NIO和epoll
NIO、EPOLL和协程
从IO说起
用户线程发起IO操作后(比如读),网络数据读取过程分两步:
- 用户线程等待内核将数据从网卡拷贝到内核空间
- 内核将数据从内核空间拷贝到用户空间
同步阻塞IO
用户线程发起read后让出CPU一直阻塞直到内核把网卡数据读到内核空间,然后再拷贝到用户空间,然后唤醒用户线程
同步非阻塞IO
用户线程发起read后,不阻塞,反复尝试读取,直到内核把网卡数据读到内核空间,用户线程继续read,这时进入阻塞直到数据拷贝到用户空间
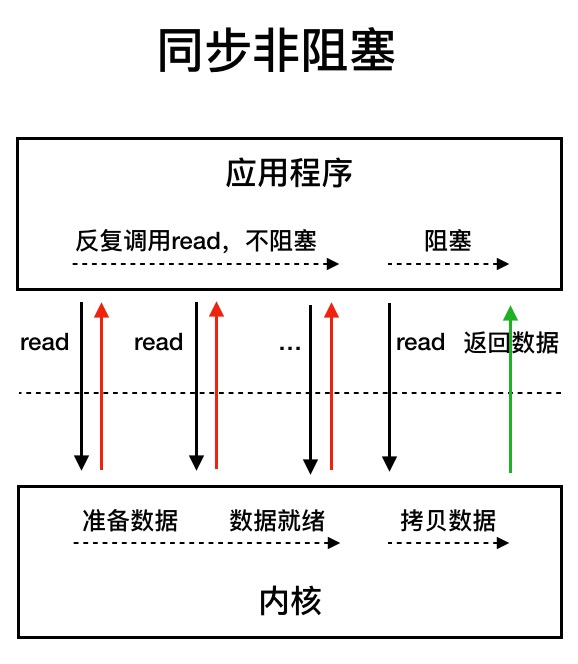
阻塞和非阻塞指的是发起IO操作后是等待还是返回,同步和异步指的是应用程序与内核通信时数据从内核空间拷贝到用户空间的操作是内核主动触发(异步)还是应用程序触发(同步)
IO多路复用、Epoll
一个进程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来看,多个请求复用了一个进程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做时分多路复用。
epoll作用:进程内同时刻找到缓冲区或者连接状态变化的所有TCP连接,主要是基于同一时刻活跃连接只在总连接中占一小部分
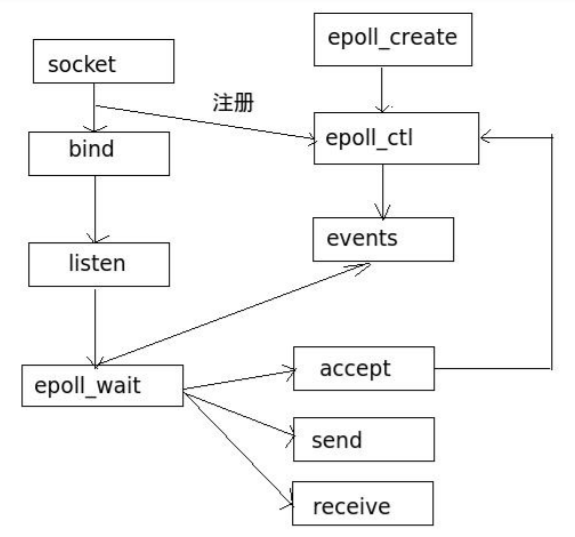
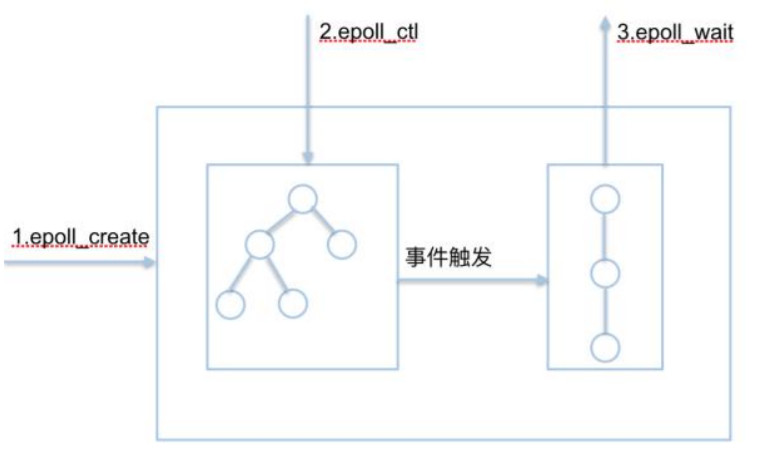
用户线程读取分成两步,用户线程先发起select调用(确认内核是否准备好数据),准备好后才调用read,将数据从内核空间读取到用户空间(read这里还是阻塞)。主要是一个select线程可以向内核查多个数据通道的状态
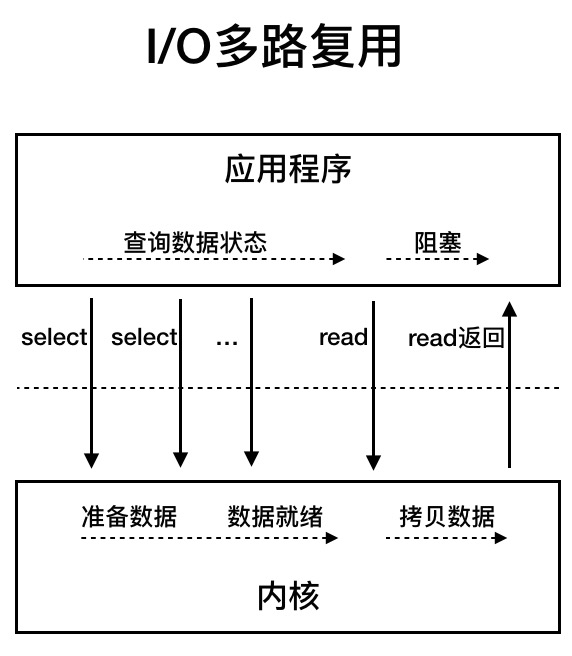
IO多路复用和同步阻塞、非阻塞的区别主要是用户线程发起read的时机不一样,IO多路复用是等数据在内核空间准备好了再通过同步read去读取;而阻塞和非阻塞因为没法预先知道数据是否在内核空间准备好,所以早早触发了read然后等待,只是阻塞会一直等,而非阻塞是指触发read后不用等,反复read直到read到数据。
Tomcat中的NIO指的是同步非阻塞,但是触发时机又是通过Java中的Selector,可以理解成通过Selector跳过了前面的阻塞和非阻塞,实际用户线程在数据Ready前没有触发read操作,数据到了才出发read操作。
阻塞IO和NIO的主要区别是:NIO面对的是Buffer,可以做到读取完毕后再一次性处理;而阻塞IO面对的是流,只能边读取边处理
多路复用 API 返回的事件并不一定可读写的,如果使用阻塞 I/O, 那么在调用 read/write 时则会发生程序阻塞,因此最好搭配非阻塞 I/O,以便应对极少数的特殊情况
epoll JStack 堆栈
像Redis采取的是一个进程绑定一个core,然后处理所有连接的所有事件,因为redis主要是内存操作,速度比较快,这样做避免了加锁,权衡下来更有利(实践上为了利用多核会部署多个redis实例;另外新版本的redis也开始支持多线程了)。但是对大多服务器就不可取了,毕竟单核处理能力是瓶颈,另外就是IO速度和CPU速度的差异非常大,所以不能采取Redis的设计。
Nginx采取的是多个Worker通过reuseport来监听同一个端口,一个Worker对应一个Epoll红黑树,上面挂着所有这个Worker负责处理的连接。默认多个worker是由OS来调度,可以通过 worker_cpu_affinity 来指定某个worker绑定到哪个core。
eg: 启动4个worker,分别绑定到CPU0~CPU3上
1 | worker_processes 4; |
or
启动2个worker;worker 1 绑定到CPU0/CPU2上;worker 2 绑定到CPU1/CPU3上
1 | worker_processes 2; |
or 自动绑定(推荐方式)
1 | worker_processes auto; |
