历时5年的net_write_timeout 报错分析
历时5年的net_write_timeout 报错分析
全网关于 JDBC 报错:net_write_timeout 的最好/最全总结
前言
上一次为了讲如何分析几百万个抓包,所以把这个问题中的一部分简化写了这篇抓包篇:https://articles.zsxq.com/id_lznw3w4zieuc.html 建议你先去看看把场景简化下,然后本篇中的分析涉及抓包部分就不再啰嗦讲解,请看抓包篇
问题描述
用户为了做数据分析需要把160个DB中的数据迁移到另外一个只读库中,有专门的迁移工具,但是这个迁移工具跑一阵后总是报错,报错堆栈显示是Tomcat 到DB之间的连接出了异常:
1 | Caused by: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Application was streaming results when the connection failed. Consider raising value of 'net_write_timeout' on the server. |
这个异常堆栈告诉我们Tomcat 到Database之间的连接异常了,似乎是 net_write_timeout 超时导致的
对应业务结构:

net_write_timeout 原理简介
先看下 net_write_timeout的解释:
The number of seconds to wait for a block to be written to a connection before aborting the write. 只针对执行查询中的等待超时,网络不好,tcp buffer满了(应用迟迟不读走数据)等容易导致mysql server端报net_write_timeout错误,指的是mysql server hang在那里长时间无法发送查询结果。
报这个错就是DB 等了net_write_timeout这么久没写数据,可能是Tomcat 端卡死没有读走数据。
但是根据我多年来和这个报错打交道的经验告诉我:这个报错不只是因为net_write_timeout 超时导致的,任何Tomcat 到 DB间的连接断开了,都报这个错误,原因是JDBC 驱动搞不清楚断开的具体原因,统统当 net_write_timeout 了
一定要记住这个原理。如果这里不理解可以进一步阅读:https://wx.zsxq.com/dweb2/index/topic_detail/412251415855228
分析
首先把Tomcat 集群从负载均衡上摘一个下来,这样没有业务流量干扰更利于测试和分析日志
然后让迁移数据工具直接连这个没有流量的节点,问题仍然稳定重现。
进一步提取迁移工具的SQL,然后走API手工提交给Tomcat 执行,问题仍然稳定重现,现在重现越来越简单了,效率高多了。
Tomcat 上抓包
因为没有业务流量干扰,抓包很干净,但是因为DB 节点太多,所以量还是很大的,分析如抓包篇:https://articles.zsxq.com/id_lznw3w4zieuc.html
如下图红框所示的地方可以看到MySQL Server 传着传着居然带了个 fin 包在里面,表示MySQL Server要断开连接了,无奈Client只能也发送quit 断开连接。红框告诉我们一个无比有力的证据MySQL Server 在不应该断开的地方断开了连接,问题在 MySQL Server 端

看起来是Database 主动端开了连接,因为这个过程Tomcat 不需要发任何东西给 Database。这个现象5年前在其它用户场景下就抓到过了,最后问题也不了了之,这次希望搞清楚
Database 分析
打开 DB 日志,捞取全量日志可以看到 DB 断开的原因是收到了kill Query!
有这个结果记住上面抓包图,以后类似这样莫名起来 DB 主动断开大概率就是 kill Query 导致的(经验攒得不容易!)
Database 抓包
确实能抓到kill,而且从用户账号来看就是从 Tomcat 发过去的!
继续分析Tomcat 抓包
从 DB 分析来看还是有人主动 kill 导致的,所以继续分析Tomcat的抓包看是不是因为代码bug导致Tomcat 发了kill 给DB
大海捞针,搜 kill,找Tomcat 发给DB的tcp length 长度是16-20的(刚好容纳kill id) 总的来说就是找不到,很神奇
由于 DB上记录的 Tomcat IP、port 都被中间链路转换过几次了,根本没办法一一对应搞清楚是哪个Tomcat 节点发出来的
继续尝试重现
分析完Tomcat 业务代码后感觉业务不会去kill,于是灵机一动在没有流量的Tomcat上跑了一个Sleep 600秒,不用任何数据,神奇的问题也稳定重现了,这下大概知道什么原因了,肯定是客户自己加了慢查询监控逻辑,一旦发现慢查询就 kill
于是问客户是不是有这种监控,果然有,停掉后反复重试不再有问题!
测试环境手工触发kill,然后能抓到下发的kill Query 给Database

未解谜题
为什么没在Tomcat 抓到发给Database的 kill ?
