通过案例来理解MSS、MTU等相关TCP概念
就是要你懂TCP–通过案例来学习MSS、MTU
问题的描述
- 最近要通过Docker的方式把产品部署到客户机房, 过程中需要部署一个hbase集群,hbase总是部署失败(在我们自己的环境没有问题)
- 发现hbase卡在同步文件,人工登上hbase 所在的容器中看到在hbase节点之间scp同步一些文件的时候,同样总是失败(稳定重现)
- 手工尝试scp那些文件,发现总是在传送某个文件的时候scp卡死了
- 尝试单独scp这个文件依然卡死
- 在这个容器上scp其它文件没问题(小文件)
- 换一个容器scp这个文件没问题
分析过程
实在很难理解为什么单单这个文件在这个容器上scp就卡死了,既然scp网络传输卡死,那么就同时在两个容器上tcpdump抓包,想看看为什么传不动了
在客户端抓包如下:(33端口是服务端的sshd端口,10.16.11.108是客户端ip)

从抓包中可以得到这样一些结论:
- 从抓包中可以明显知道scp之所以卡死是因为丢包了,客户端一直在重传,图中绿框
- 图中篮框显示时间间隔,时间都是花在在丢包重传等待的过程
- 奇怪的问题是图中橙色框中看到的,网络这时候是联通的,客户端跟服务端在这个会话中依然有些包能顺利到达(Keep-Alive包)
- 同时注意到重传的包长是1442,包比较大了,看了一下tcp建立连接的时候MSS是1500,应该没有问题
- 查看了scp的两个容器的网卡mtu都是1500,正常
1 | 基本上看到这里,能想到是因为丢包导致的scp卡死,因为两个容器mtu都正常,包也小于mss,那只能是网络路由上某个环节mtu太小导致这个1442的包太大过不去,所以一直重传,看到的现状就是scp卡死了 |
接下来分析网络传输链路
scp传输的时候实际路由大概是这样的
1 | 容器A---> 宿主机1 ---> ……中间的路由设备 …… ---> 宿主机2 ---> 容器B |
- 前面提过其它容器scp同一个文件到容器B没问题,所以我认为中间的路由设备没问题,问题出在两台宿主机上
- 在宿主机1上抓包发现抓不到丢失的那个长度为 1442 的包,也就是问题出在了 容器A—> 宿主机1 上
查看宿主机1的dmesg看到了这样一些信息
2016-08-08T08:15:27.125951+00:00 server kernel: openvswitch: ens2f0.627: dropped over-mtu packet: 1428 > 1400
2016-08-08T08:15:27.536517+00:00 server kernel: openvswitch: ens2f0.627: dropped over-mtu packet: 1428 > 1400
验证方法
-D Set the Don’t Fragment bit.
-s packetsize
Specify the number of data bytes to be sent. The default is 56, which translates into 64
ICMP data bytes when combined with the 8 bytes of ICMP header data. This option cannot be
used with ping sweeps.
