一次春节大促性能压测不达标的瓶颈推演
一次春节大促性能压测不达标的瓶颈推演
本文示范了教科书式的在分布式应用场景下如何通过一个节点的状态来推演分析瓶颈出在上下游的哪个环节上。
场景描述
某客户通过PTS(一个打压力工具)来压选号业务(HTTP服务在9108端口上),一个HTTP请求对应一次select seq-id 和 一次insert
PTS端看到RT900ms+,QPS大概5万(期望20万), 数据库代理服务 rt 5ms,QPS 10万+
链路:
pts发起压力 -> 5个eip -> slb -> app(300个容器运行tomcat监听9108端口上) -> slb -> 数据库代理服务集群 -> RDS集群
性能不达标,怀疑数据库代理服务或者RDS性能不行,作为数据库需要自证清白,所以从RDS和数据库代理服务开始分析问题在哪里。
略过一系列在数据库代理服务、RDS上分析数据和监控图表都证明数据库代理服务和RDS没问题的过程。
在明确给出证据数据库代理服务和RDS都没问题后还是要解决问题,所以只能进一步帮助前面的app来分析为什么性能不达标。
在其中一个app应用上抓包(00:18秒到1:04秒),到数据库代理服务的一个连接分析:

数据库代理服务每个HTTP请求的响应时间都控制在15ms(一个前端HTTP请求对应一个select seq-id,一个 select readonly, 一个insert, 这个响应时间符合预期)。一个连接每秒才收到20 tps(因为压力不够,压力加大的话这个单连接tps还可以增加), 20*3000 = 6万 , 跟压测看到基本一致
