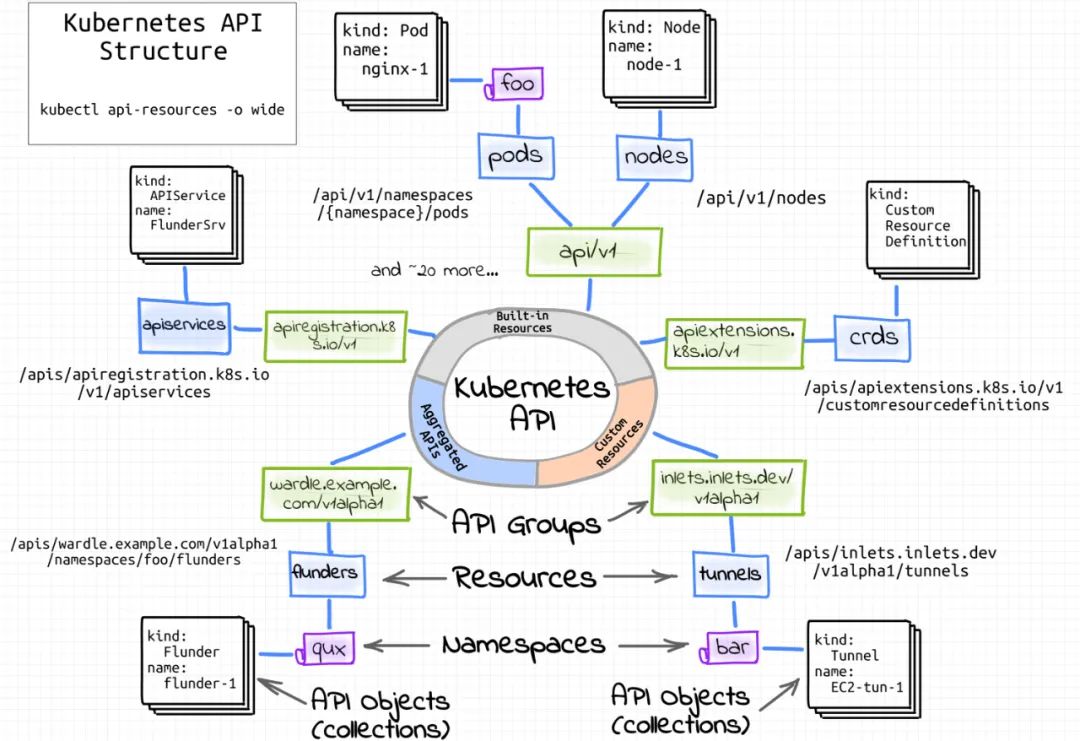
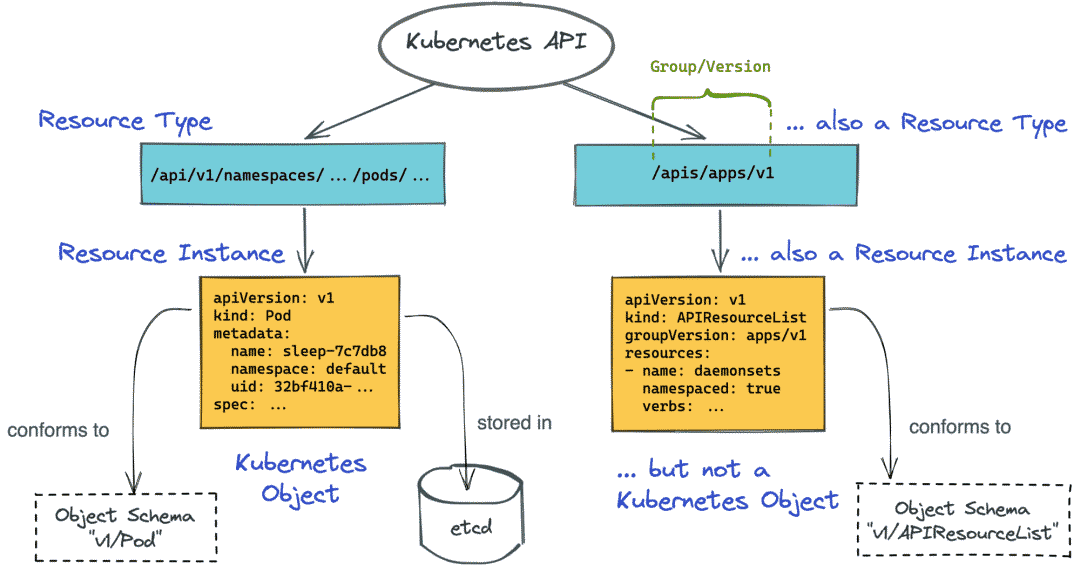
kubernetes 集群部署 部署 系统参数修改
docker部署
kubeadm install
https://www.kubernetes.org.cn/4256.html
https://github.com/opsnull/follow-me-install-kubernetes-cluster
镜像源被墙,可以用阿里云镜像源
1 2 3 4 5 6 7 8 9 10 11 12 13 # 配置源 cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF # 安装 yum install -y kubelet kubeadm kubectl ipvsadm
初始化集群 多网卡情况下有必要指定网卡:–apiserver-advertise-address=192.168.0.80
1 2 3 4 5 6 7 8 9 10 11 12 13 # 使用本地 image repository kubeadm init --kubernetes-version=1.18.0 --apiserver-advertise-address=192.168.0.110 --image-repository registry:5000/registry.aliyuncs.com/google_containers --service-cidr=10.10.0.0/16 --pod-network-cidr=10.122.0.0/16 # 给api-server 指定外网地址,在服务器有内网、外网多个ip的时候适用 kubeadm init --control-plane-endpoint 外网-ip:6443 --image-repository=registry:5000/registry.aliyuncs.com/google_containers --kubernetes-version=v1.21.0 --pod-network-cidr=172.16.0.0/16 # --apiserver-advertise-address=30.1.1.1,设置 apiserver 的 IP 地址,对于多网卡服务器来说很重要(比如 VirtualBox 虚拟机就用了两块网卡),可以指定 apiserver 在哪个网卡上对外提供服务。 # node join command # kubeadm token create --print-join-command kubeadm join 192.168.0.110:6443 --token 1042rl.b4qn9iuz6xv1ri7b --discovery-token-ca-cert-hash sha256:341a4bcfde9668077ef29211c2a151fe6e9334eea8955f645698706b3bf47a49 # kubectl get configmap -n kube-system kubeadm-config -o yaml
将一个node设置为不可调度,隔离出来,比如master 默认是不可调度的
1 2 kubectl cordon <node-name> kubectl uncordon <node-name>
kubectl 管理多集群 一个kubectl可以管理多个集群,主要是 ~/.kube/config 里面的配置,比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 clusters: - cluster: certificate-authority: /root/k8s-cluster.ca server: https://192.168.0.80:6443 name: context-az1 - cluster: certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCQl0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K server: https://192.168.0.97:6443 name: context-az3 - context: cluster: context-az1 namespace: default user: az1-admin name: az1 - context: cluster: context-az3 namespace: default user: az3-read name: az3 current-context: az3 //当前使用的集群 kind: Config preferences: {} users: - name: az1-admin user: client-certificate: /root/k8s.crt //key放在配置文件中 client-key: /root/k8s.key - name: az3-read user: client-certificate-data: LS0tLS1CRUQ0FURS0tLS0tCg== client-key-data: LS0tLS1CRUdJThuL2VPM0YxSWpEcXBQdmRNbUdiU2c9PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=