分析worker和core的绑定关系(psr–当前进程跑在哪个core上,没有绑定就会飘来飘去,没有意义)
1 | ps -eo pid,ni,pri,pcpu,psr,comm|grep nginx|awk '{++s[$(NF-1)]}END{for (i in s)print "core-id",i,"\t",s[i]}'|sort -nr -k 3 |
而Tomcat等服务器会专门有一个(或多个)线程处理新连接IO(Accept),然后老的连接全部交给一个线程池(Reactor)来处理,这个线程池的线程数量可以根据机器CPU core数量来调整
完整的NIO中Acceptor逻辑JStack:
//3306 acceptor端口
"HTTPServer" #32 prio=5 os_prio=0 tid=0x00007fb76cde6000 nid=0x4620 runnable [0x00007fb6db5f6000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:275)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x000000070007fde0> (a sun.nio.ch.Util$3)
- locked <0x000000070007fdc8> (a java.util.Collections$UnmodifiableSet)
- locked <0x000000070002cbc8> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at com.alibaba.cobar.net.NIOAcceptor.run(NIOAcceptor.java:63)
Locked ownable synchronizers:
- None
1 | 33 public NIOAcceptor(String name, int port, FrontendConnectionFactory factory, boolean online) throws IOException{ |
创建server(Listen端口)就是创建一个NIOAcceptor,监听在特定端口上,NIOAcceptor有多个(一般和core一致) NIOProcessor 线程,一个NIOProcessor 中还可以有一个 NIOReactor
NIOAcceptor(一般只有一个,可以有多个)是一个Thread,只负责处理新建连接(建立新连接会设置这个Socket的Options,比如buffer size、keepalived等),将新建连接绑定到一个NIOProcessor(NIOProcessor数量一般和CPU Core数量一致,一个NIOProcessor对应一个NIOReactor),连接上的收发包由NIOReactor来处理。也就是一个连接(Socket)创建后就绑定到了一个固定的 NIOReactor来处理,每个NIOReactor 有一个 R线程和一个 W线程(写不走epoll的话用这个W线程按queue写出)。这个 R线程一直阻塞在selector,等待新连接或者读写事件的到来。
新连接进来后NIOAcceptor.select 阻塞解除,执行accept逻辑,accept返回一个channel(对socket封装),设置channel TCP options,将这个channel和一个 NIOProcessor绑定(一个NIOProcessor可以绑定多个channel,反之一个channel只能绑定到一个NIOProcessor),同时将这个channel插入(offer)到NIOProcessor里面的NIOReactor的队列中,并唤醒NIOReactor的selector,将新连接注册到 NIOReactor的selector中(进行连接的mysql协议认证)。然后阻塞在这个selector等待事件中,等待读写事件的到来
