TCP传输速度案例分析
TCP传输速度案例分析
前言
TCP传输速度受网络带宽和传输窗口的影响(接收、发送、拥塞窗口),带宽我们没办法改变,以下案例主要是讨论rt、窗口如何影响速度。
详细的buffer、rt对TCP传输速度的影响请看这篇:
以及 就是要你懂TCP–最经典的TCP性能问题 Nagle和Delay ack
上面两篇以及下面几个案例读完,应该所有TCP传输速度问题都能解决了。
前后端rtt差异大+vip下载慢的案例
来源:https://mp.weixin.qq.com/s/er8vTKZUcahA6-Pf8DZBng 文章中的trace-cmd工具也不错
如下三个链路,有一个不正常了
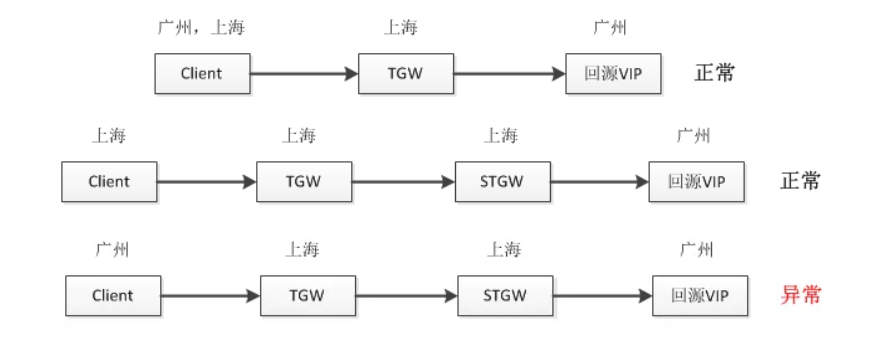
首先通过 ss -it dst “ip:port” 来分析cwnd、ssthresh、buffer,到底是什么导致了传输慢
原因TCPLossProbe:
如果尾包发生了丢包,没有新包可发送触发多余的dup ack来实现快速重传,完全依赖RTO超时来重传,代价太大,那如何能优化解决这种尾丢包的情况。也就是在某些情况下一个可以的重传包就能触发ssthresh减半,从而导致传输速度上不来。
本案例中,因为client到TGW跨了地域,导致rtt增大,但是TGW和STGW之间的rtt很小,导致握手完毕后STGW认为和client的rtt很小,所以很快就触发了丢包重传,实际没有丢包,只是rtt变大了,所以触发了如上的TLP( PTO=max(2rtt, 10ms) , 因为只有一次重传并收到了 dup,还是不应该触发TLP,但是因为老版本kernel bug导致,4.0的kernel修复了这个问题, 函数 is_tlp_dupack)
握手完毕后第七号包很快重传了
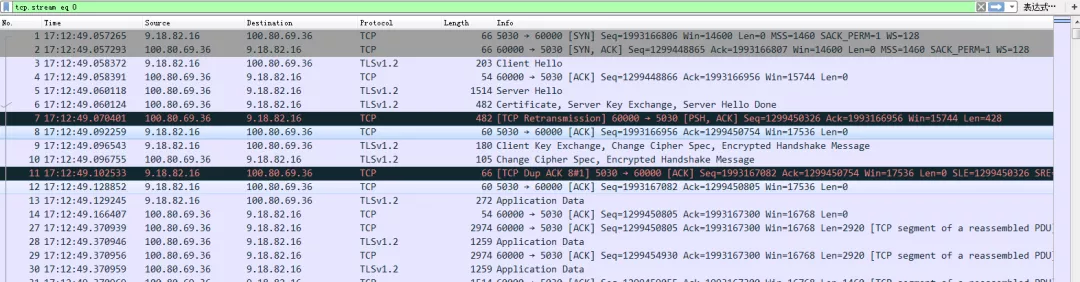
观察:
netstat -s |grep TCPLossProbes
解决:
tcp_early_retrans可用于开启和关闭ER和TLP,默认是3(enable TLP and delayed ER),sysctl -w net.ipv4.tcp_early_retrans=2 关掉TLP
