epoll和惊群
epoll和惊群
本文尝试追踪不同的内核版本增加的方案来看内核是如何来尝试解决惊群问题的。以及像 SO_REUSEPORT 和EPOLLEXCLUSIVE又带来了什么小问题。
什么是惊群
惊群效应也有人叫做雷鸣群体效应,惊群就是多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(或者线程),但是最终却只可能有一个进程(线程)获得这个事件的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群。
惊群的本质在于多个线程处理同一个事件。
为了更好的理解何为惊群,举一个很简单的例子,当你往一群鸽子中间扔一粒谷子,所有的鸽子都被惊动前来抢夺这粒食物,但是最终只有一只鸽子抢到食物。这里鸽子表示进程(线程),那粒谷子就是等待处理的事件。
linux 内核通过睡眠队列来组织所有等待某个事件的 task,而 wakeup 机制则可以异步唤醒整个睡眠队列上的 task,wakeup 逻辑在唤醒睡眠队列时,会遍历该队列链表上的每一个节点,调用每一个节点的 callback,从而唤醒睡眠队列上的每个 task,为什么要欢行所有的task,关键在于内核不知道这个消息是一个task处理就够了还是从逻辑上这些wakeup的所有task都要处理,所以只能全部唤醒。这样,在一个 connect 到达这个 lisent socket 的时候,内核会唤醒所有睡眠在 accept 队列上的 task。N 个 task 进程(线程)同时从 accept 返回,但是,只有一个 task 返回这个 connect 的 fd,其他 task 都返回-1(EAGAIN)。这是典型的 accept”惊群”现象。
