就是要你懂TCP--性能优化大全
TCP性能优化大全
先从一个问题看起,客户通过专线访问云上的DRDS,专线100M,时延20ms,一个SQL查询了22M数据,结果花了大概25秒,这慢得不太正常,如果通过云上client访问云上DRDS那么1-2秒就返回了。如果通过http或者scp传输这22M的数据大概两秒钟也传送完毕了,所以这里问题的原因基本上是DRDS在这种网络条件下有性能问题,需要找出为什么。
抓包 tcpdump+wireshark
这个查询结果22M的需要25秒,如下图(wireshark 时序图),横轴是时间纵轴是sequence number:
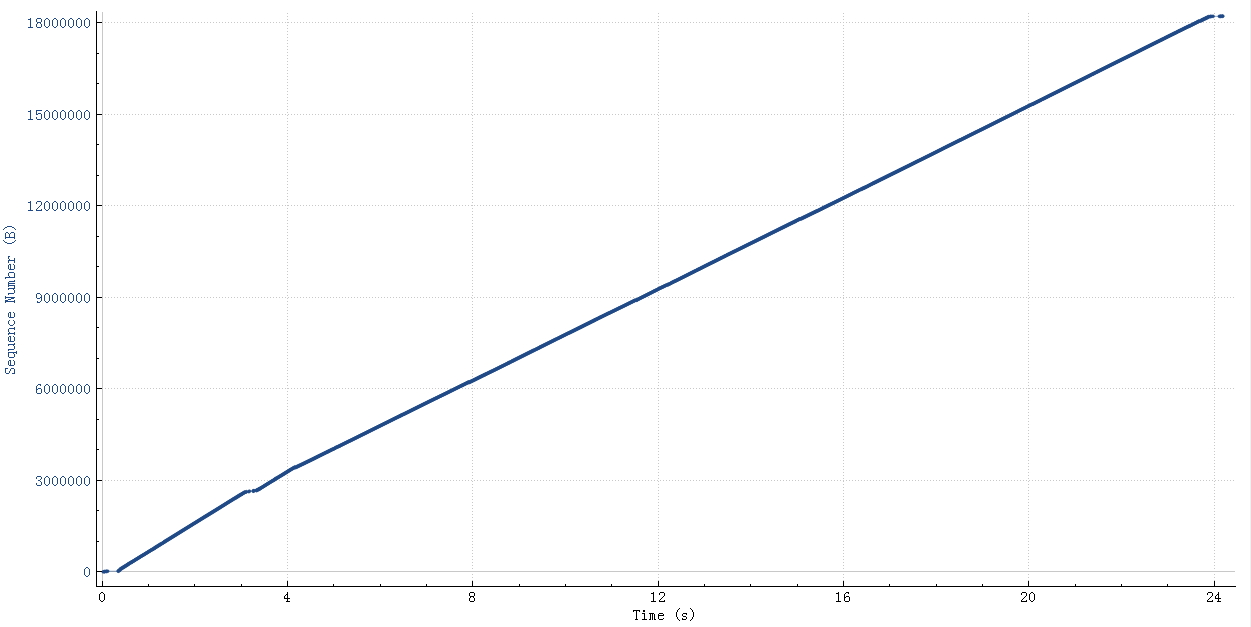
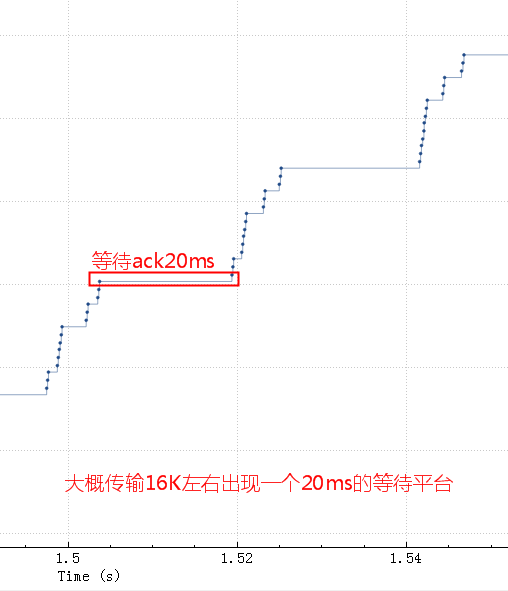
粗一看没啥问题,把这个图形放大看看
换个角度,看看窗口尺寸图形:
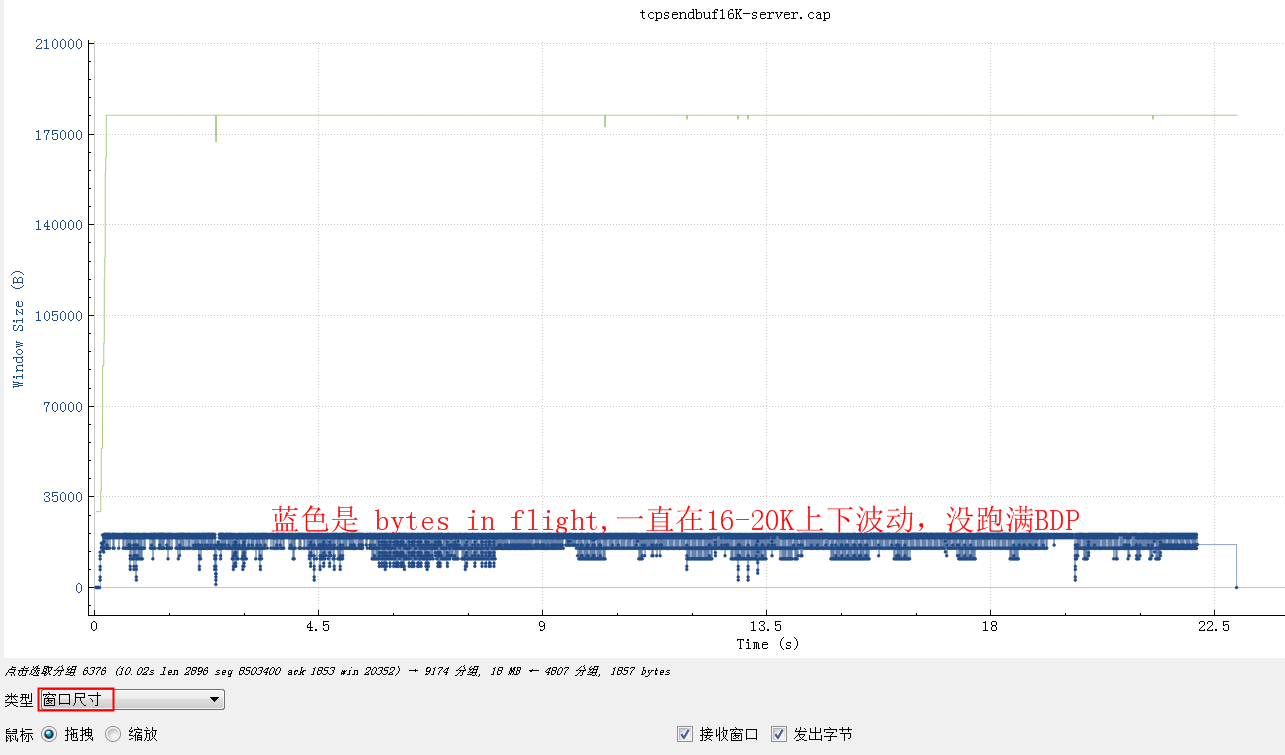
从bytes in flight也大致能算出来总的传输时间 16K*1000/20=800Kb/秒
DRDS会默认设置 socketSendBuffer 为16K:
socket.setSendBufferSize(16*1024) //16K send buffer
来看一下tcp包发送流程:

(图片来自:https://www.atatech.org/articles/9032)

如果sendbuffer不够就会卡在上图中的第一步 sk_stream_wait_memory, 通过systemtap脚本可以验证:
#!/usr/bin/stap
# Simple probe to detect when a process is waiting for more socket send
# buffer memory. Usually means the process is doing writes larger than the
# socket send buffer size or there is a slow receiver at the other side.
# Increasing the socket's send buffer size might help decrease application
# latencies, but it might also make it worse, so buyer beware.
#
# Typical output: timestamp in microseconds: procname(pid) event
#
# 1218230114875167: python(17631) blocked on full send buffer
# 1218230114876196: python(17631) recovered from full send buffer
# 1218230114876271: python(17631) blocked on full send buffer
# 1218230114876479: python(17631) recovered from full send buffer
probe kernel.function("sk_stream_wait_memory")