小结
kernel版本小于4.0+TLP开启+VIP代理导致RS认为rtt很小,实际比较大,这两个条件下就会出现如上问题。
这个问题一看就是跟client和VIP代理之间的rtt扩大有关系,不过不是因为扩大后发送窗口不够之类导致的。
长肥网络(高rtt)场景下tcp_metrics记录的ssthresh太小导致传输慢的案例
https://www.atatech.org/articles/109967
tcp_metrics会记录下之前已关闭tcp 连接的状态,包括发送端拥塞窗口和拥塞控制门限,如果之前网络有一段时间比较差或者丢包比较严重,就会导致tcp 的拥塞控制门限ssthresh降低到一个很低的值,这个值在连接结束后会被tcp_metrics cache 住,在新连接建立时,即使网络状况已经恢复,依然会继承 tcp_metrics 中cache 的一个很低的ssthresh 值,在长肥管道情况下,新连接经历短暂的“慢启动”后,随即进入缓慢的拥塞控制阶段, 导致连接速度很难在短时间内上去。而后面的连接,需要很特殊的场景之下才能将ssthresh 再次推到一个比较高的值缓存下来,因此很有很能在接下来的很长一段时间,连接的速度都会处于一个很低的水平
因为 tcp_metrics记录的ssthresh非常小,导致后面新的tcp连接传输数据时很快进入拥塞控制阶段,如果传输的文件不大的话就没有机会将ssthresh撑大。除非传输一个特别大的文件,忍受拥塞控制阶段的慢慢增长,最后tcp_metrics记录下撑大后的ssthresh,整个网络才会恢复正常。
所以关闭 tcp_metrics其实是个不错的选择: net.ipv4.tcp_no_metrics_save = 1
或者清除: sudo ip tcp_metrics flush all
从系统cache中查看 tcp_metrics item
$sudo ip tcp_metrics show | grep 100.118.58.7
