到底是谁reset了你的连接
到底是谁reset了你的连接
通过一个案例展示TCP连接是如何被reset的,以及identification、ttl都可以帮我们干点啥。
背景
用户经常连不上服务,经过抓包发现是链路上连接被reset了,需要定位到是哪个设备发起的reset
比如:
- 用户用navicat从自己访问云上的MySQL的时候,点开数据库总是报错(不是稳定报错,有一定的概率报错)
- 某家居客户通过专线访问云上MySQL,总是被reset( 内网ip地址重复–都是192.168.*, 导致连接被reset)
进程被kill、异常退出时,针对它打开的连接,内核就会发送 RST 报文来关闭。RST 的全称是 Reset 复位的意思,它可以不走四次挥手强制关闭连接,但当报文延迟或者重复传输时,这种方式会导致数据错乱,所以这是不得已而为之的关闭连接方案。当然还有其它场景也会触发reset
抓包
在 Navicat 机器上抓包如下:
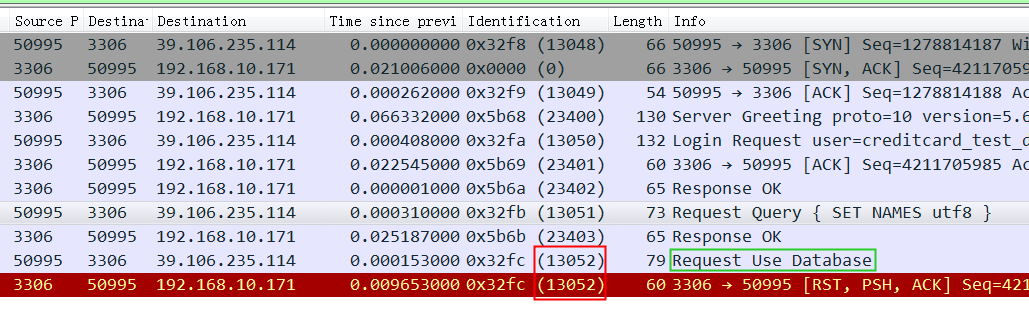
从抓包可以清楚看到 Navicat 发送 Use Database后收到了 MySQL(来自3306端口)的Reset重接连接命令,所以连接强行中断,然后 Navicat报错了。注意图中红框中的 Identification 两次都是13052,先留下不表,这是个线索。
MySQL Server上抓包
特别说明下,MySQL上抓到的不是跟Navicat上抓到的同一次报错,所以报错的端口等会不一样
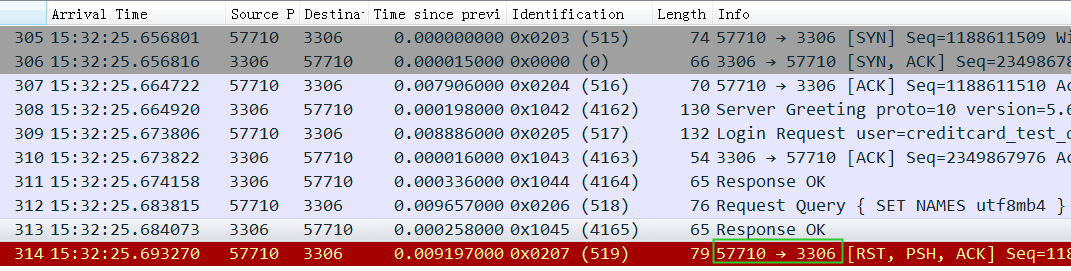
从这个图中可以清楚看到reset是从 Navicat 客户端发过来的,并且 Use Database被拦截了,没有发到MySQL上。
从这里基本可以判断是客户的防火墙之类的中间设备监控到了关键字之类的触发了防火墙向两边发送了reset,导致了 Navicat 报错。
如果连接已经断开
如果连接已经断开后还收到Client的请求包,因为连接在Server上是不存在的,这个时候Server收到这个包后也会发一个reset回去,这个reset的特点是identification是0.
到底是谁动了这个连接呢?
得帮客户解决问题
虽然原因很清楚,但是客户说连本地 MySQL就没这个问题,连你的云上MySQL就这样,你让我们怎么用?你们得帮我们找到是哪个设备。
这不废话么,连本地没经过这么多防火墙、网关当然没事了。但是客户第一,不能这么说,得找到问题所在。
Identification 和 TTL
线索一 Identification
还记得第一个截图中的两个相同的identification 13052吧,让我们来看看基础知识:

(摘自 TCP卷一),简单来说这个 identification 用来标识一个连接中的每个包,这个序号按包的个数依次递增,通信双方是两个不同的序列。主要是用于ip packet的reassemble。
所以如果这个reset是MySQL发出来的话,因为MySQL发出的前一个包的 identification 是23403,所以这个必须是23404,实际上居然是13502(而且还和Navicat发出的 Use Database包是同一个 identification),这是非常不对的。
所以可以大胆猜测,这里有个中间设备收到 Use Database后触发了不放行的逻辑,于是冒充 Navicat给 MySQL Server发了reset包,src ip/src port/seq等都直接用Navicat的,identification也用Navicat的,所以 MySQL Server收到的 Reset看起来很正常(啥都是对的,没留下一点冒充的痕迹)。
但是这个中间设备还要冒充MySQL Server给 Navicat 也发个reset,有点难为中间设备了,这个时候中间设备手里只有 Navicat 发出来的包, src ip/src port/seq 都比较好反过来,但是 identification 就不好糊弄了,手里只有 Navicat的,因为 Navicat和MySQL Server是两个序列的 identification,这下中间设备搞不出来MySQL Server的identification,怎么办? 只能糊弄了,就随手用 Navicat 自己的 identification填回去了(所以看到这么个奇怪的 identification)
identification不对不影响实际连接被reset,也就是验证包的时候不会判断identification的正确性。
TTL
identification基本撇清了MySQL的嫌疑,还得进一步找到是哪个机器,我们先来看一个基础知识 TTL(Time-to-Live):

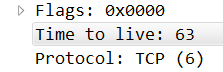
然后我们再看看 Navicat收到的这个reset包的ttl是63,而正常的MySQL Server回过来的包是47,而发出的第一个包初始ttl是64,所以这里可以很清楚地看到在Navicat 下一跳发出的这个reset
既然是下一跳干的直接拿这个包的src mac地址,然后到内网中找这个内网设备就可以了,最终找到是一个锐捷的防火墙。
如果不是下一跳可以通过 traceroute/mtr 来找到这个设备的ip
某家居的reset
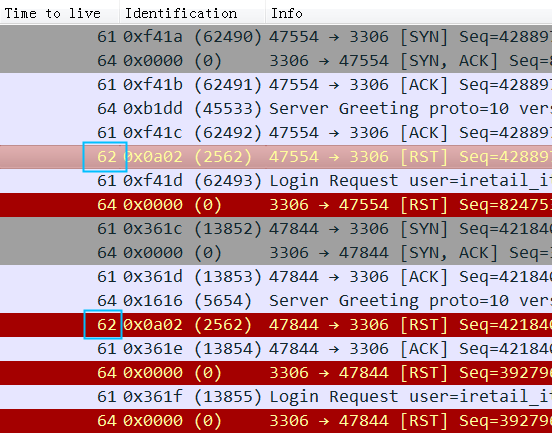
从图中可以清楚看到都是3306收到ttl为62的reset,正常ttl是61,所以推定reset来自client的下一跳上。
某ISV vpn环境reset
client通过公网到server有几十跳,偶尔会出现连接被reset。反复重现发现只要是: select * from table1 ; 就一定reset,但是select * from table1 limit 1 之有极低的概率会被reset,reset的概率跟查询结果的大小比较相关。
于是在server和client上同时抓到了一次完整的reset
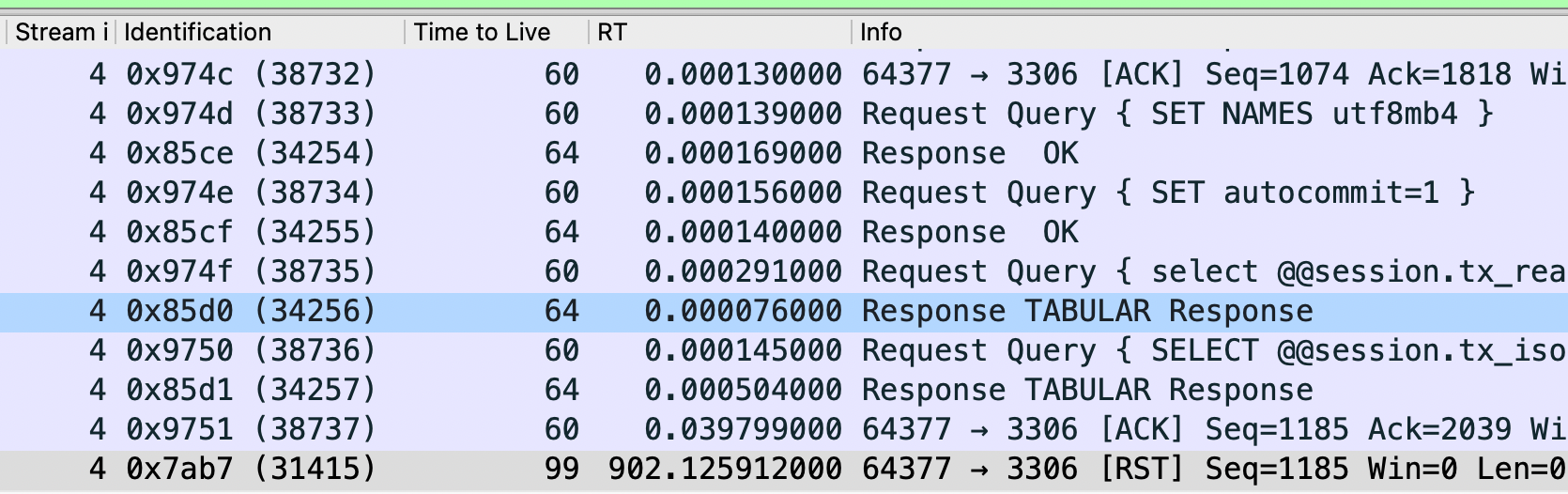
如下图红框 Server正常发出了一个大小为761的response包,id 51101,注意seq号,另外通过上下文知道server client之间的rt是15ms左右(15ms后 server收到了一个reset id为0)

