实战瓶颈定位-我的MySQL为什么压不上去
实战瓶颈定位-我的MySQL为什么压不上去
背景
环境两台云上相同 128C的EC2(有点豪),一台当压力机一台当服务器,用Sysbench测试MySQL纯读场景,不存在任何修改,也就几乎没有锁
1 | #uname -r |
EC2机器128核,故意只给MySQLD绑定了其中的24Core,网卡32队列
1 | #ethtool -l eth0 |
压测过程
走同一交换机内网IP压MySQL跑不满CPU,跑压力和不跑压力时ping rtt 分别是 0.859/0.053(RTT 有增加–注意点), 此时TPS:119956.67 1000并发 RT 8.33
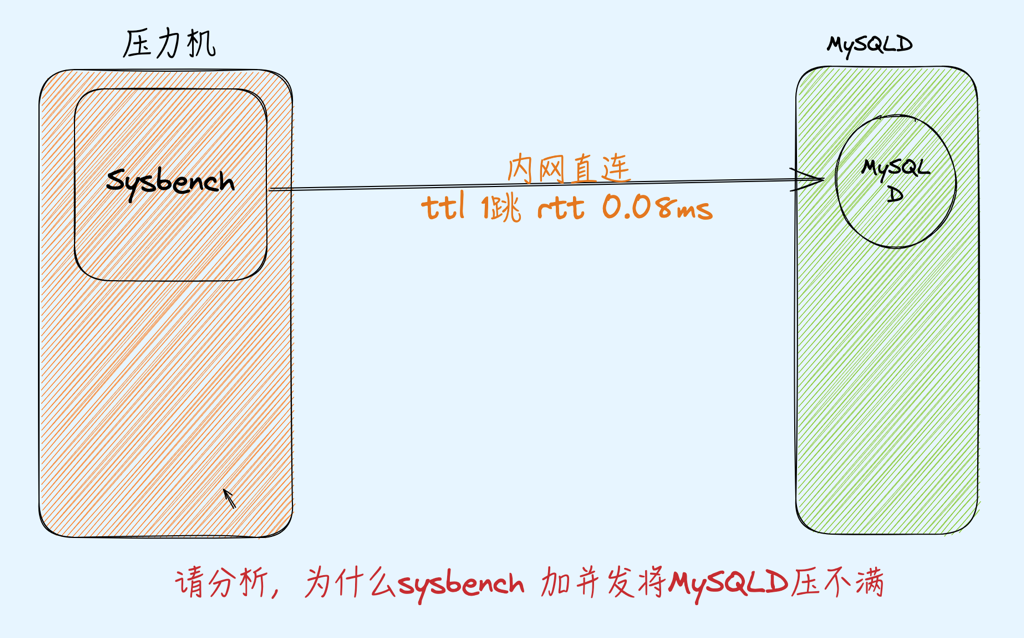
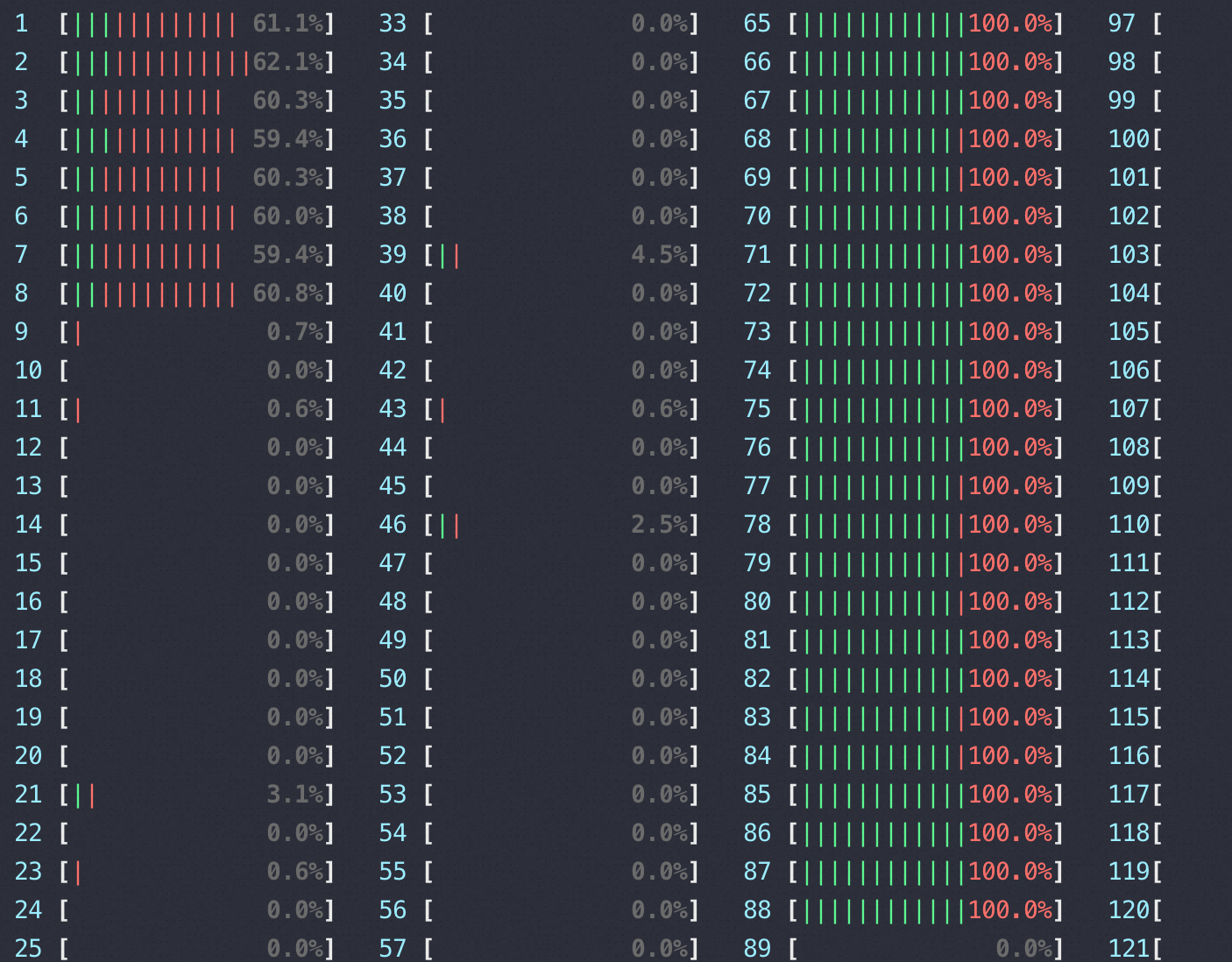
下图是压测时 htop 看到的MySQLD 所在EC2的 CPU使用情况,右边65-88是MySQLD进程(绿色表示us, 红色表示sys+si CPU)
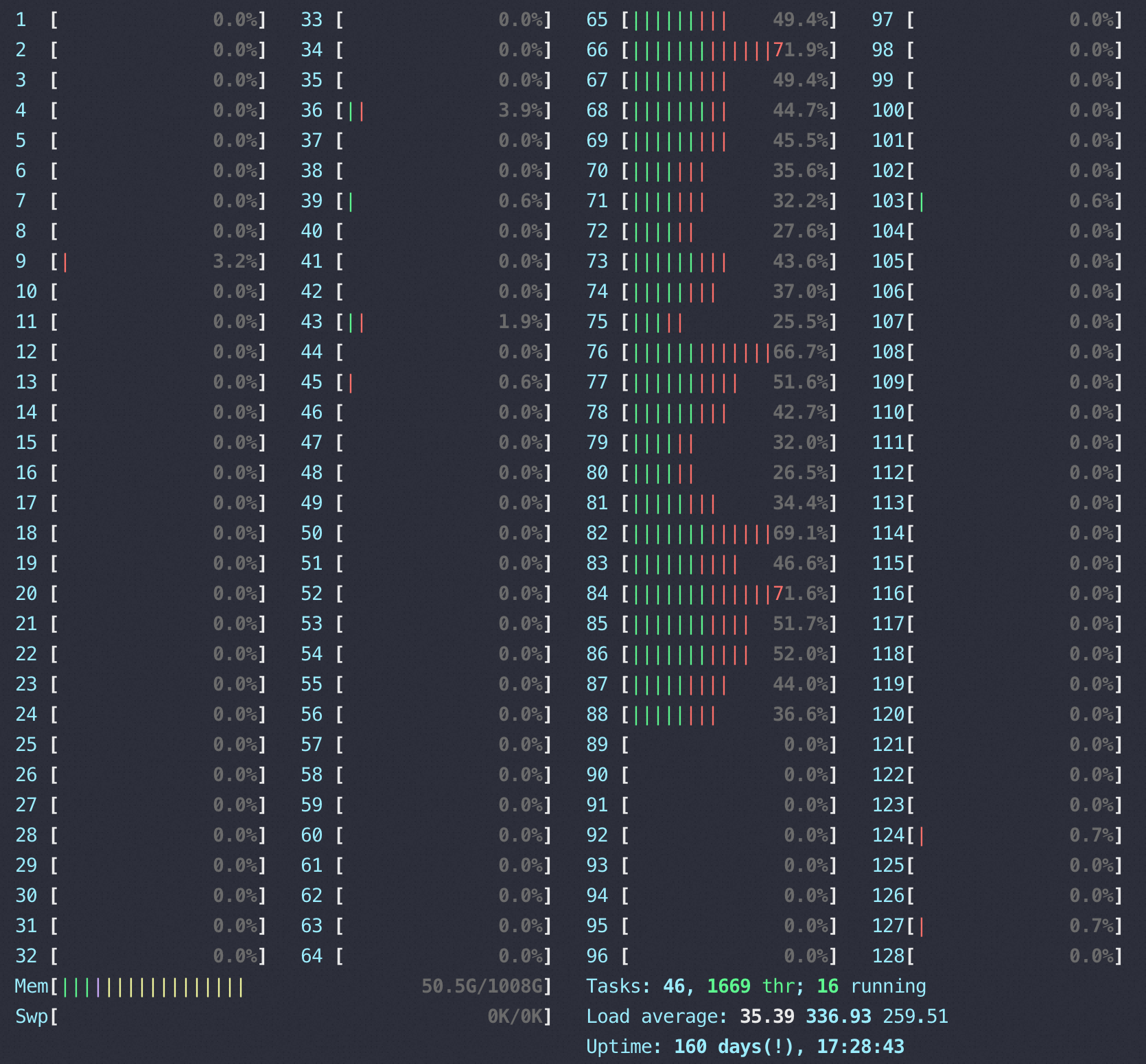
