Linux Network Stack
Linux Network Stack
文章目标
从一个网络包进到网卡后续如何流转,进而了解中间有哪些关键参数可以控制他们,有什么工具能帮忙可以看到各个环节的一些指征,以及怎么调整他们。
接收流程
接收流程大纲
在开始收包之前,也就是OS启动的时候,Linux要做许多的准备工作:
- 创建ksoftirqd线程,为它设置好它自己的线程函数,用来处理软中断
- 协议栈注册,linux要实现许多协议,比如arp,icmp,ip,udp,tcp,每一个协议都会将自己的处理函数注册一下,方便包来了迅速找到对应的处理函数
- 网卡驱动初始化,每个驱动都有一个初始化函数,内核会让驱动也初始化一下。在这个初始化过程中,把自己的DMA准备好,把NAPI的poll函数地址告诉内核
- 启动网卡,分配RX,TX队列,注册中断对应的处理函数
以上是内核准备收包之前的重要工作,当上面都ready之后,就可以打开硬中断,等待数据包的到来了。
当数据到来了以后,第一个迎接它的是网卡:
- 网卡将数据帧DMA到内存的RingBuffer中,然后向CPU发起中断通知
- CPU响应中断请求,调用网卡启动时注册的中断处理函数
- 中断处理函数几乎没干啥,就发起了软中断请求
- 内核线程ksoftirqd线程发现有软中断请求到来,先关闭硬中断
- ksoftirqd线程开始调用驱动的poll函数收包
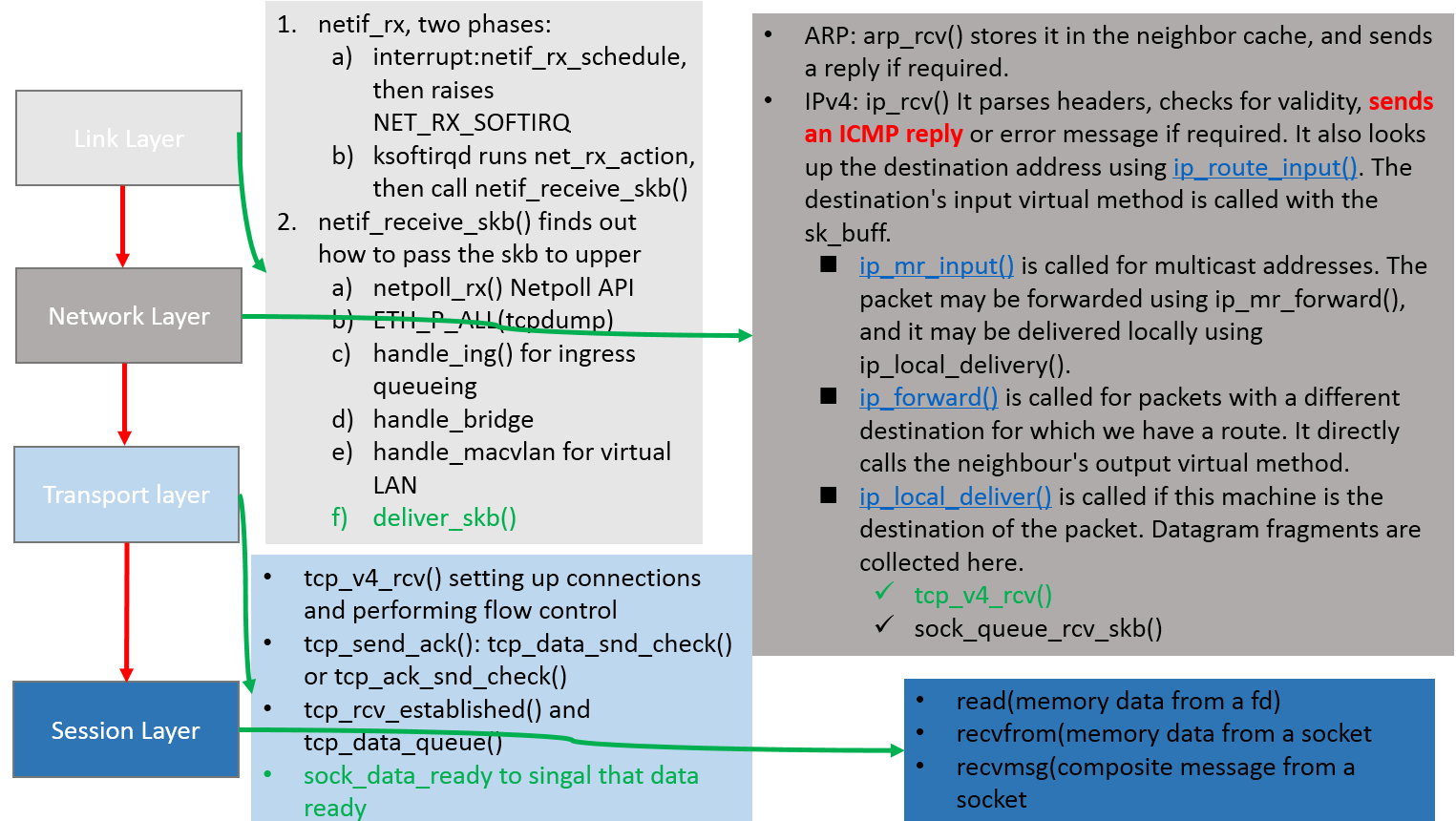
- poll函数将收到的包送到协议栈注册的ip_rcv函数中
- ip_rcv函数再讲包送到udp_rcv函数中(对于tcp包就送到tcp_rcv)
详细接收流程
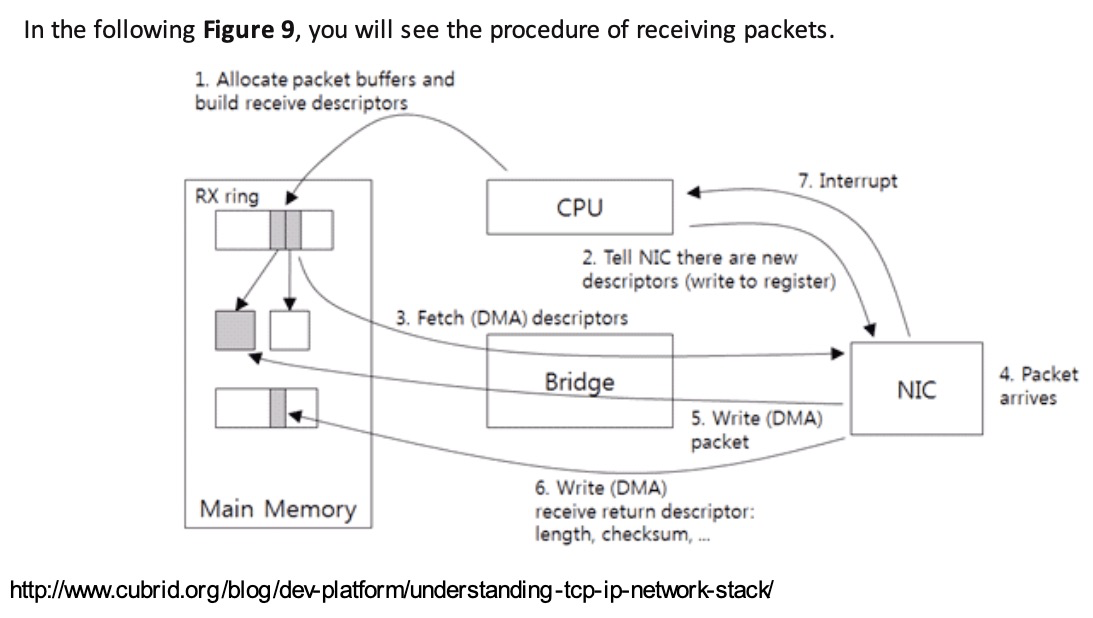
- 网络包进到网卡,网卡驱动校验MAC,看是否扔掉,取决是否是混杂 promiscuous mode
- 网卡在启动时会申请一个接收ring buffer,其条目都会指向一个skb的内存。
- DMA完成数据报文从网卡硬件到内存到拷贝
- 网卡发送一个中断通知CPU。
- CPU执行网卡驱动注册的中断处理函数,中断处理函数只做一些必要的工作,如读取硬件状态等,并把当前该网卡挂在NAPI的链表中;
- Driver “触发” soft IRQ(NET_RX_SOFTIRQ (其实就是设置对应软中断的标志位)
- CPU中断处理函数返回后,会检查是否有软中断需要执行。因第6步设置了NET_RX_SOFTIRQ,则执行报文接收软中断。
- 在NET_RX_SOFTIRQ软中断中,执行NAPI操作,回调第5步挂载的驱动poll函数。
- 驱动会对interface进行poll操作,检查网卡是否有接收完毕的数据报文。
- 将网卡中已经接收完毕的数据报文取出,继续在软中断进行后续处理。注:驱动对interface执行poll操作时,会尝试循环检查网卡是否有接收完毕的报文,直到系统设置的net.core.netdev_budget上限(默认300),或者已经就绪报文。
- net_rx_action
- 内核分配 sk_buff 内存
- 内核填充 metadata: 协议等,移除 ethernet 包头信息
- 将skb 传送给内核协议栈 netif_receive_skb
__netif_receive_skb_core:将数据送到抓包点(tap)或协议层(i.e. tcpdump)// 出抓包点:dev_queue_xmit_nit- 进入到由 netdev_max_backlog 控制的qdisc
- 开始 ip_rcv 处理流程,主要处理ip协议包头相关信息
- 调用内核 netfilter 框架(iptables PREROUTING)
- 进入L4 protocol tcp_v4_rcv
- 找到对应的socket
- 根据 tcp_rmem 进入接收缓冲队列
- 内核将数据送给接收的应用
http://arthurchiao.art/blog/linux-net-stack-implementation-rx-zh:
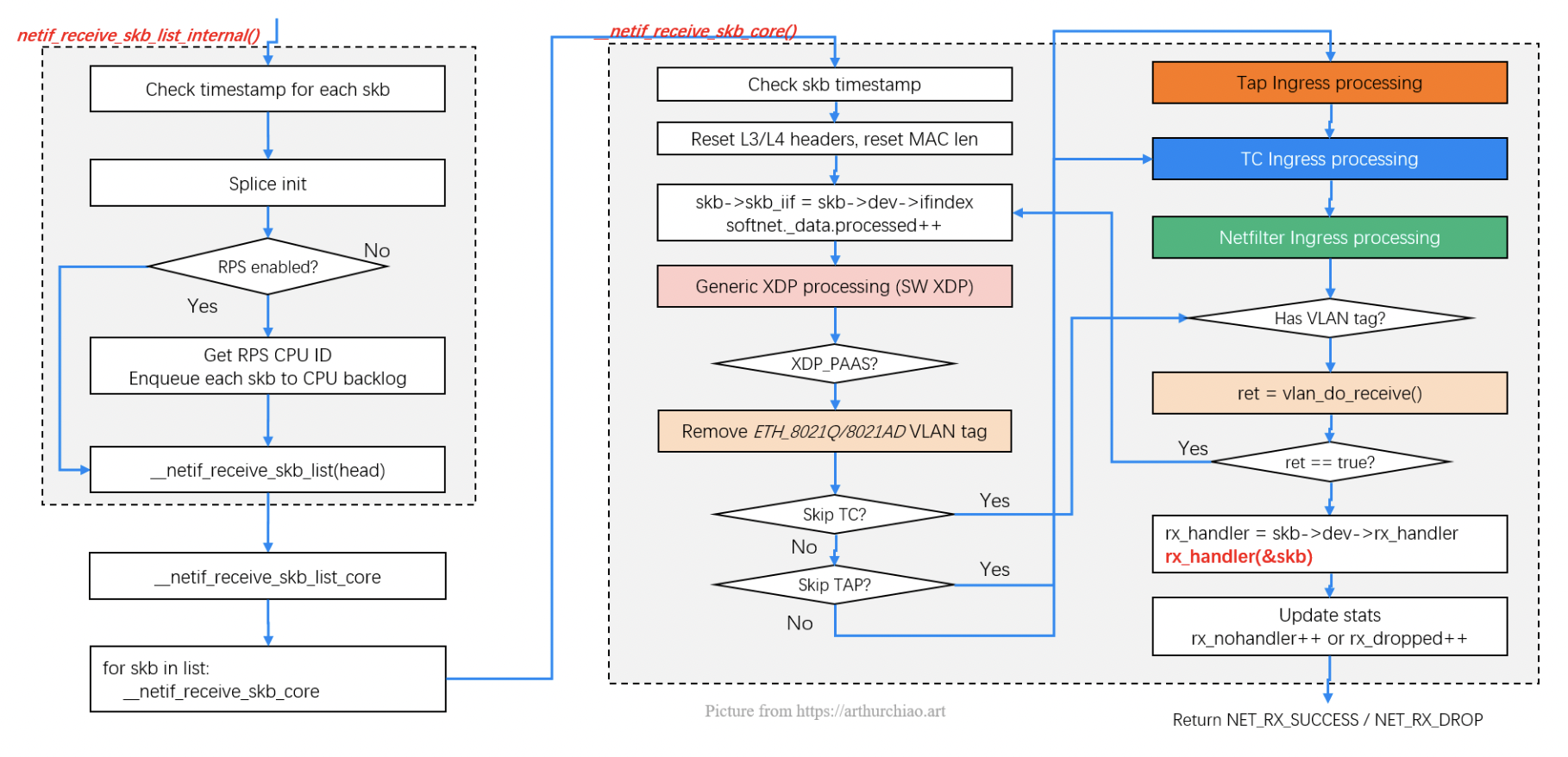
TAP 处理点就是 tcpdump 抓包、流量过滤。
注意:netfilter 或 iptables 规则都是在软中断上下文中执行的, 数量很多或规则很复杂时会导致网络延迟。