300个容器,每个容器 10个连接到数据库代理服务
如果300个容器上的并发压力不够的话就没法将3000个连接跑满,所以看到的QPS是5万。
从300个容器可以计算得到这个集群能支持的tps: 300*10(10个连接)* 1000/15(每秒钟每个连接能处理的请求数)=20万个tps (关键分析能力)
也就是说通过单QPS 15ms,我们计算可得整个后端的吞吐能力在20万QPS。所以目前问题不在后端,而是压力没有打到后端就出现瓶颈了。
9108的HTTP服务端口上的抓包分析
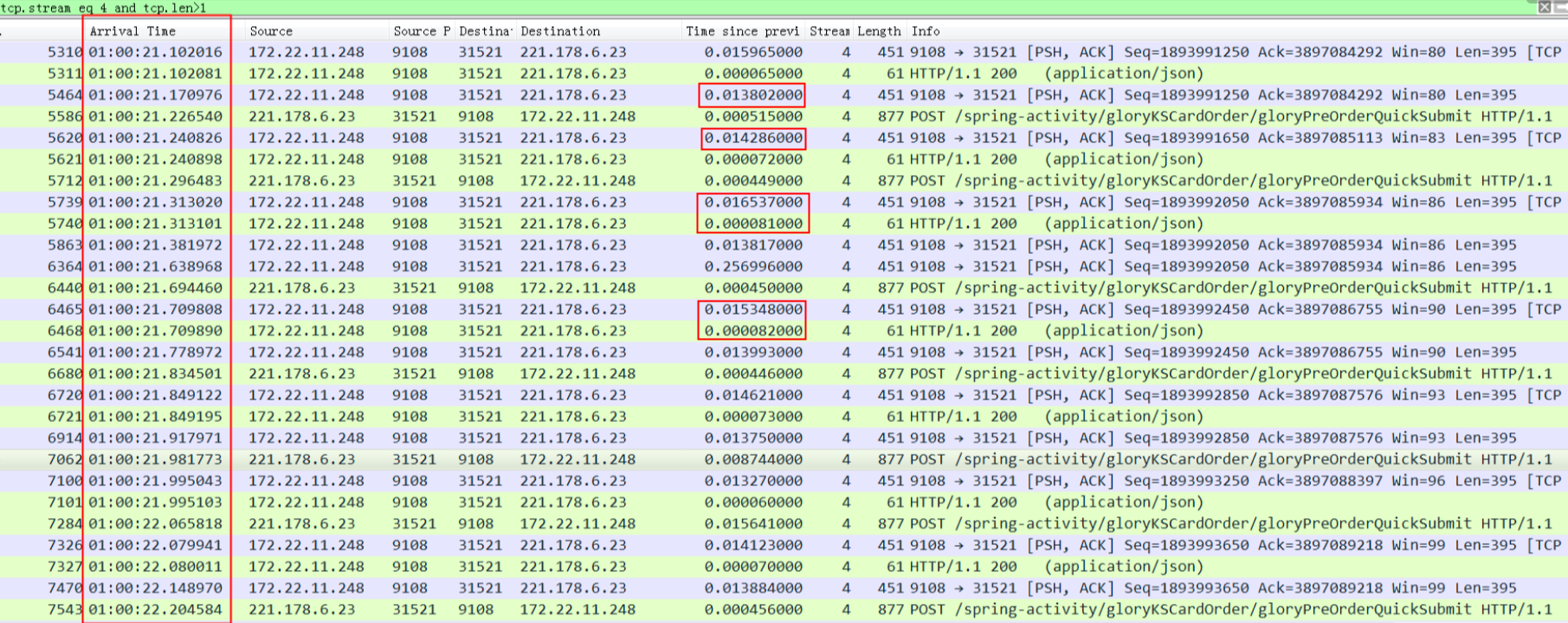
9108服务的每个HTTP response差不多都是15ms(这个响应时间基本符合预期),一个HTTP连接上在45秒的抓包时间范围只收到23个HTTP Request。