100.118.58.7 age 1457674.290sec tw_ts 3195267888/5752641sec ago rtt 1000us rttvar 1000us ssthresh 361 cwnd 40 ----这两个值对传输性能很重要
192.168.1.100 age 1051050.859sec ssthresh 4 cwnd 2 rtt 4805us rttvar 4805us source 192.168.0.174 ---这条记录有问题,缓存的ssthresh 4 cwnd 2都太小,传输速度一定慢
清除 tcp_metrics, sudo ip tcp_metrics flush all
关闭 tcp_metrics 功能,net.ipv4.tcp_no_metrics_save = 1
sudo ip tcp_metrics delete 100.118.58.7
每个连接的ssthresh默认是个无穷大的值,但是内核会cache对端ip上次的ssthresh(大部分时候两个ip之间的拥塞窗口大小不会变),这样大概率到达ssthresh之后就基本拥塞了,然后进入cwnd的慢增长阶段。
长肥网络(rt很高、带宽也高)下接收窗口对传输性能的影响
最后通过一个实际碰到的案例,涉及到了接收窗口、发送Buffer以及高延时情况下的性能问题
案例描述:从中国访问美国的服务器下载图片,只能跑到220K,远远没有达到带宽能力,其中中美之间的网络延时时150ms,这个150ms已经不能再优化了。业务结构是:
client ——150ms—–>>>LVS—1ms–>>>美国的统一接入server—–1ms—–>>>nginx
通过下载一个4M的文件大概需要20秒,分别在client和nginx上抓包来分析这个问题(统一接入server没权限上去)
Nginx上抓包
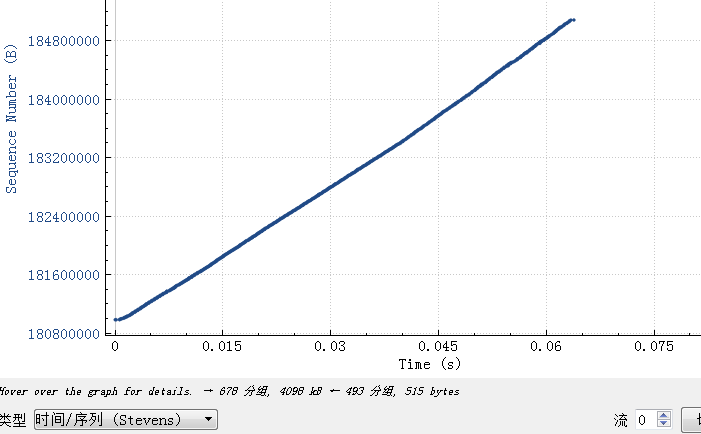
从这里可以看到Nginx大概在60ms内就将4M的数据都发完了
client上抓包
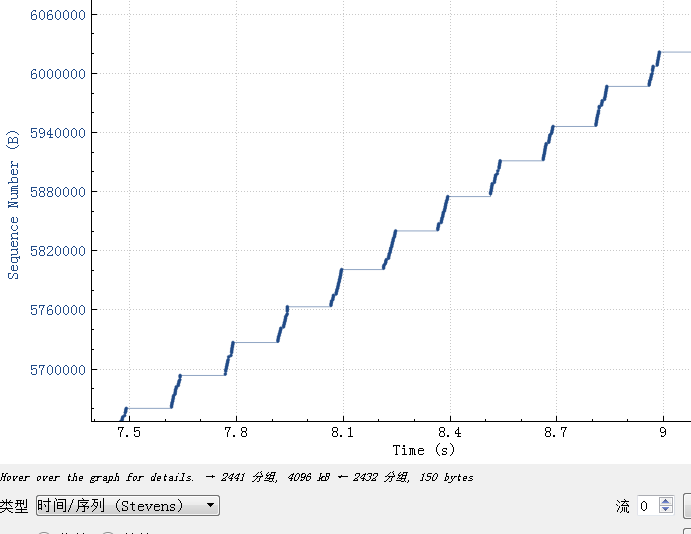
从这个图上可以清楚看到大概每传输大概30K数据就有一个150ms的等待平台,这个150ms基本是client到美国的rt。