多个集群中切换的话 : kubectl config use-context az3
快速合并两个cluster 简单来讲就是把两个集群的 .kube/config 文件合并,注意context、cluster name别重复了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 必须提前保证两个config文件中的cluster、context名字不能重复 export KUBECONFIG=~/.kube/config:~/someotherconfig kubectl config view --flatten #激活这个上下文 kubectl config use-context az1 #查看所有context kubectl config get-contexts CURRENT NAME CLUSTER AUTHINFO NAMESPACE az1 context-az1 az1-admin default * az2 kubernetes kubernetes-admin az3 context-az3 az3-read default
背后的原理类似于这个流程:
1 2 3 4 5 6 7 8 9 # 添加集群 集群地址上一步有获取 ,需要指定ca文件,上一步有获取 kubectl config set-cluster cluster-az1 --server https://192.168.146.150:6444 --certificate-authority=/usr/program/k8s-certs/k8s-cluster.ca # 添加用户 需要指定crt,key文件,上一步有获取 kubectl config set-credentials az1-admin --client-certificate=/usr/program/k8s-certs/k8s.crt --client-key=/usr/program/k8s-certs/k8s.key # 指定一个上下文的名字,我这里叫做 az1,随便你叫啥 关联刚才的用户 kubectl config set-context az1 --cluster=context-az1 --namespace=default --user=az1-admin
apiserver高可用 默认只有一个apiserver,可以考虑用haproxy和keepalive来做一组apiserver的负载均衡:
1 2 3 4 5 6 docker run -d --name kube-haproxy \ -v /etc/haproxy:/usr/local/etc/haproxy:ro \ -p 8443:8443 \ -p 1080:1080 \ --restart always \ haproxy:1.7.8-alpine
haproxy配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #cat /etc/haproxy/haproxy.cfg global log 127.0.0.1 local0 err maxconn 50000 uid 99 gid 99 #daemon nbproc 1 pidfile haproxy.pid defaults mode http log 127.0.0.1 local0 err maxconn 50000 retries 3 timeout connect 5s timeout client 30s timeout server 30s timeout check 2s listen admin_stats mode http bind 0.0.0.0:1080 log 127.0.0.1 local0 err stats refresh 30s stats uri /haproxy-status stats realm Haproxy\ Statistics stats auth will:will stats hide-version stats admin if TRUE frontend k8s-https bind 0.0.0.0:8443 mode tcp #maxconn 50000 default_backend k8s-https backend k8s-https mode tcp balance roundrobin server lab1 192.168.1.81:6443 weight 1 maxconn 1000 check inter 2000 rise 2 fall 3 server lab2 192.168.1.82:6443 weight 1 maxconn 1000 check inter 2000 rise 2 fall 3 server lab3 192.168.1.83:6443 weight 1 maxconn 1000 check inter 2000 rise 2 fall 3
