time_zone 是怎么打爆你的MySQL的
time_zone 是怎么打爆你的MySQL的
基础知识
这篇关于time_zone 的总结写得非常好Time_zone ,建议先读完做个基础知识的打底
Mysql日期和时间存储数据类型
| 存储类型 | 存储值示例 | 解释 | 适用场景 |
|---|---|---|---|
| Datetime | YYYY-MM-DD HH:MM:SS | 时间日期类型。DB时区切换它的值不时区相关常见名词解释变, 但时区切换后代表的时间信息已改变. | 使用简单、直观、方便。适用于无需考虑时区的业务场景,例如国内业务 |
| Timestamp | 名词1547077063000 | 解释以UTC时间戳来保存, DB时区切换它代表的时间信息值不会变,但是会随着连接会话的时区变化而变化。 内部以4个字节储存, 最大值可表示到2037年. | 适用于客户端需要支持多时区自适应的场景,因精度有限,不推荐使用 |
| Date | GMTYYYY-MM-DD | 全称Greenwich Mean Time 格林威治(也称:格林尼治)时间,也叫世界时(Universal Time),也叫世界标准时间。是指位于英国伦敦郊区的【皇家格林尼治天文台】的标准时间,是本初子午线上的地方时,是0时区的区时。GMT格林威治时间可认为是以前的标准时间日期类型,不包含时间信息 | 不关注时区只需要显示日期的场景 |
| Varchar | UTCYYYY-MM-DD HH:MM:SS | 全称Coodinated Universal Time 协调世界时,又称世界统一时间、世界标准时间、国际协调时间。它是以原子时(物质的原子内部发射的电磁振荡频率为基准的时间计量系统)作为计量单位的时间,计算结果极其严谨和精密。它比GMT时间更来得精准,误差值必须保持在0.9秒以内,倘若大于0.9秒就会通过闰秒来”解决”。UTC时间是现在使用的世界时间标准字符串类型,可以用时间字符串来表示日期时间类型,格式可自定义,如果用ISO标准时间格式存储,则可以包含时区信息:yyyy-MM-dd’T’HH:mm:ss.SSS+HH:MM | 自定义存储日期时间格式,可包含时区信息,适用于只需要显示时间的场景,不方便计算 |
