MySQL 线程池导致的卡顿 问题描述 简单小表的主键点查SQL,单条执行很快,但是放在业务端,有时快有时慢,取了一条慢sql,在MySQL侧查看,执行时间很短。
通过Tomcat业务端监控有显示慢SQL,取slow.log里显示有12秒执行时间的SQL,但是这次12秒的执行在MySQL上记录下来的执行时间都不到1ms。
所在节点的tsar监控没有异常,Tomcat manager监控上没有fgc,Tomcat实例规格 16C32g*8, MySQL 32c128g *32 。
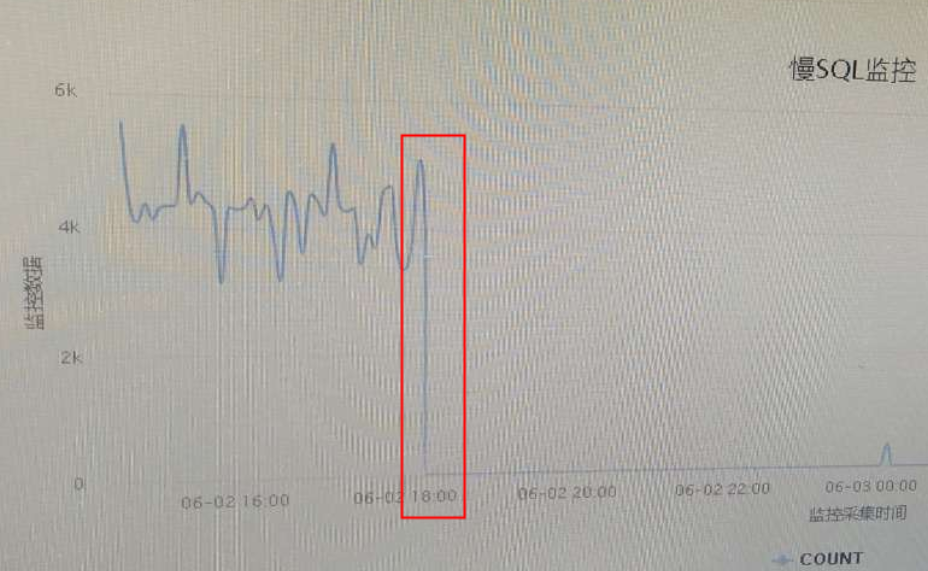
5-28号现象复现,从监控图上CPU、内存、网络都没发现异常,MySQL侧查到的SQL依然执行很快,Tomcat侧记录12S执行时间,当时Tomcat节点的网络流量、CPU压力都很小。
所以客户怀疑Tomcat有问题或者Tomcat上的代码写得有问题导致了这个问题,需要排查和解决掉。
接下来我们会先分析这个问题出现的原因,然后会分析这类问题的共性同时拓展到其它场景下的类似问题。
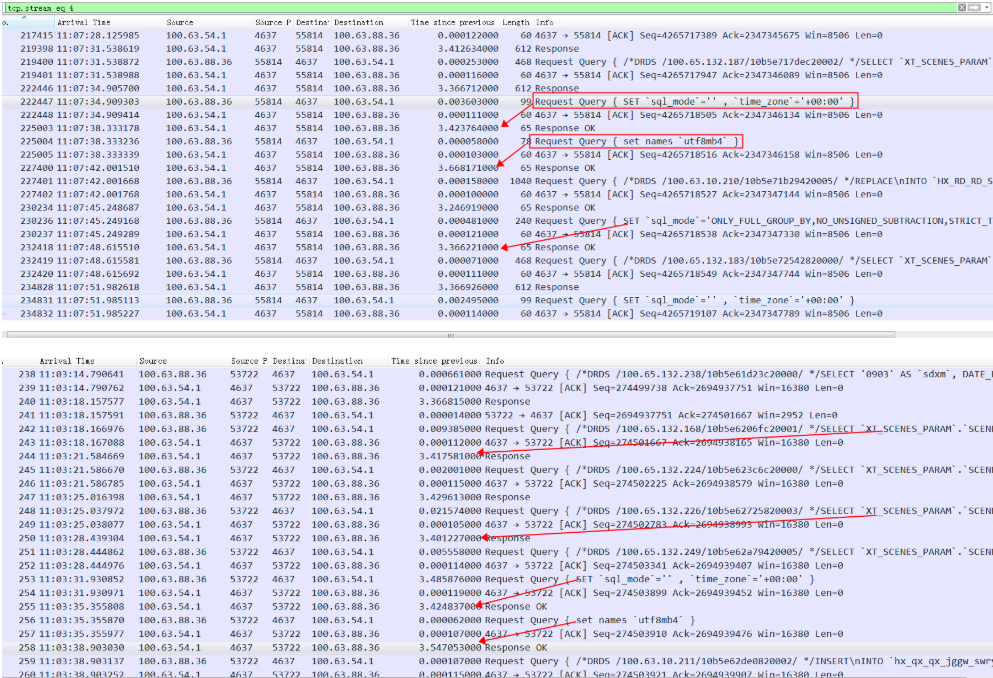
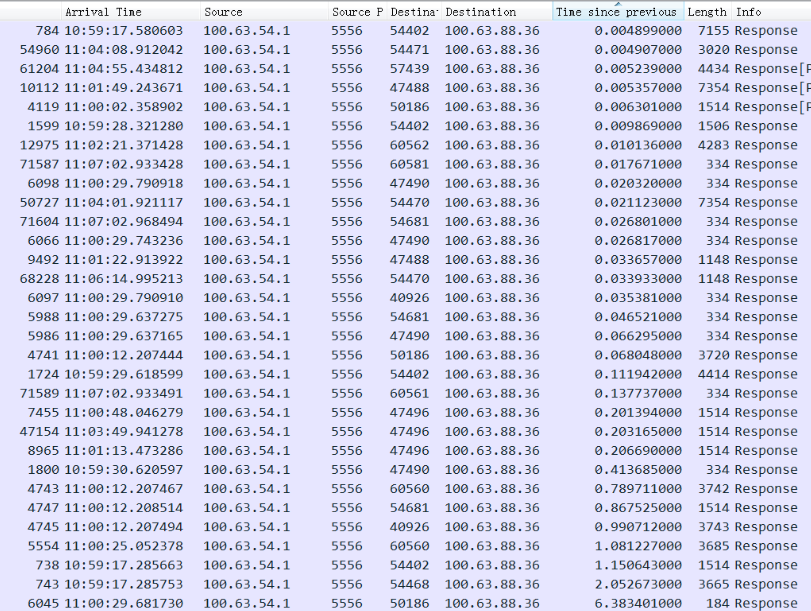
Tomcat上抓包分析 慢的连接 经过抓包分析发现在慢的连接上,所有操作都很慢,包括set 命令,慢的时间主要分布在3秒以上,1-3秒的慢查询比较少,这明显不太符合分布规律。并且目前看慢查询基本都发生在MySQL的0库的部分连接上(后端有一堆MySQL组成的集群),下面抓包的4637端口是MySQL的服务端口:
以上两个连接都很慢,对应的慢查询在MySQL里面记录很快。
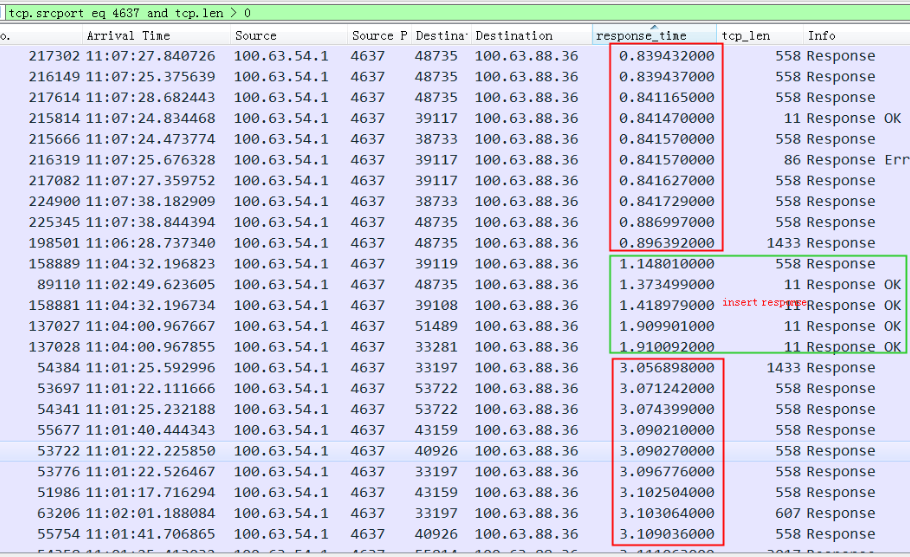
慢的SQL的response按时间排序基本都在3秒以上:
或者只看response time 排序,中间几个1秒多的都是 Insert语句。也就是1秒到3秒之间的没有,主要是3秒以上的查询
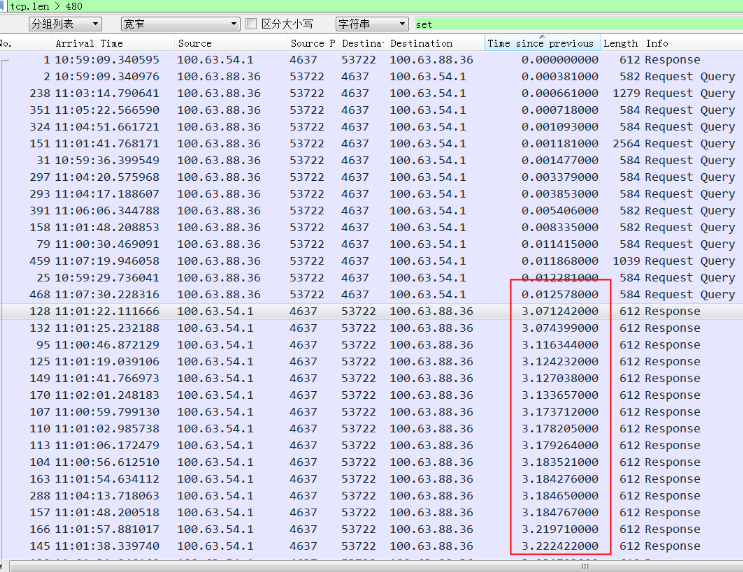
快的连接 同样一个查询SQL,发到同一个MySQL上(4637端口),下面的连接上的所有操作都很快,下面是两个快的连接上的执行截图
别的MySQL上都比较快,比如5556分片上的所有response RT排序,只有偶尔极个别的慢SQL
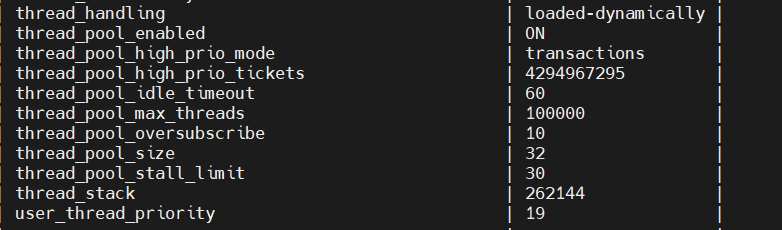
MySQL相关参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 mysql> show variables like '%thread%'; +--------------------------------------------+-----------------+ | Variable_name | Value | +--------------------------------------------+-----------------+ | innodb_purge_threads | 1 | | innodb_MySQL_thread_extra_concurrency | 0 | | innodb_read_io_threads | 16 | | innodb_thread_concurrency | 0 | | innodb_thread_sleep_delay | 10000 | | innodb_write_io_threads | 16 | | max_delayed_threads | 20 | | max_insert_delayed_threads | 20 | | myisam_repair_threads | 1 | | performance_schema_max_thread_classes | 50 | | performance_schema_max_thread_instances | -1 | | pseudo_thread_id | 12882624 | | MySQL_is_dump_thread | OFF | | MySQL_threads_running_ctl_mode | SELECTS | | MySQL_threads_running_high_watermark | 50000 | | rocksdb_enable_thread_tracking | OFF | | rocksdb_enable_write_thread_adaptive_yield | OFF | | rocksdb_signal_drop_index_thread | OFF | | thread_cache_size | 100 | | thread_concurrency | 10 | | thread_handling | pool-of-threads | | thread_pool_high_prio_mode | transactions | | thread_pool_high_prio_tickets | 4294967295 | | thread_pool_idle_timeout | 60 | | thread_pool_max_threads | 100000 | | thread_pool_oversubscribe | 10 | | thread_pool_size | 96 | | thread_pool_stall_limit | 30 | | thread_stack | 262144 | | threadpool_workaround_epoll_bug | OFF | | tokudb_cachetable_pool_threads | 0 | | tokudb_checkpoint_pool_threads | 0 | | tokudb_client_pool_threads | 0 | +--------------------------------------------+-----------------+ 33 rows in set (0.00 sec)
综上结论 问题原因跟MySQL线程池比较相关,慢的连接总是慢,快的连接总是快。需要到MySQL Server下排查线程池相关参数。
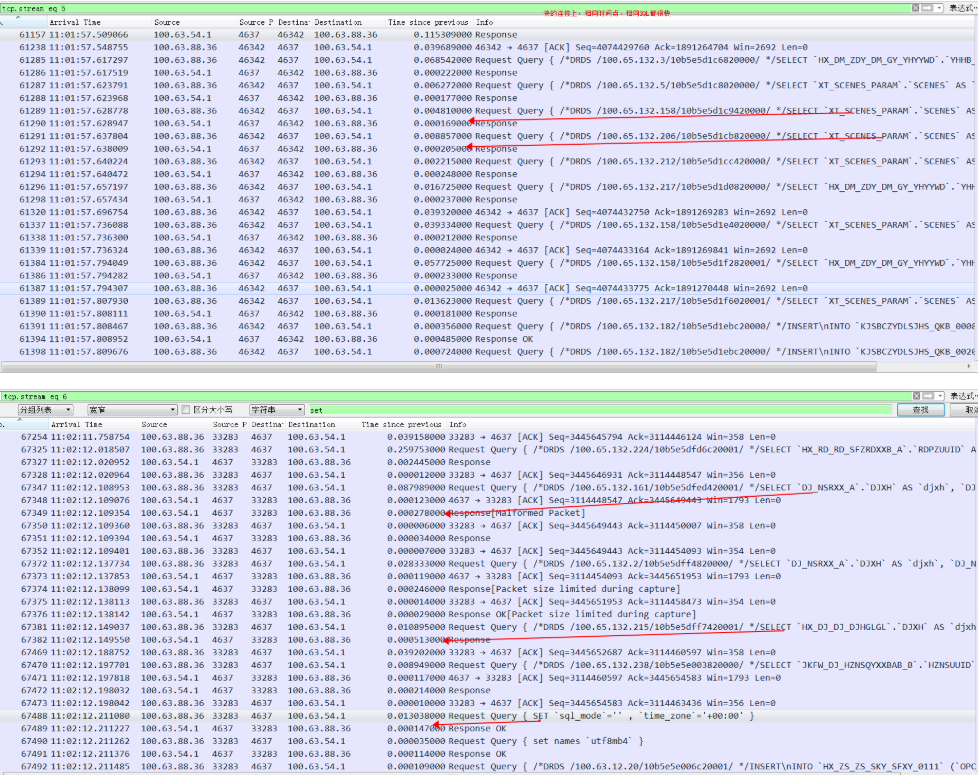
同一个慢的连接上的回包,所有 ack 就很快(OS直接回,不需要进到MySQL),但是set就很慢,基本理解只要进到MySQL的就慢了,所以排除了网络原因(流量本身也很小,也没看到乱序、丢包之类的)
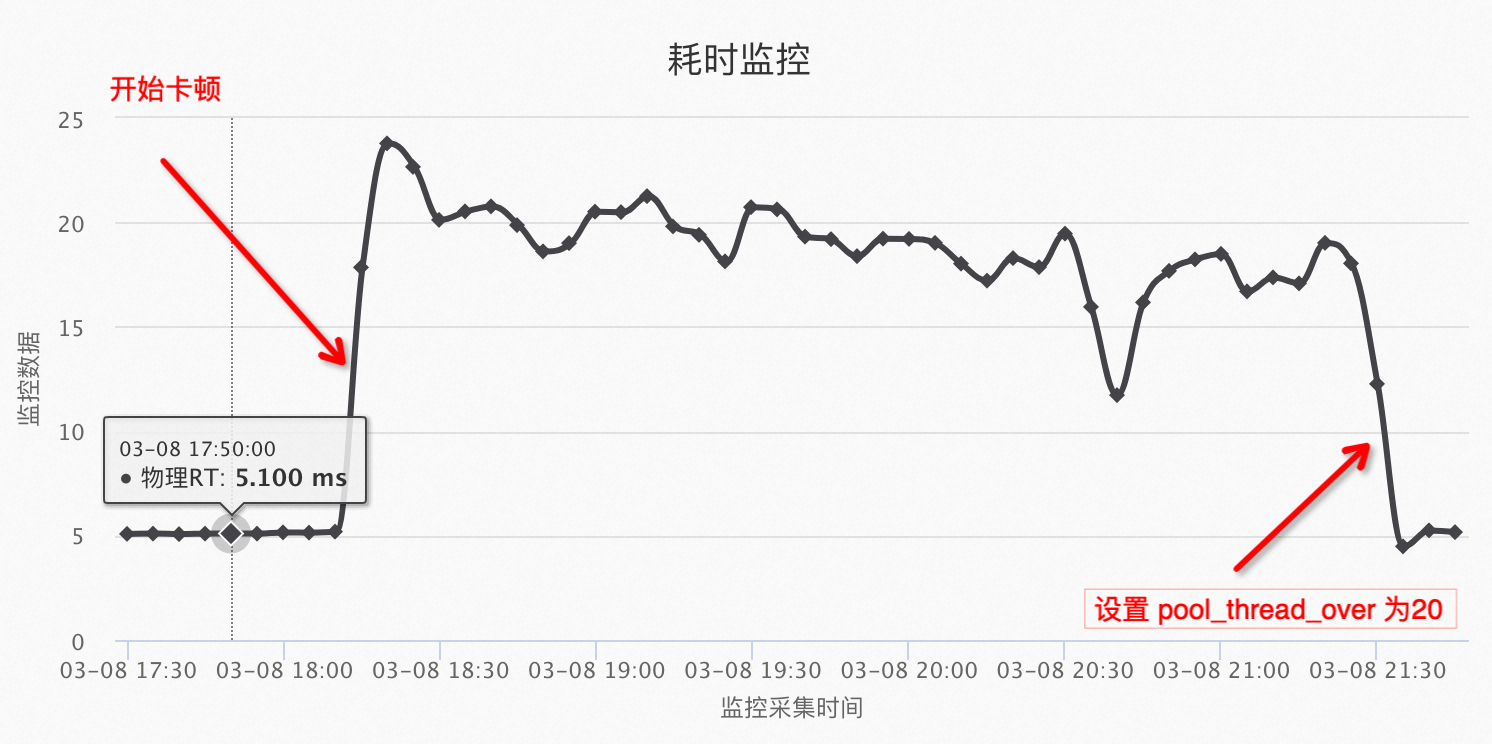
问题解决 18点的时候将4637端口上的MySQL thread_pool_oversubscribe 从10调整到20后,基本没有慢查询了:
当时从MySQL的观察来看,并发压力很小,很难抓到running thread比较高的情况(update: 可能是任务积压在队列中,只是96个thread pool中的一个thread全部running,导致整体running不高)
MySQL记录的执行时间是指SQL语句开始解析后统计,中间的等锁、等Worker都不会记录在执行时间中,所以当时对应的SQL在MySQL日志记录中很快。
thread_pool_stall_limit 会控制一个SQL过长时间(默认60ms)占用线程,如果出现stall_limit就放更多的SQL进入到thread pool中直到达到thread_pool_oversubscribe个
The thread_pool_stall_limit affects executing statements. The value is the amount of time a statement has to finish after starting to execute before it becomes defined as stalled, at which point the thread pool permits the thread group to begin executing another statement. The value is measured in 10 millisecond units, so the default of 6 means 60ms. Short wait values permit threads to start more quickly. Short values are also better for avoiding deadlock situations. Long wait values are useful for workloads that include long-running statements, to avoid starting too many new statements while the current ones execute.
