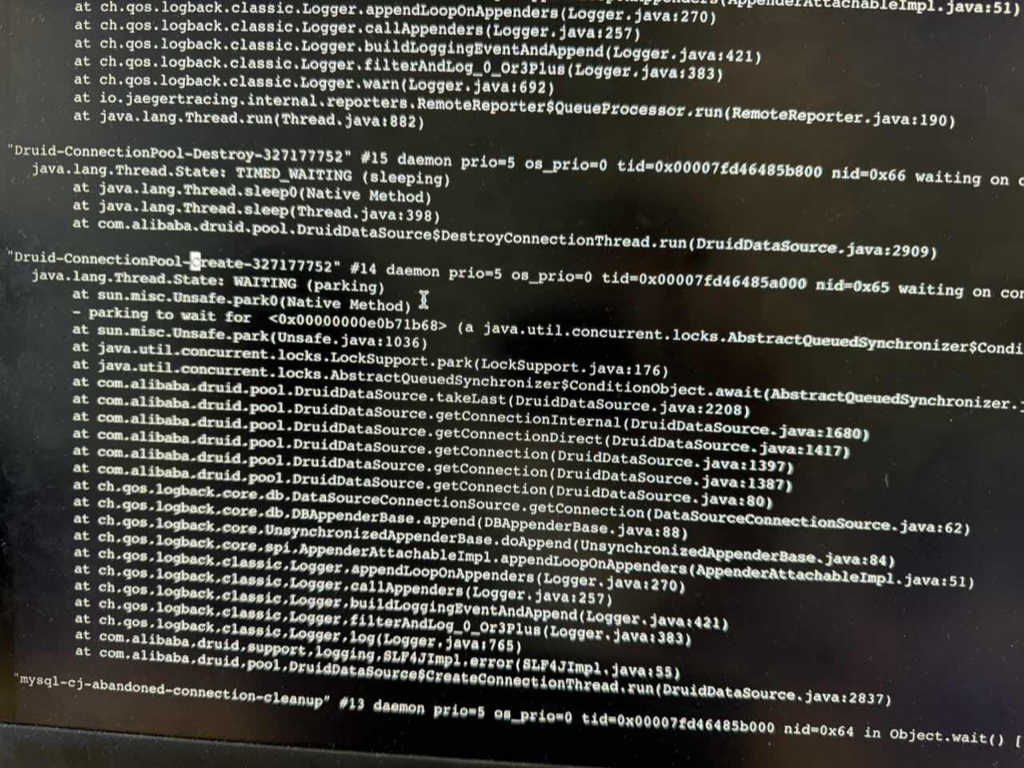
"Druid-ConnectionPool-Create-1647809146" #265 daemon prio=5 os_prio=0 tid=0x00007fbcdfd5f000 nid=0x1a0 runnable [0x00007fbcdf9fd000] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:171) at java.net.SocketInputStream.read(SocketInputStream.java:141) at com.mysql.jdbc.util.ReadAheadInputStream.fill(ReadAheadInputStream.java:101) at com.mysql.jdbc.util.ReadAheadInputStream.readFromUnderlyingStreamIfNecessary(ReadAheadInputStream.java:144) at com.mysql.jdbc.util.ReadAheadInputStream.read(ReadAheadInputStream.java:174) - locked <0x00000000e71ca648> (a com.mysql.jdbc.util.ReadAheadInputStream) at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:3001) at com.mysql.jdbc.MysqlIO.readPacket(MysqlIO.java:567) at com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:1018) at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2253) at com.mysql.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:2284) at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2083) - locked <0x00000000e7f898f0> (a com.mysql.jdbc.JDBC4Connection) at com.mysql.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:806) at com.mysql.jdbc.JDBC4Connection.<init>(JDBC4Connection.java:47) at sun.reflect.GeneratedConstructorAccessor196.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at com.mysql.jdbc.Util.handleNewInstance(Util.java:404) at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:410) at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:328) at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1558) at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1623) at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:2468) "Druid-ConnectionPool-Create-1823047135" #160 