网络 1 2 3 4 kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml #或者老版本的calico curl https://docs.projectcalico.org/v3.15/manifests/calico.yaml -o calico.yaml
默认calico用的是ipip封包(这个性能跟原生网络差多少有待验证,本质也是overlay网络,比flannel那种要好很多吗?)
在所有node节点都在一个二层网络时候,flannel提供hostgw实现,避免vxlan实现的udp封装开销,估计是目前最高效的;calico也针对L3 Fabric,推出了IPinIP的选项,利用了GRE隧道封装;因此这些插件都能适合很多实际应用场景。
Service cluster IP尽可在集群内部访问,外部请求需要通过NodePort、LoadBalance或者Ingress来访问
网络插件由 containernetworking-plugins rpm包来提供,一般里面会有flannel、vlan等,安装在 /usr/libexec/cni/ 下(老版本没有带calico)
kubelet启动参数会配置 KUBELET_NETWORK_ARGS=–network-plugin=cni –cni-conf-dir=/etc/cni/net.d –cni-bin-dir=/usr/libexec/cni
kubectl 启动容器 1 2 kubectl run -i --tty busybox --image=registry:5000/busybox -- sh kubectl attach busybox -c busybox -i -t
dashboard 1 2 3 4 kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc7/aio/deploy/recommented.yaml #暴露 dashboard 服务端口 (recommended中如果已经定义了 30000这个nodeport,所以这个命令不需要了) kubectl port-forward -n kubernetes-dashboard svc/kubernetes-dashboard 30000:443 --address 0.0.0.0
dashboard login token:
1 2 #kubectl describe secrets -n kubernetes-dashboard | grep token | awk 'NR==3{print $2}' eyJhbGciOiJSUzI1NiIsImtpZCI6IndRc0hiMkdpWHRwN1FObTcyeUdhOHI0eUxYLTlvODd2U0NBcU1GY0t1Sk0ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkZWZhdWx0LXRva2VuLXRia3o5Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImRlZmF1bHQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIwYzM2MzBhOS0xMjBjLTRhNmYtYjM0ZS0zM2JhMTE1OWU1OWMiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6ZGVmYXVsdCJ9.SP4JEw0kGDmyxrtcUC3HALq99Xr99E-tie5fk4R8odLJBAYN6HxEx80RbTSnkeSMJNApbtwXBLrp4I_w48kTkr93HJFM-oxie3RVLK_mEpZBF2JcfMk6qhfz4RjPiqmG6mGyW47mmY4kQ4fgpYSmZYR4LPJmVMw5W2zo5CGhZT8rKtgmi5_ROmYpWcd2ZUORaexePgesjjKwY19bLEXFOwdsqekwEvj1_zaJhKAehF_dBdgW9foFXkbXOX0xAC0QNnKUwKPanuFOVZDg1fhyV-eyi6c9-KoTYqZMJTqZyIzscIwruIRw0oauJypcdgi7ykxAubMQ4sWEyyFafSEYWg
dashboard 显示为空的话(留意报错信息,一般是用户权限,重新授权即可)
1 2 kubectl delete clusterrolebinding kubernetes-dashboard kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard --user="system:serviceaccount:kubernetes-dashboard:default"
其中:system:serviceaccount:kubernetes-dashboard:default 来自于报错信息中的用户名
默认dashboard login很快expired,可以设置不过期:
1 2 3 4 5 6 7 8 9 $ kubectl -n kubernetes-dashboard edit deployments kubernetes-dashboard ... spec: containers: - args: - --auto-generate-certificates - --token-ttl=0 //增加这行表示不expire --enable-skip-login //增加这行表示不需要token 就能login,不推荐
kubectl proxy –address 0.0.0.0 –accept-hosts ‘.*’
node管理调度 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 //如何优雅删除node kubectl drain my-node # 对 my-node 节点进行清空操作,为节点维护做准备 kubectl drain ky4 --ignore-daemonsets --delete-local-data # 驱逐pod kubectl delete node ky4 # 删除node kubectl cordon my-node # 标记 my-node 节点为不可调度 kubectl uncordon my-node # 标记 my-node 节点为可以调度 kubectl top node my-node # 显示给定节点的度量值 kubectl cluster-info # 显示主控节点和服务的地址 kubectl cluster-info dump # 将当前集群状态转储到标准输出 kubectl cluster-info dump --output-directory=/path/to/cluster-state # 将当前集群状态输出到 /path/to/cluster-state # 如果已存在具有指定键和效果的污点,则替换其值为指定值 kubectl taint nodes foo dedicated=special-user:NoSchedule kubectl taint nodes poc65 node-role.kubernetes.io/master:NoSchedule-
地址 这些字段的用法取决于你的云服务商或者物理机配置。
HostName:由节点的内核设置。可以通过 kubelet 的 --hostname-override 参数覆盖。
ExternalIP:通常是节点的可外部路由(从集群外可访问)的 IP 地址。
InternalIP:通常是节点的仅可在集群内部路由的 IP 地址。
状况 1 2 3 4 5 # kubectl get node -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME 172.26.137.114 Ready master 6d1h v1.19.0 172.26.137.114 <none> CentOS Linux 7 (Core) 3.10.0-957.21.3.el7.x86_64 docker://19.3.8 172.26.137.115 Ready node 6d1h v1.19.0 172.26.137.115 <none> CentOS Linux 7 (Core) 3.10.0-957.21.3.el7.x86_64 docker://19.3.8 172.26.137.116 Ready,SchedulingDisabled node 6d1h v1.19.0 172.26.137.116 <none> CentOS Linux 7 (Core) 3.10.0-957.21.3.el7.x86_64 docker://19.3.8
如果 Ready 条件处于 Unknown 或者 False 状态的时间超过了 pod-eviction-timeout 值, (一个传递给 kube-controller-manager 的参数), 节点上的所有 Pod 都会被节点控制器计划删除。默认的逐出超时时长为 5 分钟 。 某些情况下,当节点不可达时,API 服务器不能和其上的 kubelet 通信。 删除 Pod 的决定不能传达给 kubelet,直到它重新建立和 API 服务器的连接为止。 与此同时,被计划删除的 Pod 可能会继续在游离的节点上运行。
node cidr 缺失 flannel pod 运行正常,pod无法创建,检查flannel日志发现该node cidr缺失
1 2 3 4 I0818 08:06:38.951132 1 main.go:733] Defaulting external v6 address to interface address (<nil>) I0818 08:06:38.951231 1 vxlan.go:137] VXLAN config: VNI=1 Port=0 GBP=false Learning=false DirectRouting=false E0818 08:06:38.951550 1 main.go:325] Error registering network: failed to acquire lease: node "ky3" pod cidr not assigned I0818 08:06:38.951604 1 main.go:439] Stopping shutdownHandler...