如果一个连接的请求需要通知多个线程,就容易出现惊群。比如accept,一般都是一个线程负责accept新连接然后分发,这样不会有惊群,但是如果一个线程成为瓶颈那么就要安排多个线程来accept,当有新连接进来默认只能通知所有线程都来处理,这就是惊群。如果用reuseport来用多个线程监听同一个端口的话,在内核层面会通过hash将新连接派发给一个具体的worker这样也不会有惊群了。
连接建立后,一般的处理逻辑就是将连接一对一挂到一个epoll 红黑树上,一般会有多个epoll 红黑树,然后每个epoll都由一个固定的线程来处理上面的消息,这种是不会有惊群的。也是典型的server处理模式(nginx、tomcat、netty都是如此)
关键点:多个进程监听相同事件(或者说一个epoll有多个进程来处理)
先上总结
如果服务器采用accept阻塞调用方式群在2.6内核就通过增加WQ_FLAG_EXCLUSIVE在内核中就行排他解决惊群了;
只有epoll的accept才有惊群,这是因为epoll监听句柄中后续可能是accept(建连接),也有可能是read/write网络IO事件,accept有时候一个进程处理不过来、或者accept跟读写混用进程处理,所以内核层面没直接解决epoll的惊群,交由上层应用来根据IO事件如何处理。
epoll的惊群在3.10内核加了SO_REUSEPORT来解决惊群,但如果处理accept的worker也要处理read/write(Nginx的工作方式)就可能导致不同的worker有的饥饿有的排队假死一样;4.5的内核