扑朔迷离的根因分析--抖动和并发
扑朔迷离的根因分析–抖动和并发
前言
我们之前说过根因分析第一就是要追着 RT跑,随着并发的增加哪里RT增加快哪里就是瓶颈,这是我们的基本原则,但总有一些例外,我们今天想说说例外
场景
如下图,应用是多个Tomcat集群,Tomcat节点可以随意增加,后端是一组DB集群,有几百个Database实例,每一次业务请求都会对应多个Database查询
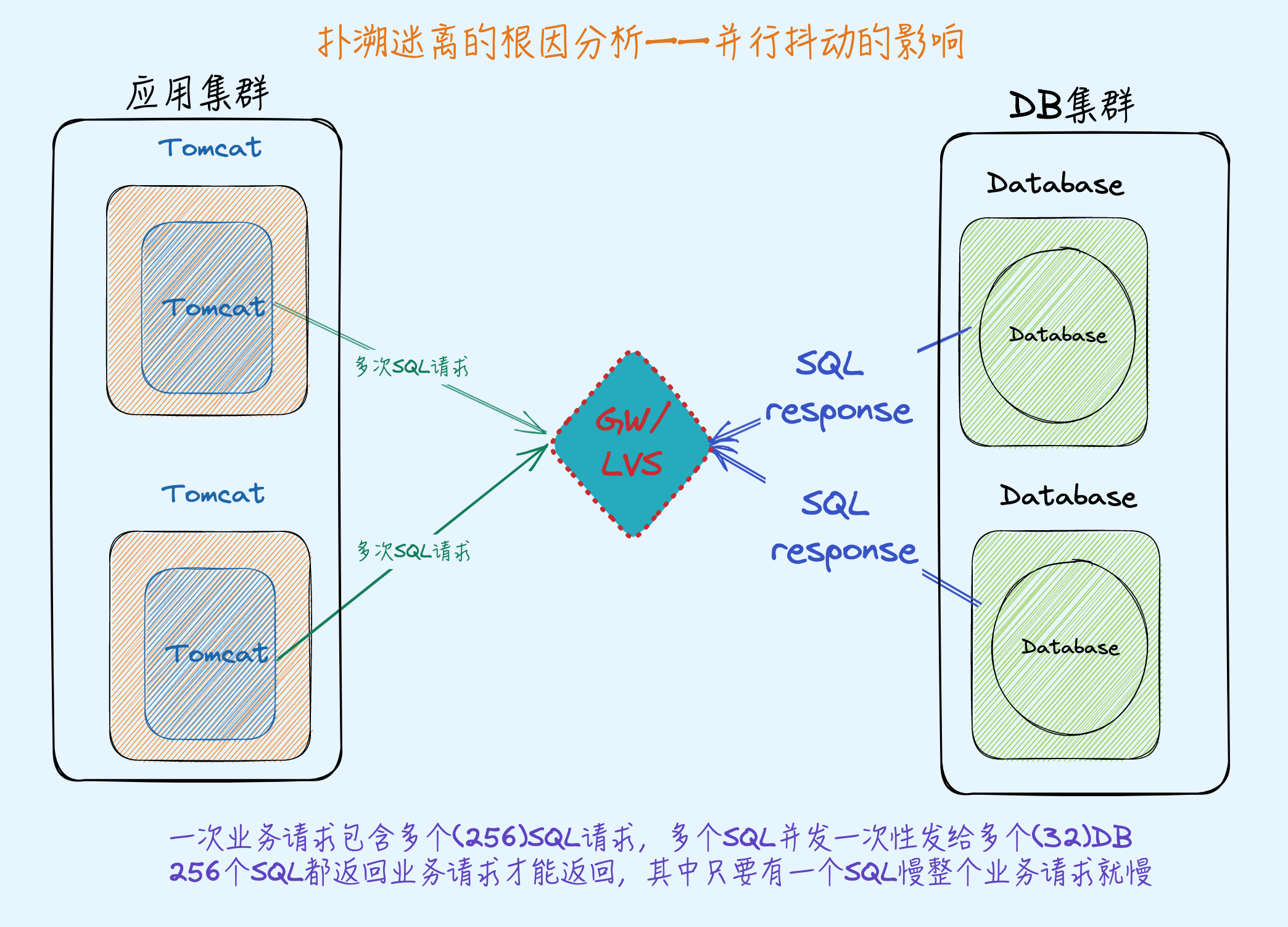
问题
开始的时候客户端压2个Tomcat集群,QPS 700,Tomcat节点CPU 90%,Database每个节点CPU 20%左右,于是增加1个Tomcat 节点这个时候QPS 还是700,Tomcat的RT增加了50%,Tomcat CPU 降低到60%,继续增加Tomcat 节点 RT、QPS保持稳定,CPU使用率下降。
所以这里要搞清楚哪里是瓶颈,如果Tomcat是瓶颈加Tomcat节点为什么没有效果。如果Database是瓶颈但是增加Tomcat节点的时候Database 的RT有一点点增加,远远没有到增加50%的RT 程度
分析
