存储原理
存储原理
本文记录各种存储、接口等原理性东西

磁盘信息
Here are some common ones:
hdX— ATA hard disk, pre-libata. You’ll only see this with old distros (probably based on Linux 2.4.x or older)sdX— “SCSI” hard disk. Also includes SATA and SAS. And IDE disks using libata (on any recent distro).hdXY,sdXY— Partition on the hard diskhdXorsdX.loopX— Loopback device, used for mounting disk images, etc.loopXpY— Partitions on the loopback deviceloopX; used when mounting an image of a complete hard drive, etc.scdX,srX— “SCSI” CD, using same weird definition of “SCSI”. Also includes DVD, Blu-ray, etc.mdX— Linux MDraiddm-X— Device Mapper. Use-Nto see what these are, orls -l /dev/mapper. Device Mapper underlies LVM2 and dm-crypt. If you’re using either LVM or encrypted volumes, you’ll seedm-Xdevices.
回顾串行磁盘技术的发展历史,从光纤通道,到SATA,再到SAS,几种技术各有所长。光纤通道最早出现的串行化存储技术,可以满足高性能、高可靠和高扩展性的存储需要,但是价格居高不下;SATA硬盘成本倒是降下来了,但主要是用于近线存储和非关键性应用,毕竟在性能等方面差强人意;SAS应该算是个全才,可以支持SAS和SATA磁盘,很方便地满足不同性价比的存储需求,是具有高性能、高可靠和高扩展性的解决方案。
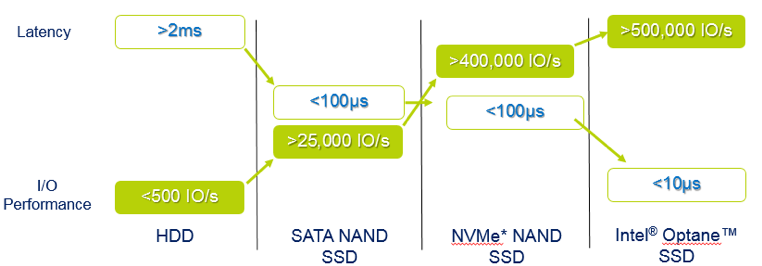
SSD中,SATA、m2、PCIE和NVME各有什么意义
高速信号协议
SAS,SATA,PCIe 这三个是同一个层面上的,模拟串行高速接口。
- SAS 对扩容比较友好,也支持双控双活。接上SAS RAID 卡,一般在阵列上用的比较多。
- SATA 对热插拔很友好,早先台式机装机市场的 SSD基本上都是SATA的,现在的 机械硬盘也是SATA接口居多。但速率上最高只能到 6Gb/s,上限 768MB/s左右,现在已经慢慢被pcie取代。
- PCIe 支持速率更高,也离CPU最近。很多设备 如 网卡,显卡也都走pcie接口,当然也有SSD。现在比较主流的是PCIe 3.0,8Gb/s 看起来好像也没比 SATA 高多少,但是 PCIe 支持多个LANE,每个LANE都是 8Gb/s,这样性能就倍数增加了。目前,SSD主流的是 PCIe 3.0x4 lane,性能可以做到 3500MB/s 左右。
