Nginx reuseport 导致偶发性卡顿 by @橘橘球
背景 从2018年开始,我们有个业务陆续接到反馈 Nginx 线上集群经常出现不响应或者偶发性的“超慢”请求。这种卡顿每天都有少量出现。而只有多个集群中的一个出现,其他压力更大的集群皆未出现。
一些观察到的现象:
出问题前不久升级 Nginx 配置,打开了 reuseport 功能
在压力大的后端(upstream)服务环境不容易出现,后端压力轻对应的Nginx卡顿概率更高
关闭 reuseport 后 问题少了很多
失败的请求响应时间都是 0ms(Nginx日志不靠谱了)
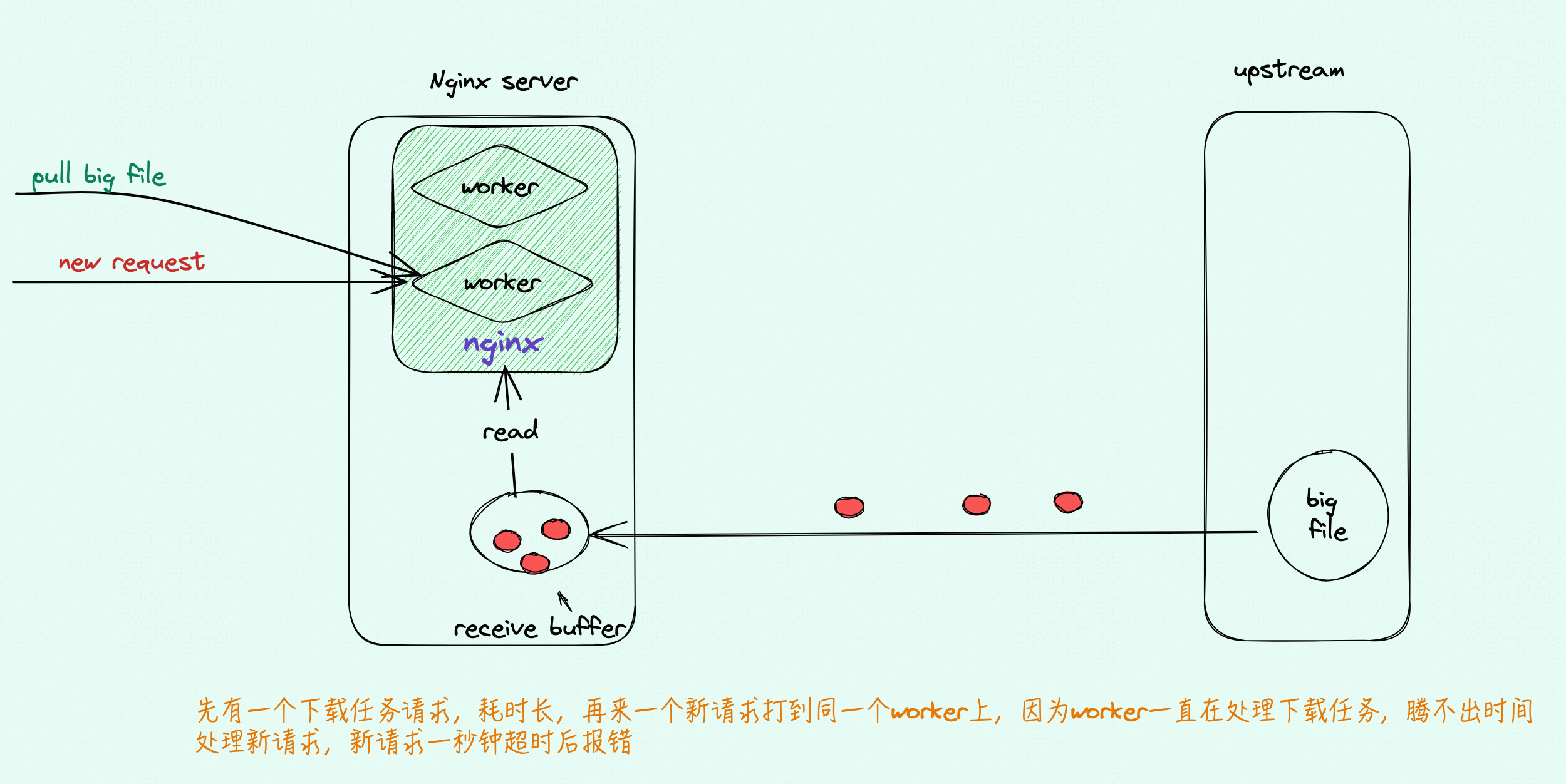
从 Nginx 日志上看,所有失败的健康检查请求都是0ms 的499 错误码(健康检查设置超时是2秒),但实际出问题的时候有5s-2分钟没有任何日志输出(Nginx卡了这么久)要么是Nginx卡住没去accept,要么是accept了没响应
所有超时来自同一个worker(一个Nginx服务一般按照机器核数开启多个worker)
并且已知,卡顿的原因是打开 reuseport 后,新进来的请求可以由内核 hash 派发给一个 Nginx woker ,避免了锁争抢以及惊群。但如果网络条件足够好,压力足够低,Nginx worker 一直来不及读完 receive buffer 中的内容时,就无法切换并处理其他的 request,于是在新请求的客户端会观测不间断的卡顿,而压力大的后端由于网络传输慢,经常卡顿,Nginx worker 反而有时间能处理别的请求。在调小 receive buffer 人为制造卡顿后该问题得以解决。
目标 由于所述场景比较复杂,缺乏直接证据,打算通过构造一个较简单的环境来复现这个问题,并且在这个过程中抓包、观测Nginx worker的具体行为,验证这个假设。
术语 快连接和慢连接
快连接:通常是传输时间短、传输量小的连接,耗时通常是ms级别
慢连接:通常是传输时间长、传输量大的连接,可以维持传输状态一段时间(如30s, 1min)
在本次场景复现过程中,这两种连接都是短连接,每次请求开始前都需要三次握手建立连接,结束后都需要四次挥手销毁连接
Epoll Nginx使用了epoll模型,epoll 是多路复用的一种实现。在多路复用的场景下,一个task(process)会批量处理多个socket,哪个来了数据就去读那个。这就意味着要公平对待所有这些socket,不能阻塞在任何socket的”数据读”上,也就是说不能在阻塞模式下针对任何socket调用recv/recvfrom。
epoll 每次循环为O(1) 操作,循环前会得到一个就绪队列,其中包含所有已经准备好的 socket stream(有数据可读),不需要循环全部 socket stream 读取数据,在循环后会将被读取数据的 stream 重新放回睡眠队列。睡眠队列中的 socket stream 有数据可读时,再唤醒加入到 就绪队列中。
epoll 伪代码 (不包含唤醒、睡眠)
