从 0 到 1 复刻一个 Claude Code 这样的 Agent
从 0 到 1 复刻一个 Claude Code 这样的 Agent
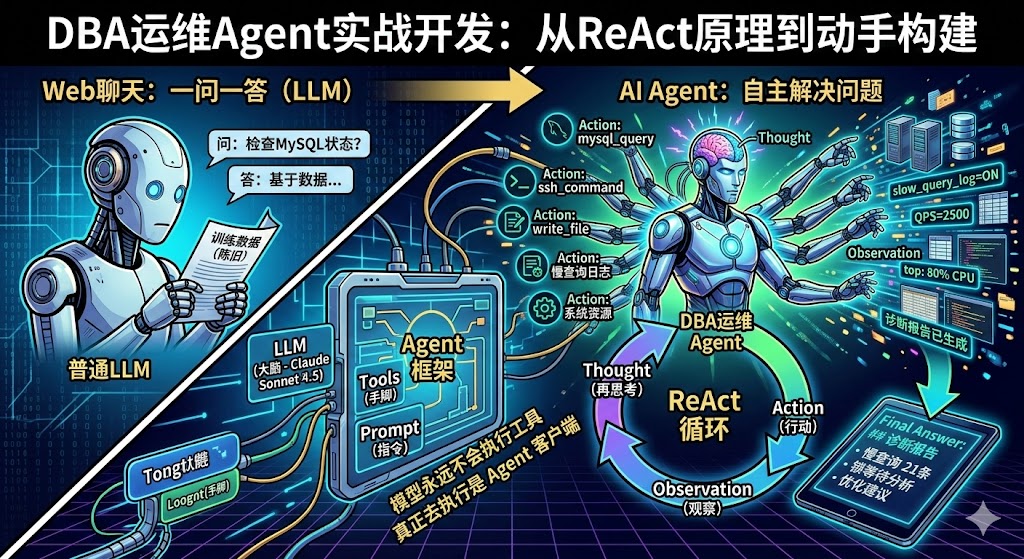
基于 DBA 运维 Agent 的实战开发过程,结合 ReAct 论文原理,帮助你理解 Claude Code 这类 Agent 的工作本质,并具备自己动手构建一个专属 Agent 的能力。
为什么要了解 Agent
我们日常使用 Claude Code 这样的工具时,可能觉得它很神奇——丢一个问题进去,它就能帮你定位问题、修改代码、甚至操作服务器。但如果你不理解它背后的运行原理,就很难把 AI 真正融入自己的工作流。
了解 Agent 的意义有两个层面:
- 理解原理,提升使用效率:知道 Claude Code 怎么工作的,你就知道怎么更好地跟它协作,什么该交给它,什么需要你来把控。
- 自己动手,定制专属工具:当你理解了 Agent 的本质之后,你完全可以基于公司提供的 API 和模型,开发一个专属于自己业务场景的 Agent——比如一个 MySQL 运维 Agent、一个监控告警分析 Agent。
本文的目标就是:通过开发一个极简的 MySQL 运维 Agent,彻底搞懂 Claude Code 这类工具是怎么工作的。以后再看到小龙虾/Claude code/kiro 这样的 agent/智能体就犹如庖丁解牛
一、从”一问一答”到”自主解决问题”
网页聊天 vs Agent 的本质区别
以前我们在网页上使用大模型,交互方式是一问一答:你丢一个问题,模型基于训练数据吐一个答案,仅此而已。模型不知道你的服务器状况,不知道你的数据库配置,也没办法帮你执行任何命令。
Claude Code 的方式完全不同。它拿到你的问题之后,会带着一堆工具(比如执行 bash 命令、读写文件、查看 CPU 等),反复跟大模型交互:
- 把你的问题 + 工具列表发给大模型
- 大模型分析后说:”帮我执行一下
top命令” - Claude Code 执行
top,把结果塞回去 - 大模型看到结果,又说:”再帮我看一下磁盘”
- 继续执行,继续把结果塞回去
- 反复迭代十几轮,直到大模型说:”信息够了,我来给你最终结论”
对用户来说,你只输入了一句话,然后等着就行。 但背后 Agent 可能已经跟模型来回跑了十几轮。
2025 年 AI 为什么突然”厉害了”
很多人感觉从 2025 年下半年开始,AI 工具突然变得非常实用——能帮你写代码、部署服务、定位故障。但这里有一个常见的误解:不是模型本身变强了多少,而是 Agent 这个”客户端”变强了。
以前的模型只能基于训练数据回答问题,现在的 Agent 可以不断地给模型”喂”新信息——实时的系统状态、数据库查询结果、日志内容。模型不再是闭卷考试,而是变成了”开卷 + 有助手帮你翻书”的模式。
二、两个必须记住的基本原则
原则一:模型没有记忆
这一点非常关键,虽然很多人在各种文章中看到过,但可能理解不够深刻。
大模型是没有任何记忆的。 不管你是同一个账户、同一次会话,前后两次提问之间,模型不会记住或关联它们。你觉得它”记住了”上一轮的内容,那是因为 Agent 帮它做了一件事:把前面所有的对话历史、工具执行结果,全部打包成一个巨大的 prompt,每次都完整地发给模型。
所以你会看到,每一轮交互,Agent 发给模型的内容会越来越长——第一轮可能 1000 字,第五轮可能 5000 字,第十轮可能上万字。这就是为什么 token 消耗会这么快。
原则二:模型永远不会执行工具
大模型自己不会也不能执行任何工具。它只做一件事:根据你的问题和已有信息,告诉 Agent 应该调用什么工具、参数是什么。
真正去执行 SSH 命令、跑 MySQL 查询的是 Agent 程序本身。执行完之后,Agent 也不理解这些返回结果(可能成功了、可能报错了),它只是原样把结果丢给模型,让模型来判断下一步该怎么做。
三、什么是 Agent
Agent(智能体)= 让模型持续思考、持续调用外部工具、直到解决用户问题的程序。
