比较不同CPU下的分支预测
比较不同CPU下的分支预测
目的
本文通过一段对分支预测是否友好的代码来验证 branch load miss 差异,已经最终带来的 性能差异。同时在x86和aarch64 下各选几款CPU共5款进行差异性对比
CPU 情况
intel x86
1 | #lscpu |
hygon 7260
1 | #lscpu |
ARM 鲲鹏920
1 | #lscpu |
ARM M710
1 | #lscpu |
ARM FT S2500
1 | #lscpu |
测试代码
对一个数组中较大的一半的值累加:
1 |
|
以上代码可以注释掉第15行,也就是不对代码排序直接累加,不排序的话 if (data[c] >= 128) 有50% 概率成立,排序后前一半元素if都不成立,后一半元素if都成立,导致CPU流水线很好预测后面的代码,可以提前加载运算打高IPC
测试结果
aarch64 鲲鹏920
1 | #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./aftersort |
以上在相同CPU下数据对比可以看到核心差异是branch-load-misses和branch-misses,当然最终也体现在 IPC 数值上,排序后IPC更高不是因为数据有序取起来更快,而是因为执行逻辑更容易提前预测,也就是可以提前加载if代码到cache中。符合预期
aarch64 M710
1 | #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-icache-load-misses,L1-icache-loads,LLC-load-misses,LLC-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./aftersort |
M710上排序与否和鲲鹏差不多,但是 M710比 鲲鹏要快一些,差别只要有主频高一点点(6%),另外M710编译后的指令数量也略少(8%)。
最大的差别是没有排序的话 branch-load-misses(1,232,325,180)/branch-loads(14,776,289,690) 比例只有鲲鹏的50%,导致整体 IPC 比鲲鹏高不少(1.66 VS 1.04)
如果是排序后的数据来看 M710比鲲鹏好40%,IPC 好了20%,iTLB-loads 差异特别大
aarch64 FT S2500
1 | #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,alignment-faults,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,iTLB-load-misses ./aftersort |
Intel x86 8163
1 | #perf stat -e branch-instructions,branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,ref-cycles,alignment-faults,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-stores,L1-icache-load-misses,LLC-load-misses,LLC-loads,LLC-store-misses,LLC-stores,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,dTLB-store-misses,dTLB-stores,iTLB-load-misses,iTLB-loads,node-load-misses,node-loads,node-store-misses,node-stores ./aftersort |
从 x86 和 aarch 对比来看,x86 编译后的指令数是 aarch 的35%,ARM 是精简指令,数量多比较好理解。主频2.5 GHz 较 M710低了11%。
IPC 差异比较大,有一部分是因为 ARM 精简指令本来有较高的 IPC。
从排序前的差异来看除了指令集外导致 IPC 较高的原因主要也是 branch-load-misses(1,232,325,180)/branch-loads(14,776,289,690) 比 intel的 1,602,020,038/6,568,921,480, 也就是 M710的 branch miss 率比 intel 低了一倍。