首先最容易想到的是Tomcat 和 Database之间的网络、网关、LVS 等资源到了瓶颈,但是经过排查分析这些环节都排除了,另外也排除了Tomcat到Database的连接池、Database的磁盘等瓶颈,另外Tomcat 访问Database全是查询,没有事务。
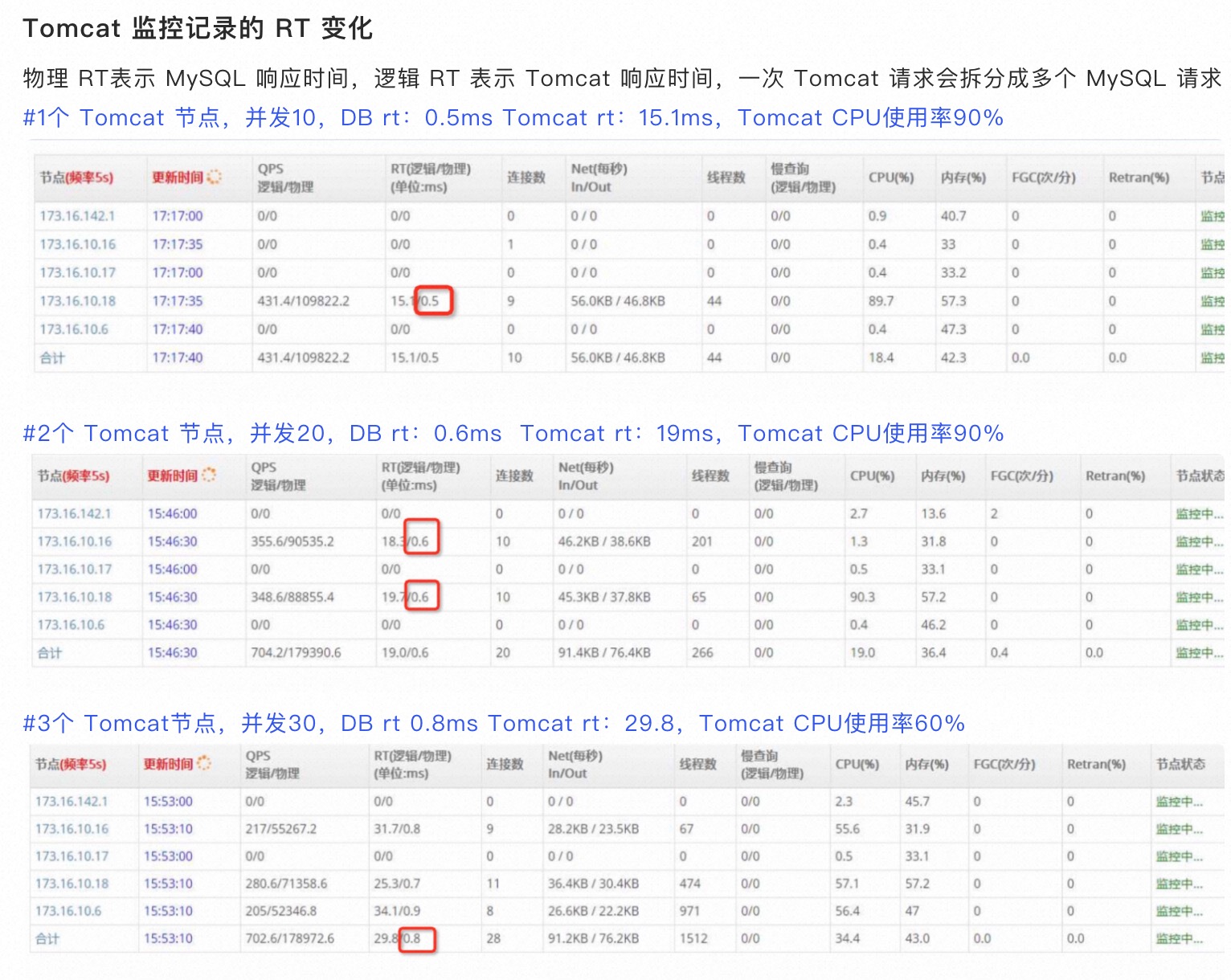
看起来事情比想象的复杂,于是进行了如下压测:
先用一个压力端压3个Tomcat中的2个,QPS 跑到700,然后新开一个压力端压第三个Tomcat(新开压力端是排查压力机的问题,新开Tomcat是想排除Tomcat 的问题),如果Tomcat是瓶颈的话QPS应该上去,或者说后端没有问题的话那两个Tomcat 的700 QPS得保持基本稳定不变或略微下降才对。
实际上第二个压力端跑起来后,前两个Tomcat的QPS 铛就掉下去了,总QPS 保持稳定不变,也就是随着Tomcat给后端并发压力的增加后端肯定给了一个负反馈给那两Tomcat,导致那两Tomcat QPS掉下去了。这个负反馈明显得是Database的RT在增加,但是从监控来看Database的RT 从0.6增加到了0.8,但是Tomcat 的RT 增加更快从19.7增加到了29.8.
