一个Linux 内核 bug 导致的 TCP连接卡死
Linux BUG内核导致的 TCP连接卡死
问题描述
客户端从 server 拖数据,偶尔会出现 TCP 连接卡死,卡死的现象就是 server 不遵循 TCP 重传逻辑,客户端不停地发 dup ack,但是服务端不响应这些dup ack仍然发一些新的包(从server抓包可以看到),一会后服务端不再发任何新包,也不响应dup ack 来传丢掉的包,进入永久静默,最终连接闲置过久被reset,客户端抛连接异常.
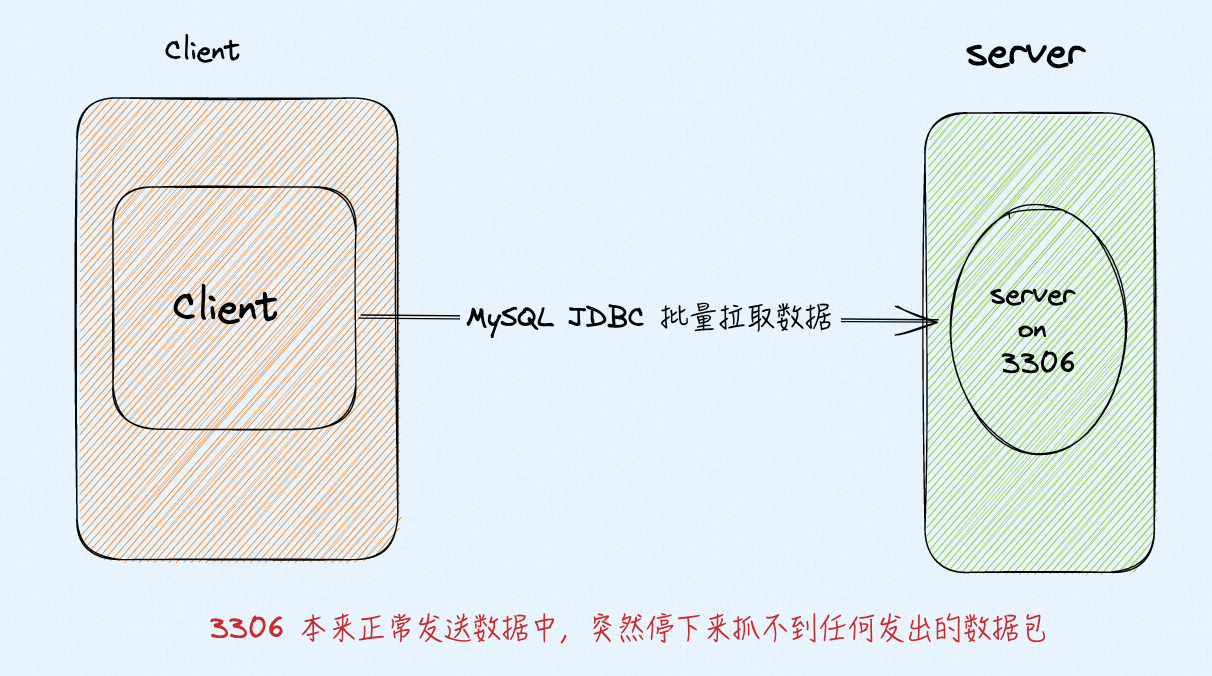
Client MySQL JDBC 协议拉取 Server 3306端口 数据,频繁出现卡死与超时,Client端Java 报错:Application was streaming results when the connection failed. Consider raising value of ‘net_write_timeout’ on the server. - com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Application was streaming results when the connection failed. Consider raising value of ‘net_write_timeout’ on the server.