Claude Code、OpenCode 这些都是 Agent,它们只是一个客户端工具,背后需要一个大模型来完成推理工作。
用一张图来理解:
1 | 你的代码(Agent 框架) |
核心区别:
- 普通 LLM 调用:一问一答,模型只能靠训练数据回答
- Agent 模式:模型可以主动调工具获取实时信息,多轮推理后给出答案
这里还有一个细节值得注意:Agent 启动时会把所有工具的定义(名称、用途、参数说明)都一次性发给模型。比如你配了 GitHub、MCP、bash 等几十个工具,不管你的问题跟哪个工具有没有关系,全部都会带上。这就是为什么你一打开 Claude Code,上下文消耗就已经很高了——因为光工具定义就占了几万字。
四、ReAct:Agent 的核心工作模式
ReAct(Reasoning + Acting)是目前 Agent 最主流的工作模式,来自 2022 年发表的论文 ReAct: Synergizing Reasoning and Acting in Language Models。
核心循环
1 | ┌─────────────────────────────────────────────────────┐ |
核心理念是:大模型先思考(Thought)当前需要什么信息,然后决定一个行动(Action)让 Agent 去执行,Agent 执行后返回观察结果(Observation),模型再根据新信息继续思考。这个循环不需要你写任何 if-else 逻辑——模型自己决定调什么工具、调几次、什么时候停。
以前我们写自动化程序,靠的是模板匹配和条件判断,需要穷举各种场景,所以做起来很麻烦、动不动就要改。现在 Agent 把所有判断逻辑交给了模型,模型来决定下一步做什么。
实际运行示例
以”检查 MySQL 主从复制状态”为例,Agent 的实际思考过程:
1 | [LLM #1] |
在这个过程中,模型自己判断了:先查从库状态 → 发现不是从库 → 转查主库状态 → 确认是主库 → 检查从库连接 → 查日志。你完全不需要预设这些逻辑,模型根据每一步的返回自行决策。
五、Agent 开发三要素
1 | ┌────────────────────────────────────────────┐ |
| 要素 | 你需要做什么 | 本项目示例 |
|---|---|---|
| LLM | 选模型、配 API 地址 | Claude Sonnet 4.5 via API 网关 |
| Tools | 写 Python 函数,让模型能调用 | ssh_command / mysql_query / write_file |
| Prompt | 告诉模型它是谁、能做什么 | “你是 DBA 专家,只读诊断…” |
80% 的开发工作在写 Tools。 LLM 和 Prompt 通常很快就定了。
六、Step by Step 开发流程
Step 1:明确场景,定义工具边界
先回答三个问题:
- Agent 要解决什么问题?→ MySQL/Linux 远程只读诊断
- 需要哪些工具?→ SSH 执行命令、MySQL 查询、写报告文件
- 安全边界是什么?→ 只读,不能执行写操作
1 | 场景:DBA 日常诊断 |
工具代码中的注释(description)非常重要——模型就是靠这些描述来决定什么时候调用哪个工具、传什么参数。这些注释不是给人看的,是给模型看的。
为了安全起见,我们还需要给工具加上黑白名单,比如 MySQL 工具只允许 SHOW、SELECT 等只读操作,禁止 DROP、DELETE、TRUNCATE 等危险命令。
Step 2:搭项目结构
1 | mkdir -p ~/q/agent/tools |
Step 3:写工具(核心工作量)
每个工具就是一个 Python 类,继承 BaseTool,实现 _run 方法:
1 | from crewai.tools import BaseTool |
工具开发要点:
description写清楚——模型靠它判断何时调用_run返回纯文本——模型只能处理文本- 做好安全拦截——模型可能尝试危险操作
- 加超时控制——防止
tail -f等命令无限阻塞
Step 4:配置 LLM 连接
1 | # config.yaml |
1 | from crewai import LLM |
注意:如果 API 网关是 OpenAI 兼容协议,模型名需要加
openai/前缀让 litellm 走 OpenAI 通道。
Step 5:组装 Agent
1 | from crewai import Agent, Task, Crew |
Step 6:跑起来
1 | task = Task( |
七、实战:一次完整的诊断过程
我们给 Agent 一个实际任务:”分析 SQL 响应时间以及内存资源”。
Agent 开始工作后,debug 模式下可以看到完整的交互过程:
第 1 轮:模型收到问题,决定先查慢查询配置
1 | Action: mysql_query → SHOW GLOBAL VARIABLES LIKE '%slow%' |
第 2 轮:模型知道了慢查询阈值是 0.5 秒,继续查慢查询数量
1 | Action: mysql_query → SHOW GLOBAL STATUS LIKE 'Slow_queries' |
第 3 - 8 轮:模型继续查询 QPS、线程状态、锁信息、查询缓存…
第 9 - 12 轮:模型觉得还需要看系统资源,自动通过 SSH 执行 top、free 等命令
第 18 轮:模型终于认为信息足够了,输出 Final Answer:
- 慢查询数量:21 条,阈值 0.5 秒
- QPS 统计和慢查询占比
- 锁等待分析
- 内存使用状况
- 综合评分和优化建议
整个过程中,你只输入了一行命令,但 Agent 已经自动完成了 18 轮诊断。 这就是 Agent 的魅力所在。
八、踩坑记录
实际开发中遇到的问题和解决方案(这部分经验非常重要,第一次把代码写出来能直接跑通的概率几乎为零):
| 问题 | 原因 | 解决 |
|---|---|---|
| MySQL root 连接被拒 | root 只允许 socket 连接 | 改为 SSH + mysql CLI 方式 |
| 模型报 prefill 错误 | 部分后端不支持 assistant prefill | 换用支持的模型版本 |
| 找不到 litellm | openai/ 前缀需要 litellm 做路由 |
pip install 'litellm<1.60' |
| chromadb 报 sqlite3 版本太低 | 系统自带 sqlite 版本不够 | pip install pysqlite3-binary + monkey-patch |
| numpy 不兼容 CPU | numpy 2.x 需要新指令集 | pip install 'numpy<2' |
tail -f 导致工具永远不返回 |
paramiko recv_exit_status() 无限阻塞 |
改用 channel 级非阻塞读取 + deadline 超时 |
SHOW SLAVE STATUS\G 报错 |
\G 是 mysql CLI 交互命令,batch 模式不支持 |
模型自动修正去掉 \G 重试 |
| debug 日志不输出 | 框架覆盖了自定义 logger | monkey-patch 保护自定义 logger |
关键经验:模型第一次生成的代码几乎不可能直接跑通。 你需要提供一个真实的调试环境(一台可以 SSH 的机器、一个可以连的 MySQL 实例),让 AI 在真实环境中反复调试。这个调试和验证的过程,才是开发 Agent 中最关键的一步。你需要做的是给 AI 搭好舞台——准备好机器、配好免密、提供连接信息,然后让它自己去试、去修、去迭代。
九、调试技巧
加 –debug 看完整的 LLM 交互
1 | python3 main.py --host 10.0.0.1 --debug "检查MySQL版本" |