也就是只有Acceptor阶段会有惊群(但是上面的代码只有一个Acceptor,所以也没有惊群了),收发数据阶段因为Socket已经绑定到了一个固定的Thread,所以不会有惊群了,但是可能会存在某个Thread有慢处理导致新进来的请求长时间得不到响应。
Select 触发 read/write 堆栈:
"Processor2-R" #26 prio=5 os_prio=0 tid=0x00007fb76cc9a000 nid=0x4611 runnable [0x00007fb6dbdfc000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:275)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
- locked <0x000000070006e090> (a sun.nio.ch.Util$3)
- locked <0x000000070006cd68> (a java.util.Collections$UnmodifiableSet)
- locked <0x00000007000509e0> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at com.alibaba.cobar.net.NIOReactor$R.run(NIOReactor.java:88)
at java.lang.Thread.run(Thread.java:852)
NIOReactor.java:
1 | 82 |
Socket是一个阻塞的IO,一个Socket需要一个Thread来读写;SocketChannel对Socket进行封装,是一个NIO的Socket超集,一个Select线程就能处理所有的SocketChannel(也就是所有的Socket)
Java的Netty框架和 Corba的NIOProcessor 就是基于java的NIO库,用的(多)selector形式
NIO 多路复用Java example
1 | public class SelectorNIO { |
Channel
Channel 类位于 java.nio.channels 包中,但并不是 Channel 仅仅支持 NIO,其分为两种类型:
- FileChannel:完全不支持 NIO;
- SocketChannel/ServerSocketChannel 等 Channel 默认情况下并不支持 NIO,只有显式地调用配置方法才能够进入非阻塞模式(
ServerSocketChannel.configBlocking(false))。
下面主要以 SocketChannel 的角度来介绍 Channel 类。
Channel 我们可以理解为对应于 BIO 中的 Socket,也可以理解为 Scoket.inputStream/SocketOutputStream。如果认为是流,那么我们做一个比较:
- 传统 Socket:我们调用 Socket 的
getInputStream()以及getOutputStream()进行数据的读和写。 - Channel:我们不再需要得到输入输出流进行读和写,而是通过 Channel 的
read()以及write()方法进行读和写。
Channel 如此实现也付出了代价(如下图所示):
- 读写模式需要调用
flip()方法进行切换,读模式下调用write()试图进行写操作会报错。 - 读写不再能够接受一个简单的字节数组,而是必须是封装了字节数组的 Buffer 类型。
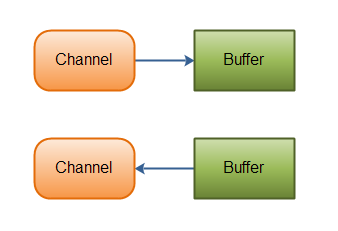
目前已知 Channel 的实现类有:
FileChannel 一个用来写、读、映射和操作文件的通道。
DatagramChannel
SocketChannel
SocketChannel 可以看做是具有非阻塞模式的 Socket。其可以运行在阻塞模式,也可以运行在非阻塞模式。其只能依靠 ByteBuffer 进行读写,而且是尽力读写,尽力的含义是:
- ByteBuffer 满了就不能再读了;