用top查看详细的每个 core 使用(只展示MySQLD使用的24core ,top 然后按1–还可以试试2/3,有惊喜)
1 | top - 13:49:55 up 160 days, 18:10, 3 users, load average: 555.26, 720.12, 462.21 |
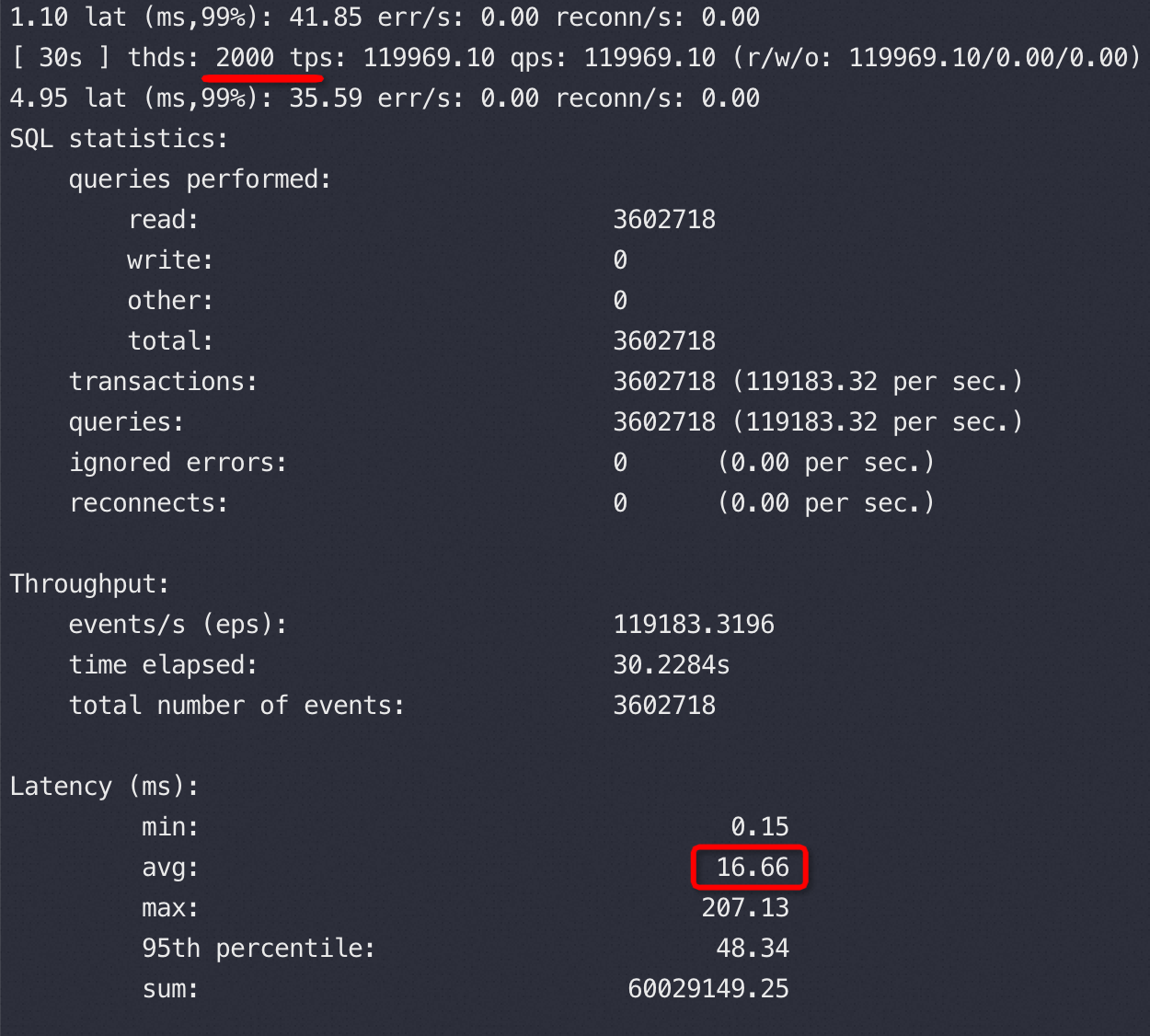
继续尝试用2000并发,TPS、CPU、ping rtt都和1000并发没有区别,当然按照我们以前QPS、RT理论2000并发的时候RT应该翻倍,实际确实是16.66,所以这里的问题就是翻倍的 RT哪里来的瓶颈就在哪里。
也试过用两个压力机每个压力机分别用1000并发同时压,QPS一样稳定——目的快速排除压力端、链路上有瓶颈。
写到这里RT 刚好翻倍16.66=8.33*2 数字精准得好像编故事一样,不得不贴一下原始数据证实一下:
1000 并发和2000并发时的ping RTT对比(ttl 64说明内网直达)
1 | #ping mysqld27 |
抓包证明
在抓保证明前推荐一个工具快速绕过抓包(原理也是通过pcap lib去分析网络包,tcpdump也会调用pcap lib)