或者下图:
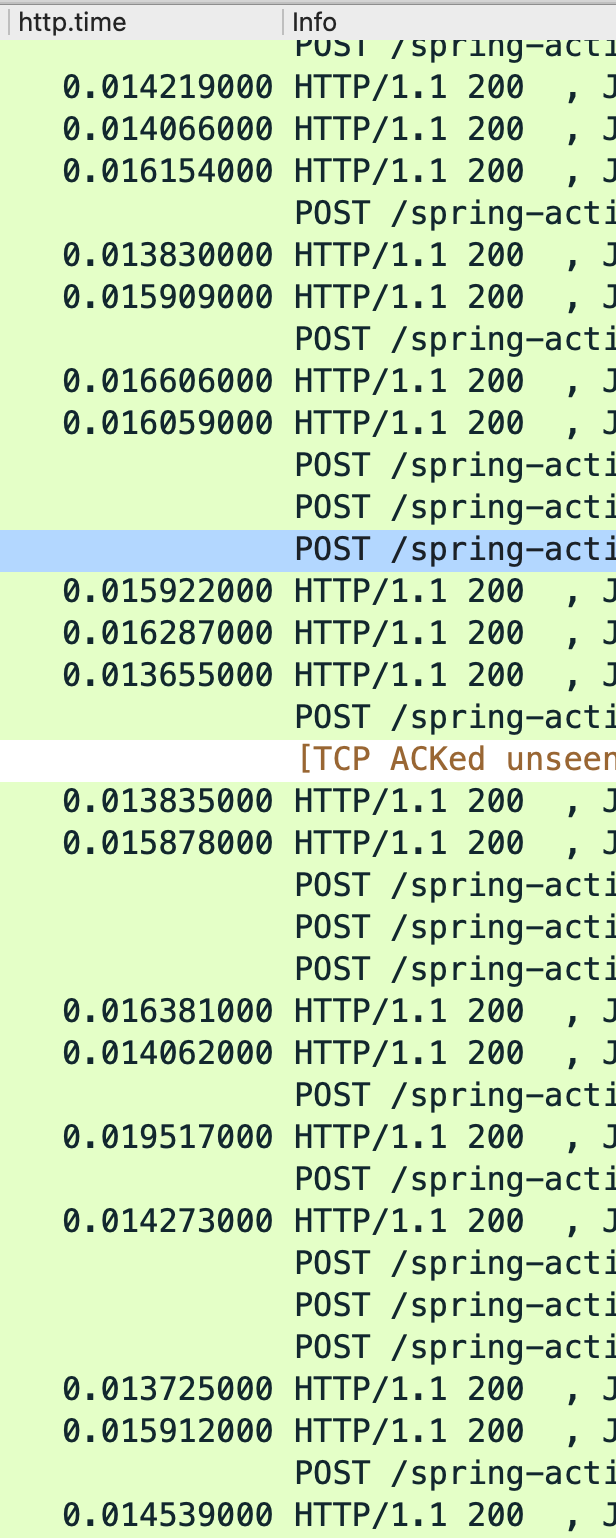
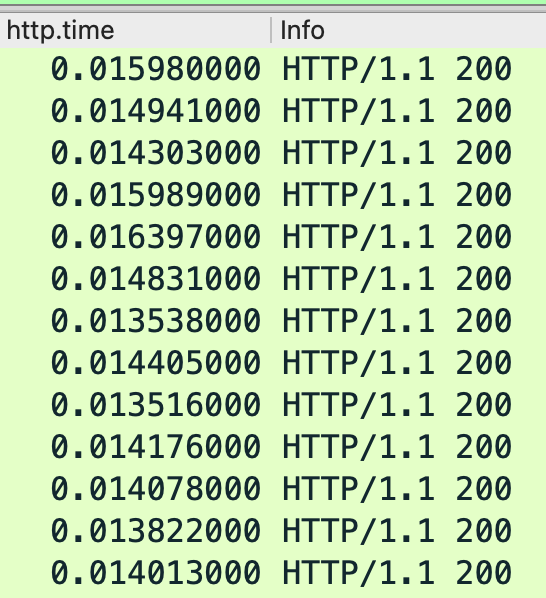
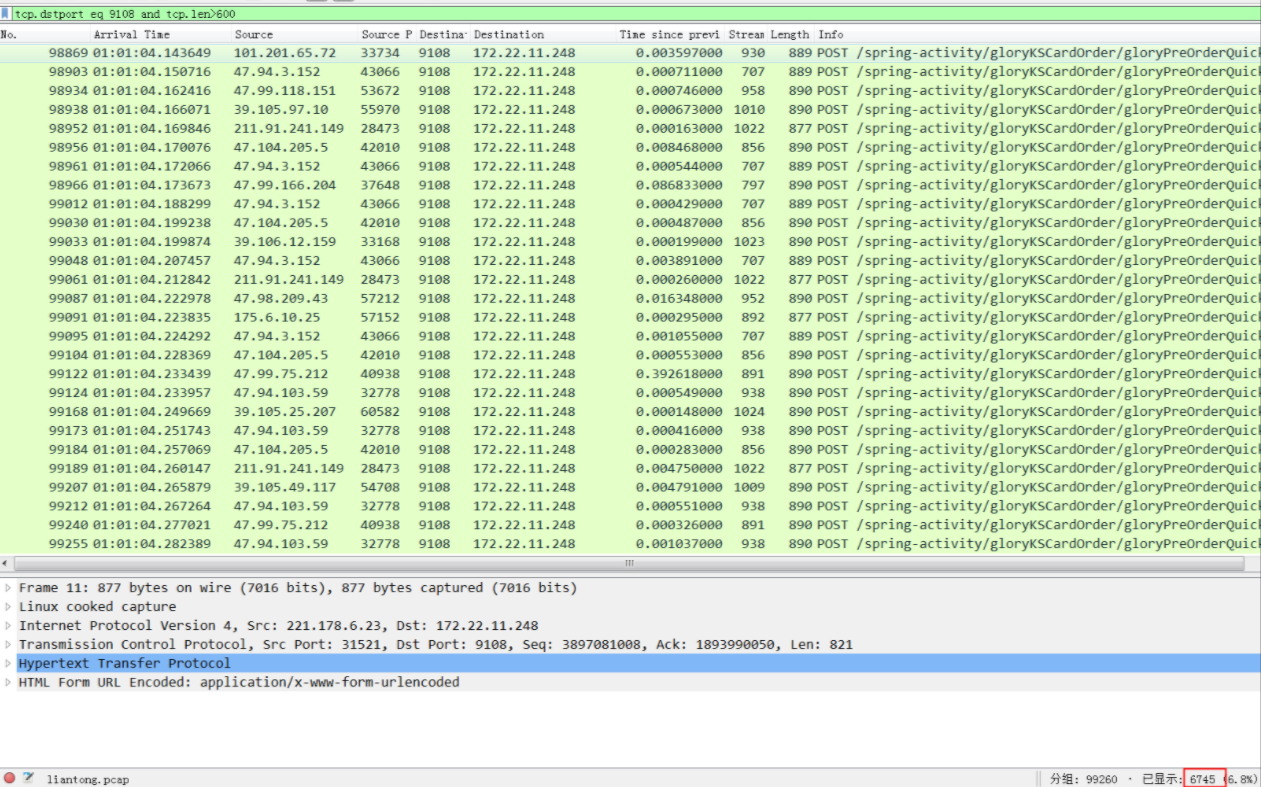
统计9108端口在45秒总共收到的HTTP请求数量是6745(如下图),也就是每个app每秒钟收到的请求是150个,300*150=4.5万(理论值,300个app可能压力分布不一样?),从这里看app收到的压力还不够,所以压力还没有打到应用容器中的app,还在更前面
后来从容器app监控也确认了这个响应时间和抓包看到的一致,所以从抓包分析http响应时间也基本得到15ms的rt关键结论
