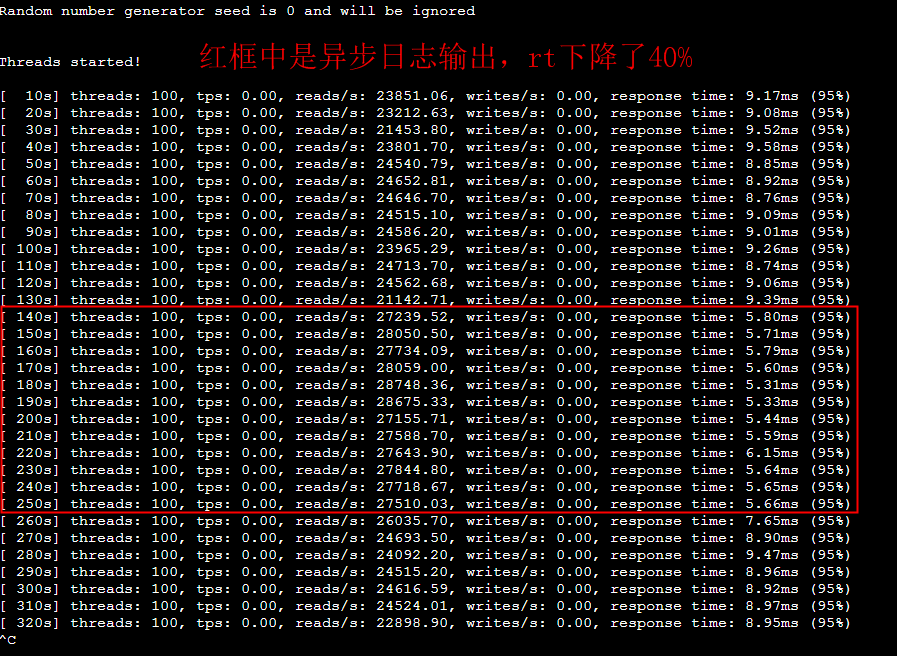
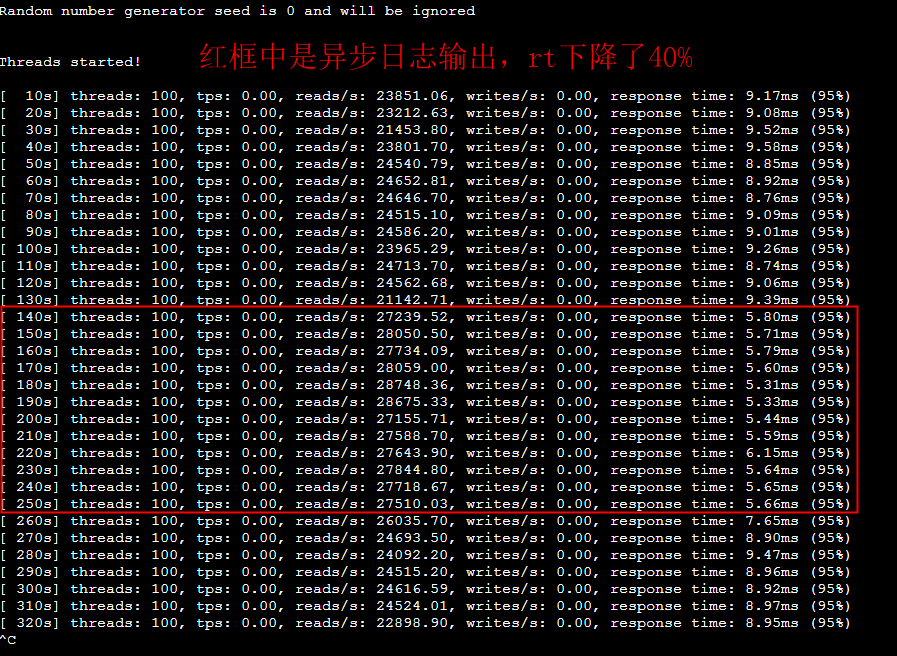
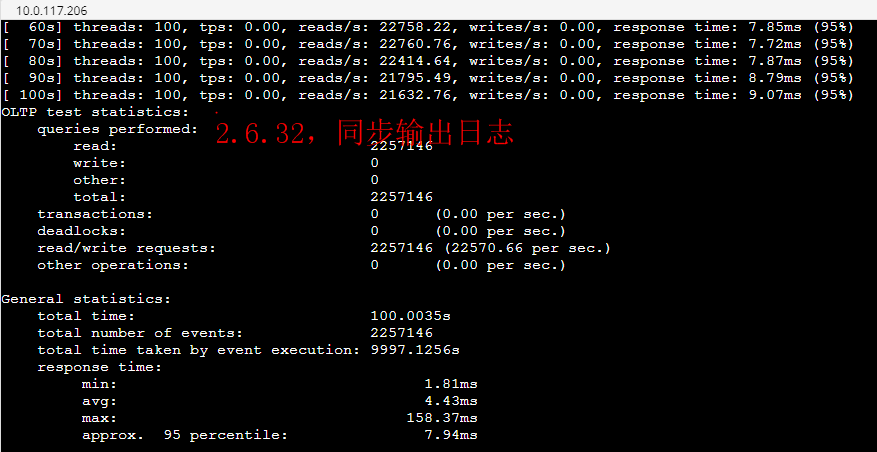
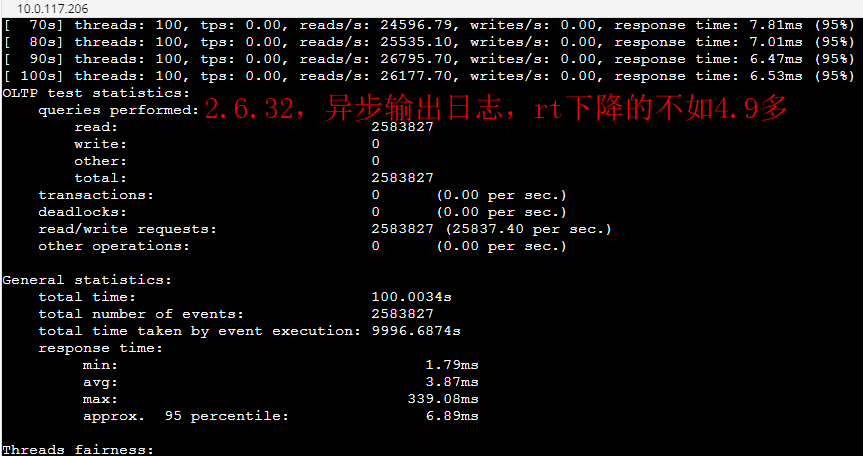
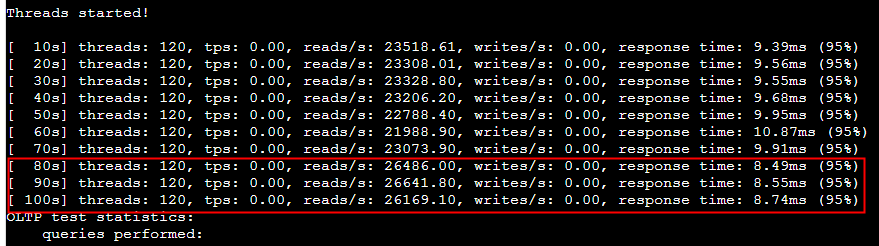
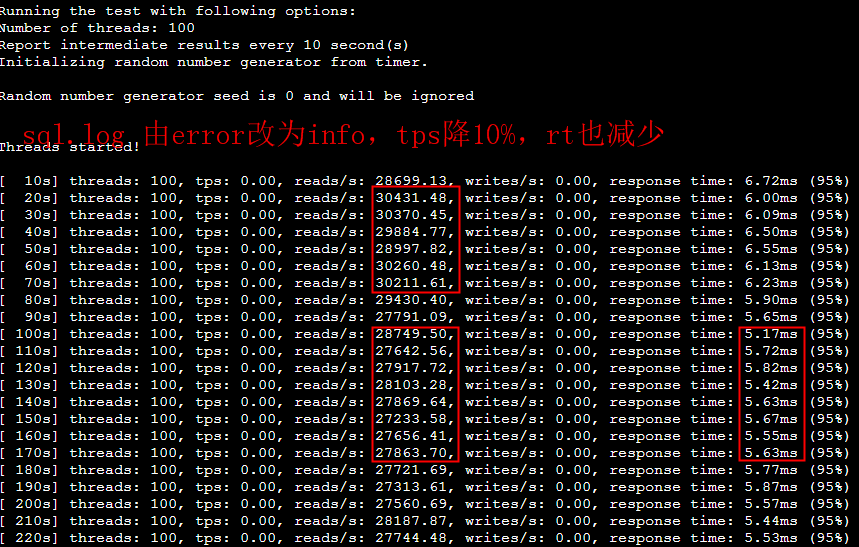
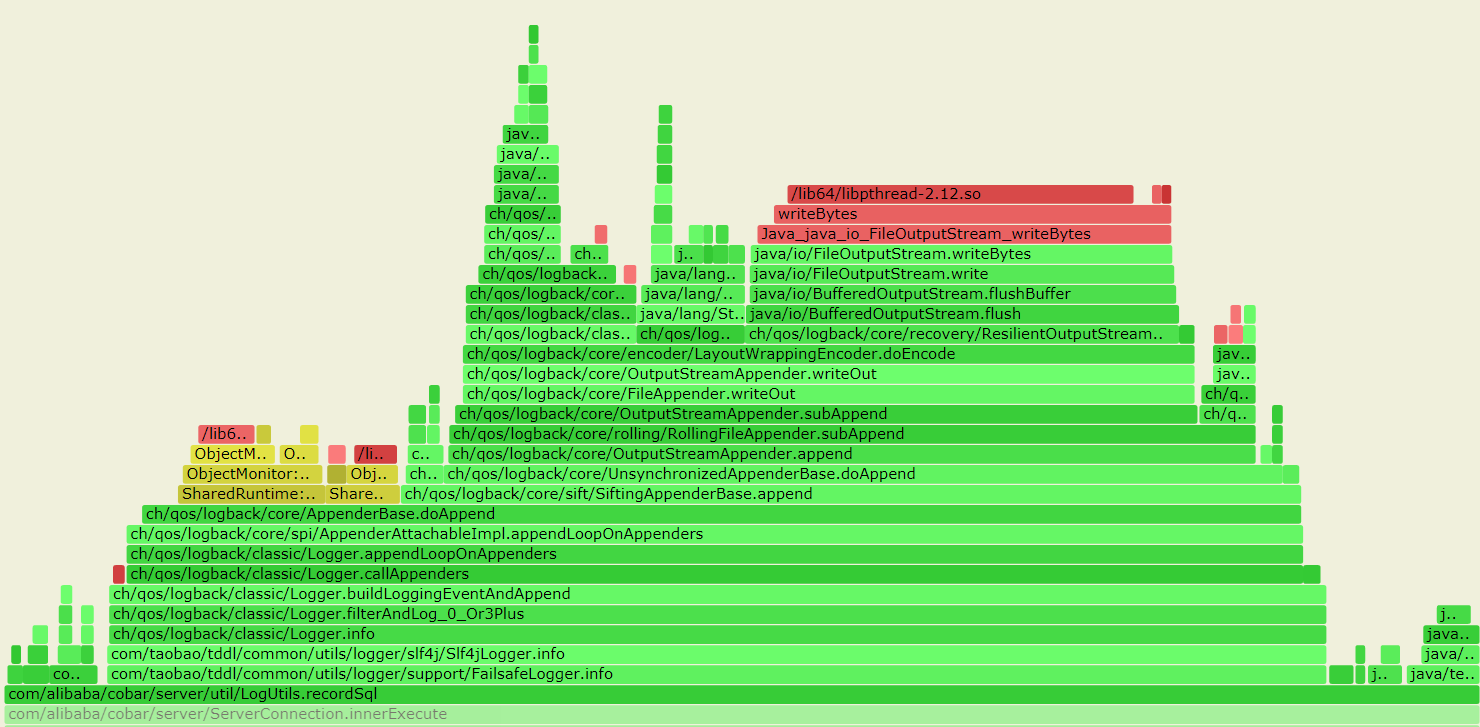
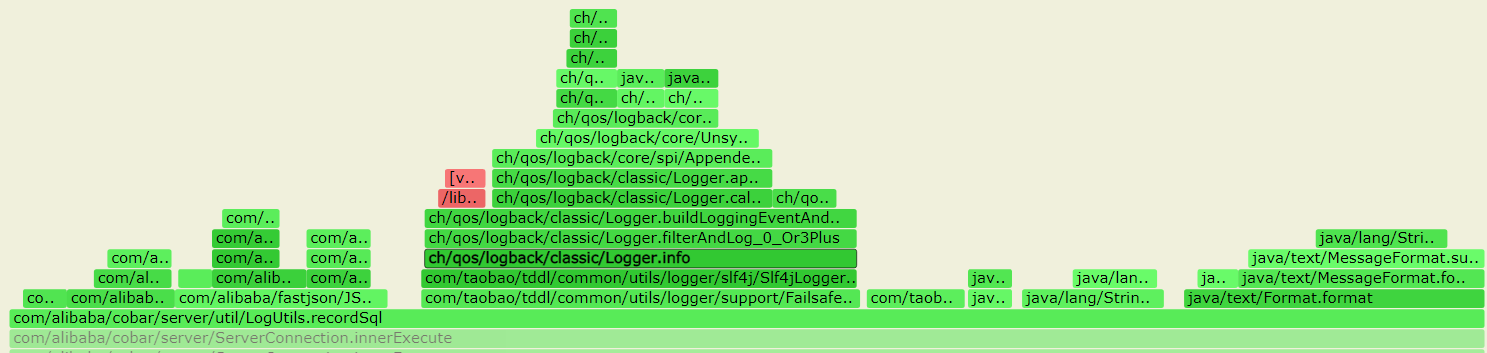
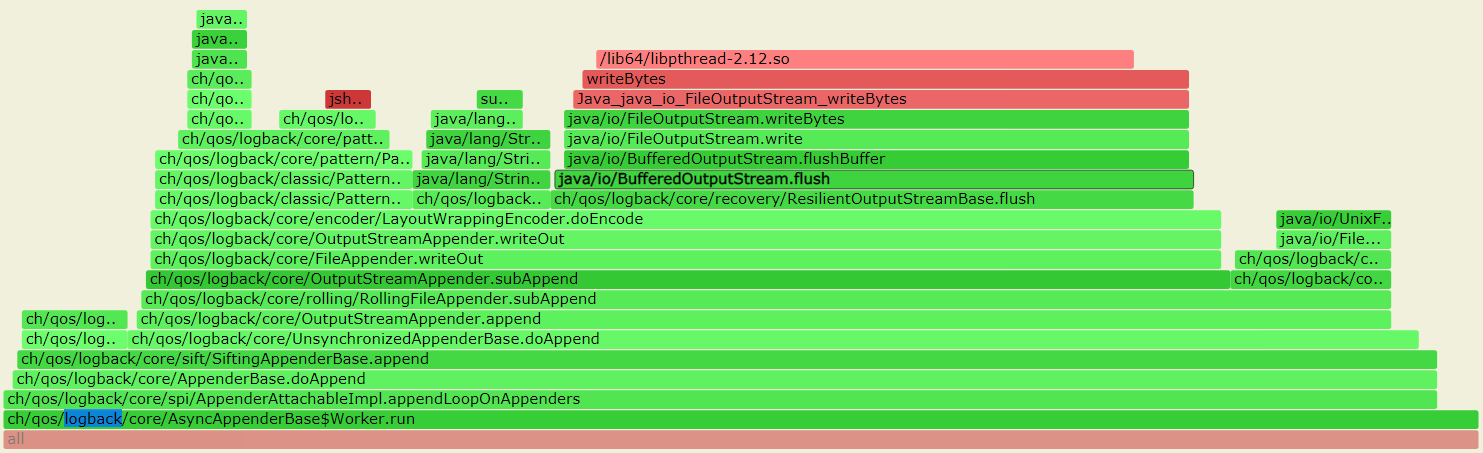
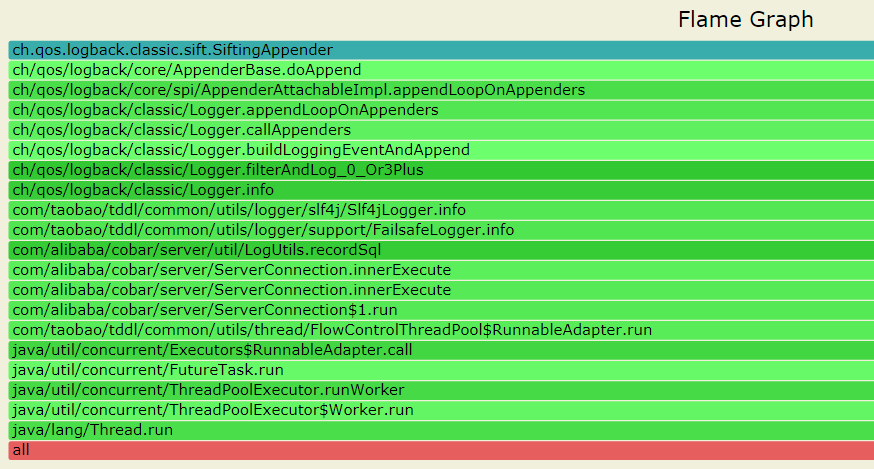
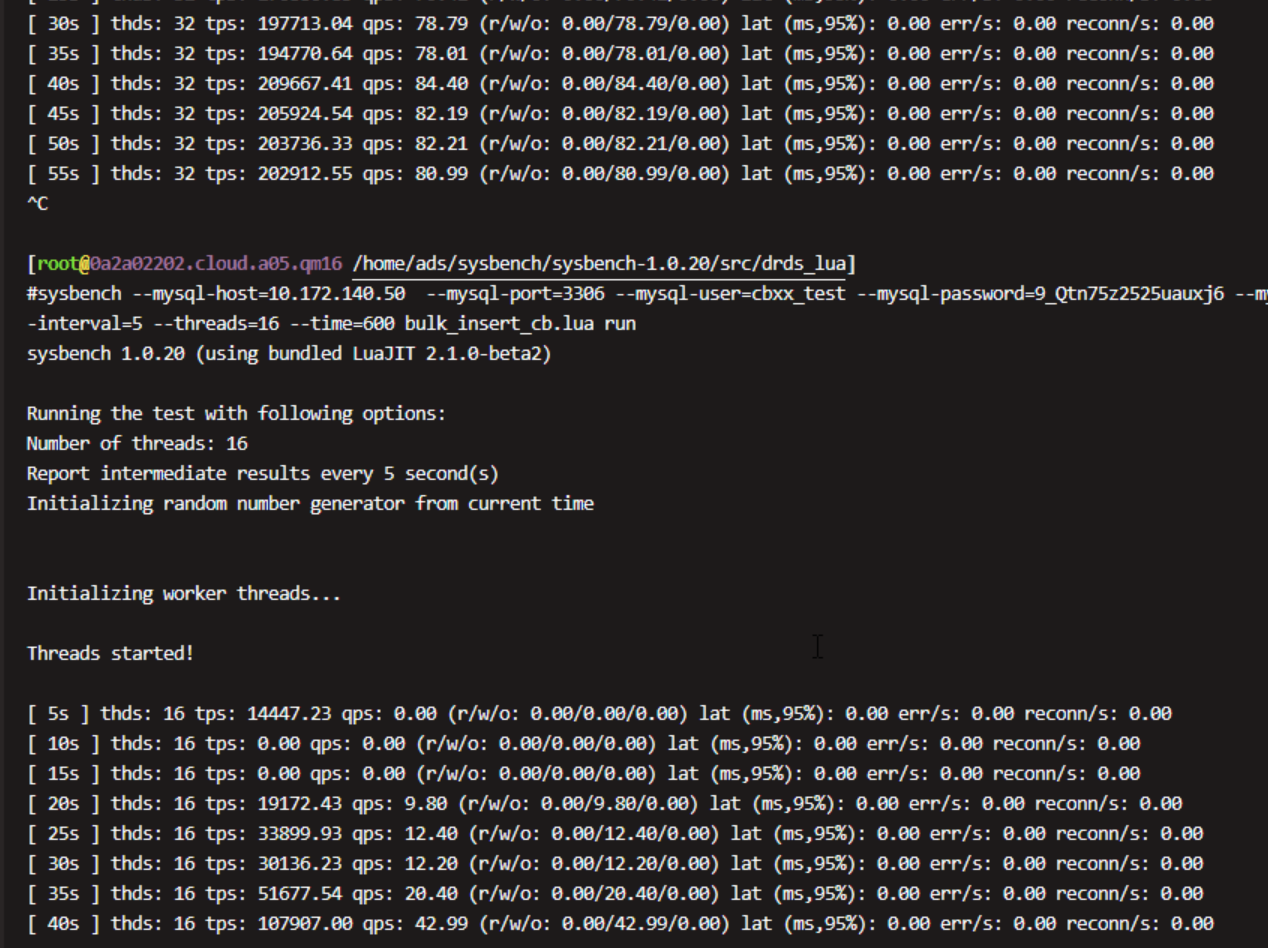
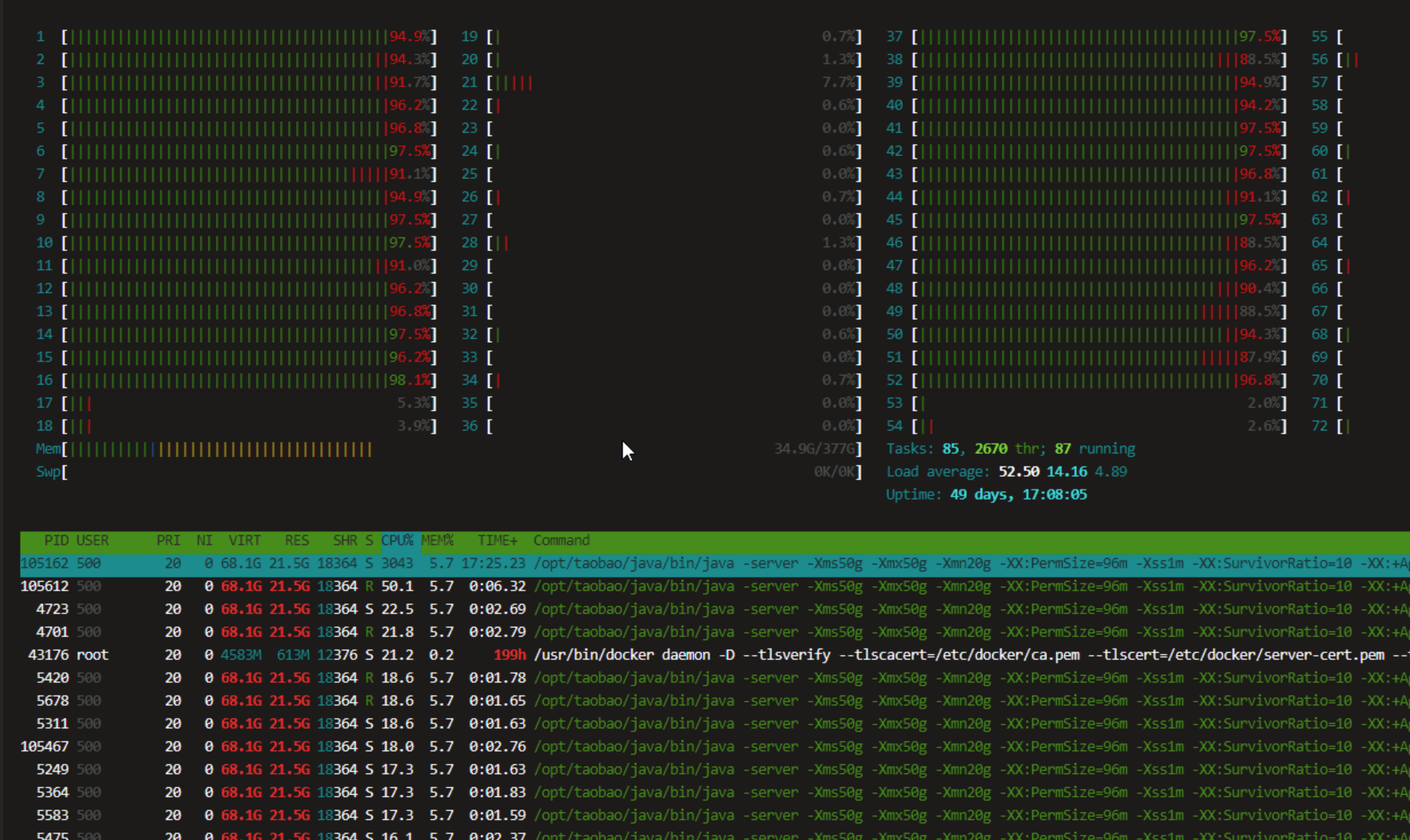
