Linux内存--PageCache
Linux内存–PageCache
本系列有如下几篇
[Linux 内存问题汇总](/2020/01/15/Linux 内存问题汇总/)
read/write
read(2)/write(2) 是 Linux 系统中最基本的 I/O 读写系统调用,我们开发操作 I/O 的程序时必定会接触到它们,而在这两个系统调用和真实的磁盘读写之间存在一层称为 Kernel buffer cache 的缓冲区缓存。在 Linux 中 I/O 缓存其实可以细分为两个:Page Cache 和 Buffer Cache,这两个其实是一体两面,共同组成了 Linux 的内核缓冲区(Kernel Buffer Cache),Page Cache 是在应用程序读写文件的过程中产生的:
- 读磁盘:内核会先检查
Page Cache里是不是已经缓存了这个数据,若是,直接从这个内存缓冲区里读取返回,若否,则穿透到磁盘去读取,然后再缓存在Page Cache里,以备下次缓存命中; - 写磁盘:内核直接把数据写入
Page Cache,并把对应的页标记为 dirty,添加到 dirty list 里,然后就直接返回,内核会定期把 dirty list 的页缓存 flush 到磁盘,保证页缓存和磁盘的最终一致性。
在 Linux 还不支持虚拟内存技术之前,还没有页的概念,因此 Buffer Cache 是基于操作系统读写磁盘的最小单位 – 块(block)来进行的,所有的磁盘块操作都是通过 Buffer Cache 来加速,Linux 