我反复去重现了,如果是我手工触发Tomcat kill是可以清晰地抓到Tomcat 会发160个kill 给Database,但是我任其自然等待用户监控来杀就一定抓不到kill 下发给DB
我猜和 Tomcat 集群有关,首先用户监控是走的LVS,通过其中一个Tomcat 可以查询到所有 Tomcat 上的请求,然后发起 kill
但因为节点太多无法证实!当然业务监控也可以监控DB 然后直接发kill,但是和抓包看到的发起kill的用户不对,发起 kill 的用户是Tomcat独一无二的。
JDBC驱动报错 net_write_timeout 结论
Application was streaming results when the connection failed. Consider raising value of ‘net_write_timeout’ on the server. - com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Application was streaming results when the connection failed. Consider raising value of ‘net_write_timeout’ on the server.
这个报错不一定是 net_write_timeout 设置过小导致的,JDBC 在 streaming 流模式下只要连接异常就会报如上错误,比如:
- 连接被 TCP reset
- RDS 前端自带的Proxy 主动断开连接
- 连接因为某种原因(比如 QueryTimeOut) 触发 kill Query导致连接中断
- RDS 端因为kill 主动断开连接 //比如用户监控RDS、DRDS脚本杀掉慢查询
net_write_timeout:表示这么长时间RDS/DN 无法写数据到网络层发给DRDS/CN,原因是DRDS/CN 长时间没将数据读走
总结
首先一个错误现象对应多个完全不一样的错误原因是非常头疼的,这个问题反反复复在多个场景下出现,当然原因各异,但是这个传数据途中 DB 主动 fin连接还是第一次碰到并搞清楚,同样主动 fin 不一定是kill,但是我们要依照证据推进问题,既然是DB fin就有必要先从DB 来看原因。
从这个问题你可以先从什么是JDBC 流模式出发(mysql –quick 就是流模式,你可以快速查一个大数据试试;然后去掉–quick 对比一下),结合网络buffer 来了解流模式:https://plantegg.github.io/2020/07/03/MySQL%20JDBC%20StreamResult%20%E5%92%8C%20net_write_timeout/
然后从流模式来学习MySQL 的 net_write_timeout,假如你的代码报了 net_write_timeout 你会分析吗?
最后从连接断开去总结,比如网络不好、比如内核bug、比如DB crash、比如 kill、比如……都会导致连接断开,但这一切对业务来说只有 net_write_timeout 一个现象
这个问题分享出来是因为非常综合,我惊抱怨 socketTimeout、Communication failure等异常,这些异常也挺常见导致的原因多种,但是和 net_write_timeout 比起来还是不如 net_write_timeout 更综合,所以分享给大家,建议这几篇一起阅读效果最好!
实验模拟 Consider raising value of ‘net_write_timeout’
使用 Java MySQL JDBC Driver 的同学经常碰到如下错误堆栈,到底这个错误是 net_write_timeout 设置太小还是别的原因也会导致这个问题?需要我们用实验验证一下:
1 | com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Application was streaming results when the connection failed. Consider raising value of 'net_write_timeout' on the server. |
JDBC 驱动对这个错误有如下提示(坑人):
Application was streaming results when the connection failed. Consider raising value of ‘net_write_timeout’ on the server. - com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Application was streaming results when the connection failed. Consider raising value of ‘net_write_timeout’ on the server.