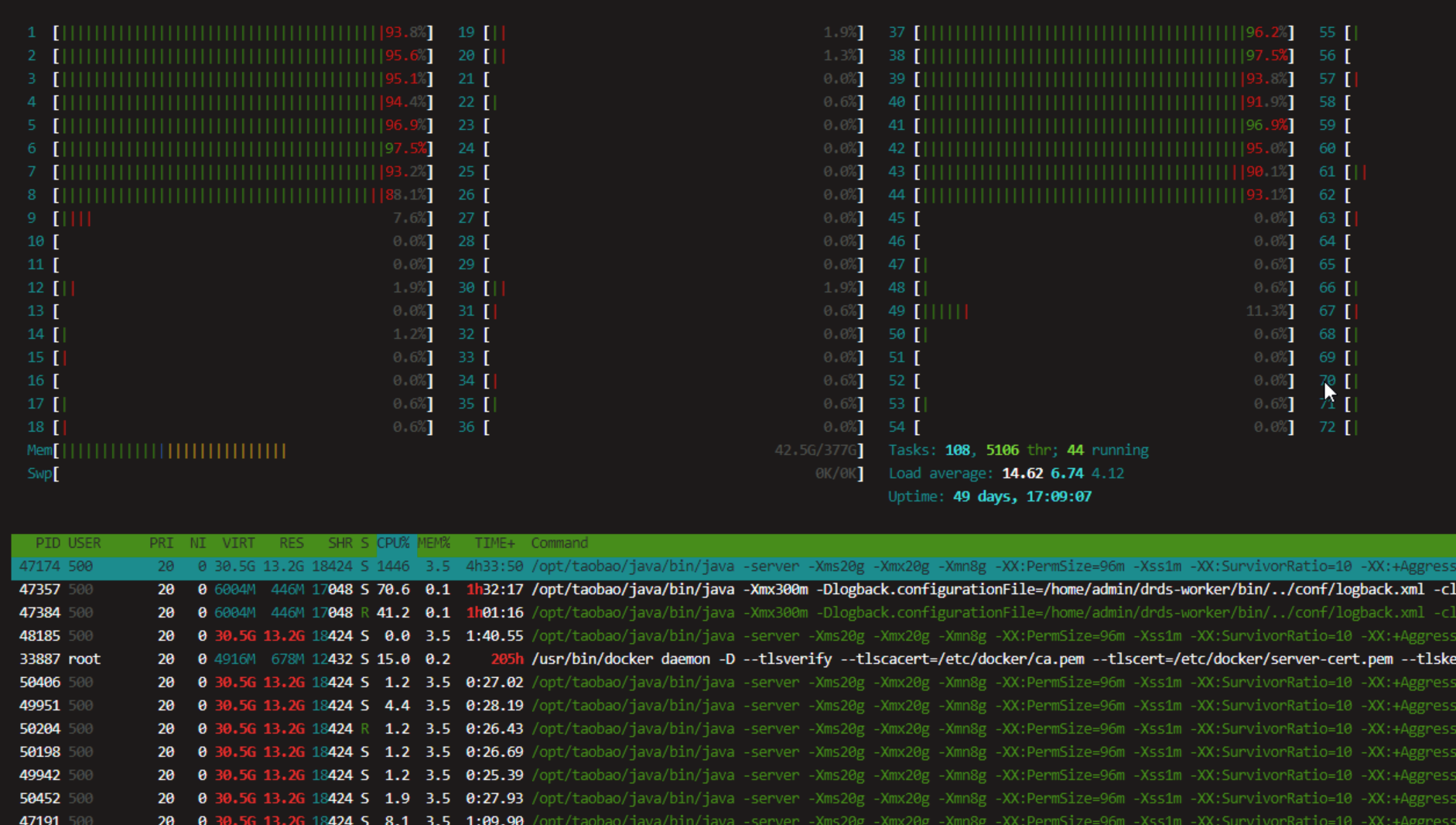
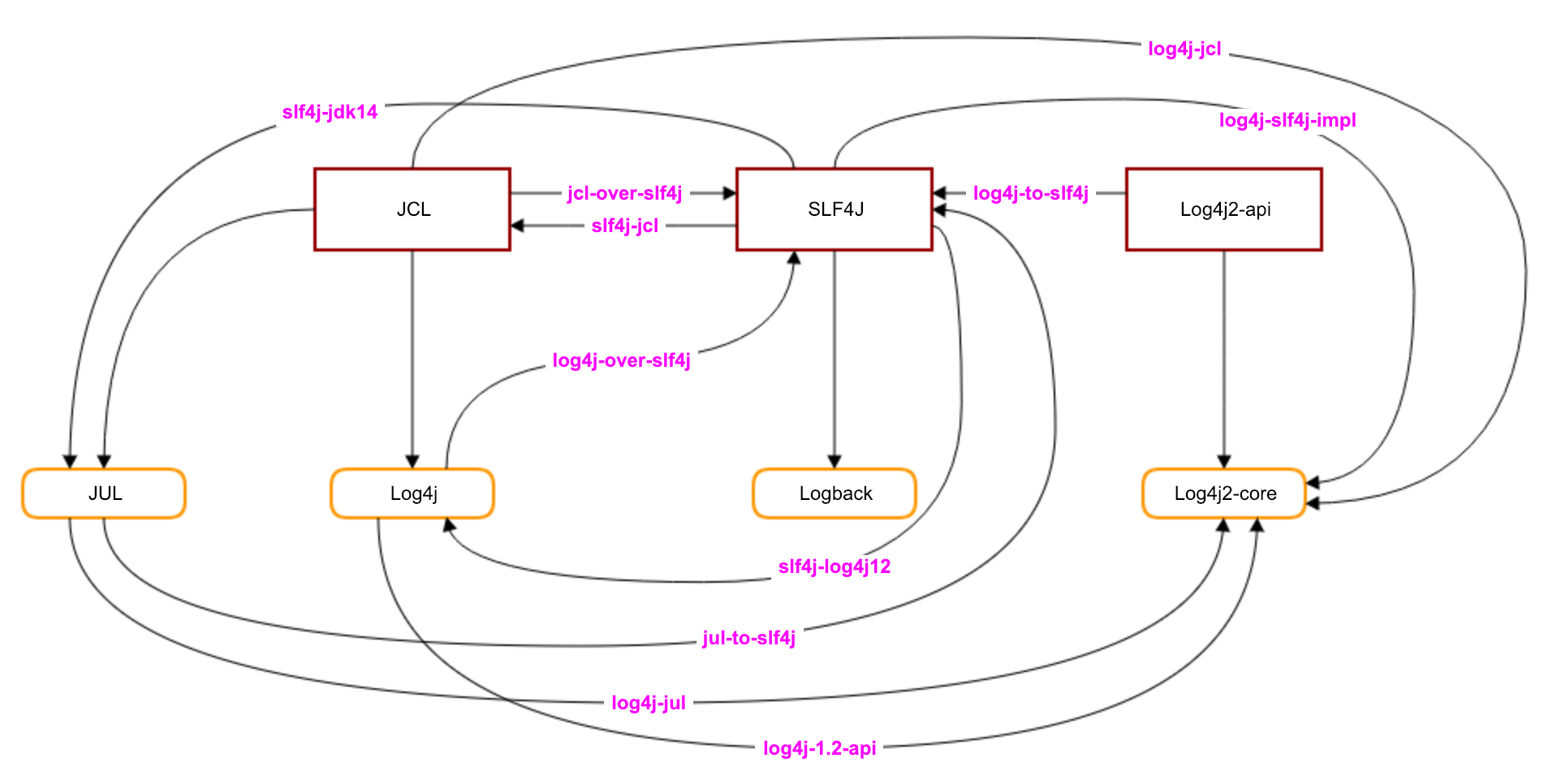
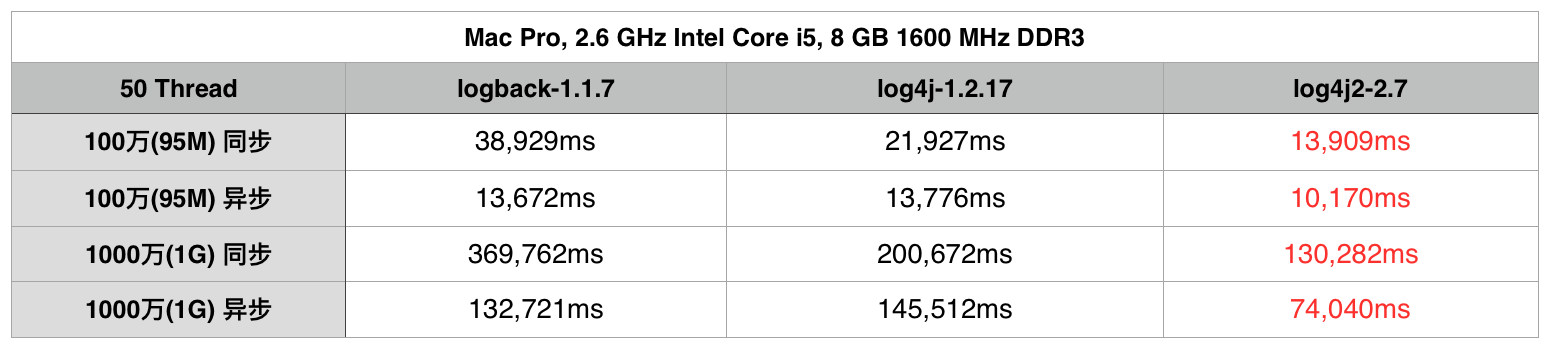
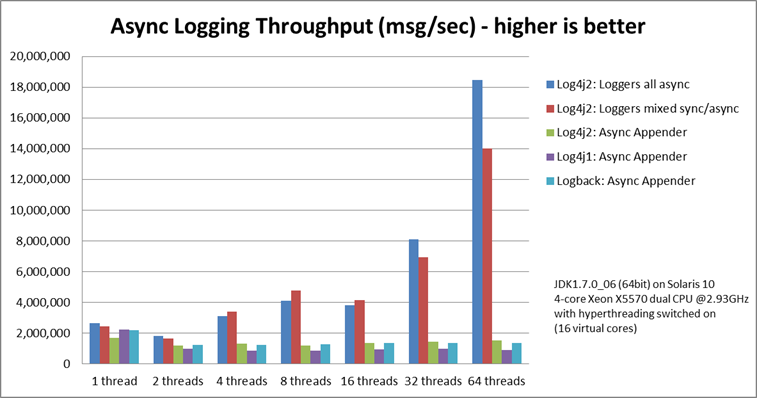
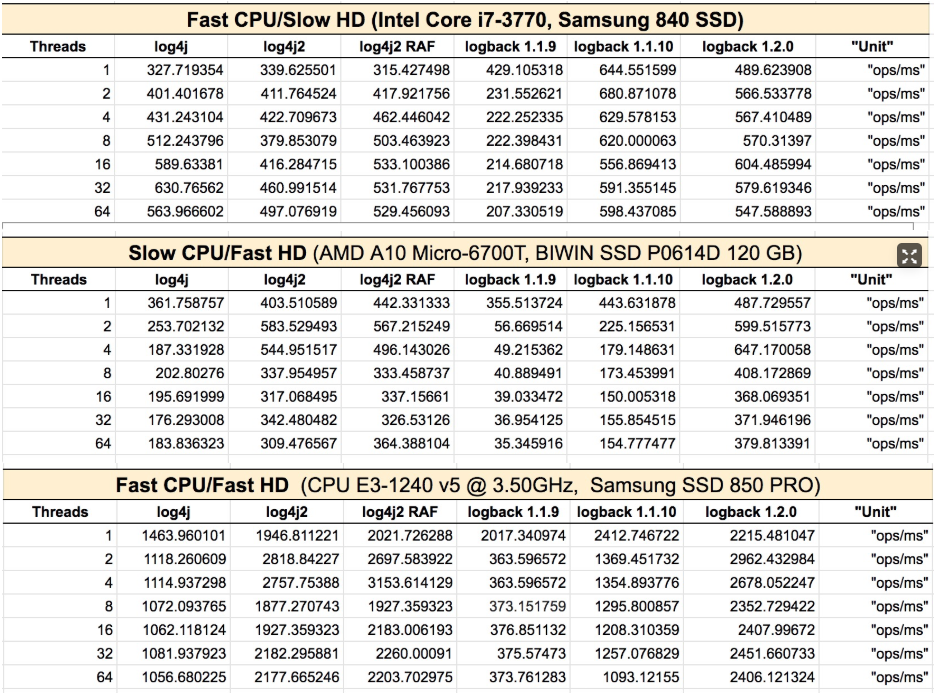
--- 1687260767618 ns (100.00%), 91083 samples [ 0] ch.qos.logback.classic.sift.SiftingAppender [ 1] ch.qos.logback.core.AppenderBase.doAppend [ 2] ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders [ 3] ch.qos.logback.classic.Logger.appendLoopOnAppenders [ 