增加EPOLLEXCLUSIVE在内核中直接将worker放在一个大queue,同时感知worker状态来派发任务更好地解决了惊群,但是因为LIFO的机制导致在压力不大的情况下,任务主要派发给少数几个worker(能接受,压力大就会正常了)。
无IO复用时Accept
无IO复用(就只能一个进程监听listen 端口)的accept 不会有惊群,epoll_wait 才会。accept一定是只需要一个进程处理消息,内核可以解决。但是select、epoll就不一定了,所以内核只能唤醒所有的。
在linux2.6版本以后,linux内核已经解决了accept()函数的“惊群”现象,大概的处理方式就是,当内核接收到一个客户连接后,只会唤醒等待队列上的第一个进程(线程),所以如果服务器采用accept阻塞调用方式,在2.6的linux系统中已经没有“惊群效应”了。
1 | /* nr_exclusive的值默认设为1 */ |
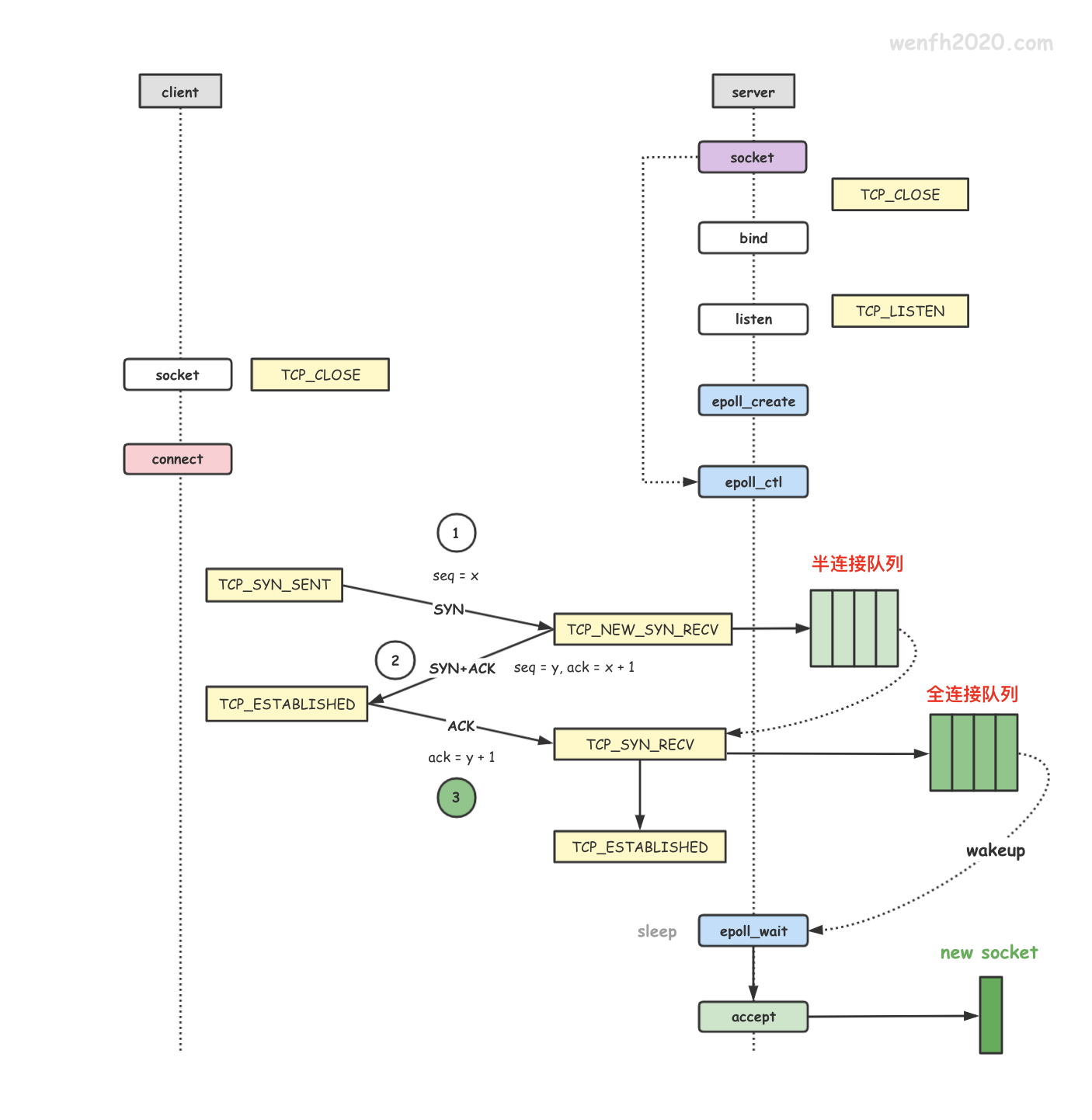
sock中定义了几个I/O事件,当协议栈遇到这些事件时,会调用它们的处理函数。当监听socket收到新的连接时,会触发有数据可读事件,调用sock_def_readable,唤醒socket等待队列中的进程。进程被唤醒后,会执行accept的后续操作,最终返回新连接的描述符。
这个socket等待队列是一个FIFO,所以最终是均衡的,也不需要惊群,有tcp connection ready的话直接让等待队列中第一个的线程出队就好了。