类似案例 一个其它客户同样的问题的解决过程,最终发现是因为thread pool group中的active thread count 计数有泄漏,导致达到thread_pool_oversubscribe 的上限(实际没有任何线程运行)
问题:1)为什么调整到20后 active_thread_count 没变,但是不卡了?那以前卡着的10个 thread在干嘛?
2)卡住的根本原因是,升级能解决?
调整前的 thread pool 配置:
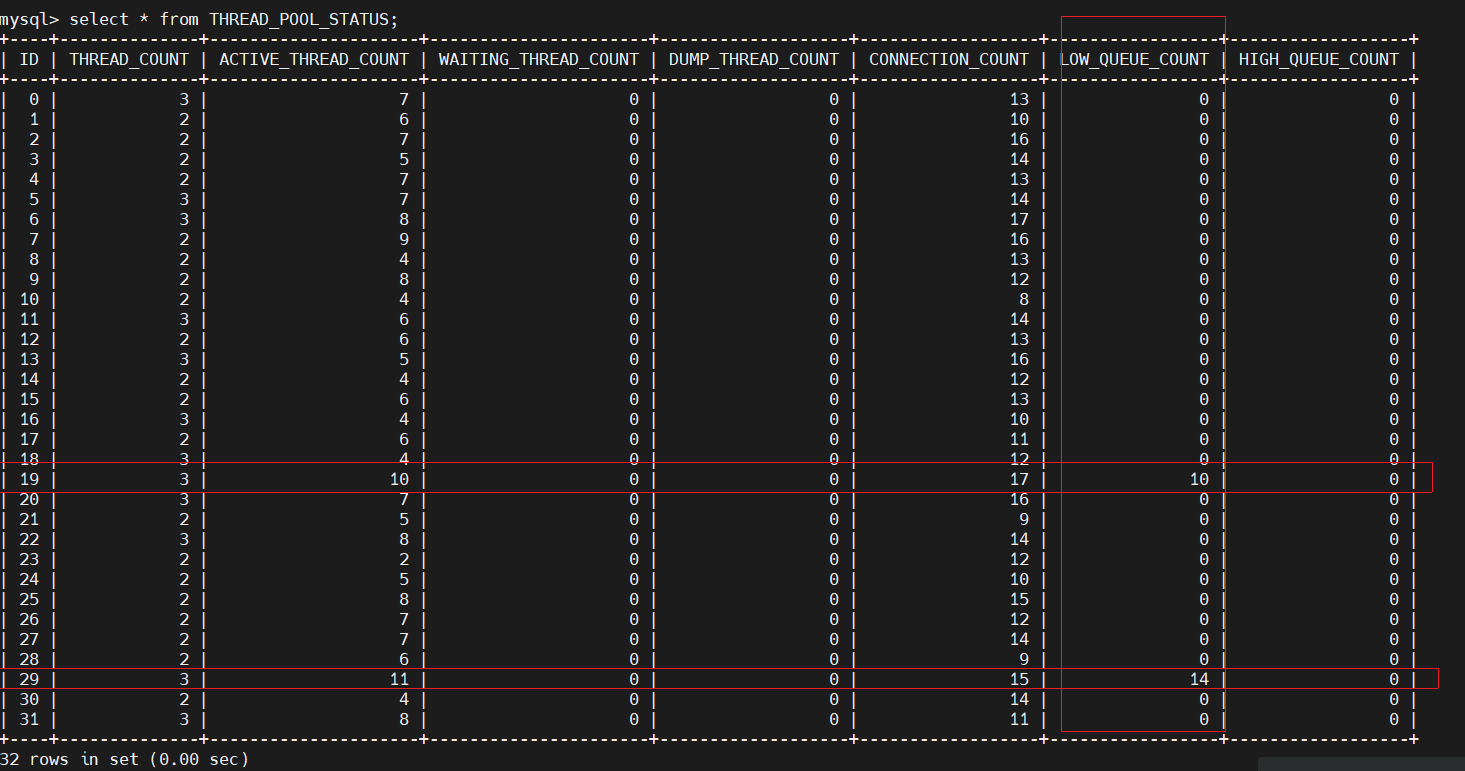
出问题时候的线程池 32个 group状态,有两个group queue count、active thread都明显到了瓶颈:select * from information_schema.THREAD_POOL_STATUS;
id 线程组id
thread_count // 当前线程组中的线程数量
active_thread_count //当前线程组中活跃线程数量,这个不包含dump线程
waiting_thread_count // 当前线程组中处于waiting状态的线程数量
dump_thread_count // dump类线程数量
slow_thread_timeout_count // 目前仅对DDL生效
connection_count // 当前线程组中的连接数量
low_queue_count // 低优先级队列中的请求数量
high_queue_count // 高优先级队列中的请求数量
waiting_thread_timeout_count // 处于waiting状态并且超时的线程数量
or: select sum(LOW_QUEUE_COUNT) from information_schema.thread_pool_status;
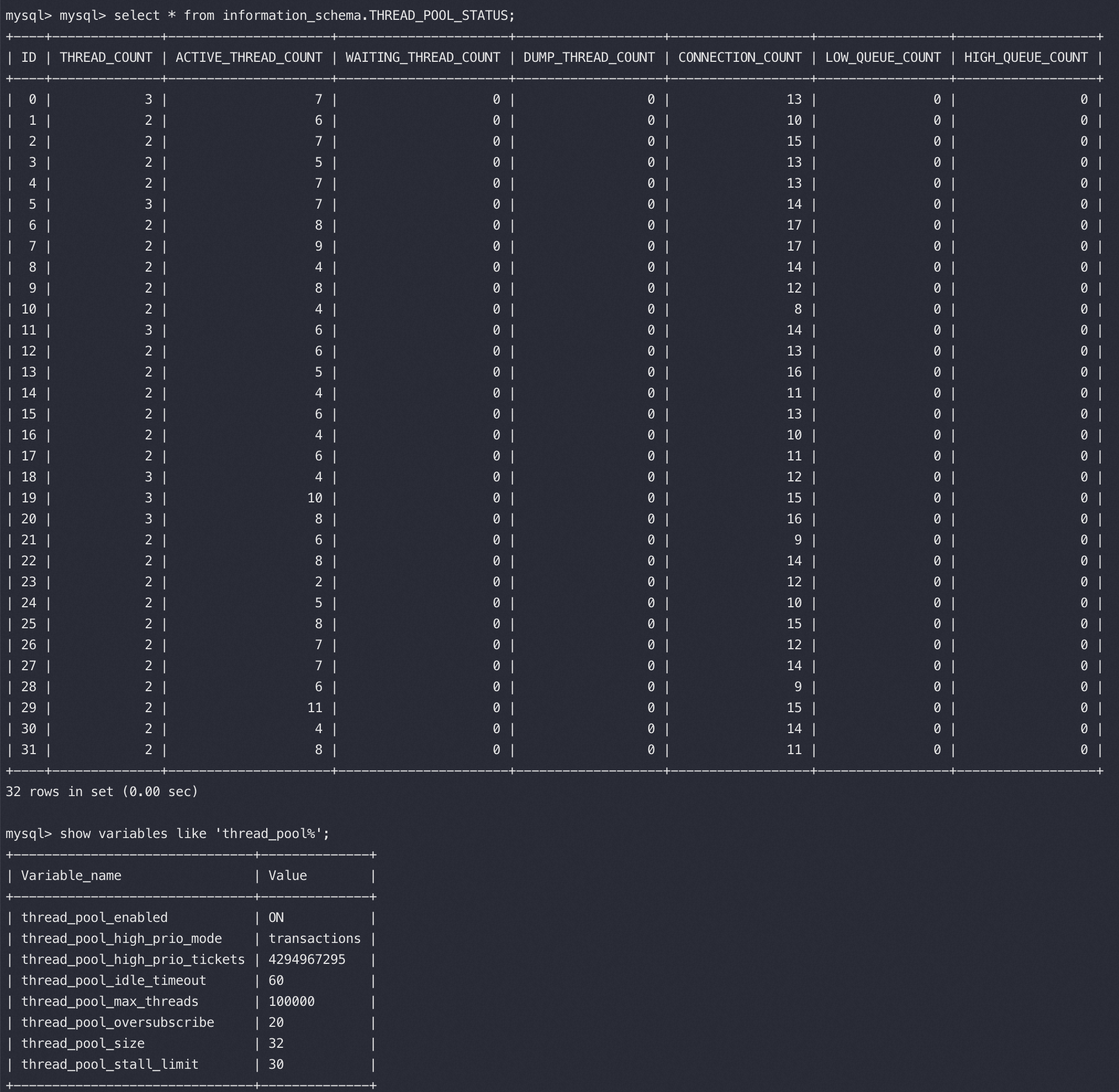
调整 thread_pool_oversubscribe由10到20后不卡了,这时的 pool status(重点注意 ACTIVE_THREAD_COUNT 数字没有任何变化):
看起来像是 ACTIVE_THREAD 全假死了,没有跑任务也不去take新任务一直卡在那里,类似线程泄露。查看了一下所有MySQLD 线程都是 S 的正常状态,并无异常。
继续分析统计了一下mysqld线程数量(157),远小于 thread pool 中的active线程数量(202),看起来像是计数器在线程异常(磁盘故障时)忘记 减减 了,导致计数器虚高进而无法新创建新线程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #top -H -b -n 1 -p 130650 |grep mysqld | wc -l 157 # mysql -e "select sum(THREAD_COUNT), sum(ACTIVE_THREAD_COUNT) from information_schema.THREAD_POOL_STATUS" +-------------------+--------------------------+ | sum(THREAD_COUNT) | sum(ACTIVE_THREAD_COUNT) | +-------------------+--------------------------+ | 71 | 206 | +-------------------+--------------------------+ # mysql -e "select sum(THREAD_COUNT), sum(ACTIVE_THREAD_COUNT) from information_schema.THREAD_POOL_STATUS" +-------------------+--------------------------+ | sum(THREAD_COUNT) | sum(ACTIVE_THREAD_COUNT) | +-------------------+--------------------------+ | 75 | 202 | +-------------------+--------------------------+ # mysql_secbox --exe-path=mysql -A -uroot -h127.0.0.1 -P3054 -e "select ID,THREAD_COUNT,ACTIVE_THREAD_COUNT AS ATC,CONNECTION_COUNT AS CC,LOW_QUEUE_COUNT,HIGH_QUEUE_COUNT from information_schema.THREAD_POOL_STATUS" +----+--------------+-----+----+-----------------+------------------+ | ID | THREAD_COUNT | ATC | CC | LOW_QUEUE_COUNT | HIGH_QUEUE_COUNT | +----+--------------+-----+----+-----------------+------------------+ | 0 | 3 | 7 | 13 | 0 | 0 | | 19 | 3 | 10 | 14 | 0 | 0 | | 20 | 3 | 8 | 13 | 0 | 0 | | 21 | 2 | 5 | 9 | 0 | 0 | | 28 | 2 | 6 | 6 | 0 | 0 | //增加了一个active count,执行完毕后active thread count会减下去 | 29 | 2 | 12 | 14 | 0 | 0 | | 30 | 2 | 4 | 11 | 0 | 0 | | 31 | 2 | 8 | 10 | 0 | 0 | +----+--------------+-----+----+-----------------+------------------+
正常的thread_pool状态, ACTIVE_THREAD_COUNT极小且小于 THREAD_COUNT:
1 2 3 4 5 6 7 8 9 10 11 12 13 mysql> select ID,THREAD_COUNT,ACTIVE_THREAD_COUNT AS ATC,CONNECTION_COUNT AS CC,LOW_QUEUE_COUNT,HIGH_QUEUE_COUNT from information_schema.THREAD_POOL_STATUS; +----+--------------+-----+----+-----------------+------------------+ | ID | THREAD_COUNT | ATC | CC | LOW_QUEUE_COUNT | HIGH_QUEUE_COUNT | +----+--------------+-----+----+-----------------+------------------+ | 0 | 2 | 0 | 3 | 0 | 0 | | 1 | 2 | 0 | 2 | 0 | 0 | | 2 | 2 | 0 | 2 | 0 | 0 | | 3 | 2 | 0 | 2 | 0 | 0 | | 4 | 2 | 0 | 4 | 0 | 0 | | 5 | 2 | 0 | 3 | 0 | 0 | | 6 | 2 | 0 | 4 | 0 | 0 | | 7 | 2 | 0 | 4 | 0 | 0 | +----+--------------+-----+----+-----------------+------------------+
MySQL 原有线程调度方式有每个连接一个线程(one-thread-per-connection)和所有连接一个线程(no-threads)。
no-threads一般用于调试,生产环境一般用one-thread-per-connection方式。one-thread-per-connection 适合于低并发长连接的环境,而在高并发或大量短连接环境下,大量创建和销毁线程,以及线程上下文切换,会严重影响性能。另外 one-thread-per-connection 对于大量连接数扩展也会影响性能。