实验中的一些说明:
- netTimeoutForStreamingResults=1 表示设置 net_write_timeout 为 1 秒,客户端会发送 set net_write_timeout=1 给数据库
- conn.setAutoCommit(false); //流式读取必须要 关闭自动提交
- stmt.setFetchSize(Integer.MIN_VALUE);
以上 2/3是触发流式读取的必要条件,第一条不设置默认是 600 秒,比较难等 :)
如果确实是 net_write_timeout 太小超时了, RDS 直接发 fin(但是 fin 前面还有一堆 response 包也在排队),然后 RDS 日志先报错:
1 | 2024-11-28T14:33:03.447397Z 12 [Note] Aborted connection 12 to db: 'test' user: 'root' host: '172.26.137.130' (Got timeout writing communication packets) |
此时客户端还慢悠悠地读,RDS 没有回任何错误信息给客户端,客户端读完所有 Response 然后直接读到连接断开就报 Consider raising value of ‘net_write_timeout’ on the server 了,如果客户端读的慢,比如要 10 分钟实际连接在 RDS 上 10 分钟前就进入 fin 了,但是 10 分钟后客户端才报错
1 | #netstat -anto | grep "3307" |
重现代码,数据库上构造一个大表,比如 10万行就行,能堆满默认的 tcp buffer size:
1 | import java.sql.Connection; |
Consider raising value of ‘net_write_timeout’ 这个报错数据库端不会返回任何错误码给客户端,只是发 fin 断开连接,对客户端来说这条连接是 net_write_timeout 超时了 还是 被kill(或者其他原因) 是没法区分的,所以不管什么原因,只要连接异常 MySQL JDBC Driver 就抛 net_write_timeout 错误
如图,3 秒钟后 fin 包混在数据库 response 就被发到了客户端,实际2 秒前数据库已经报错了,也就是客户端和数据库端报错时间会差 2 秒(具体差几秒取决于重现代码里 sleep 多久然后-1)
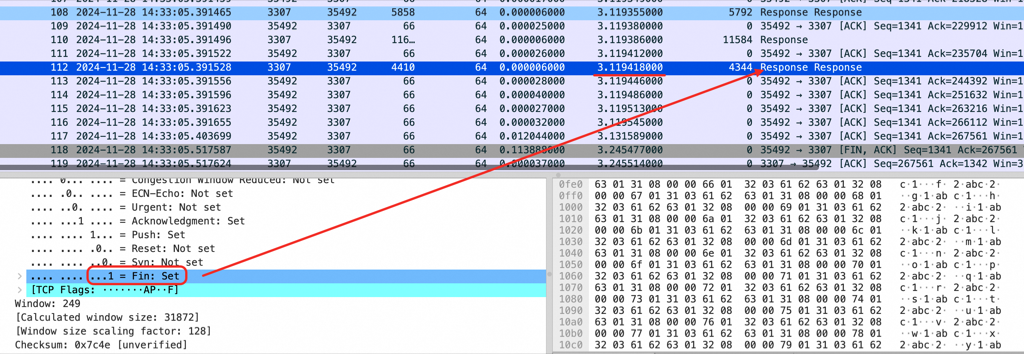
实验总结
这个报错不一定是 net_write_timeout 设置过小导致的,JDBC 在 streaming 流模式下只要连接异常就会报如上错误,比如:
- 连接被 TCP reset
- RDS 前端自带的Proxy 主动断开连接
- 连接因为某种原因(比如 QueryTimeOut) 触发 kill Query导致连接中断
- RDS 端因为kill 主动断开连接 //比如用户监控RDS 脚本杀掉慢查询
- 开启流式读取后,只要客户端在读取查询结果没有结束就读到了 fin 包就会报这个错误
可以将 netTimeoutForStreamingResults 设为 0 或者 100,然后在中途 kill 掉 MySQL 上的 SQL,你也会在客户端看到同样的错误, kill SQL 是在 MySQL 的报错日志中都是同样的:
1 | 2024-11-28T07:33:12.967012Z 23 [Note] Aborted connection 23 to db: 'test' user: 'root' host: '172.26.137.130' (Got an error writing communication packets) |
所以你看一旦客户端出现这个异常堆栈,除了抓包似乎没什么好办法,其实抓包也只能抓到数据库主动发了 fin 什么原因还是不知道,我恨这个没有错误码一统江湖的报错
net_write_timeout 后 RDS 直接发 fin(有时 fin 前面还有一堆 response 包也在排队),然后 rds 日志先报错:2024-11-28T06:33:03.447397Z 12 [Note] Aborted connection 12 to db: ‘test’ user: ‘root’ host: ‘172.26.137.130’ (Got timeout writing communication packets)
客户端慢悠悠地读,RDS 没有传任何错误信息给客户端,客户端读完所有 response 然后直接读到连接断开就报 Consider raising value of ‘net_write_timeout’ on the server 了,如果客户端读的慢,比如要 10 分钟实际连接在 RDS 上 10 分钟前就进入 fin 了,但是 10 分钟后客户端才报错
进阶阅读:https://plantegg.github.io/2024/09/25/%E4%B8%80%E4%B8%AA%E5%8E%86%E6%97%B65%E5%B9%B4%E7%9A%84%E9%97%AE%E9%A2%98%E5%88%86%E6%9E%90/ 和 https://x.com/plantegg/status/1867535551337050153