{
printf("%u: %s(%d) blocked on full send buffer\n",
gettimeofday_us(), execname(), pid())
}
probe kernel.function("sk_stream_wait_memory").return
{
printf("%u: %s(%d) recovered from full send buffer\n",
gettimeofday_us(), execname(), pid())
}
如果tcp发送buffer也就是SO_SNDBUF只有16K的话,这些包很快都发出去了,但是这16K不能立即释放出来填新的内容进去,因为tcp要保证可靠,万一中间丢包了呢。只有等到这16K中的某些ack了,才会填充一些进来然后继续发出去。由于这里rt基本是20ms,也就是16K发送完毕后,等了20ms才收到一些ack,这20ms应用、内核什么都不能做,所以就是如第二个图中的大概20ms的等待平台。这块请参考这篇文章
sendbuffer相当于发送仓库的大小,仓库的货物都发走后,不能立马腾出来发新的货物,而是要等发走的获取对方确认收到了(ack)才能腾出来发新的货物, 仓库足够大了之后接下来的瓶颈就是高速公路了(带宽、拥塞窗口)
如果是UDP,就没有send buffer的概念,有数据统统发出去,根本不关心对方是否收到。
几个发送buf相关的内核参数
vm.lowmem_reserve_ratio = 256 256 32
net.core.wmem_max = 1048576
net.core.wmem_default = 124928
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.udp_wmem_min = 4096
net.ipv4.tcp_wmem 默认就是16K,而且是能够动态调整的,只不过我们代码中这块的参数是很多年前从Corba中继承过来的,一直没有修改。代码中设置了这个参数后就关闭了内核的动态调整功能,所以能看到http或者scp都很快。
接收buffer是有开关可以动态控制的,发送buffer没有开关默认就是开启,关闭只能在代码层面来控制
net.ipv4.tcp_moderate_rcvbuf
优化
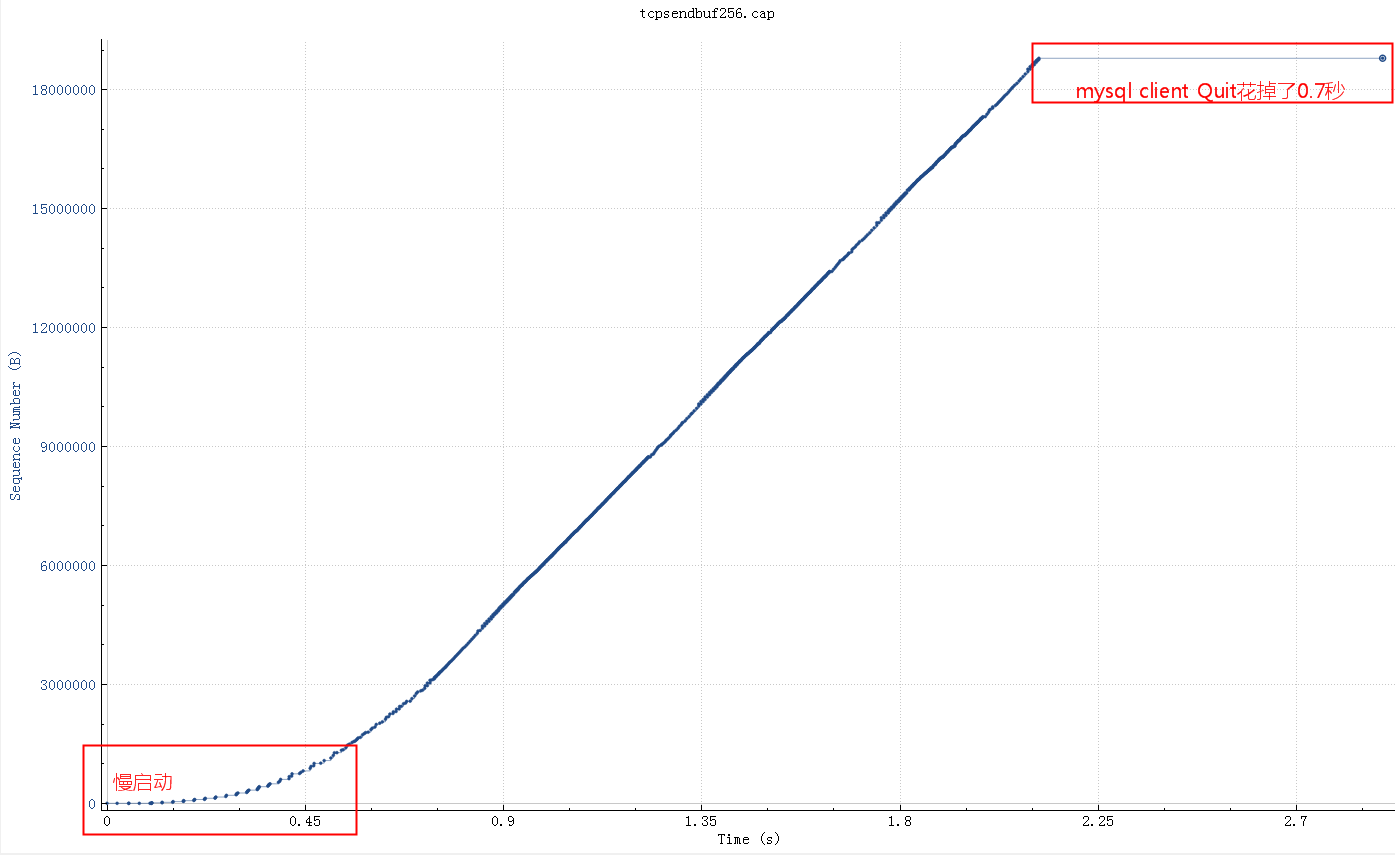
调整 socketSendBuffer 到256K,查询时间从25秒下降到了4秒多,但是比理论带宽所需要的时间略高
继续查看系统 net.core.wmem_max 参数默认最大是130K,所以即使我们代码中设置256K实际使用的也是130K,调大这个系统参数后整个网络传输时间大概2秒(跟100M带宽匹配了,scp传输22M数据也要2秒),整体查询时间2.8秒。测试用的mysql client短连接,如果代码中的是长连接的话会块300-400ms(消掉了慢启动阶段),这基本上是理论上最快速度了