分析
服务端抓包可以看到:这个 TCP 流, 17:40:40 后 3306 端口不做任何响应,进入卡死状态,在卡死前有一些重传
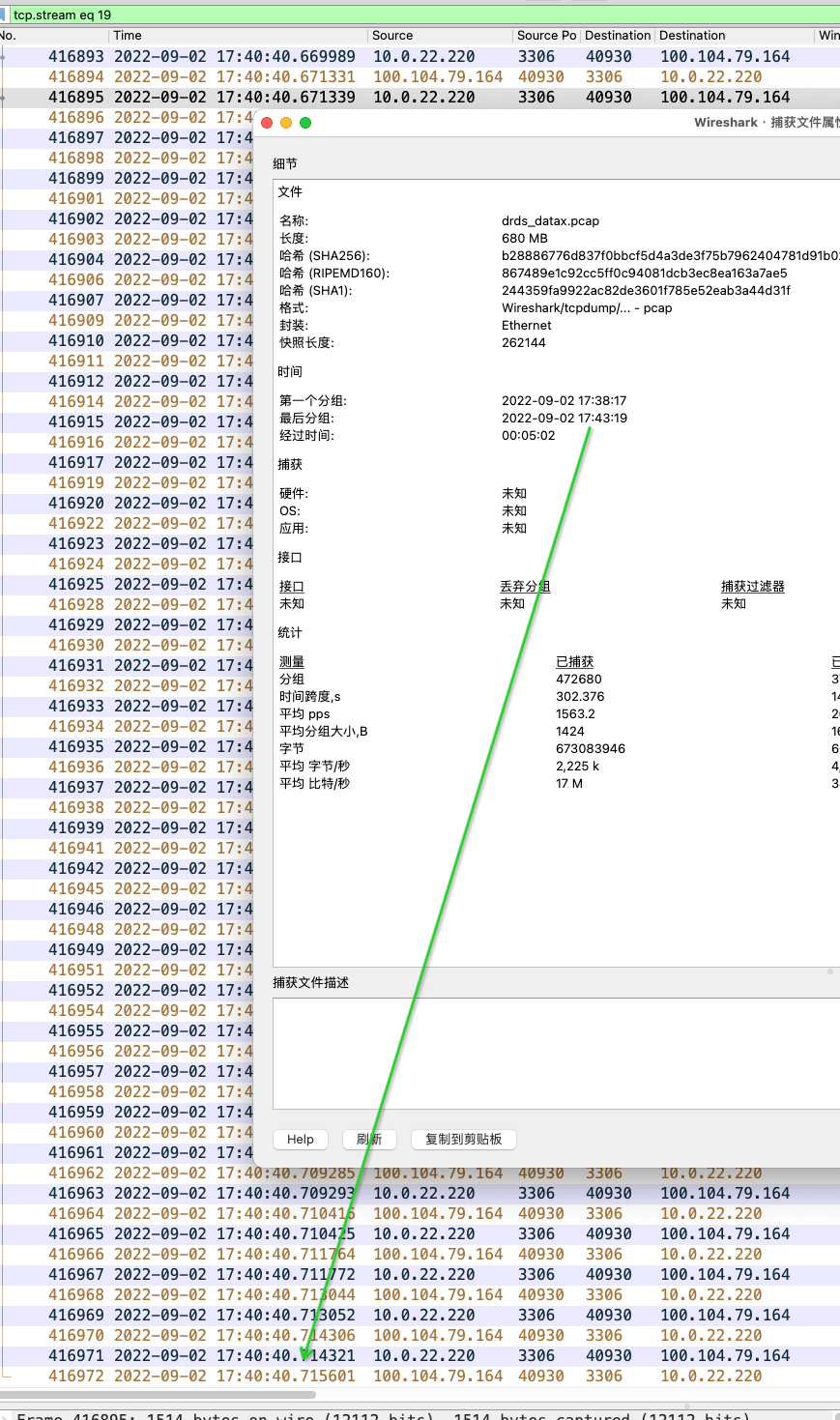
同时通过观察这些连接的实时状态:
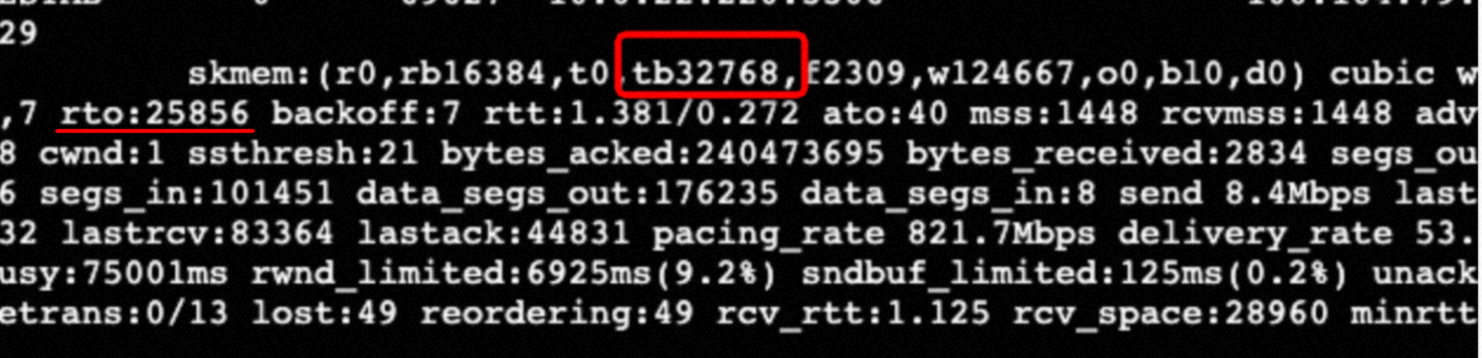
rto一直在增加,但是这个时候 server 上抓不到任何包,说明内核在做 rto 重传,但是重传包没有到达本机网卡,应该还是被内核其它环节吃掉了。
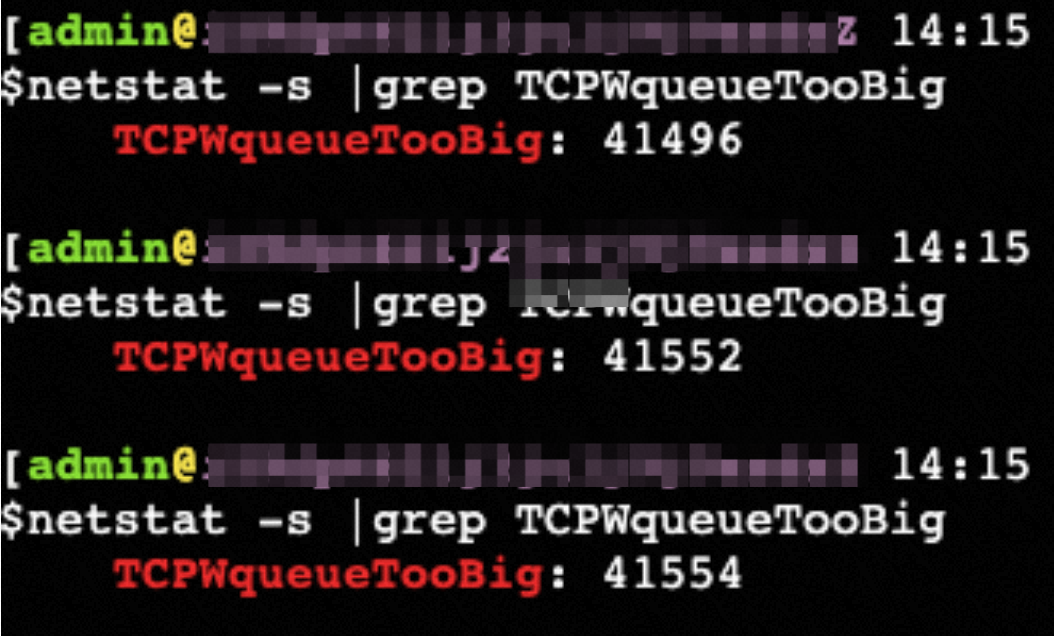
再观察 netstat -s 状态,重传的时候,TCPWqueueTooBig 值会增加,也就是重传->TCPWqueueTooBig->重传包未发出->循环->相当于 TCP 连接卡死、静默状态
顺着 TCPWqueueTooBig 查看内核代码提交记录, 红色部分是修 CVE-2019-11478 添加的代码,引入了这个 卡死 的bug,绿色部分增加了更严格的条件又修复了卡死的 bug
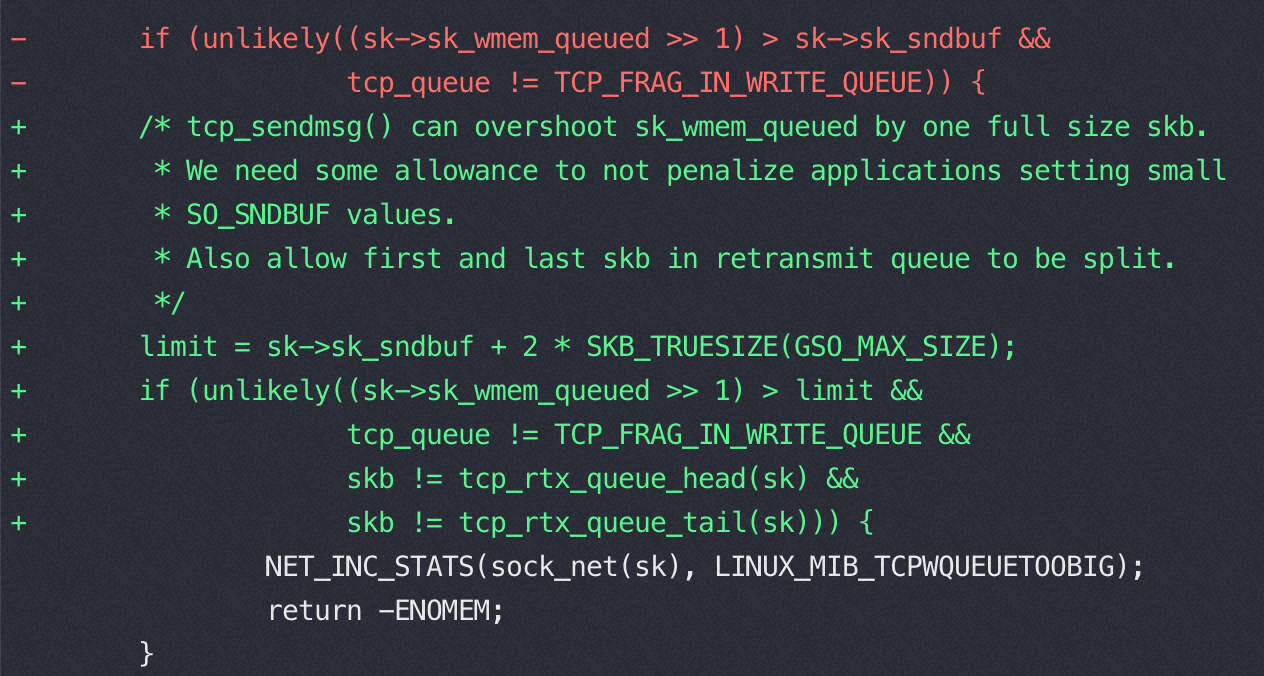
原因
2019-05 为了解决 CVE-2019-11478 增加了这个commit:f070ef2ac66716357066b683fb0baf55f8191a2e,这部分代码在发送 buffer 满的时候忽略要发的包,进入静默有包也不发
为了解决这个问题 2019-07-20 fix 版本:https://github.com/torvalds/linux/commit/b617158dc096709d8600c53b6052144d12b89fab
4.19.57 是 2019-07-03 发布,完美引入了这个 bug
快速确认:netstat -s | grep TCPWqueueTooBig 如果不为0 就出现过 TCP 卡死,同时还可以看到 tb(待发送队列) 大于 rb(发送队列 buffer)