为了解决上述问题,MariaDB、Percona、Aliyun RDS、Oracle MySQL 都推出了线程池方案,它们的实现方式大体相似,这里以 Percona 为例来简略介绍实现原理,同时会介绍我们在其基础上的一些改进。
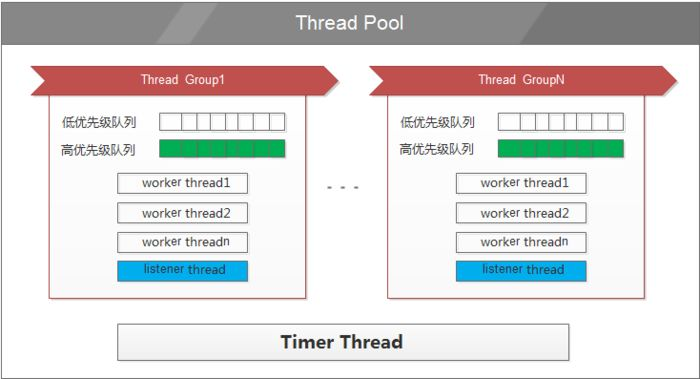
线程池由一系列 worker 线程组成,这些worker线程被分为thread_pool_size个group。用户的连接按 round-robin 的方式映射到相应的group 中,一个连接可以由一个group中的一个或多个worker线程来处理。
thread_pool_oversubscribe 一个group中活跃线程和等待中的线程超过thread_pool_oversubscribe时,不会创建新的线程。 此参数可以控制系统的并发数,同时可以防止调度上的死锁,考虑如下情况,A、B、C三个事务,A、B 需等待C提交。A、B先得到调度,同时活跃线程数达到了thread_pool_max_threads上限,随后C继续执行提交,此时已经没有线程来处理C提交,从而导致A、B一直等待。thread_pool_oversubscribe控制group中活跃线程和等待中的线程总数,从而防止了上述情况。
MySQL Thread Pool之所以分成多个小的Thread Group Pool而不是一个大的Pool,是为了分解锁(每个group中都有队列,队列需要加锁。类似ConcurrentHashMap提高并发的原理),提高并发效率。另外如果对每个Pool的 Worker做CPU 亲和性绑定也会对cache更友好、效果更高
group中又有多个队列,用来区分优先级的,事务中的语句会放到高优先队列(非事务语句和autocommit 都会在低优先队列);等待太久的SQL也会挪到高优先队列,防止饿死。
比如启用Thread Pool后,如果出现多个慢查询,容易导致拨测类请求超时,进而出现Server异常的判断(类似Nginx 边缘触发问题);或者某个group满后导致慢查询和拨测失败之类的问题
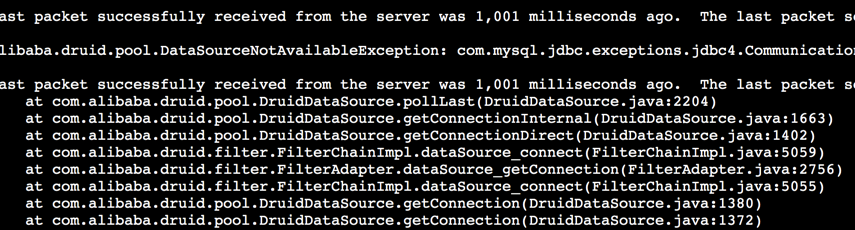
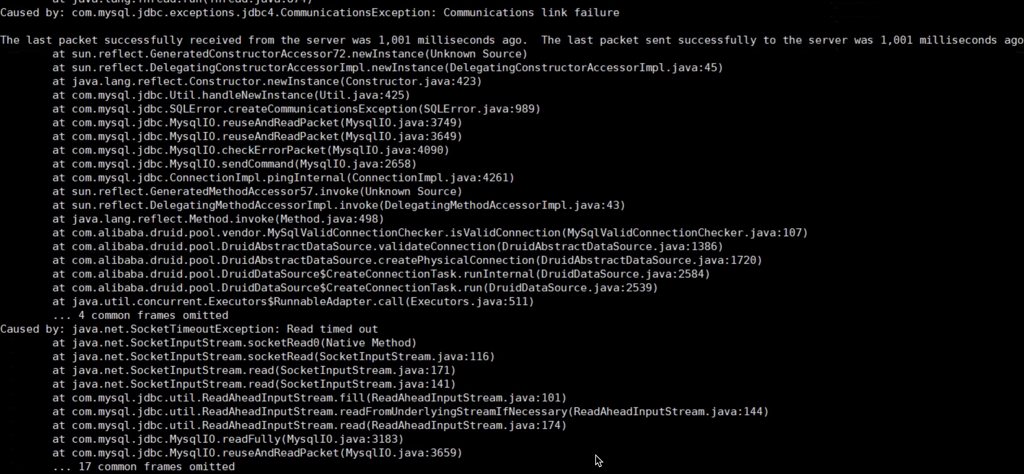
thread_pool_size 过小的案例 应用出现大量1秒超时报错:
分析代码,这个Druid报错堆栈是数据库连接池在创建到MySQL的连接后或者从连接池取一个连接给业务使用前会发送一个ping来验证下连接是否有效,有效后才给应用使用。说明TCP连接创建成功,但是MySQL 超过一秒钟都没有响应这个 ping,说明 MySQL处理指令缓慢。
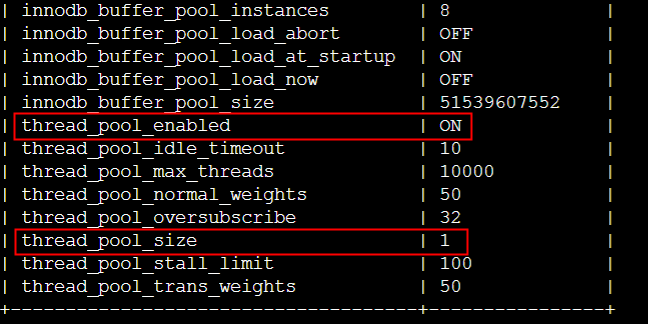
继续分析MySQL的参数:
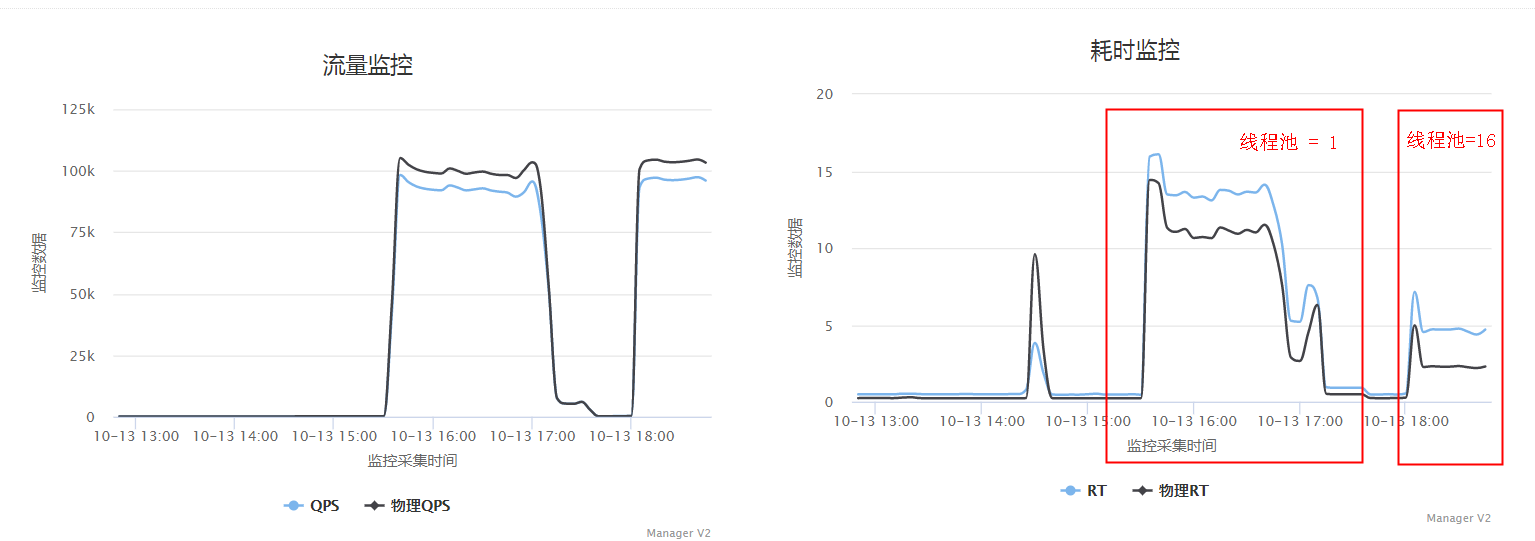
可以看到thread_pool_size是1,太小了,将所有MySQL线程都放到一个buffer里面来抢锁,锁冲突的概率太高。调整到16后可以明显看到MySQL的RT从原来的12ms下降到了3ms不到,整个QPS大概有8%左右的提升。这是因为pool size为1的话所有sql都在一个队列里面,多个worker thread加锁等待比较严重,导致rt延迟增加。
这个问题发现是因为压力一上来的时候要创建大量新的连接,这些连结创建后会去验证连接的有效性,也就是Druid给MySQL发一个ping指令,一般都很快,同时Druid对这个valid操作设置了1秒的超时时间,从实际看到大量超时异常堆栈,从而发现MySQL内部响应有问题。
MySQL ping 和 MySQL 协议相关知识
Ping use the JDBC method Connection.isValid(int timeoutInSecs) . Digging into the MySQL Connector/J source, the actual implementation uses com.mysql.jdbc.ConnectionImpl.pingInternal() to send a simple ping packet to the DB and returns true as long as a valid response is returned.