如果指定了tcp_wmem,则net.core.wmem_default被tcp_wmem的覆盖。send Buffer在tcp_wmem的最小值和最大值之间自动调节。如果调用setsockopt()设置了socket选项SO_SNDBUF,将关闭发送端缓冲的自动调节机制,tcp_wmem将被忽略,SO_SNDBUF的最大值由net.core.wmem_max限制。
BDP 带宽时延积
这个buf调到1M测试没有帮助,从理论计算BDP(带宽时延积) 0.02秒*(100MB/8)=250Kb 所以SO_SNDBUF为256Kb的时候基本能跑满带宽了,再大实际意义也不大了。
因为BDP是250K,也就是拥塞窗口即将成为新的瓶颈,所以调大buffer没意义了。
用tc构造延时和带宽限制的模拟重现环境
sudo tc qdisc del dev eth0 root netem delay 20ms
sudo tc qdisc add dev eth0 root tbf rate 500kbit latency 50ms burst 15kb
这个案例的结论
默认情况下Linux系统会自动调整这个buf(net.ipv4.tcp_wmem), 也就是不推荐程序中主动去设置SO_SNDBUF,除非明确知道设置的值是最优的。
平时看到的一些理论在实践中用起来比较难,最开始看到抓包结果的时候比较怀疑发送、接收窗口之类的,没有直接想到send buffer上,理论跟实践的鸿沟
需要调整tcp_rmem 的问题 Case
发送和接收Buffer对性能的完整影响参考这篇
总结下TCP跟速度相关的几个概念
- CWND:Congestion Window,拥塞窗口,负责控制单位时间内,数据发送端的报文发送量。TCP 协议规定,一个 RTT(Round-Trip Time,往返时延,大家常说的 ping 值)时间内,数据发送端只能发送 CWND 个数据包(注意不是字节数)。TCP 协议利用 CWND/RTT 来控制速度。这个值是根据丢包动态计算出来的
- SS:Slow Start,慢启动阶段。TCP 刚开始传输的时候,速度是慢慢涨起来的,除非遇到丢包,否则速度会一直指数性增长(标准 TCP 协议的拥塞控制算法,例如 cubic 就是如此。很多其它拥塞控制算法或其它厂商可能修改过慢启动增长特性,未必符合指数特性)。
- CA:Congestion Avoid,拥塞避免阶段。当 TCP 数据发送方感知到有丢包后,会降低 CWND,此时速度会下降,CWND 再次增长时,不再像 SS 那样指数增,而是线性增(同理,标准 TCP 协议的拥塞控制算法,例如 cubic 是这样,很多其它拥塞控制算法或其它厂商可能修改过慢启动增长特性,未必符合这个特性)。
- ssthresh:Slow Start Threshold,慢启动阈值。当数据发送方感知到丢包时,会记录此时的 CWND,并计算合理的 ssthresh 值(ssthresh <= 丢包时的 CWND),当 CWND 重新由小至大增长,直到 sshtresh 时,不再 SS 而是 CA。但因为数据确认超时(数据发送端始终收不到对端的接收确认报文),发送端会骤降 CWND 到最初始的状态。