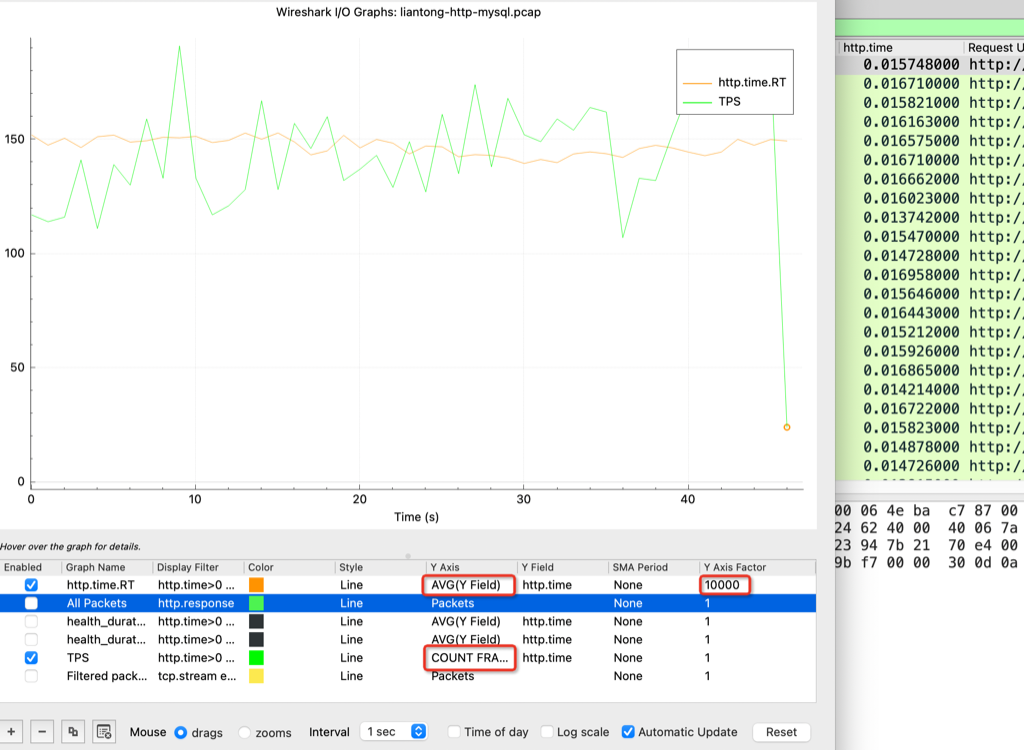
从wireshark IO Graphs 也能看到RT 和 QPS
从应用容器上的netstat统计来看,也是压力端回复太慢
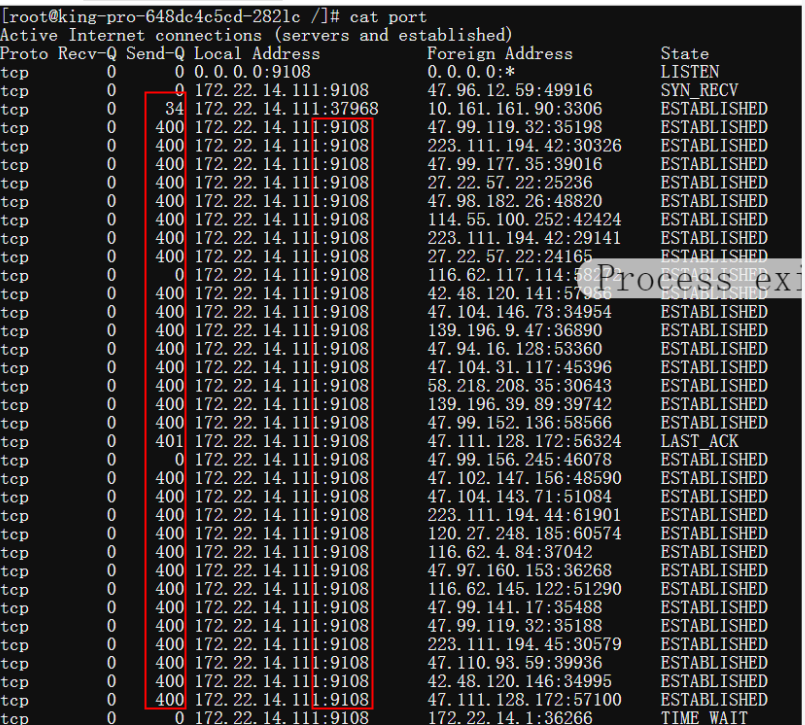
send-q表示回复从9108发走了,没收到对方的ack
ARMS监控分析9108端口上的RT
后来PTS的同学说ARMS可以捞到监控数据,如下是对rt时间降序排
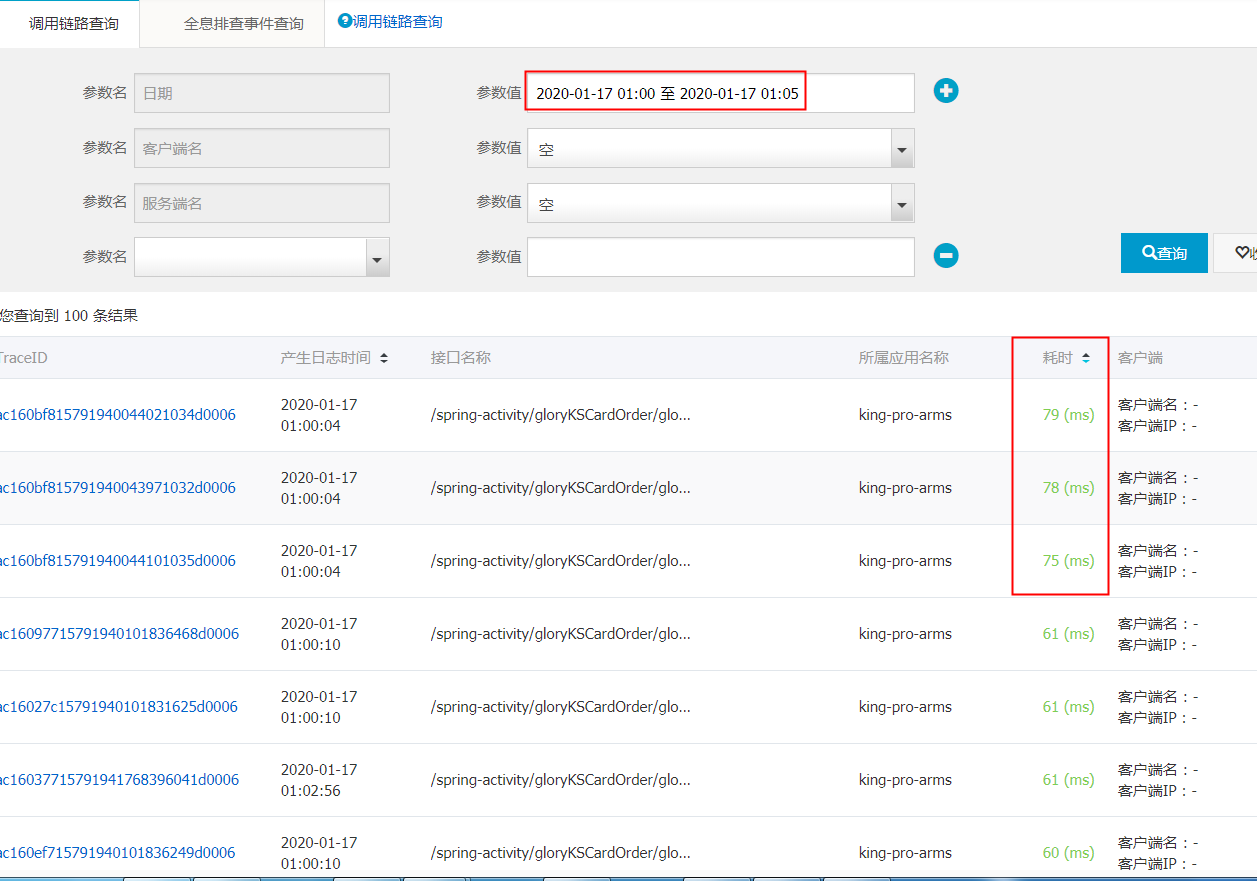
中的rt平均时间,可以看到http的rt确实14.4ms,表现非常平稳,从这个监控也发现实际app是330个而不是用户自己描述的300个,这也就是为什么实际是tps是5万,但是按300个去算的话tps是4.5万(不要纠结客户为什么告诉你是300个容器而不是330个,有时候他们也搞不清楚,业务封装得太好了)