监控tcprstat,从网络层抓包来对比两个并发下的RT:
1 | //./tcprstat -p 3307 -t 1 -n 0 -l 10.9.10.22 -f "%T\t\t%n\t\t%a\t%h\t%S\t%C\t%95M\t%95a\t%95S\t%99M\t%99a\t%99S\n" |
也就是网卡层面确认了压不上去瓶颈不在MySQL 上,加并发后网卡的RT没变(网卡RT包含MySQLD RT),因为ping RTT 在1000和2000并发也没有差异,推测交换机不是瓶颈,大概率出网卡的虚拟层面
在客户端的机器上抓包,上面我们说过了1000并发的RT是8.33毫秒:
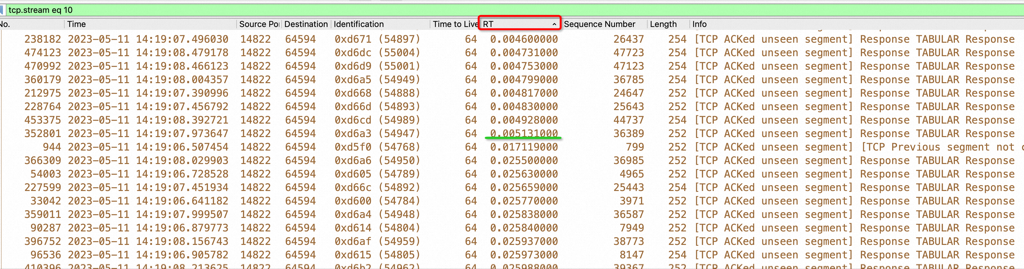
注意上图,我把RT排序了,明显看到5ms到17ms 中间没有这个RT范围的包,但是有很多25ms的RT,平均下来确实是8.33毫秒,留下一个疑问:RT分布不符合正态,而且中间有很大一段范围镂空了!这是不应该的。
同样我们再到MySQLD 所在机器抓包分析(注:正常路径先抓MySQLD上的包就行了):
