MySQL针对秒杀场景的优化
MySQL针对秒杀场景的优化
背景
对于秒杀热点场景,MySQL官方版本500 TPS每秒,在对MySQL优化前只能用redis来扛,redis没有事务能力,比如一个item下有多个sku就搞不定了。同时在前端搞限流、答题等让秒杀流量控制在可以承受的范围内。
过程
对于秒杀热点场景,MySQL官方版本扣减只能做到 500 TPS每秒,扛不住大促的流量,需要优化。从控制并发量将500优化到1400,再通过新语法来消除网络rtt对加锁时间的控制这样达到了 4000 TPS。最后合并多个扣减到一个,累积比如10ms提交,能将TPS 能升到4万以上这个能力。
排队控制并发
拍减模式在整个交易过程中只有一次扣减交互,所以是不需要付款减库存那样的判重逻辑,就是说,拍减的减库存sql只有一条update语句就搞定了。而付减有两条,一条insert判重+一条update减库存(双十一拍减接口在高峰的rt约为8ms,而付减接口在高峰的rt约为15ms);
其次,当大量请求(线程)落到mysql的同一条记录上进行减库存时,线程之间会存在竞争关系,因为要争夺InnoDB的行锁,当一个线程获得了行锁,其他并发线程就只能等待(InnoDB内部还有死锁检测等机制会严重影响性能),当并发度越高时,等待的线程就越多,此时tps会急剧下降,rt会飙升,性能就不能满足要求了。那如何减少锁竞争?答案是:排队!库存中心从几个层面做了排队策略。
首先,在应用端进行排队,因为很多商品都是有sku的,当sku库存变化时item的库存也要做相应变化,所以需要根据itemId来进行排队,相同itemId的减库存操作会进入串行化排队处理逻辑,不过应用端的排队只能做到单机内存排队,当应用服务器数量过多时,落到db的并发请求仍然很多,所以最好的办法是在db端也加上排队策略,今年库存中心db部署了两个的排队patch,一个叫“并发控制”,是做在InnoDB层的,另一个叫“queue on pk”,是做在mysql的server层的,两个patch各有优缺点,前者不需要应用修改代码,db自动判断,后者需要应用程序写特殊的sql hint,前者控制的全局的sql,后者是根据hint来控制指定sql,两个patch的本质和应用端的排队逻辑是一致的,具体实现不同。双十一库存中心使用的是“并发控制”的patch。
2013年的单减库存TPS最高记录是1381次每秒。
对于秒杀热点场景,官方版本500tps每秒,问题在于同时涌入的请求太多,每次取锁都要检查其它等锁的线程(防止死锁),这个线程队列太长的话导致这个检查时间太长; 继续在前面增加能够进入到后面的并发数的控制,通过增加线程池、控制并发能到1400(no deadlock list check);