- 即使此次 Socket 流没有传输完毕,但是一旦 Channel 中的数据读完了,那么就返回了,这就是非阻塞读。所以读的方法有 -1(EOF),0(Channel 中的数据读完了,但是整个数据流本身没有消耗完),其他整数,此次读的数据(因为 ByteBuffer 并不是每次都是空的,原来就有数据时只能够尽力装满)。
ServerSocketChannel 这个类似于 ServerSocket 起到的作用。
一个比喻比较他们的不同
打个不是极其恰当的比方:假如你去餐馆吃饭,厨师(内核)给你准备饭菜(数据)
- 阻塞IO:老板,饭好了吗?于是你傻傻在窗口等着。等着厨师把饭做好给你。干等着,不能玩手机。
- 非阻塞IO:老板,饭好了吗?没好?那我玩手机。哈哈,刷个微博。十分钟过去了,你又去问,饭好了吗?还没好,那我再斗个地主吧。过了一会儿,你又去问。。。。等饭的过程中可以玩手机,不过你得时不时去问一下好了没。
- IO多路复用:你们一帮人一口气点了十几个菜,其他人坐着该做啥做啥,派一个人等着厨房的通知。。。问厨师,这么多个菜,有哪几个菜好了呢?厨师告诉你A、C、E好了,你可以取了;又过了一会儿,你去问厨师,有哪些菜好了呢?厨师告诉你D、F好了,可以取了。。。
- 异步IO:老板,饭好了麻烦通知我一下。我去看电视,不用再去问饭好了没有了,饭好厨师会给你的。等饭的过程中当然可以玩手机。完全托管的机制。
- 同步:端菜上桌过程必须是阻塞,异步相当于厨师将菜送到桌子上后通知你吃
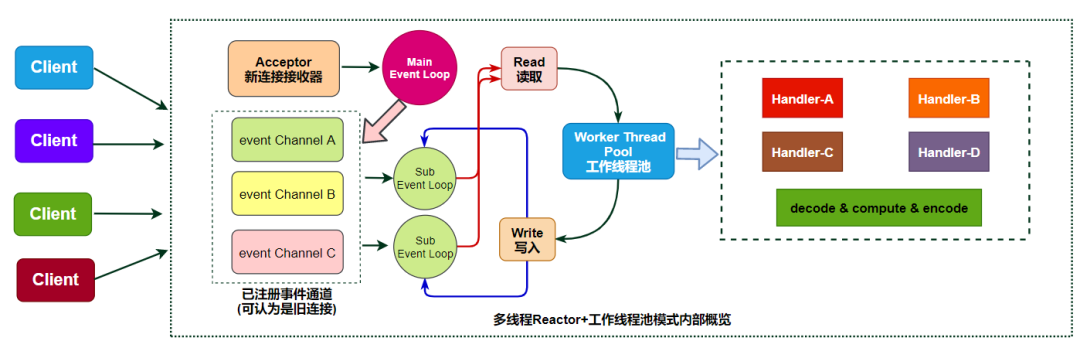
Tomcat中的NIO+多路复用的实现
NIOEndpoint组件实现了NIO和IO多路复用,IO多路复用指的是Poller通过Selector处理多个Socket(SocketChannel)
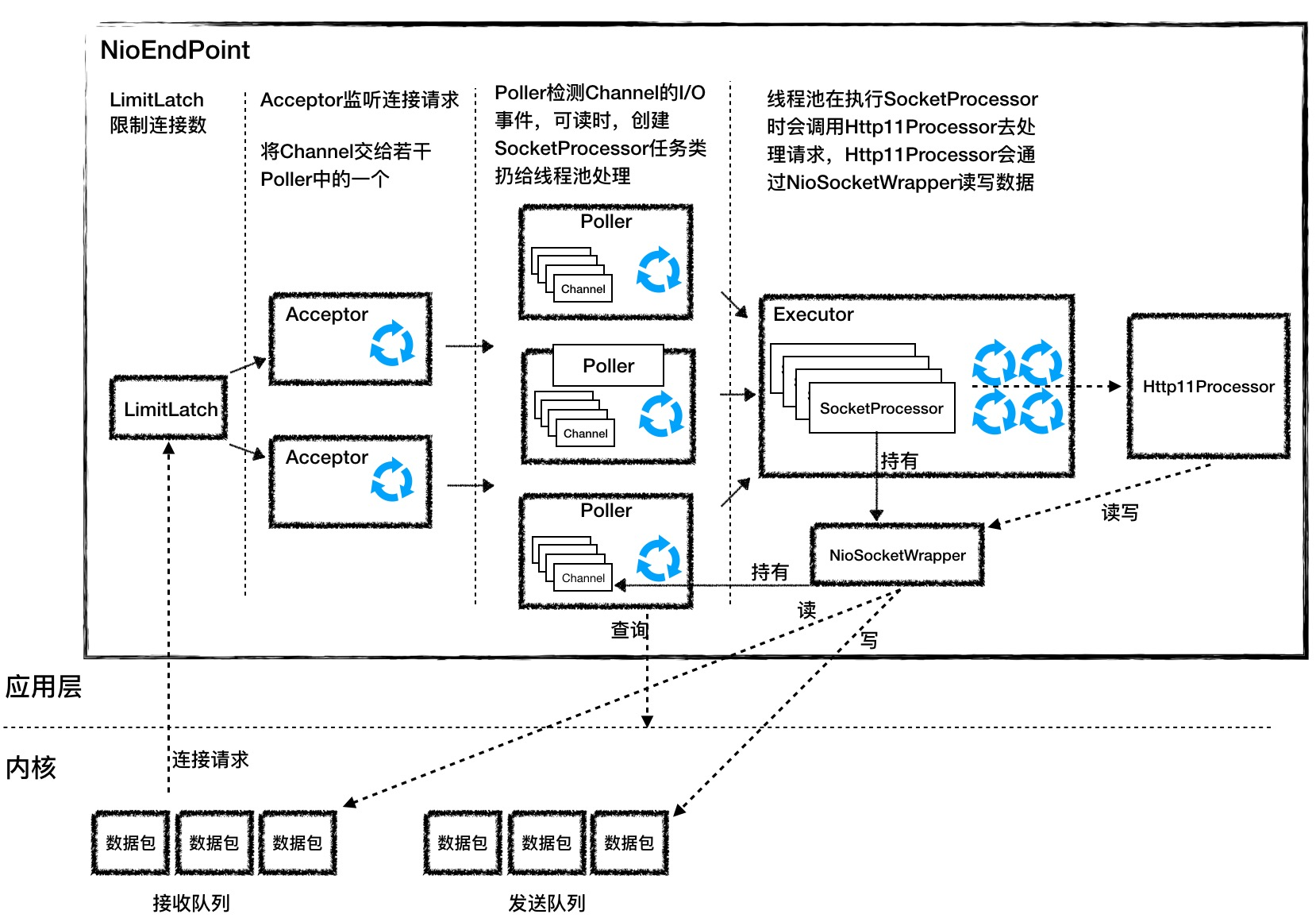
- LimitLatch 是连接控制器,负责控制最大连接数,NIO模式下默认是10000,达到阈值后新连接被拒绝
- Acceptor 跑在一个单独的线程里,一旦有新连接进来accept方法返回一个SocketChannel对象,接着把SocketChannel对象封装在一个PollerEvent对象中,并将PollerEvent对象压入Poller的Queue里交给Poller处理。 Acceptor和Poller之间是典型的生产者-消费者模式
- Poller的本质是一个Selector,内部维护一个Channel数组,通过一个死循环不断地检测Channel中的数据是否就绪,一旦就绪就生成一个 SocketProcessor任务对象扔给 Executor处理。同时Poller还会循环遍历自己所管理的SocketChannel是否已经超时,如果超时就关闭这个SocketChannel
- Executor是线程池,主要处理具体业务逻辑,Poller主要处理读取Socket数据逻辑。Executor主要负责执行 SocketProcessor对象中的run方法,SocketProcessor对象的run方法用 Http11Processor来读取和解析请求数据。
- Http11Processor是应用层协议的封装,他会调用容器获得请求(ServletRequest),再将响应通过Channel写出给请求
因为Tomcat支持同步非阻塞IO模型和异步IO模型,所以Http11Processor不是直接读取Channel。针对不同的IO模型在Java API中对Channel有不同的实现,比如:AsynchronousSocketChannel 和 SocketChannel,为了对 Http11Processor屏蔽这些差异,Tomcat设计了一个包装类SocketWrapper,Http11Processor只需要调用SocketWrapper的读写方法
Tomcat核心参数
- acceptorThreadCount: Acceptor线程数量,多核情况下充分利用多核来应对大量连接的创建,默认值是1
- acceptCount: TCP全连接队列大小,默认值是100,这个值是交给内核,由内核来维护这个队列的大小,满了后Tomcat无感知
