网络通不通是个大问题–半夜鸡叫
网络通不通是个大问题–半夜鸡叫
半夜鸡叫
凌晨啊,还有同学在为网络为什么不通的问题搏斗着:
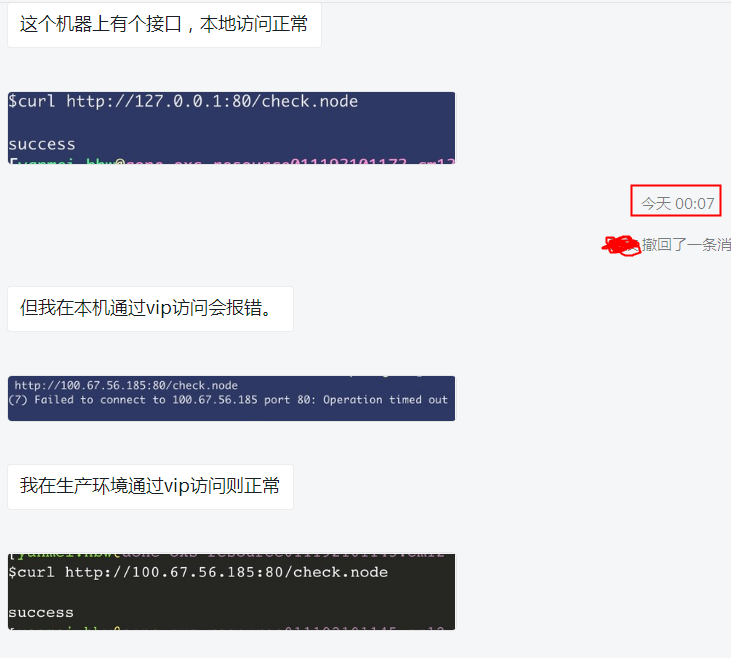
问题描述大概如下:
slb后面配了一台realserver(就叫172吧), 在172上通过curl http://127.0.0.1:80/ 是正常的(说明服务自身是正常的)
如果从开发同学的笔记本直接curl slb-ip 就卡住了,进一步发现如果从北京的办公网curl slb-ip就行,但是从杭州的curl slb-ip就不行。
从杭州curl的时候在172上抓包如下: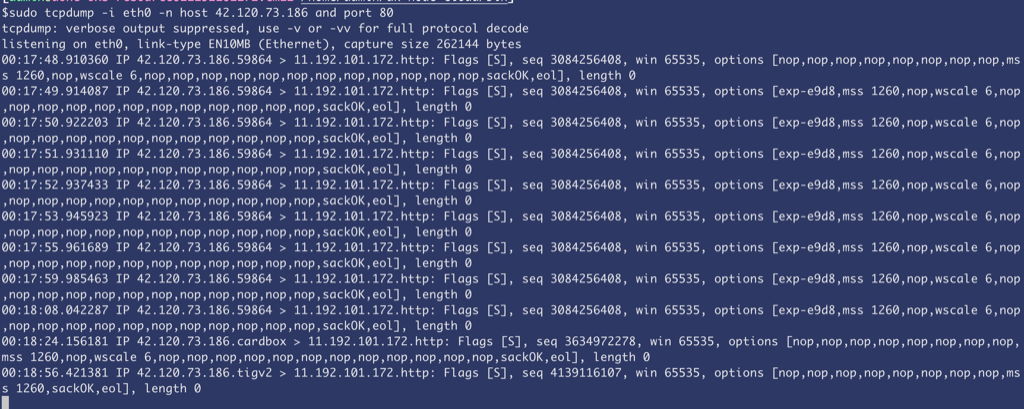
明显可以看到tcp握手包正确到达了172,但是172一直没有回复。也就是如果是杭州访问服务的话,服务端收到握手请求后直接扔掉没有任何回复(回想下哪些场景会扔包)
问题排查
先排除了iptables的问题
略过
route 的嫌疑
因为北京可以杭州不行,明显是某些IP可以,于是检查route 表,解决问题的必杀技(基础知识)都在这里
发现杭州的ip和北京的ip确实命中了不同的路由规则,简单说就是172绑在eth0上,机器还有另外一块网卡eth1. 而回复杭州ip的时候要走eth1. 至于为什么没有从eth1回复等会再说
知道原因就好说了,修改一下route,让eth0成为默认路由,这样北京、杭州都能走eth0进出了
所以到这里,问题描述如下:
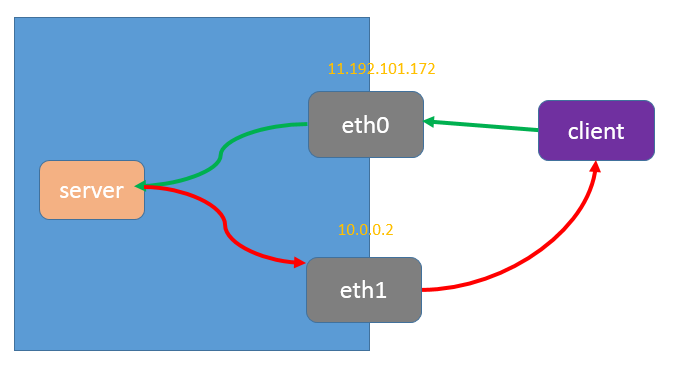
机器有两块网卡,请求走eth0 进来(绿线),然后走 eth1回复(路由决定的,红线),但是实际没走eth1回复,像是丢包了。
解决办法
修改一下route,让eth0成为默认路由,这样北京、杭州都能走eth0进出了
为什么5U的机器可以
开发同学接着反馈,出问题的172是7U2的系统,但是还有一些5U7的机器完全正常,5U7的机器上也是两块网卡,route规则也是一样的。
这确实诡异,看着像是7U的内核行为跟5U不一致,咨询了内核同学,让检查一下 rp_filter 参数。果然看到7U2的系统默认 rp_filter 开着,而5U7是关着的,于是反复开关这个参数稳定重现了问题
1 | sysctl -w net.ipv4.conf.eth0.rp_filter=0 |
rp_filter 原理和监控
