为什么你的连接不均衡了?
为什么你的连接不均衡了?
场景
假如你有两个Redis 服务,挂载在一个LVS 下,然后客户端使用的Jedis,Jedis 配置的最大连接池是200个连接,最小是100个(也就是超过100个,当闲置一段时间后就释放掉)。然后过一阵假设来了一个访问高峰,把连接数打到200,过一会高峰过去连接就会释放到100,客户端每次取连接然后随便 get 以下就归还连接
场景构造小提示:
- 用Jedis;
- 构造流量一波一波,就是有流量高峰(触发新建连接)、有流量低峰(触发连接释放),如此反复
- 不需要太大流量把Redis 节点打到出现瓶颈
如下图:
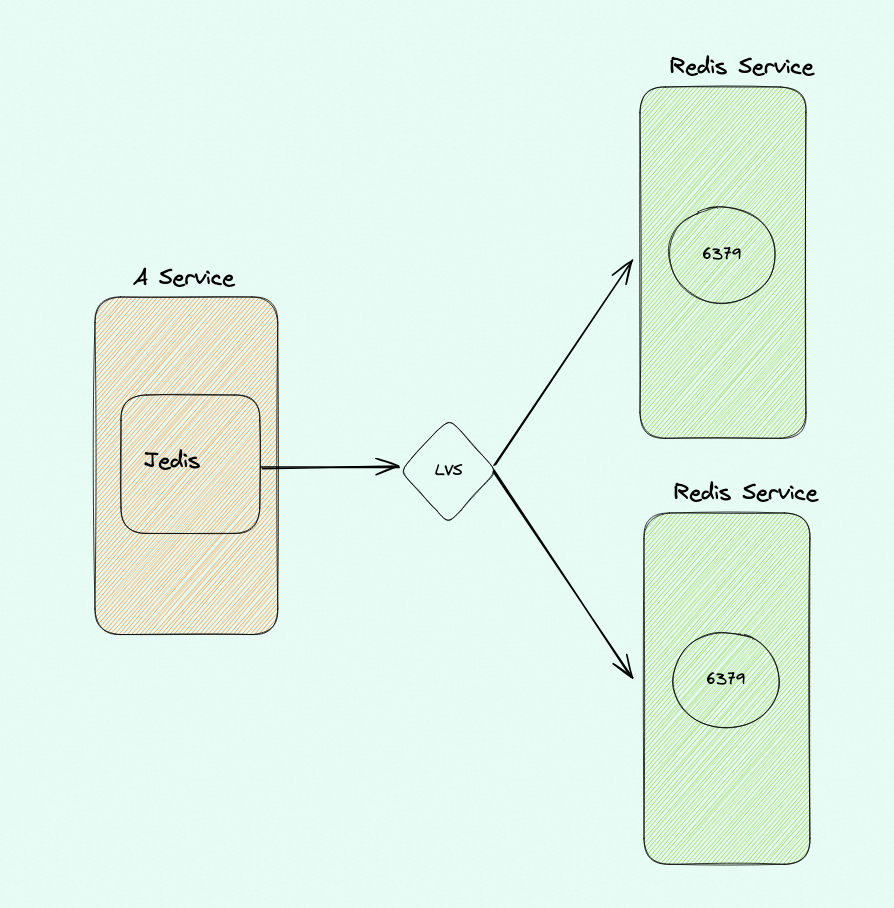
期待场景:在这个过程中,Jedis 每次取一个连接随便get 一个key 就行了,无论怎么折腾两个Redis Service 的连接数基本是均衡的,实际也确实是这样
比如可以这样设置Jedis 参数(你也可以随便改),也可以用你们生产环境
1 | JedisPoolConfig config = new JedisPoolConfig(); |
验证代码
1 | import com.taobao.eagleeye.redis.clients.jedis.Jedis; |
运行如上代码,应该看到一个负载均衡正常环境——符合预期
不均衡重现
背景里描述的是完全符合预期的,假设实际使用中两个 Redis中的一个节点的CPU有一个降频了/争抢/温度高 等种种原因,导致这个节点处理更慢了
如何模拟其中一个节点突然慢了(这些手段在之前的星球案例重现里都反复使用过了)
- 你可以把Redis 进程绑到一个核上,然后在这这个核上跑一个死循环故意让;
- 或者,也可以在这个节点上给网络延迟加200ms 进去
这个时候你再重新跑背景描述里的代码,一段时间后你会看到下图中红线对应的 Redis 节点上的连接数越来越高,QPS 越来越高(别用太大的压力,导致这个节点的访问超时哈)