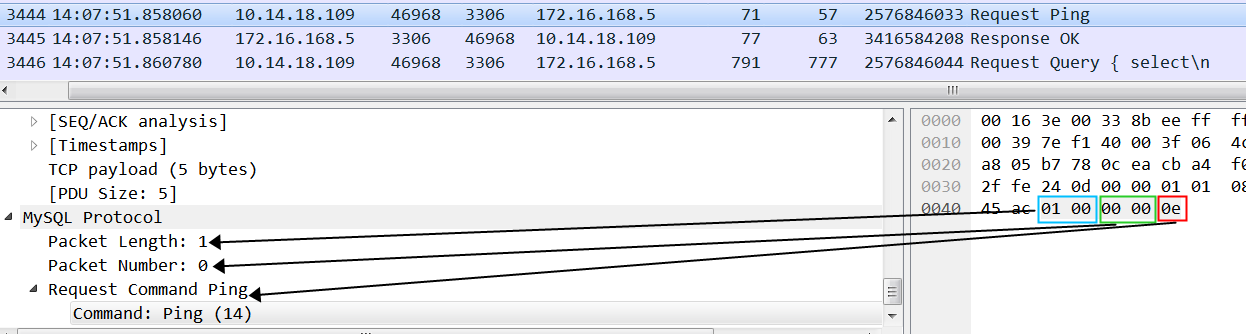
MySQL ping protocol是发送了一个 0e 的byte标识给Server,整个包加上2byte的Packet Length(内容为:1),2byte的Packet Number(内容为:0),总长度为5 byte。Druid、DRDS默认都会 testOnBorrow,所以每个连接使用前都会先做ping。
1 2 3 4 5 6 7 8 9 10 11 12 public class MySQLPingPacket implements CommandPacket { private final WriteBuffer buffer = new WriteBuffer(); public MySQLPingPacket() { buffer.writeByte((byte) 0x0e); } public int send(final OutputStream os) throws IOException { os.write(buffer.getLengthWithPacketSeq((byte) 0)); // Packet Number os.write(buffer.getBuffer(),0,buffer.getLength()); // Packet Length 固定为1 os.flush(); return 0; } }
也就是一个TCP包中的Payload为 MySQL协议中的内容长度 + 4(Packet Length+Packet Number):https://dev.mysql.com/doc/dev/mysql-server/8.4.2/page_protocol_com_ping.html
线程池卡死案例:show stats导致集群3406监控卡死 现象 应用用于获取监控信息的端口 3406卡死,监控脚本无法连接上3406,监控没有数据(需要从3406采集)、DDL操作、show processlist、show stats操作卡死(需要跟整个集群的3406端口同步)。
通过jstack看到应用进程的3406端口线程池都是这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 "ManagerExecutor-1-thread-1" #47 daemon prio=5 os_prio=0 tid=0x00007fe924004000 nid=0x15c runnable [0x00007fe9034f4000 ] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116 ) at java.net.SocketInputStream.read(SocketInputStream.java:171 ) at java.net.SocketInputStream.read(SocketInputStream.java:141 ) at com.mysql.jdbc.util.ReadAheadInputStream.fill(ReadAheadInputStream.java:101 ) at com.mysql.jdbc.util.ReadAheadInputStream.readFromUnderlyingStreamIfNecessary(ReadAheadInputStream.java:144 ) at com.mysql.jdbc.util.ReadAheadInputStream.read(ReadAheadInputStream.java:174 ) - locked <0x0000000722538b60 > (a com.mysql.jdbc.util.ReadAheadInputStream) at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:3005 ) at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3466 ) at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3456 ) at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3897 ) at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2524 ) at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2677 ) at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2545 ) - locked <0x00000007432e19c8 > (a com.mysql.jdbc.JDBC4Connection) at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2503 ) at com.mysql.jdbc.StatementImpl.executeQuery(StatementImpl.java:1369 ) - locked <0x00000007432e19c8 > (a com.mysql.jdbc.JDBC4Connection) at com.alibaba.druid.pool.ValidConnectionCheckerAdapter.isValidConnection(ValidConnectionCheckerAdapter.java:44 ) at com.alibaba.druid.pool.DruidAbstractDataSource.testConnectionInternal(DruidAbstractDataSource.java:1298 ) at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1057 ) at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:997 ) at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:987 ) at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:103 ) at com.taobao.tddl.atom.AbstractTAtomDataSource.getConnection(AbstractTAtomDataSource.java:32 ) at com.alibaba.cobar.ClusterSyncManager$1. run(ClusterSyncManager.java:60 ) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511 ) at java.util.concurrent.FutureTask.run(FutureTask.java:266 ) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511 ) at java.util.concurrent.FutureTask.run(FutureTask.java:266 ) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1152 ) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:627 ) at java.lang.Thread.run(Thread.java:882 )
原因
用户监控采集数据通过访问3306端口上的show stats,这个show stats命令要访问集群下所有节点的3406端口来执行show stats,3406端口上是一个大小为8个的Manager 线程池在执行这些show stats命令,导致占满了manager线程池的8个线程,每个3306的show stats线程都在wait 所有节点3406上的子任务的返回
每个子任务的线程,都在等待向集群所有节点3406端口的manager建立连接,建连接后会先执行testValidatation操作验证连接的有效性,这个验证操作会执行SQL Query:select 1,这个query请求又要申请一个manager线程才能执行成功
默认isValidConnection操作没有超时时间,如果Manager线程池已满后需要等待至socketTimeout后才会返回,导致这里出现卡死,还不如快速返回错误,可以增加超时来改进
从线程栈来说,就是出现了活锁
解决方案
增加manager线程池大小
代码逻辑上优化3406 jdbc连接池参数,修改jdbc默认的socketTimeout超时时间以及替换默认checker(一般增加一个1秒超时的checker)