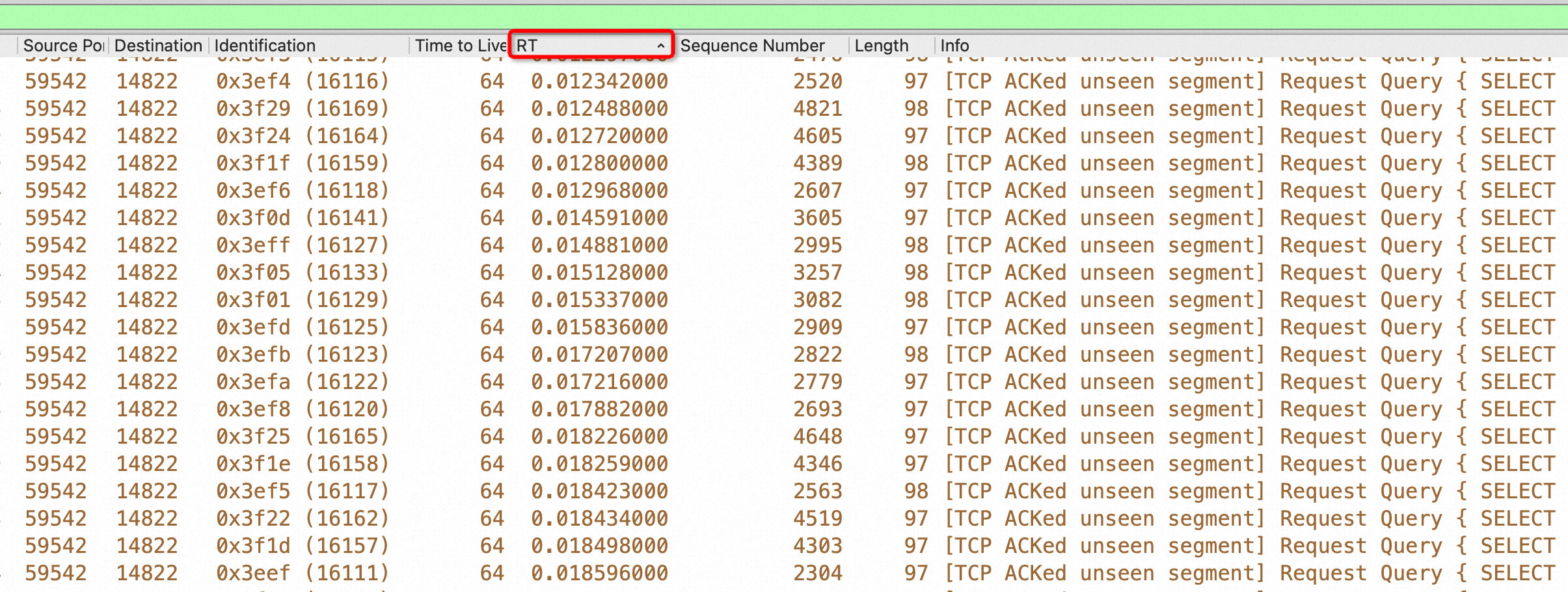
同样是对RT 排序了,但是慢的RT都是对端发慢了(注意最右边的select, MySQL相应是 response),同样对这个抓包求平均时间就是tcprstat 看到的103微秒,也就是0.1毫秒。如下图红框是请求,请求的间隔是11毫米,绿框是响应,响应的间隔都是0.2ms不到
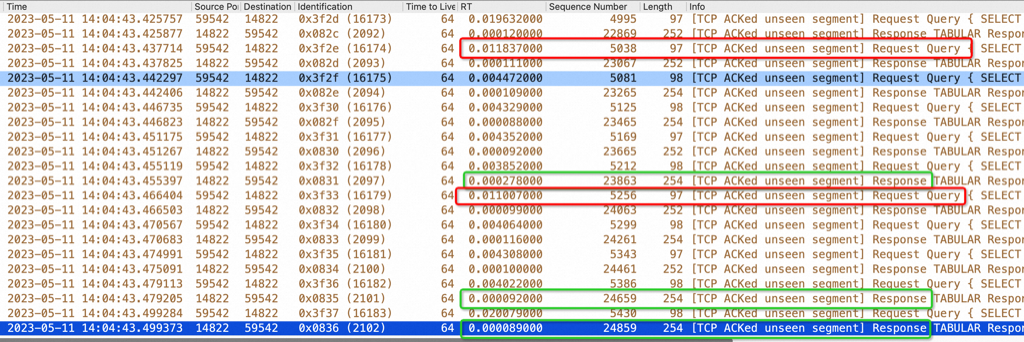
同样在2000并发时也对MySQLD所在网卡抓包对比,response 的RT 没有变化,从这里可以看出瓶颈点在sysbench 和 MySQLD 的网卡之间的链路上,似乎有限流、管控
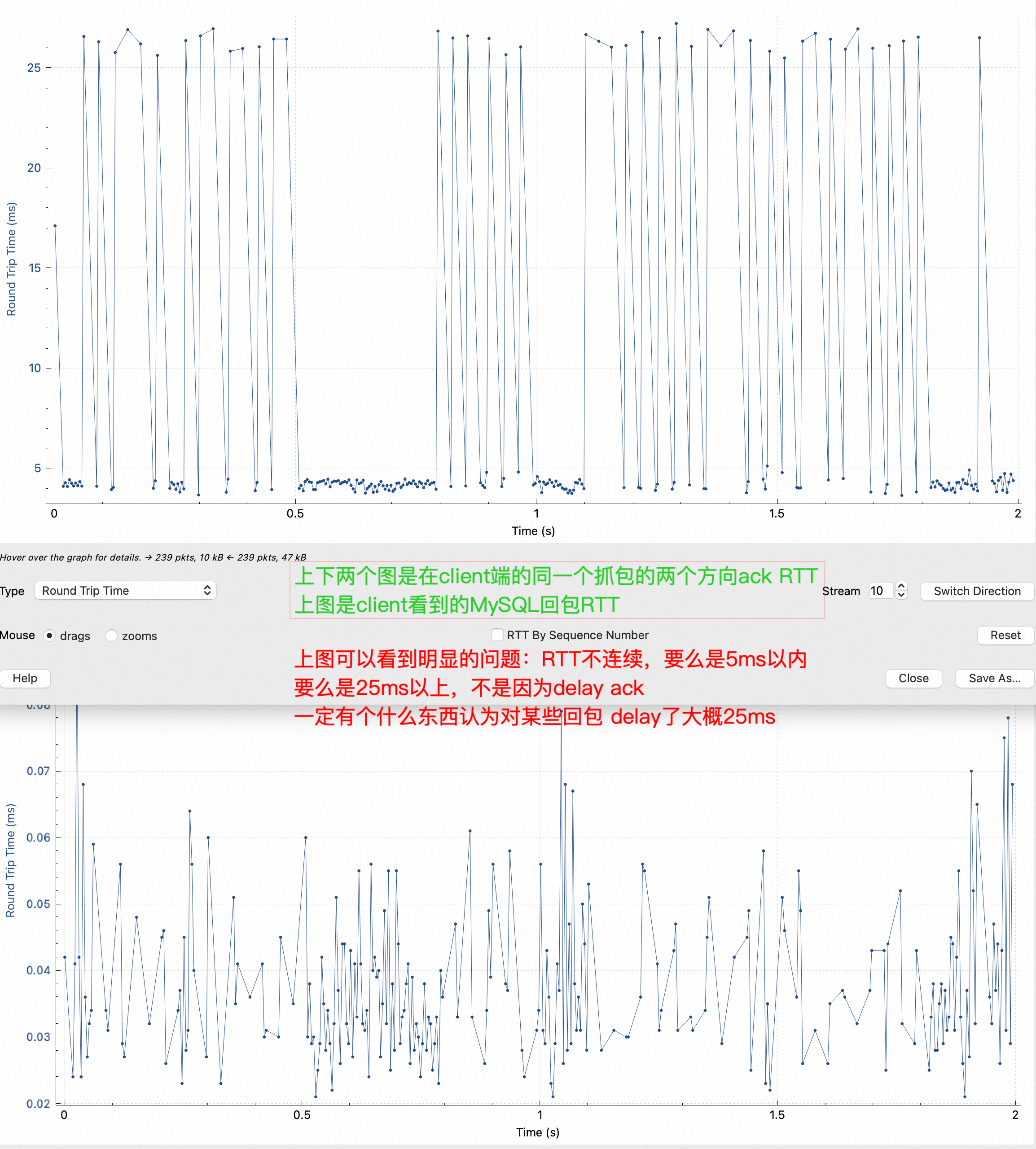
快速验证
到这里我们已经找到了有力的证据,RT是在离开MySQLD网卡后增加上去的,先验证下走走本机127.0.0.1快速压一把,让sysbench 跑在0-7 core上,这时可以看到MySQL跑满了CPU,下图左边1-8核是压力进程,右边65-88是业务进程,TPS:239969.91 1000并发 RT 4.16