- maxConnections: NIO模式默认10000,最大同时处理的连接数量。如果是BIO,一个connections需要一个thread来处理,不应设置太大。
- maxThreads: 专门处理IO操作的Worker线程数量,默认值是200
Acceptor
Acceptor实现了Runnable接口,可以跑在单线程里,一个Listen Port只能对应一个ServerSocketChannel,因此这个ServerSocketChannel是在多个Acceptor线程之间共享
serverSock = ServerSocketChannel.open();
serverSock.socket().bind(addr,getAcceptCount());
serverSock.configureBlocking(true);
- bind方法的第二个参数是操作系统的等待队列长度,也就是TCP的全连接队列长度,对应着Tomcat的 acceptCount 参数配置,默认是100
- ServerSocketChannel被设置成阻塞模式,也就是连接创建的时候是阻塞的方式。
多路复用–多个socket共用同一个线程来读取socket中的数据
多路复用可以是对accept,也可以是read,一般而言对于accept一个listen port就是一个线程,但是对于read,如果是高并发情况下,一个线程来读取N多socket肯定性能不够好,同时也没用利用上物理上的多核,所以一般是core+1或者2*core数量的线程来读取N多socket,因为有些read还做一些其它逻辑所以会设置的比core数量略微多些。
正常一个连接一个线程(tomcat的BIO模型),导致的问题连接过多的话线程也过多,而大部分连接都是空闲的。如果活跃连接数比较多的话,导致CPU主要用在了线程调度、切换以及过高的内存消耗上(C10K)。而对于NIO即使活跃连接数非常多,但是实际处理他们的线程也就几个(一般设置跟core数差不多),所以也不会有太高的上下文切换(参考后面阐述的协程的原理)。
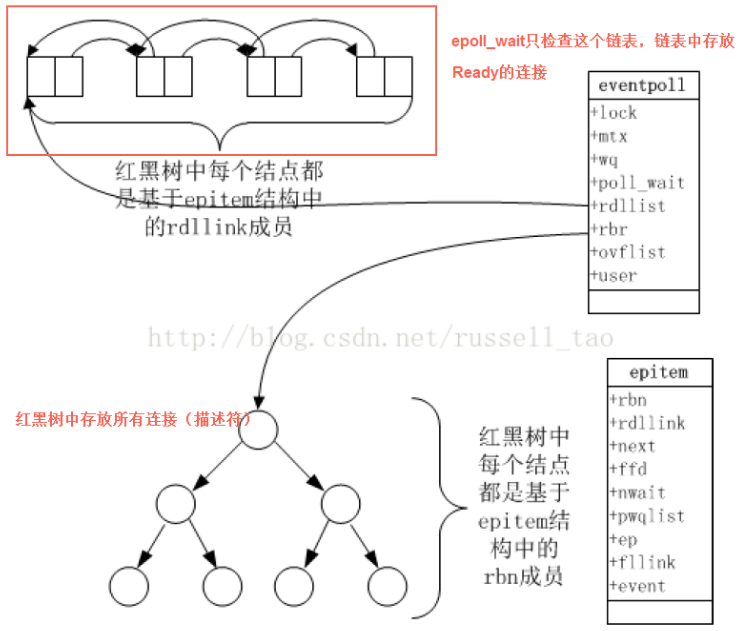
Select和epoll本质是为了IO多路复用(多个连接共用一个线程–监听是否连接有数据到达)。有报文进来的时候触发Select,Select轮询所有连接确认是哪个连接有报文进来了。连接过多放大了这种无用轮询。
epoll通过一颗红黑树维护所有连接,同时将有数据进来的连接通过回调更新到一个队列中,那么epoll每次检查的时候只需要检查队列而不是整个红黑树,效率大大提高了。
事件驱动适合于I/O密集型服务,多进程或线程适合于CPU密集型服务
多路复用有很多种实现,在linux上,2.4内核前主要是select和poll,现在主流是epoll
select解决了一个线程监听多个socket的问题,但是因为依靠fd_set结构体记录所监控的socket,带来了能监听的socket数量有限(不超过1024)
poll在select的基础上解决了1024个的问题,但是还是要依次轮询这1024个socket,效率太低
epoll 异步非阻塞多路复用
闲置线程或进程不会导致系统上下文切换过高(但是每个线程都会消耗内存)。只有ready状态过多时上下文切换才不堪重负。对于CPU连说调度10M的线程、进程不现实,这个时候适合用协程
netty自带telnet server的example中,一个boss epoll负责listen新连接,新连接分配给多个worker epoll(worker则使用默认的CPU数*2.),每个连接之后的读写都由固定的一个worker来处理
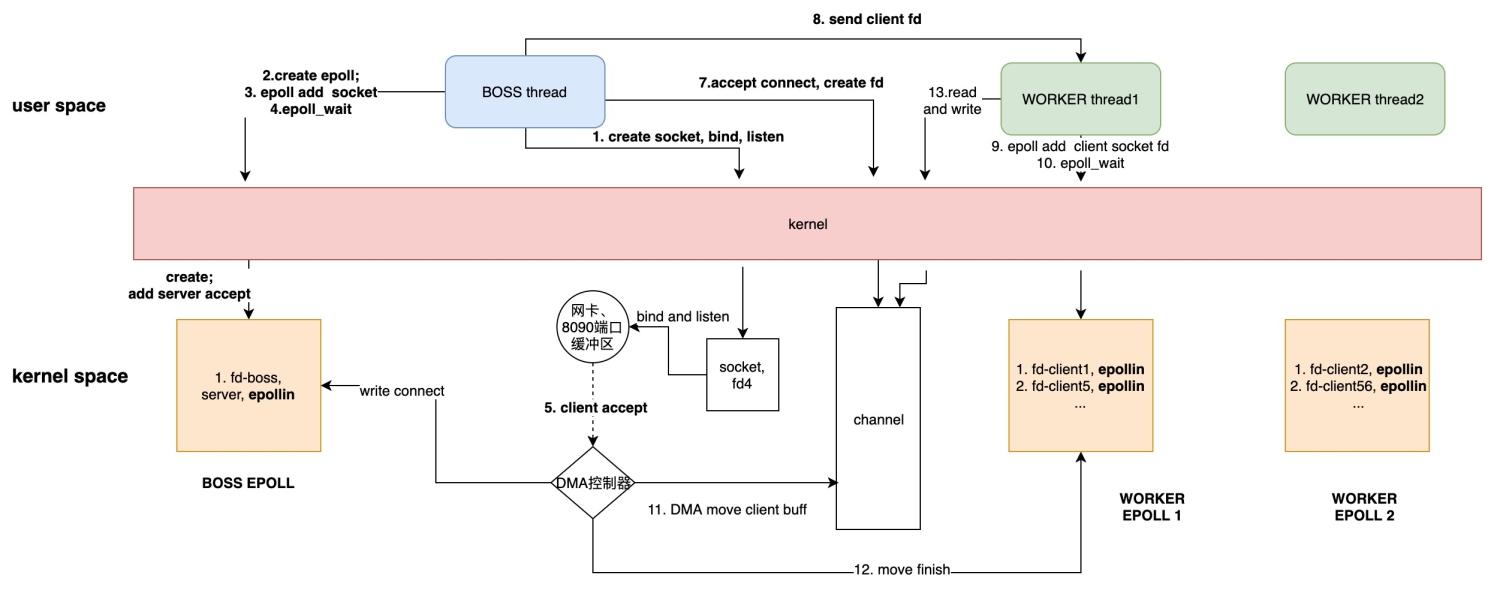
以上netty结构中:
BOSS负责accept连接(通过BOSS监听的channel的read事件),然后实例化新连接的channel
将该channel绑定到worker线程组下的某个eventloop上,后续所有该channel的事件、任务 均有该eventloop执行。这是单个channel无锁的关键