rp_filter参数用于控制系统是否开启对数据包源地址的校验, 收到包后根据source ip到route表中检查是否否和最佳路由,否的话扔掉这个包【可以防止DDoS,攻击等】
0:不开启源地址校验。
1:开启严格的反向路径校验。对每个进来的数据包,校验其反向路径是否是最佳路径。如果反向路径不是最佳路径,则直接丢弃该数据包。
2:开启松散的反向路径校验。对每个进来的数据包,校验其源地址是否可达,即反向路径是否能通(通过任意网口),如果反向路径不通,则直接丢弃该数据包。
那么对于这种丢包,可以打开日志:/proc/sys/net/ipv4/conf/eth0/log_martians 来监控到:

rp_filter: IP Reverse Path Filter, 在ip层收包的时候检查一下反向路径是不是最优路由,代码位置:
ip_rcv->NF_HOOK->ip_rcv_finish->ip_rcv_finish_core
也就是rp_filter在收包的流程中检查每个进来的包,是不是符合rp_filter规则,而不是回复的时候来做判断,这也就是为什么抓包只能看到进来的syn就没有然后了
开启rp_filter参数的作用
- 减少DDoS攻击: 校验数据包的反向路径,如果反向路径不合适,则直接丢弃数据包,避免过多的无效连接消耗系统资源。
- 防止IP Spoofing: 校验数据包的反向路径,如果客户端伪造的源IP地址对应的反向路径不在路由表中,或者反向路径不是最佳路径,则直接丢弃数据包,不会向伪造IP的客户端回复响应。
通过netstat -s来观察IPReversePathFilter
$netstat -s | grep -i filter
IPReversePathFilter: 35428
$netstat -s | grep -i filter
IPReversePathFilter: 35435
能明显看到这个数字在增加,如果没开rp_filter 就看不到这个指标或者数值不变
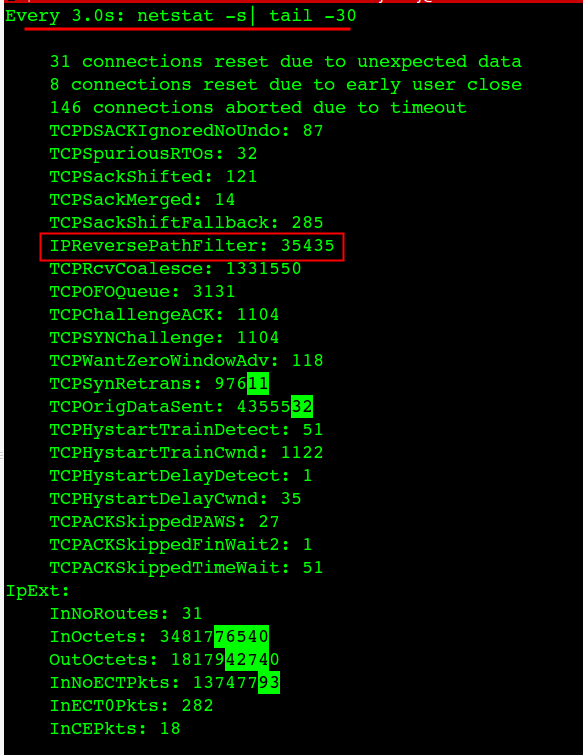
问题出现的时候,尝试过用 watch -d -n 3 ‘netstat -s’ 来观察过哪些指标在变化,只是变化的指标太多,留意不过来,或者只是想着跟drop、route有关的参数
1 | $netstat -s |egrep -i "drop|route" |
当时观察到这几个指标,都没有变化,实际他们看着像但是都跟rp_filter没关系,最后我打算收藏如下命令保平安:
1 | $netstat -s |egrep -i "drop|route|overflow|filter|retran|fails|listen" |
如果客户端建立连接的时候抛异常,可能的原因(握手失败,建不上连接):
- 网络不通,诊断:ping ip
- 端口不通, 诊断:telnet ip port
- rp_filter 命中(rp_filter=1, 多网卡环境), 诊断: netstat -s | grep -i filter ;
- snat/dnat的时候宿主机port冲突,内核会扔掉 syn包。 troubleshooting: sudo conntrack -S | grep insert_failed //有不为0的
- 全连接队列满的情况,诊断: netstat -s | egrep “listen|LISTEN”
- syn flood攻击, 诊断:同上
- 若远端服务器的内核参数 net.ipv4.tcp_tw_recycle 和 net.ipv4.tcp_timestamps 的值都为 1,则远端服务器会检查每一个报文中的时间戳(Timestamp),若 Timestamp 不是递增的关系,不会响应这个报文。配置 NAT 后,远端服务器看到来自不同的客户端的源 IP 相同,但 NAT 前每一台客户端的时间可能会有偏差,报文中的 Timestamp 就不是递增的情况。nat后的连接,开启timestamp。因为快速回收time_wait的需要,会校验时间该ip上次tcp通讯的timestamp大于本次tcp(nat后的不同机器经过nat后ip一样,保证不了timestamp递增),诊断:是否有nat和是否开启了timestamps
- NAT 哈希表满导致 ECS 实例丢包 nf_conntrack full
总结
本质原因就是服务器开启了 rp_filter 为1,严格校验进出包是否走同一块网卡,而如果请求从杭州机房发过来的话,回复包的路由走的是另外一块网卡,触发了内核的rp_filter扔包逻辑。
改server的路由可以让杭州的包也走同一块网卡,就不扔掉了。当然将 rp_filter 改成0 关掉这个校验逻辑也可以完全避免这个扔包。
从问题的解决思路来说,基本都可以认定是握手的时候服务器扔包了。只有知道 rp_filter 参数的内核老司机可以直接得出是这里的原因。如果对于一个新手的话还是得掌握如何推理分析得到原因。