1 2 3 4 5 6 while(true) { streamArr = getEpollReadyStream(); // 找到准备好的stream for(Stream i: streamArr) { // 循环准备好的stream doSomething(); } }
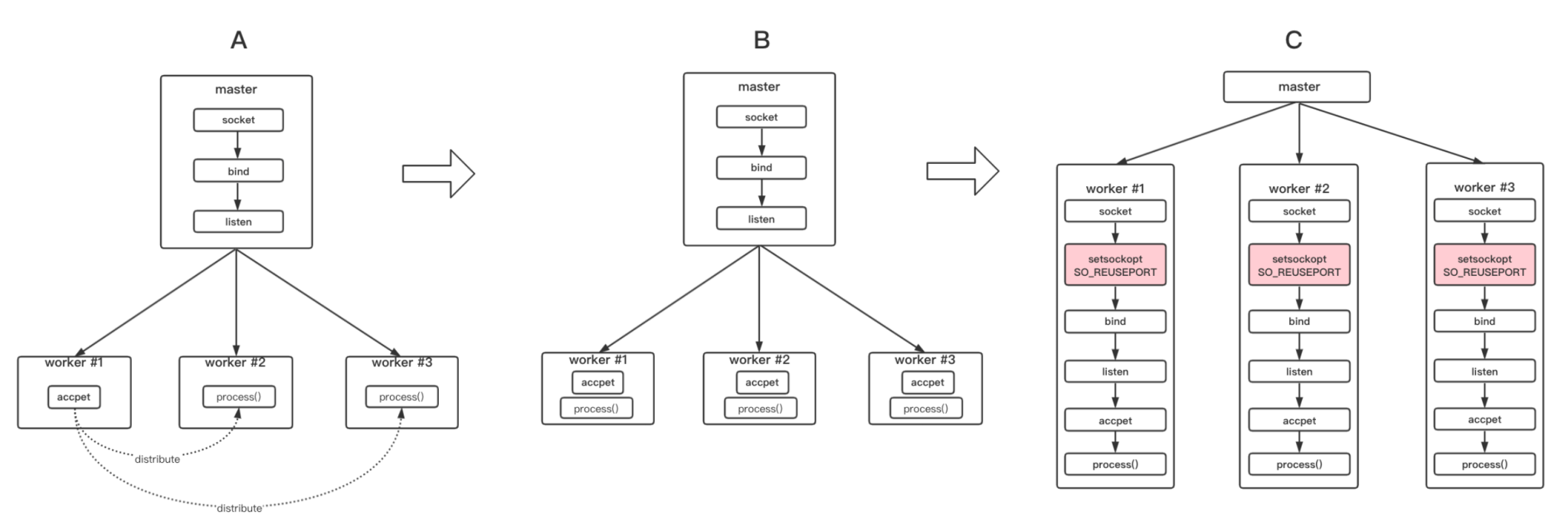
reuseport与惊群 Nginx reuseport 选项解决惊群的问题:在 TCP 多进程/线程场景中(B 图),服务端如果所有新连接只保存在一个 listen socket 的全连接队列中,那么多个进程/线程去这个队列里获取(accept)新的连接,势必会出现多个进程/线程对一个公共资源的争抢,争抢过程中,大量资源的损耗,也就会发生惊群现象。
但同时也是由于这个分配机制,避免了上下文切换,在服务压力不大,网络情况足够好的情况下,进程/线程更有可能专注于持续读取某个慢连接数据而忽视快连接建立的请求,从而造成快连接方卡顿。
复现过程 思路
整体的架构是N个client->1个Nginx->N个server。因为卡顿原因和reuseport机制有关,和server数量无关,server数量设为任意数字都能复现,这里为了方便设成1。client数量设为2,为了将快连接和慢连接区分开便于抓包观测
用慢连接制造卡顿环境,用快连接观测卡顿。在快连接客户端进行观测和抓包
进程数量要足够少,使得同一个 worker 有几率分配到多个连接 worker_processes 2
连接数目要足够多,慢连接数目>=进程数量,使得快连接在分配时,有一定概率分配到一个正在处理慢连接的worker上
reuseport: 这个配置要开启,卡顿现象才能观测到。listen 8000 reuseport
环境 1 2 3 4 5 linux kernal version: 6.1 linux image: amazon/al2023-ami-2023.0.20230419.0-kernel-6.1-x86_64 instance type: 1X AWS t2.micro (1 vCPU, 1GiB RAM) – Nginx client(fast request) 3X AWS t3.micro (2 vCPU, 1GiB RAM) – Http server, Nginx server, Nginx client(slow request)
复现操作
在server instance上放置一个 2GiB 大文件(0000000000000000.data)和一个 3MiB 小文件(server.pcap),并开启一个http server
1 nohup python -m http.server 8000
在Nginx instance上安装、配置好Nginx,并启动Nginx (注意要绑核!)