BOSS 提交Channel.regist任务到worker线程组,之后BOSS任务结束,转入继续listen
协程
协程是一种轻量级的,用户态的执行单元。相比线程,它占用的内存非常少,在很多实现中(比如 Go 语言)甚至可以做到按需分配栈空间。
它主要有三个特点:
- 占用的资源更少 ;
- 所有的切换和调度都发生在用户态;
- 它的调度是协商式的,而不是抢占式的。
协程的全部精神就在于控制流的主动让出和恢复,工程实现得考虑如何让协程的让出与恢复高效。一般在协程中调用 yield_to 来主动把执行权从本协程让给另外一个协程。yield_to 机器码:
1 | 000000000040076d <_Z8yield_toP9coroutineS0_>: |
yield_to 中,参数 old_co 指向老协程,co 则指向新的协程,也就是我们要切换过去执行的目标协程。
这段代码的作用是,首先,把当前 rsp 寄存器的值存储到 old_co 的 stack_pointer 属性(第 9 行),并且把新的协程的 stack_pointer 属性更新到 rsp 寄存器(第 10 行),然后,retq 指令将会从栈上取出调用者的地址,并跳转回调用者继续执行(第 12 行)。
当调用这一次 yield_to 时,rsp 寄存器刚好就会指向新的协程 co 的栈,接着就会执行”pop rbp”和”retq”这两条指令。这里你需要注意一下,栈的切换,并没有改变指令的执行顺序,因为栈指针存储在 rsp 寄存器中,当前执行到的指令存储在 IP 寄存器中,rsp 的切换并不会导致 IP 寄存器发生变化。
这个协程切换过程并没有使用任何操作系统的系统调用,就实现了控制流的转移。也就是说,在同一个线程中,我们真正实现了两个执行单元。这两个执行单元并不像线程那样是抢占式地运行,而是相互主动协作式执行,所以,这样的执行单元就是协程。我们可以看到,协程的切换全靠本执行单元主动调用 yield_to 来把执行权让渡给其他协程。
每个协程都拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方(上述例子中,保存在 coroutine 对象中),在切回来的时候,恢复先前保存的寄存器上下文和栈。
多进程和多线程优劣的比较
把进程看做是资源分配的单位,把线程才看成一个具体的执行实体。
进程间内存难以共享,多线程可以共享内存;多进程内核管理成本高。
每个线程消耗内存过多, 比如,64 位的 Linux 为每个线程的栈分配了 8MB 的内存,还预分配了 64MB 的内存作为堆内存池;切换请求是内核通过切换线程实现的,什么时候会切换线程呢?不只时间片用尽,当调用阻塞方法时,内核为了让 CPU 充分工作,也会切换到其他线程执行。一次上下文切换的成本在几十纳秒到几微秒间,当线程繁忙且数量众多时,这些切换会消耗绝大部分的 CPU 运算能力。
协程把内核态的切换工作交由用户态来完成.
目前主流语言基本上都选择了多线程作为并发设施,与线程相关的概念是抢占式多任务(Preemptive multitasking),而与协程相关的是协作式多任务。不管是进程还是线程,每次阻塞、切换都需要陷入系统调用 (system call),先让 CPU 执行操作系统的调度程序,然后再由调度程序决定该哪一个进程 (线程) 继续执行。
由于抢占式调度执行顺序无法确定,我们使用线程时需要非常小心地处理同步问题,而协程完全不存在这个问题。因为协作式的任务调度,是要用户自己来负责任务的让出的。如果一个任务不主动让出,其他任务就不会得到调度。这是协程的一个弱点,但是如果使用得当,这其实是一个可以变得很强大的优点。
同步、异步、协程的比较
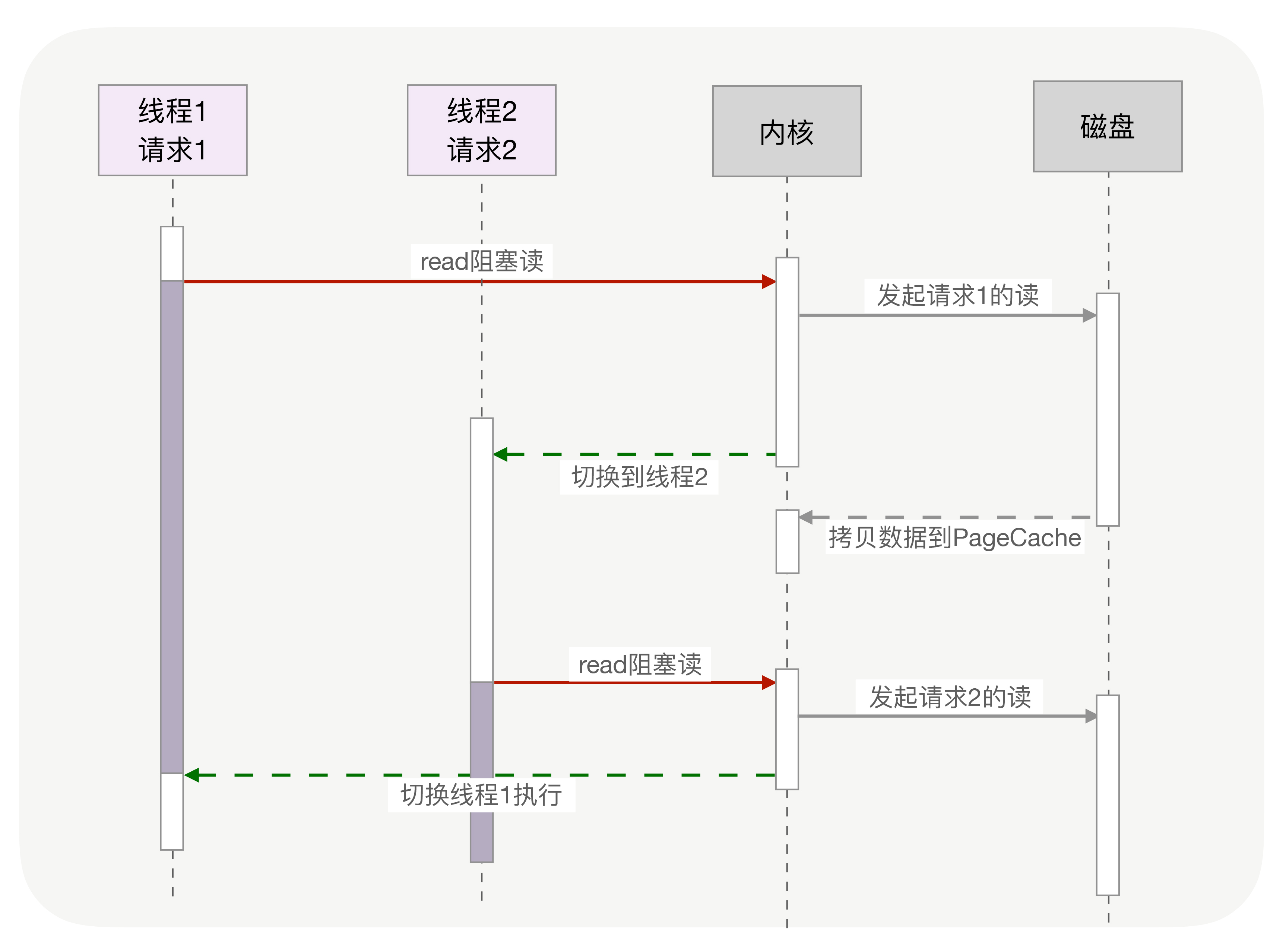
同步调用
切换请求是内核通过切换线程实现的,什么时候会切换线程呢?不只时间片用尽,当调用阻塞方法时,内核为了让 CPU 充分工作,也会切换到其他线程执行。一次上下文切换的成本在几十纳秒到几微秒间,当线程繁忙且数量众多时,这些切换会消耗绝大部分的 CPU 运算能力。
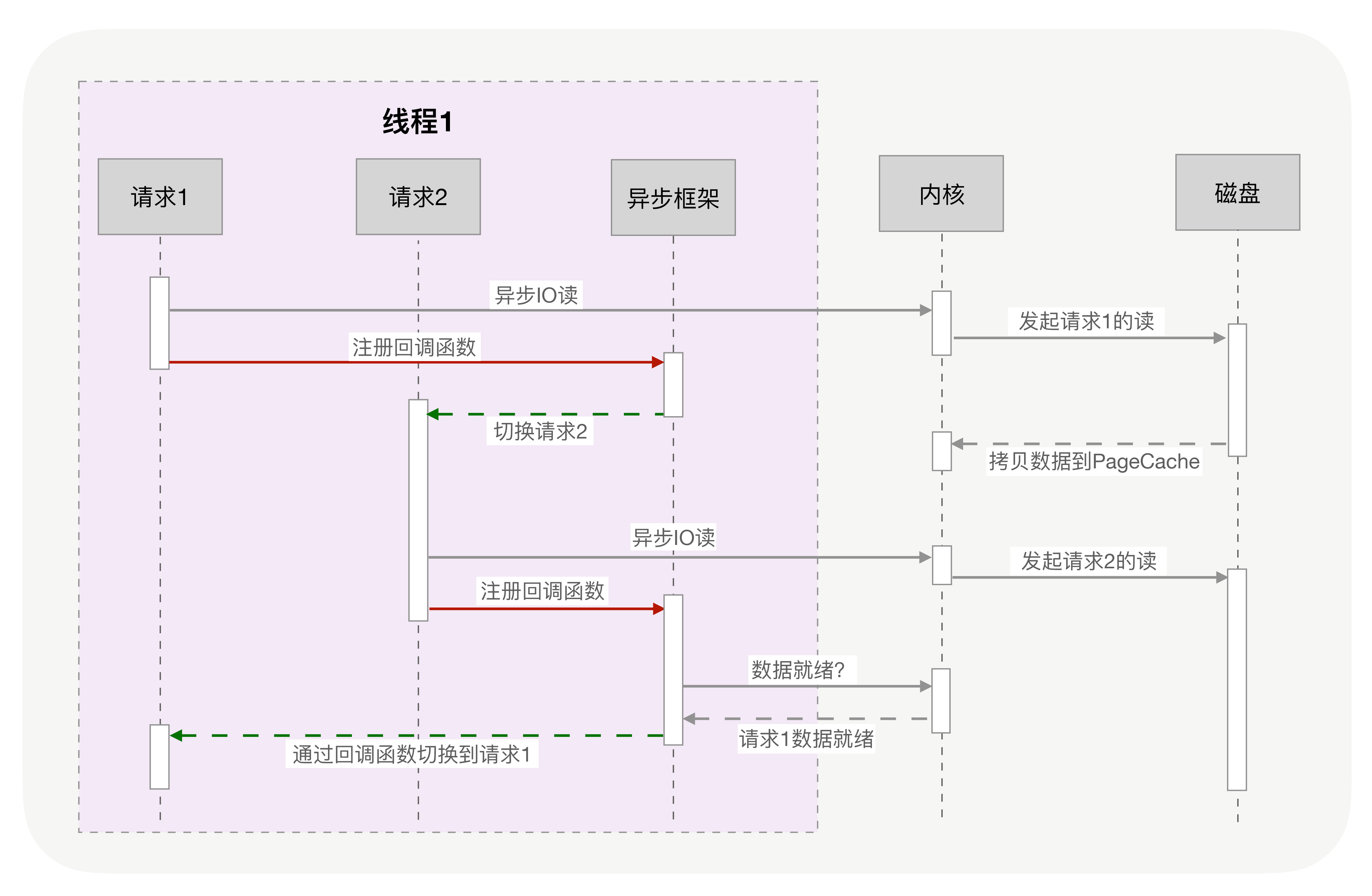