2.6内核层面添加了一个WQ_FLAG_EXCLUSIVE标记,告诉内核进行排他性的唤醒,即唤醒一个进程后即退出唤醒的过程(适合accept,但是不适合 epoll–因为epoll除了有accept,还有其它IO事件)
所以这就是大家经常看到的accept不存在惊群问题,内核10年前就解决了这个问题的场景,实际指的是非epoll下的accept 惊群。
epoll的Accept
epoll监听句柄,后续可能是accept,也有可能是read/write网络IO事件,这些IO事件不一定只能由一个进程处理(很少见需要多个进程处理的),所以内核层面没直接解决epoll的惊群,交由上层应用来根据IO事件如何处理。
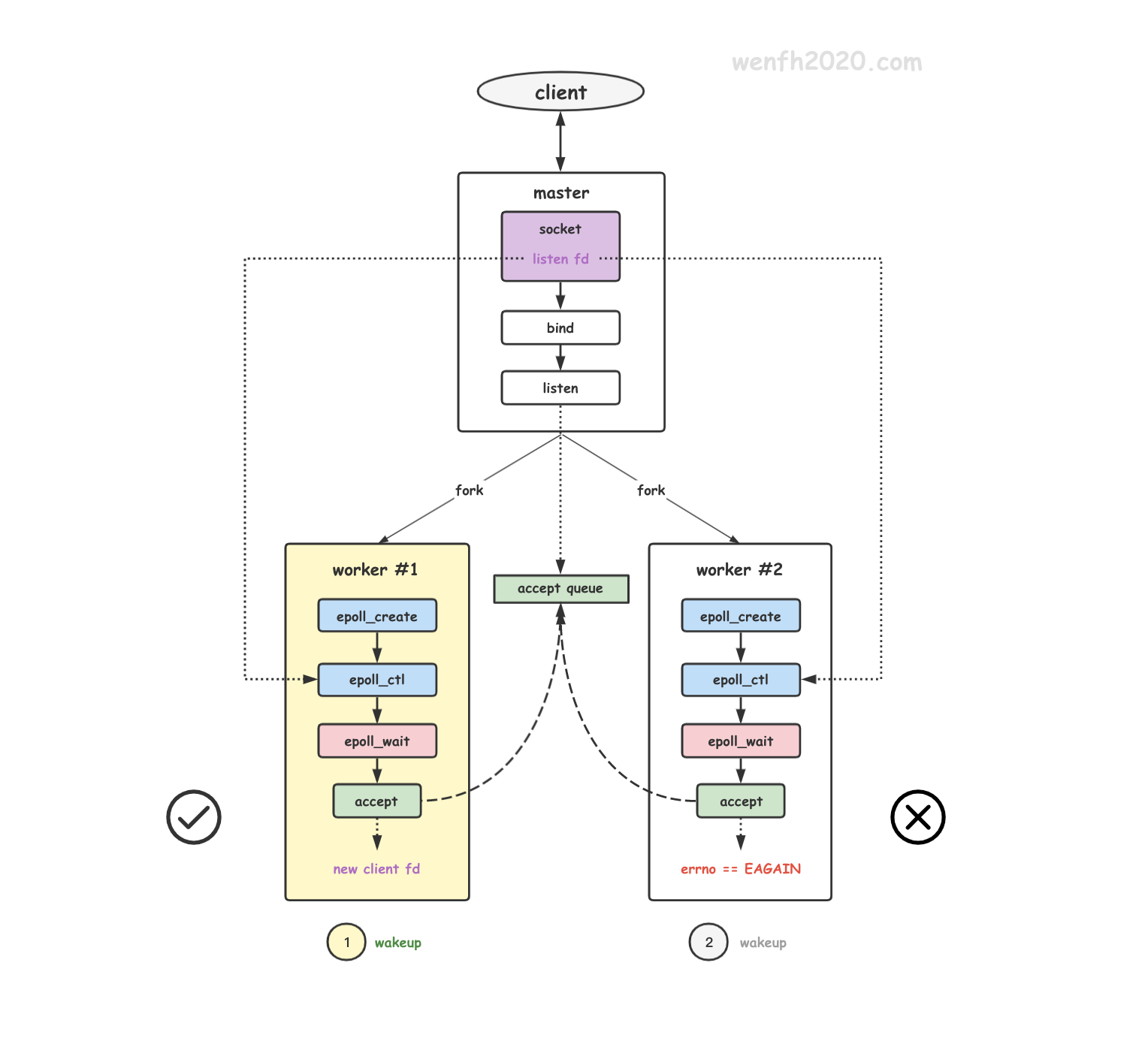
也就是只要是epoll事件,os默认会唤醒监听这个epoll的所有线程。所以常见的做法是一个epoll绑定到一个thread。
1 | //主进程中: |
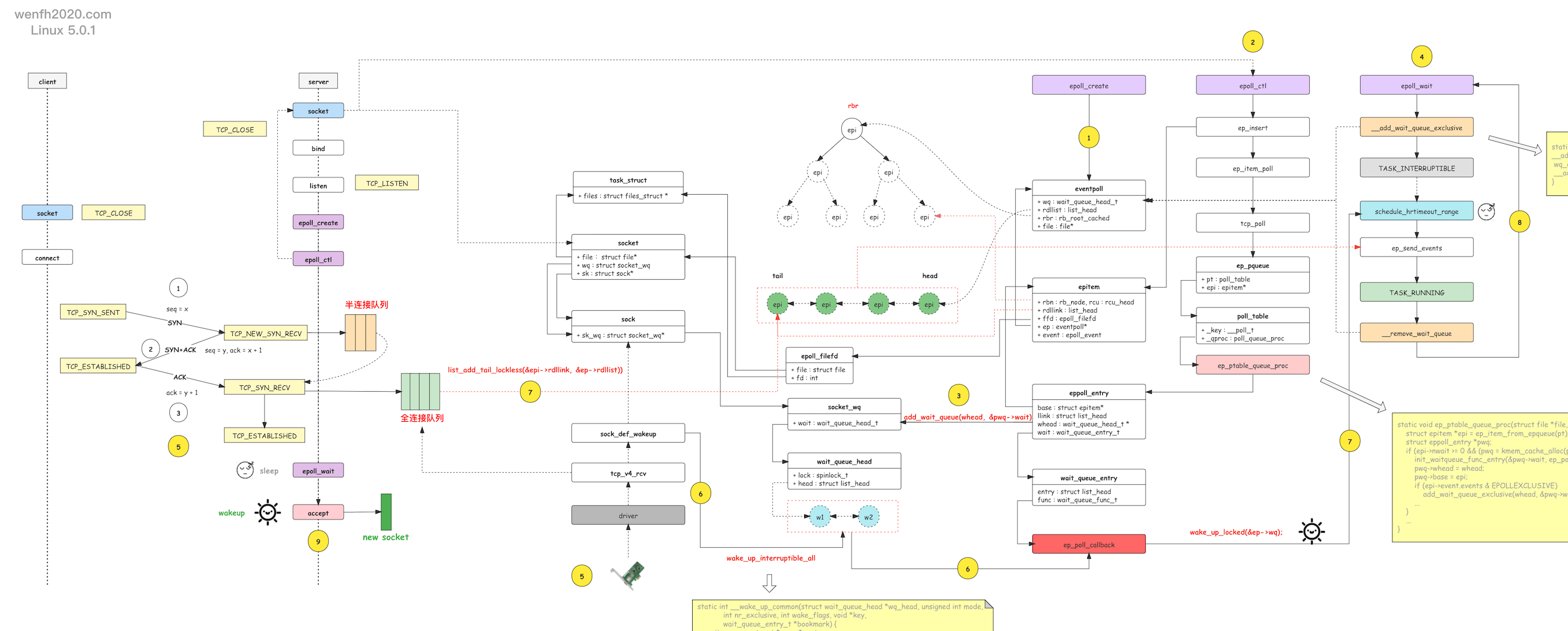
和普通的accept不同,使用epoll时,是在epoll_wait()返回后,发现监听socket有可读事件,才调用accept()。由于epoll_wait()是LIFO,导致多个子进程在accept新连接时,也变成了LIFO。
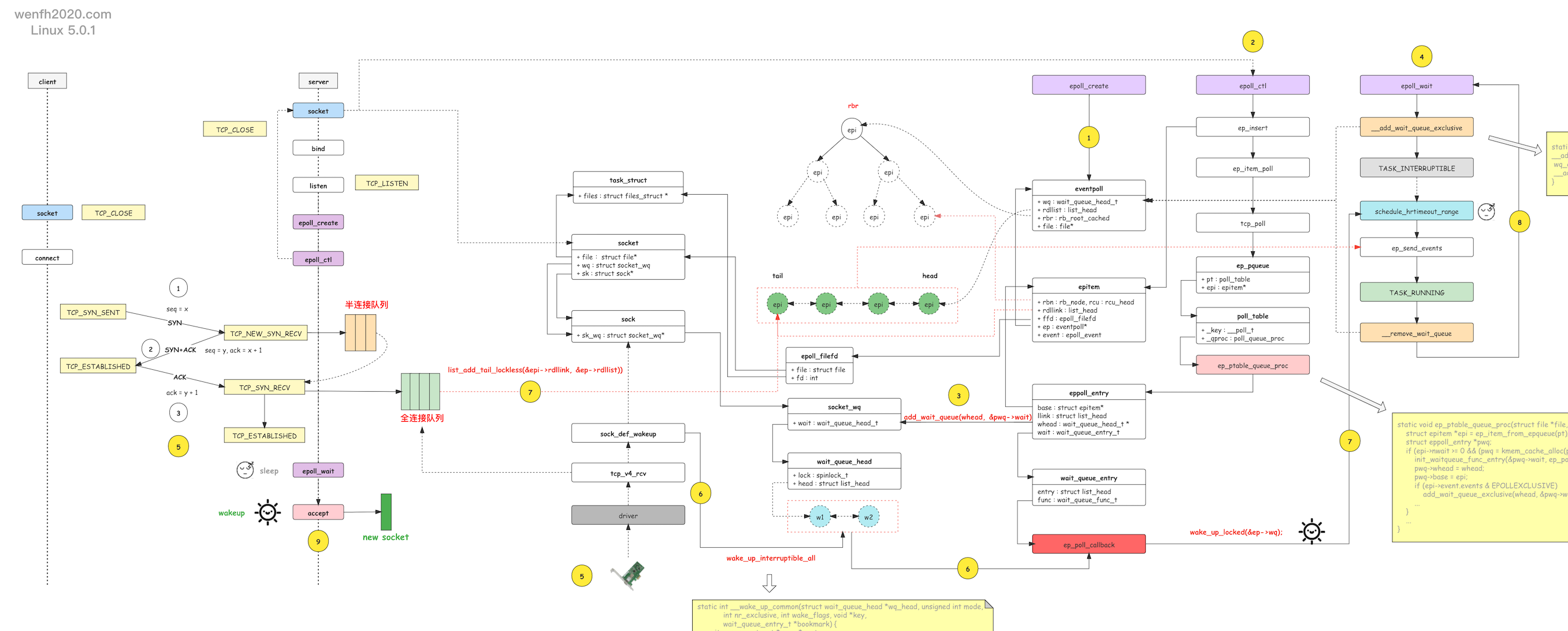
epoll_wait
ep_poll
/* 创建等待任务,把等待任务加入到epfd等待队列的头部,而不是尾部 */
init_waitqueue_entry(&wait, current)
__add_wait_queue_exclusive(&ep->wq, &wait)
...