输出每次发给模型的完整 prompt 和模型的完整回复,能清楚看到:
- 模型在”想”什么(Thought)
- 模型决定调什么工具(Action)
- 工具返回了什么(Observation)
- Token 消耗量
先单独测试工具
不要一上来就跑完整 Agent,先验证每个工具独立可用:
1 | from tools.ssh_tool import SSHCommandTool |
关键公式
1 | Agent 效果 = 模型能力 × 工具质量 × Prompt 清晰度 |
- 模型不够强 → 换更大的模型
- 工具返回乱码 → 格式化输出
- 模型不知道用哪个工具 → 改 description
- 模型反复出错重试 → 加 –debug 看 prompt,调 backstory
十、进阶思考:从个人效率到团队赋能
第一阶段:用好现有工具
把 Claude Code 这样的工具融入日常工作,让以前花两三个小时的任务,现在 5 分钟搞定。这是最基础的提效。
第二阶段:定制专属 Agent
结合自己的业务场景,开发专属 Agent。比如 DBA 运维 Agent,可以进一步接入更多数据源:
- 监控数据:接入 Prometheus,让 Agent 能查看历史指标趋势
- 日志平台:接入 SLS 等日志服务,让 Agent 能自动拉取和分析错误日志
- 元数据库:接入 DBA 平台的元数据,让 Agent 通过实例名自动查到机器、端口、配置
- 即时通讯:接入飞书、Telegram 等,让团队成员直接在群里向 Agent 提问
工具越丰富,Agent 能做的事情就越多。 你最了解自己的日常工作,最清楚哪些环节可以让 Agent 来接手。
第三阶段:理解原理,看透产品
当你真正理解了 Agent 的运行原理之后,再去看市面上各种 AI 产品,你会发现:
- 它们的核心原理都是一样的——ReAct 循环 + 工具调用
- 产品之间的差异主要在于:提供了哪些工具、交互界面做成什么样、安全策略怎么设计
- 有些产品把命令行工具做成了白屏化的界面,降低了使用门槛,所以对非技术人员更友好
- 有些产品默认不做授权确认,用起来更”丝滑”,但在生产环境需要注意安全风险
理解了本质,你就能站在更高的视角去评估和选择工具,而不是被产品的外表所迷惑。
完整提示词参考
如果你想自己复刻这个 MySQL 运维 Agent,只需要将以下提示词依次交给 Claude Code:
起始提示词(创建项目):
1 | 我想基于 CrewAI 来实现一个我自己的 DBA 运维 agent,~/q/agent/ |
调试提示词(非常关键):
1 | <目标IP> 是我的部署机器,ssh root 免密了,请帮我部署并调试, |
修复 Bug 示例:
1 | 请帮我修复当执行 ssh_command 比如 tail -100 /data0/mysql_3306/log/slow-queries.log |
增加工具示例:
1 | 非常好,现在帮我加一个写文件的 tool,然后可以将大模型的输出写入到某个文件中; |
项目架构
1 | 用户输入 → main.py (CLI) → crew.py (CrewAI Agent) |
使用方式:
1 | cd /data0/scripts/agent |
总结
| 你以为的 | 实际上的 |
|---|---|
| 大模型自己变强了 | Agent 不断喂信息让模型”开卷考试” |
| 模型会记住上下文 | 每次都把完整历史重新发一遍 |
| 模型会执行命令 | 模型只返回”要执行什么”,Agent 去执行 |
| 开发 Agent 很难 | 核心就是写好工具 + 描述清楚 + 调试验证 |
| 代码必须人写 | 提示词 → AI 生成 → 人验证迭代 |
一句话概括:Agent 就是一个死循环,把你的问题和工具带给模型,模型指挥 Agent 执行,执行结果再喂回模型,直到模型说”够了,这是最终答案”。
理解了这个本质,你就理解了 Claude Code、以及市面上所有 AI Agent 产品的工作原理。