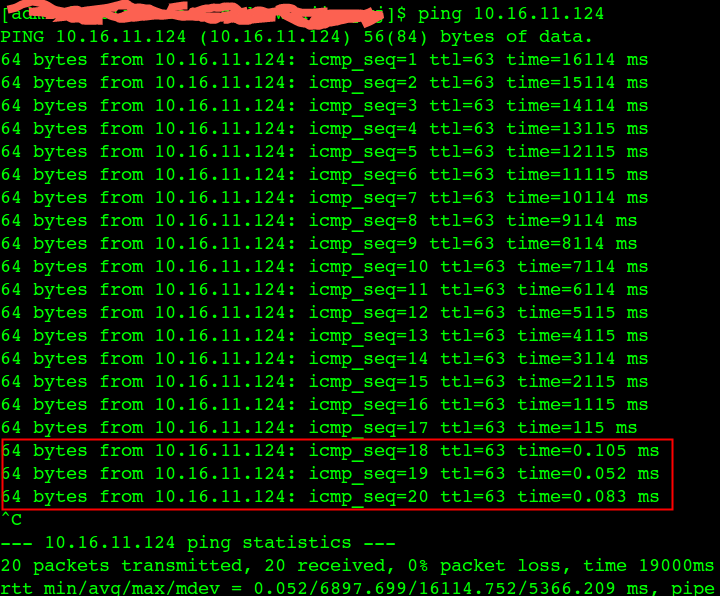
内核migration进程bug导致对应的CPU核卡死(图一),这个核上的所有进程得不到执行(Load高,CPU没有任何消耗, 图二),直到内核进程 watchdog 发现这个问题并恢复它。
出现这个bug后的症状,通过top命令看到CPU没有任何消耗但是Load偏高,如果应用进程恰好被调度到这个出问题的CPU核上,那么这个进程会卡住(大概20秒)没有任何响应,比如 ping 进程(图三图四),watchdog恢复这个问题后,多个网络包在同一时间全部通。其实所影响的不仅仅是网络卡顿,中间件容器里面的服务如果调度到这个CPU核上同样得不到执行,从外面就是感觉容器不响应了
拿如上证据求助内核开发
关键信息在这里:
代码第297行
2017-09-15T06:52:37.820783+00:00 ascliveedas4.sgdc kernel: [598346.499872] WARNING: at net/sched/sch_generic.c:297 dev_watchdog+0x270/0x280()
2017-09-15T06:52:37.820784+00:00 ascliveedas4.sgdc kernel: [598346.499873] NETDEV WATCHDOG: ens2f0 (ixgbe): transmit queue 28 timed out
kernel version: kernel-3.10.0-327.22.2.el7.src.rpm
265 static void dev_watchdog(unsigned long arg)
266 {
267 struct net_device *dev = (struct net_device *)arg;
268
269 netif_tx_lock(dev);
270 if (!qdisc_tx_is_noop(dev)) {
271 if (netif_device_present(dev) &&
272 netif_running(dev) &&
273 netif_carrier_ok(dev)) {
274 int some_queue_timedout = 0;
275 unsigned int i;
276 unsigned long trans_start;
277
278 for (i = 0; i < dev->num_tx_queues; i++) {
279 struct netdev_queue *txq;
280
281 txq = netdev_get_tx_queue(dev, i);
282 /*
283 * old device drivers set dev->trans_start
284 */
285 trans_start = txq->trans_start ? : dev->trans_start;
286 if (netif_xmit_stopped(txq) &&
287 time_after(jiffies, (trans_start +
288 dev->watchdog_timeo))) {
289 some_queue_timedout = 1;
290 txq->trans_timeout++;
291 break;
292 }
293 }
294
295 if (some_queue_timedout) {
296 WARN_ONCE(1, KERN_INFO "NETDEV WATCHDOG: %s (%s): transmit queue %u timed out\n",
297dev->name, netdev_drivername(dev), i);
298 dev->netdev_ops->ndo_tx_timeout(dev);
299 }
300 if (!mod_timer(&dev->watchdog_timer,
301round_jiffies(jiffies +
302 dev->watchdog_timeo)))
303 dev_hold(dev);
304 }
$ cat kernel_log.0915
2017-09-15T02:19:55.975310+00:00 ascliveedas4.sgdc kernel: [582026.288227] openvswitch: netlink: Key type 62 is out of range max 22
2017-09-15T03:49:41.312168+00:00 ascliveedas4.sgdc kernel: [587409.546584] md: md0: data-check interrupted.
