就是要你懂TCP队列--通过实战案例来展示问题
就是要你懂TCP队列–通过实战案例来展示问题
详细理论和实践部分可以看这篇
再写这篇原因是,即使我在上篇文章里将这个问题阐述的相当清晰,但是当我再次碰到这个问题居然还是费了一些周折,所以想再次总结下。
问题描述
使用其他团队的WEBShell 调试问题的时候非常卡,最开始怀疑是定时任务导致压力大,然后重启Server端的Tomcat就恢复了,当时该应用的开发同学看到机器磁盘、cpu、内存、gc等都正常,实在不知道为什么会这么卡
分析问题
因为每天都是上午出现问题,拿到权限后,也跟着先检查一遍定时任务,没发现什么异常。
既然在客户端表现出来卡顿,那么tsar先看看网络吧,果然大致是卡顿的时候网络重传率有点高,不过整个问题不是一直出现,只是间歇性的。
抓包、netstat -s 看重传、reset等都还好、ss -lnt 看也没有溢出,我看了很多次当前队列都是0
重启Tomcat
问题恢复,所以基本觉得问题还是跟Tomcat非常相关,抓包看到的重传率非常低(不到0.01%—被这里坑了一下),因为中间链路还有nginx等,一度怀疑是不是抓包没抓到本地回环网卡导致的,要不不会tsar看到的重传率高,而tcpdump抓下来的非常低。
重启后 jstack 看看tomcat状态,同时跟正常的server对比了一下,发现明显有一个线程不太对,一直在增加
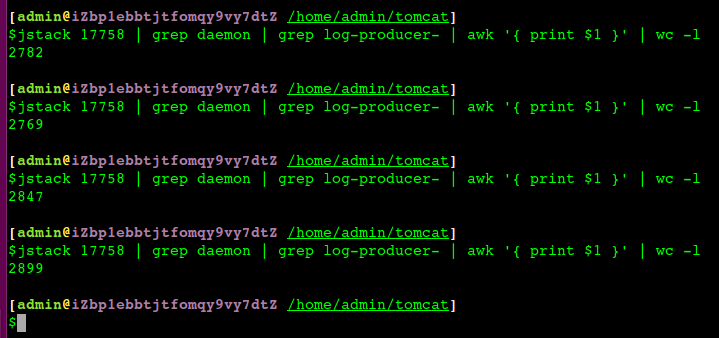
所以到这里大概知道问题的原因了,只是还不能完全确认。
应该是Tomcat里面的线程越来越多导致Tomcat越来越慢,这个慢不是表现在gc、cpu等上,所以开发同学发现卡顿上去也没看出端倪来。
那么对于网络很熟悉的同学,上去看到网络重传很高也没找到原因有点不太应该,主要是问题出现的时候间歇性非常低,通过ss -lnt去看溢出队列和netstat -s |grep -i listen 的时候基本都没什么问题,就忽视了,再说在tcpdump抓包只看到很少的几个重传,反倒是几百个reset包干扰了问题(几百个reset肯定不对,但是没有影响我所说的应用)。