从我们前面的阐述可以清楚了解到因为rt比较高,统一接入server每发送30K数据后要等150ms才能收到client的ack,然后继续发送,猜是因为上面设置的发送buffer大概是30K。
检查统一接入server的配置,可以看到接入server的配置里面果然有个32K buffer设置
将buffer改大
速度可以到420K,但是还没有跑满带宽:
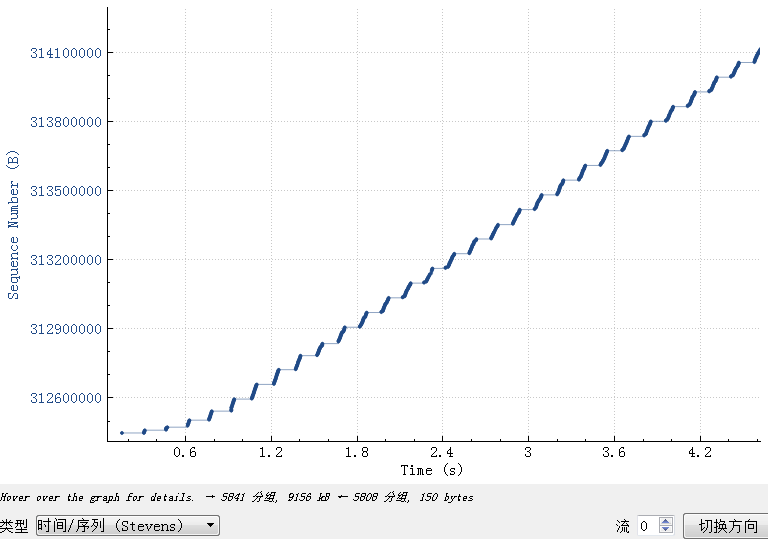

接着看一下client上的抓包
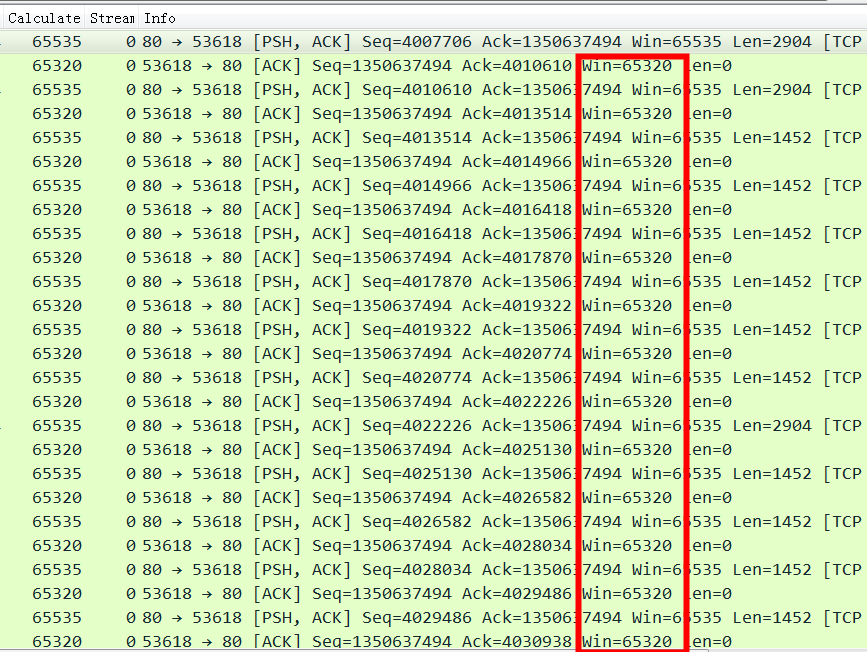
可以清楚看到 client的接收窗口是64K, 64K*1000/150=426K 这个64K很明显是16位的最大值,应该是TCP握手有一方不支持window scaling factor
那么继续分析一下握手包,syn:
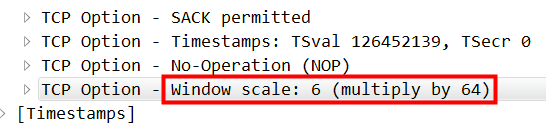
说明client是支持的,再看 syn+ack:
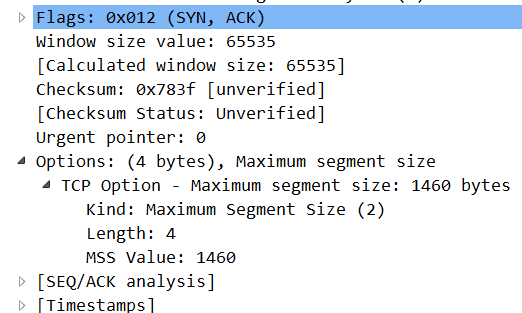
可以看到服务端不支持,那就最大只能用到64K。需要修改服务端代理程序,这主要是LVS或者代理的锅。
如果内网之间rt很小这个锅不会爆发,一旦网络慢一点就把问题恶化了
比如这是这个应用的开发人员的反馈:

长肥网络就像是很长很宽的高速公路,上面可以同时跑很多车,而如果发车能力不够,就容易跑不满高速公路。
在rt很短的时候可以理解为高速公路很短,所以即使发车慢也还好,因为车很快就到了,到了后就又能发新车了。rt很长的话就要求更大的仓库了。
整个这个问题,我最初拿到的问题描述结构是这样的(不要笑程序员连自己的业务结构都描述不清):
client ——150ms—–>>>nginx
实际开发人员也不能完全描述清楚结构,从抓包中慢慢分析反推他们的结构,到最后问题的解决。
这个案例综合了发送窗口(32K)、接收窗口(64K,因为握手LVS不支持window scale)、rt很大将问题暴露出来(跨国网络,rt没法优化)。