| Bigint | DST1547077063000 | Daylight Saving Time的简称,又称“日光节约时制”和“夏令时间”,也叫夏时制。表示为了节约能源,人为规定时间的意思。在这一制度实行期间所采用的统一时间称为“夏令时间”,在欧洲和北美用得比较多数字类型,可以存储时间戳,表示某个时刻,稳定性最好 | 存储某个时刻,可以表达时间的确定性,存储/网络传输稳定性最好 |
时区相关常见名词解释
| 名词 | 解释 |
|---|---|
| GMT | 全称Greenwich Mean Time 格林威治(也称:格林尼治)时间,也叫世界时(Universal Time),也叫世界标准时间。是指位于英国伦敦郊区的【皇家格林尼治天文台】的标准时间,是本初子午线上的地方时,是0时区的区时。GMT格林威治时间可认为是以前的标准时间 |
| UTC | 全称Coodinated Universal Time 协调世界时,又称世界统一时间、世界标准时间、国际协调时间。它是以原子时(物质的原子内部发射的电磁振荡频率为基准的时间计量系统)作为计量单位的时间,计算结果极其严谨和精密。它比GMT时间更来得精准,误差值必须保持在0.9秒以内,倘若大于0.9秒就会通过闰秒来”解决”。UTC时间是现在使用的世界时间标准 |
| DST | Daylight Saving Time的简称,又称“日光节约时制”和“夏令时间”,也叫夏时制。表示为了节约能源,人为规定时间的意思。在这一制度实行期间所采用的统一时间称为“夏令时间”,在欧洲和北美用得比较多 |
| PDT | 全称Pacific Daylight Time太平洋夏季时间,也称夏令时。每年的3月份第二个星期日凌晨2点开始至11月份第一个星期日凌晨2点结束,第一天23个小时。「北美的西海岸太平洋沿岸地区,大城市有:温哥华,西雅图,旧金山,洛杉矶,拉斯×××,圣迭戈,萨克拉门托,波特兰等」 |
| PST | 全称Pacific Standard Time太平洋标准时间,也称冬令时。从11月份第一个星期日凌晨2点开始至次年3月份第二个星期日凌晨2点结束,第一天25个小时。 |
| CST | CST可视为中国、古巴的标准时间或美国、澳大利亚的中部时间CST可以表示如下4个不同的时区的缩写:中国标准时间:China Standard Time UT+8:00古巴标准时间:Cuba Standard Time UT-4:00美国中部时间:Central Standard Time (USA) UT-6:00澳大利亚中部时间:Central Standard Time (Australia) UT+9:30因此具体含义需要根据上下文环境确定具体含义。在中国就表示东八区”北京时间” |