正常来说describe node会看到如下的cidr信息
1 2 3 Kube-Proxy Version: v1.15.8-beta.0 PodCIDR: 172.19.1.0/24 Non-terminated Pods: (3 in total)
可以手工给node添加cidr
1 kubectl patch node ky3 -p '{"spec":{"podCIDR":"172.19.3.0/24"}}'
prometheus 1 2 3 git clone https://github.com/coreos/kube-prometheus.git kubectl apply -f manifests/setup kubectl apply -f manifests/
暴露grafana端口:
1 kubectl port-forward --address 0.0.0.0 svc/grafana -n monitoring 3000:3000
部署应用 DRDS deployment 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 apiVersion: v1 kind: Namespace metadata: name: drds --- apiVersion: apps/v1 kind: Deployment metadata: name: drds-deployment namespace: drds labels: app: drds-server spec: # 创建2个nginx容器 replicas: 3 selector: matchLabels: app: drds-server template: metadata: labels: app: drds-server spec: containers: - name: drds-server image: registry:5000/drds-image:v5_wisp_5.4.5-15940932 ports: - containerPort: 8507 - containerPort: 8607 env: - name: diamond_server_port value: "8100" - name: diamond_server_list value: "192.168.0.79,192.168.0.82" - name: drds_server_id value: "1"
DRDS Service 每个 drds 容器会通过8507提供服务,service通过3306来为一组8507做负载均衡,这个service的3306是在cluster-ip上,外部无法访问
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: v1 kind: Service metadata: name: drds-service namespace: drds spec: selector: app: drds-server ports: - protocol: TCP port: 3306 targetPort: 8507
通过node port来访问 drds service(同时会有负载均衡):
1 kubectl port-forward --address 0.0.0.0 svc/drds-service -n drds 3306:3306
部署mysql statefulset应用 drds-pv-mysql-0 后面的mysql 会用来做存储,下面用到了三个mysql(需要三个pvc)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #cat mysql-deployment.yaml apiVersion: v1 kind: Service metadata: name: mysql spec: ports: - port: 3306 selector: app: mysql clusterIP: None --- apiVersion: apps/v1 kind: Deployment metadata: name: mysql spec: selector: matchLabels: app: mysql strategy: type: Recreate template: metadata: labels: app: mysql spec: containers: - image: mysql:5.7 name: mysql env: # Use secret in real usage - name: MYSQL_ROOT_PASSWORD value: "123456" ports: - containerPort: 3306 name: mysql volumeMounts: - name: mysql-persistent-storage mountPath: /var/lib/mysql volumes: - name: mysql-persistent-storage persistentVolumeClaim: claimName: pv-claim
清理:
1 2 3 kubectl delete deployment,svc mysql kubectl delete pvc mysql-pv-claim kubectl delete pv mysql-pv-volume
查看所有pod ip以及node ip:
1 kubectl get pods -o wide
配置 Pod 使用 ConfigMap ConfigMap 允许你将配置文件与镜像文件分离,以使容器化的应用程序具有可移植性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 # cat mysql-configmap.yaml //mysql配置文件放入: configmap apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: master.cnf: | # Apply this config only on the master. [mysqld] log-bin mysqld.cnf: | [mysqld] pid-file = /var/run/mysqld/mysqld.pid socket = /var/run/mysqld/mysqld.sock datadir = /var/lib/mysql #log-error = /var/log/mysql/error.log # By default we only accept connections from localhost #bind-address = 127.0.0.1 # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION' # 慢查询阈值,查询时间超过阈值时写入到慢日志中 long_query_time = 2 innodb_buffer_pool_size = 257M slave.cnf: | # Apply this config only on slaves. [mysqld] super-read-only 786 26/08/20 15:27:00 kubectl create configmap game-config-env-file --from-env-file=configure-pod-container/configmap/game-env-file.properties 787 26/08/20 15:28:10 kubectl get configmap -n kube-system kubeadm-config -o yaml 788 26/08/20 15:28:11 kubectl get configmap game-config-env-file -o yaml