引入虚拟内存的机制来管理内存后,页成为虚拟内存管理的最小单位,因此也引入了 Page Cache 来缓存 Linux 文件内容,主要用来作为文件系统上的文件数据的缓存,提升读写性能,常见的是针对文件的 read()/write() 操作,另外也包括了通过 mmap() 映射之后的块设备,也就是说,事实上 Page Cache 负责了大部分的块设备文件的缓存工作。而 Buffer Cache 用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用。
在 Linux 2.4 版本之后,kernel 就将两者进行了统一,Buffer Cache 不再以独立的形式存在,而是以融合的方式存在于 Page Cache 中
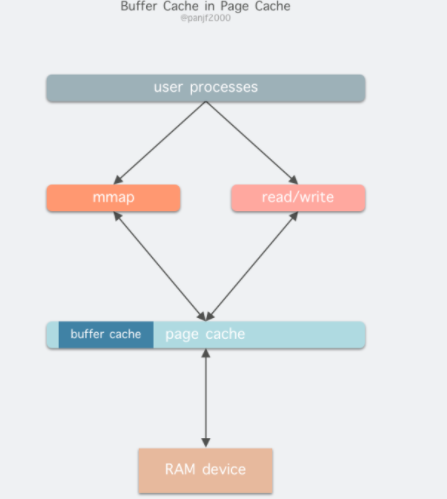
融合之后就可以统一操作 Page Cache 和 Buffer Cache:处理文件 I/O 缓存交给 Page Cache,而当底层 RAW device 刷新数据时以 Buffer Cache 的块单位来实际处理。
pagecache 的产生和释放
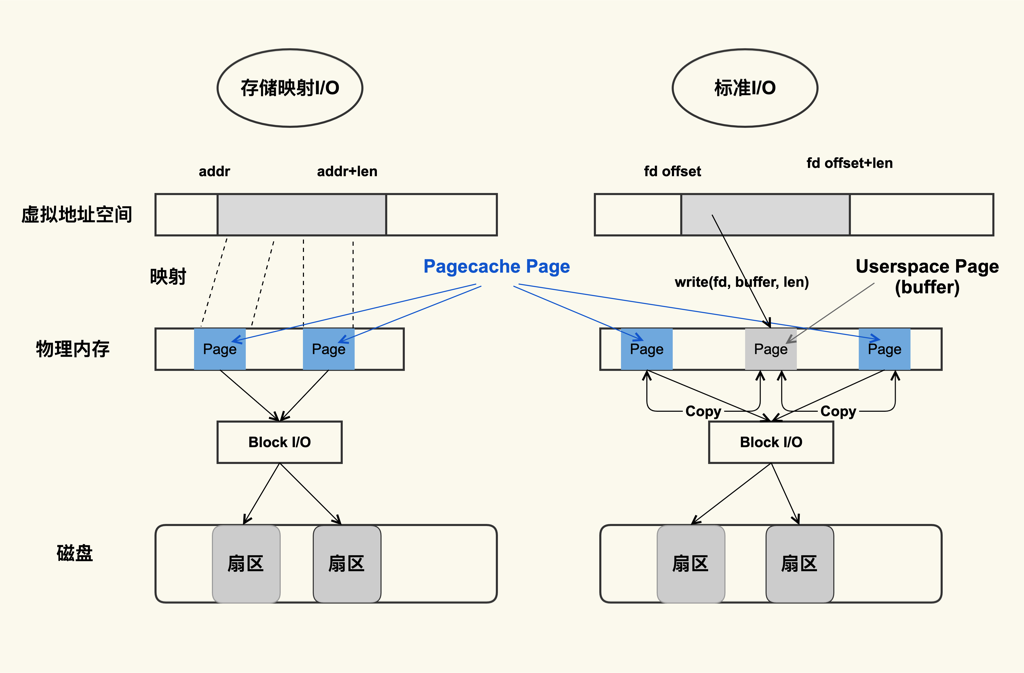
- 标准 I/O 是写的 (write(2)) 用户缓冲区 (Userpace Page 对应的内存),然后再将用户缓冲区里的数据拷贝到内核缓冲区 (Pagecache Page 对应的内存);如果是读的 (read(2)) 话则是先从内核缓冲区拷贝到用户缓冲区,再从用户缓冲区读数据,也就是 buffer 和文件内容不存在任何映射关系。