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 # install sudo yum install nginx # config (/etc/nginx/nginx.conf) user nginx; worker_processes 2; error_log /var/log/nginx/error.log notice; pid /run/nginx.pid; include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } http { log_format main '$remote_addr [$time_local] "$request" ' 'status=$status body_bytes_sent=$body_bytes_sent ' 'rt=$request_time uct="$upstream_connect_time" uht="$upstream_header_time" urt="$upstream_response_time"'; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; keepalive_timeout 60; types_hash_max_size 4096; include /etc/nginx/mime.types; default_type application/octet-stream; # Load modular configuration files from the /etc/nginx/conf.d directory. # See http://nginx.org/en/docs/ngx_core_module.html#include # for more information. include /etc/nginx/conf.d/*.conf; server { listen 8000 reuseport; server_name server1; root /usr/share/nginx/html; # Load configuration files for the default server block. include /etc/nginx/default.d/*.conf; location / { proxy_pass http://172.31.86.252:8000; # server ip proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; } error_page 404 /404.html; location = /404.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } } } # start nginx sudo taskset -c 0 nginx
启动慢连接client,开启4个下载进程并计时,测试脚本在此
启动快连接client,开启1个下载进程并计时,抓包,测试脚本在此
进入Nginx instance观察access.log
关掉reuseport或者调小recv buffer大小,重试一次
结果 ip maping:
1 2 3 4 172.31.86.252: http server 172.31.89.152: nginx server 172.31.91.109: 快连接 client 172.31.92.10: 慢连接 client
