为什么你的 SYN 包被丢 net.ipv4.tcp_tw_recycle
为什么你的 SYN 包被丢 net.ipv4.tcp_tw_recycle
本来这是我计划在知识星球里要写的连续剧,我打算好好多写几篇的(每篇都计划重现一个场景/坑点),后来没看到任何一个同学参与,这样的话写了你们看完也没有体感,所以我直接公布答案吧,还能节省点你们的时间,记住干货就好:不要开 net.ipv4.tcp_tw_recycle
作为全网最权威/最全面的 net.ipv4.tcp_tw_recycle 问题分析还是从知识星球分享出来,希望更多的人避免踩坑
答案
首先不通了是因为服务端开启了 net.ipv4.tcp_tw_recycle,需要判断握手包的时间得保持递增(T2 - T1 >1)
tcpping 一直是通的,因为服务端没有记录到 T1,T1 是每次 FIN 断开时记录,T2 是每个 SYN 包中携带。当 curl 然后断开时走了 FIN 服务端记录下 T1,下次 tcpping 就可以比较了,所以有一半概率不通,直到 1 分钟后 T1 一直没有跟新,超过 60 秒的 T1 失效,后面连接正常
为什么要有 net.ipv4.tcp_tw_recycle?
net.ipv4.tcp_tw_recycle 是一个 Linux 内核参数,用于控制 TCP 连接的 TIME_WAIT 状态的处理方式。这个参数的主要作用是加速 TIME_WAIT 套接字的回收。
参考:Coping with the TCP TIME-WAIT state on busy Linux servers
PAWS(Protection Against Wrapped Sequences)
TCP 包的 seq 是有限的(4字节 32bit),会在达到最大值后回绕到零,这种情况称为”seq回绕”,seq 回绕后怎么判断这个 seq 是重复的(丢弃) 还是可以接受的?
引入 PAWS 的目的是确保即使seq 回绕发生,也能正确地处理序列号,除了 seq 外额外在 TCP options 里面增加了 timestamp 来作为维护数据包的seq 正确的判断。时间戳随每个数据包发送,并且单调增加,因此即使序列号回绕,接收方也可以使用时间戳来确定数据包的真实顺序,这就是 PAWS
PAWS会检查syn 网络包的 timestamps ,来判断这个syn包的发送时间是否早于上一次同 ip/stream(3.10 是 per ip/4.10 是 per stream) 的 fin包,如果早就扔掉,这也是导致syn 握手失败的一个高发原因,尤其是在NAT场景下。原本 PAWS 是每个连接的维度,但同时开启tcp_timestamp和tcp_tw_recycle之后,PAWS就变成per host粒度了
1 | timestamp为TCP/IP协议栈提供了两个功能: |
不同 OS 内核版本因为 timestamp 生成不一样导致 PAWS 行为还不一样,通过参数来控制:net.ipv4.tcp_timestamps
服务端如何通过判断时间戳来丢包?
对同一个 src-ip 记录最后一次 FIN 包的时间戳为 T1,当这个 src-ip 有 SYN 包时取 SYN 包中的时间戳为 T2
如果 T2-T1 小于 1 就扔掉这个 SYN 包
一旦发生这种 SYN 包被丢弃,对应的监控指标(LINUX_MIB_PAWSPASSIVEREJECTED):
1 | //第二个指标包含第一个,passive connections rejected 了也一定会是 SYN dropped |
这个指标也很重要,我喜欢这种
服务端丢包条件更多细节
服务端设置 net.ipv4.tcp_tw_recycle 为 1 是必要条件,然后同时满足了这两个条件:
(u32)get_seconds() - tm->tcpm_ts_stamp < TCP_PAWS_MSL(=60):容易满足,几乎总是满足。对比的是本地时间。收到syn的本地时间相比上次收包记录的本地时间,小于60s(s32)(tm->tcpm_ts - req->ts_recent) > TCP_PAWS_WINDOW(=1):对比的是tcp时间戳,上次更新的tcp时间戳 - 这次syn的tcp时间戳,大于1(并且小于231)。也就是这次syn的tcp时间戳,如果小于上次记录到的时间戳(ms级),就会被丢掉。
这里tm和req对应什么?一个四元组,还是ip地址,还是其他?3.10对应的是ip地址(不同内核版本不一样)
上次记录的时间戳是什么?注意这里对比的都是tm时间,是在连接关闭相关阶段,通过tcp_remember_stamp或tcp_tw_remember_stamp函数记录的,具体情况比较多。
服务端将客户端的时间戳保存在哪里?