传输层协议
SCSI,ATA,NVMe 都属于这一层。主要是定义命令集,数字逻辑层。
- SCSI 命令集 历史悠久,应用也很广泛。U盘,SAS 盘,还有手机上 UFS 之类很多设备都走的这个命令集。
- ATA 则只是跑在SATA 协议上
- NVMe 协议是有特意为 NAND 进行优化。相比于上面两者,效率更高。主要是跑在 PCIe 上的。当然,也有NVMe-MI,NVMe-of之类的。是个很好的传输层协议。
NVMe(Non-Volatile Memory Express)
NVMe其实与AHCI一样都是逻辑设备接口标准(是接口标准,并不是接口),NVMe全称Non-Volatile Memory Express,非易失性存储器标准,是使用PCI-E通道的SSD一种规范,NVMe的设计之初就有充分利用到PCI-E SSD的低延时以及并行性,还有当代处理器、平台与应用的并行性。SSD的并行性可以充分被主机的硬件与软件充分利用,相比与现在的AHCI标准,NVMe标准可以带来多方面的性能提升。
NVMe标准是面向PCI-E SSD的,使用原生PCI-E通道与CPU直连可以免去SATA与SAS接口的外置控制器(PCH)与CPU通信所带来的延时。而在软件层方面,NVMe标准的延时只有AHCI的一半不到,NVMe精简了调用方式,执行命令时不需要读取寄存器;而AHCI每条命令则需要读取4次寄存器,一共会消耗8000次CPU循环,从而造成大概2.5微秒的延迟。
NVMe标准和传统的SATA/SAS相比,一个重大的差别是引入了多队列机制。
主机与SSD进行数据交互采用“生产者-消费者”模型进行数据交互。在原有AHCI规范中,只定义了一个交互队列,主机与HDD之间的数据交互只能通过一个队列通信,多核处理器也只能通过一个队列与HDD进行数据交互。在传统磁盘存储时代,单队列在一个IO调度器,可以很好的保证提交请求的IO顺序最优化。
而NAND存储介质具有很高的性能,AHCI原有的规范不再适用,NVMe规范替代了原有的AHCI规范,在软件层面的处理命令也进行了重新定义,不再采用SCSI/ATA命令规范集。相比以前AHCI、SAS等协议规范,NVMe规范是一种非常简化,面向新型存储介质的协议规范。该规范将存储外设拉到了处理器局部总线上,性能大为提升。并且主机和SSD处理器之间采用多队列的设计,适应了多核的发展趋势,每个处理器核与SSD之间可以采用独立的硬件Queue Pair进行数据交互。
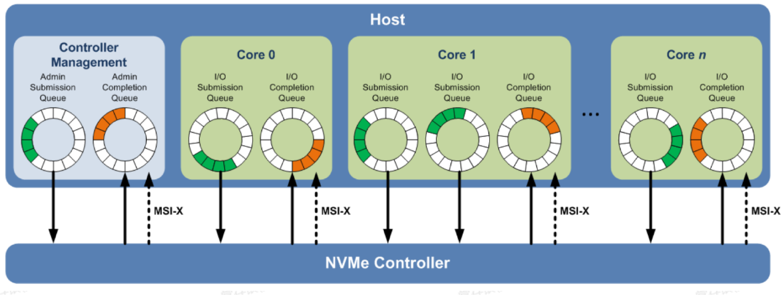
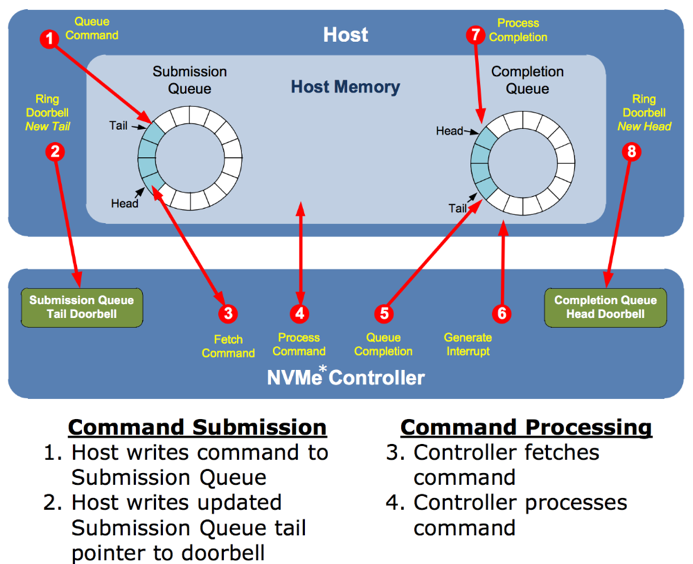
如上图从软件的角度来看,每个CPU Core都可以创建一对Queue Pair和SSD进行数据交互。Queue Pair由Submission Queue与Completion Queue构成,通过Submission queue发送数据;通过Completion queue接受完成事件。SSD硬件和主机驱动软件控制queue的Head与Tail指针完成双方的数据交互。
