程序员如何学习和构建网络知识体系
程序员如何学习和构建网络知识体系
大家学习网络知识的过程中经常发现当时看懂了,很快又忘了,最典型的比如TCP三次握手、为什么要握手,大家基本都看过,但是种感觉还差那么一点点。都要看是因为面试官总要问,所以不能不知道啊。
我们来看一个典型的面试问题:
问:为什么TCP是可靠的?
答:因为TCP有连接(或者回答因为TCP有握手)追问:为什么有连接就可靠了?(面试的人估计心里在骂,你这不是傻逼么,有连接就可靠啊)
追问:这个TCP连接的本质是什么?网络上给你保留了一个带宽所以能可靠?
答:……懵了(或者因为TCP有ack,所以可靠)追问:握手的本质是什么?为什么握手就可靠了
答:因为握手需要ack
追问:那这个ack也只是保证握手可靠,握手是怎么保证后面可靠的?握手本质做了什么事情?追问:有了ack可靠后还会带来什么问题(比如发一个包ack一下,肯定是可行的,但是效率不行,面试官想知道的是这里TCP怎么传输的,从而引出各个buffer、拥塞窗口的概念)
基本上我发现99%的程序员会回答TCP相对UDP是可靠的,70%以上的程序员会告诉你可靠是因为有ack(其他的会告诉你可靠是因为握手或者有连接),再追问下次就开始王顾左右而言他、胡言乱语。
我的理解:
物理上没有一个连接的东西在这里,udp也类似会占用端口、ip,但是大家都没说过udp的连接。而本质上我们说tcp的握手是指tcp是协商和维护一些状态信息的,这个状态信息就包含seq、ack、窗口/buffer,tcp握手就是协商出来这些初始值。这些状态才是我们平时所说的tcp连接的本质。
这说明大部分程序员对问题的本质的理解上出了问题,或者教科书描述的过于教条不够接地气所以看完书本质没get到。
想想 费曼学习方法 中对事物本质的理解的重要性。
## 重点掌握如下两篇文章
一个网络包是如何到达目的地的 – 这篇可以帮你掌握网络如何运转,在本机上从端口、ip、mac地址如何一层层封上去,链路上每一个点拆开mac看看,拆看ip看看,然后替换mac地址继续扔到链路的下一跳,这样一跳跳到达目的。
对BDP、Buffer、各种窗口、rt的理解和运用 这一篇可以让你入门TCP
以上两篇都是站在程序员的角度来剖析关于网络我们应该掌握哪些,也许第一篇有点像网工要掌握的,实际我不这么认为,目前很流行的微服务化、云原生对网络的要求更高了,大多时候需要程序员去掌握这些,也就是在网络包从你的网卡离开你才有资格呼叫网工,否则成本很高!
我本周还碰到了网络不通的问题
我的测试机器不能连外网(公司安全策略)
走流程申请开通,开通后会在测试机器安装客户端以及安全配置文件
但仍然不通,客户端自检都能通
我的排查就是第一篇文章:ping 公网ip;ip route get 公网-ip;ping 网关;
很快就发现是路由的问题,公网ip正好命中了docker 容器添加的某个路由,以及默认路由缺失
如果我自己不会那就开工单、描述问题、call各种人、申请权限……
我碰到的程序员一看到网络连接异常就吓尿了,不关我的事,网络不通,但是在call人前你至少可以做:
- ping ip 通不通(也有个别禁掉了icmp)
- telnet ip port通不通
- 网络包发出去没有(抓包)
- 是不是都不通还是只有你的机器不通
来看一个案例
我第一次看RFC1180的时候是震惊的,觉得讲述的太好了,2000字就把一本教科书的知识阐述的无比清晰、透彻。但是实际上我发现很快就忘了,而且大部分程序员基本都是这样
RFC1180写的确实很好,清晰简洁,图文并茂,结构逻辑合理,但是对于95%的程序员没有什么用,当时看的时候很爽、也觉得自己理解了、学会了,实际上看完几周后就忘得差不多了。问题出在这种RFC偏理论多一点看起来完全没有体感无法感同身受,所以即使似乎当时看懂了,但是忘得也快,需要一篇结合实践的文章来帮助理解
在这个问题上,让我深刻地理解到:
一流的人看RFC就够了,差一些的人看《TCP/IP卷1》,再差些的人要看一个个案例带出来的具体知识的书籍了,比如《wireshark抓包艺术》,人和人的学习能力有差别必须要承认。
也就是我们要认识到每个个人的学习能力的差异,我超级认同这篇文章中的一个评论
看完深有感触,尤其是后面的知识效率和工程效率型的区别。以前总是很中二的觉得自己看一遍就理解记住了,结果一次次失败又怀疑自己的智商是不是有问题,其实就是把自己当作知识效率型来用了。一个不太恰当的形容就是,有颗公主心却没公主命!