- SO_SNDBUF、SO_RCVBUF 发送、接收buffer
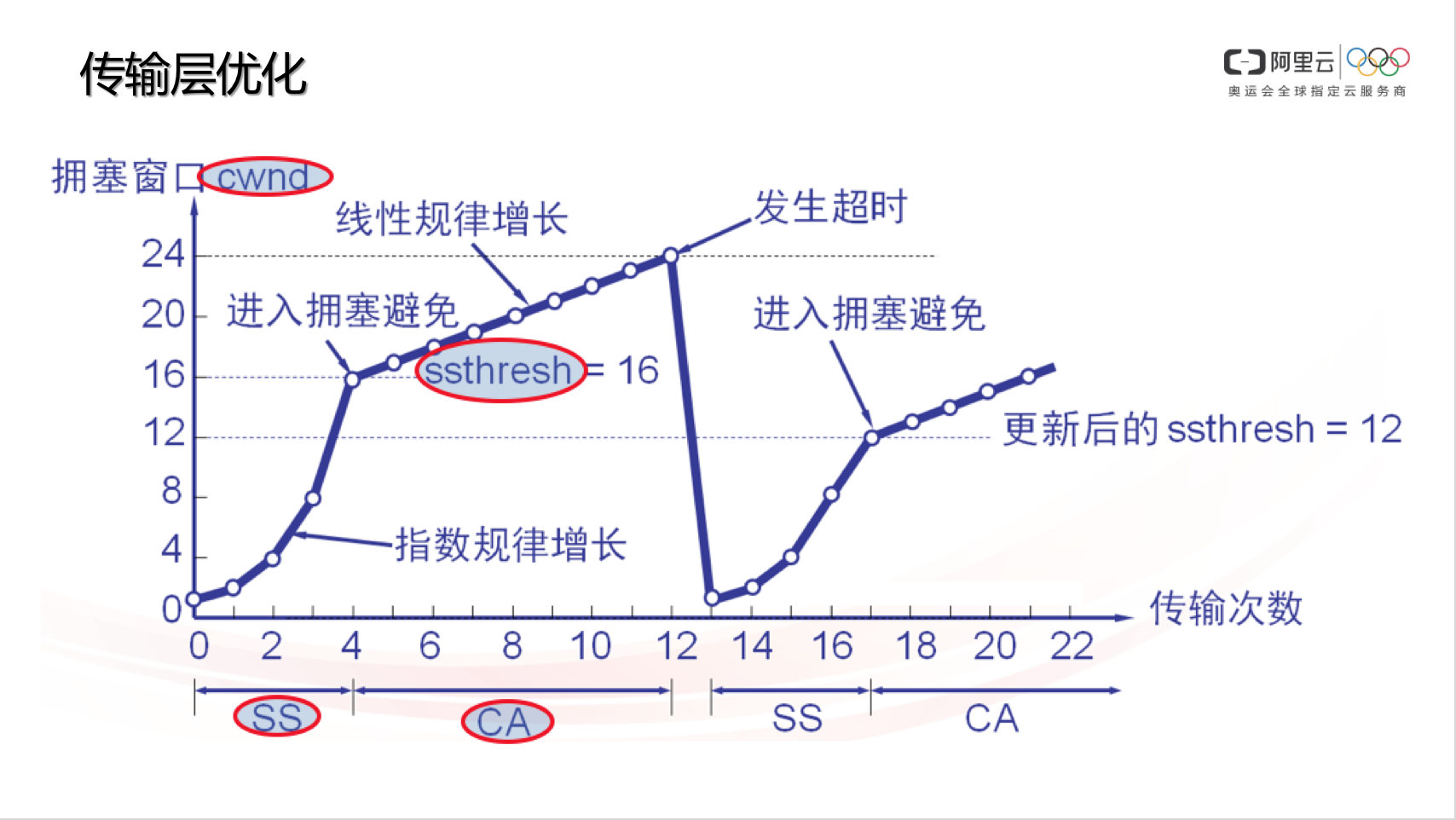
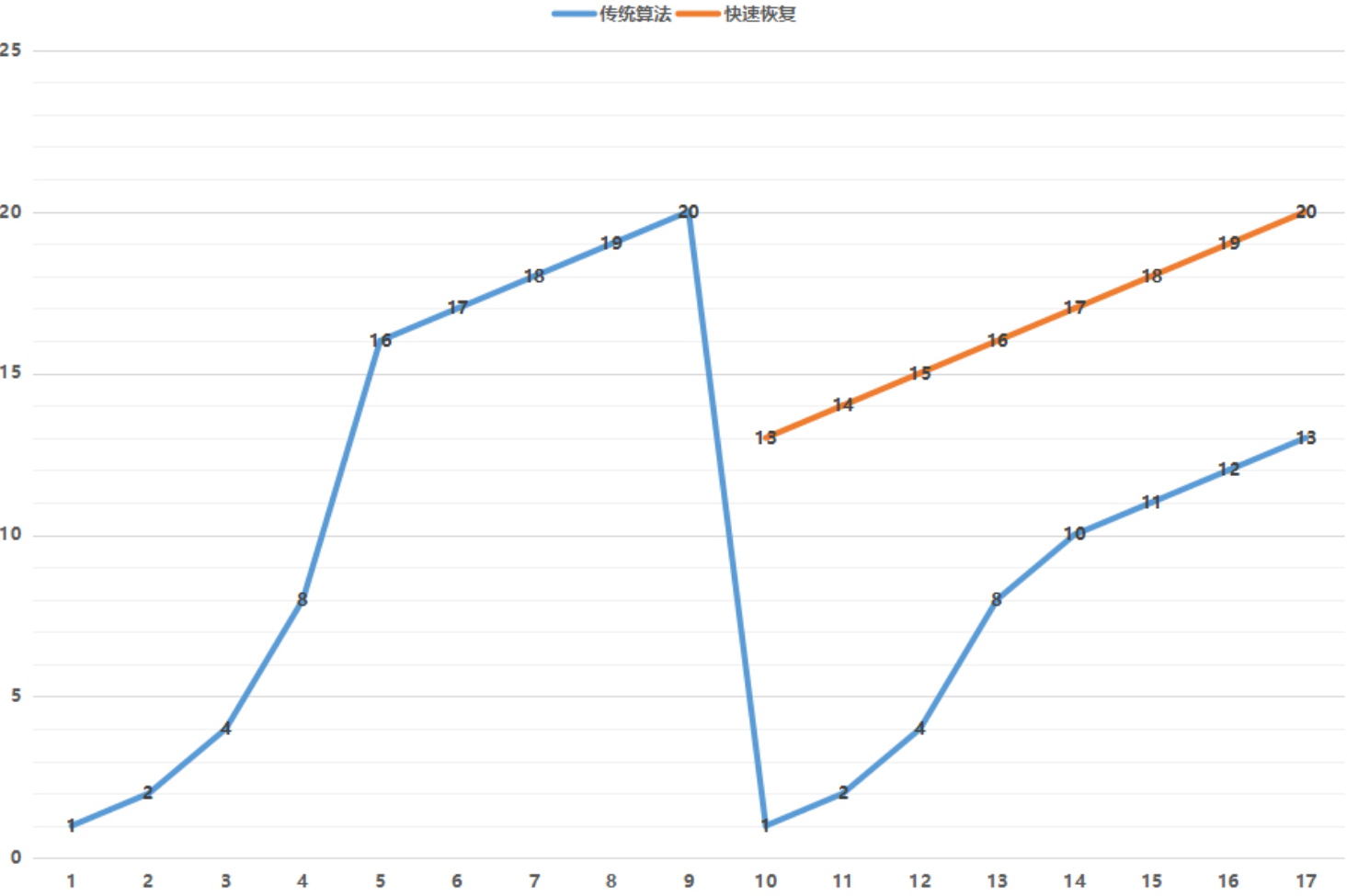
上图一旦发生丢包,cwnd降到1 ssthresh降到cwnd/2,一夜回到解放前,太保守了,实际大多情况下都是公网带宽还有空余但是链路过长,非带宽不够丢包概率增大,对此没必要这么保守(tcp诞生的背景主要针对局域网、双绞线来设计,偏保守)。RTT越大的网络环境(长肥管道)这个问题越是严重,表现就是传输速度抖动非常厉害。
所以改进的拥塞算法一旦发现丢包,cwnd和ssthresh降到原来的cwnd的一半。
TCP性能优化点
- 建连优化:TCP 在建立连接时,如果丢包,会进入重试,重试时间是 1s、2s、4s、8s 的指数递增间隔,缩短定时器可以让 TCP 在丢包环境建连时间更快,非常适用于高并发短连接的业务场景。
- 首包优化:此优化其实没什么实质意义,若要说一定会有意义的话,可能就是满足一些评测标准的需要吧,例如有些客户以首包时间作为性能评判的一个依据。所谓首包时间,简单解释就是从 HTTP Client 发出 GET 请求开始计时,到收到 HTTP 响应的时间。为此,Server 端可以通过 TCP_NODELAY 让服务器先吐出 HTTP 头,再吐出实际内容(分包发送,原本是粘到一起的),来进行提速和优化。据说更有甚者先让服务器无条件返回 “HTTP/“ 这几个字符,然后再去 upstream 拿数据。这种做法在真实场景中没有任何帮助,只能欺骗一下探测者罢了,因此还没见过有直接发 “HTTP/“ 的,其实是一种作弊行为。
- 平滑发包:如前文所述,在 RTT 内均匀发包,规避微分时间内的流量突发,尽量避免瞬间拥塞,此处不再赘述。
- 丢包预判:有些网络的丢包是有规律性的,例如每隔一段时间出现一次丢包,例如每次丢包都连续丢几个等,如果程序能自动发现这个规律(有些不明显),就可以针对性提前多发数据,减少重传时间、提高有效发包率。
- RTO 探测:如前文讲 TCP 基础时说过的,若始终收不到 ACK 报文,则需要触发 RTO 定时器。RTO 定时器一般都时间非常长,会浪费很多等待时间,而且一旦 RTO,CWND 就会骤降(标准 TCP),因此利用 Probe 提前与 RTO 去试探,可以规避由于 ACK 报文丢失而导致的速度下降问题。
- 带宽评估:通过单位时间内收到的 ACK 或 SACK 信息可以得知客户端有效接收速率,通过这个速率可以更合理的控制发包速度。
- 带宽争抢:有些场景(例如合租)是大家互相挤占带宽的,假如你和室友各 1Mbps 的速度看电影,会把 2Mbps 出口占满,而如果一共有 3 个人看,则每人只能分到 1/3。若此时你的流量流量达到 2Mbps,而他俩还都是 1Mbps,则你至少仍可以分到 2/(2+1+1) * 2Mbps = 1Mbps 的 50% 的带宽,甚至更多,代价就是服务器侧的出口流量加大,增加成本。(TCP 优化的本质就是用带宽换用户体验感)