改成异步化后:
把上图中本来由内核实现的请求切换工作,交由用户态的代码来完成就可以了,异步化编程通过应用层代码实现了请求切换,降低了切换成本和内存占用空间。异步化依赖于 IO 多路复用机制,比如 Linux 的 epoll 或者 Windows 上的 iocp,同时,必须把阻塞方法更改为非阻塞方法,才能避免内核切换带来的巨大消耗。Nginx、Redis 等高性能服务都依赖异步化实现了百万量级的并发。
然而,写异步化代码很容易出错。因为所有阻塞函数,都需要通过非阻塞的系统调用拆分成两个函数。虽然这两个函数共同完成一个功能,但调用方式却不同。第一个函数由你显式调用,第二个函数则由多路复用机制调用。这种方式违反了软件工程的内聚性原则,函数间同步数据也更复杂。特别是条件分支众多、涉及大量系统调用时,异步化的改造工作会非常困难。
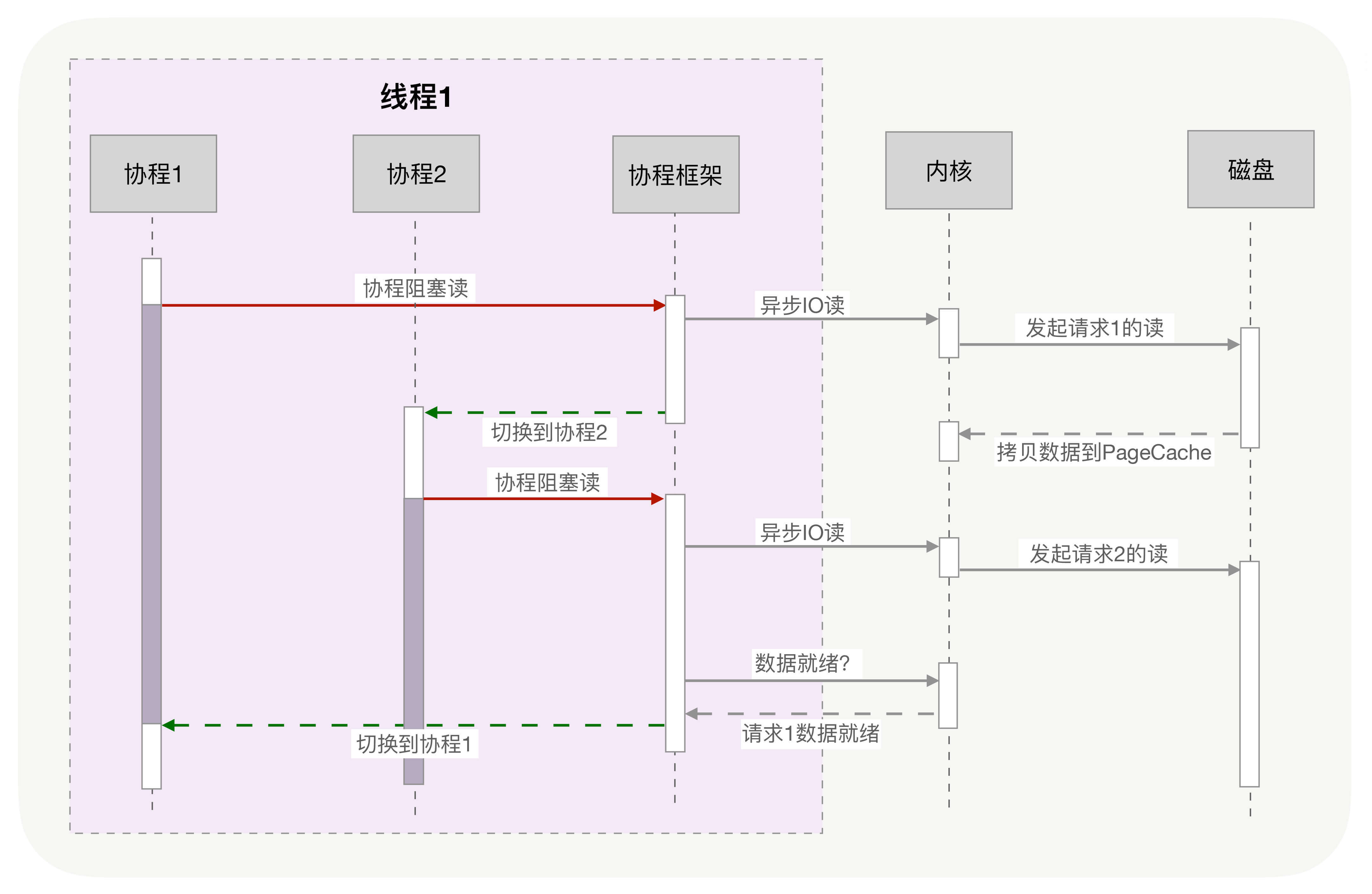
用协程来实现
协程与异步编程相似的地方在于,它们必须使用非阻塞的系统调用与内核交互,把切换请求的权力牢牢掌握在用户态的代码中。但不同的地方在于,协程把异步化中的两段函数,封装为一个阻塞的协程函数。这个函数执行时,会使调用它的协程无感知地放弃执行权,由协程框架切换到其他就绪的协程继续执行。当这个函数的结果满足后,协程框架再选择合适的时机,切换回它所在的协程继续执行。
实际上,用户态的代码切换协程,与内核切换线程的原理是一样的。内核通过管理 CPU 的寄存器来切换线程,我们以最重要的栈寄存器和指令寄存器为例,看看协程切换时如何切换程序指令与内存。
每个线程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU 中的栈寄存器 SP 指向了当前线程的栈,而指令寄存器 IP 保存着下一条要执行的指令地址。因此,从线程 1 切换到线程 2 时,首先要把 SP、IP 寄存器的值为线程 1 保存下来,再从内存中找出线程 2 上一次切换前保存好的寄存器值,写入 CPU 的寄存器,这样就完成了线程切换。(其他寄存器也需要管理、替换,原理与此相同,不再赘述。)
协程的切换
协程的切换与此相同,只是把内核的工作转移到协程框架实现而已,下图是协程切换前的状态:
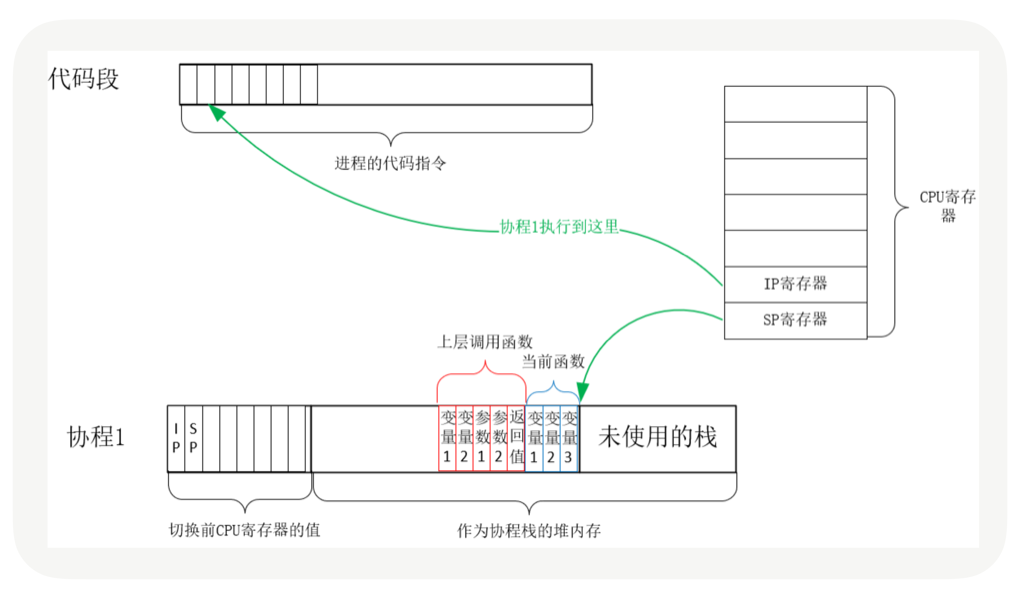
从协程 1 切换到协程 2 后的状态如下图所示:
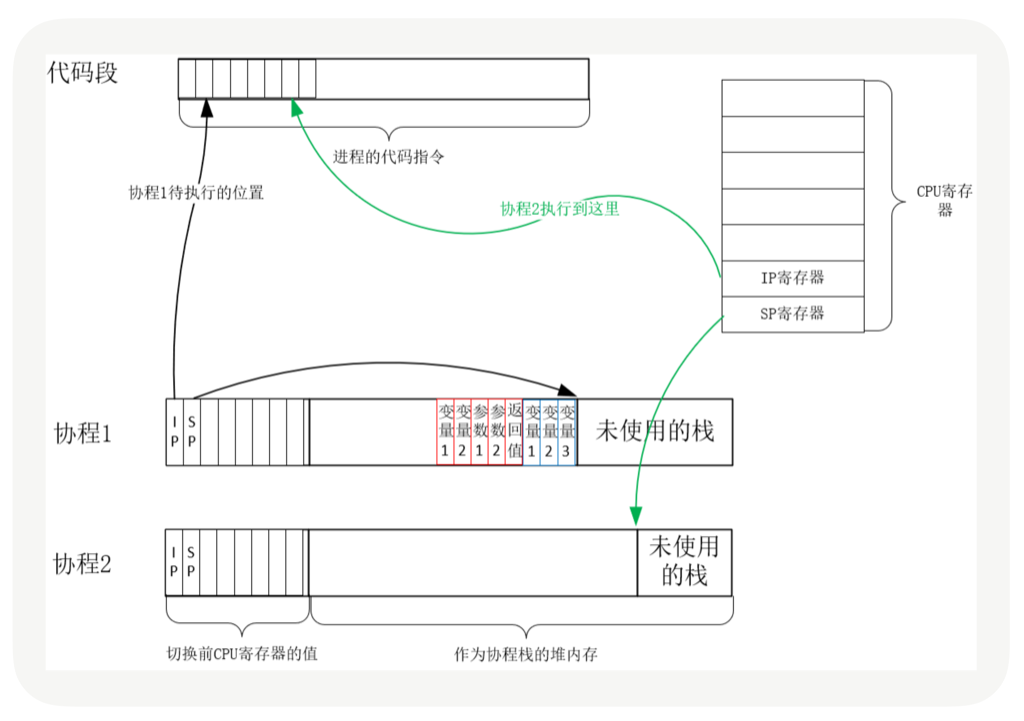
协程就是用户态的线程。然而,为了保证所有切换都在用户态进行,协程必须重新封装所有的阻塞系统调用,否则,一旦协程触发了线程切换,会导致这个线程进入休眠状态,进而其上的所有协程都得不到执行。比如,普通的 sleep 函数会让当前线程休眠,由内核来唤醒线程,而协程化改造后,sleep 只会让当前协程休眠,由协程框架在指定时间后唤醒协程。再比如,线程间的互斥锁是使用信号量实现的,而信号量也会导致线程休眠,协程化改造互斥锁后,同样由框架来协调、同步各协程的执行。
非阻塞+epoll+同步编程 = 协程
协程主要是将IO Wait等场景自动识别然后以非常小的代价切换到其它任务处理,一旦Wait完毕再切换回来。
协程在实现上都是试图用一组少量的线程来实现多个任务,一旦某个任务阻塞,则可能用同一线程继续运行其他任务,避免大量上下文的切换。每个协程所独占的系统资源往往只有栈部分。而且,各个协程之间的切换,往往是用户通过代码来显式指定的(跟各种 callback 类似),不需要内核参与,可以很方便的实现异步。
这个技术本质上也是异步非阻塞技术,它是将事件回调进行了包装,让程序员看不到里面的事件循环。程序员就像写阻塞代码一样简单。比如调用 client->recv() 等待接收数据时,就像阻塞代码一样写。实际上是底层库在执行recv时悄悄保存了一个状态,比如代码行数,局部变量的值。然后就跳回到EventLoop中了。什么时候真的数据到来时,它再把刚才保存的代码行数,局部变量值取出来,又开始继续执行。
协程是异步非阻塞的另外一种展现形式。Golang,Erlang,Lua协程都是这个模型。