重现条件
必要条件:合并了 commit:f070ef2ac66716357066b683fb0baf55f8191a2e 的内核版本
提高重现概率的其它非必要条件:
- 数据量大—拖数据任务、大查询;
- 有丢包—链路偏长连接,丢包概率大;
- 多个任务 —一个失败整个任务失败,客户体感强烈
- Server 设置了小buffer,出现概率更高
在这四种情况下出现概率更高。用户单个小查询SQL 睬中这个bug后一般可能就是个连接异常,重试就过去了,所以可能没有抱怨。 得这四个条件一起用户的抱怨就会凸显出来。
用 packetdrill 复现
编译 packetdrill 报找不到lib包的错误的话,到Makefile 里去掉 -static , 默认用静态link方式,本地没有pthread静态包
https://xargin.com/packetdrill-intro/ packetdrill介绍
文章末尾一堆链接里好多人重现这个bug都用到了 packetdrill
复现的关键两点
- 让对端重传一个大包(包的长度超过一个mss,进而触发tcp_fragment)
- sk_wmem_queued 远大于 sk_sndbuf,即使得tcp_fragment函数的条件成立,具体如下:

复现代码
1 | `gtests/net/common/defaults.sh` |
复现结果有问题的内核版本上 tcpdump抓包看到卡死,用ss命令展示的信息,可以看到sk_wmem_queued为w22680,远大于tb8192
1 | State Recv-Q Send-Q Local Address:Port Peer Address:Port |
解决
升级内核到带有2019-07-20 fix 版本:https://github.com/torvalds/linux/commit/b617158dc096709d8600c53b6052144d12b89fab
相关资料
https://www.secrss.com/articles/11570
https://access.redhat.com/solutions/4302501
https://access.redhat.com/solutions/5162381
databricks 的相同案例: https://www.databricks.com/blog/2019/09/16/adventures-in-the-tcp-stack-performance-regressions-vulnerability-fixes.html
6月第一个人报了这个bug:https://lore.kernel.org/netdev/CALMXkpYVRxgeqarp4gnmX7GqYh1sWOAt6UaRFqYBOaaNFfZ5sw@mail.gmail.com/
Hi Eric, I now have a packetdrill test that started failing (see below). Admittedly, a bit weird test with the SO_SNDBUF forced so low. Nevertheless, previously this test would pass, now it stalls after the write() because tcp_fragment() returns -ENOMEM. Your commit-message mentions that this could trigger when one sets SO_SNDBUF low. But, here we have a complete stall of the connection and we never recover.
I don’t know if we care about this, but there it is :-)