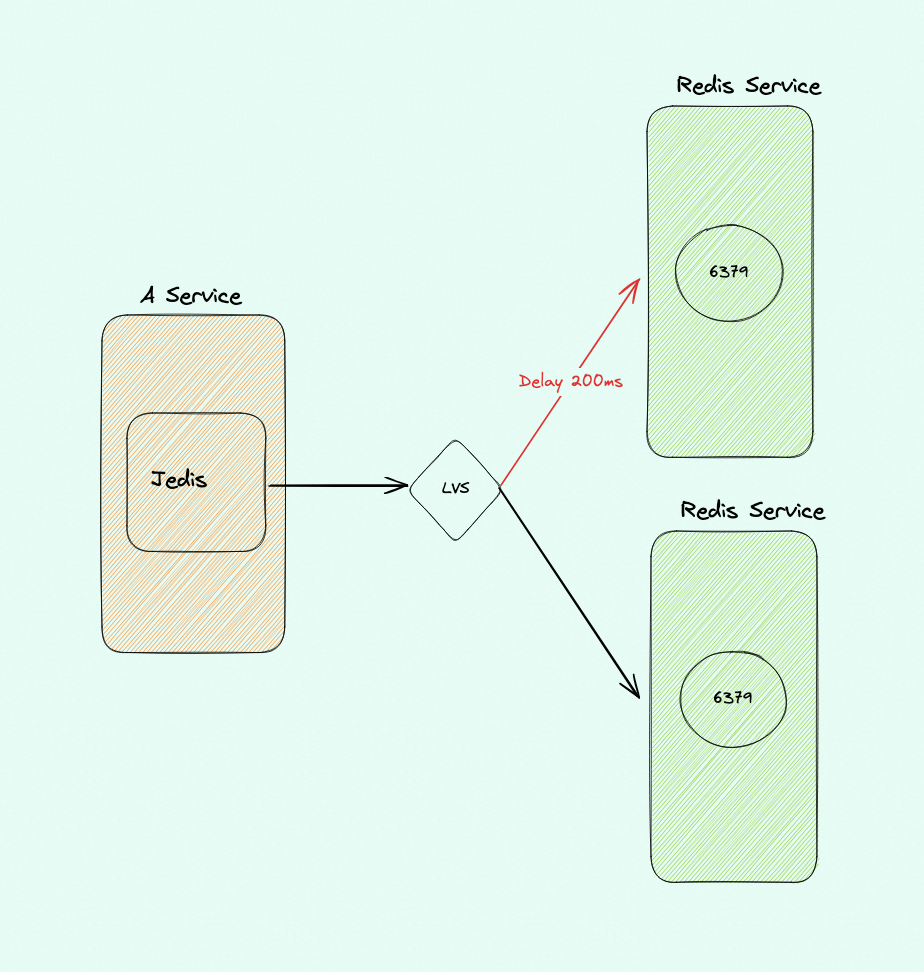
到这里就算是问题重现出来了
重现确认注意:
如果只是看到瞬间连接数不均衡这应该没有重现出来,因为节点慢了所以 active 要变高才会维系住同样的QPS,这是符合预期的。
期望的是长期运行后慢的节点上统计意义上的连接数越来越多、QPS 越来越大
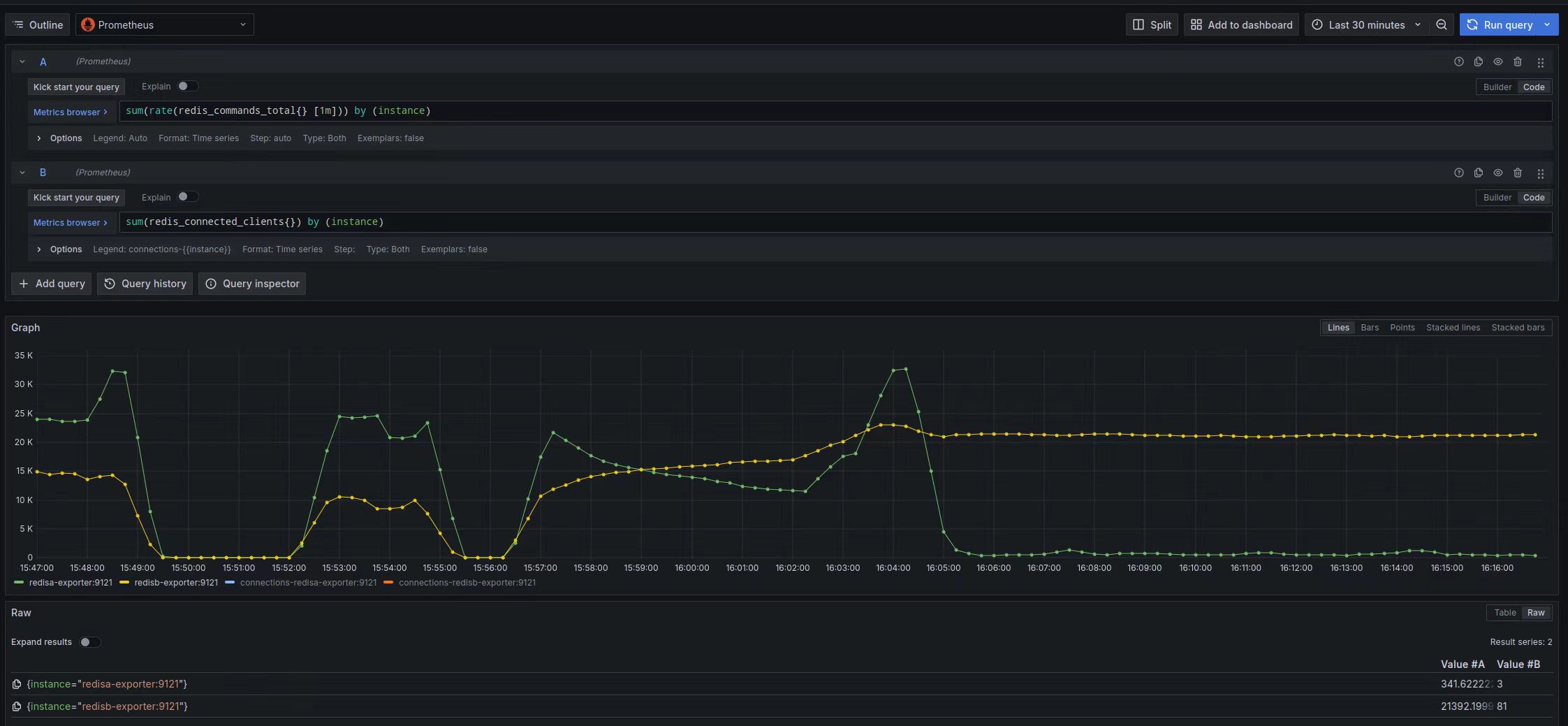
比如下图是重现过程中的连接数监控,可以看到橙色线对应的Redis 节点上的连接越来越多:

下图是对应的QPS 监控,问题Redis 节点(黄色线)的QPS 比另外一个节点大很多,长期下去会导致问题节点成为瓶颈:
重现脚本和代码
以下涉及的脚本、代码提交到 github,这些脚本、手段在我们之前的实验、案例都反复出现过了,我就不给了
参考星球里扒老师的操作(不含客户端Java代码):https://malleable-elbow-b9f.notion.site/redis-f7dfcecb7f7441e1ba96f4da3ca8aee8?pvs=4
星球里橘橘球用python 3.8 实现了一个python 版本的:https://github.com/gongyisheng/playground/blob/dev/network/lvs_case/readme.md
好奇同学用Java/Jedis 和Go两个版本(Go 版本是没有Jedis,也能重现问题)的实现代码:https://github.com/haoqixu/case-reproduction-240618
docker
用 docker起两个Redis 节点
1 | //这里提供Redis docker run脚本 |
ipvsadm
1 | //创建一个 LVS,将上面的两个Redis 加入到负载均衡里面 |
Java 客户端代码