| UTC+08:00 | 基于UTC标准时间的时区偏移量,可表示东八区。UTC±[hh]:[mm]形式表示某个时区的区时,由UTC和偏移量组成。UTC+08:00就表示东八区时区的本地时间 = 世界协调时间UTC + 时区偏移量(+8h) |
| ISO | 在时间日期上它全称是ISO 8601,是一种日期/时间表示方法的规范。规定了一种明确的、国际上都能理解的日历和时钟格式。在Java语言中常见格式:●ISO.DATE:yyyy-MM-dd, e.g. “2023-02-03”●ISO.TIME:HH:mm:ss.SSSXXX, e.g. “10:30:00.000-11:00”●ISO.DATE_TIME:yyyy-MM-dd’T’HH:mm:ss.SSSXXX, e.g. “2022-10-31T01:30:00.000-05:00”. |
| 时间戳 | 时间戳一般指的UNIX时间,或类UNIX系统(比如Linux、macOS等)使用的时间表示方式。定义为:从UTC时间的1970-1-1 0:0:0起到现在的总秒数(秒是毫秒、微妙、纳秒的总称),可简单理解为某个时刻 |
问题
一般MySQL Server 实例都会设置 time_zone 为 system,方便实例部署在不同的国家、时区也都能很好兼容,这是很合理的设置。
如果我们的 SQL 中有一个列类型是 timestamp 的话,意味着:
timestamp 数据类型会存储当时 session的时区信息,读取时会根据当前 session 的时区进行转换;而 datetime 数据类型插入的是什么值,再读取就是什么值,不受时区影响。也可以理解为已经存储的数据是不会变的,只是 timestamp 类型数据在读取时会根据时区转换