nginx buffer 分析参考案例:https://juejin.cn/post/6875223721615818765 nginx上下游收发包速率不一致导致nginx buffer打爆, 关闭nginx proxy_buffering 可解 (作者:挖坑的张师傅)
应用层发包逻辑影响了BDP不能跑满
来自 dog250: 一行代码解决scp在Internet传输慢的问题(RT高的网络环境)
用scp在长链路上传输文件竟然慢到无法忍受!100~200毫秒往返时延的链路,wget下载文件吞吐可达40MBps,scp却只有9MBps。
这次不是因为buffer导致BDP跑不满,而是scp业务层有自己流控的逻辑导致发包慢了
SSH允许在一个TCP连接上复用多个channel,需要对每一个channel做流控以保证公平,所以每个channel必须自己做而不是使用TCP的流控,OpenSSH的实现有问题。
delay ack拉高实际rt的案例
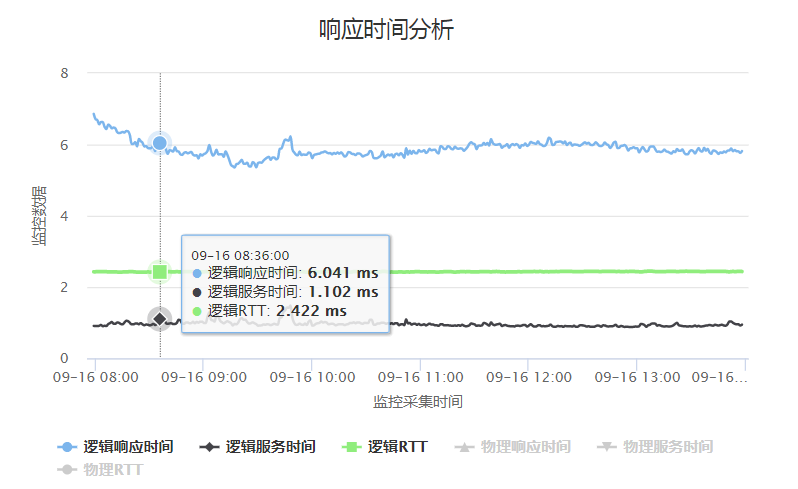
这个案例跟速度没有关系,只是解析监控图表上的rt为什么不符合逻辑地偏高了。
如下业务监控图:实际处理时间(逻辑服务时间1ms,rtt2.4ms,加起来3.5ms),但是系统监控到的rt(蓝线)是6ms,如果一个请求分很多响应包串行发给client,这个6ms是正常的(1+2.4*N),但实际上如果send buffer足够的话,按我们前面的理解多个响应包会并发发出去,所以如果整个rt是3.5ms才是正常的。
抓包来分析原因:
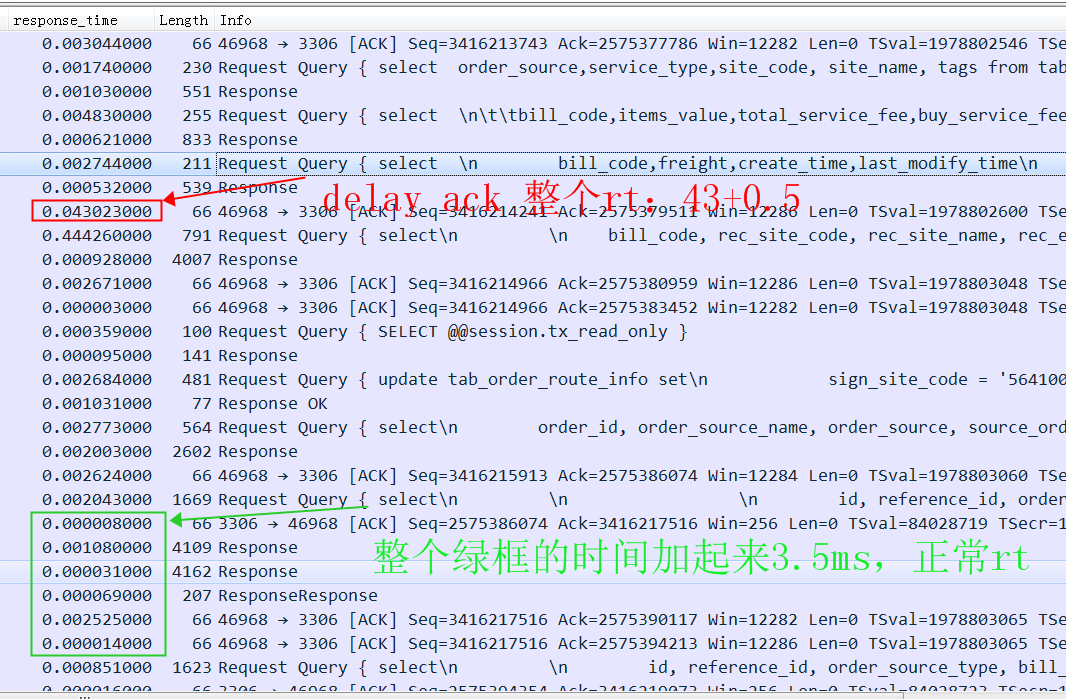
实际看到大量的response都是3.5ms左右,符合我们的预期,但是有少量rt被delay ack严重影响了
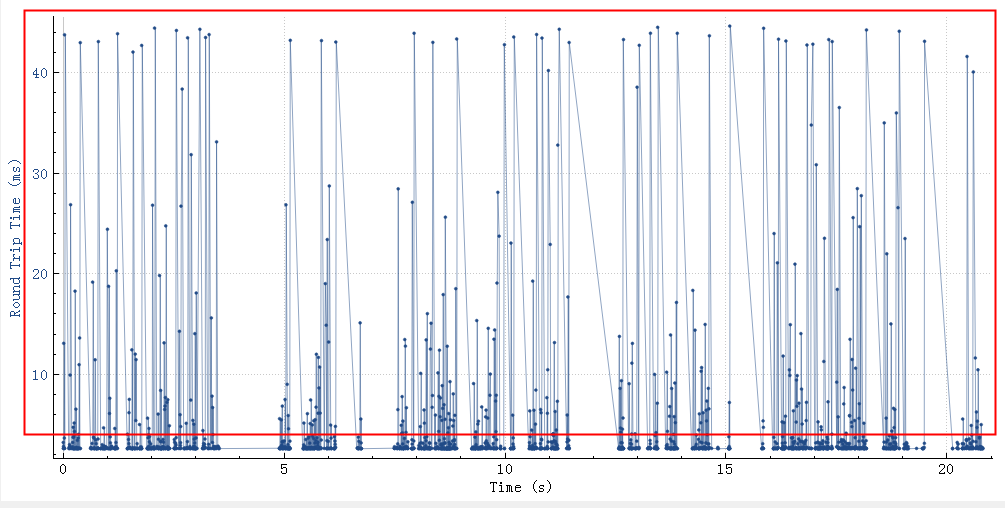
从下图也可以看到有很多rtt超过3ms的,这些超长时间的rtt会最终影响到整个服务rt
参考资料
Why when I transfer a file through SFTP, it takes longer than FTP?