排序后去掉了 branch miss 差异,M710 比 intel 快了 10%,只要是因为主频的差异
on 8269 3.2GHz
1 | #perf stat -e branch-instructions,branch-misses,cpu-cycles,instructions,branch-load-misses,branch-loads,task-clock,cpu-clock ./beforesort |
hygon 7260
1 | #perf stat -e branch-instructions,branch-misses,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-prefetches,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./aftersort |
hygon 在这两个场景中排序前比 intel 好了 20%,IPC 好30%,但是指令数多了10%,最关键的也是因为hygon的 branch-load-misses 率较低。
排序后 hygon 略慢10%,主要是指令数多了将近10%。
如果直接将 intel 下 编译好的二进制放到 hygon 下运行,完全可以跑通,指令数也显示和 intel 一样了,但是总时间较在hygon下编译的二进制没有变化
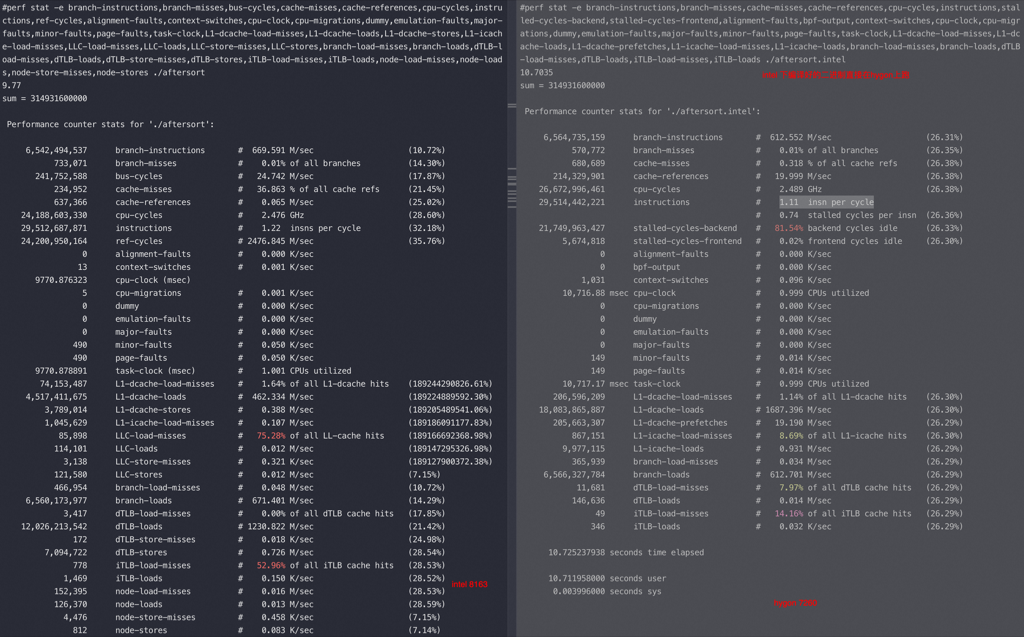
开启 gcc O3 优化
intel 8163
1 | #perf stat -e branch-instructions,branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,ref-cycles,alignment-faults,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-stores,L1-icache-load-misses,LLC-load-misses,LLC-loads,LLC-store-misses,LLC-stores,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,dTLB-store-misses,dTLB-stores,iTLB-load-misses,iTLB-loads,node-load-misses,node-loads,node-store-misses,node-stores ./beforesort |
可以看到 O3 优化后是否排序执行时间差不多,并且都比没有 O3 前的快几倍,指令数较优化前基本不变。
最明显的是排序前的 branch-load-misses 几乎都被优化掉了,这也导致 IPC 从0.41 提升到了3.59
aarch64 M710
1 | #perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-icache-load-misses,L1-icache-loads,LLC-load-misses,LLC-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads ./beforesort |
可以看到在M710上开启 O3 优化后是否排序执行时间差不多,并且都比没有 O3 前
的快几倍,最明显的是指令数只有之前的7%。另外就是排序前的 branch-load-misses 几乎都被优化掉了,虽然这里 IPC 提升不大但主要在指令数的减少上。
O3意味着代码尽可能展开,更长的代码意味着对 L1i(以及 L2和更高级别)高速缓存的压力更高。这会导致性能降低。更短的代码可以运行得更快。幸运的是,gcc 有一个优化选项可以指定此项。如果使用-Os,则编译器将优化代码大小。使用后,能够增加代码大小的哪些优化将被禁用。使用此选项通常会产生令人惊讶的结果。特别是循环展开和内联没有实质优势时,那么此选项将是一个很好的选择。
分支预测原理介绍
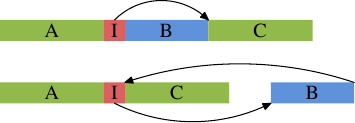
如上图的上面部分代表通常情况下的简单代码布局。如果区域 B(这里是内联函数 inlfct 生成的代码)经常由于条件 I 被跳过,而不会执行,处理器的预取将拉入很少使用的包含块 B 的高速缓存行。使用块重新排序可以改变这种局面,改变之后的效果可以在图的下半部分看到。经常执行的代码在内存中是线性的,而很少执行的代码被移动到不会损害预取和 L1i 效率的位置。