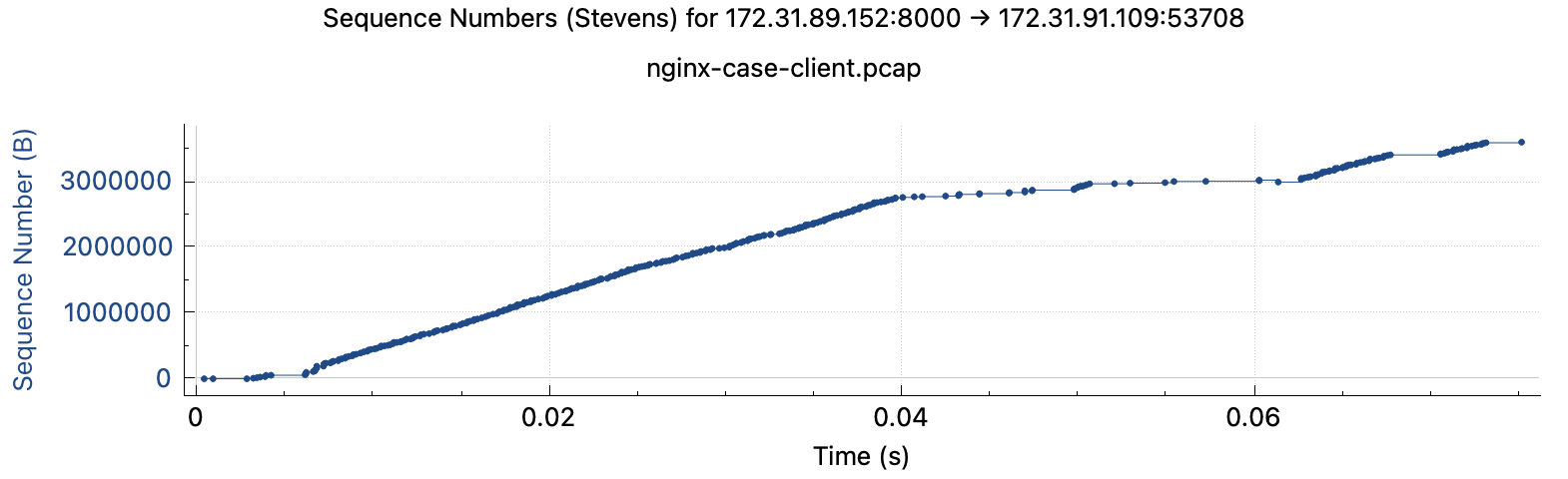
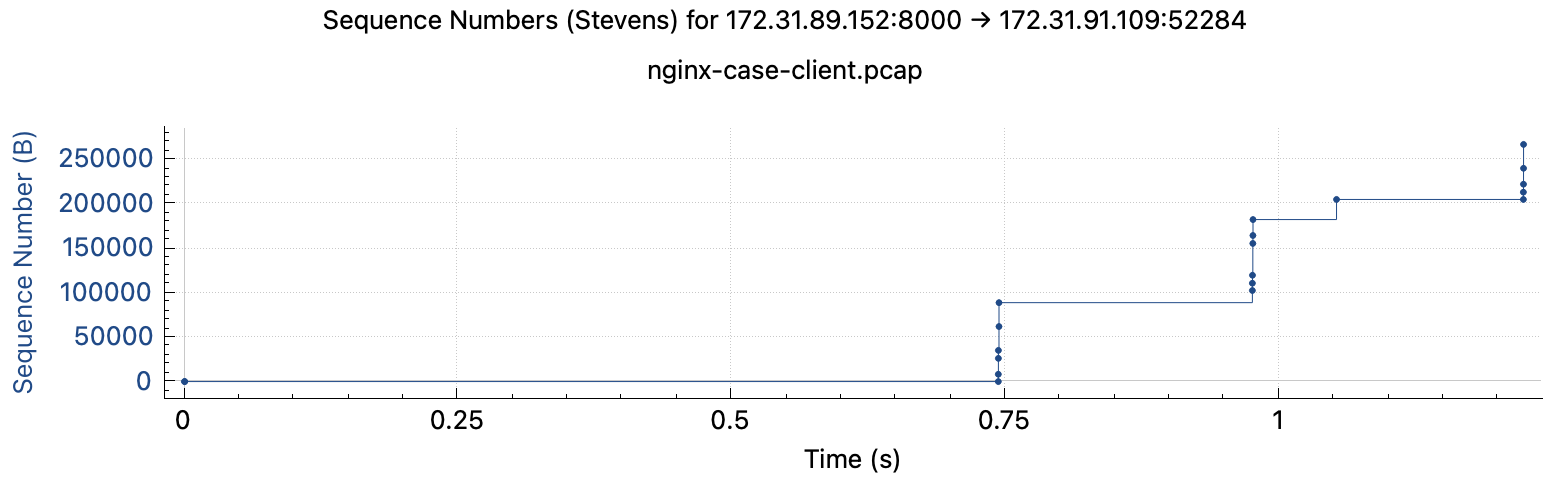
快连接client端:下载同一个小文件的下载时长有快有慢,方差很大,完整日志在此
1 2 3 4 5 6 7 8 [2023-05-31 08:27:32,127] runtime=1010 [2023-05-31 08:27:33,140] runtime=1009 [2023-05-31 08:27:34,152] runtime=38 [2023-05-31 08:27:34,192] runtime=1011 [2023-05-31 08:27:35,205] runtime=37 [2023-05-31 08:27:35,245] runtime=1008 [2023-05-31 08:27:36,256] runtime=57 [2023-05-31 08:27:36,315] runtime=1011
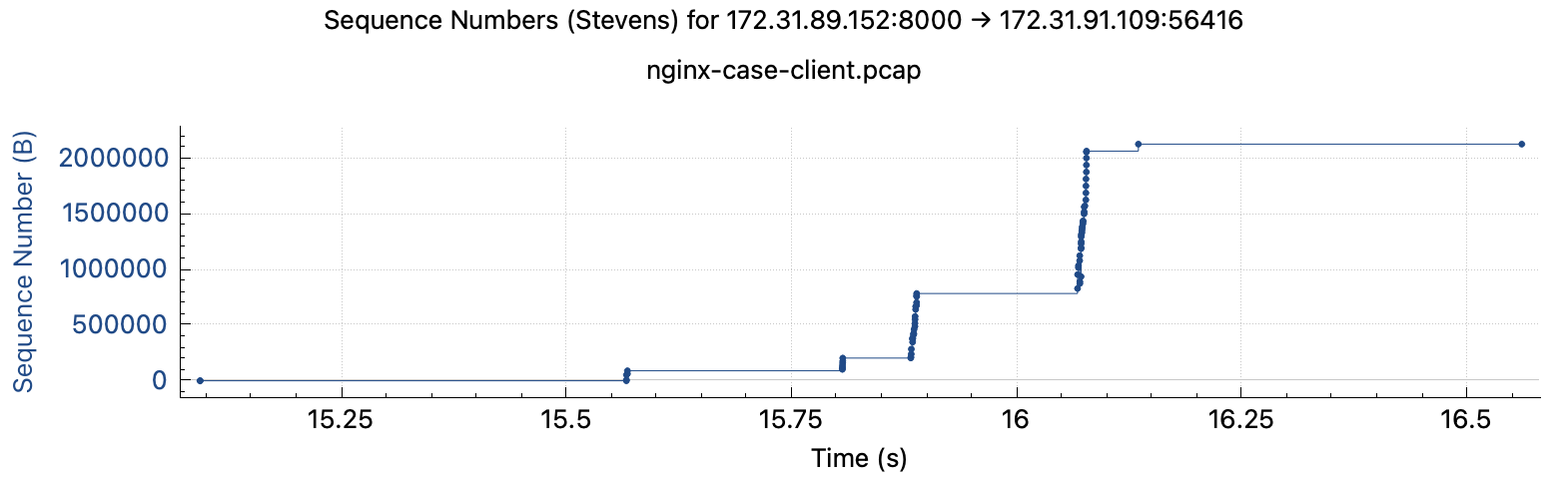
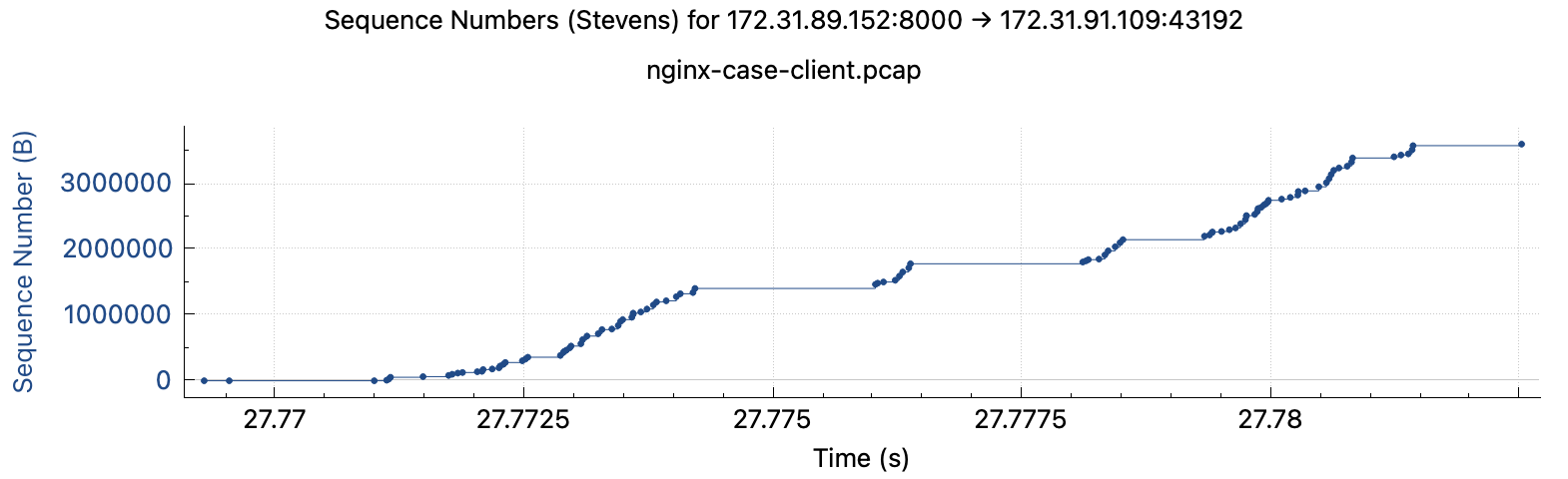
快连接client:无论耗时长短,抓包结果都显示存在不同程度卡顿,抓包文件在此 耗时长的下载过程
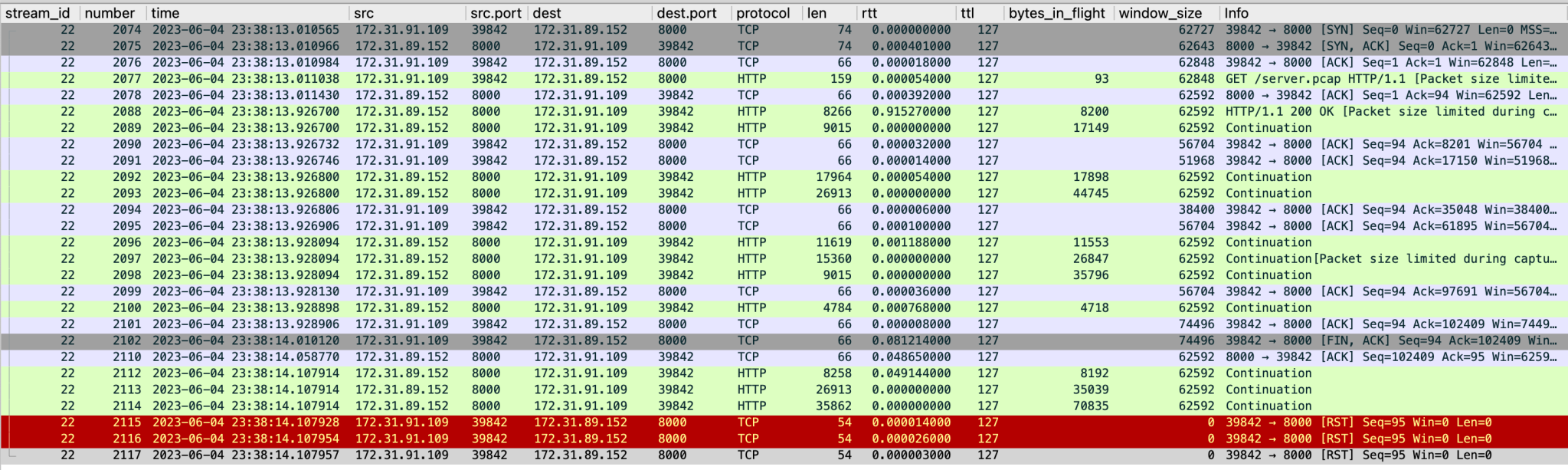
Nginx access.log 存在大量未下载完的200请求,和少量499请求,且499请求的耗时为0,access.log文件在此
1 2 3 4 5 6 7 8 172.31.91.109 [31/May/2023:08:27:49 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=102195 rt=0.790 uct="0.413" uht="0.592" urt="0.791" 172.31.91.109 [31/May/2023:08:27:50 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=3602590 rt=0.058 uct="0.000" uht="0.002" urt="0.053" 172.31.91.109 [31/May/2023:08:27:51 +0000] "GET /server.pcap HTTP/1.1" status=499 body_bytes_sent=0 rt=0.000 uct="-" uht="-" urt="0.000" 172.31.91.109 [31/May/2023:08:27:51 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=102195 rt=0.763 uct="0.400" uht="0.580" urt="0.763" 172.31.91.109 [31/May/2023:08:27:52 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=102195 rt=0.767 