6u(2.6.32)代码:
由于inet_timewait_sock在连接进入tw状态会被释放掉,其中记录最近一次接收报文的timestamp信息会丢失;VJ 的思路,把此tcp stamp信息放入路由cache表的rtable中struct inet_peer中,rtable中只保srcIP,dstIP的PATH信息,没有端口号信息,也就是同src-dstIP(即使端口不同)的所有连接受同一个timestamp限制。
7u(3.10.0)代码:
3.5版本以后的内核版本不再使用rtable记录,tcp stamp信息改为存放在目标地址出接口net中存放的tcp_metrics_block,timestamp判断逻辑跟6u比增加了“如果之前有记录timestamp且在一个MSL内,而本次连接无timestamp时,请求被丢弃”的逻辑,这么修改的原因参见:
https://patchwork.ozlabs.org/patch/380021/
https://patchwork.ozlabs.org/patch/379163/
2017 年的这个讨论https://patchwork.ozlabs.org/project/netdev/patch/20170315203046.158791-1-soheil.kdev@gmail.com/ 要去掉这个全局存放,改成可以按客户端 port 来记录
客户端如何生成时间戳?
- 3.10 内核是按 客户端 ip 来生成 timestamp,也就是不管跟谁通信都是全局单调递增
- 4.19(4.12)是按 ip 对(per-destination timestamp**)**来生 timestamp ,也就是一对 ip 之间保证单调递增;
- 4.10之前是 per-client 生成递增 timestamp ,4.10 改成 per-connection 生成递增 timestamp(导致了兼容 net.ipv4.tcp_tw_recycle问题严重),4.11 改成 per-destination-host 生成递增 timestamp(downgrade to per-host timestamp offsets);4.12 去掉 net.ipv4.tcp_tw_recycle 参数永远解决问题
有哪些场景会触发 net.ipv4.tcp_tw_recycle 丢包
服务端的内核参数 net.ipv4.tcp_tw_recycle(4.12内核 中删除这个参数了) 和 net.ipv4.tcp_timestamps 的值都为 1时,服务器会检查每一个 SYN报文中的时间戳(Timestamp,跟同一ip下最近一次 FIN包时间对比),若 Timestamp 不是递增的关系,就扔掉这个SYN包(诊断:netstat -s | grep “ passive connections rejected because of time stamp”),常见触发时间戳非递增场景:
- 4.10 内核,一直必现大概率性丢包。4.11 改成了 per-destination host的算法 //内核改来改去也是坑点