软中断:可以把软中断系统想象成一系列内核线程(每个 CPU 一个),这些线程执行针对不同 事件注册的处理函数(handler)。如果你用过
top命令,可能会注意到ksoftirqd/0这个内核线程,其表示这个软中断线程跑在 CPU 0 上。硬中断发生在哪一个核上,它发出的软中断就由哪个核来处理。可以通过加大网卡队列数,这样硬中断工作、软中断工作都会有更多的核心参与进来。
__napi_schedule干两件事情,一件事情是把struct napi_struct 挂到struct softnet_data 上,注意softnet_data是一个per cpu变量,换句话说,软中断结构是挂在触发硬中断的同一个CPU上;另一件事情是调用__raise_softirq_irqoff 把irq_stat的__softirq_pending 字段置位,irq_stat 也是个per cpu 变量,表示当前这个cpu上有软中断待处理。
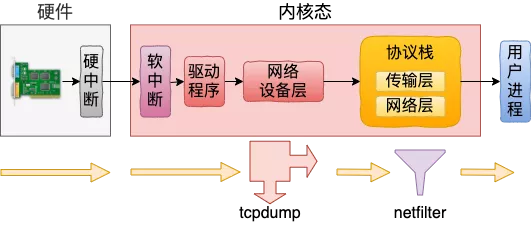
从上图可以看到tcpdump在协议栈之前,也就是netfilter过滤规则对tcpdump无效,发包则是反过来:
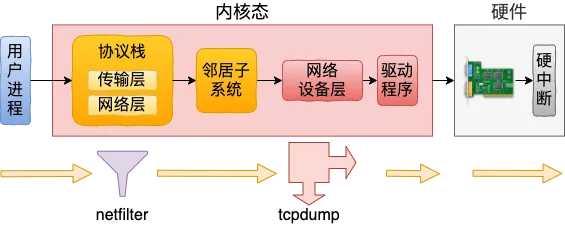
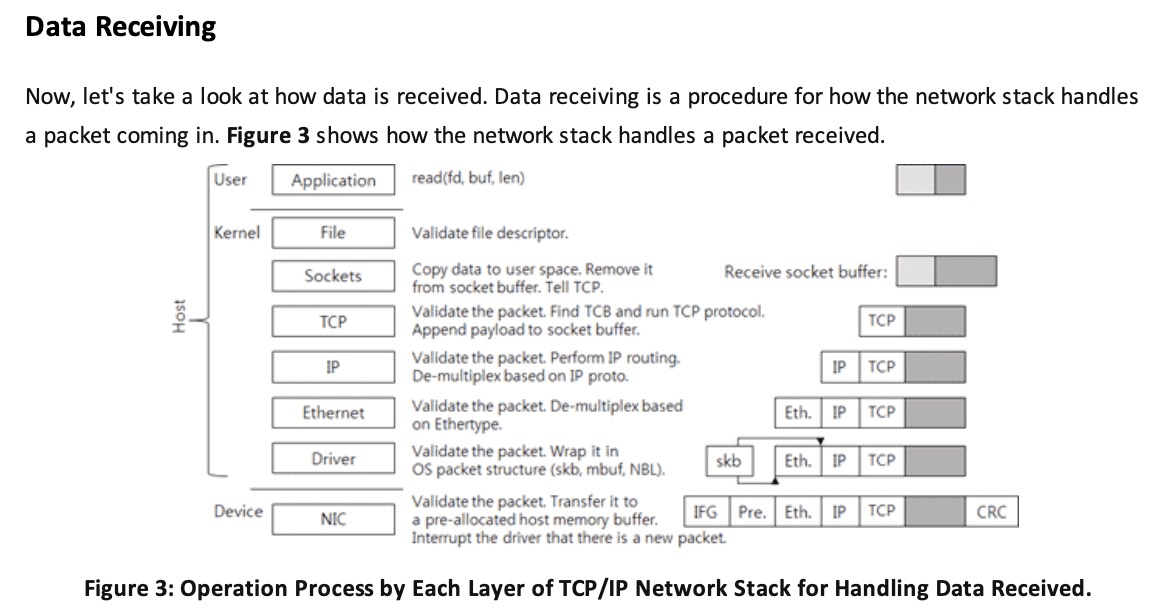
典型的接收堆栈

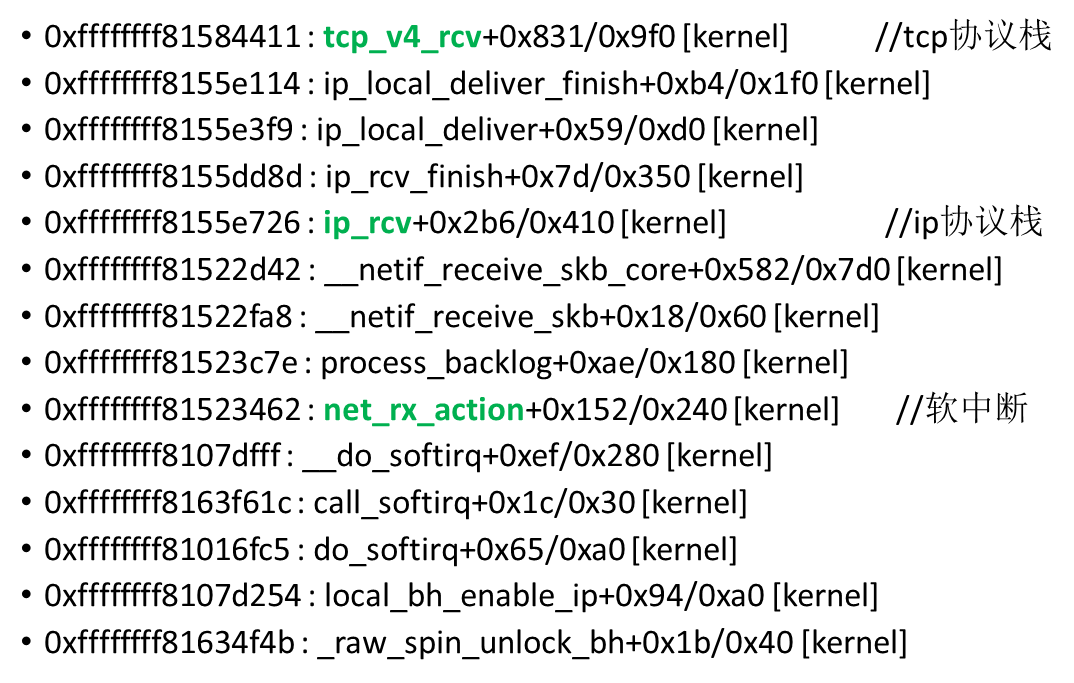
从四层协议栈来看收包流程
DMA驱动部分流程图
DMA是一个硬件逻辑,数据传输到系统物理内存的过程中,全程不需要CPU的干预,除了占用总线之外(期间CPU不能使用总线),没有任何额外开销。
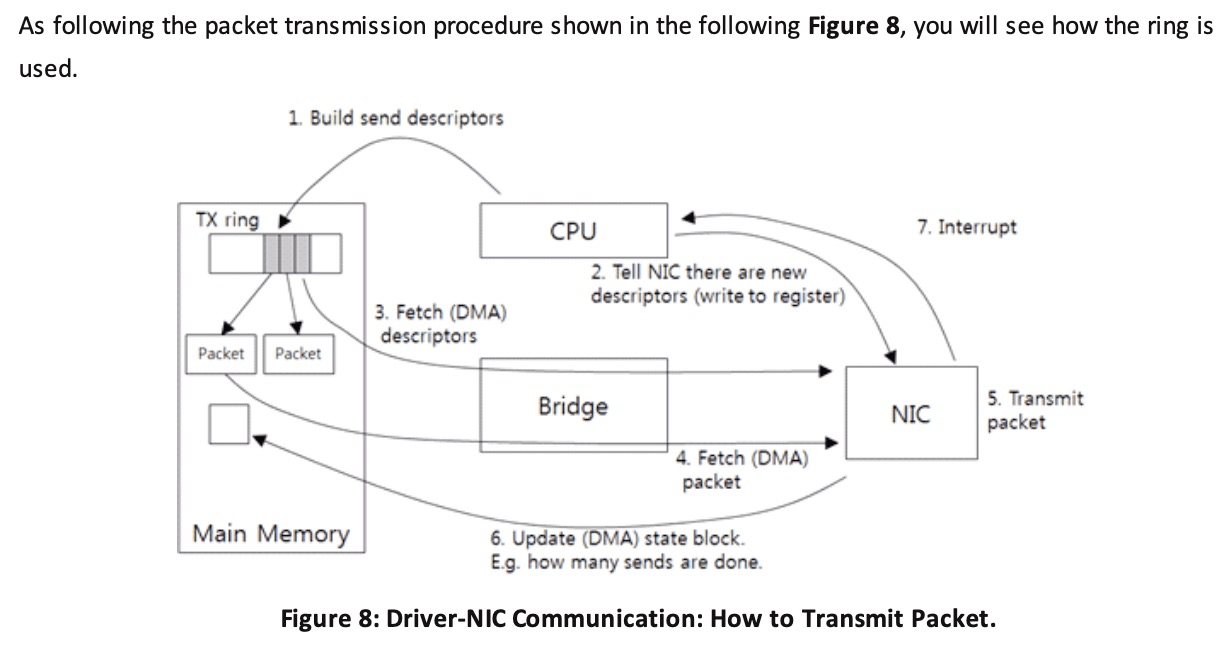
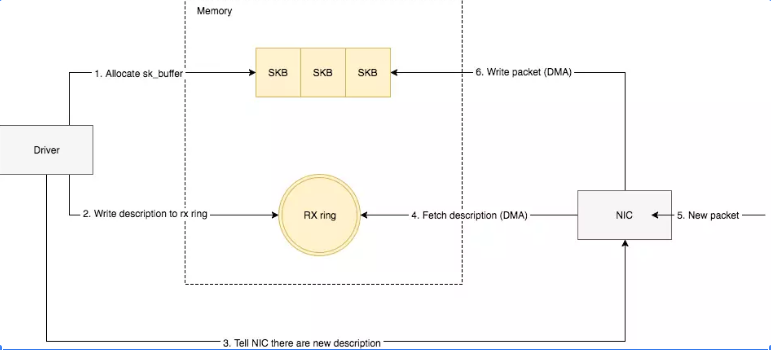
- 驱动在内存中分配一片缓冲区用来接收数据包,叫做sk_buffer;
- 将上述缓冲区的地址和大小(即接收描述符),加入到rx ring buffer。描述符中的缓冲区地址是DMA使用的物理地址;
- 驱动通知网卡有一个新的描述符;
- 网卡从rx ring buffer中取出描述符,从而获知缓冲区的地址和大小;
- 网卡收到新的数据包;
- 网卡将新数据包通过DMA直接写到sk_buffer中。
Linux network queues overview
可以通过perf来监控包的堆栈:
1 | perf trace --no-syscalls --event 'net:*' ping baidu.com -c1 |
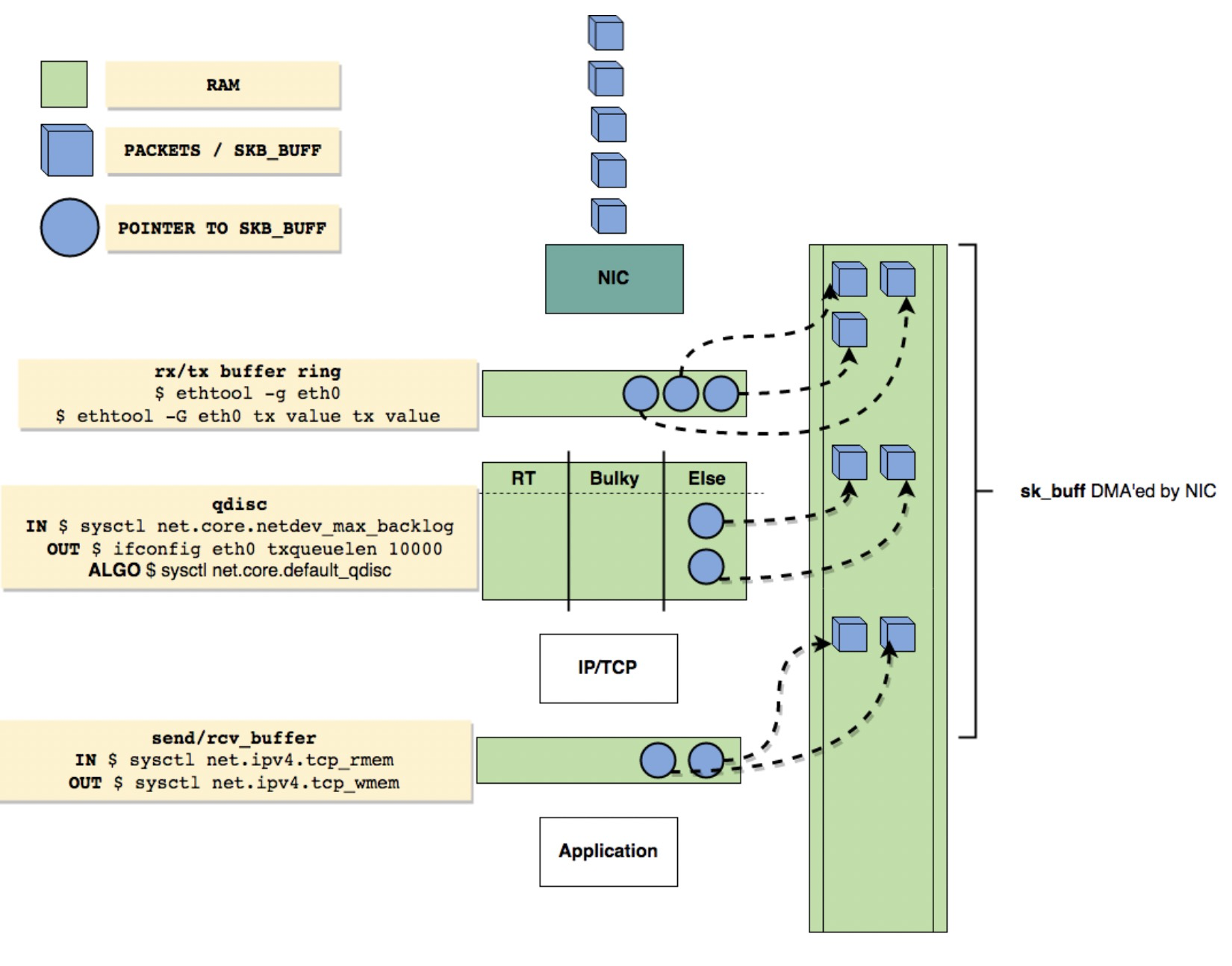
buffer和流控
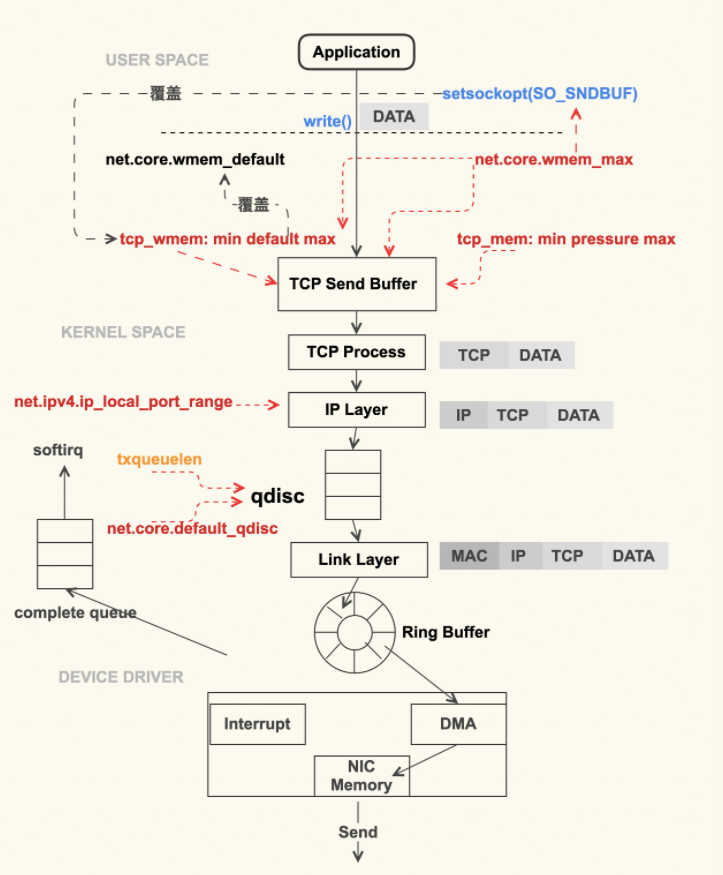
影响发送的速度的几个buffer和queue,接收基本一样
网卡传递数据包到内核的流程图及参数
软中断NET_TX_SOFTIRQ的处理函数为net_tx_action,NET_RX_SOFTIRQ的为net_rx_action
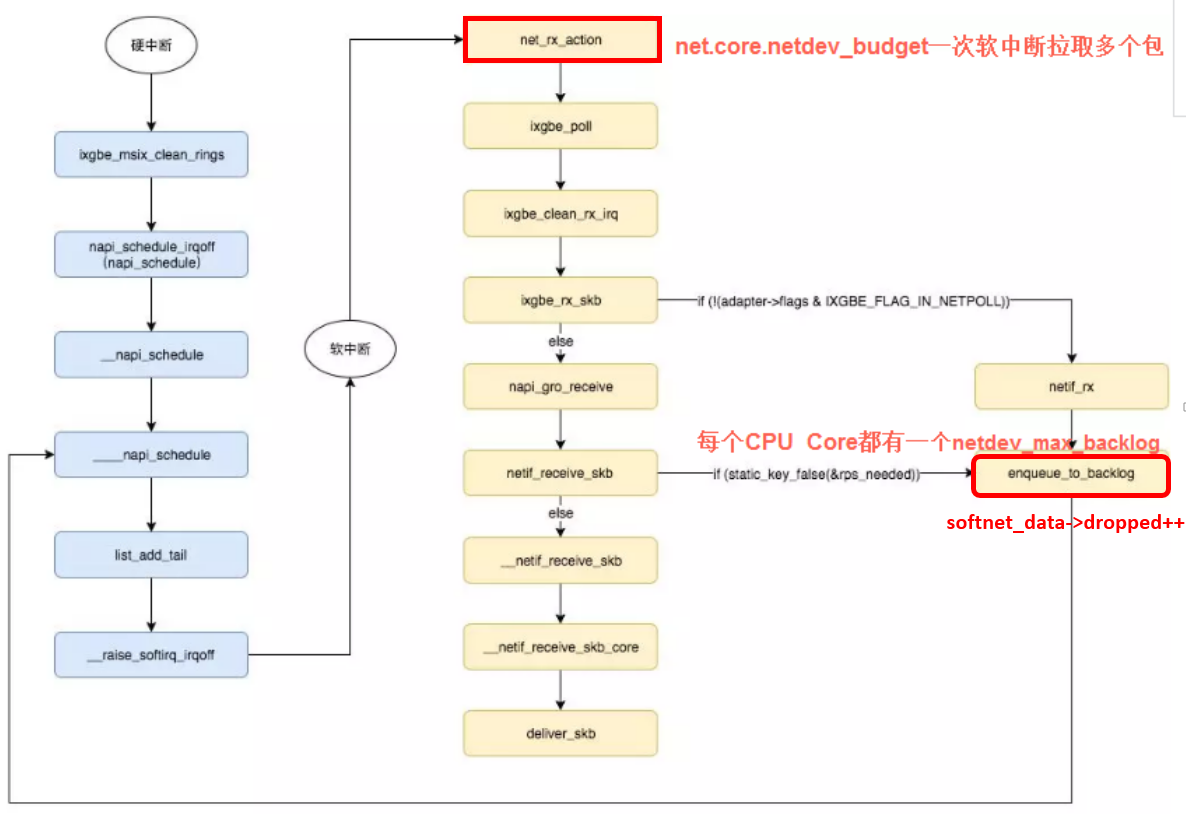
在网络子系统初始化中为NET_RX_SOFTIRQ注册了处理函数net_rx_action。所以net_rx_action函数就会被执行到了。
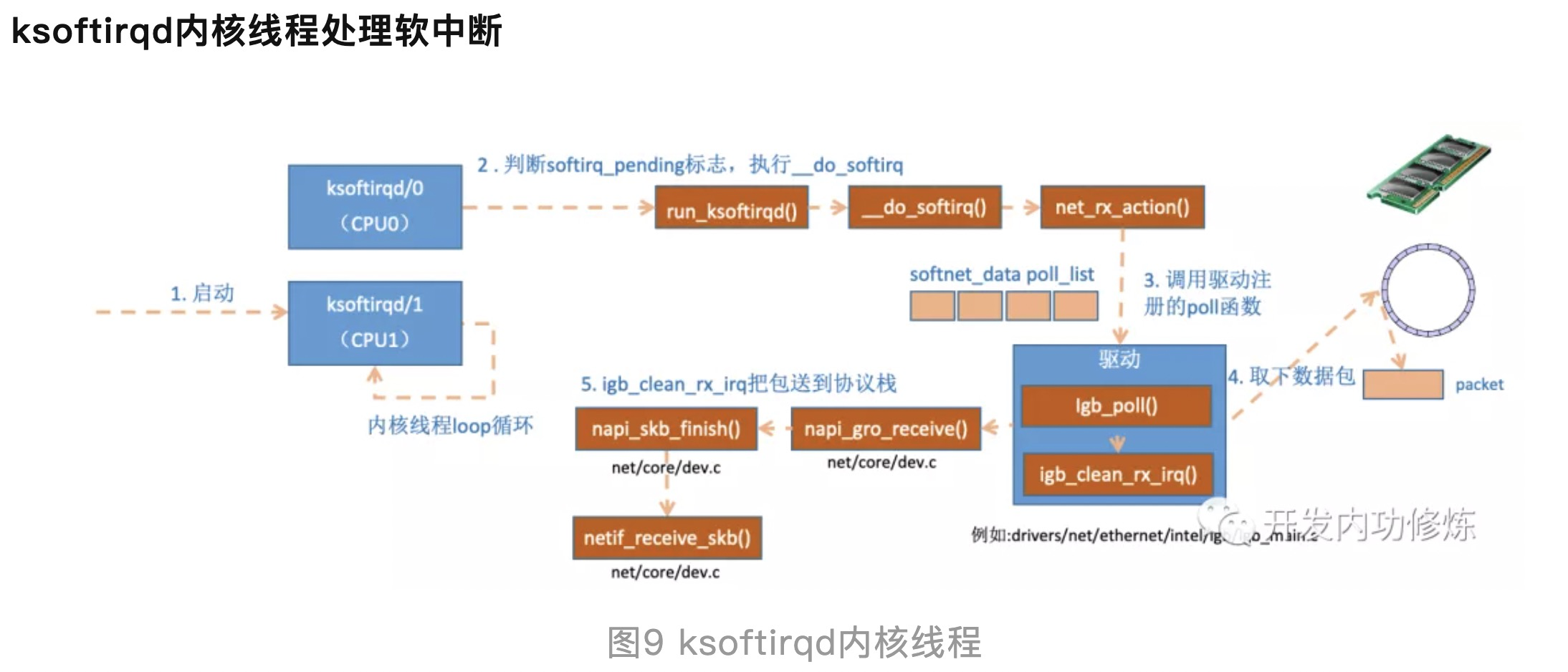
这里需要注意一个细节,硬中断中设置软中断标记,和ksoftirq的判断是否有软中断到达,都是基于smp_processor_id()的。这意味着只要硬中断在哪个CPU上被响应,那么软中断也是在这个CPU上处理的。所以说,如果你发现你的Linux软中断CPU消耗都集中在一个核上的话,做法是要把调整硬中断的CPU亲和性,来将硬中断打散到不同的CPU核上去。
软中断(也就是 Linux 里的 ksoftirqd 进程)里收到数据包以后,发现是 tcp 的包的话就会执行到 tcp_v4_rcv 函数。如果是 ESTABLISHED 状态下的数据包,则最终会把数据拆出来放到对应 socket 的接收队列中。然后调用 sk_data_ready 来唤醒用户进程。

对应的堆栈(本堆栈有问题,si%打满):