热点更新下的死锁检测(no deadlock list check)
由于热点更新是分布式的客户端并发的向单点的数据库进行了并行更新一条记录,到数据库最后是把并行的线程转行成串行的操作。但在串行操作的时候,由于对同一记录的锁申请列表过大,死锁检测的机制在检测锁队列的时候,反而拖慢了每一个更新。
原生版本的MySQL对于正常业务链接没有拒绝机制(除了TDDL的链接池或者MySQL的user_connnection不够用),对于同一行记录到innodb层修改的时候,凡是到innodb层的任务都必须拿到innodb_thread_concurrency的槽位才能执行(当然这里也有很多细节,这里就说最主要的代码改动点),举例来说:开启一个事务,对于id=1的行记录更新,进到innodb层,占着1个innodb_thread_concurrency,等到id=1的事务结束,会释放innodb_thread_concurrency,从而达到innodb_thread_concurrency的平衡;
再进一步,开启一个事务,对id=1的行记录更新进到innodb层,占着1个innodb_thread_concurrency,事务不提交(假设innodb_thread_concurrency=32),如果有下一个对id=1记录来更新的话,进到innodb层,又占着1个innodb_thread_concurrency,检测发现是对id=1的更新,排到第1个对id=1的队列的后面,同时释放innodb_thread_concurrency;以此类推这个链表有可能会很长比如1024;执行的时候又需要做死锁检测等一系列工作,都需要用到一个叫做kernel_mutex的mutex(这是一个全局互斥量用来管理锁系统,事务系统,MVCC多版本控制),对于大并发,整个链表非常长的时候,可想而知kernel_metex的竞争多么激烈,从而在链表检测的时间变长。
缩短锁时间
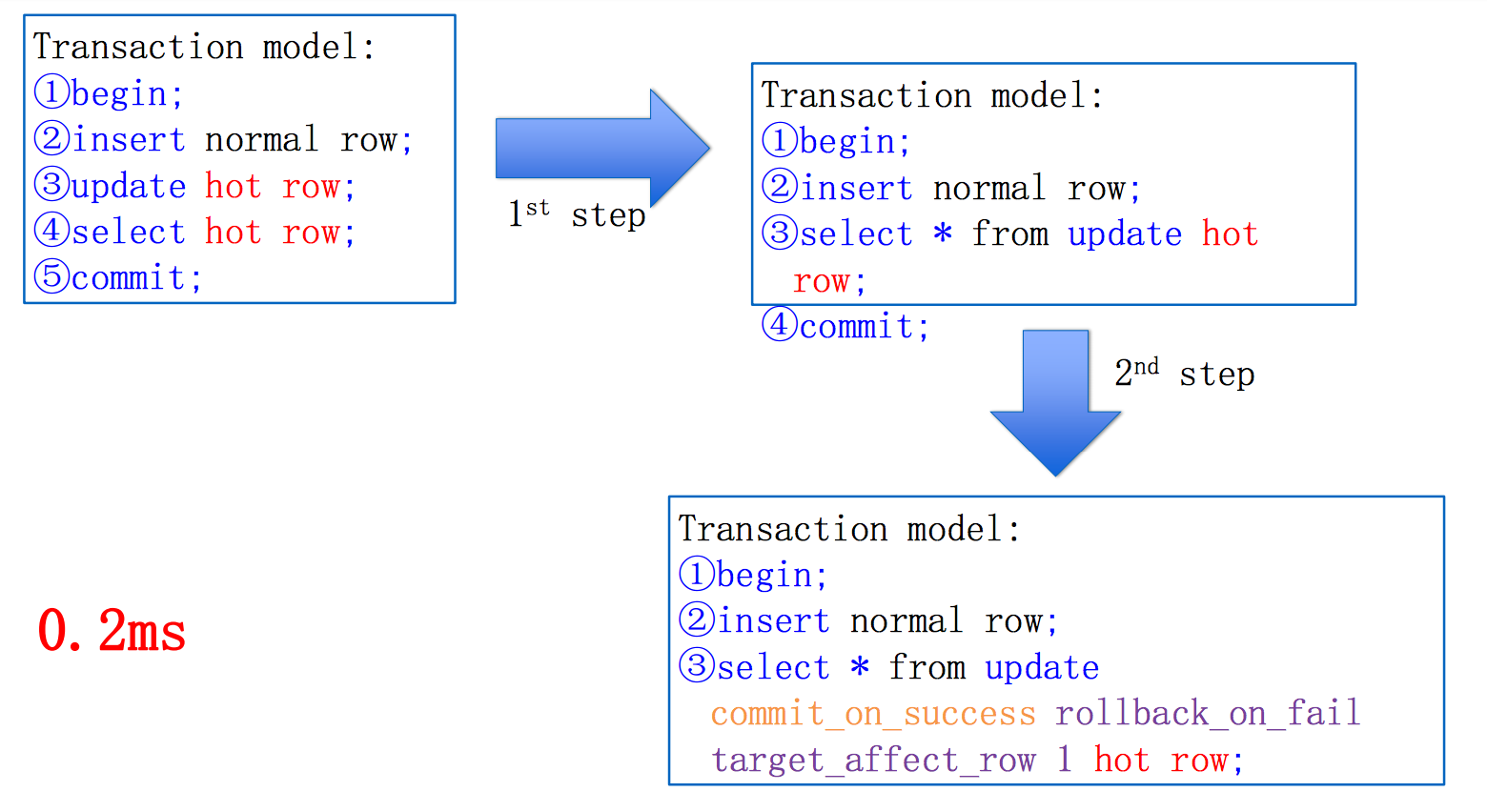
接下来的问题在于一个事务中有多条语句(最少也有一个update+一个commit),这样update(减库存,开始锁表),走网络,查询结果(走网络),commit,两次跨网络调用导致update锁行比较久,于是可以新造一个语法 select update一次搞定,继续优化 select update commit_on_success_or_fail_rollback,将所有操作一次网络操作全部搞定,能到4000;