如果MySQL 读取 timestamp 字段时,需要做时区转换,当 time_zone 设置为 system 时,意味着MySQL 要去follow OS系统时区,也就是把读到的timestamp 根据OS系统时区进行转换,这个转换调用OS 的glibc 的时区函数来获取 Linux OS 的时区,在这个函数中会加 mutex 锁,当并发高时,会出现 mutex 竞争激烈,每次只有一个线程获得锁,释放锁时会唤醒所有等锁线程,但最终只有一个能获取,于是一下子导致系统 sys飙高、上下文切换飙高。每读取一行带 timestamp 字段时,都会通过这个 glibc 的时区函数导致锁竞争特别激烈最终 QPS 拉胯厉害。
想一想,你一个SQL查1万行,10个并发这点流量其实一点都不过分,但是这里需要10*1万次转换,锁争抢就激烈了。
分析参考这个: https://opensource.actionsky.com/20191112-mysql/
perf 以及火焰图如下:
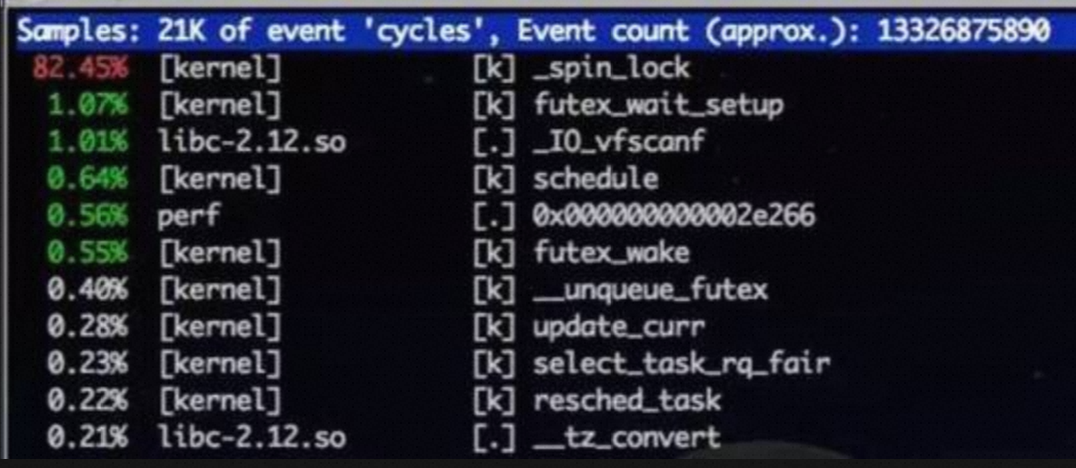
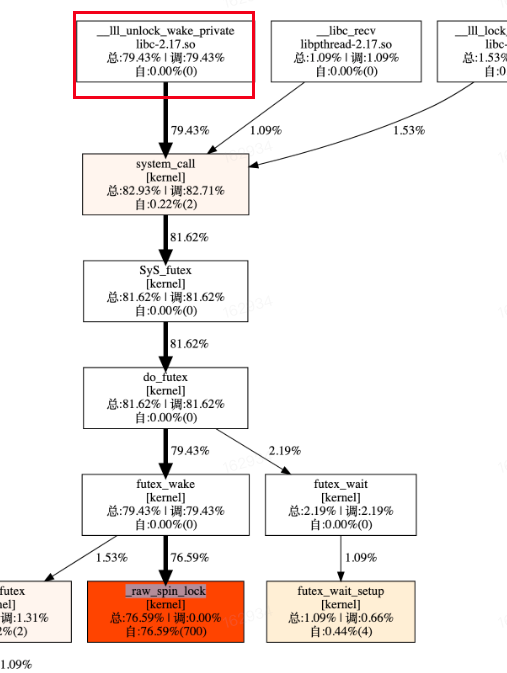

解决
在中国可以将 time_zone=’+8:00’ 将 time_zone 固定死,不再需要follow OS 时区,所以也不需要调用glibc 获取系统时区,避免了前面所说的锁竞争
这个经验来自无数次线上故障复盘,因为 time_zone 设置为 system 是个默认行为,所以要全部改过来还真不容易,给了我们就业机会 :)
当然学习总是希望交叉起来,既有深度又有宽度你才能掌握更好,所以请趁热打铁:
进一步学习
东八区CST 被JDBC 驱动错误识别成了美国的中央时间,官方修复: 8.0.23 改了 CST 解析行为(不再依赖 server 字符串),但完全规避时区坑还是要靠显式 serverTimezone=Asia/Shanghai 或服务端 time_zone=’+08:00’,不能光靠升驱动。
实验
在我们 99块钱的 ECS 启动一个MySQL 的Docker 容器(配置简单,换MySQL版本对比也方便)
1 | docker run --name mysql --network host -v /plantegg/test/my.cnf:/etc/my.cnf -e MYSQL_ROOT_PASSWORD=123 -d mysql --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci |
my.cnf配置文件
1 | # cat /plantegg/test/my.cnf |