嗯,大部分时候我们都觉得自己看一遍就理解了记住了能实用解决问题了,实际上了是马上忘了,停下来想想自己是不是这样的?在网络的相关知识上大部分看RFC、TCP卷1等东西是很难实际理解的,还是要靠实践来建立对知识的具体的理解,而网络相关的东西基本离大家有点远(大家不回去读tcp、ip源码,纯粹是靠对书本的理解),所以很难建立具体的概念,所以这里有个必杀技就是学会抓包和用wireshark看包,同时针对实际碰到的文题来抓包、看包分析。
比如这篇《从计算机知识到落地能力,你欠缺了什么?》就对上述问题最好的阐述,程序员最常碰到的网络问题就是网络为啥不通?
这是最好建立对网络知识具体理解和实践的机会,你把《从计算机知识到落地能力,你欠缺了什么?》实践完再去看RFC1180 就明白了。通过案例把RFC1180抽象的描述给它具体化、场景化了,理解起来就很轻松不容易忘记了。
经验一: 通过具体的东西(案例、抓包)来建立对网络基础的理解

不要追求知识的广度
学习网络知识过程中,不建议每个知识点都去看,因为很快会忘记,我的方法是只看经常碰到的问题点,碰到一个点把他学透理解明白。
比如我曾经碰到过 nslookup OK but ping fail–看看老司机是如何解决问题的,解决问题的方法肯定比知识点重要多了,同时透过一个问题怎么样通篇来理解一大块知识,让这块原理真正在你的知识体系中扎根下来 , 这个问题Google上很多人在搜索,说明很普遍,但是没找到有资料能把这个问题说清楚,所以借着这个机会就把 Linux下的 NSS(name service switch)的原理搞懂了。要不然碰到问题老司机告诉你改下 /etc/hosts 或者 /etc/nsswitch 或者 /etc/resolv.conf 之类的问题就能解决,但是你一直不知道这三个文件怎么起作用的,也就是你碰到过这种问题也解决过但是下次碰到类似的问题你不一定能解决。
当然对我来说为了解决这个问题最后写了4篇跟域名解析相关的文章,从windows到linux,涉及到vpn、glibc、docker等各种场景,我把他叫做场景驱动。后来换来工作环境从windows换到mac后又补了一篇mac下的路由、dns文章。
TCP是最复杂的,要从实用出发
比如拥塞算法基本大家不会用到,了解下就行,你想想你有碰到过因为拥塞算法导致的问题吗?极少是吧。还有拥塞窗口、慢启动,这个实际中碰到的概率不高,面试要问你基本上是属于炫技类型。
实际碰到更多的是传输效率(对BDP、Buffer、各种窗口、rt的理解和运用),还有为什么连不通、连接建立不起来、为什么收到包不回复、为什么要reset、为什么丢包了之类的问题。
关于为什么连不通,我碰到了这个问题,随后在这个问题的基础上进行了总结,得到客户端建连接的时候抛异常,可能的原因(握手失败,建不上连接):