- 链路质量记忆(后面有反面案例):如果一个 Client IP 或一个 C 段 Network,若已经得知了网络质量规律(例如 CWND 多大合适,丢包规律是怎样的等),就可以在下次连接时,优先使用历史经验值,取消慢启动环节直接进入告诉发包状态,以提升客户端接收数据速率。
这些经验都来自CDN @辟拾 的 网络优化 - TCP 是如何做到提速 20 倍的
重要参数
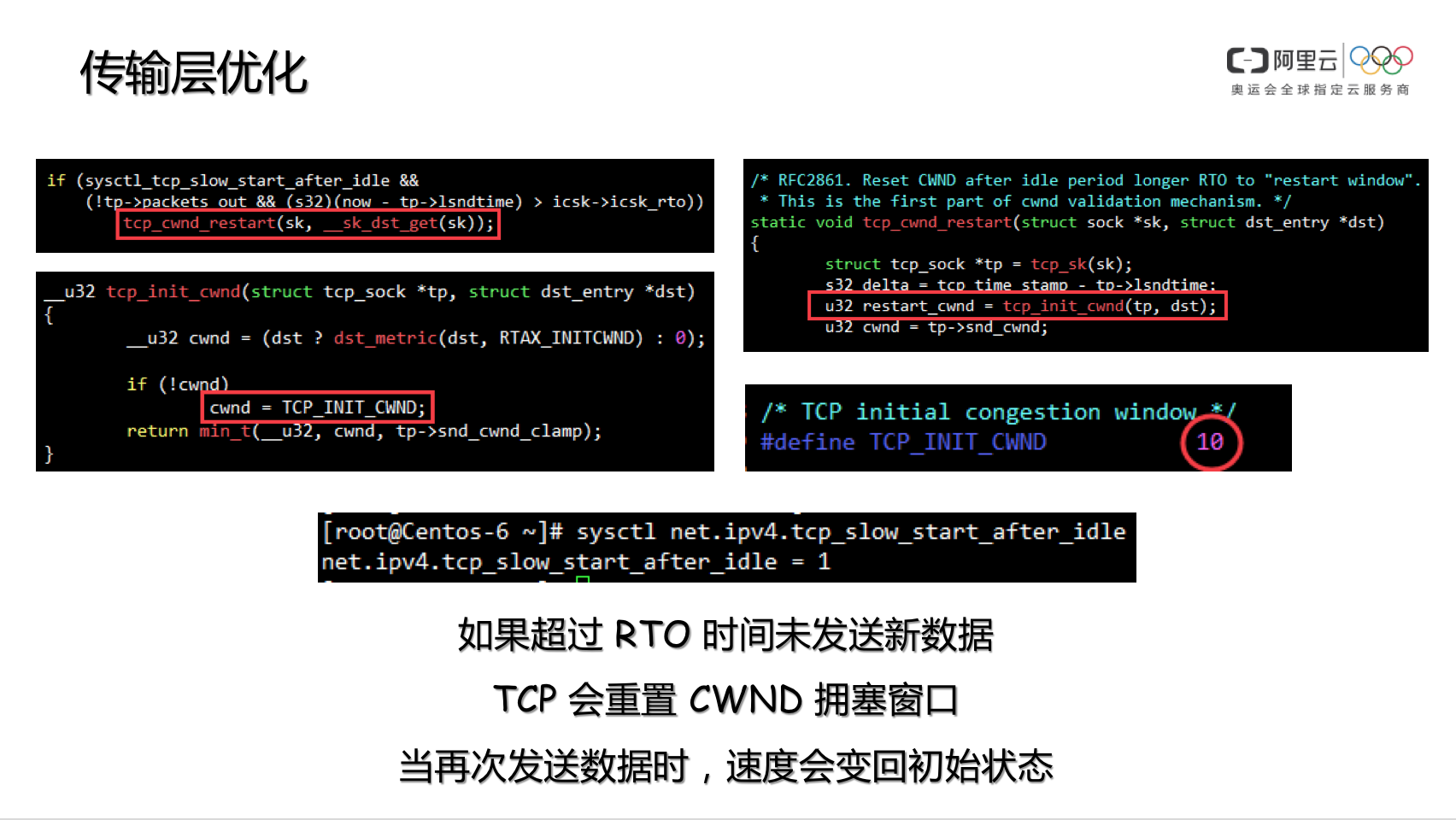
net.ipv4.tcp_slow_start_after_idle
内核协议栈参数 net.ipv4.tcp_slow_start_after_idle 默认是开启的,这个参数的用途,是为了规避 CWND 无休止增长,因此在连接不断开,但一段时间不传输数据的话,就将 CWND 收敛到 initcwnd,kernel-2.6.32 是 10,kernel-2.6.18 是 2。因此在 HTTP Connection: keep-alive 的环境下,若连续两个 GET 请求之间存在一定时间间隔,则此时服务器端会降低 CWND 到初始值,当 Client 再次发起 GET 后,服务器会重新进入慢启动流程。
RFC2414中关于拥塞窗口初始化的3个场景:
TCP implementations use slow start in as many as three different ways:
(1) to start a new connection (the initial window);
(2) to restart a transmission after a long idle period (the restart window); and
(3) to restart after a retransmit timeout (the loss window).
这种友善的保护机制,但是对于目前的网络坏境没必要这么谨慎和彬彬有礼,建议将此功能关闭,以提高长连接环境下的用户体验感。
sysctl net.ipv4.tcp_slow_start_after_idle=0
确认运行中每个连接 CWND/ssthresh(slow start threshold)
$ss -itn dst 11.163.187.32 |grep -v "Address:Port" | xargs -L 1 | grep ssthresh
ESTAB 0 0 11.163.187.33:33833 11.163.187.32:2181 cubic wscale:7,7 rto:201 rtt:0.16/0.186 ato:40 mss:1448 cwnd:10 ssthresh:7 send 724.0Mbps lastsnd:2813 lastrcv:2813 lastack:2813 pacing_rate 1445.7Mbps rcv_rtt:52081.5 rcv_space:29344
ESTAB 0 0 11.163.187.33:2376 11.163.187.32:46793 cubic wscale:7,7 rto:201 rtt:0.169/0.137 ato:40 mss:1448 cwnd:59 ssthresh:48 send 4044.1Mbps lastsnd:334 lastrcv:409 lastack:334 pacing_rate 8052.5Mbps retrans:0/759 reordering:34 rcv_rtt:50178 rcv_space:137603