下图是client收到的 id 51101号包,seq也正常,只是原来的response内容被替换成了reset,可以推断是中间环节检测到id 51101号包触发了某个条件,然后向server、client同时发出了reset,server收到的reset包是id 是0(伪造出来的),client收到的reset包还是51101,可以判断出是51101号包触发的reset,中间环节披着51101号包的外衣将response替换成了reset,这种双向reset基本是同时发出,从server和client的接收时间来看,这个中间环节挨着client,同时server收到的reset 的id是0,结合ttl等综合判断client侧的防火墙发出了这个reset

最终排查后client端
公司部分网络设置了一些拦截措施,然后现在把这次项目中涉及到的服务器添加到了白名单中,现在运行正常了
扩展一下
假如这里不是下一跳,而是隔了几跳发过来的reset,那么这个src mac地址就不是发reset设备的mac了,那该怎么办呢?
可以根据中间的跳数(TTL),再配合 traceroute 来找到这个设备的ip
SLB reset
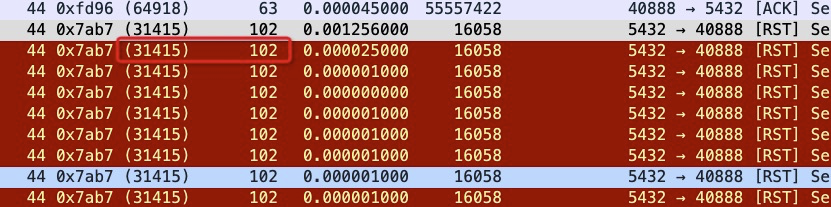
如果连接闲置15分钟(900秒)后,SLB会给两端发送reset,设置的ttl为102(102年,下图经过3跳后到达RS 节点所以看到的是99),identification 为31415(π)
被忽略的reset
不是收到reset就一定释放连接,OS还是会验证一下这个reset 包的有效性,主要是通过reset包的seq是否落在接收窗口内来验证,当然五元组一定要对。

但是对于SLB来说,收到reset就会clean 连接的session(SLB没做合法性验证),一般等session失效后(10秒)
SLB主动reset的话
ttl是102, identification是31415,探活reset不是这样的。
如下图就是SLB发出来的reset packet
总结
基础知识很重要,但是知道ttl、identification到会用ttl、identification是两个不同的层次。只是看书的话未必会有很深的印象,实际也不一定会灵活使用。
平时不要看那么多书,会用才是关键。