__remove_wait-queue(&ep->wq, &wait) /* 最终从epfd等待队列中删除 */
回调触发逻辑:
tcp_v4_rcv
tcp_v4_do_rcv
tcp_child_process
sock_def_readable /* sock I/O 有数据可读事件 */
wake_up_interruptible_sync_poll
__wake_up_common
/* curr->func是等待任务的回调函数,在ep_insert初始化等待任务时,设置为ep_poll_callback */
if (curr->func(curr, mode, wake_flags, key) && (flags & WQ_FLAG_EXCLUSIVE) &&
!--nr_exclusive)
break;
那么这种情况下内核如何来解决惊群呢?
SO_REUSEPORT
虽然通过将一个epoll绑定到一个thread来解决竞争问题,但是对于高并发的处理一个thread明显不够,所以有时候不得不设置多个thread来处理一个epoll上的所有socket事件(比如accept)
在3.10的内核中通过引入SO_REUSEPORT解决了这个epoll accept惊群的问题。
linux man文档中一段文字描述其作用:
The new socket option allows multiple sockets on the same host to bind to the same port, and is intended to improve the performance of multithreaded network server applications running on top of multicore systems.
SO_REUSEPORT支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,解决的问题:
- 允许多个套接字 bind()/listen() 同一个TCP/UDP端口
- 每一个线程拥有自己的服务器套接字
- 在服务器套接字上没有了锁的竞争
- 内核层面实现负载均衡,内核通过socket的五元组来hash到不同的socket listener上
- 安全层面,监听同一个端口的套接字只能位于同一个用户下面
其核心的实现主要有三点:
- 扩展 socket option,增加 SO_REUSEPORT 选项,用来设置 reuseport。
- 修改 bind 系统调用实现,以便支持可以绑定到相同的 IP 和端口
- 修改处理新建连接的实现,查找 listener 的时候,能够支持在监听相同 IP 和端口的多个 sock 之间均衡选择。
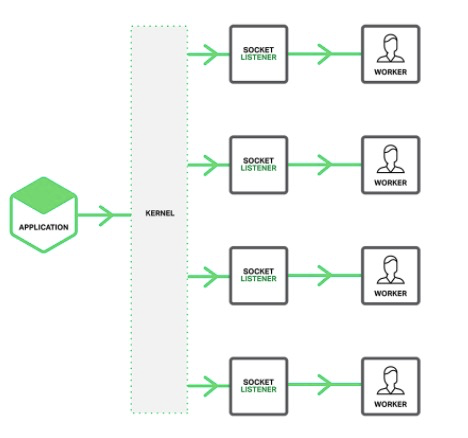
- Nginx的accept_mutex通过抢锁来控制是否将监听套接字加入到epoll 中。监听套接字只在一个子进程的 epoll 中,当新的连接来到时,其他子进程当然不会惊醒了。通过 accept_mutex加锁性能要比reuseport差
- Linux内核解决了epoll_wait 惊群的问题,Nginx 1.9.1利用Linux3.10 的reuseport也能解决惊群、提升性能。
- 内核的reuseport中相当于所有listen同一个端口的多个进程是一个组合,内核收包时不管查找到哪个socket,都能映射到他们所属的 reuseport 数组,再通过五元组哈希选择一个socket,这样只有这个socket队列里有数据,所以即便所有的进程都添加了epoll事件,也只有一个进程会被唤醒。