- 网络不通,诊断:ping ip
- 端口不通, 诊断:telnet ip port
- rp_filter 命中(rp_filter=1, 多网卡环境), 诊断: netstat -s | grep -i filter
- 防火墙、命中iptables 被扔掉了,可以试试22端口起sshd 能否正常访问,能的话说明是端口被干了
- snat/dnat的时候宿主机port冲突,内核会扔掉 syn包。诊断: sudo conntrack -S | grep insert_failed //有不为0的
- Firewalld 或者 iptables
- 全连接队列满的情况,诊断: netstat -s | egrep “listen|LISTEN”
- syn flood攻击, 诊断:同上
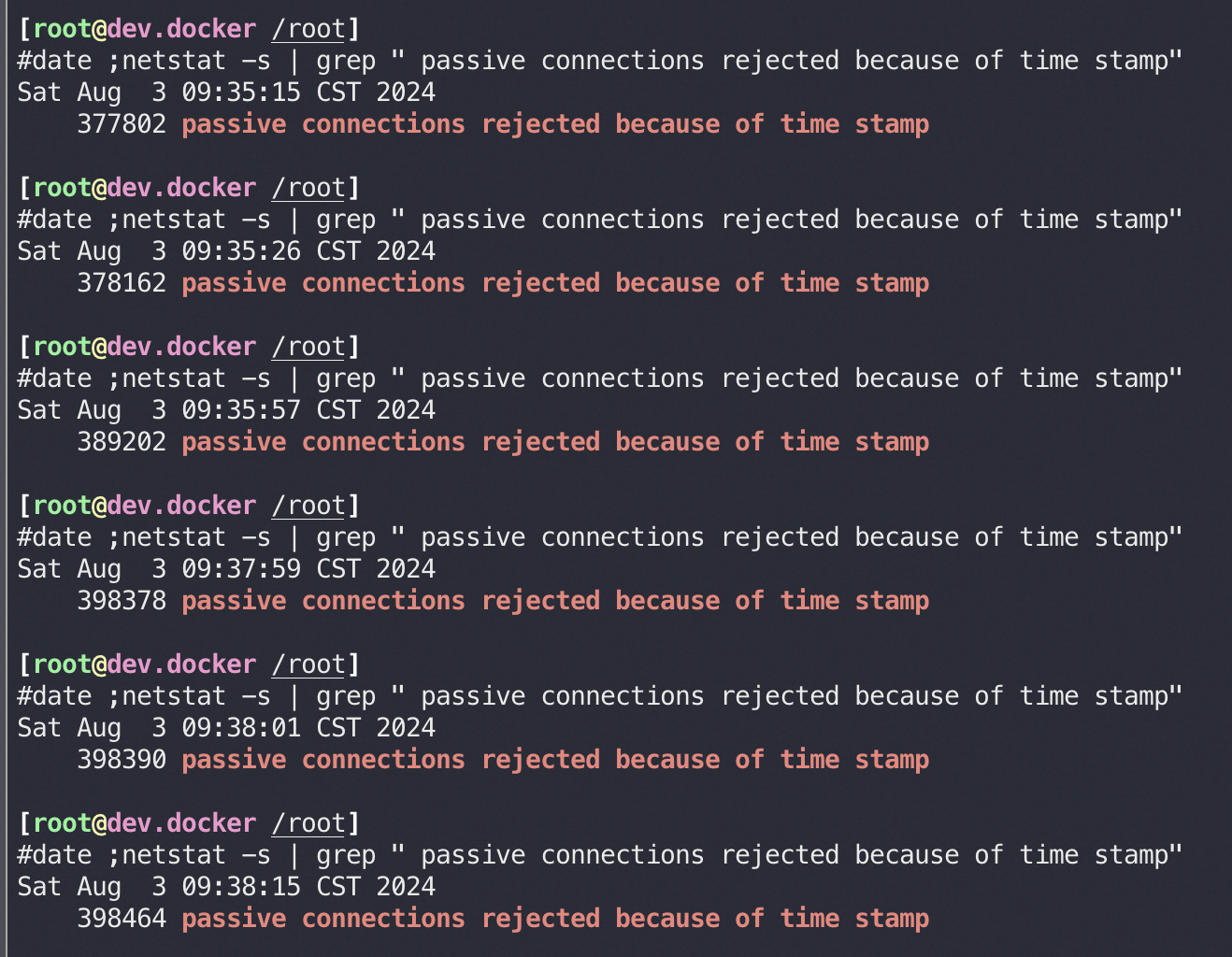
- 服务端的内核参数 net.ipv4.tcp_tw_recycle(4.12内核删除这个参数了) 和 net.ipv4.tcp_timestamps 的值都为 1时,服务器会检查每一个 SYN报文中的时间戳(Timestamp,跟同一ip下最近一次 FIN包时间对比),若 Timestamp 不是递增的关系,就扔掉这个SYN包(诊断:netstat -s | grep “ passive connections rejected because of time stamp”),常见触发时间戳非递增场景:
- 4.10 内核,一直必现大概率性丢包。4.11 改成了 per-destination host的算法
- tcpping 这种时间戳按连接随机的,必现大概率持续丢包
- 同一个客户端通过直连或者 DNAT 后两条链路到同一个服务端,客户端生成时间戳是 by dst ip,导致大概率持续丢包
- 经过NAT/LVS 后多个客户端被当成一个客户端,小概率偶尔出现
- 网路链路复杂/链路长容易导致包乱序,进而出发丢包,取决于网络会小概率出现——通过 tc qdisc 可以来构造丢包重现该场景
- 客户端修改 net.ipv4.tcp_timestamps
- 1->0,触发持续60秒大概率必现的丢包,60秒后恢复
- 0->1 持续大概率一直丢包60秒; 60秒过后如果网络延时略高且客户端并发大一直有上一次 FIN 时间戳大于后续SYN 会一直概率性丢包持续下去;如果停掉所有流量,重启客户端流量,恢复正常
- 2->1 丢包,情况同2
- 1->2 不触发丢包
- 若服务器所用端口是 time_wait 状态,这时新连接刚好和 time_wait 5元组重复,一般服务器不会回复syn+ack 而是回复time_wait 前的ack
