网络丢包
网络丢包
查看网卡是否丢包,一般是ring buffer太小
ethtool -S eth0 | grep rx_ | grep errors
当驱动处理速度跟不上网卡收包速度时,驱动来不及分配缓冲区,NIC接收到的数据包无法及时写到sk_buffer(由网卡驱动直接在内核中分配的内存,并存放数据包,供内核软中断的时候读取),就会产生堆积,当NIC内部缓冲区写满后,就会丢弃部分数据,引起丢包。这部分丢包为rx_fifo_errors,在 /proc/net/dev中体现为fifo字段增长,在ifconfig中体现为overruns指标增长。
查看ring buffer的大小设置
ethtool ‐g eth0
Socket buffer太小导致的丢包(一般不多见)
内核收到包后,会给对应的socket,每个socket会有 sk_rmem_alloc/sk_wmem_alloc/sk_omem_alloc、sk_rcvbuf(bytes)来存放包
When sk_rmem_alloc >
sk_rcvbuf the TCP stack will call a routine which “collapses” the receive queue
查看collapses:
netstat -sn | egrep "prune|collap"; sleep 30; netstat -sn | egrep "prune|collap"
17671 packets pruned from receive queue because of socket buffer overrun
18671 packets pruned from receive queue because of socket buffer overrun
测试发现在小包情况下,这两个值相对会增大且比较快。增大 net.ipv4.tcp_rmem 和 net.core.rmem_max、net.core.rmem_default 后没什么效果 – 需要进一步验证
net.core.netdev_budget
sysctl net.core.netdev_budget //默认300, The default value of the budget is 300. This will
cause the SoftIRQ process to drain 300 messages from the NIC before getting off the CPU
如果 /proc/net/softnet_stat 第三列一直在增加的话需要,表示SoftIRQ 获取的CPU时间太短,来不及处理足够多的网络包,那么需要增大这个值
net/core/dev.c->net_rx_action 函数中会按netdev_budget 执行softirq,budget每次执行都要减少,一直到没有了,就退出softirq
一般默认软中断只绑定在CPU0上,如果包的数量巨大的话会导致 CPU0利用率 100%(主要是si),这个时候可以检查文件 /proc/net/softnet_stat 的第三列 或者 RX overruns 是否在持续增大
net.core.netdev_max_backlog
enqueue_to_backlog函数中,会对CPU的softnet_data 实例中的接收队列(input_pkt_queue)进行判断,如果队列中的数据长度超过netdev_max_backlog ,那么数据包将直接丢弃,这就产生了丢包。
参数net.core.netdev_max_backlog指定的,默认大小是 1000。
netdev_max_backlog 接收包队列(网卡收到还没有进行协议的处理队列),每个cpu core一个队列,如果/proc/net/softnet_stat第二列增加就表示这个队列溢出了,需要改大。
/proc/net/softnet_stat:(第一列和第三列的关系?)