htop状态:
各CPU 详细分析:
- us MySQL解析SQL、处理查询
- si 网络软中断
- sy OS 的sys API 消耗,一般用户进程会调用系统 API, 比如读写文件、分配内存、网络访问等
1 | //sysbench |
就以上sysbench VS MySQLD 的CPU 消耗来看,因为sysbench 处理逻辑简单,就是发SQL给MySQLD,所以 sysbench自身US很少,大部分都是调用OS的网络操作,而MySQLD有 60% CPU用于US,也就是自身业务逻辑,MySQLD收到SQL要做SQL解析,要去查找数据,这些都是用户态消耗,找到数据后走网络发给Sysbench,这部分是sy
到这里可以拿着证据去VIP通道(土豪+专业的客户得有VIP通道)找做网络管控的了,不会再有撕逼和甩锅
sysbench 结果不是正态分布
把所有请求RT 分布进行图形化,此时平均 RT 8.33,理论上是一个正态分布,下图是有限速时:
1 | 3.615 | 2177 |
去掉限速后平均 RT 3.26(比下图中大概的中位数2.71大了不少) 完美正态
1 | 1.857 |** 19894 |
用其他网络业务验证
先测试一下网络下载时的ping:
1 | --无流量 |
有限速方向,尝试了BBR和cubic 拥塞算法:
1 | #tcpperf -c 172.16.0.205 -t 100 |
跑tcpperf触发限速时的监控(上下两个窗口是同一台机器),红色是丢包率挺高的,绿色丢包就没了,应该是拥塞算法和限速管控达成了平衡
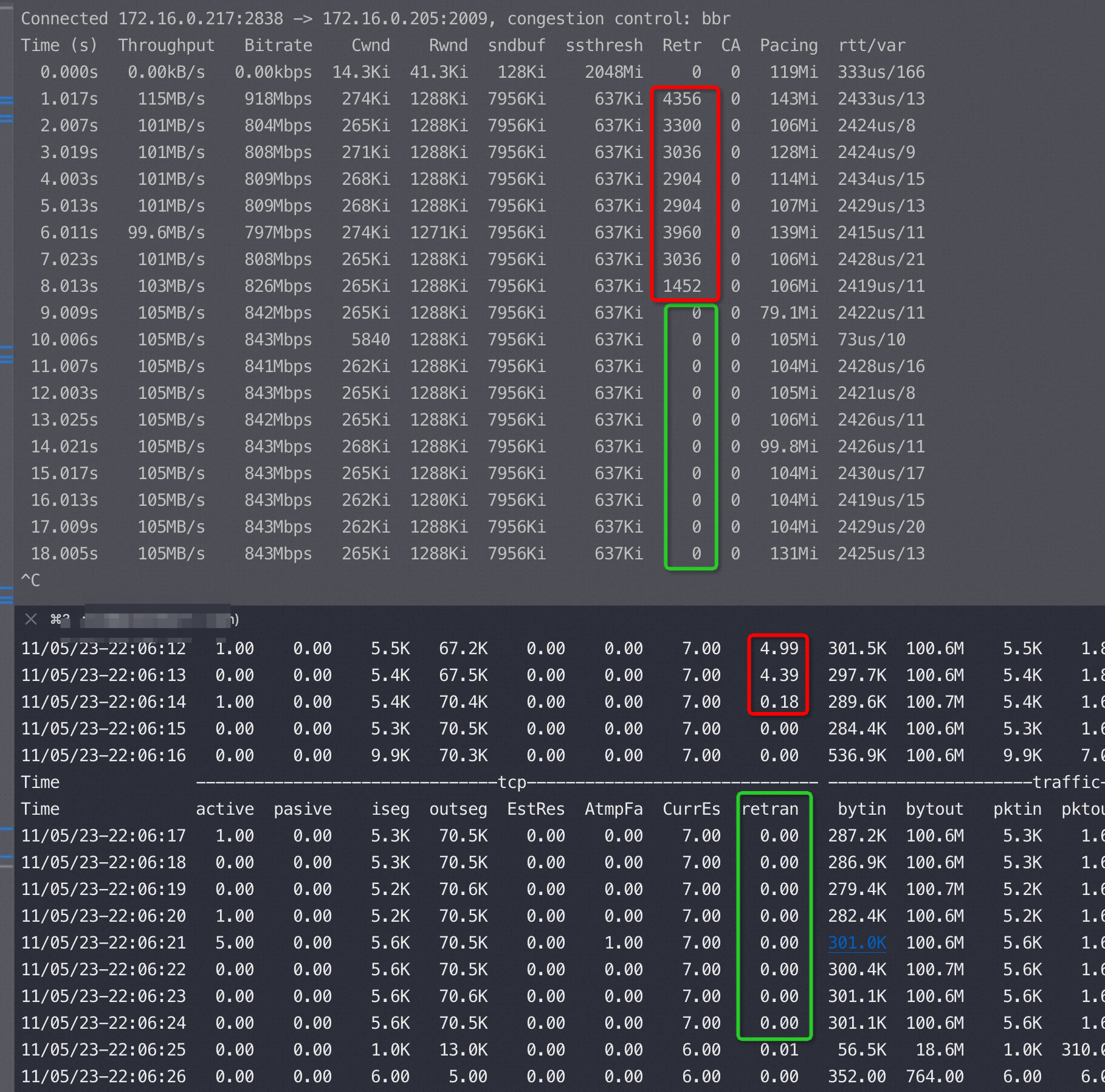
反过来限速被我去掉了(限速可以进出双向单独控制)
1 | #tcpperf -c mysqld217 -t 1000 |
查看限速配置如下:
1 | {txcmbps:844.000, txckpps:120.000} |
sysbench(主键查询-小包) 12万QPS 正好命中 txckpps:120,tcpperf (大包)稳定的105MB带宽命中txcmbps:844
去掉后长这样:
1 | #ovsctl -n set_out_pps -v -1 //把pps限制为-1==不限制 |
对这块网络管控感兴趣可以去了解一下 ovs 这个开源项目(open virtual switch)