igb_fetch_rx_buffer和igb_is_non_eop的作用就是把数据帧从RingBuffer上取下来。为什么需要两个函数呢?因为有可能帧要占多个RingBuffer,所以是在一个循环中获取的,直到帧尾部。获取下来的一个数据帧用一个sk_buff来表示。收取完数据以后,对其进行一些校验,然后开始设置sbk变量的timestamp, VLAN id, protocol等字段。接下来进入到napi_gro_receive中,里面还会调用关键的 netif_receive_skb, 在netif_receive_skb中,数据包将被送到协议栈中,上图中的tcp_v4_rcv就是其中之一(tcp协议)
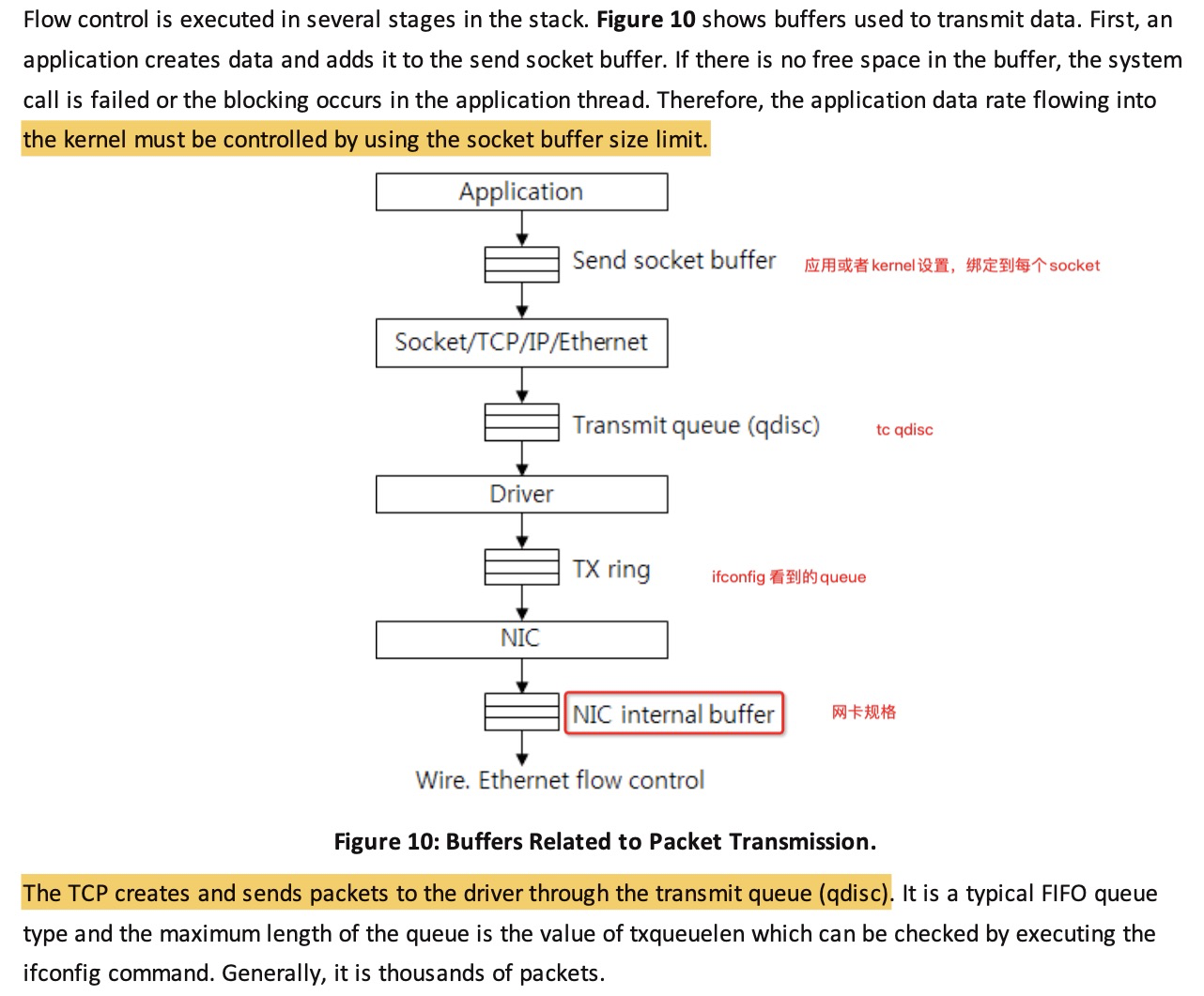
发送流程
- 应用调 sendmsg
- 数据拷贝到sk_write_queue上的最后一个skb中,如果该skb指向的数据区已经满了,则调用sk_stream_alloc_skb创建一个新的skb,并挂到这个sk_write_queue上
- TCP 分片 skb_buff
- 根据 tcp_wmem 缓存需要发送的包
- 构造TCP包头(src/dst port)
- ipv4 调用 tcp_write_xmit 和 tcp_transmit_skb
- ip_queue_xmit, 构建 ip 包头(获取目标ip和port,找路由)
- 进入 netfilter 流程 nf_hook(),iptables规则在这里生效
- 路由流程 POST_ROUTING,iptables 的nat和mangle表会在这里设置规则,对数据包进行一些修改
- ip_output 分片
- 进入L2 dev_queue_xmit,tc 网络流控在这里
- 填入 txqueuelen 队列
- 进入发送 Ring Buffer tx
- 驱动触发软中断 soft IRQ (NET_TX_SOFTIRQ)
在传输层的出口函数tcp_transmit_skb中,会对这个skb进行克隆(skb_clone),克隆得到的子skb和原先的父skb 指向共同的数据区。并且会把struct skb_shared_info的dataref 的计数加一。
传输层以下各层处理的skb 实际就是这个克隆出来的skb,而原先的skb保留在TCP连接的发送队列上。
克隆skb再经过协议栈层层处理后进入到驱动程序的RingBuffer 中。随后网卡驱动真正将数据发送出去,当发送完成时,由硬中断通知 CPU,然后由中断处理程序来清理 RingBuffer中指向的skb。注意,这里只释放了这个skb结构本身,而skb指向的数据区,由于dataref而不会被释放。要等到TCP层接收到ACK后,再释放父skb的同时,释放数据区。
比如ip_queue_xmit发现无法路由到目标地址,就会丢弃发送包,这里丢弃的是克隆包,原始包还在发送队列里,所以TCP层就会在定时器到期后进行重传。
发包卡顿
内核从3.16开始有这样一个机制,在生成的一个新的重传报文前,先判断之前的报文的是否还在qdisc里面,如果在,就避免生成一个新的报文。
也就是对内核而言这个包发送了但是没收到ack,但实际这个包还在本机qdisc queue或者driver queue里,所以没必要重传
对应的监控计数:
1 | #netstat -s |grep -i spur |
这个发包过程在发送端实际抓不到这个包,因为还没有真正发送,而是在发送端的queue里排队,但是对上层应用来说包发完了(回包ack也不需要应用来感知),所以抓包看起来正常,就是应用感觉卡了(卡的原因还是包在发送端内核 queue 排队,一般是 pfifo_fast bug 和 bug2)
关于 TCPSpuriousRtxHostQueues 指标的作用:
Host queues (Qdisc + NIC) can hold packets so long that TCP can
eventually retransmit a packet before the first transmit even left
the host.Its not clear right now if we could avoid this in the first place :
We could arm RTO timer not at the time we enqueue packets, but
at the time we TX complete them (tcp_wfree())Cancel the sending of the new copy of the packet if prior one