The 1st column is the number of frames received by the interrupt handler. (第一列是中断处理程序接收的帧数)
The 2nd column is the number of frames dropped due to netdev_max_backlog being exceeded. netdev_max_backlog
The 3rd column is the number of times ksoftirqd ran out of netdev_budget or CPU time when there was still work to be done net.core.netdev_budget
rp_filter
https://www.yuque.com/plantegg/weyi1s/uc7a5g
关于ifconfig的种种解释
- RX errors: 表示总的收包的错误数量,这包括 too-long-frames 错误,Ring Buffer 溢出错误,crc 校验错误,帧同步错误,fifo overruns 以及 missed pkg 等等。
- RX dropped: 表示数据包已经进入了 Ring Buffer,但是由于内存不够等系统原因,导致在拷贝到内存的过程中被丢弃。
- RX overruns: 表示了 fifo 的 overruns,这是由于 Ring Buffer(aka Driver Queue) 传输的 IO 大于 kernel 能够处理的 IO 导致的,而 Ring Buffer 则是指在发起 IRQ 请求之前的那块 buffer。很明显,overruns 的增大意味着数据包没到 Ring Buffer 就被网卡物理层给丢弃了,而 CPU 无法及时地处理中断是造成 Ring Buffer 满的原因之一,上面那台有问题的机器就是因为 interruprs 分布的不均匀(都压在 core0),没有做 affinity 而造成的丢包。
- RX frame: 表示 misaligned 的 frames。
dropped数量持续增加,建议增大Ring Buffer ,使用ethtool ‐G 进行设置。
txqueuelen:1000 对应着qdisc队列的长度(发送队列和网卡关联着)
而对应的接收队列由内核参数来设置:
net.core.netdev_max_backlog
Adapter buffer defaults are commonly set to a smaller size than the maximum//网卡进出队列大小调整 ethtool -G eth rx 8192 tx 8192
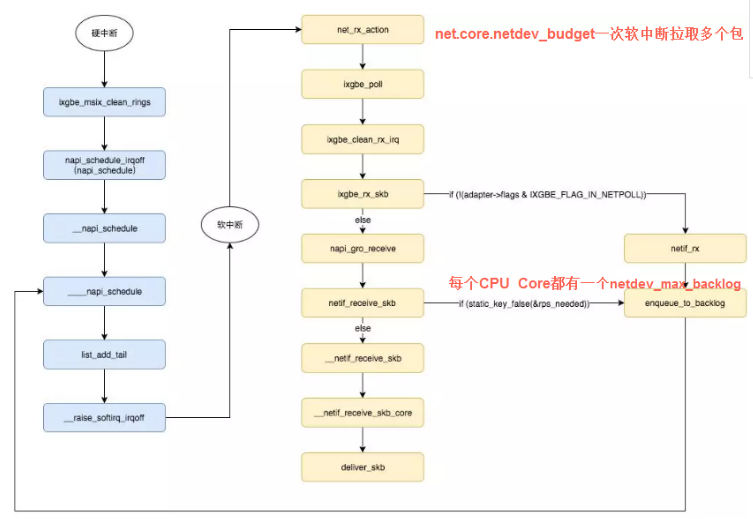
核心流程
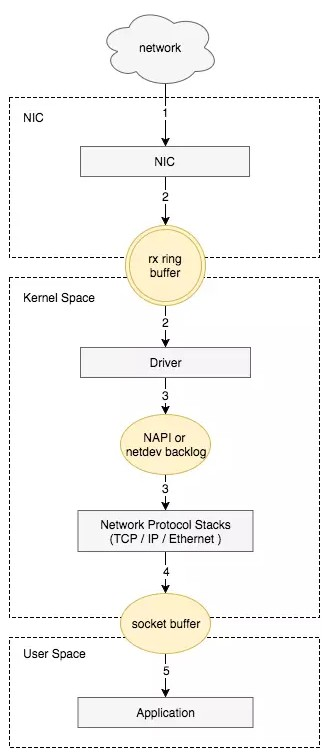
接收数据包是一个复杂的过程,涉及很多底层的技术细节,但大致需要以下几个步骤:
- 网卡收到数据包。
- 将数据包从网卡硬件缓存转移到服务器内存中。
- 通知内核处理。
- 经过TCP/IP协议逐层处理。
- 应用程序通过read()从socket buffer读取数据。
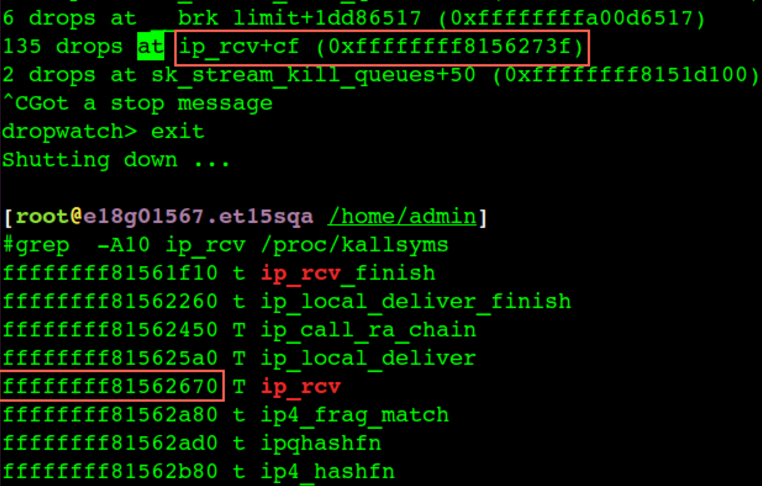
通过 dropwatch来查看丢包点
dropwatch -l kas (-l 加载符号表) // 丢包点位置等于 ip_rcv地址+ cf(偏移量)
一个典型的接收包调用堆栈:
0xffffffff8157af10 : tcp_may_send_now+0x0/0x160 [kernel]
0xffffffff815765f8 : tcp_fastretrans_alert+0x868/0xb50 [kernel]
0xffffffff8157729d : tcp_ack+0x8bd/0x12c0 [kernel]
0xffffffff81578295 : tcp_rcv_established+0x1d5/0x750 [kernel]