去掉网卡限速后的结果
实际结构如下:
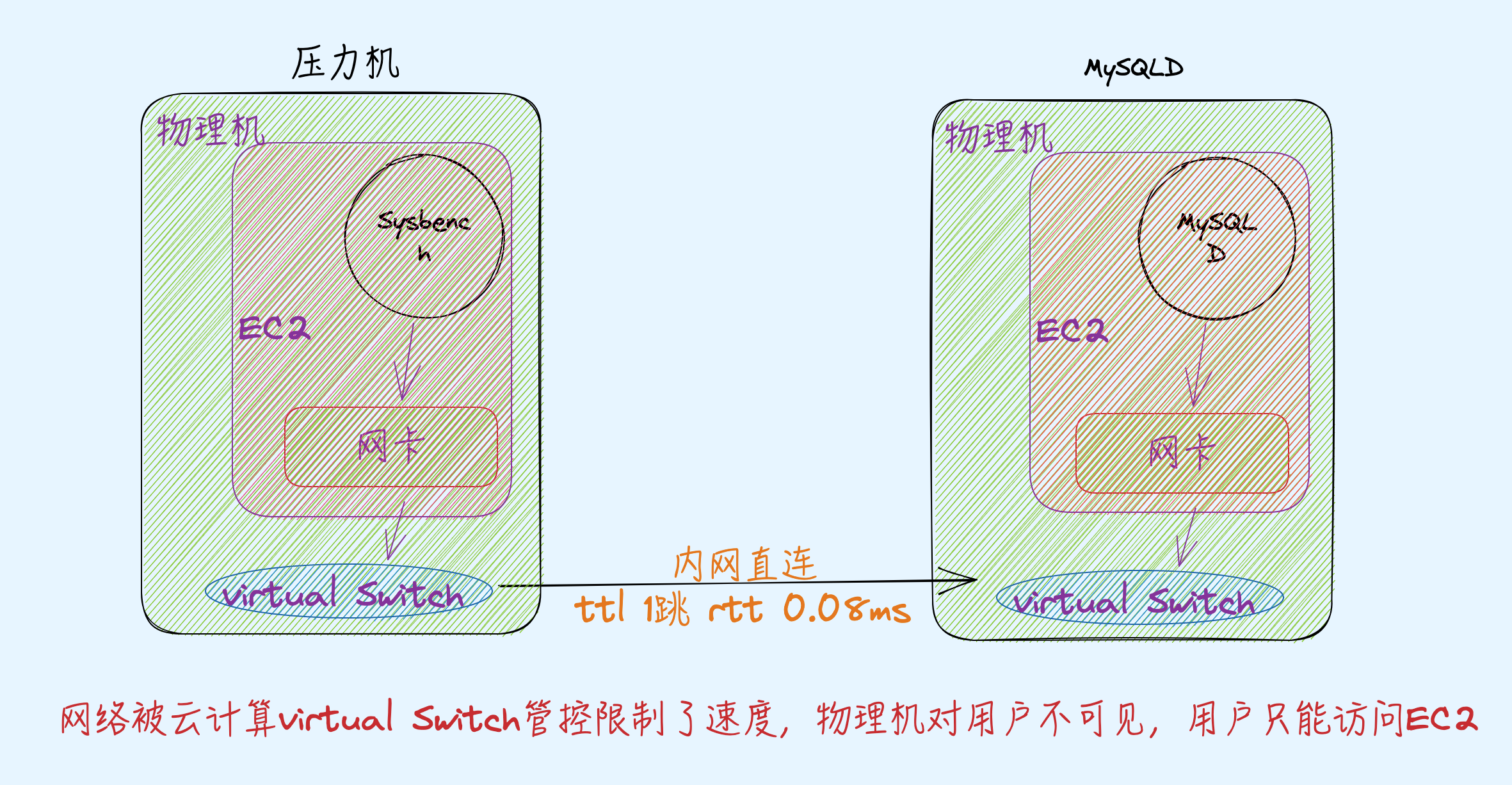
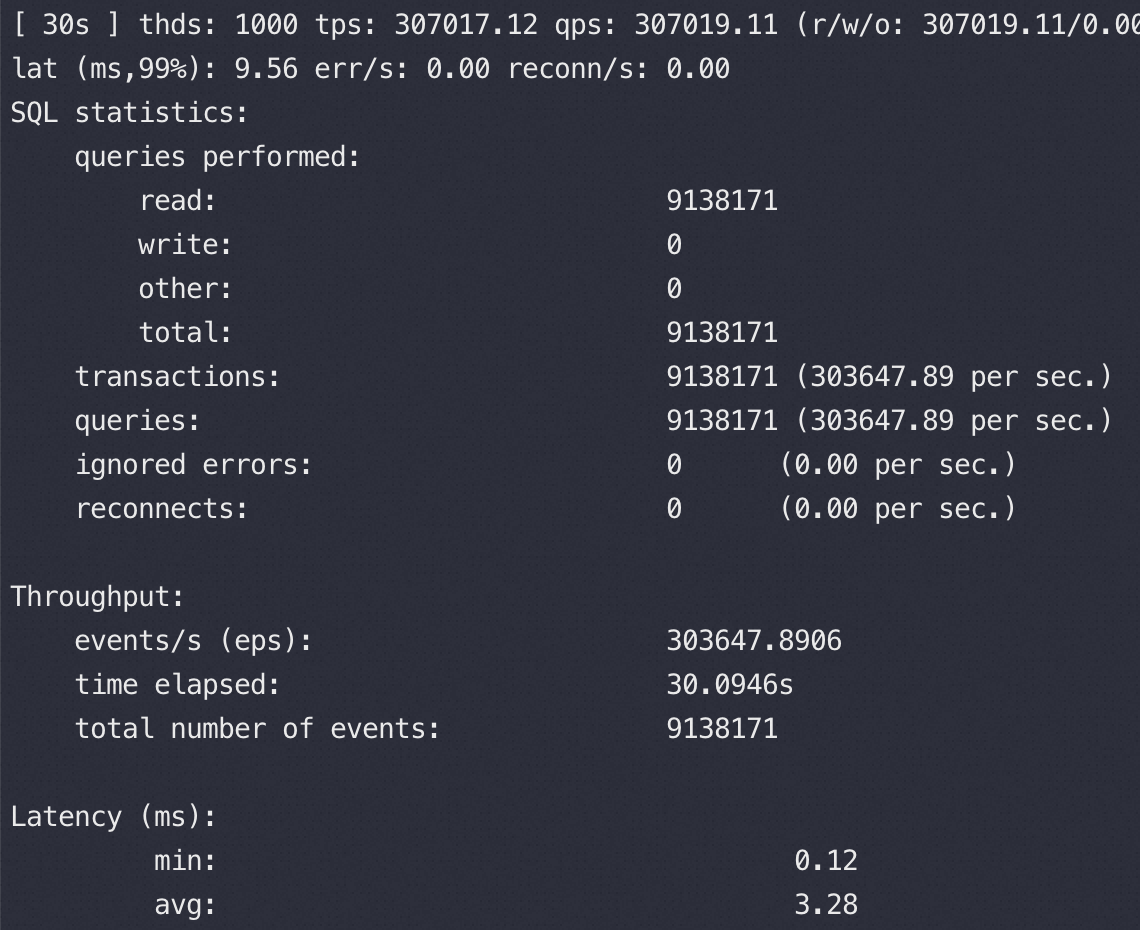
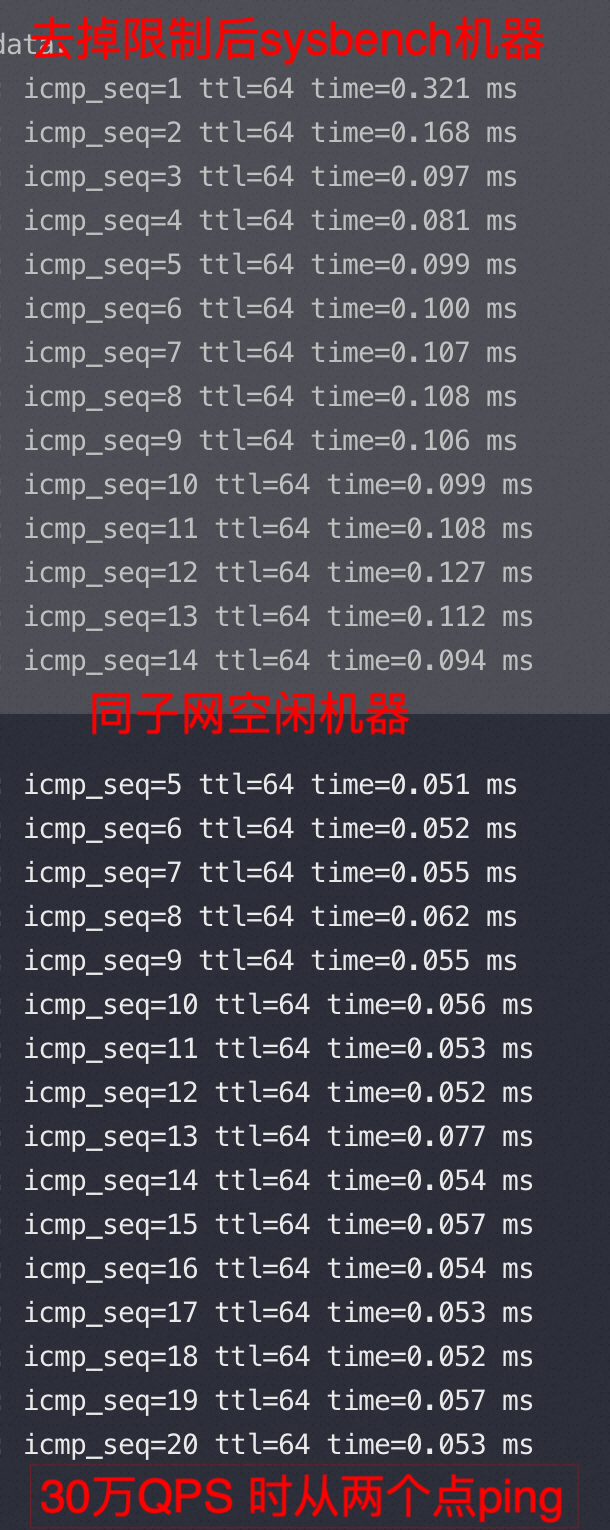
放开所有网络控制后,1000并发压力 30万QPS,RT 3.28,此时从sysbench 以及空闲机器ping MySQLD机器的 RTT和没压力基本一致
top状态:
1 | %Node1 : 23.4 us, 12.3 sy, 0.0 ni, 61.4 id, 0.0 wa, 0.0 hi, 3.0 si, 0.0 st |
小思考:
我们中间尝试走本机127.0.0.1 压测时QPS 是24万,比跨机器压的 30万打了8折,想想为什么?网络延时消耗完全没影响?
总结
简单可复制的证明办法:抓包,快速撕逼和分析
肯定有很多人想到:内存、磁盘、线程池、队列、网络等等原因,但是这些所有原因有一个共同的爹:RT,所有这些影响因素最后体现出来就是RT 高了,你CPU资源不够、内存慢最后总表现就是在客户端看来你的 RT 太高。
所以我们去掉这些复杂因素先在MySQLD所在EC2 的网卡上抓一个包看看RT,再对比一下1000/2000并发时抓包看到的 RT 有没有升高,如果有升高说明问题在MySQLD这端(含OS、MySQLD的问题),如果 RT 不变那么问题不在MySQLD这端,并且从EC2网卡出去都是很快的,那么问题只能是在路上或者客户端的sysbench自己慢了。
这是我们星球里说的无招胜有招–抓包大法,扯皮过程中我还没见过几个不认网络抓包的,也有那么一两个扯上是不是网卡驱动有问题,我的代码不会有问题
两个限速条件:pps 120k(每秒最多12万网络包),带宽 844mbps=105.5MB/s
Sysbench 查询都是小包,触发第一个条件,tcpperf触发第二个条件
ping ping神功失效了吗?也没有,我后来又测试了100、200并发,rtt 0.2ms和0.4ms,也就是说随着并发的增加rtt 增加到0.8ms后就不再增加了。上来1000并发已经到了天花板
1 | 64 bytes from polardbxyt27 (mysqld217): icmp_seq=159 ttl=64 time=0.226 ms |