先创建一个Database ren,然后在里面再创建一个表t,如下:
1 | CREATE DATABASE `ren` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ |
插入一条数据:
1 | insert into t values('2021-12-02 16:45:39','2021-12-02 16:45:39'); |
现在我们基本得到了一个100万行的测试表,接下来就要实验验证,同时开30个并发来查 ts列(timestamp, 要做时区转换) VS 查 dt 列(不需要做时区转换),对比他们的效率:
1 | for i in {1..30}; do (time mysql -h127.0.0.1 -P3306 -uroot -p123 ren -e " select ts from t " >>tmp ) & done |
可以清楚地看到 查ts 需要20秒左右,查 dt 需要4秒左右,差了5倍,结合我们前面的理论讲解,肯定可以想到这是在做时区转换有额外的开销,其实这还好只是开销大了几倍,有没有一种可能因为glibc 加锁导致整个系统雪崩了?大家可以试试能否搞出雪崩的场景来
Perf 安装和使用命令:
1 | yum install perf -y |
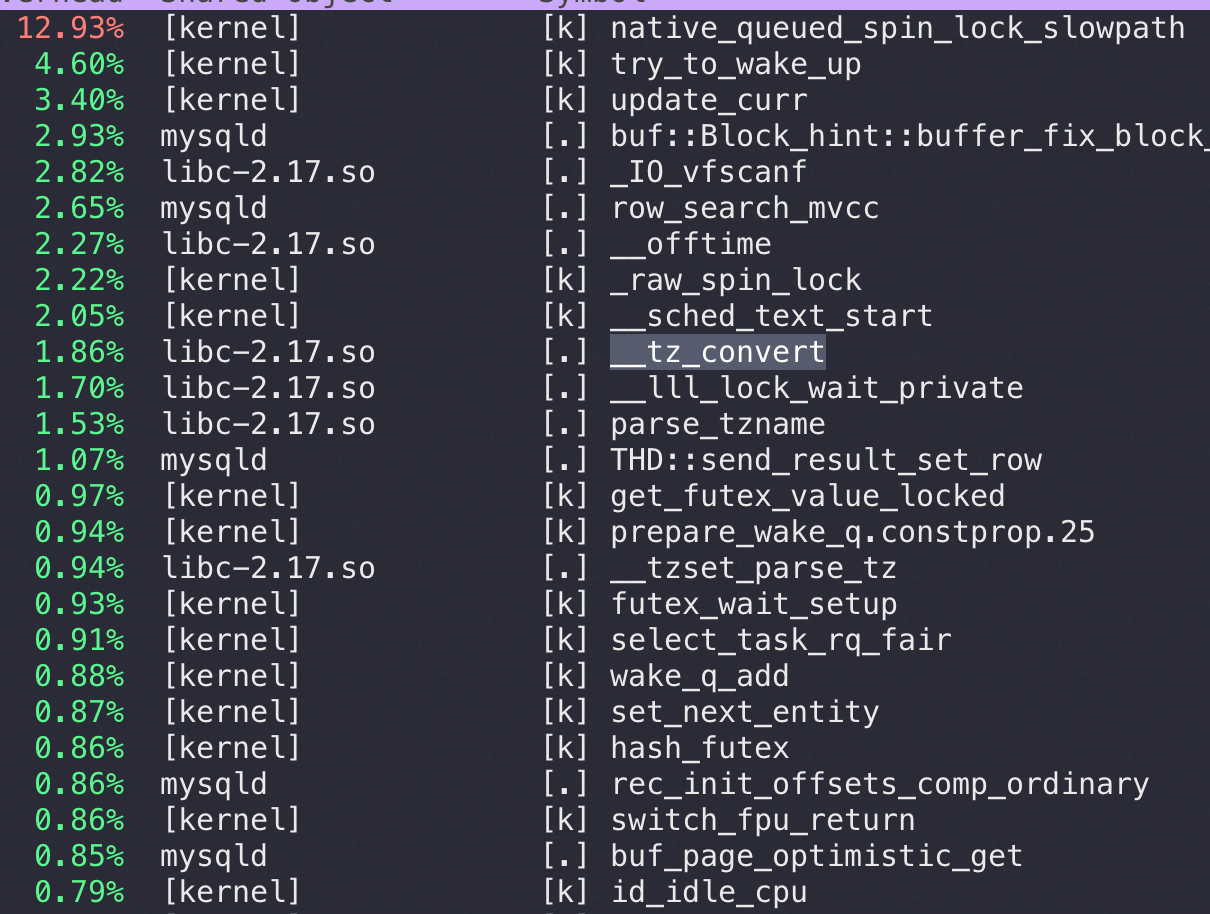
比如用 perf top 可以看到查 timestamp 才有如下图前两行的 futex_wait_setup/libc-2.28 的wcscoll_l , 对比一下查 datetime 是完全看不到这些内核、libc的消耗的:
64 核机器 CPU 使用率(CPU 核数越多反而性能越差)
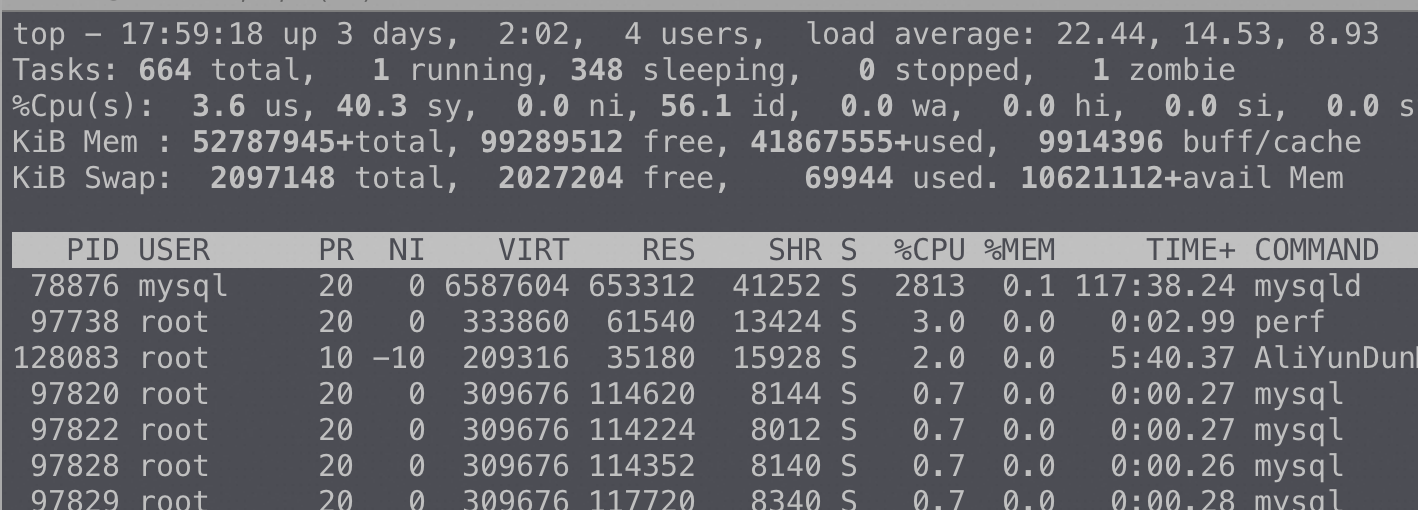
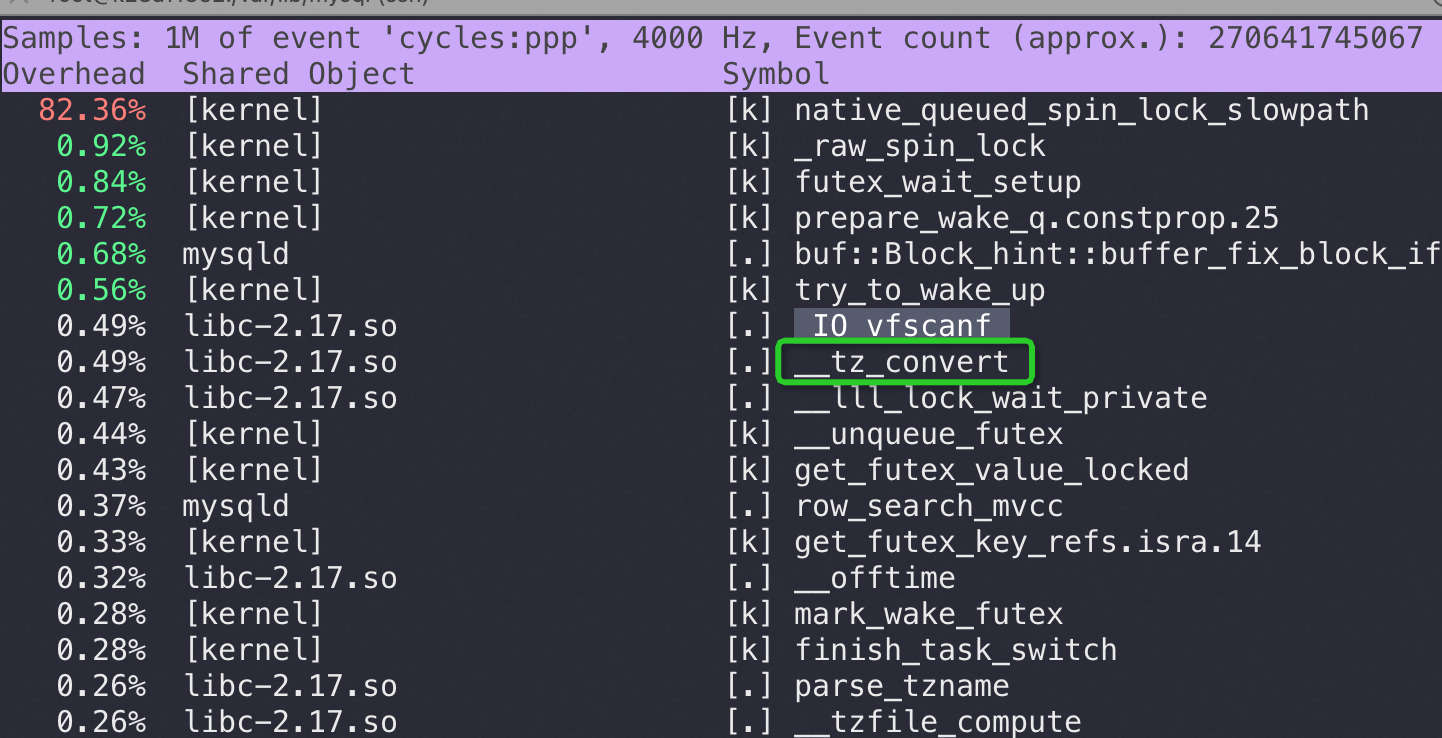
如果只给 MySQLD 4 核反而跑得更快了,明显在锁上的 CPU 消耗降低了很多:
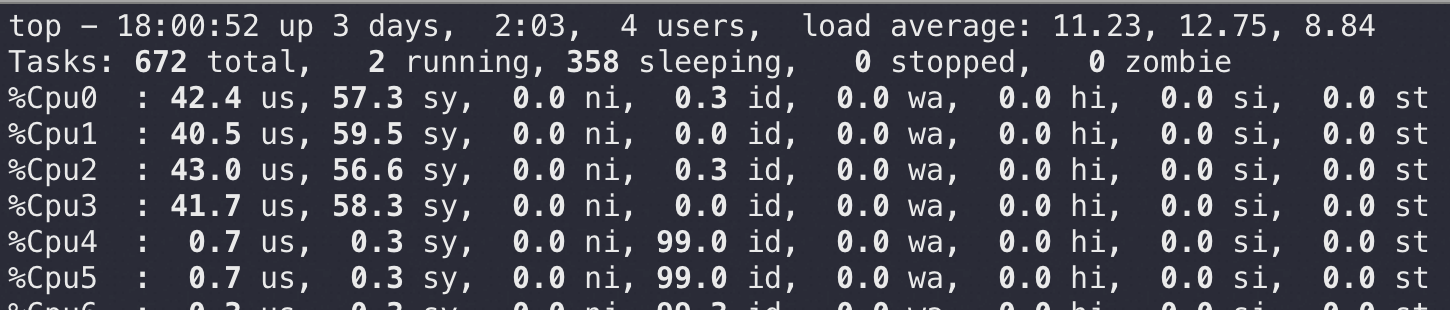
停下来花点时间来分析他们的性能差异,多结合理论表述这篇,另外反过来想想如果你不知道这个原因,但是你看到这个现象(timestamp 和 datetime 性能差5倍的时候),你怎么来分析是为什么?