2017-09-15T06:52:37.820782+00:00 ascliveedas4.sgdc kernel: [598346.499865] ------------[ cut here ]------------
2017-09-15T06:52:37.820783+00:00 ascliveedas4.sgdc kernel: [598346.499872] WARNING: at net/sched/sch_generic.c:297 dev_watchdog+0x270/0x280()
2017-09-15T06:52:37.820784+00:00 ascliveedas4.sgdc kernel: [598346.499873] NETDEV WATCHDOG: ens2f0 (ixgbe): transmit queue 28 timed out
2017-09-15T06:52:37.820784+00:00 ascliveedas4.sgdc kernel: [598346.499916] Modules linked in: 8021q garp mrp xt_nat veth xt_addrtype ipt_MASQUERADE nf_nat_masquerade_ipv4 iptable_nat nf_conntrack_ipv4 nf_defrag_ipv4 nf_nat_ipv4 iptable_filter xt_conntrack nf_nat nf_conntrack bridge stp llc tcp_diag udp_diag inet_diag binfmt_misc overlay() vfat fat intel_powerclamp coretemp intel_rapl kvm_intel kvm crc32_pclmul ghash_clmulni_intel aesni_intel lrw gf128mul glue_helper ablk_helper cryptd raid10 ipmi_devintf iTCO_wdt iTCO_vendor_support sb_edac lpc_ich hpwdt edac_core hpilo i2c_i801 ipmi_si sg mfd_core pcspkr ioatdma ipmi_msghandler acpi_power_meter shpchp wmi pcc_cpufreq openvswitch libcrc32c nfsd auth_rpcgss nfs_acl lockd grace sunrpc ip_tables ext4 mbcache jbd2 sd_mod crc_t10dif crct10dif_generic mgag200 syscopyarea sysfillrect sysimgblt drm_kms_helper ixgbe crct10dif_pclmul ahci ttm crct10dif_common igb crc32c_intel mdio libahci ptp drm pps_core i2c_algo_bit libata i2c_core dca dm_mirror dm_region_hash dm_log dm_mod
2017-09-15T06:52:37.820786+00:00 ascliveedas4.sgdc kernel: [598346.499928] CPU: 10 PID: 123 Comm: migration/10 Tainted: G L ------------ T 3.10.0-327.22.2.el7.x86_64#1
2017-09-15T06:52:37.820787+00:00 ascliveedas4.sgdc kernel: [598346.499929] Hardware name: HP ProLiant DL160 Gen9/ProLiant DL160 Gen9, BIOS U20 12/27/2015
2017-09-15T06:52:37.820788+00:00 ascliveedas4.sgdc kernel: [598346.499935] ffff88207fc43d88 000000001cdfb0f1 ffff88207fc43d40 ffffffff816360fc
2017-09-15T06:52:37.820789+00:00 ascliveedas4.sgdc kernel: [598346.499939] ffff88207fc43d78 ffffffff8107b200 000000000000001c ffff881024660000
2017-09-15T06:52:37.820790+00:00 ascliveedas4.sgdc kernel: [598346.499942] ffff881024654f40 0000000000000040 000000000000000a ffff88207fc43de0
2017-09-15T06:52:37.820791+00:00 ascliveedas4.sgdc kernel: [598346.499943] Call Trace:
2017-09-15T06:52:37.820792+00:00 ascliveedas4.sgdc kernel: [598346.499952] <IRQ> [<ffffffff816360fc>] dump_stack+0x19/0x1b
2017-09-15T06:52:37.820794+00:00 ascliveedas4.sgdc kernel: [598346.499956] [<ffffffff8107b200>] warn_slowpath_common+0x70/0xb0
2017-09-15T06:52:37.820795+00:00 ascliveedas4.sgdc kernel: [598346.499959] [<ffffffff8107b29c>] warn_slowpath_fmt+0x5c/0x80
2017-09-15T06:52:37.820795+00:00 ascliveedas4.sgdc kernel: [598346.499964] [<ffffffff8154d4f0>] dev_watchdog+0x270/0x280
2017-09-15T06:52:37.820796+00:00 ascliveedas4.sgdc kernel: [598346.499966] [<ffffffff8154d280>] ? dev_graft_qdisc+0x80/0x80
2017-09-15T06:52:37.820797+00:00 ascliveedas4.sgdc kernel: [598346.499972] [<ffffffff8108b0a6>] call_timer_fn+0x36/0x110
2017-09-15T06:52:37.820798+00:00 ascliveedas4.sgdc kernel: [598346.499974] [<ffffffff8154d280>] ? dev_graft_qdisc+0x80/0x80
2017-09-15T06:52:37.820799+00:00 ascliveedas4.sgdc kernel: [598346.499977] [<ffffffff8108dd97>] run_timer_softirq+0x237/0x340
2017-09-15T06:52:37.820800+00:00 ascliveedas4.sgdc kernel: [598346.499980] [<ffffffff81084b0f>] __do_softirq+0xef/0x280
2017-09-15T06:52:37.820801+00:00 ascliveedas4.sgdc kernel: [598346.499985] [<ffffffff81103360>] ? cpu_stop_should_run+0x50/0x50
2017-09-15T06:52:37.820801+00:00 ascliveedas4.sgdc kernel: [598346.499988] [<ffffffff8164819c>] call_softirq+0x1c/0x30
2017-09-15T06:52:37.820802+00:00 ascliveedas4.sgdc kernel: [598346.499994] [<ffffffff81016fc5>] do_softirq+0x65/0xa0
2017-09-15T06:52:37.820803+00:00 ascliveedas4.sgdc kernel: [598346.499996] [<ffffffff81084ea5>] irq_exit+0x115/0x120
2017-09-15T06:52:37.820804+00:00 ascliveedas4.sgdc kernel: [598346.499999] [<ffffffff81648e15>] smp_apic_timer_interrupt+0x45/0x60
2017-09-15T06:52:37.820805+00:00 ascliveedas4.sgdc kernel: [598346.500003] [<ffffffff816474dd>] apic_timer_interrupt+0x6d/0x80
2017-09-15T06:52:37.820813+00:00 ascliveedas4.sgdc kernel: [598346.500007] <EOI> [<ffffffff811033df>] ? multi_cpu_stop+0x7f/0xf0
2017-09-15T06:52:37.820815+00:00 ascliveedas4.sgdc kernel: [598346.500010] [<ffffffff81103666>] cpu_stopper_thread+0x96/0x170
某银行客户RAID阵列坏掉,导致物理机重启后容器的net-alias域名解析不到
docker daemon 的endpoint用的容器名存在zk中,如果创建一个重复名字的容器,那么会失败,然后回滚,回滚动作会把zk中别人的endpoint删掉,从而导致域名不通。
物理机异常后,我们的调度程序会在其它物理机重新调度生成这个容器,但是当原来的物理机回来后,这里有两个一样的容器会自动删掉宕机的物理机上的这个容器,从而误删net-alias,进而域名无法解析