uct="0.480" uht="0.768" urt="0.768" 172.31.91.109 [31/May/2023:08:27:53 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=580007 rt=0.773 uct="0.330" uht="0.431" urt="0.773" 172.31.91.109 [31/May/2023:08:27:55 +0000] "GET /server.pcap HTTP/1.1" status=499 body_bytes_sent=0 rt=0.000 uct="-" uht="-" urt="0.000" 172.31.91.109 [31/May/2023:08:27:55 +0000] "GET /server.pcap HTTP/1.1" status=499 body_bytes_sent=0 rt=0.000 uct="-" uht="-" urt="0.000"
下载中途被关闭的连接(200),可以观测到Nginx server在客户端已经请求FIN并被ACK之后仍然在发送一些网络数据包,客户端非常迷惑,向Nginx发送RST
限制Nginx server所在的instance的recv buffer大小,重新进行实验,可以观测到仍然有少量停顿,但整体耗时好了很多,不再有长达1s的卡顿,也不再有RST,完整日志在此
1 sysctl -w net.ipv4.tcp_rmem="40960 40960 40960"
client runtime log: 耗时稳定在50-100ms,比无慢连接、纯跑快连接时要大一倍(25-50ms)
1 2 3 4 5 6 7 8 9 10 [2023-06-05 06:13:22,791] runtime=120 [2023-06-05 06:13:22,913] runtime=82 [2023-06-05 06:13:22,997] runtime=54 [2023-06-05 06:13:23,054] runtime=61 [2023-06-05 06:13:23,118] runtime=109 [2023-06-05 06:13:23,229] runtime=58 [2023-06-05 06:13:23,290] runtime=55 [2023-06-05 06:13:23,347] runtime=79 [2023-06-05 06:13:23,429] runtime=65 [2023-06-05 06:13:23,497] runtime=53
client 抓包结果:
1 2 3 4 5 6 7 8 172.31.91.109 [05/Jun/2023:06:13:22 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=3602590 rt=0.101 uct="0.001" uht="0.004" urt="0.101" 172.31.91.109 [05/Jun/2023:06:13:22 