0xffffffff81582bca : tcp_v4_do_rcv+0x10a/0x340 [kernel]
0xffffffff81584411 : tcp_v4_rcv+0x831/0x9f0 [kernel]
0xffffffff8155e114 : ip_local_deliver_finish+0xb4/0x1f0 [kernel]
0xffffffff8155e3f9 : ip_local_deliver+0x59/0xd0 [kernel]
0xffffffff8155dd8d : ip_rcv_finish+0x7d/0x350 [kernel]
0xffffffff8155e726 : ip_rcv+0x2b6/0x410 [kernel]
0xffffffff81522d42 : __netif_receive_skb_core+0x582/0x7d0 [kernel]
0xffffffff81522fa8 : __netif_receive_skb+0x18/0x60 [kernel]
0xffffffff81523c7e : process_backlog+0xae/0x180 [kernel]
0xffffffff81523462 : net_rx_action+0x152/0x240 [kernel]
0xffffffff8107dfff : __do_softirq+0xef/0x280 [kernel]
0xffffffff8163f61c : call_softirq+0x1c/0x30 [kernel]
0xffffffff81016fc5 : do_softirq+0x65/0xa0 [kernel]
0xffffffff8107d254 : local_bh_enable_ip+0x94/0xa0 [kernel]
0xffffffff81634f4b : _raw_spin_unlock_bh+0x1b/0x40 [kernel]
0xffffffff8150d968 : release_sock+0x118/0x170 [kernel]
如果客户端建立连接的时候抛异常,可能的原因(握手失败,建不上连接):
- 网络不通,诊断:ping ip
- 端口不通, 诊断:telnet ip port
- rp_filter 命中(rp_filter=1, 多网卡环境), 诊断: netstat -s | grep -i filter ;
- snat/dnat的时候宿主机port冲突,内核会扔掉 syn包。 troubleshooting: sudo conntrack -S | grep insert_failed //有不为0的
- 全连接队列满的情况,诊断: netstat -s | egrep “listen|LISTEN”
- syn flood攻击, 诊断:同上
- 若远端服务器的内核参数 net.ipv4.tcp_tw_recycle 和 net.ipv4.tcp_timestamps 的值都为 1,则远端服务器会检查每一个报文中的时间戳(Timestamp),若 Timestamp 不是递增的关系,不会响应这个报文。配置 NAT 后,远端服务器看到来自不同的客户端的源 IP 相同,但 NAT 前每一台客户端的时间可能会有偏差,报文中的 Timestamp 就不是递增的情况。nat后的连接,开启timestamp。因为快速回收time_wait的需要,会校验时间该ip上次tcp通讯的timestamp大于本次tcp(nat后的不同机器经过nat后ip一样,保证不了timestamp递增),诊断:是否有nat和是否开启了timestamps
- NAT 哈希表满导致 ECS 实例丢包 nf_conntrack full
iptables和tcpdump
sudo iptables -A INPUT -p tcp –destination-port 8089 -j DROP
tcpdump 是直接从网卡驱动拿包,也就是包还没进入内核tcpdump就拿到了,而iptables是工作在内核层,也就是即使被DROP还是能tcpdump到8089的packet。