对于checker,参考druid的实现,com/alibaba/druid/pool/vendor/MySqlValidConnectionChecker.java:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 public boolean isValidConnection (Connection conn, String validateQuery, int validationQueryTimeout) throws Exception { if (conn.isClosed()) { return false ; } if (usePingMethod) { if (conn instanceof DruidPooledConnection) { conn = ((DruidPooledConnection) conn).getConnection(); } if (conn instanceof ConnectionProxy) { conn = ((ConnectionProxy) conn).getRawObject(); } if (clazz.isAssignableFrom(conn.getClass())) { if (validationQueryTimeout <= 0 ) { validationQueryTimeout = DEFAULT_VALIDATION_QUERY_TIMEOUT; } try { ping.invoke(conn, true , validationQueryTimeout * 1000 ); } catch (InvocationTargetException e) { Throwable cause = e.getCause(); if (cause instanceof SQLException) { throw (SQLException) cause; } throw e; } return true ; } } String query = validateQuery; if (validateQuery == null || validateQuery.isEmpty()) { query = DEFAULT_VALIDATION_QUERY; } Statement stmt = null ; ResultSet rs = null ; try { stmt = conn.createStatement(); if (validationQueryTimeout > 0 ) { stmt.setQueryTimeout(validationQueryTimeout); } rs = stmt.executeQuery(query); return true ; } finally { JdbcUtils.close(rs); JdbcUtils.close(stmt); } } public final static String DEFAULT_DRUID_MYSQL_VALID_CONNECTION_CHECKERCLASS = "com.alibaba.druid.pool.vendor.MySqlValidConnectionChecker" ; String validConnnectionCheckerClassName = TAtomConstants.DEFAULT_DRUID_MYSQL_VALID_CONNECTION_CHECKERCLASS; try { Class.forName(validConnnectionCheckerClassName); localDruidDataSource.setValidConnectionCheckerClassName(validConnnectionCheckerClassName);
这种线程池打满特别容易在分布式环境下出现,除了以上案例比如还有:
分库分表业务线程池,接收一个逻辑 SQL,如果需要查询1024分片的sort merge join,相当于派生了一批子任务,每个子任务占用一个线程,父任务等待子任务执行后返回数据。如果这样的逻辑SQL同时来一批并发,就会出现父任务都在等子任务,子任务又因为父任务占用了线程,导致子任务也在等着从线程池中取线程,这样父子任务就进入了死锁
比如并行执行的SQL MPP线程池也有这个问题,多个查询节点收到SQL,拆分出子任务做并行,互相等待资源
X应用对分布式任务打挂线程池的优化 对如下这种案例:
X 应用通过线程池来接收一个逻辑SQL并处理,如果需要查询1024分片的sort merge join,相当于派生了1024个子任务,每个子任务占用一个线程,父任务等待子任务执行后返回数据。如果这样的逻辑SQL同时来一批并发,就会出现父任务都在等子任务,子任务又因为父任务占用了线程,导致子任务也在等着从线程池中取线程,这样父子任务就进入了死锁
首先X对执行SQL 的线程池分成了多个bucket,每个SQL只跑在一个bucket里面的线程上,同时通过滑动窗口向线程池提交任务数,来控制并发量,进而避免线程池的死锁、活锁问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public static final ServerThreadPool create (String name, int poolSize, int deadLockCheckPeriod, int bucketSize) { return new ServerThreadPool (name, poolSize, deadLockCheckPeriod, bucketSize); } public ServerThreadPool (String poolName, int poolSize, int deadLockCheckPeriod, int bucketSize) { this .poolName = poolName; this .deadLockCheckPeriod = deadLockCheckPeriod; this .numBuckets = bucketSize; this .executorBuckets = new ThreadPoolExecutor [bucketSize]; int bucketPoolSize = poolSize / bucketSize; this .poolSize = bucketPoolSize; for (int bucketIndex = 0 ; bucketIndex < bucketSize; bucketIndex++) { ThreadPoolExecutor executor = new ThreadPoolExecutor (bucketPoolSize, bucketPoolSize, 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>(), new NamedThreadFactory (poolName + "-bucket-" + bucketIndex, true )); executorBuckets[bucketIndex] = executor; } this .lastCompletedTaskCountBuckets = new long [bucketSize]; if (deadLockCheckPeriod > 0 ) { this .timer = new Timer (SERVER_THREAD_POOL_TIME_CHECK, true ); buildCheckTask(); this .timer.scheduleAtFixedRate(checkTask, deadLockCheckPeriod, deadLockCheckPeriod); } }
通过bucketSize将一个大的线程池分成多个小的线程池,每个SQL 控制跑在一个小的线程池中,这里和MySQL的thread_pool是同样的设计思路,当然MySQL 的thread_pool主要是为了改进大锁的问题。
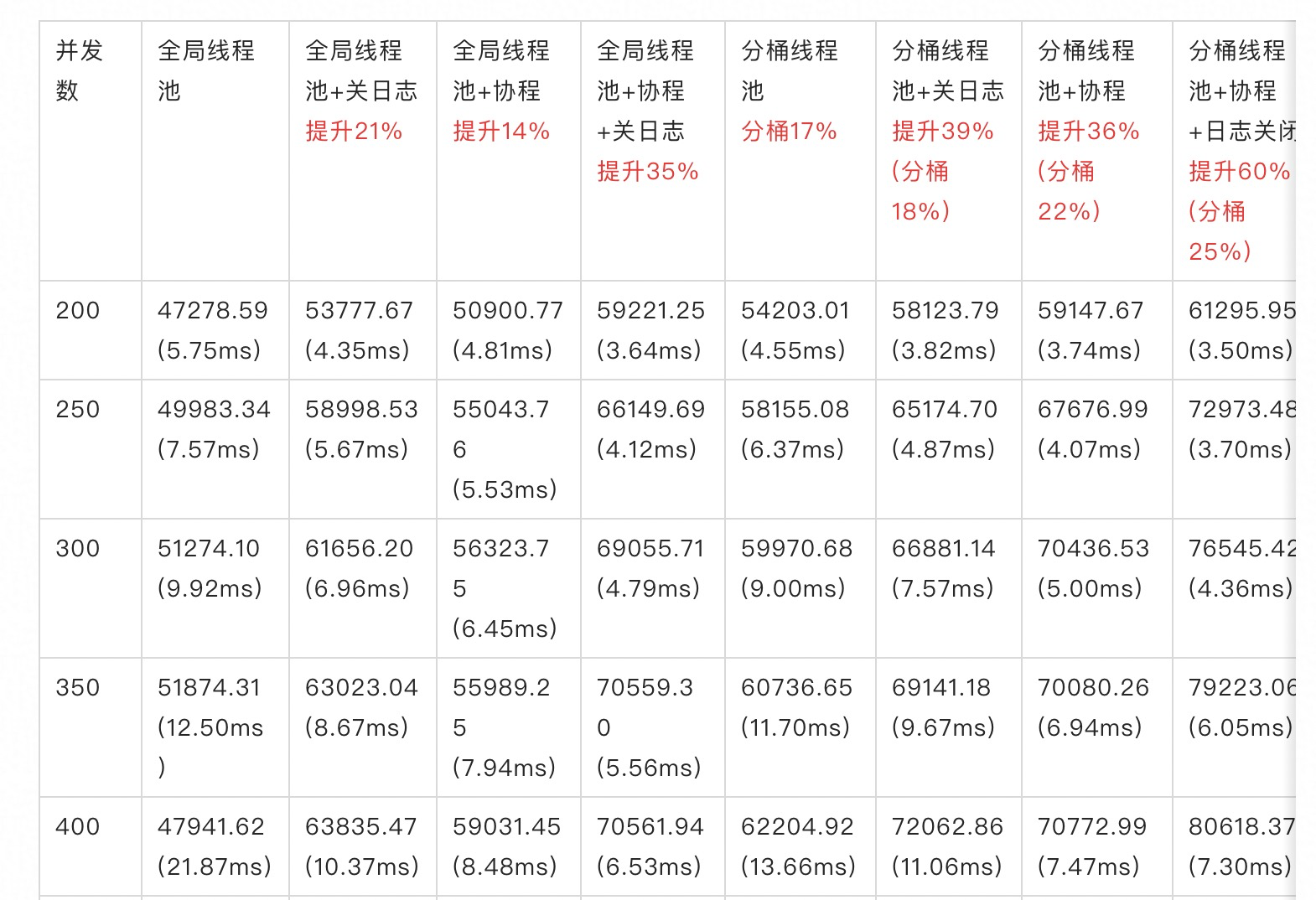
另外DRDS上线程池拆分后性能也有提升:
测试结果说明:(以全局线程池为基准,分别关注:关日志、分桶线程池、协程)
关日志,整体性能提升在20%左右 (8core最好成绩在6.4w qps)
协程,整体性能15%左右
关日志+协程,整体提升在35%左右 (8core最好成绩在7w qps)
分桶,整体性能提升在18%左右
分桶+关日志,整体提升在39%左右 (8core最好成绩在7.4w qps)
分桶+协程,整体提升在36%左右
分桶+关日志+协程,整体提升在60%左右 (8core最好成绩在8.3w qps)
线程池拆成多个bucket优化分析 拆分前锁主要是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 Started [lock] profiling --- Execution profile --- Total samples: 496 Frame buffer usage: 0.0052 % --- 352227700 ns (53.09 %), 248 samples [ 0 ] java.util.Properties [ 1 ] java.util.Hashtable.get [ 2 ] java.util.Properties.getProperty [ 3 ] com.taobao.tddl.common.properties.SystemPropertiesHelper.getPropertyValue [ 4 ] com.taobao.tddl.executor.MatrixExecutor.configMppExecutionContext [ 5 ] com.taobao.tddl.executor.MatrixExecutor.optimize [ 6 ] com.taobao.tddl.matrix.jdbc.TConnection.optimizeThenExecute [ 7 ] com.taobao.tddl.matrix.jdbc.TConnection.executeSQL [ 8 ] com.taobao.tddl.matrix.jdbc.TPreparedStatement.executeSQL [ 9 ] com.taobao.tddl.matrix.jdbc.TStatement.executeInternal [10 ] com.taobao.tddl.matrix.jdbc.TPreparedStatement.execute [11 ] com.alibaba.cobar.server.ServerConnection.innerExecute [12 ] com.alibaba.cobar.server.ServerConnection.innerExecute [13 ] com.alibaba.cobar.server.ServerConnection$1. run [14 ] com.taobao.tddl.common.utils.thread.FlowControlThreadPool$RunnableAdapter.run [15 ] java.util.concurrent.Executors$RunnableAdapter.call [16 ] java.util.concurrent.FutureTask.run [17 ] java.util.concurrent.ThreadPoolExecutor.runWorker [18 ] java.util.concurrent.ThreadPoolExecutor$Worker.run [19 ] java.lang.Thread.run --- 307781689 ns (46.39 %), 243 samples [ 0 ] java.util.Properties [ 1 ] java.util.Hashtable.get [ 2 ] java.util.Properties.getProperty [ 3 ] com.taobao.tddl.common.properties.SystemPropertiesHelper.getPropertyValue [ 4 ] com.taobao.tddl.config.ConfigDataMode.isDrdsMasterMode [ 5 ] com.taobao.tddl.matrix.jdbc.TConnection.updatePlanManagementInfo [ 6 ] com.alibaba.cobar.server.ServerConnection.innerExecute [ 7 ] com.alibaba.cobar.server.ServerConnection.innerExecute [ 8 ] com.alibaba.cobar.server.ServerConnection$1. run [ 9 ] com.taobao.tddl.common.utils.thread.FlowControlThreadPool$RunnableAdapter.run [10 ] java.util.concurrent.Executors$RunnableAdapter.call [11 ] java.util.concurrent.FutureTask.run [12 ] java.util.concurrent.ThreadPoolExecutor.runWorker [13 ] java.util.concurrent.ThreadPoolExecutor$Worker.run [14 ] java.lang.Thread.run --- 3451038 ns (0.52 %), 4 samples [ 0 ] java.lang.Object [ 1 ] sun.nio.ch.SocketChannelImpl.ensureReadOpen [ 2 ] sun.nio.ch.SocketChannelImpl.read [ 3 ] com.alibaba.cobar.net.AbstractConnection.read [ 4 ] com.alibaba.cobar.net.NIOReactor$R.read [ 5 ] com.alibaba.cobar.net.NIOReactor$R.run [ 6 ] java.lang.Thread.run --- 4143 ns (0.00 %), 1 sample [ 0 ] com.taobao.tddl.common.IdGenerator [ 1 ] com.taobao.tddl.common.IdGenerator.nextId [ 2 ] com.alibaba.cobar.server.ServerConnection.genTraceId [ 3 ] com.alibaba.cobar.server.ServerQueryHandler.query [ 4 ] com.alibaba.cobar.net.FrontendConnection.query [ 5 ] com.alibaba.cobar.net.handler.FrontendCommandHandler.handle [ 6 ] com.alibaba.cobar.net.FrontendConnection$1. run [ 7 ] java.util.concurrent.ThreadPoolExecutor.runWorker [ 8 ] java.util.concurrent.ThreadPoolExecutor$Worker.run [ 9 ] java.lang.Thread.run ns percent samples top ---------- ------- ------- --- 660009389 99.48 % 491 java.util.Properties 3451038 0.52 % 4 java.lang.Object 4143 0.00 % 1 com.taobao.tddl.common.IdGenerator
com.taobao.tddl.matrix.jdbc.TConnection.optimizeThenExecute调用对应代码逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if (InsertSplitter.needSplit(sql, policy, extraCmd)) { executionContext.setDoingBatchInsertBySpliter(true ); InsertSplitter insertSplitter = new InsertSplitter (executor); resultCursor = insertSplitter.execute(sql,executionContext,policy, (String insertSql) -> optimizeThenExecute(insertSql, executionContext,trxPolicyModified)); } else { resultCursor = optimizeThenExecute(sql, executionContext,trxPolicyModified); } 最终会访问到: protected void configMppExecutionContext (ExecutionContext executionContext) { String instRole = (String) SystemPropertiesHelper.getPropertyValue(SystemPropertiesHelper.INST_ROLE); SqlType sqlType = executionContext.getSqlType(); 相当于执行每个SQL都要加锁访问HashMap(SystemPropertiesHelper.getPropertyValue),这里排队比较厉害
实际以上测试结果显示bucket对性能有提升这么大是不对的,刚好这个版本把对HashMap的访问去掉了,这才是提升的主要原因,当然如果线程池入队出队有等锁的话改成多个肯定是有帮助的,但是从等锁观察是没有这个问题的。
在这个代码基础上将bucket改成1,在4core机器下经过反复对比测试性能基本没有明显的差异,可能core越多这个问题会更明显些。总结
回到最开始部分查询卡顿这个问题,本质在于 MySQL线程池开启后,因为会将多个连接分配在一个池子中共享这个池子中的几个线程。导致一个池子中的线程特别慢的时候会影响这个池子中所有的查询都会卡顿。即使别的池子很空闲也不会将任务调度过去。
MySQL线程池设计成多个池子(Group)的原因是为了将任务队列拆成多个,这样每个池子中的线程只是内部竞争锁,跟其他池子不冲突,类似ConcurrentHashmap的实现,当然这个设计带来的问题就是多个池子中的任务不能均衡了。
同时从案例我们也可以清楚地看到这个池子太小会造成锁冲突严重的卡顿,池子太大(每个池子中的线程数量就少)容易造成等线程的卡顿。
**类似地这个问题也会出现在Nginx的多worker中,一旦一个连接分发到了某个worker,就会一直在这个worker上处理,如果这个worker上的某个连接有一些慢操作,会导致这个worker上的其它连接的所有操作都受到影响,特别是会影响一些探活任务的误判。**Nginx的worker这么设计也是为了将单worker绑定到固定的cpu,然后避免多核之间的上下文切换。
如果池子卡顿后,调用方有快速fail,比如druid的MySqlValidConnectionChecker,那么调用方从堆栈很快能发现这个问题,如果没有异常一直死等的话对问题的排查不是很友好。
另外可以看到分布式环境下死锁、活锁还是很容易产生的,想要一次性提前设计好比较难,需要不断踩坑爬坑。
参考文章 记一次诡异的数据库故障的排查过程
http://mysql.taobao.org/monthly/2016/02/09/
https://dbaplus.cn/news-11-1989-1.html
慢查询触发kill后导致集群卡死 把queryTimeout换成socketTimeout,这个不会发送kill,只会断开连接
青海湖、天津医保 RDS线程池过小导致DRDS查询卡顿问题排查