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=3602590 rt=0.064 uct="0.001" uht="0.002" urt="0.064" 172.31.91.109 [05/Jun/2023:06:13:23 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=3602590 rt=0.044 uct="0.000" uht="0.001" urt="0.044" 172.31.91.109 [05/Jun/2023:06:13:23 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=3602590 rt=0.047 uct="0.000" uht="0.001" urt="0.047" 172.31.91.109 [05/Jun/2023:06:13:23 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=3602590 rt=0.100 uct="0.000" uht="0.001" urt="0.099" 172.31.91.109 [05/Jun/2023:06:13:23 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=3602590 rt=0.047 uct="0.000" uht="0.001" urt="0.047" 172.31.91.109 [05/Jun/2023:06:13:23 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=3602590 rt=0.045 uct="0.001" uht="0.002" urt="0.045" 172.31.91.109 [05/Jun/2023:06:13:23 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=3602590 rt=0.066 uct="0.000" uht="0.002" urt="0.066"
对于慢连接大文件下载时长略有影响:46s (无限制) vs 53s (有限制)
关闭nginx reuseport
卡顿依然大量存在,但大多以连接能够建立但是下载不完的形式(200)出现,499较少,并且存在惊群现象,完整日志在此
client runtime log:存在卡顿,和benchmark没有区别
1 2 3 4 5 6 7 8 9 [2023-06-05 06:38:06,682] runtime=1008 [2023-06-05 06:38:07,692] runtime=1008 [2023-06-05 06:38:08,703] runtime=220 [2023-06-05 06:38:08,926] runtime=112 [2023-06-05 06:38:09,040] runtime=60 [2023-06-05 06:38:09,103] runtime=865 [2023-06-05 06:38:09,970] runtime=1009 [2023-06-05 06:38:10,982] runtime=1008 [2023-06-05 06:38:11,992] runtime=1009