比如库存扣减的业务逻辑可以简化为下面这个事务:
(1)begin;
(2)insert 交易流水表; – 交易流水对账
(3)update 库存明细表 where id in (sku_id,item_id);
(4)select 库存明细表;
(5)commit
SQL case:
1 | 4059550 Query SET autocommit=0 |
批量提交
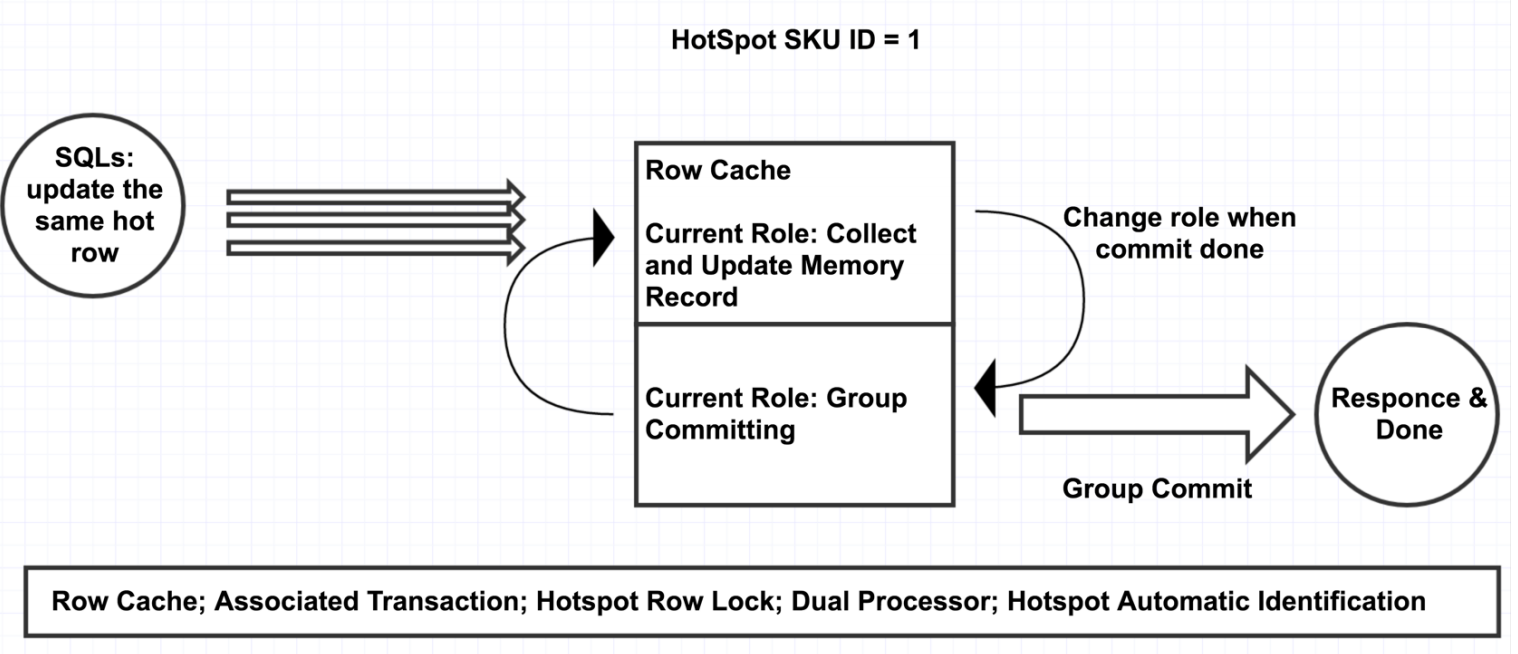
其主要的核心思想是:针对应用层SQL做轻量化改造,带上”热点行SQL”的hint,当这种SQL进入内核后,在内存中维护一个hash表,将主键或唯一键相同的请求(一般也就是同一商品id)hash到同一个地方做请求的合并,经过一段时间后(默认100us)统一提交,从而实现了将串行处理变成了批处理,让每个热点行更新请求并不需要都去扫描和更新btree。
- 热点的自动识别:前面已经讲过了,库存的扣减SQL都会有commit on success标记。mysql内部分为普通通道和热点扣减通道。普通通道里是正常的事务。热点通道里收集带有commit on success标记的事务。在一定的时间区间段内(0.1ms),将收集到的热点按照主键或者唯一键进行hash; hash到同一个桶中为相同的sku; 分批组提交这0.1ms收集到的热点商品。
- 轮询处理: 第一批进行提交时,第二批进行收集; 当第一批完成了提交开始收集时,第二批就可以进行提交了。不断轮询,提高效率
通过内存合并库存减操作,干到100000(每个减库存操作生成一条独立的update binlog,不影响其他业务2016年双11),实际这里还可以调整批提交时间间隔来进一步提升扣减QPS
超卖:付款减库存会超卖,拍减库存要防止恶意拍不付款。拍减的话可以通过增加SQL新语法来进一步优化DB响应(select update)
innodb_buffer_pool_instance: 将buffer pool 分成几个(hash),避免高并发修改的时候一个大锁mutex导致性能不高
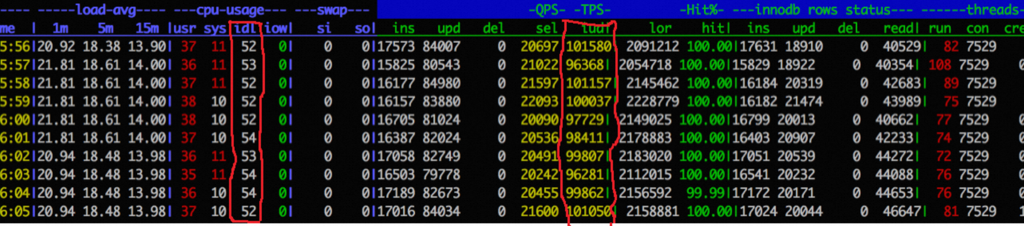
批量提交的压测效果:
业务优化
延迟扣减item,一般一个item下会有多个sku(比如 iPhone14 不同的颜色、配置就是一个不同的sku),而库存会有总库存(item),也有sku 库存,sku库存加起来就是item库存
导致扣减的时候 item库存更热