将mysql root密码放入secret并查看 secret密码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # cat mysql-secret.yamlapiVersion: v1 kind: Secret metadata: name: mysql-root-password type: Opaque data: password: MTIz # echo -n '123' | base64 //生成密码编码# kubectl get secret mysql-root-password -o jsonpath='{.data.password}' | base64 --decode - 或者创建一个新的 secret: kubectl create secret generic my-secret --from-literal=password="Password"
在mysql容器中使用以上configmap中的参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 spec: volumes: - name: conf emptyDir: {} - name: myconf emptyDir: {} - name: config-map configMap: name: mysql initContainers: - name: init-mysql image: mysql:5.7 command: - bash - "-c" - | set -ex # Generate mysql server-id from pod ordinal index. [[ `hostname` =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]} echo [mysqld] > /mnt/conf.d/server-id.cnf # Add an offset to avoid reserved server-id=0 value. echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf #echo "innodb_buffer_pool_size=512m" > /mnt/rds.cnf # Copy appropriate conf.d files from config-map to emptyDir. #if [[ $ordinal -eq 0 ]]; then cp /mnt/config-map/master.cnf /mnt/conf.d/ cp /mnt/config-map/mysqld.cnf /mnt/mysql.conf.d/ #else # cp /mnt/config-map/slave.cnf /mnt/conf.d/ #fi volumeMounts: - name: conf mountPath: /mnt/conf.d - name: myconf mountPath: /mnt/mysql.conf.d - name: config-map mountPath: /mnt/config-map containers: - name: mysql image: mysql:5.7 env: #- name: MYSQL_ALLOW_EMPTY_PASSWORD # value: "1" - name: MYSQL_ROOT_PASSWORD valueFrom: secretKeyRef: name: mysql-root-password key: password
通过挂载方式进入到容器里的 Secret,一旦其对应的 Etcd 里的数据被更新,这些 Volume 里的文件内容,同样也会被更新。其实,这是 kubelet 组件在定时维护这些 Volume。
集群会自动创建一个 default-token-**** 的secret,然后所有pod都会自动将这个 secret通过 Porjected Volume挂载到容器,也叫 ServiceAccountToken,是一种特殊的Secret
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-ncgdl (ro) Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: default-token-ncgdl: Type: Secret (a volume populated by a Secret) SecretName: default-token-ncgdl Optional: false QoS Class: BestEffort
apply create操作 先 kubectl create,再 replace 的操作,我们称为命令式配置文件操作
kubectl apply 命令才是“声明式 API”
kubectl replace 的执行过程,是使用新的 YAML 文件中的 API 对象,替换原有的 API 对象;
而 kubectl apply,则是执行了一个对原有 API 对象的 PATCH 操作。
kubectl set image 和 kubectl edit 也是对已有 API 对象的修改
kube-apiserver 在响应命令式请求(比如,kubectl replace)的时候,一次只能处理一个写请求,否则会有产生冲突的可能。而对于声明式请求(比如,kubectl apply),一次能处理多个写操作,并且具备 Merge 能力
声明式 API,相当于对外界所有操作(并发接收)串行merge,才是 Kubernetes 项目编排能力“赖以生存”的核心所在
如何使用控制器模式,同 Kubernetes 里 API 对象的“增、删、改、查”进行协作,进而完成用户业务逻辑的编写过程。
label 给多个节点加标签
1 2 3 4 kubectl label --overwrite=true nodes 10.0.0.172 10.0.1.192 10.0.2.48 topology.kubernetes.io/region=cn-hangzhou //查看 kubectl get nodes --show-labels
helm Helm 是 Kubernetes 的包管理器。包管理器类似于我们在 Ubuntu 中使用的apt、Centos中使用的yum 或者Python中的 pip 一样,能快速查找、下载和安装软件包。Helm 由客户端组件 helm 和服务端组件 Tiller 组成, 能够将一组K8S资源打包统一管理, 是查找、共享和使用为Kubernetes构建的软件的最佳方式。
建立local repo index:
1 helm repo index [DIR] [flags]