ESTAB 0 0 11.163.187.33:33829 11.163.187.32:2181 cubic wscale:7,7 rto:201 rtt:0.065/0.002 ato:40 mss:1448 cwnd:10 ssthresh:7 send 1782.2Mbps lastsnd:2825 lastrcv:2825 lastack:2825 pacing_rate 3550.7Mbps rcv_rtt:51495.8 rcv_space:29344
ESTAB 0 0 11.163.187.33:33828 11.163.187.32:2181 cubic wscale:7,7 rto:201 rtt:0.113/0.061 ato:40 mss:1448 cwnd:10 ssthresh:7 send 1025.1Mbps lastsnd:2826 lastrcv:2826 lastack:2826 pacing_rate 2043.5Mbps rcv_rtt:54801.8 rcv_space:29344
ESTAB 0 0 11.163.187.33:2376 11.163.187.32:47047 cubic wscale:7,7 rto:206 rtt:5.977/9.1 ato:40 mss:1448 cwnd:10 ssthresh:51 send 19.4Mbps lastsnd:522150903 lastrcv:522150906 lastack:522150903 pacing_rate 38.8Mbps retrans:0/44 reordering:31 rcv_rtt:86067 rcv_space:321882
ESTAB 0 0 11.163.187.33:2376 11.163.187.32:46789 cubic wscale:7,7 rto:201 rtt:0.045/0.003 ato:40 mss:1448 cwnd:10 ssthresh:9 send 2574.2Mbps lastsnd:522035639 lastrcv:1589957951 lastack:522035639 pacing_rate 5077.9Mbps retrans:0/12 reordering:20 rcv_space:28960
ESTAB 0 0 11.163.187.33:33831 11.163.187.32:2181 cubic wscale:7,7 rto:201 rtt:0.071/0.01 ato:40 mss:1448 cwnd:10 ssthresh:7 send 1631.5Mbps lastsnd:2825 lastrcv:2825 lastack:2825 pacing_rate 3263.1Mbps rcv_rtt:54805.8 rcv_space:29344
从系统cache中查看 tcp_metrics item