is still in queue.This patch adds instrumentation so that we can at least see how
often this problem happens.TCPSpuriousRtxHostQueues SNMP counter is incremented every time
we detect the fast clone is not yet freed in tcp_transmit_skb()
发包卡死
从四层协议栈来看发包流程
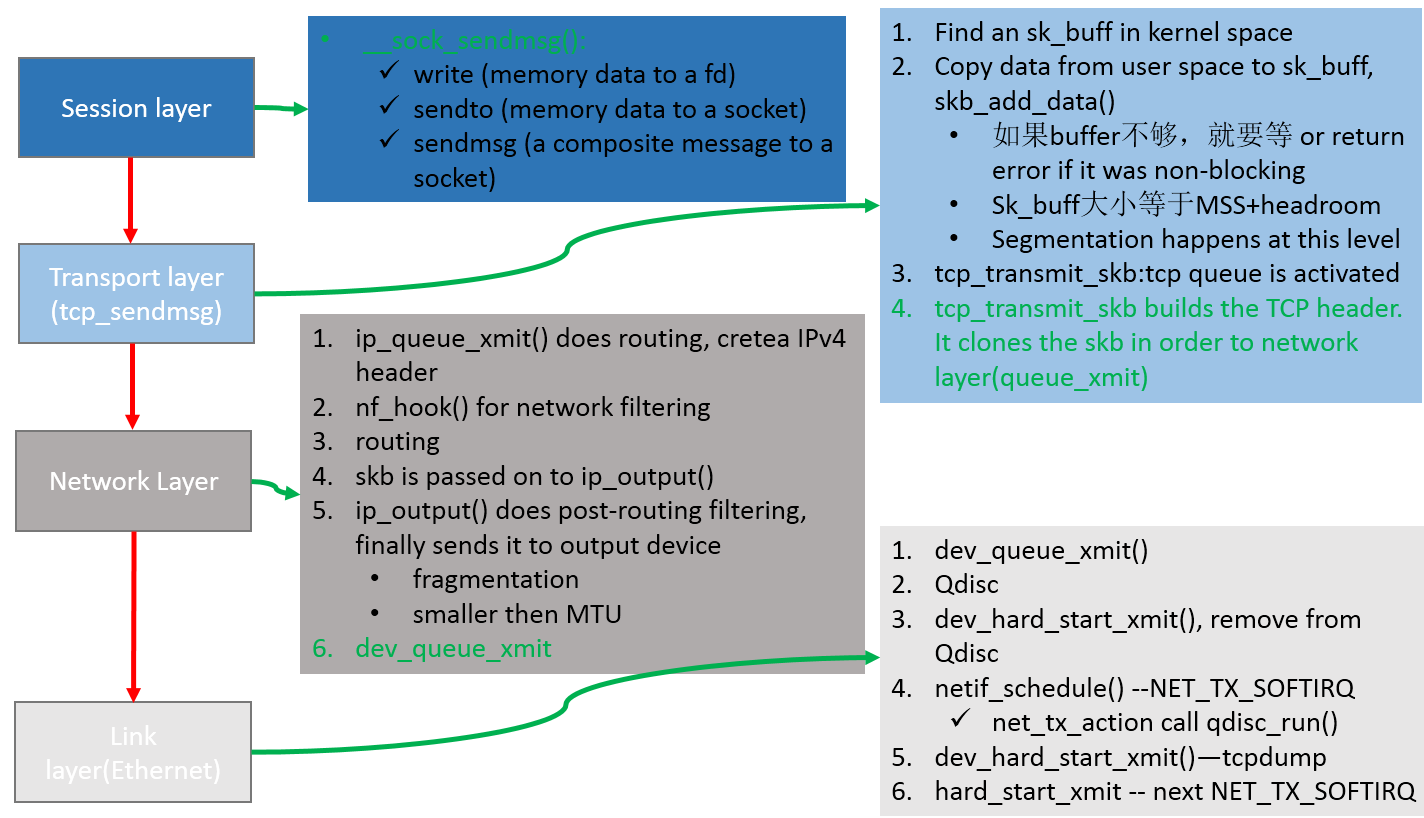
发包流程对应源代码:
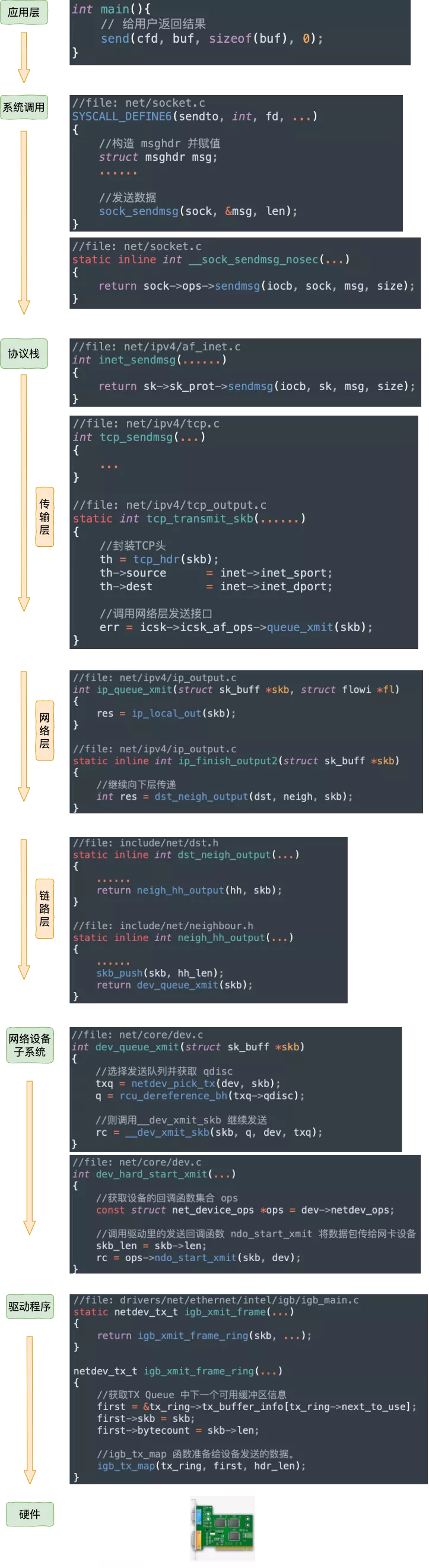
net.core.dev_weight 用来调整 __qdisc_run 的循环处理权重,调大后也就是 __netif_schedule 更多的被调用执
另外发包默认是系统调用完成的(占用 sy cpu),只有在包太多,为了避免系统调用长时间占用 CPU 导致应用层卡顿,这个时候内核给了发包时间一个quota(net.core.dev_weight 参数来控制),用完后即使包没发送完也退出发包的系统调用,队列中未发送完的包留待 tx-softirq 来发送(这是占用 si cpu)
tcp在做tcp_sendmsg 的时候会将应用层msg做copy到内核层的skb,在调用网络层执行tcp_transmit_skb 会将这个 skb再次copy交给网络层,内核态的skb继续保留直到收到ack。
tcp_transmit_skb 还会设置tcp头,在skb中 tcp头、ip头内存都预留好了,只需要填写内容。
然后就是ip层,主要是分包、路由控制,然后就是netfilter(比如iptables规则匹配)。再然后进入neighbour(arp) , 获取mac后进入网络层
用 sudo ifconfig eth0 txqueuelen ** 来控制qdisc 发送队列长度
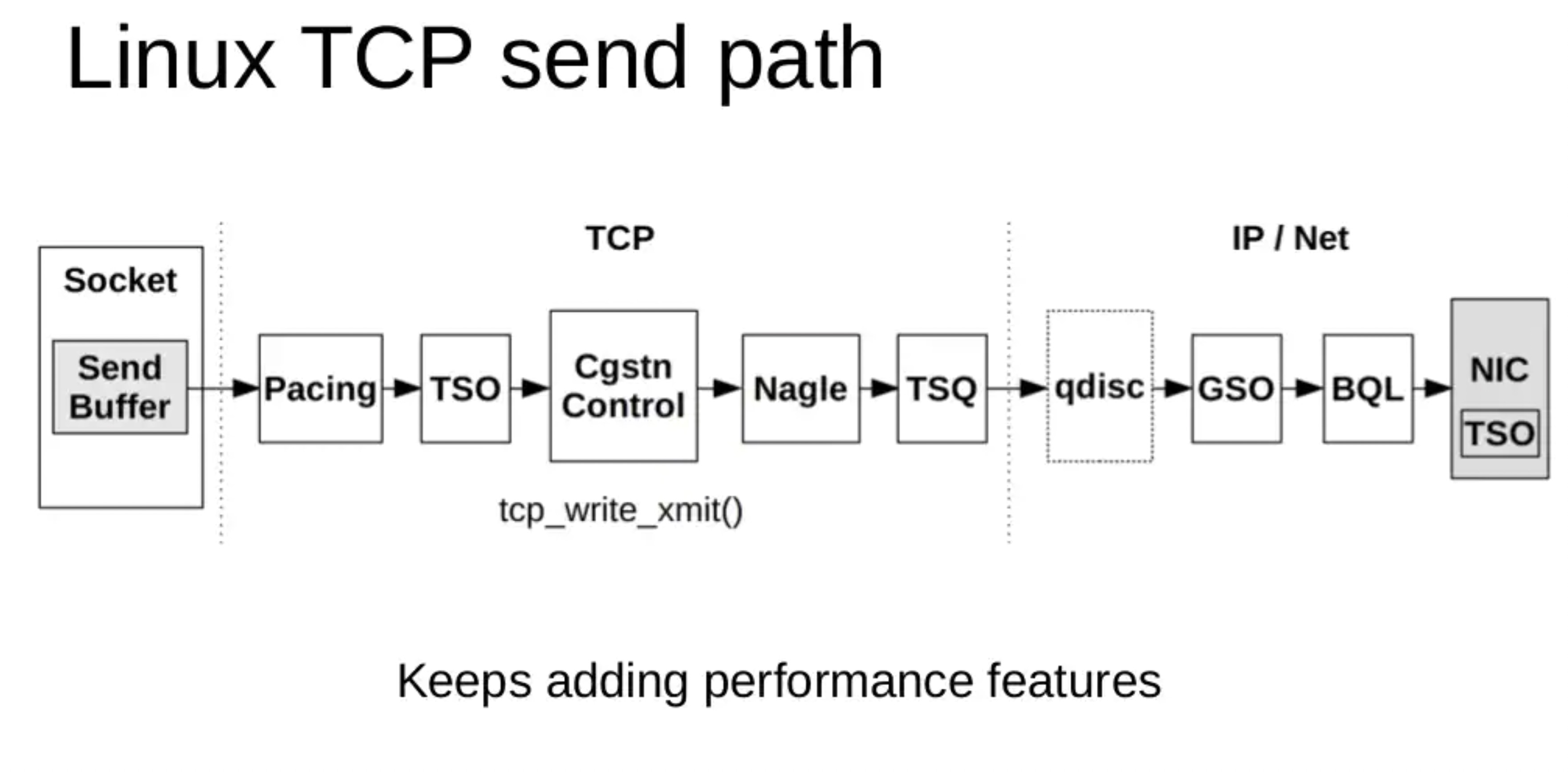
粗略汇总一下进出堆栈:
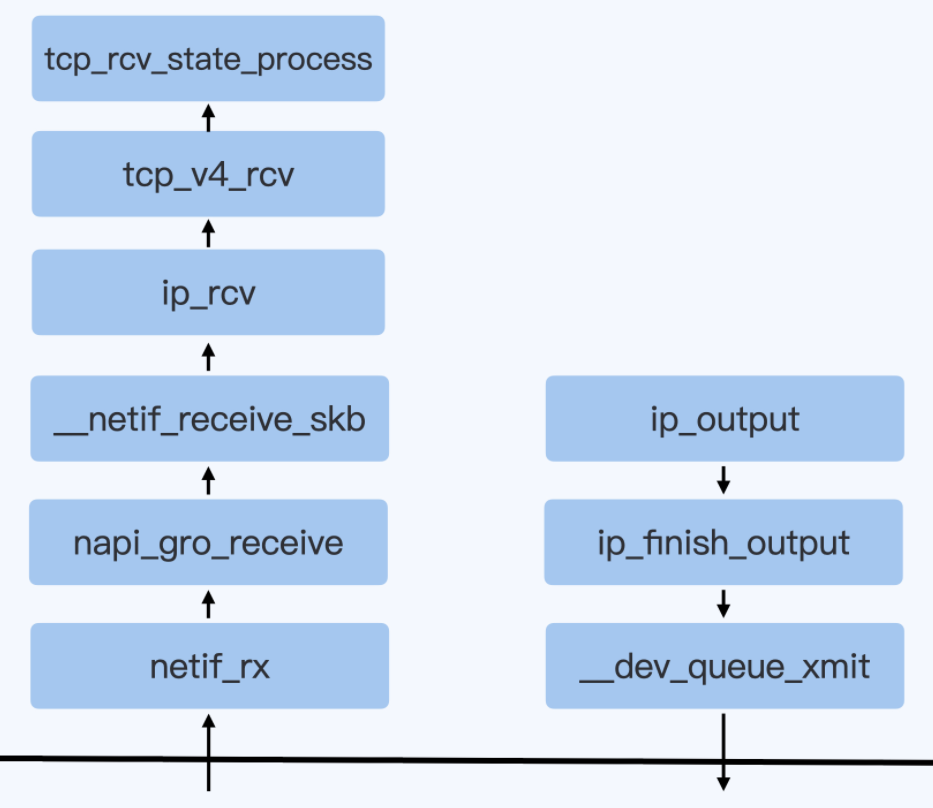
http://docshare02.docshare.tips/files/21804/218043783.pdf 中也有描述:
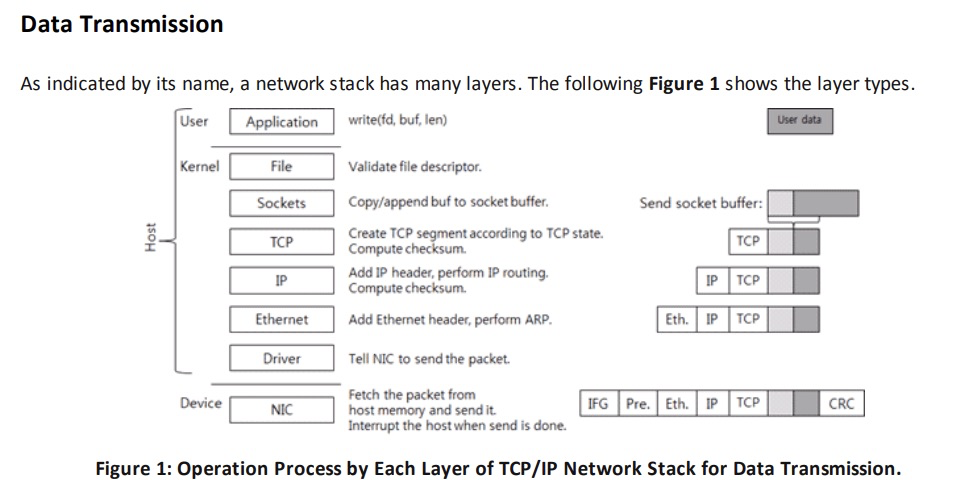
软中断
一般net_rx 远大于net_tx, 如下所示,这是因为每个包发送完成后还需要清理回收内存(释放 skb),这是通过硬中断触发 rx-softirq 来完成的,无论是收包、还是发送包完毕都是触发这个rx-softirq。
1 | #cut /proc/softirqs -c 1-70 |
发送的时候如果 net.core.dev_weight 配额够的话直接通过系统调用就将包发送完毕,不需要触发软中断
内核相关参数
Ring Buffer
Ring Buffer位于NIC和IP层之间,是一个典型的FIFO(先进先出)环形队列。Ring Buffer没有包含数据本身,而是包含了指向sk_buff(socket kernel buffers)的描述符。
可以使用ethtool -g eth0查看当前Ring Buffer的设置:
$sudo ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
上面的例子是一个小规格的ECS,接收队列、传输队列都为256。
$sudo ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 512
这是一台物理机,接收队列为4096,传输队列为512。接收队列已经调到了最大,传输队列还可以调大。队列越大丢包的可能越小,但数据延迟会增加
调整 Ring Buffer 队列数量
1 | ethtool -l eth0 |
网卡多队列就是指的有多个RingBuffer,每个RingBufffer可以由一个core来处理
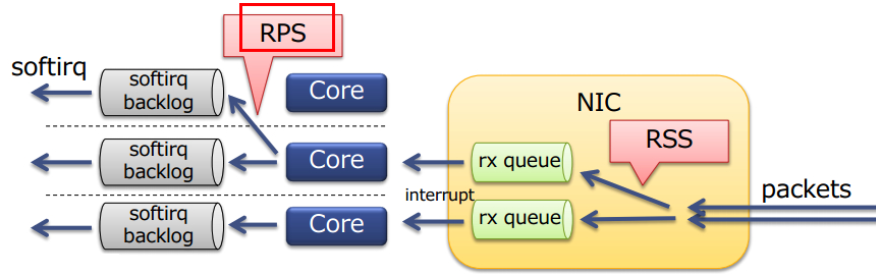
网卡各种统计数据查看
ethtool -S eth0 | grep errors
ethtool -S eth0 | grep rx_ | grep errors //查看网卡是否丢包,一般是ring buffer太小