Linux内核流水线优化案例
在Linux Kernel中有大量的 likely/unlikely
1 | //ip 层收到消息后,如果是tcp就调用tcp_v4_rcv作为tcp协议的入口 |
__builtin_expect 这个指令是 gcc 引入的。该函数作用是允许程序员将最有可能执行的分支告诉编译器,来辅助系统进行分支预测。(参见 https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html)
它的用法为:__builtin_expect(EXP, N)。意思是:EXP == N的概率很大。那么上面 likely 和 unlikely 这两句的具体含义就是:
- __builtin_expect(!!(x),1) x 为真的可能性更大 //0两次取反还是0,非0两次取反都是1,这样可以适配__builtin_expect(EXP, N)的N,要不N的参数没法传
- __builtin_expect(!!(x),0) x 为假的可能性更大
当正确地使用了__builtin_expect后,编译器在编译过程中会根据程序员的指令,将可能性更大的代码紧跟着前面的代码,从而减少指令跳转带来的性能上的下降。让L1i中加载的代码尽量有效紧凑
这样可以让 CPU流水线分支预测的时候默认走可能性更大的分支。如果分支预测错误所有流水线都要取消重新计算。
如果程序员利用这些宏,然后使用 -freorder-blocks 优化选项,则 gcc 将对块进行重新排序,如原理解图所示。该选项在 -O 2中启用,但在-Os 中禁用。还有另一种对块进行重新排序的选项(-freorder-blocks-and-partition ),但是它的用处有限,因为它不适用于异常处理。
总结
不排序的代码(分支极难预测正确)运行数据对比:
| branch-load-misses/branch-loads | instructions | IPC | 耗时(秒) | 排序后耗时(秒) | |
|---|---|---|---|---|---|
| 鲲鹏920 | 21.7% | 83,694,841,472 | 1.04 | 30.92 | 11.44 |
| M710 | 8.3% | 77,083,625,280 | 1.66 | 16.89 | 8.20 |
| Intel 8163 | 24.4% | 29,618,485,912 | 0.41 | 29.52 | 9.77 |
| hygon 7260 | 11.8% | 32,850,416,330 | 0.56 | 23.36 | 10.95 |
| FT S2500 | 24% | 83,872,213,462 | 1.01 | 39.8 | 16.63 |
排序后的代码(分支预测容易)运行数据对比:
| instructions | instructions(排序前) | IPC | 耗时(秒) | |
|---|---|---|---|---|
| 鲲鹏920 | 83,666,813,837 | 83,694,841,472 | 2.82 | 11.44 |
| M710 | 77,068,271,833 | 77,083,625,280 | 3.42 | 8.20 |
| Intel 8163 | 29,491,804,977 | 29,618,485,912 | 1.22 | 9.77 |
| hygon 7260 | 32,785,270,866 | 32,850,416,330 | 1.20 | 10.95 |
| FT S2500 | 83,918,069,835 | 83,872,213,462 | 2.41 | 16.63 |
- 所有 CPU 都期望对分支预测友好的代码
- 分支预测重点关注 perf branch-load-misses/branch-loads
- aarch64 较 x86_64 指令数是2.6倍,同时对流水线更友好,也就是 IPC 更高(2.6倍),测试代码单线程、无锁
- M710的分支预测正确率是鲲鹏920、intel的3倍,hygon 是鲲鹏 、intel的分支预测率的2倍
- 10% 的分支load miss 会带来一倍的性能差异
- gcc O3 优化效果很明显,代价就是代码展开后很大,容易造成icache不够,对小段测试代码效果最好,实践不一定
- 测试代码只是极简场景,实际生产环境更复杂,也就是预测效果不会这么明显