nvme多队列
物理接口
M.2 , U.2 , AIC, NGFF 这些属于物理接口
像 M.2 可以是 SATA SSD 也可以是 NVMe(PCIe) SSD。金手指上有一个 SATA/PCIe 的选择信号,来区分两者。很多笔记本的M.2 接口也是同时支持两种类型的盘的。
- M.2 , 主要用在 笔记本上,优点是体积小,缺点是散热不好。
- U.2,主要用在 数据中心或者一些企业级用户,对热插拔需求高的地方。优点热插拔,散热也不错。一般主要是pcie ssd(也有sas ssd),受限于接口,最多只能是 pcie 4lane
- AIC,企业,行业用户用的比较多。通常会支持pcie 4lane/8lane,带宽上限更高
SSD 的性能特性和机制
SSD 的内部工作方式和 HDD 大相径庭,我们先了解几个概念。
单元(Cell)、页面(Page)、块(Block)。
当今的主流 SSD 是基于 NAND 的,它将数字位存储在单元中。每个 SSD 单元可以存储一位或多位。对单元的每次擦除都会降低单元的寿命,所以单元只能承受一定数量的擦除。单元存储的位数越多,制造成本就越低,SSD 的容量也就越大,但是耐久性(擦除次数)也会降低。
一个页面包括很多单元,典型的页面大小是 4KB,页面也是要读写的最小存储单元。SSD 上没有“重写”操作,不像 HDD 可以直接对任何字节重写覆盖。一个页面一旦写入内容后就不能进行部分重写,必须和其它相邻页面一起被整体擦除重置。
多个页面组合成块。一个块(Block)的典型大小为 512KB 或 1MB,也就是大约 128 或 256 (Page–16KB)页。块是擦除的基本单位,每次擦除都是整个块内的所有页面都被重置。
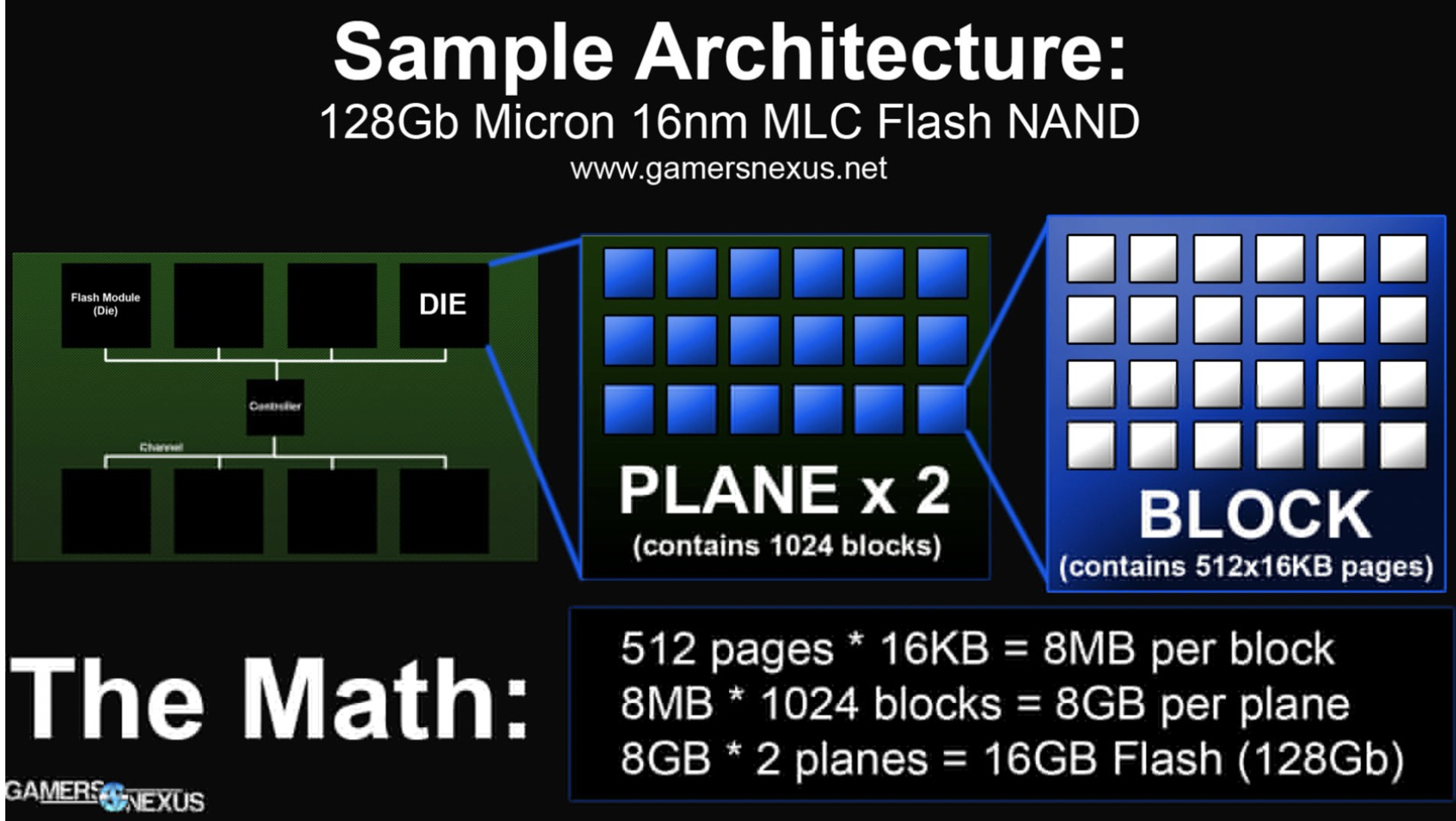
擦除速度相对很慢,通常为几毫秒。所以对同步的 IO,发出 IO 的应用程序可能会因为块的擦除,而经历很大的写入延迟。为了尽量地减少这样的场景,保持空闲块的阈值对于快速的写响应是很有必要的。SSD 的垃圾回收(GC)的目的就在于此。GC 可以回收用过的块,这样可以确保以后的页写入可以快速分配到一个全新的页。
SSD的基本结构:
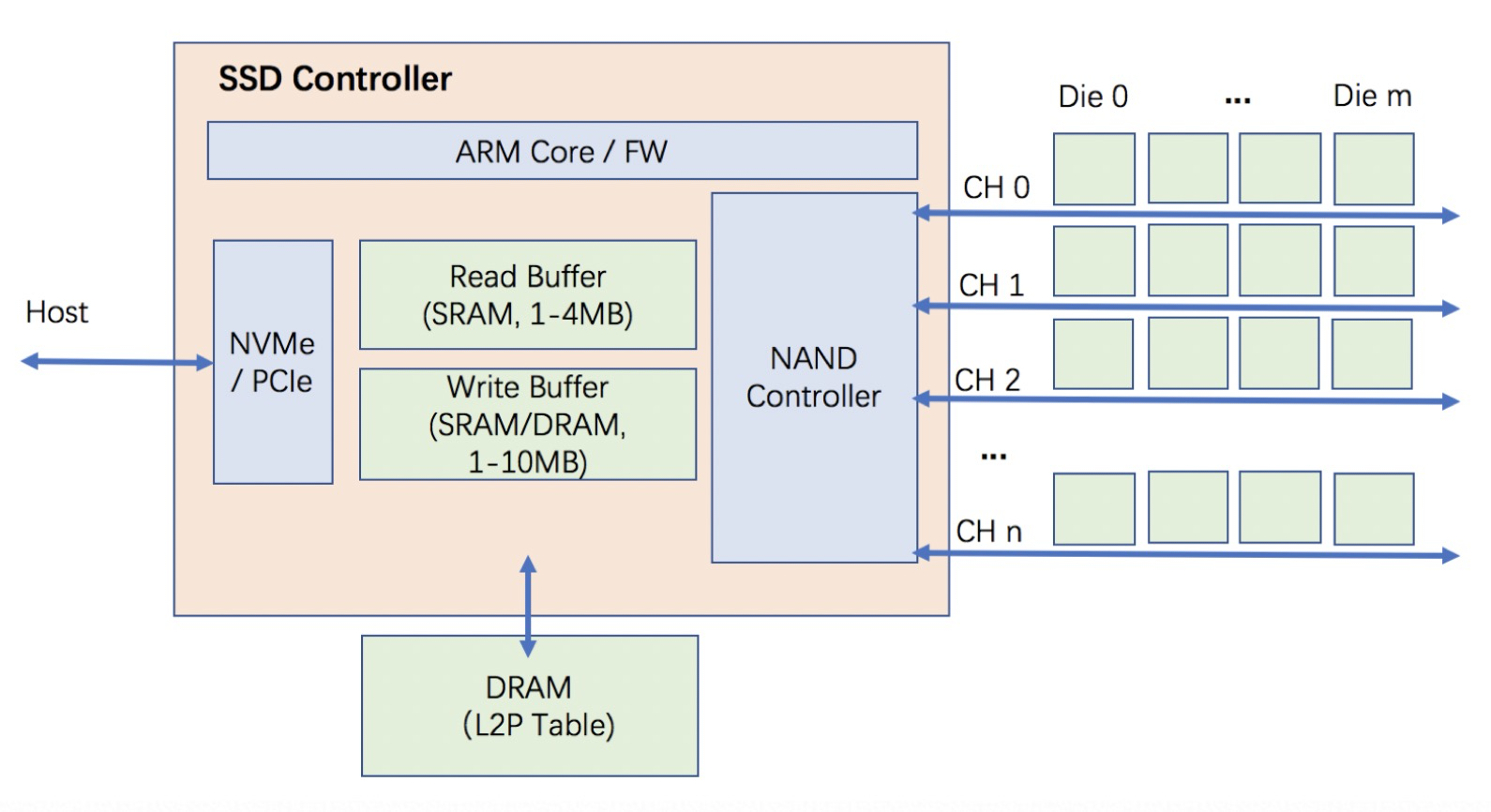
比如Intel P4510 SSD控制器内部集成了两个Cotex A15 ARM core,这两个CPU core各自处理50%物理地址空间的读写命令(不同CPU负责不同的Die,以提高并发度)。在处理IO命令的过程中,为了充分发挥两个cpu的并行处理效率,每个cpu core单次处理的最大数据块是128kB。所以P4510对于128k对齐(4k,8k,16k,32k,64k,128k)或者128k整数倍(256k,512k,1024k)的数据块的处理效率最高。因为这些数据块都能够在SSD内部被组装或者拆分为完整的128k数据块。但是,对于非128k对齐的数据块(68k,132k,260k,516k,1028k),由于每个提交给SSD的写命令都有一个非128k对齐的“尾巴”需要跨CPU来处理,这样便会导致SSD处理单个命令的效率下降,写带宽随之也下降。