以nginx为例,一个worker处理一个epoll(对应一个红黑树)上的所有事件,一般连接新建由accept线程专门处理,连接建立后会加入到某个epoll上,也就是以后会由一个固定的worker/线程来处理。
- 每个 Worker 都会有一个属于自己的 epoll 对象
- 每个 Worker 会关注所有的 listen 状态上的新连接事件(可以通过accept_mutex或者reuseport来解决惊群)
- 对于用户连接,只有一个 Worker 会处理,其它 Worker 不会持有该用户连接的 socket(不会惊群)
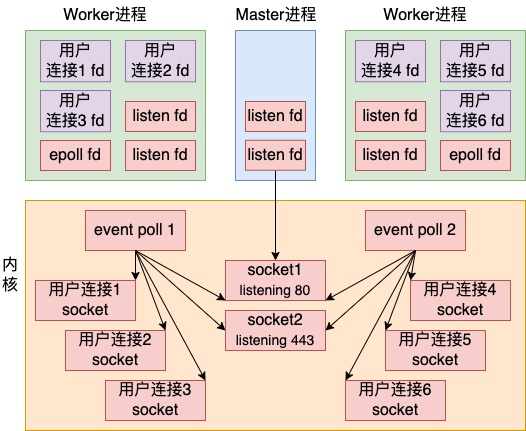
当有包进来,根据5元组,如果socket是ESTABLISHED那么直接给对应的socket,如果是握手,则跟据SO_REUSEPORT匹配到对应的监听port的多个线程中的一个
因为Established socket对应于一个唯一的worker,其上所有的读写事件一般是只有一个worker在监听一个的epoll,所以不存在惊群。Listen Socket才可能会对应多个worker,才有可能惊群。
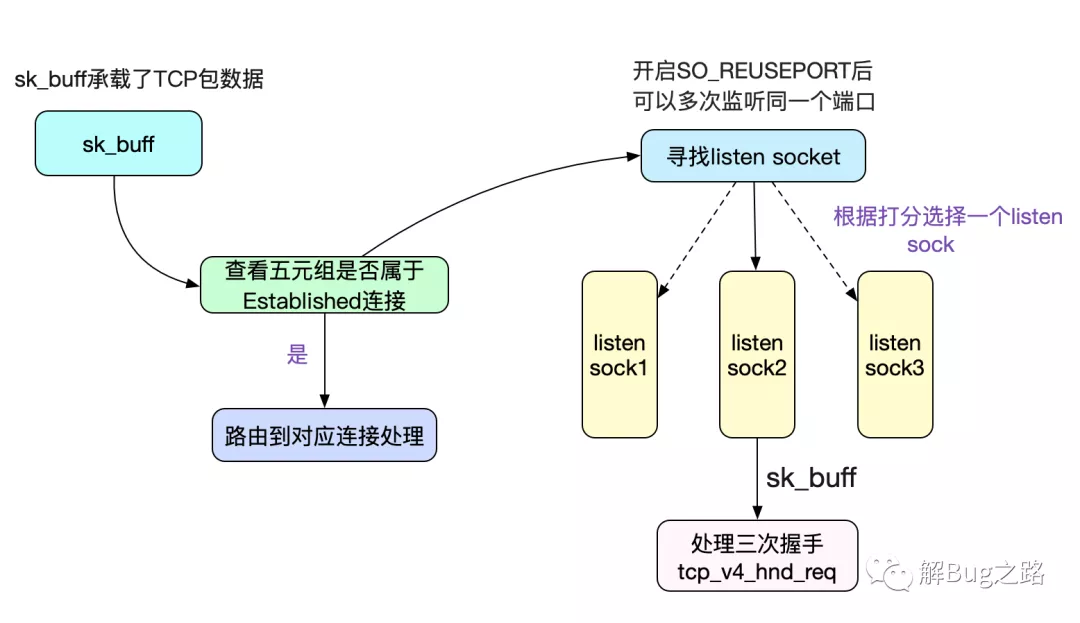
图片来自:https://wenfh2020.com/2021/11/22/question-thundering-herd/
Nginx下SO_REUSEPORT 带来的小问题
从下图可以看出Nginx的一个worker即处理上面的accept也处理对应socket的read/write,如果一个read/write比较耗时的话也会影响到这个worker下的别的socket上的read/write或者accept
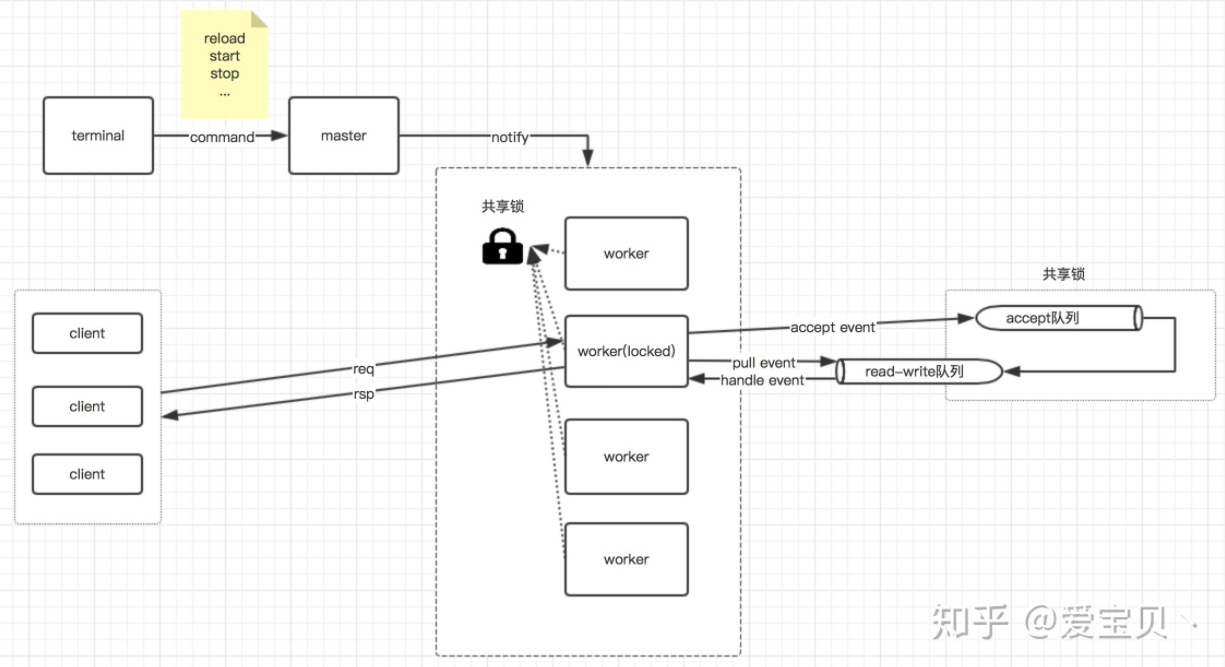
SO_REUSEPORT打开后,去掉了上图的共享锁,变成了如下结构:
再有请求进来不再是各个进程一起去抢,而是内核通过五元组Hash来分配,所以不再会惊群了。但是可能会导致撑死或者饿死的问题,比如一个worker一直在做一件耗时的任务(比如压缩、解码),但是内核通过hash分配新连接过来的时候是不知道worker在忙(抢锁就不会发生这种情况,你没空就不会去抢),以Nginx为例
因为Nginx是ET模式,epoll处理worker要一直将事件处理完毕才能进入epoll_wait(才能响应新的请求)。带来了新的问题:如果有一个慢请求(比如gzip压缩文件需要2分钟),那么处理这个慢请求的进程在reuseport模式下还是会被内核分派到新的连接(或者这个worker上的其它请求),但是这个时候worker一直在压缩如同hang死了,新分配进来的请求无法处理。如果不是reuseport模式,他在处理慢请求就根本腾不出来时间去在惊群中抢到锁。但是还是会影响Established 连接上的请求,这个影响和Reuseport没有关系,是一个线程处理多个Socket带来的必然结果 当然这里如果Nginx把accept和read/write分开用不同的线程来处理也不会有这个问题,毕竟accept正常都很快。
上面Nginx Hang死的原因是:Nginx 使用了边缘触发模式,因此Nginx 在套接字有可读性事件的情况下,必须把所有数据都读掉才行,在gzip buffer < connection rcvbuf 同时后端比较快时候,一次性读不完连接上所有数据,就会出现读数据->压缩->新数据到达->继续读数据-> 继续压缩… 的循环,由于压缩需要时间,此时套接字上又来了新的数据,只要数据来的速度比压缩的快,就会出现数据一直读不完的情况,CPU 就一直切不出去。