//监控
ethtool -S eth0 | grep -e "err" -e "drop" -e "over" -e "miss" -e "timeout" -e "reset" -e "restar" -e "collis" -e "over" | grep -v "\: 0"
网卡进出队列大小调整
//查看目前的进出队列大小
ethtool -g eth0
//修改进出队列
ethtool -G eth0 rx 8192 tx 8192
要注意如果设置的值超过了允许的最大值,用默认的最大值,一些ECS之类的虚拟机、容器就不允许修改这个值。
txqueuelen
ifconfig 看到的 txqueuelen 跟Ring Buffer是两个东西,IP协议下面就是 txqueuelen,txqueuelen下面才到Ring Buffer.
常用的tc qdisc、netfilter就是在txqueuelen这一环节。 qdisc 的队列长度是我们用 ifconfig 来看到的 txqueuelen
发送队列就是指的这个txqueuelen,和网卡关联着。 而每个Core接收队列由内核参数: net.core.netdev_max_backlog来设置
1 | //当前值通过ifconfig可以查看到,修改: |
如果txqueuelen 太小导致数据包被丢弃的情况,这类问题可以通过下面这个命令来观察:
1 | $ ip -s -s link ls dev eth0 |
如果观察到 dropped 这一项不为 0,那就有可能是 txqueuelen 太小导致的。当遇到这种情况时,你就需要增大该值了,比如增加 eth0 这个网络接口的 txqueuelen:
$ ifconfig eth0 txqueuelen 2000
Interrupt Coalescence (IC) - rx-usecs, tx-usecs, rx-frames, tx-frames (hardware IRQ)
可以通过降低终端的频率,也就是合并硬中断来提升处理网络包的能力,当然这是以增大网络包的延迟为代价。
//检查
$ethtool -c eth0
Coalesce parameters for eth0:
Adaptive RX: off TX: off
stats-block-usecs: 0
sample-interval: 0
pkt-rate-low: 0
pkt-rate-high: 0
rx-usecs: 1
rx-frames: 0
rx-usecs-irq: 0
rx-frames-irq: 0
tx-usecs: 0
tx-frames: 0
tx-usecs-irq: 0
tx-frames-irq: 256
rx-usecs-low: 0
rx-frame-low: 0
tx-usecs-low: 0
tx-frame-low: 0
rx-usecs-high: 0
rx-frame-high: 0
tx-usecs-high: 0
tx-frame-high: 0
//修改,
ethtool -C eth0 rx-usecs value tx-usecs value
//监控
cat /proc/interrupts
我们来说一下上述结果的大致含义
Adaptive RX: 自适应中断合并,网卡驱动自己判断啥时候该合并啥时候不合并
rx-usecs:当过这么长时间过后,一个RX interrupt就会被产生。How many usecs to delay an RX interrupt after a packet arrives.
rx-frames:当累计接收到这么多个帧后,一个RX interrupt就会被产生。Maximum number of data frames to receive before an RX interrupt.
rx-usecs-irq: How many usecs to delay an RX interrupt while an interrupt is being serviced by the host.rx-frames-irq: Maximum number of data frames to receive before an RX interrupt is generated while the system is servicing an interrupt.