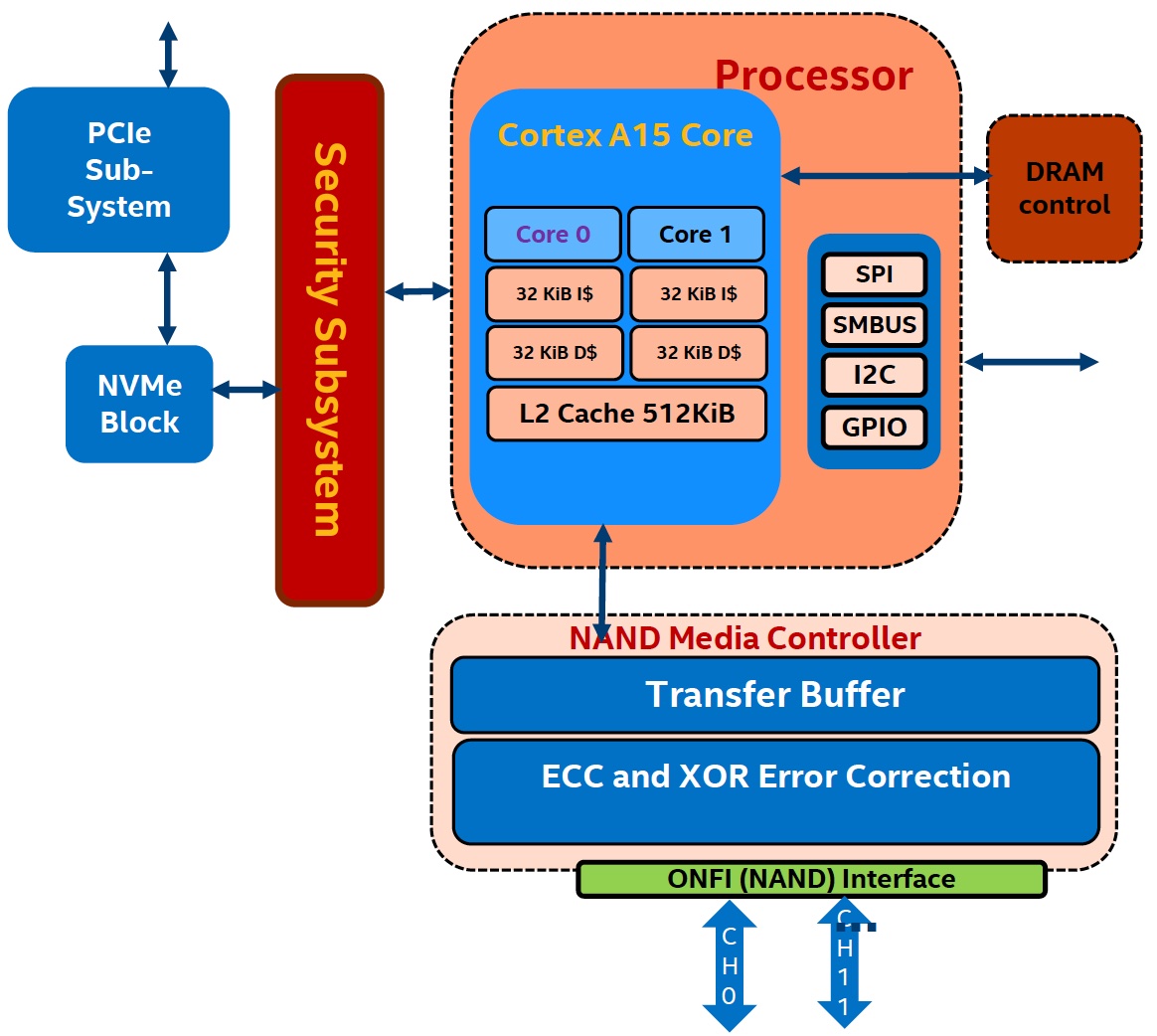
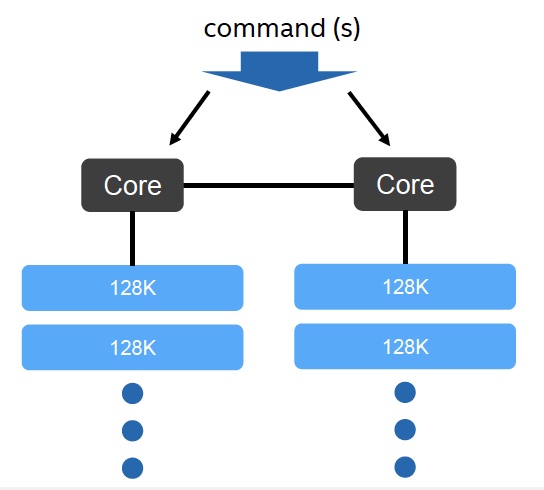
SSD内部使用写缓存。写缓存主要用来降低写延迟。当写请求发送给SSD时,写数据会被先保存在写缓存,此时SSD会直接发送确认消息通知主机端写请求已完成,实现最低的写延迟。SSD固件在后台会异步的定期把写缓存中的数据通过写操作命令刷回给NAND颗粒。为了满足写操作的持久化语义,SSD内有大容量电容保证写缓存中数据的安全。当紧急断电情况发生时,固件会及时把写缓存中的数据写回NAND颗粒. 也就是紧急断电后还能通过大电容供电来维持最后的落盘。
SSD内嵌内存容量的问题也限制了大容量NVMe SSD的发展,为了解决内存问题,目前一种可行的方法是增大sector size。标准NVMe SSD的sector size为4KB,为了进一步增大NVMe SSD的容量,有些厂商已经开始采用16KB的sector size。16KB Sector size的普及应用,会加速大容量NVMe SSD的推广。
以海康威视E200P为例,PCB上的硬件PLP掉电保护电路从D200Pro的10个钽电容+6个电感,简化为6个钽电容+6个电感。钽电容来自Panasonic,单颗47uF,6个钽电容并联可以为SSD提供几十毫秒的放电时间,让SSD把处理中的数据写入NAND中并更新映射表。这样的硬件PLP电路对比普通的家用产品要强悍很多。

或者如下结构:

SSD存储持久化原理
记录一个比特很容易理解。给电容里面充上电有电压的时候就是 1,给电容放电里面没有电就是 0。采用这样方式存储数据的 SSD 硬盘,我们一般称之为使用了 SLC 的颗粒,全称是 Single-Level Cell,也就是一个存储单元中只有一位数据。
但是,这样的方式会遇到和 CPU Cache 类似的问题,那就是,同样的面积下,能够存放下的元器件是有限的。如果只用 SLC,我们就会遇到,存储容量上不去,并且价格下不来的问题。于是呢,硬件工程师们就陆续发明了 MLC(Multi-Level Cell)、TLC(Triple-Level Cell)以及 QLC(Quad-Level Cell),也就是能在一个电容里面存下 2 个、3 个乃至 4 个比特。
只有一个电容,我们怎么能够表示更多的比特呢?别忘了,这里我们还有一个电压计。4 个比特一共可以从 0000-1111 表示 16 个不同的数。那么,如果我们能往电容里面充电的时候,充上 15 个不同的电压,并且我们电压计能够区分出这 15 个不同的电压。加上电容被放空代表的 0,就能够代表从 0000-1111 这样 4 个比特了。
不过,要想表示 15 个不同的电压,充电和读取的时候,对于精度的要求就会更高。这会导致充电和读取的时候都更慢,所以 QLC 的 SSD 的读写速度,要比 SLC 的慢上好几倍。
SSD对碎片很敏感,类似JVM的内存碎片需要整理,碎片整理就带来了写入放大。也就是写入空间不够的时候需要先进行碎片整理、搬运,这样写入的数据更大了。