$sudo ip tcp_metrics show | grep 100.118.58.7
100.118.58.7 age 1457674.290sec tw_ts 3195267888/5752641sec ago rtt 1000us rttvar 1000us ssthresh 361 cwnd 40 metric_5 8710 metric_6 4258
如果因为之前的网络状况等其它原因导致tcp_metrics缓存了一个非常小的ssthresh(这个值默应该非常大),ssthresh太小的话tcp的CWND指数增长阶段很快就结束,然后进入CWND+1的慢增加阶段导致整个速度感觉很慢
清除 tcp_metrics
sudo ip tcp_metrics flush all
关闭 tcp_metrics 功能
net.ipv4.tcp_no_metrics_save = 1
sudo ip tcp_metrics delete 100.118.58.7
tcp_metrics会记录下之前已关闭TCP连接的状态,包括发送端CWND和ssthresh,如果之前网络有一段时间比较差或者丢包比较严重,就会导致TCP的ssthresh降低到一个很低的值,这个值在连接结束后会被tcp_metrics cache 住,在新连接建立时,即使网络状况已经恢复,依然会继承 tcp_metrics 中cache 的一个很低的ssthresh 值,对于rt很高的网络环境,新连接经历短暂的“慢启动”后(ssthresh太小),随即进入缓慢的拥塞控制阶段(rt太高,CWND增长太慢),导致连接速度很难在短时间内上去。而后面的连接,需要很特殊的场景之下(比如,传输一个很大的文件)才能将ssthresh 再次推到一个比较高的值更新掉之前的缓存值,因此很有很能在接下来的很长一段时间,连接的速度都会处于一个很低的水平。
ssthresh 是如何降低的
在网络情况较差,并且出现连续dup ack情况下,ssthresh 会设置为 cwnd/2, cwnd 设置为当前值的一半,
如果网络持续比较差那么ssthresh 会持续降低到一个比较低的水平,并在此连接结束后被tcp_metrics 缓存下来。下次新建连接后会使用这些值,即使当前网络状况已经恢复,但是ssthresh 依然继承一个比较低的值。
ssthresh 降低后为何长时间不恢复正常
ssthresh 降低之后需要在检测到有丢包的之后才会变动,因此就需要机缘巧合才会增长到一个比较大的值。
此时需要有一个持续时间比较长的请求,在长时间进行拥塞避免之后在cwnd 加到一个比较大的值,而到一个比较
大的值之后需要有因dup ack 检测出来的丢包行为将 ssthresh 设置为 cwnd/2, 当这个连接结束后,一个
较大的ssthresh 值会被缓存下来,供下次新建连接使用。
也就是如果ssthresh 降低之后,需要传一个非常大的文件,并且网络状况超级好一直不丢包,这样能让CWND一直慢慢稳定增长,一直到CWND达到带宽的限制后出现丢包,这个时候CWND和ssthresh降到CWND的一半那么新的比较大的ssthresh值就能被缓存下来了。
tcp windows scale