96核环境下对比
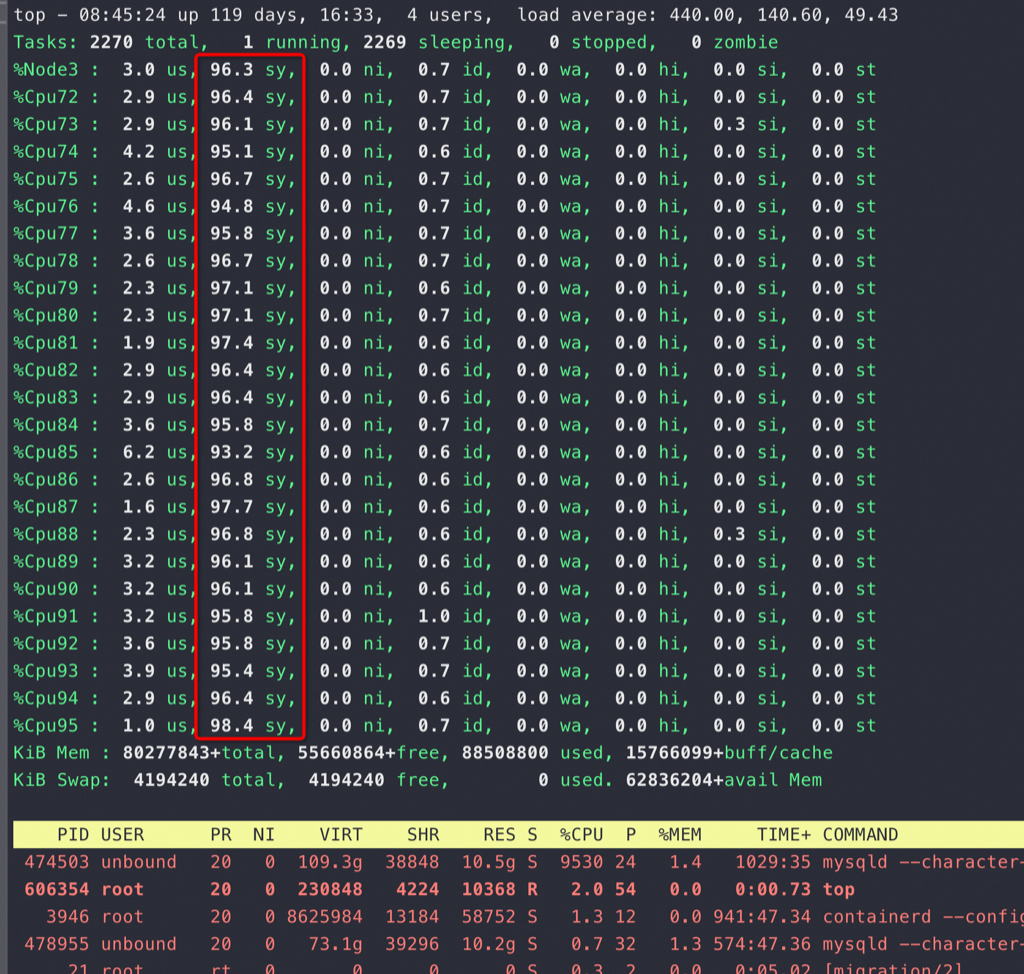
找个核数多的机器做同样的测试,比如以下数据是在96核机器上完成,让锁竞争更激烈,实际是把问题更加明显化
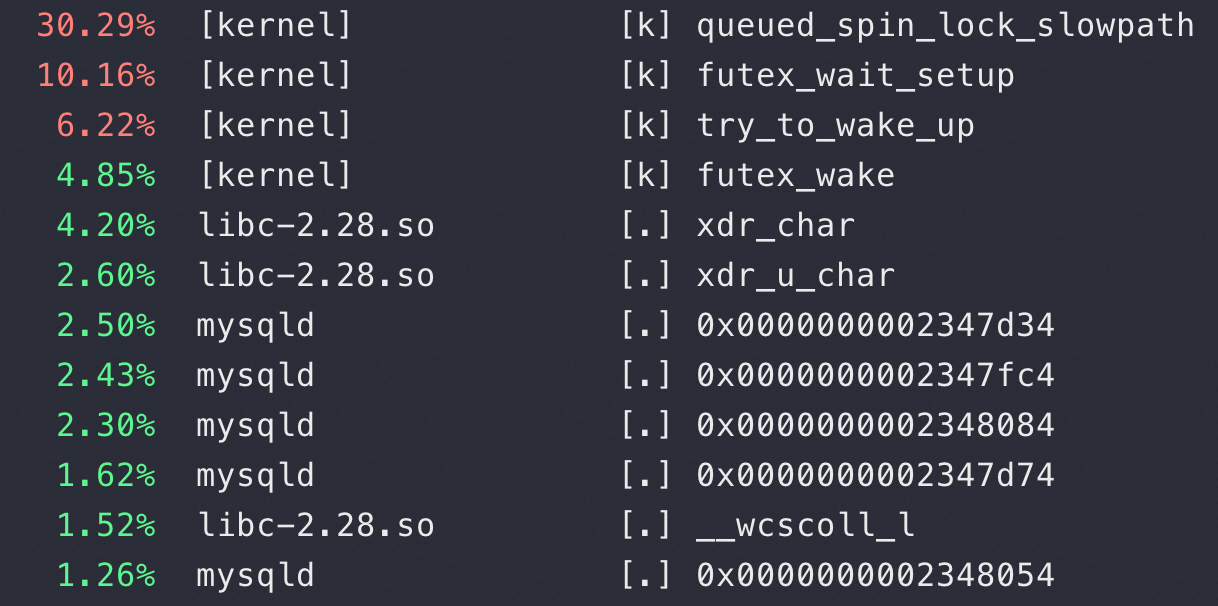
从 top 也可以看到CPU 都花在了sys(内核态系统调用)上,这明显是不符合逻辑的。同时也可以看到96个核基本都跑满,整个MySQLD 进程的CPU 消耗接近 9600%,又回到了我们常说的CPU 有使用没有效率,不过站在CPU的角度是有效率的,这个效率都是在做锁相关的事情,但是站在业务角度是没有效率的:
在这么明显的不正常情况下可以进一步通过 perf record 来采集调用关系,通过调用关系来回溯是哪个函数导致的锁争抢从而找到问题
从这里也可以看到这个问题在不同核数下表现完全不一样,如果只是一个核很少的实例那么看起来问题还没那么明显,只是慢了,但是到了96核下这个SQL 反而全崩了,这个SQL 完全查不出结果(CPU 都在sy 上干抢锁的内耗上,能查出才怪),核数越多这个问题就越严重,也即内耗越严重,如果有业务流量源源不断地进来就类似雪崩了:
1 | # mysql -h127.0.0.1 -P3306 -uroot -p123 ren -e "show processlist" |
代码分析
从下图可以看到 70% 的 CPU 时间消耗在 Time_zone_system::gmt_sec_to_TIME() 方法的调用上,就是以下这一段的代码。
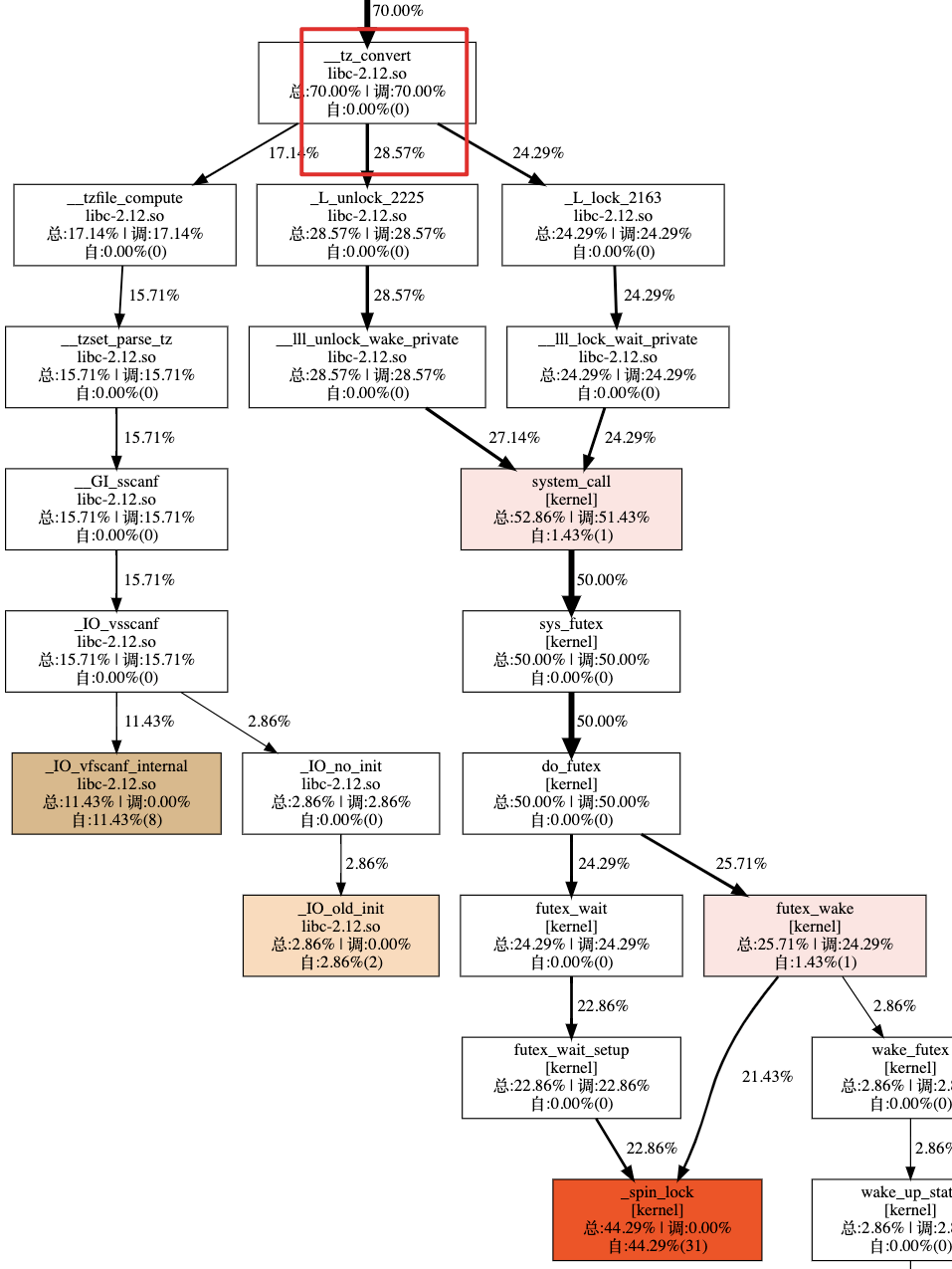
对应代码:
1 | void Time_zone_system::gmt_sec_to_TIME(MYSQL_TIME *tmp, my_time_t t) const { |
代码最终会使用 atomic_compare_and_exchange_val_24_acq() 尝试对 futex 加锁。
而 futex 作为多个 thread 间共享的一块内存区域在多个 client thread(多个会话/查询)竞争的场景下会引发系统调用而进入系统态,导致 SYS 系统态 CPU 使用率上升。