SSD寿命:以Intel 335为例再来算一下,BT用户可以用600TB × 1024 / 843 = 728天,普通用户可以用600TB/2 = 300年!情况十分乐观
两种逻辑门
NAND(NOT-AND) gate
NOR(NOT-OR) gate
如上两种门实现的介质都是非易失存储介质,在写入前都需要擦除。实际上NOR Flash的一个bit可以从1变成0,而要从0变1就要擦除整块。NAND flash都需要擦除。
| NAND Flash | NOR Flash | |
|---|---|---|
| 芯片容量 | <32GBit | <1GBit |
| 访问方式 | 块读写(顺序读写) | 随机读写 |
| 接口方式 | 任意I/O口 | 特定完整存储器接口 |
| 读写性能 | 读取快(顺序读) 写入快 擦除快(可按块擦除) | 读取快(RAM方式) 写入慢 檫除很慢 |
| 使用寿命 | 百万次 | 十万次 |
| 价格 | 低廉 | 高昂 |
NAND Flash更适合在各类需要大数据的设备中使用,如U盘、SSD、各种存储卡、MP3播放器等,而NOR Flash更适合用在高性能的工业产品中。
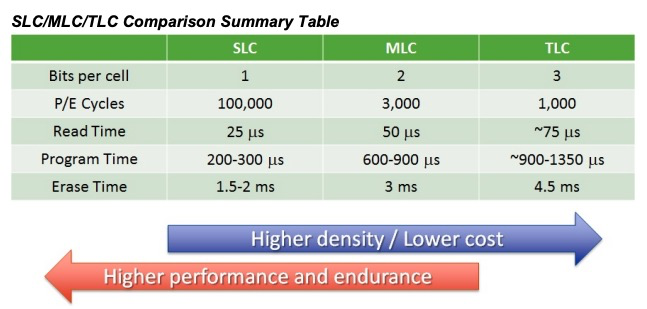
高端SSD会选取MLC(Multi-Level Cell)甚至SLC(Single-Level Cell),低端SSD则选取 TLC(Triple-Level Cell)。SD卡一般选取 TLC(Triple-Level Cell)
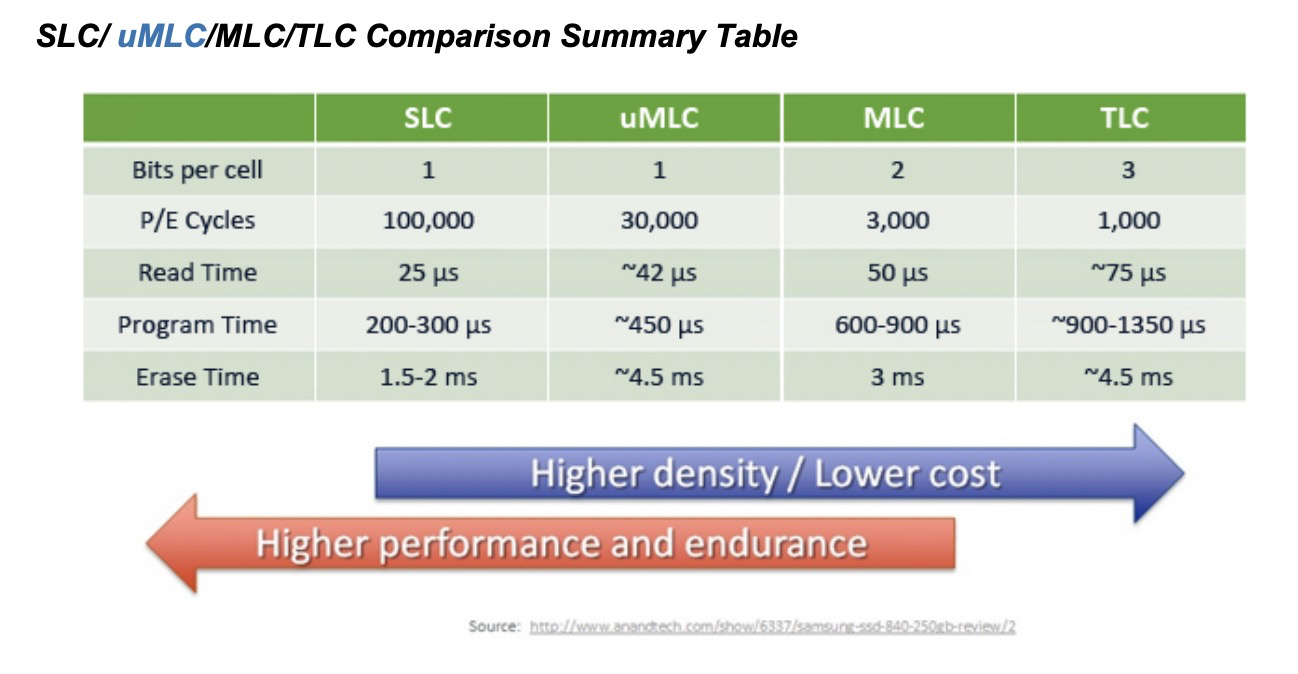

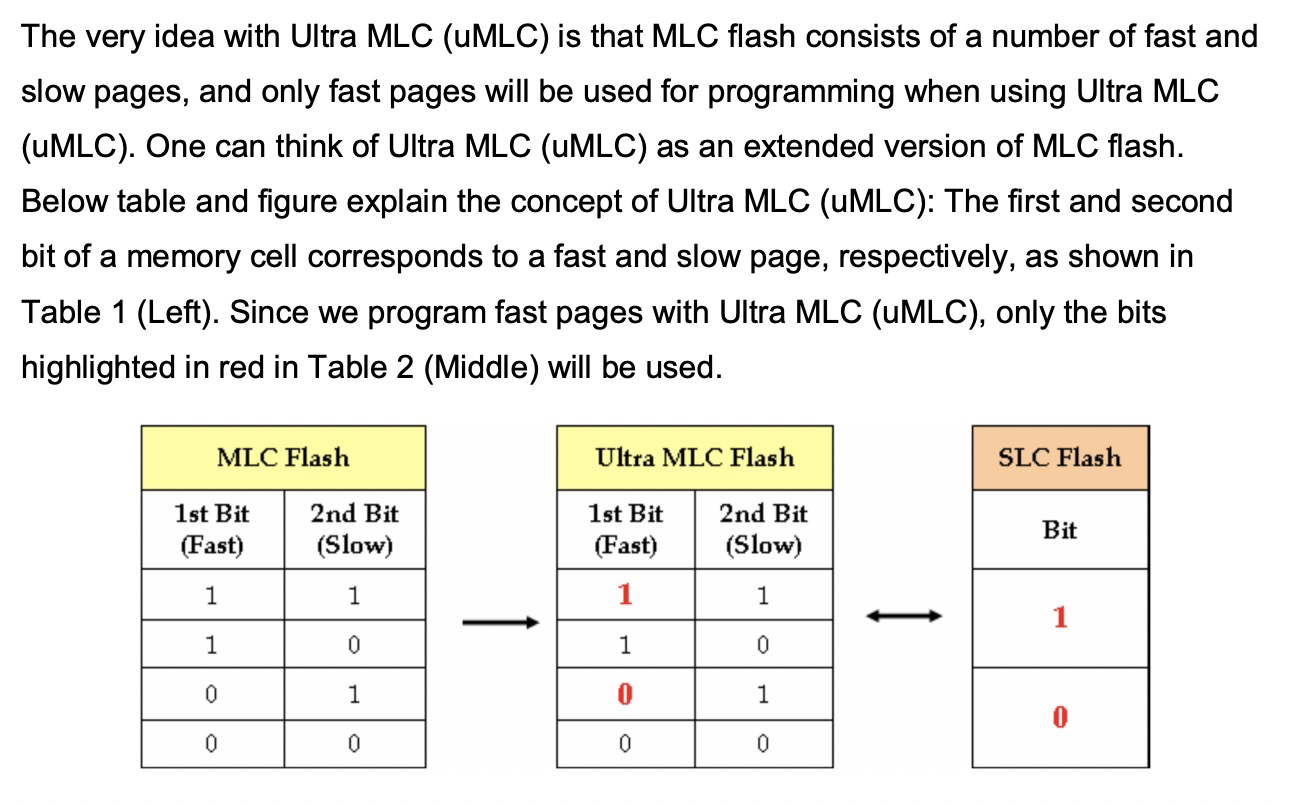
umlc
NOR FLash主要用于:Bios、机顶盒,大小一般是1-32MB
对于TLC NAND (每个NAND cell存储3 bits的信息),下面列出了每种操作的典型耗时的范围:
读操作(Tread) : 50-100us,
写操作(Tprog) : 500us-5ms,
擦除操作(Terase) : 2-10ms。
为什么断电后SSD不丢数据
SSD的存储硬件都是NAND Flash。实现原理和通过改变电压,让电子进入绝缘层的浮栅(Floating Gate)内。断电之后,电子仍然在FG里面。但是如果长时间不通电,比如几年,仍然可能会丢数据。所以换句话说,SSD的确也不适合作为冷数据备份。比如标准要求SSD:温度在30度的情况下,数据要能保持52周。
写入放大(Write Amplification, or WA)
这是 SSD 相对于 HDD 的一个缺点,即实际写入 SSD 的物理数据量,有可能是应用层写入数据量的多倍。一方面,页级别的写入需要移动已有的数据来腾空页面。另一方面,GC 的操作也会移动用户数据来进行块级别的擦除。所以对 SSD 真正的写操作的数据可能比实际写的数据量大,这就是写入放大。一块 SSD 只能进行有限的擦除次数,也称为编程 / 擦除(P/E)周期,所以写入放大效用会缩短 SSD 的寿命。
SSD 的读取和写入的基本单位,不是一个比特(bit)或者一个字节(byte),而是一个页(Page)。SSD 的擦除单位就更夸张了,我们不仅不能按照比特或者字节来擦除,连按照页来擦除都不行,我们必须按照块来擦除。