4] ch.qos.logback.classic.Logger.callAppenders [ 5] ch.qos.logback.classic.Logger.buildLoggingEventAndAppend [ 6] ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus [ 7] ch.qos.logback.classic.Logger.info [ 8] com.taobao.tddl.common.utils.logger.slf4j.Slf4jLogger.info [ 9] com.taobao.tddl.common.utils.logger.support.FailsafeLogger.info [10] com.alibaba.cobar.server.util.LogUtils.recordSql [11] com.alibaba.cobar.server.ServerConnection.innerExecute [12] com.alibaba.cobar.server.ServerConnection.innerExecute [13] com.alibaba.cobar.server.ServerConnection$1.run [14] com.taobao.tddl.common.utils.thread.FlowControlThreadPool$RunnableAdapter.run [15] java.util.concurrent.Executors$RunnableAdapter.call [16] java.util.concurrent.FutureTask.run [17] java.util.concurrent.ThreadPoolExecutor.runWorker [18] java.util.concurrent.ThreadPoolExecutor$Worker.run [19] java.lang.Thread.run "ServerExecutor-3-thread-480" #753 daemon prio=5 os_prio=0 tid=0x00007f8265842000 nid=0x26f1 waiting for monitor entry [0x00007f82270bf000] java.lang.Thread.State: BLOCKED (on object monitor) at ch.qos.logback.core.AppenderBase.doAppend(AppenderBase.java:64) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) at ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:48) at ch.qos.logback.classic.Logger.appendLoopOnAppenders(Logger.java:282) at ch.qos.logback.classic.Logger.callAppenders(Logger.java:269) at ch.qos.logback.classic.Logger.buildLoggingEventAndAppend(Logger.java:470) at ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus(Logger.java:424) at ch.qos.logback.classic.Logger.info(Logger.java:628) at com.taobao.tddl.common.utils.logger.slf4j.Slf4jLogger.info(Slf4jLogger.java:42) at com.taobao.tddl.common.utils.logger.support.FailsafeLogger.info(FailsafeLogger.java:102) at com.alibaba.cobar.server.util.LogUtils.recordSql(LogUtils.java:115) at com.alibaba.cobar.server.ServerConnection.innerExecute(ServerConnection.java:874) - locked <0x00007f87382cb108> (a com.alibaba.cobar.server.ServerConnection) at com.alibaba.cobar.server.ServerConnection.innerExecute(ServerConnection.java:569) - locked <0x00007f87382cb108> (a com.alibaba.cobar.server.ServerConnection) at com.alibaba.cobar.server.ServerConnection$1.run(ServerConnection.java:402) at com.taobao.tddl.common.utils.thread.FlowControlThreadPool$RunnableAdapter.run(FlowControlThreadPool.java:480) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1152) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:627) at java.lang.Thread.run(Thread.java:861)
- waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - locked <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender) - waiting to lock <0x00007f866dcec208> (a ch.qos.logback.classic.sift.SiftingAppender)
/**
* Creates a new buffered output stream to write data to the
* specified underlying output stream.
*
* @param out the underlying output stream.
*/
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}