单独压DB,DB的QPS能高5倍,CPU 也可以跑到100%。看起来单压都没问题,一组合就不行了
问题在Database
绕过Tomcat 用相同的SQL 压Database QPS 一下子就能上去,Database 的CPU 也跑到了100%,但是只要走Tomcat 就会上不去。
打开Tomcat 日志将所有Database的响应时间拉出来分析,发现随着并发的增加 100 ms的响应也多了很多,实际上这些查询都是1ms就应该返回
原因
当压力增加的时候MySQL端等锁导致的 RT 抖动或者说长尾越来越多,虽然没有数据库的写,但是查询的时候优化器也需要统计行数等数据来为查询优化器做选择依据,这个统计动作会触发加锁排队(极短),但是因为这一代Intel CPU指令的变化导致这个锁被放大了10 被,所以最终Tomcat 端看到的长尾就多了
为什么
为什么同样的环境、同样的SQL 绕过Tomcat 就能压上去?
绕过后的压测场景没有业务逻辑,每次请求就是一条SQL,虽然有抖动但是对平均RT拉升不明显。
走业务逻辑压Tomcat 为什么不行?
业务逻辑是一次请求会发256条SQL,等这256条SQL全部返回来了业务请求才会返回!请反复读这句话3遍再往下看
如果256条SQL 中有一条花了100 ms返回那么整个业务逻辑的RT 就是100ms,假设1%的概率一条SQL是100ms,99%的SQL 是 1ms,你可以先停下来算一算这种业务模型下的平均RT是多少
计算抖动下的平均RT
关于这个抖动对整体rt的影响计算:
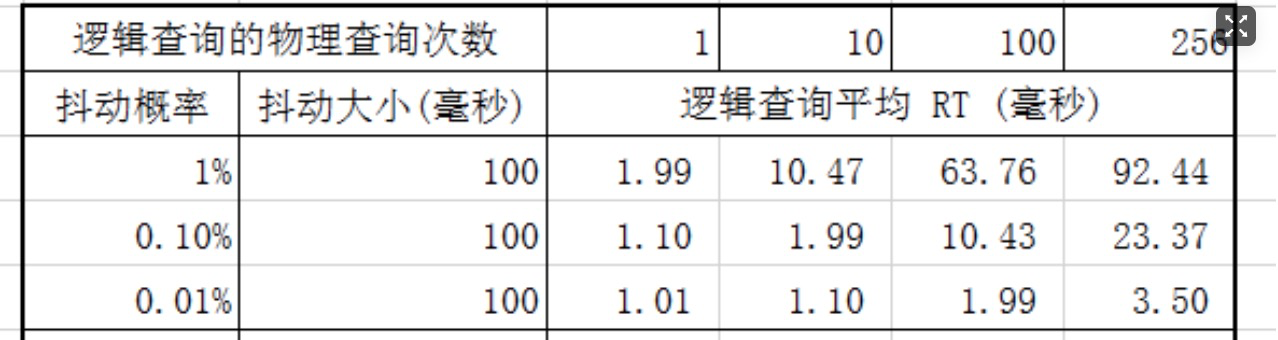
注:假设正常查询rt 1ms,逻辑平均rt=(1-power(1-抖动概率,物理查询次数))*抖动大小+(power(1-抖动概率,物理查询次数))*1ms
当前场景下,逻辑QPS:物理QPS=1:256,假如每次查询有1%的物理(RDS)rt抖动到100ms,则会导致逻辑平均rt恶化到92.44ms.
在一次逻辑查询里,只有所有物理查询都不抖整体才是不抖,RT正常;如果有一个或多个物理查询抖了,那么逻辑RT就是抖动RT。
所以一次逻辑查询不抖的概率是: power(1-抖动概率, 物理查询次数)
反过来想这256条SQL都不碰上抖动这次业务请求才会1ms返回(概率极低),否则就是256ms返回
为什么要讲这个案例
倒不是出于原因分析,这个原因几年前就分析清楚了,但是这个场景:一次业务请求会涉及多次SQL、Redis、MQ的调用,只要其中有一个有短板、抖动这次业务请求就慢了。这简直太常见了
但难在别人的抖动很低被平均掉了,但是业务(Tomcat) 就要替别人背锅了,因为别人的RT 几乎没有增加或者加很少,但是Tomcat RT增加很明显,瓶颈当然看着像是在Tomcat 上。背锅吧也不可怕可怕的是你增加Tomcat 节点也不能解决问题,这才是你要从这个案例里学到的。
如果你的Tomcat 调后端因为短板(抖动)导致压力打不到后端,因为抖动导致Tomcat不能快速返回
上游影响下游:
和本文无关但是可以放一起综合来看上下游互相影响的复杂性
以前认为事务不提交的主要代价是行锁持有时间变长(这确实是个问题),今天见识到了新代价,事务不提交会导致事务活跃链表变长,增加copy readview的代价,进而导致DB的RT 增高,实际导致DB RT高的根本原因是DB前面的业务早到了瓶颈,来不及发送commit,导致DB端事务堆积严重。也就是业务瓶颈导致了后端DB RT高,只看RT就会被蒙蔽——怎么解决?可以抓包看commit发送慢