SLC 的芯片,可以擦除的次数大概在 10 万次,MLC 就在 1 万次左右,而 TLC 和 QLC 就只在几千次了。这也是为什么,你去购买 SSD 硬盘,会看到同样的容量的价格差别很大,因为它们的芯片颗粒和寿命完全不一样。
从本质上讲,NAND Flash是一种不可靠介质,非常容易出现Bit翻转问题。SSD通过控制器和固件程序将这种不可靠的NAND Flash变成了可靠的数据存储介质。
为了在这种不可靠介质上构建可靠存储,SSD内部做了大量工作。在硬件层面,需要通过ECC单元解决经常出现的比特翻转问题。每次数据存储的时候,硬件单元需要为存储的数据计算ECC校验码;在数据读取的时候,硬件单元会根据校验码恢复被破坏的bit数据。ECC硬件单元集成在SSD控制器内部,代表了SSD控制器的能力。在MLC存储时代,BCH编解码技术可以解决问题,4KB数据中存在100bit翻转时可以纠正错误;在TLC存储时代,bit错误率大为提升,需要采用更高纠错能力的LDPC编解码技术,在4KB出现550bit翻转时,LDPC硬解码仍然可以恢复数据。对比LDPC硬解码、BCH以及LDPC软解码之间的能力,可以看出LDPC软解码具有更强的纠错能力,通常使用在硬解码失效的情况下。LDPC软解码的不足之处在于增加了IO的延迟。
在软件层面,SSD内部设计了FTL(Flash Translation Layer),该软件层的设计思想和Log-Structured File System设计思想类似。采用log追加写的方式记录数据,采用LBA至PBA的地址映射表记录数据组织方式。Log-structured系统最大的一个问题就是垃圾回收(GC)。因此,虽然NAND Flash本身具有很高的IO性能,但受限于GC的影响,SSD层面的性能会大受影响,并且存在十分严重的IO QoS问题,这也是目前标准NVMe SSD一个很重要的问题。
耗损平衡 (Wear Leveling)
对每一个块而言,一旦达到最大数量,该块就会死亡。对于 SLC 块,P/E 周期的典型数目是十万次;对于 MLC 块,P/E 周期的数目是一万;而对于 TLC 块,则可能是几千。为了确保 SSD 的容量和性能,我们需要在擦除次数上保持平衡,SSD 控制器具有这种“耗损平衡”机制可以实现这一目标。在损耗平衡期间,数据在各个块之间移动,以实现均衡的损耗,这种机制也会对前面讲的写入放大推波助澜。
non-volatile memory (NVM)
NVM是一种新型的硬件存储介质,同时具备磁盘和DRAM的一些特性。突出的NVM技术产品有:PC-RAM、STT-RAM和R-RAM。因为NVM具有设备层次上的持久性,所以不需要向DRAM一样的刷新周期以维持数据状态。因此NVM和DRAM相比,每bit耗费的能量更少。另外,NVM比硬盘有更小的延迟,读延迟甚至和DRAM相当;字节寻址;比DRAM密度更大。
1、NVM特性
数据访问延迟:NVM的读延迟比磁盘小很多。由于NVM仍处于开发阶段,来源不同延迟不同。STT-RAM的延迟1-20ns。尽管如此,他的延迟也已经非常接近DRAM了。