完整代码应该很简单,就是一个Java + Jedis 的HelloWorld 上传到 github,别人下载代码后,自己配置一个 LVS + Redis 的负载均衡环境就能重现以上问题
tc qdisc
1 | //给其中的一个 节点构造 200ms 的延时 |
也可以跑死循环抢 CPU
分析
原因:Jedis 连接池使用的是 apache commons-pool 这个组件,默认从连接池取连接使用的是 LIFO(last in first out) ,如果两个节点负载正常两个节点上的连接基本能保持在队列里交叉均衡;如果连接闲置久了释放的时候就是均衡释放的
但如果有一个节点处理慢了,那么这个节点的连接被取出来使用的时候必然需要更多的时间在连接池外面处理请求,用完归还的时候就会更高概率出现在队列的顶部,导致下次首先被取出来使用,长期下去就会出现快的节点上的连接慢慢被释放,慢的节点的连接越来越多,进而慢的节点的QPS 越来越高,最后这个节点崩了
泛化问题
针对这个问题就一定是Jedis 和 Redis 才有吗?本质是我们没法期望所有节点一样快,导致连接归还一定有慢的,进而只要是取连接用 LIFO(last in first out) 就会有这个问题,Jedis/Lettuce/MySQL dbcp 都用了 apache commons-pool 这个组件来实现连接池功能,而 apache commons-pool 默认就是 LIFO ,所以这些组件全部中枪。应该是用的 LinkedBlockingDeque 队列,它有有 FIFO 和 FILO 两种策略
那么没有用 apache-commons-pools 的就安全吗?也不一定,得看取连接的逻辑,一般都是 LIFO,比如 Druid 连接池的实现用的 stack ,也就是 stack 顶部的几个连接被反复使用,可能底部连接完全用不到的情况。 且Druid 还不提供接口去设置是不是 stack/queue(LIFO/FIFO)
你们的微服务只要是用连接池大概率也会有同样的问题