- tcpping 这种时间戳按连接随机的,必现大概率持续丢包
- 同一个客户端通过直连或者 NAT 后两条链路到同一个服务端,客户端生成时间戳是 by dst ip,导致大概率持续丢包
- 经过NAT/LVS 后多个客户端被当成一个客户端,小概率偶尔出现——通过 tc qdisc 可以来构造丢包重现该场景
- 网路链路复杂/链路长容易导致包乱序,进而出发丢包,取决于网络会小概率出现
- 客户端修改 net.ipv4.tcp_timestamps
- 1->0,触发持续60秒大概率必现的丢包,60秒后恢复
- 0->1 持续大概率一直丢包60秒; 60秒过后如果网络延时略高且客户端并发大一直有上一次 FIN 时间戳大于后续SYN 会一直概率性丢包持续下去;如果停掉所有流量,重启客户端流量,恢复正常
- 2->1 丢包,情况同2
- 1->2 不触发丢包
其它 SYN 连不上的场景延伸阅读:程序员如何学习和构建网络知识体系
一些特殊场景
这些特殊场景很可怕,不知不觉会产生 T2 不大于 T1 的情况,导致连接异常
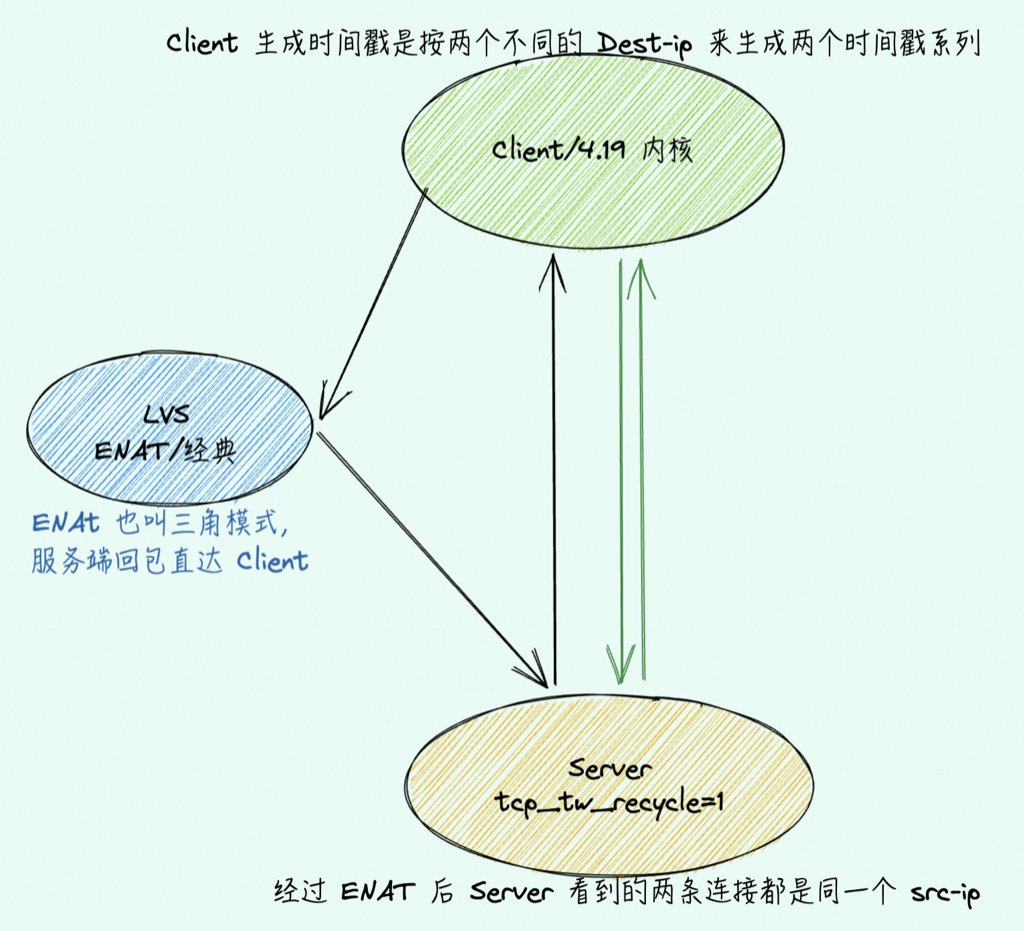
DNAT/ENAT
请求经过 DNAT 后 Server 端看到的 src-ip 是 client 的 IP,客户端同时通过直连(绿色)和走 LVS(黑色)两条链路就会大概率不通:
没有挥手断开场景
有些 HA 探测都是握手/select 1/ RESET 连接,不走 FIN 四次挥手(比如 Jedis,见小作业应用断开连接的时候如何让 OS 走 RST 流程:https://articles.zsxq.com/id_v0mhaadx3cx5.html ),Server 端没有机会记录 T1,也就永远不会触发丢包,看着一切正常,直到某天来了个用户 curl 一下系统就崩了
比如 Jedis 就是直接 RST 断开连接,从不走 FIN 四次挥手
延伸
如果服务端所用端口是 time_wait 状态,这时新连接 SYN 握手包刚好和 time_wait 的5元组重复,这个时候服务端不会回复 SYN+ACK 而是回复 time_wait 前的ack
其它
Server 在握手的第三阶段(TCP_NEW_SYN_RECV),等待对端进行握手的第三步回 ACK时候,如果收到RST 内核会对报文进行PAWS校验,如果 RST 带的 timestamp(TVal) 不递增就会因为通不过 PAWS 校验而被扔掉
https://github.com/torvalds/linux/commit/7faee5c0d514162853a343d93e4a0b6bb8bfec21 这个 commit 去掉了TCP_SKB_CB(skb)->when = tcp_time_stamp,导致 3.18 的内核版本linger close主动发送的 RST 中 ts_val为0,而修复的commit在 675ee231d960af2af3606b4480324e26797eb010,直到 4.10 才合并进内核
参考资料
per-connection random offset:https://lwn.net/Articles/708021/