调整参数,加速问题重现
因为总是每天上午一卡顿、有人抱怨、然后重启恢复,第二天仍是这个循环,也就是问题轻微出现后就通过重启解决了
故意将全连接队列从当前的128改成16,重启后运行正常,实际并发不是很高的时候16也够了,改成16是为了让问题出现的时候如果是全连接队列不够导致的,那么会影响更明显一些,经过一天的运行后,可以清晰地观察到:
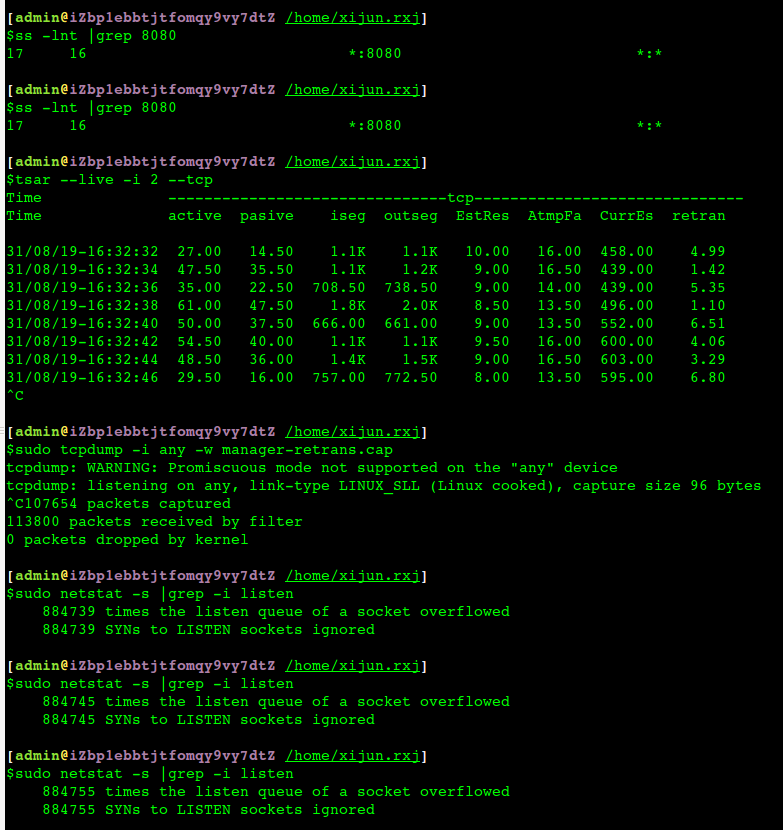
tsar的重传率稳定的很高,ss -lnt也能明显地看到全连接队列完全满了,这个满不是因为压力大了,压力一直还是差不多的,所以只能理解是Tomcat处理非常慢了,同时netstat -s 看到 overflowed也稳定增加
这个时候客户端不只是卡顿了,是完全连不上。
Tomcat jstack也能看到这几个线程创建了2万多个:

抓包(第二次抓包的机会,所以这次抓了所有网卡而不只是eth0)看到 Tomcat的8080端口上基本是这样的:
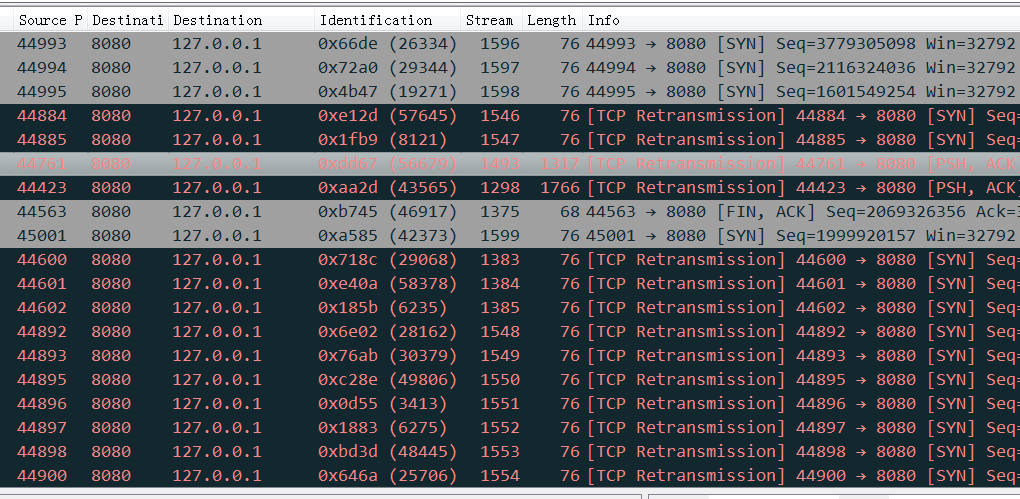
而看所有网卡的所有重传的话,这次终于可以看到重传率和tsar看到的一致,同时也清晰的看到主要127.0.0.1的本地流量,也就是Nginx过来的,而之前的抓包只抓了eth0,只能零星看到几个eth0上的重传包,跟tsar对不上,也导致问题跑偏了(重点去关注reset了)
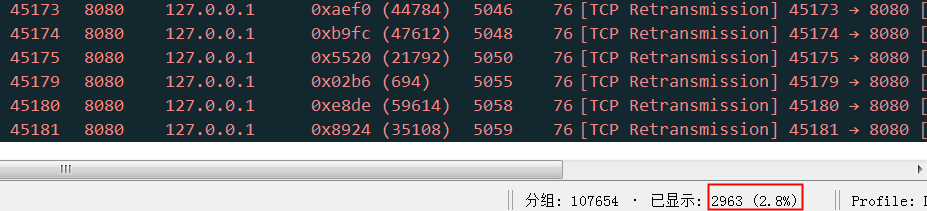
或者这个异常状态的截图

一些疑问
为什么之前抓包看不到这些重传
因为对业务部署的不了解只抓了eth0, 导致没抓到真正跟客户端表现出来的卡顿相关的重传。比如这是只抓eth0上的包,看到的重传:
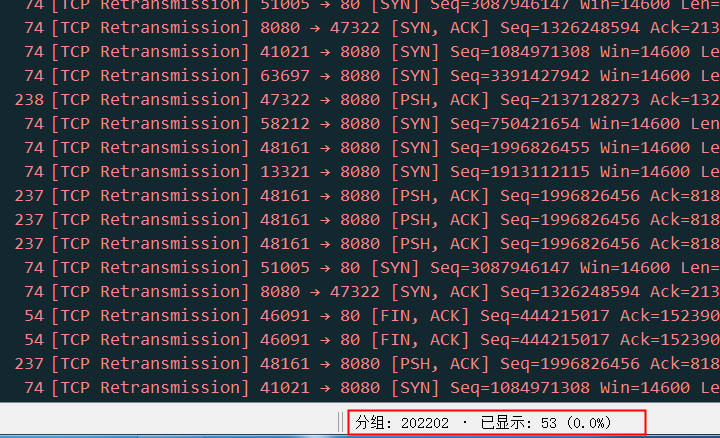
可以看到明显非常少,这完全不是问题。
为什么 ss -lnt / netstat -s 都没发现问题