那么有什么好办法来解决类似的问题吗?Druid 有个设置 phyTimeoutMillis 和 phyMaxUseCount (就是一个长连接用多久、或者执行了多少次SQL ) 来将长连接主动断开,这就有概率修复这个问题;
另外如果LVS 用的 WLC 均衡算法也可以fix 这个问题,见参考资料。
php听说有个功能,进程跑一段时间后自行销毁重建;担心内存泄漏啥的 —— 是不是很像遇到问题就重启,又不是不work,不优雅但是管用,有点像通信基站半夜重启
内核 epoll 的线程也是 FILO
参考:Why does one NGINX worker take all the load? (链接里提供完整的最简测试重现代码)
唤醒时容易最是唤醒最后几个线程(一般一个线程对应一个核),在并发压力不大时某几个线程总是被唤醒->归还->唤醒(再次取出分配执行任务)
epoll的accept模型为LIFO,倾向于唤醒最活跃的进程。多进程场景下:默认的accept是FIFO,进程加入到监听socket等待队列的尾部,唤醒时从头部开始唤醒;epoll的accept是LIFO,在epoll_wait时把进程加入到监听socket等待队列的头部,唤醒时从头部开始唤醒。
影响:当并发数较小时,只有最后几个进程会被唤醒,它们使用的CPU时间会远高于其它进程。当并发数较大时,所有的进程都有机会被唤醒,各个进程之间的差距不大。内核社区中关于epoll accept是使用LIFO还是RR有过讨论,在4.9内核和最新版本中使用的都是LIFO。
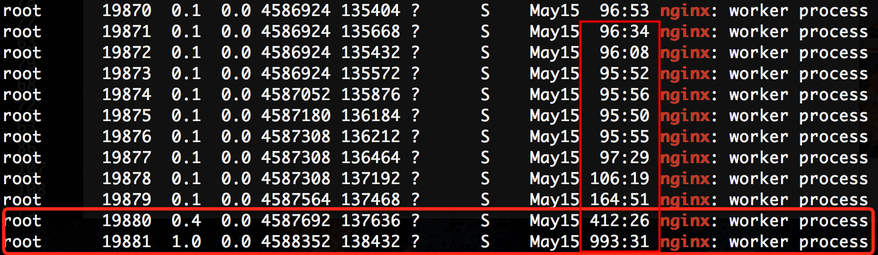
你看虽然是一次 Jedis 客户端在某些条件下导致的问题,只要你去通用化问题的本质就可以发现很容易地跳出来看到各个不同场景下同样会引起的问题,无招胜有招啊
参考资料
https://plantegg.github.io/categories/LVS/ 强调下这次的不均衡和我这个链接里的两篇文章描述的毫无关系,只是接着这个机会可以重温一下导致不均衡的其它原因,做个汇总