Ethtool 绑定端口
ntuple filtering for steering network flows
一些网卡支持 “ntuple filtering” 特性。该特性允许用户(通过 ethtool )指定一些参数来在硬件上过滤收到的包,然后将其直接放到特定的 RX queue。例如,用户可以指定到特定目端口的 TCP 包放到 RX queue 1。
Intel 的网卡上这个特性叫 Intel Ethernet Flow Director,其他厂商可能也有他们的名字,这些都是出于市场宣传原因,底层原理是类似的。
我们后面会看到,ntuple filtering 是一个叫 Accelerated Receive Flow Steering(aRFS) 功能的核心部分之一,后者使得 ntuple filtering 的使用更加方便。
这个特性适用的场景:最大化数据本地性(data locality),以增加 CPU 处理网络数据时的缓存命中率。例如,考虑运行在 80 口的 web 服务器:
- webserver 进程运行在 80 口,并绑定到 CPU 2
- 和某个 RX queue 关联的硬中断绑定到 CPU 2
- 目的端口是 80 的 TCP 流量通过 ntuple filtering 绑定到 CPU 2
- 接下来所有到 80 口的流量,从数据包进来到数据到达用户程序的整个过程,都由 CPU 2 处理
- 仔细监控系统的缓存命中率、网络栈的延迟等信息,以验证以上配置是否生效
检查 ntuple filtering 特性是否打开:
1 | $ sudo ethtool -k eth0 |
可以看到,上面的 ntuple 是关闭的。
打开:
1 | $ sudo ethtool -K eth0 ntuple on |
打开 ntuple filtering 功能,并确认打开之后,可以用 ethtool -u 查看当前的 ntuple
rules:
1 | $ sudo ethtool -u eth0 |
可以看到当前没有 rules。
我们来加一条:目的端口是 80 的放到 RX queue 2:
1 | $ sudo ethtool -U eth0 flow-type tcp4 dst-port 80 action 2 |
你也可以用 ntuple filtering 在硬件层面直接 drop 某些 flow 的包。当特定 IP 过来的流量太大时,这种功能可能会派上用场。更多关于 ntuple 的信息,参 考 ethtool man page。
软中断合并 GRO
GRO和硬中断合并的思想很类似,不过阶段不同。硬中断合并是在中断发起之前,而GRO已经到了软中断上下文中了。
如果应用中是大文件的传输,大部分包都是一段数据,不用GRO的话,会每次都将一个小包传送到协议栈(IP接收函数、TCP接收)函数中进行处理。开启GRO的话,Linux就会智能进行包的合并,之后将一个大包传给协议处理函数。这样CPU的效率也是就提高了。
1 | # ethtool -k eth0 | grep generic-receive-offload |
如果你的网卡驱动没有打开GRO的话,可以通过如下方式打开。
1 | # ethtool -K eth0 gro on |
这是收包,发包对应参数是GSO
ifconfig 监控指标
- RX overruns: overruns意味着数据包没到Ring Buffer就被网卡物理层给丢弃了,而CPU无法及时的处理中断是造成Ring Buffer满的原因之一,例如中断分配的不均匀。或者Ring Buffer太小导致的(很少见),overruns数量持续增加,建议增大Ring Buffer ,使用ethtool ‐G 进行设置。
- RX dropped: 表示数据包已经进入了Ring Buffer,但是由于内存不够等系统原因,导致在拷贝到内存的过程中被丢弃。如下四种情况导致dropped:Softnet backlog full(pfmemalloc && !skb_pfmemalloc_protocol(skb)–分配内存失败);Bad / Unintended VLAN tags;Unknown / Unregistered protocols;IPv6 frames
- RX errors:表示总的收包的错误数量,这包括 too-long-frames 错误,Ring Buffer 溢出错误,crc 校验错误,帧同步错误,fifo overruns 以及 missed pkg 等等。
overruns
当驱动处理速度跟不上网卡收包速度时,驱动来不及分配缓冲区,NIC接收到的数据包无法及时写到sk_buffer,就会产生堆积,当NIC内部缓冲区写满后,就会丢弃部分数据,引起丢包。这部分丢包为rx_fifo_errors,在 /proc/net/dev中体现为fifo字段增长,在ifconfig中体现为overruns指标增长。
监控指标 /proc/net/softnet_stat
Important details about /proc/net/softnet_stat:
- Each line of
/proc/net/softnet_statcorresponds to astruct softnet_datastructure, of which there is 1 per CPU. - The values are separated by a single space and are displayed in hexadecimal
- The first value,
sd->processed, is the number of network frames processed. This can be more than the total number of network frames received if you are using ethernet bonding. There are cases where the ethernet bonding driver will trigger network data to be re-processed, which would increment thesd->processedcount more than once for the same packet. - The second value,
sd->dropped, is the number of network frames dropped because there was no room on the processing queue. More on this later. - The third value,
sd->time_squeeze, is (as we saw) the number of times thenet_rx_actionloop terminated because the budget was consumed or the time limit was reached, but more work could have been. Increasing thebudgetas explained earlier can help reduce this. time_squeeze 计数在内核中只有一个地方会更新(比如内核 5.10),如果看到监控中有 time_squeeze 升高, 那一定就是执行到了以上 budget 用完的逻辑 - The next 5 values are always 0.
- The ninth value,
sd->cpu_collision, is a count of the number of times a collision occurred when trying to obtain a device lock when transmitting packets. This article is about receive, so this statistic will not be seen below. - The tenth value,
sd->received_rps, is a count of the number of times this CPU has been woken up to process packets via an Inter-processor Interrupt - The last value,
flow_limit_count, is a count of the number of times the flow limit has been reached. Flow limiting is an optional Receive Packet Steering feature that will be examined shortly.
对应的代码实现:
1 | // https://github.com/torvalds/linux/blob/v5.10/net/core/net-procfs.c#L172 |
net.core.netdev_budget
一次软中断(ksoftirqd进程)能处理包的上限,有就多处理,处理到300个了一定要停下来让CPU能继续其它工作。单次poll 收包是所有注册到这个 CPU 的 NAPI 变量收包数量之和不能大于这个阈值。
1 | sysctl net.core.netdev_budget //3.10 kernel默认300, The default value of the budget is 300. This will cause the SoftIRQ process to drain 300 messages from the NIC before getting off the CPU |
如果 /proc/net/softnet_stat 第三列一直在增加的话需要,表示SoftIRQ 获取的CPU时间太短,来不及处理足够多的网络包,那么需要增大这个值,当这个值太大的话有可能导致包到了内核但是应用(userspace)抢不到时间片来读取这些packet。
增大和查看 net.core.netdev_budget
sysctl -a | grep net.core.netdev_budget
sysctl -w net.core.netdev_budget=400 //临时性增大
早期的时候网卡一般是10Mb的,现在基本都是10Gb的了,还是每一次软中断、上下文切换只处理一个包的话代价太大,需要改进性能。于是引入的NAPI,一次软中断会poll很多packet
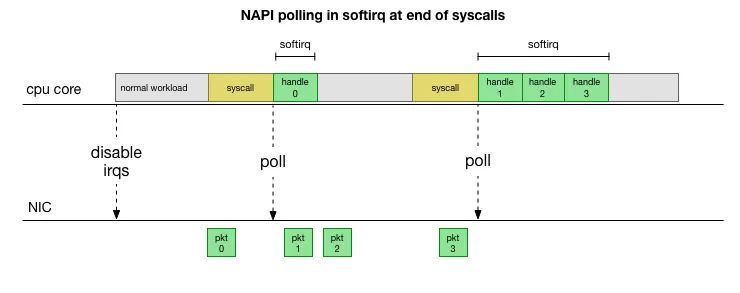
来源 This is much faster, but brings up another problem. What happens if we have so many packets to process that we spend all our time processing packets from the NIC, but we never have time to let the userspace processes actually drain those queues (read from TCP connections, etc.)? Eventually the queues would fill up, and we’d start dropping packets. To try and make this fair, the kernel limits the amount of packets processed in a given softirq context to a certain budget. Once this budget is exceeded, it wakes up a separate thread called ksoftirqd (you’ll see one of these in ps for each core) which processes these softirqs outside of the normal syscall/interrupt path. This thread is scheduled using the standard process scheduler, which already tries to be fair.
于是在Poll很多packet的时候有可能网卡队列一直都有包,那么导致这个Poll动作无法结束,造成应用一直在卡住状态,于是可以通过netdev_max_backlog来设置Poll多少Packet后停止Poll以响应用户请求。
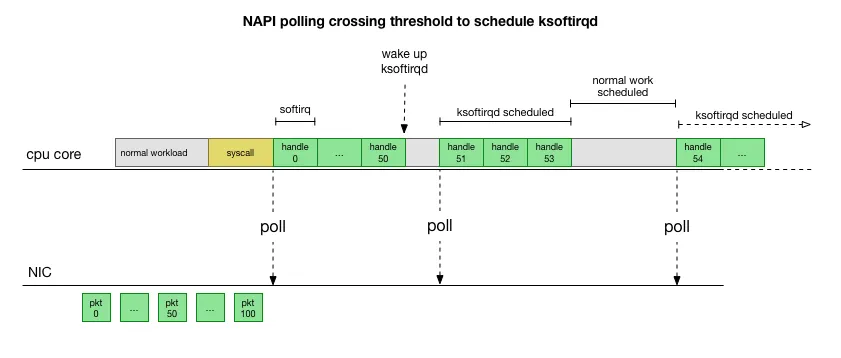
一旦出现slow syscall(如上图黄色部分慢)就会导致packet处理被延迟。
发送包的时候系统调用循环发包,占用sy,只有当发包系统quota用完的时候,循环退出,剩下的包通过触发软中断的形式继续发送,此时占用si
netdev_max_backlog
The netdev_max_backlog is a queue within the Linux kernel where traffic is stored after reception from the NIC, but before processing by the protocol stacks (IP, TCP, etc). There is one backlog queue per CPU core.