解决:OSS gzip_buffers 配置为 64*8k = 512K,给后端进程增加了设置sndbuf/rcvbuf 指令之后通过配置Tengine 与后 oss_server 之间的连接的rcvbuf 到512k 以内,这样就能解决这个问题了,实测这个修改几乎不影响后端整体吞吐,同时也不会出现Nginx worker Hang 的情况。
如果不开启SO_REUSEPORT模式,那么即使有一个worker在处理慢请求,那么他就不会去抢accept锁,也就没有accept新连接,这样就不应影响新连接的处理。当然也有极低的概率阻塞accept(准确来说是刚accept,还没处理完accept后的请求,就又切换到耗时的处理去了,导致这个新accept的请求没得到处理)
开了reuse_port 之后每个worker 都单独有个syn 队列,能按照nginx worker 数成倍提升抗synflood 攻击能力。
但是开启了SO_REUSEPORT后,内核没法感知你的worker是不是特别忙,只是按Hash逻辑派发accept连接。也就是SO_REUSEPORT会导致rt偏差更大(抖动明显一些)。这跟MySQL Thread Pool导致的卡顿原理类似,多个Pool类似这里的SO_REUSEPORT。
用图形展示大概如下:

比如中间的worker即使处理得很慢,内核还是正常派连接过来,即使其它worker空闲, 这会导致 RT 抖动加大:
Here is the same test run against the SO_REUSEPORT multi-queue NGINX setup (c):
1 | $ ./benchhttp -n 100000 -c 200 -r target:8181 http://a.a/ |
相对地一个accept queue多个 worker的模式 running against a single-queue NGINX:
1 | $ ./benchhttp -n 100000 -c 200 -r target:8181 http://a.a/ |
可以看到一个accept queue多个 worker的模式下 RT 极其稳定
SO_REUSEPORT另外的问题
在OS层面一个连接hash到了某个socket fd,但是正好这个 listen socket fd 被关了,已经被分到这个 listen socket fd 的 accept 队列上的请求会被丢掉,具体可以参考 和 LWN 上的 comment
从 Linux 4.5 开始引入了 SO_ATTACH_REUSEPORT_CBPF 和 SO_ATTACH_REUSEPORT_EBPF 这两个 BPF 相关的 socket option。通过巧妙的设计,应该可以避免掉建连请求被丢掉的情况。
EPOLLEXCLUSIVE
epoll引起的accept惊群,在4.5内核中再次引入EPOLLEXCLUSIVE来解决,且需要应用层的配合,Ngnix 在 1.11.3 之后添加了NGX_EXCLUSIVE_EVENT来支持。像tengine尚不支持,所以只能在应用层面上来避免惊群,开启accept_mutex才可避免惊群。
在epoll_ctl ADD描述符时设置 EPOLLEXCLUSIVE 标识。
1 | epoll_ctl |
在加入listen socket的sk_sleep队列的唤醒队列里使用了 add_wait_queue_exculsive()函数,当tcp收到三次握手最后一个 ack 报文时调用sock_def_readable时,只唤醒一个等待源,从而避免‘惊群’.