并且该临界区保护的锁机制限制了时区转换方法 __tz_convert() 的并发度,进而出现多个会话/查询 等待获取锁进入临界区的情况,当冲突争抢激烈的场景下引发卡顿
进一步验证
这几个算是你可以接着做的一些小任务
- 将 time_zone 从system 改成 ‘+08:00’ 再查 timestamp 列看看是不是就不存在这个问题了,反复改来改去稳定确认
- 换MySQL 5.6/5.7试试这个问题,默认用的MySQL 8.0
- 换低版本的OS 内核试试这个问题,我测试用的5.10,你可以试试3.10
- 构造雪崩,也就是随着并发、行数的加大系统陷入抢锁等锁,基本无法响应业务查询了
- 在这个基础上,各种折腾、折腾,会折腾就是能力
总结
借着 MySQL 的时区转换我们把这个问题重现了,让我们通过实际测试来验证这个差异,下次我相信你会对这个问题印象深刻的
当然我们做这个实验不是为了证明这个问题,这个知识点本身价值不是特别大,而是希望你能学到:
- 设计实验,根据你的目的设计实验
- 根据实验重现的现象反过去分析为什么——虽然你知道原因,但是如果不知道你会怎么思考
- 尝试分析问题的手段、技巧,比如 perf、比如for 循环
希望能看到你们更多的不同实验现象和分析