如果 /proc/net/softnet_stat 第二列一直在增加的话表示netdev backlog queue overflows. 需要增大 netdev_max_backlog
增大和查看 netdev_max_backlog:
sysctl -a |grep netdev_max_backlog
sysctl -w net.core.netdev_max_backlog=1024 //临时性增大
netdev_max_backlog(接收)和txqueuelen(发送)相对应
softnet_stat
关于/proc/net/softnet_stat 的重要细节:
- 每一行代表一个
struct softnet_data变量。因为每个 CPU core 都有一个该变量,所以每行 其实代表一个 CPU core - 每列用空格隔开,数值用 16 进制表示
- 第一列
sd->processed,是处理的网络帧的数量。如果你使用了 ethernet bonding, 那这个值会大于总的网络帧的数量,因为 ethernet bonding 驱动有时会触发网络数据被 重新处理(re-processed) - 第二列,
sd->dropped,是因为处理不过来而 drop 的网络帧数量。后面会展开这一话题 - 第三列,
sd->time_squeeze,前面介绍过了,由于 budget 或 time limit 用完而退出net_rx_action循环的次数 - 接下来的 5 列全是 0
- 第九列,
sd->cpu_collision,是为了发送包而获取锁的时候有冲突的次数 - 第十列,
sd->received_rps,是这个 CPU 被其他 CPU 唤醒去收包的次数 - 最后一列,
flow_limit_count,是达到 flow limit 的次数。flow limit 是 RPS 的特性, 后面会稍微介绍一下
TCP协议栈Buffer
sysctl -a | grep net.ipv4.tcp_rmem // receive
sysctl -a | grep net.ipv4.tcp_wmem // send
//监控
cat /proc/net/sockstat
接收Buffer
$netstat -sn | egrep "prune|collap"; sleep 30; netstat -sn | egrep "prune|collap"
17671 packets pruned from receive queue because of socket buffer overrun
18671 packets pruned from receive queue because of socket buffer overrun
如果 “pruning” 一直在增加很有可能是程序中调用了 setsockopt(SO_RCVBUF) 导致内核关闭了动态调整功能,或者压力大,缓存不够了。具体Case:https://blog.cloudflare.com/the-story-of-one-latency-spike/
nstat也可以看到比较多的数据
1 | $nstat -z |grep -i drop |
总体简略接收包流程
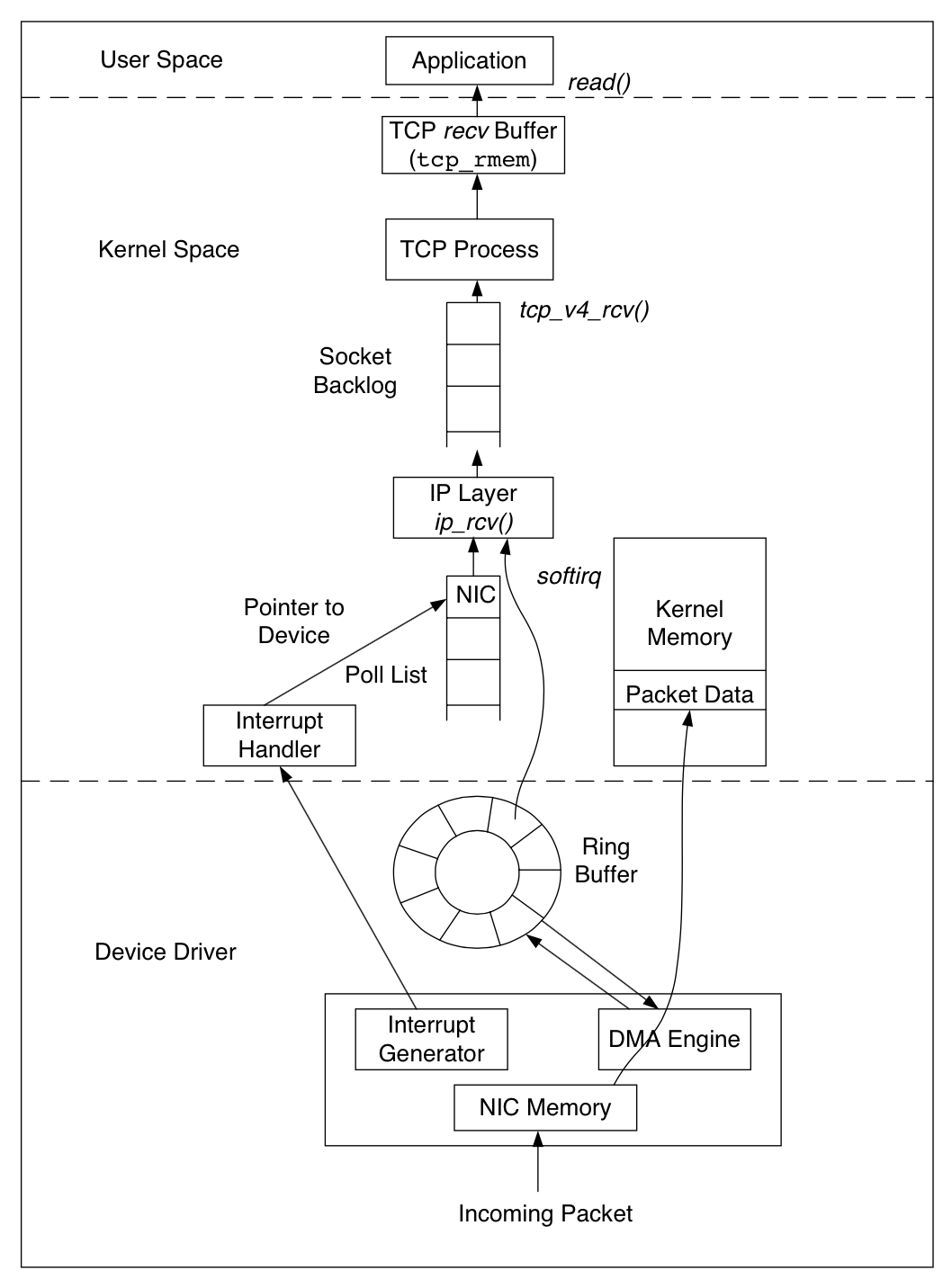
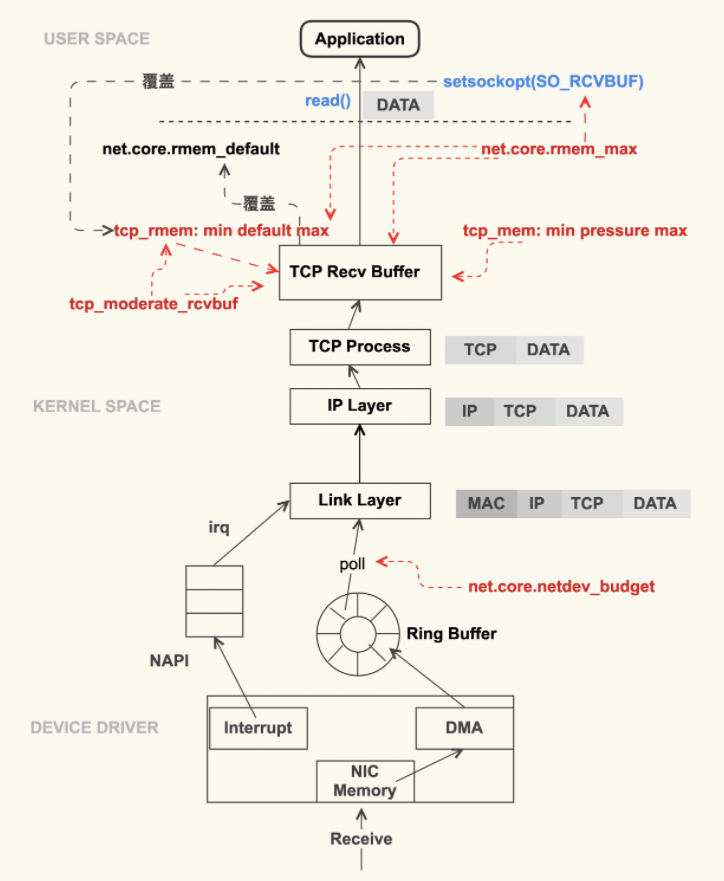
带参数版收包流程:
总体简略发送包流程
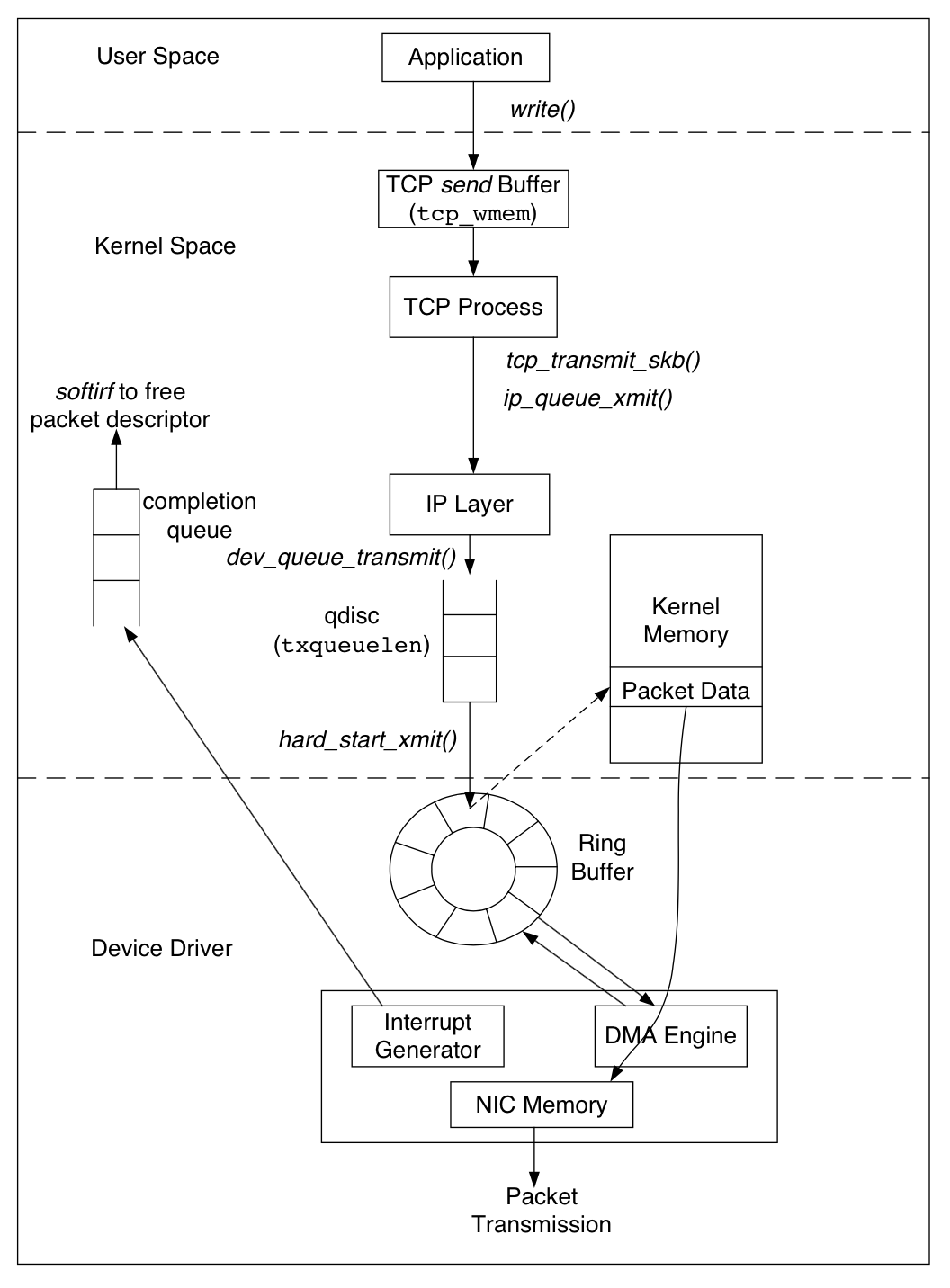
带参数版发包流程:
网络包流转结构图
跨机器网络IO
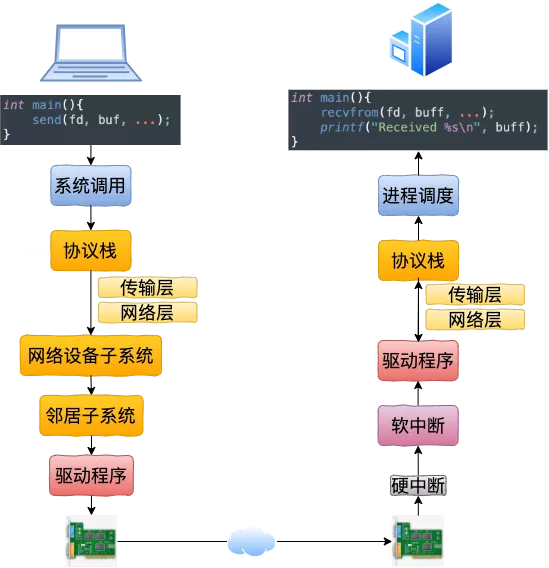
lo 网卡
127.0.0.1(lo)本机网络 IO ,无需走到物理网卡,也不用进入RingBuffer驱动队列,但是还是要走内核协议栈,直接把 skb 传给接收协议栈(经过软中断)
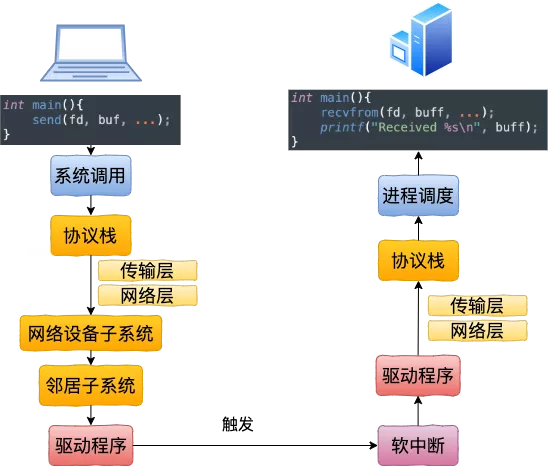
总的来说,本机网络 IO 和跨机 IO 比较起来,确实是节约了一些开销。发送数据不需要进 RingBuffer 的驱动队列,直接把 skb 传给接收协议栈(经过软中断)。但是在内核其它组件上,可是一点都没少,系统调用、协议栈(传输层、网络层等)、网络设备子系统、邻居子系统整个走了一个遍。连“驱动”程序都走了(虽然对于回环设备来说只是一个纯软件的虚拟出来的东东)。所以即使是本机网络 IO,也别误以为没啥开销,实际本机访问自己的eth0 ip也是走的lo网卡和访问127.0.0.1是一样的,测试用ab分别走127.0.0.1和eth0压nginx,在nginx进程跑满,ab还没满两者的nginx单核都是7万TPS左右,跨主机压nginx的单核也是7万左右(要调多ab的并发数)。
如果是同一台宿主机走虚拟bridge通信的话(同一宿主机下的不容docker容器通信):
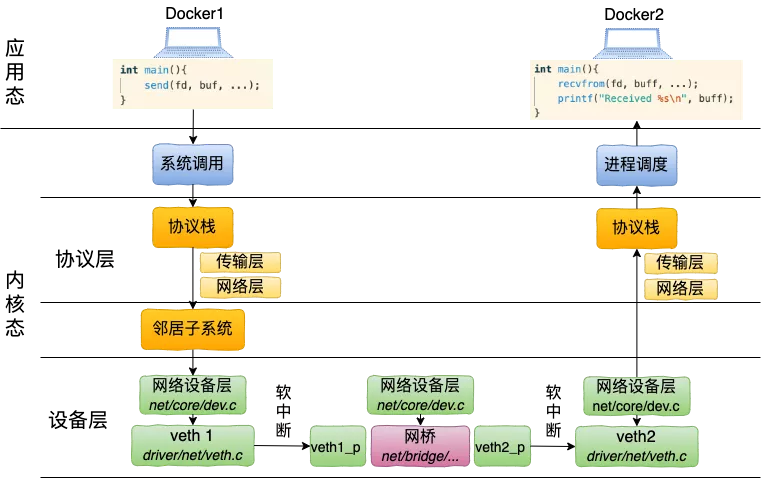
| ab 压 nginx单核(intel 8163 绑核) | |
|---|---|
| 127.0.0.1 | Requests per second: 69498.96 [#/sec] (mean) Time per request: 0.086 [ms] (mean) |
| Eth0 | Requests per second: 70261.93 [#/sec] (mean) Time per request: 0.085 [ms] (mean) |
| 跨主机压 | Requests per second: 70119.05 [#/sec] (mean) Time per request: 0.143 [ms] (mean) |
ab不支持unix domain socket,如果增加ab和nginx之间的时延,QPS急剧下降,但是增加ab的并发数完全可以把QPS拉回去。