当时抱怨的时候都是间歇性的,所以 ss -lnt看了10多次都是当前连接0, netstat -s 倒是比较疏忽没仔细比较
为什么线程暴涨没有监控到
边缘业务,本身就是监控管理其它服务的,本身监控不健全。
网络重传和业务的关系
一般我们通过tsar等看到的是整个机器的重传率,而实际影响我们业务的(比如这里的8080端口)只是我这个端口上的重传率,有时候tsar看到重传率很高,那可能是因为机器上其他无关应用拉高的,所以这里需要一个查看具体业务(或者说具体端口上的重传率的工具)
如何快速定位网络重传发生的端口
bcc、bpftrace或者systemtap等工具都提供了观察网络重传包发生的时候的网络四元组以及发生重传的阶段(握手、建立连接后……),这样对我们定位问题就很容易了
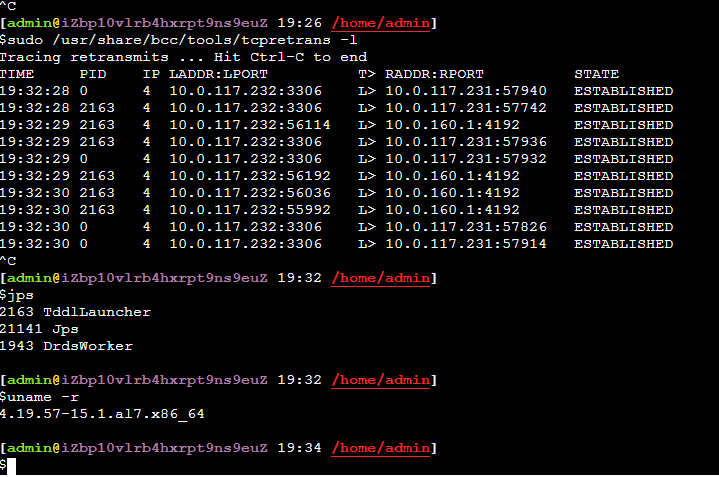
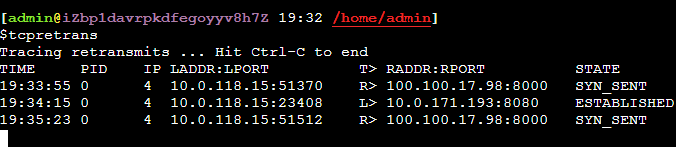

总结
问题的根本原因不是因为TCP连接队列不够,而是 Tomcat中线程泄露,导致Tomcat反应越来越慢,进而导致TCP连接队列溢出,然后网络重传率升高,最终导致了client端操作卡顿。
这种问题最快的是 jstack 发现,但是因为这只是一个后台Manager,所以基本没有监控,当时也漏看了jstack,所以导致问题定位花的时间长一些。当然通过tcpdump(漏抓了 lo 网卡,主要重传都是本地nginx和本地tomcat的,所以没有发现问题),通过 ss -lnt 和 netstat -s 本来也应该可以发现的,但是因为干扰因素太多而导致也没有发现,这个时候tcp_retrans等工具可以帮我们看的更清楚。
当然从发现连接队列不够到Tomcat处理太慢这个是紧密联系的,一般应用重启的时候也会短暂连接队列不够,那是因为重启的时候Tomcat前累积了太多连接,这个时候Tomcat重启中,需要热身,本身处理也慢,所以短暂会出现连接队列不够,等Tomcat启动几分钟后就正常了。