PC_RAM 和R-RAM的写延迟比DRAM高。但是写延迟不是很重要,因为可以通过buffer来缓解。
密度:NVM的密度比DRAM高,可以作为主存的替代品,尤其是在嵌入式系统中。例如,相对于DRAM,PC-RAM提供2到4倍的容量,便于扩展。
耐久性:即每个内存单元写的最大次数。最具竞争性的是PC-RAM和STT-RAM,提供接近DRAM的耐久性。更精确的说,NVM的耐久性是1015而DRAM是1016。另外,NVM比闪存技术的耐久性更大。
能量消耗:NVM不需要像DRAM一样周期性刷写以维护内存中数据,所以消耗的能量更少。PC-RAM比DRAM消耗能量显著的少,其他比较接近。
此外,还有字节寻址、持久性。Interl和Micron已经发起了3D XPoint技术,同时Interl开发了新的指令以支持持久内存的使用。
傲腾 PMem
Optane 的工作原理与 NAND Flash 有很大区别,NAND Flash 是基于 Floating-gate MOSFET 而 Optane 虽然因特尔没有官方资料说明但是根据国外机构用质谱法 测试的结果表明 Optane 是一种基于 PCM (相变化存储器) 原理的存储器,PCM 简单来说就是某种物质目前主要是一种或多种硫族化物的玻璃,经由加热可以改变它的状态,成为晶体或者非晶体,这些不同的状态具有相应的电阻值。
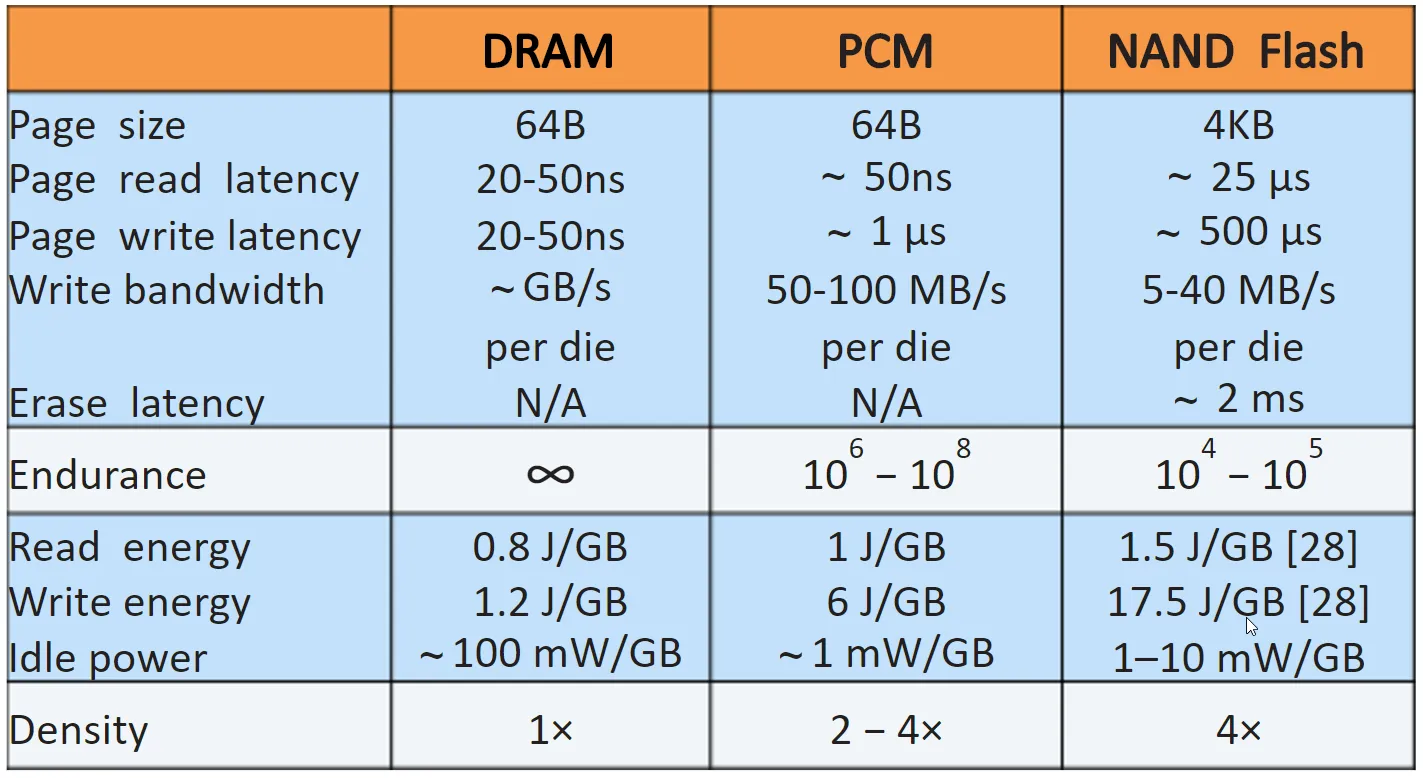
从以上数据来看 PCM 读接近 DRAM,比 NAND Flash 快了500倍,PCM 写比 DRAM 慢了20倍,但是仍然比 NAND Flash 快了500倍。DRAM 读写速度一致,PCM 和 NAND Flash 写都比读要慢20倍。
磁盘类型查看
1 | $cat /sys/block/vda/queue/rotational |
fio 结果解读
slat,异步场景下才有
其中slat指的是发起IO的时间,在异步IO模式下,发起IO以后,IO会异步完成。例如调用一个异步的write,虽然write返回成功了,但是IO还未完成,slat约等于发起write的耗时;
slat (usec): min=4, max=6154, avg=48.82, stdev=56.38: The first latency metric you’ll see is the ‘slat’ or submission latency. It is pretty much what it sounds like, meaning “how long did it take to submit this IO to the kernel for processing?”
clat
clat指的是完成时间,从发起IO后到完成IO的时间,在同步IO模式下,clat是指整个写动作完成时间
lat
lat是总延迟时间,指的是IO单元创建到完成的总时间,通常这项数据关注较多。同步场景几乎等于clat,异步场景等于clat+slat
这项数据需要关注的是max,看看有没有极端的高延迟IO;另外还需要关注stdev,这项数据越大说明,IO响应时间波动越大,反之越小,波动越小