client抓包结果:存在卡顿,存在RST,和benchmark没有区别
1 2 3 4 5 6 7 172.31.91.109 [05/Jun/2023:06:38:02 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=204595 rt=0.844 uct="0.362" uht="0.539" urt="0.845" 172.31.91.109 [05/Jun/2023:06:38:03 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=204595 rt=0.907 uct="0.334" uht="0.476" urt="0.906" 172.31.91.109 [05/Jun/2023:06:38:04 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=543900 rt=0.836 uct="0.319" uht="0.504" urt="0.836" 172.31.91.109 [05/Jun/2023:06:38:05 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=204595 rt=0.831 uct="0.161" uht="0.480" urt="0.830" 172.31.91.109 [05/Jun/2023:06:38:06 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=552849 rt=0.820 uct="0.180" uht="0.329" urt="0.819" 172.31.91.109 [05/Jun/2023:06:38:07 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=204595 rt=0.800 uct="0.122" uht="0.462" urt="0.800" 172.31.91.109 [05/Jun/2023:06:38:08 +0000] "GET /server.pcap HTTP/1.1" status=200 body_bytes_sent=543900 rt=0.871 uct="0.251" uht="0.380" urt="0.871"
存在惊群现象,以下是Nginx worker进程的cpu使用率和上下文切换频率对比
1 2 # 每5s输出一次统计结果 pidstat -w -u 5
两者的cpu使用率和上下文切换频率差不多,但关闭reuseport后花在wait上的cpu时间明显增加(1.3-1.6% vs 2.8-2.9%),这就是惊群带来的性能损耗。原始文件:开启reuseport ,关闭reuseport