网络传输速度:单位时间内(一个 RTT)发送量(再折算到每秒),不是 CWND(Congestion Window 拥塞窗口),而是 min(CWND, RWND)。除了数据发送端有个 CWND 以外,数据接收端还有个 RWND(Receive Window,接收窗口)。在带宽不是瓶颈的情况下,单连接上的速度极限为 MIN(cwnd, slide_windows)*1000ms/rt
tcp windows scale用来协商RWND的大小,它在tcp协议中占16个位,如果通讯双方有一方不支持tcp windows scale的话,TCP Windows size 最大只能到2^16 = 65535 也就是64k
如果网络rt是35ms,滑动窗口<CWND,那么单连接的传输速度最大是: 64K*1000/35=1792K(1.8M)
如果网络rt是30ms,滑动窗口>CWND的话,传输速度:CWND*1500(MTU)*1000(ms)/rt
一般通讯双方都是支持tcp windows scale的,但是如果连接中间通过了lvs,并且lvs打开了 synproxy功能的话,就会导致 tcp windows scale 无法起作用,那么传输速度就被滑动窗口限制死了(rt小的话会没那么明显)。
RTT越大,传输速度越慢
RTT大的话导致拥塞窗口爬升缓慢,慢启动过程持续越久。RTT越大、物理带宽越大、要传输的文件越大这个问题越明显
带宽B越大,RTT越大,低带宽利用率持续的时间就越久,文件传输的总时间就会越长,这是TCP慢启动的本质决定的,这是探测的代价。
TCP的拥塞窗口变化完全受ACK时间驱动(RTT),长肥管道对丢包更敏感,RTT越大越敏感,一旦有一个丢包就会将CWND减半进入避免拥塞阶段
RTT对性能的影响关键是RTT长了后丢包的概率大,一旦丢包进入拥塞阶段就很慢了。如果一直不丢包,只是RTT长,完全可以做大增加发送窗口和接收窗口来抵消RTT的增加
以上经验来自 tcp metrics 在长肥网络下引发性能问题
经典的 nagle 和 dalay ack对性能的影响
请参考这篇文章:就是要你懂 TCP– 最经典的TCP性能问题
最后的经验
抓包解千愁
就是要你懂TCP相关文章:
参考文章:
https://access.redhat.com/solutions/407743
http://www.stuartcheshire.org/papers/nagledelayedack/
https://en.wikipedia.org/wiki/Nagle%27s_algorithm
https://en.wikipedia.org/wiki/TCP_delayed_acknowledgment
https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
https://www.atatech.org/articles/109721
https://www.atatech.org/articles/109967
https://www.atatech.org/articles/27189
https://www.atatech.org/articles/45084