clat percentiles (usec):处于某个百分位的io操作时延
cpu : usr=9.11%, sys=57.07%, ctx=762410, majf=0, minf=1769 //用户和系统的CPU占用时间百分比,线程切换次数,major以及minor页面错误的数量。
SSD的direct和buffered似乎很奇怪,应该是direct=0性能更好,实际不是这样,这里还需要找资料求证下
direct``=boolIf value is true, use non-buffered I/O. This is usually O_DIRECT. Note that OpenBSD and ZFS on Solaris don’t support direct I/O. On Windows the synchronous ioengines don’t support direct I/O. Default: false.
buffered``=boolIf value is true, use buffered I/O. This is the opposite of the
directoption. Defaults to true.
iostat 结果解读
Dm-0就是lvm
1 | avg-cpu: %user %nice %system %iowait %steal %idle |
avgqu_sz,是iostat的一项比较重要的数据。如果队列过长,则表示有大量IO在处理或等待,但是这还不足以说明后端的存储系统达到了处理极限。例如后端存储的并发能力是4096,客户端并发发送了256个IO下去,那么队列长度就是256。即使长时间队列长度是256,也不能说明什么,仅仅表明队列长度是256,有256个IO在处理或者排队。
那么怎么判断IO是在调度队列排队等待,还是在设备上处理呢?iostat有两项数据可以给出一个大致的判断。svctime,这项数据的指的是IO在设备处理中耗费的时间。另外一项数据await,指的是IO从排队到完成的时间,包括了svctime和排队等待的时间。那么通过对比这两项数据,如果两项数据差不多,则说明IO基本没有排队等待,耗费的时间都是设备处理。如果await远大于svctime,则说明有大量的IO在排队,并没有发送给设备处理。
rq_affinity
参考aliyun测试文档 , rq_affinity增加2的commit: git show 5757a6d76c
1 | function RunFio |
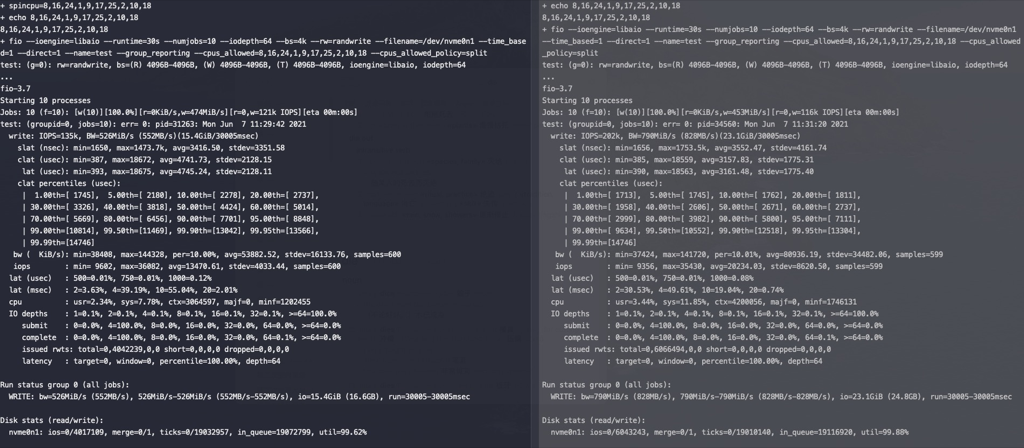
对NVME SSD进行测试,左边rq_affinity是2,右边rq_affinity为1,在这个测试参数下rq_affinity为1的性能要好(后许多次测试两者性能差不多)
参考资料
http://cizixs.com/2017/01/03/how-slow-is-disk-and-network
https://tobert.github.io/post/2014-04-17-fio-output-explained.html