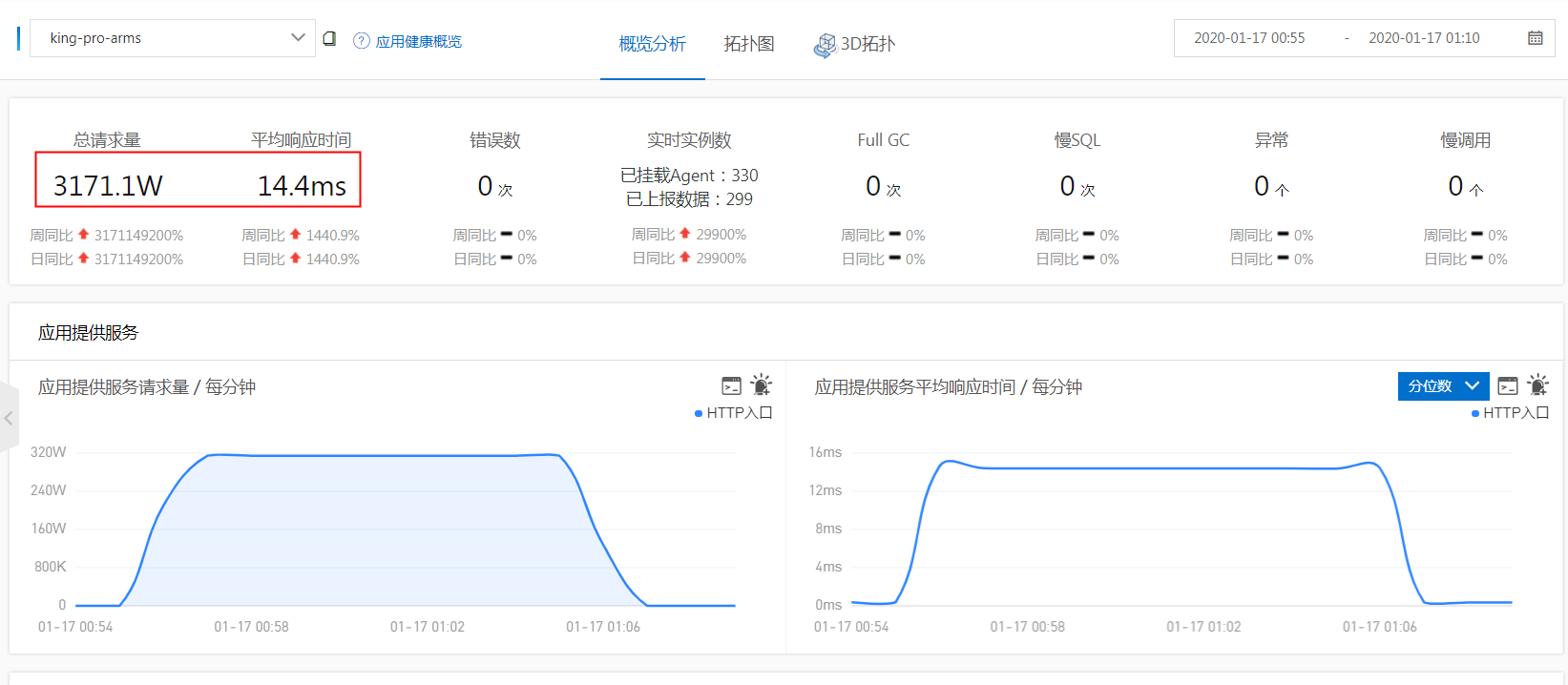
5分钟时间,QPS是5万+,HTTP的平均rt是15ms, HTTP的最大rt才79ms,和前面抓包分析一致。
从后端分析的总结
从9108端口响应时间15ms来看是符合预期的,为什么PTS看到的RT是900ms+,所以压力还没有打到APP上(也就是9108端口)
结论
最后发现是 eip 带宽不足,只有200M,调整到1G后 tps 也翻了5倍到了25万。
pts -> 5个eip(总带宽200M) -> slb -> app(330个HTTP容器) -> slb -> 数据库代理服务 -> RDS
这个案例有意思的地方是可以通过抓包就能分析出集群能扛的QPS20万(实际只有5万),那么可以把这个分析原则在每个角色上挨个分析一下,来看瓶颈出在了哪个环节。
应用端看到的rt是900ms,从后段开始往前面应用端来撸,看看每个环节的rt数据。
教训
- 搞清楚 请求 从发起端到DB的链路路径,比如 pts -> 5个eip(总带宽200M) -> slb -> app(330个HTTP容器) -> slb -> 数据库代理服务 -> RDS
- 压不上去得从发压力端开始往后端撸,撸每个产品的rt,每个产品给出自己的rt来自证清白
- 应用有arms的话学会看arms对平均rt和QPS的统计,不要纠结个别请求的rt抖动,看平均rt
- 通过抓包完全可以分析出来系统能扛多少并发,以及可能的瓶颈位置
一包在手 万事无忧