协程的优点是它比系统线程开销小,缺点是如果其中一个协程中有密集计算,其他的协程就不运行了。操作系统进程、线程切换的缺点是开销大,优点是无论代码怎么写,所有进程都可以并发运行。
协程也叫做用户态进程/用户态线程。区别就在于进程/线程是操作系统充当了EventLoop调度,而协程是自己用Epoll进行调度。
Erlang解决了协程密集计算的问题,它基于自行开发VM,并不执行机器码。即使存在密集计算的场景,VM发现某个协程执行时间过长,也可以进行中止切换。Golang由于是直接执行机器码的,所以无法解决此问题。所以Golang要求用户必须在密集计算的代码中,自行Yield。
操作系统调用不知道内部具体实现,代价包含:上下文切换(几百个指令?)、PageCache
语言自己调度(协程)一般是执行完,基于栈的切换只需要保存栈指针;一定是在同一个线程/进程内切换,各种Cache还有效。
多线程下的真正开销代价
系统调用开销其实不大,上下文切换同样也是数十条cpu指令可以完成
多线程调度下的热点火焰图:

多线程下真正的开销来源于线程阻塞唤醒调度,系统调用和上下文切换伴随着多线程,所以导致大家一直认为系统调用和上下文切换过多导致了多线程慢。
以ajdk的Wisp2协程为例
对于很快的锁,Wisp2可以很好地解决,因为任务切换不频繁,最多也就CPU核数量的任务在切换,拿到锁的协程会很快执行完然后释放锁,所以其他协程再执行的时候容易拿到锁。
但是对于像logback日志同步输出doAppend()的锁(比较慢,并发度高)Wisp2就基本无能为力了。
Wisp2的主线程跟CPU数量一致,Wisp1的时候碰到CPU执行很长的任务就容易卡主,Wisp2解决了这个问题,超过一定时间会让出这个协程。如果主线程比较闲的时候会尝试从其它主线程 steal 协程(任务)过来, steal的时候需要加锁(自旋锁)来尝试steal成功。如果碰到其他主线程也在steal就可能会失败,steal尝试几次加锁不成功(A线程尝试steal B线程的协程-任务,会尝试锁住A和B,但是比如C线程也在偷的话可能会导致A偷取失败)就放弃。
Wisp2碰到执行时间比较长的任务的话,有个线程会过一段时间去监控,如果超过100ms,就触发一个safepoint,触发抢占。
Node.js
Node.js:基于事件的异步非阻塞框架,基于V8,上层跑JavaScript应用。默认只有一个eventLoop导致也只能用一个核。
Node.js 只有一个 EventLoop,也就是只占用一个 CPU 内核,当 Node.js 被CPU 密集型任务占用,导致其他任务被阻塞时,却还有 CPU 内核处于闲置状态,造成资源浪费。
比喻
关于JAVA的网络,之前有个比喻形式的总结,分享给大家:
有一个养鸡的农场,里面养着来自各个农户(Thread)的鸡(Socket),每家农户都在农场中建立了自己的鸡舍(SocketChannel)
- 1、BIO:Block IO,每个农户盯着自己的鸡舍,一旦有鸡下蛋,就去做捡蛋处理;
- 2、NIO:No-Block IO-单Selector,农户们花钱请了一个饲养员(Selector),并告诉饲养员(register)如果哪家的鸡有任何情况(下蛋)均要向这家农户报告(select keys);
- 3、NIO:No-Block IO-多Selector,当农场中的鸡舍逐渐增多时,一个饲养员巡视(轮询)一次所需时间就会不断地加长,这样农户知道自己家的鸡有下蛋的情况就会发生较大的延迟。怎么解决呢?没错,多请几个饲养员(多Selector),每个饲养员分配管理鸡舍,这样就可以减轻一个饲养员的工作量,同时农户们可以更快的知晓自己家的鸡是否下蛋了;
- 4、Epoll模式:如果采用Epoll方式,农场问题应该如何改进呢?其实就是饲养员不需要再巡视鸡舍,而是听到哪间鸡舍的鸡打鸣了(活跃连接),就知道哪家农户的鸡下蛋了;
- 5、AIO:Asynchronous I/O, 鸡下蛋后,以前的NIO方式要求饲养员通知农户去取蛋,AIO模式出现以后,事情变得更加简单了,取蛋工作由饲养员自己负责,然后取完后,直接通知农户来拿即可,而不需要农户自己到鸡舍去取蛋。