调用栈如下:
// tcp_v4_do_rcv()
// -->tcp_child_process()
// --->sock_def_readable()
// ---->wake_up_interruptible_sync_poll()
// ----->__wake_up_sync_key()
EPOLLEXCLUSIVE可以在单个Listen Queue对多个Worker Process的时候均衡压力,不会惊群。
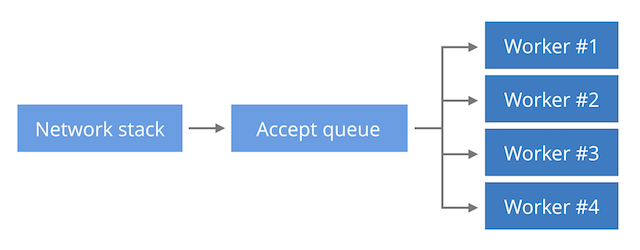
连接从一个队列里由内核分发,不需要惊群,对worker是否忙也能感知(忙的worker就不分发连接过去)

图中的电话机相当于一个worker,只是实际内核中空闲的worker像是在一个堆栈中(LIFO),有连接过来,worker堆栈会出栈,处理完毕又入栈,如此反复。而需要处理的消息是一个队列(FIFO),所以总会发现栈顶的几个worker做的事情更多。
多个worker共享一个 accept queue 带来的问题
下面这个case是观察发现Nginx在压力不大的情况下会导致最后几个核cpu消耗时间更多一些,如下图看到的:
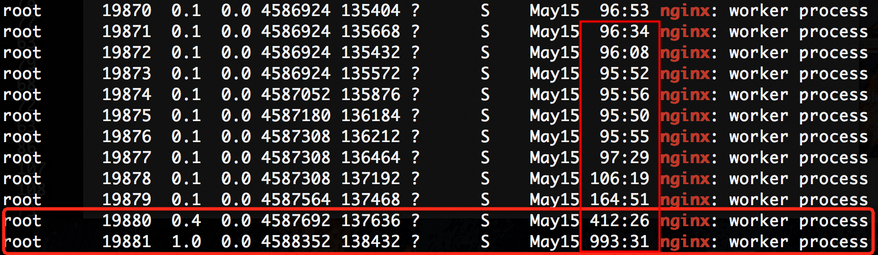
这是如前面所述,所有worker像是在一个栈(LIFO)中等着任务处理,在压力不大的时候会导致连接总是在少数几个worker上(栈底的worker没什么机会出栈),如果并发任务多,导致worker栈经常空掉,这个问题就不存在了。当然最终来看EPOLLEXCLUSIVE没有产生什么实质性的不好的影响。值得推荐
图中LIFO场景出现是在多个worker共享一个accept queue的epoll场景下,如果用 SO_REUSEPORT 搞成每个worker一个accept queue就不存在这个问题了
epoll的accept模型为LIFO,倾向于唤醒最活跃的进程。多进程场景下:默认的accept(非复用)是FIFO,进程加入到监听socket等待队列的尾部,唤醒时从头部开始唤醒;epoll的accept是LIFO,在epoll_wait时把进程加入到监听socket等待队列的头部,唤醒时从头部开始唤醒。
当并发数较小时,只有最后几个进程会被唤醒,它们使用的CPU时间会远高于其它进程。当并发数较大时,所有的进程都有机会被唤醒,各个进程之间的差距不大。内核社区中关于epoll accept是使用LIFO还是RR有过讨论,在4.9内核和最新版本中使用的都是LIFO。
比如这个case,压力低的worker进程和压力高的worker进程差异比较大:
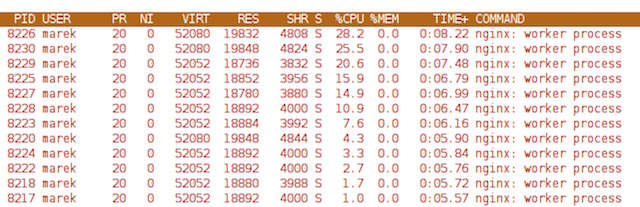
比较下EPOLLEXCLUSIVE 和 SO_REUSEPORT
EPOLLEXCLUSIVE 和 SO_REUSEPORT 都是在内核层面将连接分到多个worker,解决了epoll下的惊群,SO_REUSEPORT 会更均衡一些,EPOLLEXCLUSIVE在压力不大的时候会导致连接总是在少数几个worker上(但这个不会产生任何不利影响)。 SO_REUSEPORT在最坏的情况下会导致一个worker即使Hang了,OS也依然会派连接过去,这是非常致命的,所以4.5内核引入了 EPOLLEXCLUSIVE(总是给闲置等待队列的第一个worker派连接)
相对 SO_REUSEPORT导致的stuck, EPOLLEXCLUSIV 还是更好接受一些。
参考资料
Why does one NGINX worker take all the load?