Unix Domain Socket工作原理
接收connect 请求的时候,会申请一个新 socket 给 server 端将来使用,和自己的 socket 建立好连接关系以后,就放到服务器正在监听的 socket 的接收队列中。这个时候,服务器端通过 accept 就能获取到和客户端配好对的新 socket 了。
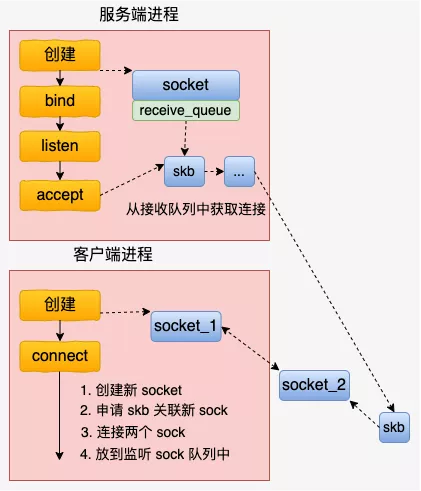
主要的连接操作都是在这个函数中完成的。和我们平常所见的 TCP 连接建立过程,这个连接过程简直是太简单了。没有三次握手,也没有全连接队列、半连接队列,更没有啥超时重传。
直接就是将两个 socket 结构体中的指针互相指向对方就行了。就是 unix_peer(newsk) = sk 和 unix_peer(sk) = newsk 这两句。
1 | //file: net/unix/af_unix.c |
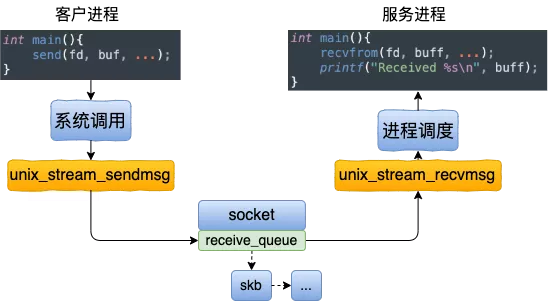
收发包过程和复杂的 TCP 发送接收过程相比,这里的发送逻辑简单简单到令人发指。申请一块内存(skb),把数据拷贝进去。根据 socket 对象找到另一端,直接把 skb 给放到对端的接收队列里了
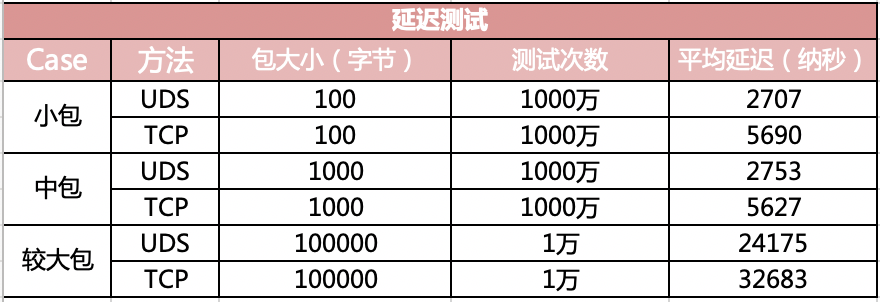
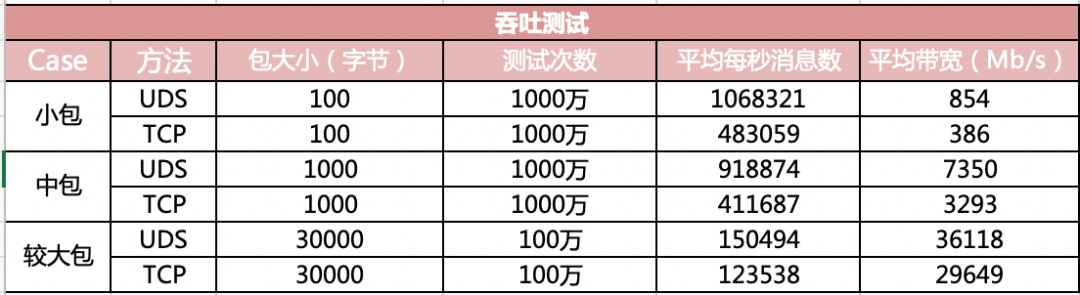
Unix Domain Socket和127.0.0.1通信相比,如果包的大小是1K以内,那么性能会有一倍以上的提升,包变大后性能的提升相对会小一些。
再来一个整体流转矢量图:
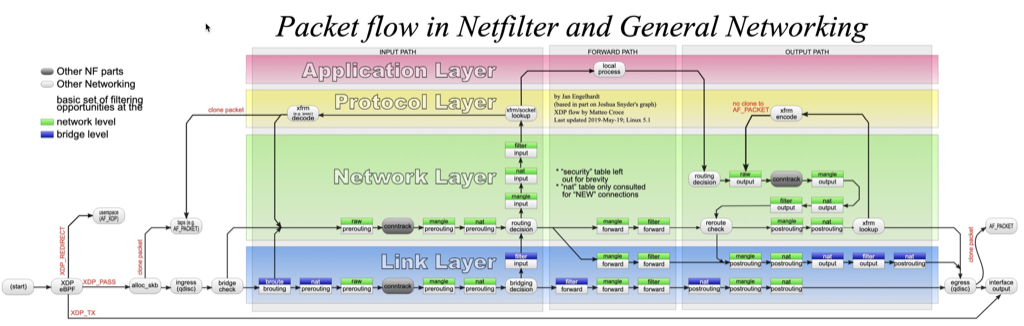
案例
snat/dnat 宿主机port冲突,丢包

snat 就是要把 192.168.1.10和192.168.1.11的两个连接替换成宿主机的ip:port
主要是在宿主机找可用port分别给这两个连接用
找可用port分两步
找到可用port将可用port写到数据库,后面做连接追踪用(conntrack)
上述两步不是事务,可能两个连接同时找到一个相同的可用port,但是只有第一个能写入成功,第二个fail,fail后这个包被扔掉
1秒钟后被扔掉的包重传,后续正常
症状:
问题发生概率不高,跟压力没有关系,跟容器也没有关系,只要有snat/dnat和并发就会发生,只发生在创建连接的第一个syn包
可以通过conntrack工具来检查fail的数量
实际影响只是请求偶尔被拉长了1秒或者3秒
snat规则创建的时候增加参数:NF_NAT_RANGE_PROTO_RANDOM_FULLY 来将冲突降低几个数量级—-可以认为修复了这个问题
sudo conntrack -L -d ip-addr
来自:https://tech.xing.com/a-reason-for-unexplained-connection-timeouts-on-kubernetes-docker-abd041cf7e02
容器(bridge)通过udp访问宿主机服务失败
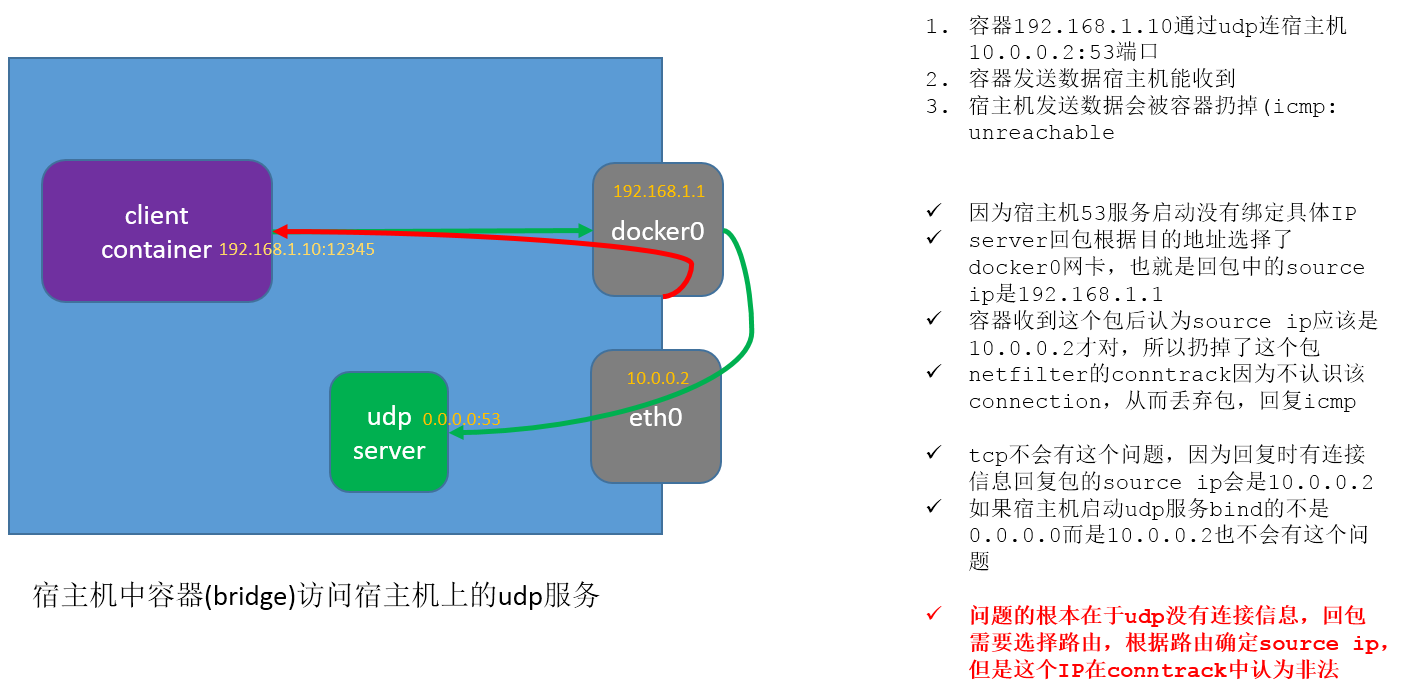
这个案例主要是讲述回包的逻辑,如果是tcp,那么用dest ip当自己的source ip,如果是UDP,无连接状态信息,那么会根据route来选择一块网卡(上面的IP) 来当source ip
来自:http://cizixs.com/2017/08/21/docker-udp-issue
https://github.com/moby/moby/issues/15127
参考资料
The Missing Man Page for ifconfig–关于ifconfig的种种解释
linux-network-performance-parameters
https://access.redhat.com/sites/default/files/attachments/20150325_network_performance_tuning.pdf
Linux 网络协议栈收消息过程-Ring Buffer : 支持 RSS 的网卡内部会有多个 Ring Buffer,NIC 收到 Frame 的时候能通过 Hash Function 来决定 Frame 该放在哪个 Ring Buffer 上,触发的 IRQ 也可以通过操作系统或者手动配置 IRQ affinity 将 IRQ 分配到多个 CPU 上。这样 IRQ 能被不同的 CPU 处理,从而做到 Ring Buffer 上的数据也能被不同的 CPU 处理,从而提高数据的并行处理能力。
收到包后内核层面的处理:从网卡注册软中断处理函数到收包逻辑
收到包后应用和协议层面的处理:图解 | 深入理解高性能网络开发路上的绊脚石 - 同步阻塞网络 IOhttps://mp.weixin.qq.com/s/cIcw0S-Q8pBl1-WYN0UwnA 当软中断上收到数据包时会通过调用 sk_data_ready 函数指针(实际被设置成了 sock_def_readable()) 来唤醒在 sock 上等待的进程
http://docshare02.docshare.tips/files/21804/218043783.pdf
https://wiki.linuxfoundation.org/networking/kernel_flow
https://wiki.nix-pro.com/view/Packet_journey_through_Linux_kernel
https://blog.packagecloud.io/eng/2017/02/06/monitoring-tuning-linux-networking-stack-sending-data/