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 开启reuseport Average: UID PID %usr %system %guest %wait %CPU CPU Command Average: 992 2590 1.77 9.57 0.00 1.25 11.35 - nginx Average: 992 2591 1.37 5.75 0.00 1.62 7.12 - nginx Average: UID PID cswch/s nvcswch/s Command Average: 992 2590 179.18 49.64 nginx Average: 992 2591 342.51 9.87 nginx # 关闭reuseport Average: UID PID %usr %system %guest %wait %CPU CPU Command Average: 992 2788 1.02 8.02 0.00 2.80 9.04 - nginx Average: 992 2789 0.92 9.07 0.00 2.97 9.99 - nginx Average: UID PID cswch/s nvcswch/s Command Average: 992 2788 159.06 28.68 nginx Average: 992 2789 250.26 22.93 nginx
惊群对于慢连接大文件下载时长略有影响:46s (开reuseport) vs 53s (关reuseport)
其他的观察
最初复现的场景是所有的instance都是t2.micro,但开2个慢连接进程时比较难复现,开4个进程又太容易触发限流,所以开始考虑用大一些又没那么容易限流的instance型号。考虑到aws是通过间歇掉包来限速的,慢连接进程数量并非越大越好,引发限速后反而会造成网络连接不畅,造成慢连接卡顿,使得快连接卡顿反而不容易观测。最后选择将慢连接全链路改成t3.micro,结果好复现多了.
可以观察到有一些access.log上499的连接,各种计时也是0,这其实是因为计时也是通过worker进行的,只有进行epoll和上下文切换才会在日志上打入时间信息,worker如果一直不进行切换,那么计时就会失真,就会看到日志上计时也是0的现象。
结论
reuseport是Nginx避免惊群的优秀feature,应该开启
开启reuseport后如果网络情况非常好且后端服务压力不大,且存在大量慢连接时,会造成快连接卡顿,这是Nginx的worker-epoll架构带来的,原因是recv buffer一直读不完,NGINX采用的epoll ET 触发模式在这种情况下一直无法触发暂停导致worker无法响应其它请求
减小recv buffer通过人为制造卡顿,提供了epoll ET切换连接的条件,可以很大程度上缓解这个问题,同时带来的负面效果是有一定性能损耗。但卡顿无法根除,只能控制在可接受范围内
参考资料
Nginx 惊群 – wenfh2020 Nginx reuseport – wenfh2020 Epoll – wenfh2020 上下文切换的案例以及CPU使用率 – cnhkzyy