ping 测试
1 | ✘ ren@mac ~/Downloads ping -c 1 -D -s 1500 www.baidu.com |
一些结论
到这里问题已经很明确了 openvswitch 收到了 一个1428大小的包因为比mtu1400要大,所以扔掉了,接着查看宿主机1的网卡mtu设置果然是1400,悲催,马上修改mtu到1500,问题解决。
正常分片是ip层来操作,路由器工作在3层,有分片能力,从容器到宿主机走的是bridge,没有进行分片,或者是因为收到这个IP包的时候里面带了 Don’t Fragment标志,路由器就不进行分片了,那为什么IP包要带这个标志呢?当然是为了有更好的性能,都经过TCP握手协商出了一个MSS,就不要再进行分片了。
当然这里TCP协商MSS的时候应该经过 PMTUD( This process is called “Path MTU discovery”.) 来确认整个路由上的所有最小MTU,但是有些路由器会因为安全的原因过滤掉ICMP,导致PMTUD不可靠,所以这里的PMTUD形同虚设,比如在我们的三次握手中会协商一个MSS,这只是基于Client和Server两方的MTU来确定的,链路上如果还有比Client和Server的MTU更小的那么就会出现包超过MTU的大小,同时设置了DF标志而不再进行分片被丢掉。
centos或者ubuntu下:
$cat /proc/sys/net/ipv4/tcp_mtu_probing //1 表示开启路径mtu检测
0
$sudo sysctl -a |grep -i pmtu
net.ipv4.ip_forward_use_pmtu = 0
net.ipv4.ip_no_pmtu_disc = 0 //默认似乎是没有启用PMTUD
net.ipv4.route.min_pmtu = 552
IPv4规定路由器至少要能处理576bytes的包,Ethernet规定的是1500 bytes,所以一般都是假设链路上MTU不小于1500
TCP中的MSS总是在SYN包中设置成下一站的MTU减去HeaderSize(40)。
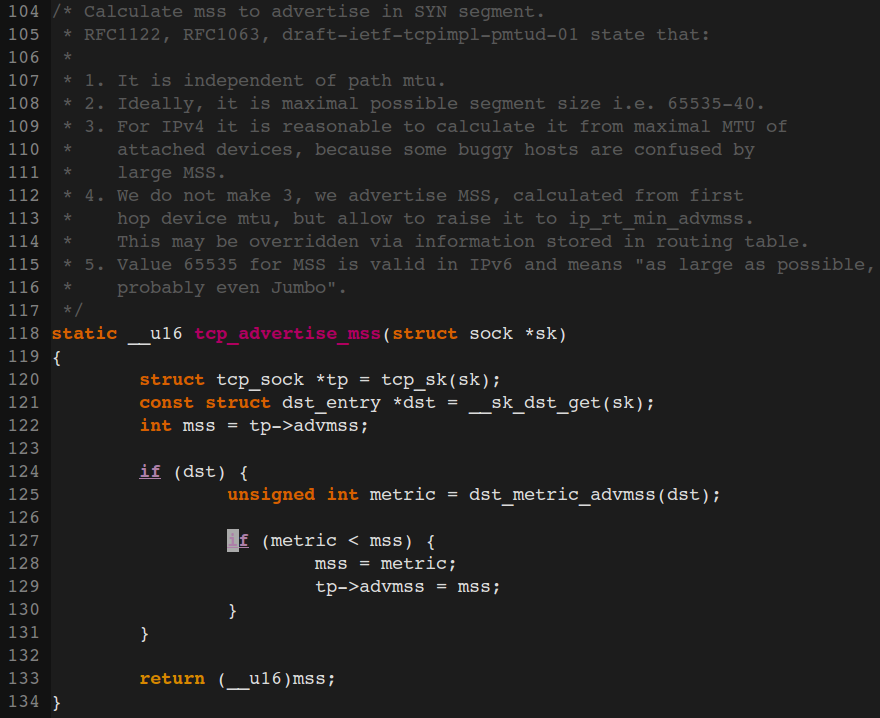
一般终端只有收到PATH MTU 调整报文才会去调整mss报文大小,PATH MTU是封装在ICMP报文里面。所以重新在ECS上抓包,抓取数据交互报文和ICMP报文。
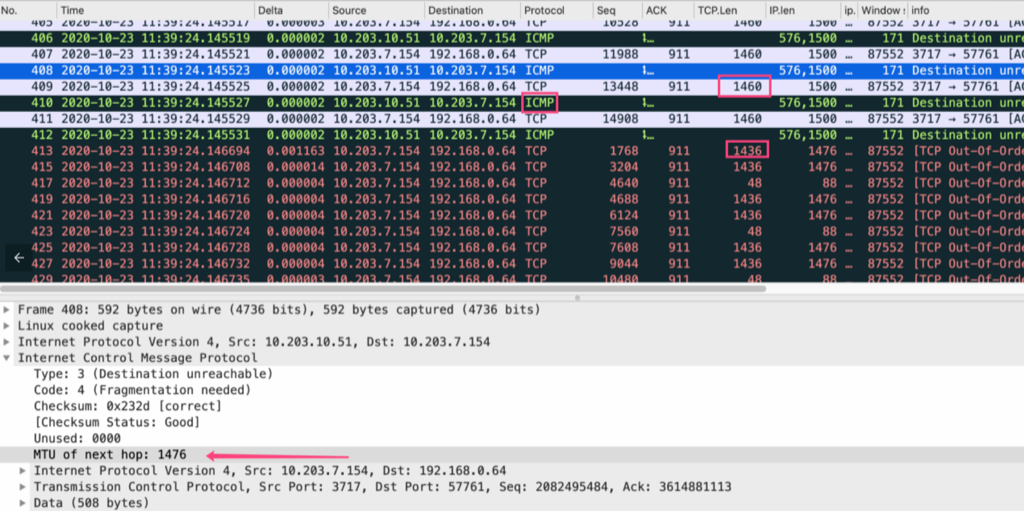
上图可以看到当服务端(3717端口)发送1460 payload的报文的时候,中间链路上的ECS会返回一个ICMP报文,此ICMP报文作用是告诉服务端,ECS的链路MTU只有1476,当服务端收到这个ICMP报文的时候,服务端就会知道中间链路只能允许payload 1436的报文通过,自然就会缩小发送的mss大小。
这个ICMP包在链路上有可能会被丢掉,比如:
Intel网卡驱动老版本RSS使用的是vxlan外层报文, 在新版本切到了内层RSS; 用的外层RSS, 对于GRE代理访问模式没有问题; 新版本用的内层RSS, 看到的源地址是192.168.0.64, 但实际发icmp包的是gre那台ecs-ip, 所以icmp跟session按内层rss策略落不到一个核去了,所以后端服务器无法收到ICMP报文,从而无法自动调整报文MSS大小。
简单说, 就是gre代理回icmp的这种场景, 在内层rss版本上不支持了。
总结
- 因为这是客户给的同一批宿主机默认想当然的认为他们的配置到一样,尤其是mtu这种值,只要不是故意捣乱就不应该乱修改才对,我只检查了两个容器的mtu,没看宿主机的mtu,导致诊断中走了一些弯路
- 通过这个案例对mtu/mss等有了进一步的了解
- 从这个案例也理解了vlan模式下容器、宿主机、交换机之间的网络传输链路
- 其实抓包还发现了比1500大得多的包顺利通过,反而更小的包无法通过,这是因为网卡基本都有拆包的功能了
- 设置由系统主动允许分片的参数 sysctl -w net.ipv4.ip_no_pmtu_disc=1 可以解决这种问题
常见问题
Q: 传输的包超过MTU后表现出来的症状?
A:卡死,比如scp的时候不动了,或者其他更复杂操作的时候不动了,卡死的状态。
Q: mtu 如何配置
ifconfig eth1 mtu 9000 up
vi /etc/sysconfig/network-scripts/ifcfg-eth0
Q: 为什么我的MTU是1500,但是抓包看到有个包2700,没有卡死?
A: 有些网卡有拆包的能力,具体可以Google:LSO、TSO,这样可以减轻CPU拆包的压力,节省CPU资源。
Q: 到哪里可以设置MSS
A: 网卡配置–ifconfig;ip route在路由上指定;iptables中限制
# Add rules
$ sudo iptables -I OUTPUT -p tcp -m tcp –tcp-flags SYN,RST SYN -j TCPMSS –set-mss 48
# delete rules
$ sudo iptables -D OUTPUT -p tcp -m tcp –tcp-flags SYN,RST SYN -j TCPMSS –set-mss 48# show router information
$ route -ne
$ ip route show
192.168.11.0/24 dev ens33 proto kernel scope link src 192.168.11.111 metric 100
# modify route table
$ sudo ip route change 192.168.11.0/24 dev ens33 proto kernel scope link src 192.168.11.111 metric 100 advmss 48