仓库只能index 到 helm package 发布后的tgz包,意义不大。每次index后需要 helm repo update
然后可以启动一个http服务:
1 nohup python -m SimpleHTTPServer 8089 &
将local repo加入到仓库:
1 2 3 4 5 helm repo add local http://127.0.0.1:8089 # helm repo list NAME URL local http://127.0.0.1:8089
install chart:
1 2 3 4 5 6 7 8 //helm3 默认不自动创建namespace,不带参数就报没有 ame 的namespace错误 helm install -name wordpress -n test --create-namespace . helm list -n test {{ .Release.Name }} 这种是helm内部自带的值,都是一些内建的变量,所有人都可以访问 image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}" 这种是我们从values.yaml文件中获取或者从命令行中获取的值。
quote是一个模板方法,可以将输入的参数添加双引号
模板片段 之前我们看到有个文件叫做_helpers.tpl,我们介绍是说存储模板片段的地方。
模板片段其实也可以在文件中定义,但是为了更好管理,可以在_helpers.tpl中定义,使用时直接调用即可。
自动补全 kubernetes自动补全:
1 2 3 source <(kubectl completion bash) echo "source <(kubectl completion bash)" >> ~/.bashrc
helm自动补全:
1 2 cd ~ helm completion bash > .helmrc && echo "source .helmrc" >> .bashrc && source .bashrc
两者都需要依赖 auto-completion,所以得先:
1 2 # yum install -y bash-completion # source /usr/share/bash-completion/bash_completion
kubectl -s polarx-test-ackk8s-atp-3826.adbgw.alibabacloud.test exec -it bushu016polarx282bc7216f-5161 bash
启动时间排序 1 2 532 [2021-08-24 18:37:19] kubectl get po --sort-by=.status.startTime -ndrds 533 [2021-08-24 18:37:41] kubectl get pods --sort-by=.metadata.creationTimestamp -ndrds
kubeadm 初始化集群的时候第一看kubelet能否起来(cgroup配置),第二就是看kubelet静态起pod,kubelet参数指定yaml目录,然后kubelet拉起这个目录下的所有yaml。
kubeadm启动集群就是如此。kubeadm生成证书、etcd.yaml等yaml、然后拉起kubelet,kubelet拉起etcd、apiserver等pod,kubeadm init 的时候主要是在轮询等待apiserver的起来。
可以通过kubelet –v 256来看详细日志,kubeadm本身所做的事情并不多,所以日志没有太多的信息,主要是等待轮询apiserver的拉起。
Kubeadm config Init 可以指定仓库以及版本
1 kubeadm init --image-repository=registry:5000/registry.aliyuncs.com/google_containers --kubernetes-version=v1.14.6 --pod-network-cidr=10.244.0.0/16
查看并修改配置
1 2 3 4 5 6 7 sudo kubeadm config view > kubeadm-config.yaml edit kubeadm-config.yaml and replace k8s.gcr.io with your repo sudo kubeadm upgrade apply --config kubeadm-config.yaml kubeadm config images pull --config="/root/kubeadm-config.yaml" kubectl get cm -n kube-system kubeadm-config -o yaml
pod镜像拉取不到的话可以在kebelet启动参数中写死pod镜像(pod_infra_container_image)
1 2 # cat /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.confExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS --pod_infra_container_image=registry:5000/registry.aliyuncs.com/google_containers/pause:3.1
构建离线镜像库 1 2 3 4 kubeadm config images list >1.24.list cat 1.24.list | awk -F / '{ print $0 " " $3}' > 1.24.aarch.list
一个集群下反复部署calico/flannel插件后,在 /etc/cni/net.d/ 下会有cni 网络配置文件残留,导致 flannel 创建容器网络的时候报证书错误。其实这不只是证书错误,还可能报其它cni配置错误,总之这是因为 10-calico.conflist 不符合 flannel要求所导致的。
1 2 3 4 5 # find /etc/cni/net.d/ /etc/cni/net.d/ /etc/cni/net.d/calico-kubeconfig /etc/cni/net.d/10-calico.conflist //默认读取了这个配置文件,不符合flannel /etc/cni/net.d/10-flannel.conflist
因为calico 排在 flannel前面,所以即使用flannel配置文件也是用的 10-calico.conflist。每次 kubeadm reset 的时候是不会去做 cni 的reset 的:
1 2 3 4 [reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf] [reset] Deleting contents of stateful directories: [/var/lib/kubelet /var/lib/dockershim /var/run/kubernetes /var/lib/cni] The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
用kubeadm部署kubernetes集群,会生成如下证书:
1 2 3 #ls /etc/kubernetes/pki/ apiserver-etcd-client.crt apiserver-kubelet-client.crt apiserver.crt ca.crt etcd front-proxy-ca.key front-proxy-client.key sa.pub apiserver-etcd-client.key apiserver-kubelet-client.key apiserver.key ca.key front-proxy-ca.crt front-proxy-client.crt sa.key
curl访问api必须提供证书
1 curl --cacert /etc/kubernetes/pki/ca.crt --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --key /etc/kubernetes/pki/apiserver-kubelet-client.key https://ip:6443/apis/apps/v1/deployments
/etc/kubernetes/pki/ca.crt —- CA机构
由CA机构签发:/etc/kubernetes/pki/apiserver-kubelet-client.crt
获取default namespace下的deployment
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # JWT_TOKEN_DEFAULT_DEFAULT=$(kubectl get secrets \ $(kubectl get serviceaccounts/default -o jsonpath='{.secrets[0].name}') \ -o jsonpath='{.data.token}' | base64 --decode) #curl --cacert /etc/kubernetes/pki/ca.crt --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --key /etc/kubernetes/pki/apiserver-kubelet-client.key https://11.158.239.200:6443/apis/apps/v1/namespaces/default/deployments --header "Authorization: Bearer $JWT_TOKEN_DEFAULT_DEFAULT" { "kind": "DeploymentList", "apiVersion": "apps/v1", "metadata": { "resourceVersion": "1233307" }, "items": [ { "metadata": { "name": "nginx-deployment", //列出default namespace下所有的pod #curl --cacert /etc/kubernetes/pki/ca.crt --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --key /etc/kubernetes/pki/apiserver-kubelet-client.key https://11.158.239.200:6443/api/v1/namespaces/default/pods --header "Authorization: Bearer $JWT_TOKEN_DEFAULT_DEFAULT" //对应的kubectl生成的curl命令 curl --cacert /etc/kubernetes/pki/ca.crt --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --key /etc/kubernetes/pki/apiserver-kubelet-client.key -v -XGET -H "Accept: application/json;as=Table;v=v1;g=meta.k8s.io,application/json;as=Table;v=v1beta1;g=meta.k8s.io,application/json" -H "User-Agent: kubectl/v1.23.3 (linux/arm64) kubernetes/816c97a" 'https://11.158.239.200:6443/api/v1/namespaces/default/pods?limit=500'
对应地可以通过 kubectl -v 256 get pods 来看kubectl的处理过程,以及具体访问的api、参数、返回结果等。实际kubectl最终也是通过libcurl来访问的这些api。这样也不用对api-server抓包分析了。
或者将kube api-server 代理成普通http服务
# Make Kubernetes API available on localhost:8080 # to bypass the auth step in subsequent queries:
然后
curl http://localhost:8080/api/v1/namespaces
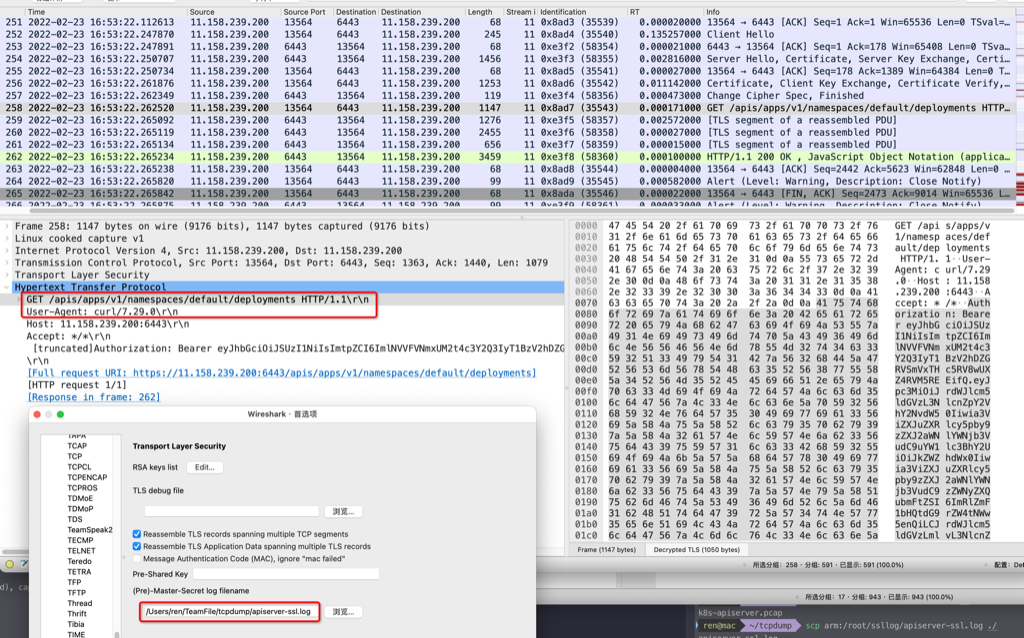
抓包 用curl调用kubernetes api-server来调试,需要抓包,先在执行curl的服务器上配置环境变量
1 export SSLKEYLOGFILE=/root/ssllog/apiserver-ssl.log
然后执行tcpdump对api-server的6443端口抓包,然后将/root/ssllog/apiserver-ssl.log和抓包文件下载到本地,wireshark打开抓包文件,同时配置tls。
以下是个完整case(技巧指定curl的本地端口为12345,然后tcpdump只抓12345,所得的请求、response结果都会解密–如果抓api-server的6443则只能看到请求被解密)
1 2 3 curl --local-port 12345 --cacert /etc/kubernetes/pki/ca.crt --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --key /etc/kubernetes/pki/apiserver-kubelet-client.key https://11.158.239.200:6443/apis/apps/v1/namespaces/default/deployments --header "Authorization: Bearer $JWT_TOKEN_DEFAULT_DEFAULT" #cat $JWT_TOKEN_DEFAULT_DEFAULT eyJhbGciOiJSUzI1NiIsImtpZCI6ImlNVVFVNmxUM2t4c3Y2Q3IyT1BzV2hDZGRVSmVxTHc5RV8wUXZ4RVM5REEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJ: File name too long
参考资料 https://kubernetes.io/zh/docs/reference/kubectl/cheatsheet/