- NAT 哈希表满导致 ECS 实例丢包 nf_conntrack full, 诊断: dmesg |grep conntrack
为什么 drop SYN 包时不去看四元组?因为tiem_wait 状态是 per-host
0->1 60秒后仍然持续丢包:
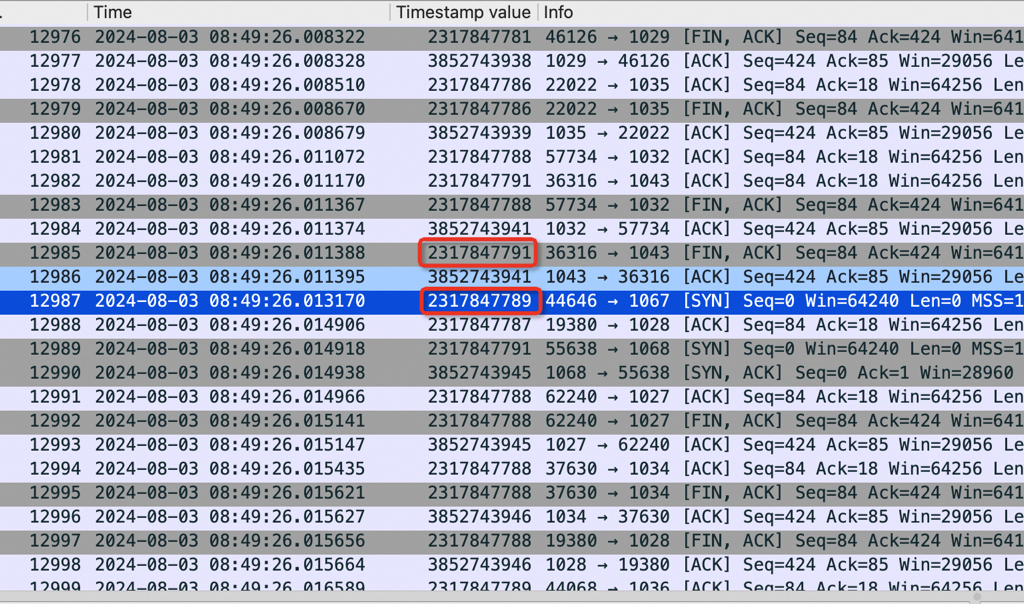
2->1 60秒后持续丢包:(非常神奇:在310客户端改不影响自己,导致510客户端(网络延时大)一直丢包,直到510 客户端重启流量才能恢复)
tcp_reuse 参数只对客户端有效(客户端是指主动发起 fin 的一方),启用后会回收超过 1 秒的 time_wait 状态端口重复使用:参考:https://ata.atatech.org/articles/11020082442
如果服务端是Time_wait 状态时收到 SYN 包怎么办?
https://developer.aliyun.com/article/1262180
tcp connect 的流程是这样的:
1、tcp发出SYN建链报文后,报文到ip层需要进行路由查询
2、路由查询完成后,报文到arp层查询下一跳mac地址
3、如果本地没有对应网关的arp缓存,就需要缓存住这个报文,发起arp请求
4、arp层收到arp回应报文之后,从缓存中取出SYN报文,完成mac头填写并发送给驱动。
问题在于,arp层报文缓存队列长度默认为3。如果你运气不好,刚好赶上缓存已满,这个报文就会被丢弃。
TCP层发现SYN报文发出去3s(1s+2s)还没有回应,就会重发一个SYN。这就是为什么少数连接会3s后才能建链。
幸运的是,arp层缓存队列长度是可配置的,用 sysctl -a | grep unres_qlen 就能看到,默认值为3
Time_Wait
socket.close 默认是四次挥手,但如果tw bucket 满了就直接走 reset,比如很多机器设置的是 5000 net.ipv4.tcp_max_tw_buckets = 5000
bucket 溢出对应的监控指标:TCPTimeWaitOverflow
1 | #netstat -s | grep -i overflow |
总结
- 一定要会用tcpdump和wireshark(纯工具,没有任何门槛,用不好只有一个原因: 懒)
- 多实践(因为网络知识离我们有点远、有点抽象),用好各种工具,工具能帮我们看到、摸到
- 不要追求知识面的广度,深抠几个具体的知识点然后让这些点建立体系
- 不要为那些基本用不到的偏门知识花太多精力,天天用的都学不过来对吧。
参考资料
per-connection random offset:https://lwn.net/Articles/708021/