daemon prio=5 os_prio=0 tid=0x00007fbd60cf0000 nid=0x142 waiting on condition [0x00007fbd043fe000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park0(Native Method) - parking to wait for <0x00000000c448b348> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at sun.misc.Unsafe.park(Unsafe.java:1036) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:176) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2047) at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:2443)
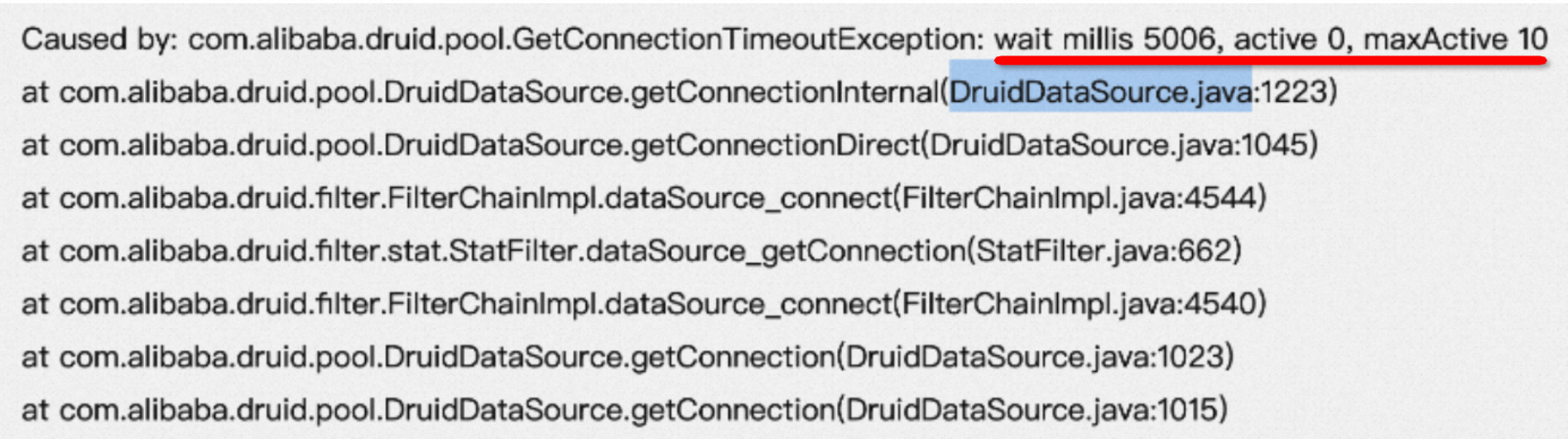
Caused by: java.sql.SQLException: maxWaitThreadCount 160, current wait Thread count 0 at com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1620) at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1404) at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:5059) at com.alibaba.druid.filter.FilterAdapter.dataSource_getConnection(FilterAdapter.java:2756) at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:5055) at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1382) at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1374) at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:98)
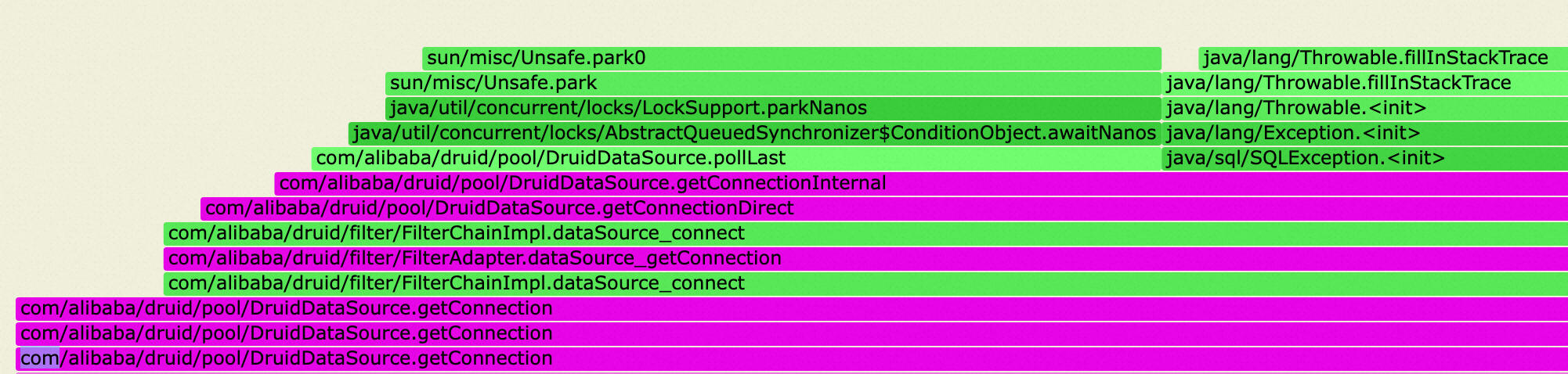
#grep CreateConnectionThread.run stack4.log at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:2818) at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:2813)
Druid 报错3
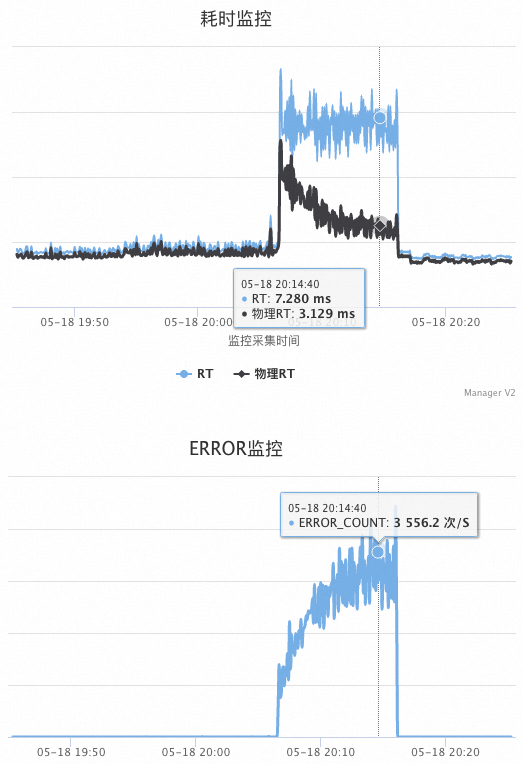
借出连接为0(active 0),creating也是0,没有新连接正在创建。
分析方法:
dump Java应用内存,用MAT内存分析工具打开dump文件
使用OQL,select * from com.alibaba.druid.pool.DruidDataSource where createTaskCount=3