- 对于存储映射 I/O(Memory-Mapped I/O) 而言,则是直接将 Pagecache Page 给映射到用户地址空间,用户直接读写 Pagecache Page 中内容,效率相对标准IO更高一些
当 将用户缓冲区里的数据拷贝到内核缓冲区 (Pagecache Page 对应的内存) 最容易发生缺页中断,OS需要先分配Page(应用感知到的就是卡顿了)
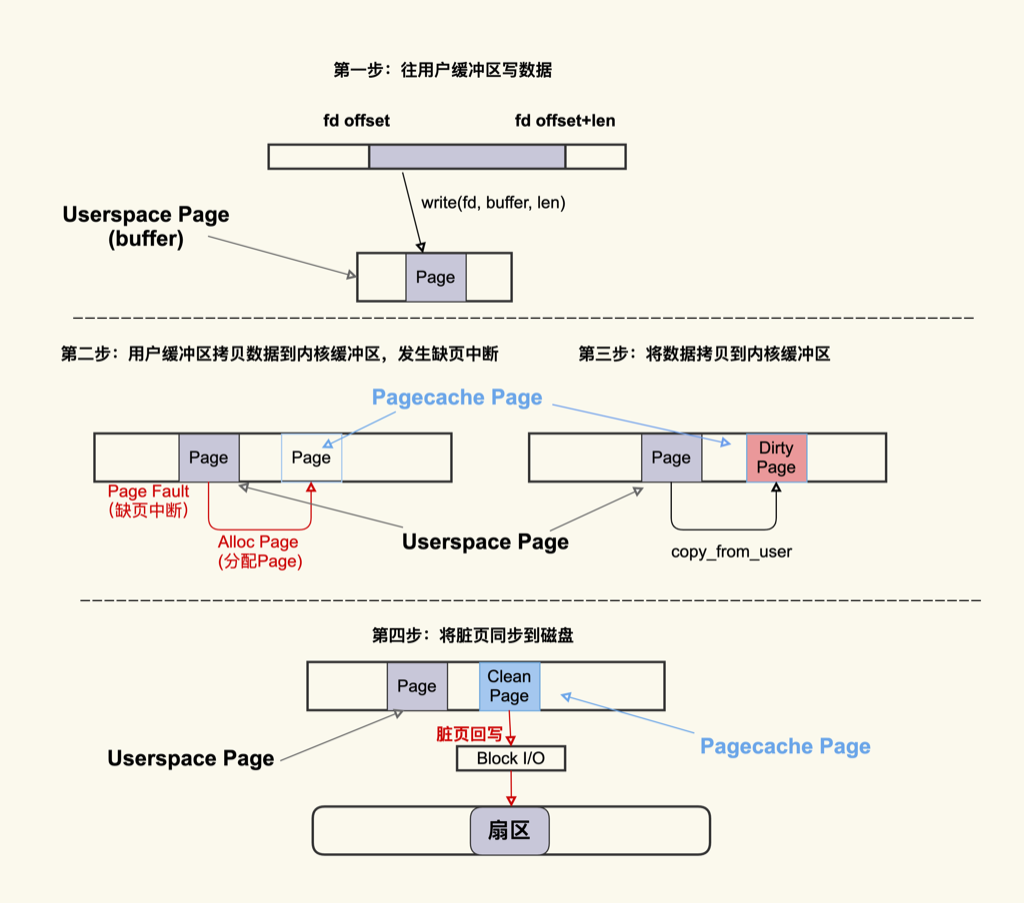
- Page Cache 是在应用程序读写文件的过程中产生的,所以在读写文件之前你需要留意是否还有足够的内存来分配 Page Cache;
- Page Cache 中的脏页很容易引起问题,你要重点注意这一块;
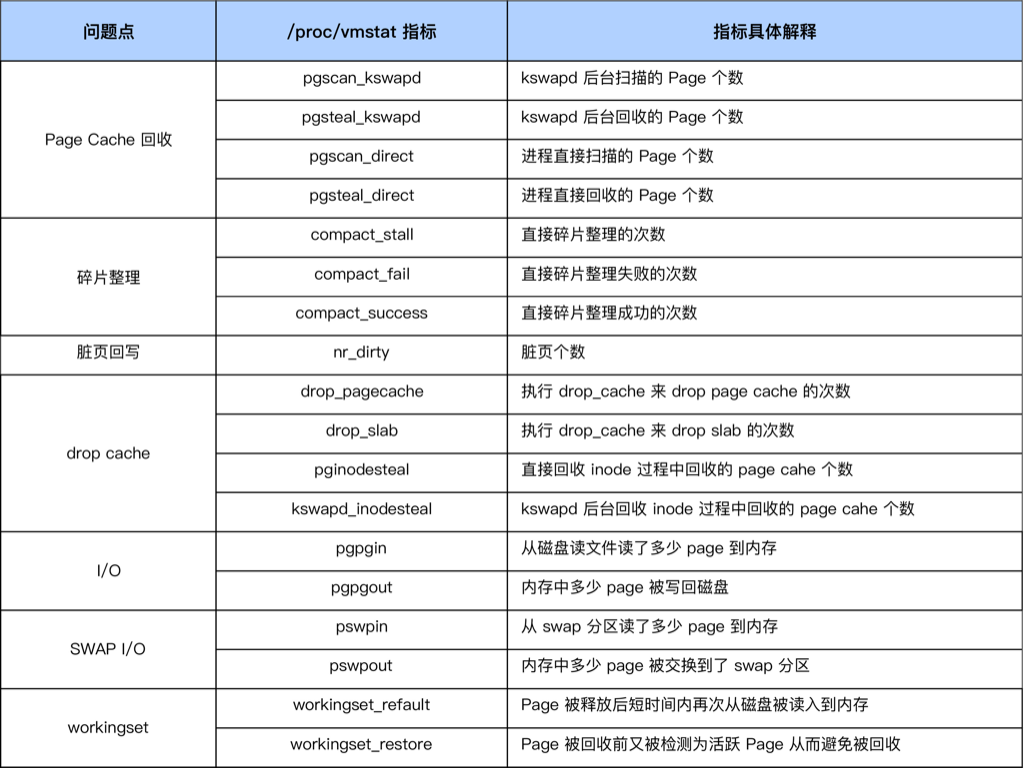
- 在系统可用内存不足的时候就会回收 Page Cache 来释放出来内存,可以通过 sar 或者 /proc/vmstat 来观察这个行为从而更好的判断问题是否跟回收有关
缺页后kswapd在短时间内回收不了足够多的 free 内存,或kswapd 还没有触发执行,操作系统就会进行内存页直接回收。这个过程中,应用会进行自旋等待直到回收的完成,从而产生巨大的延迟。
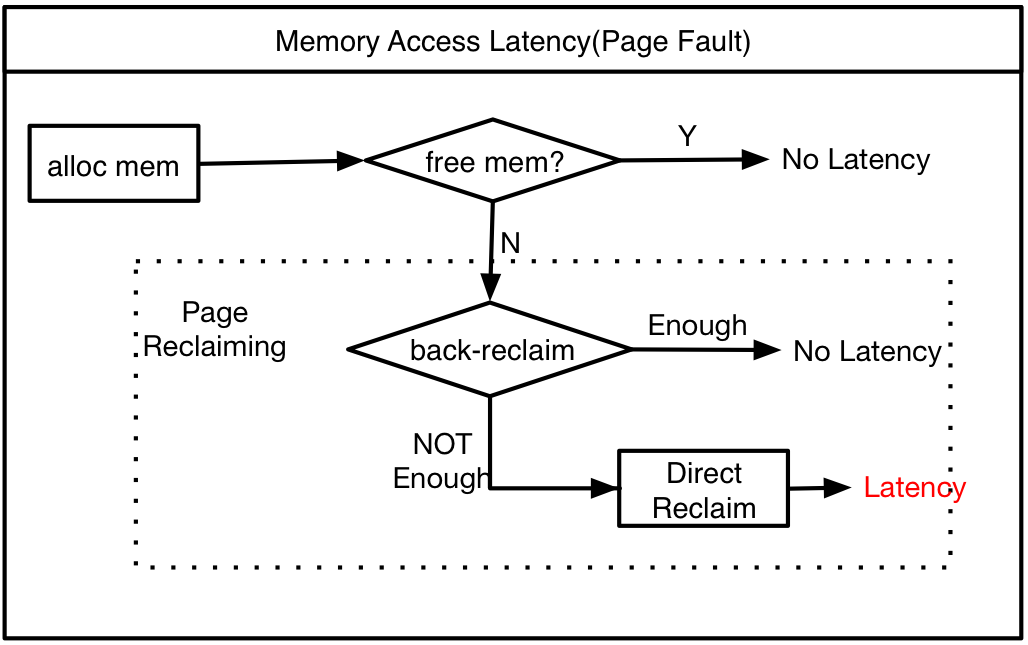
如果page被swapped,那么恢复进内存的过程也对延迟有影响,当匿名内存页被回收后,如果下次再访问就会产生IO的延迟。
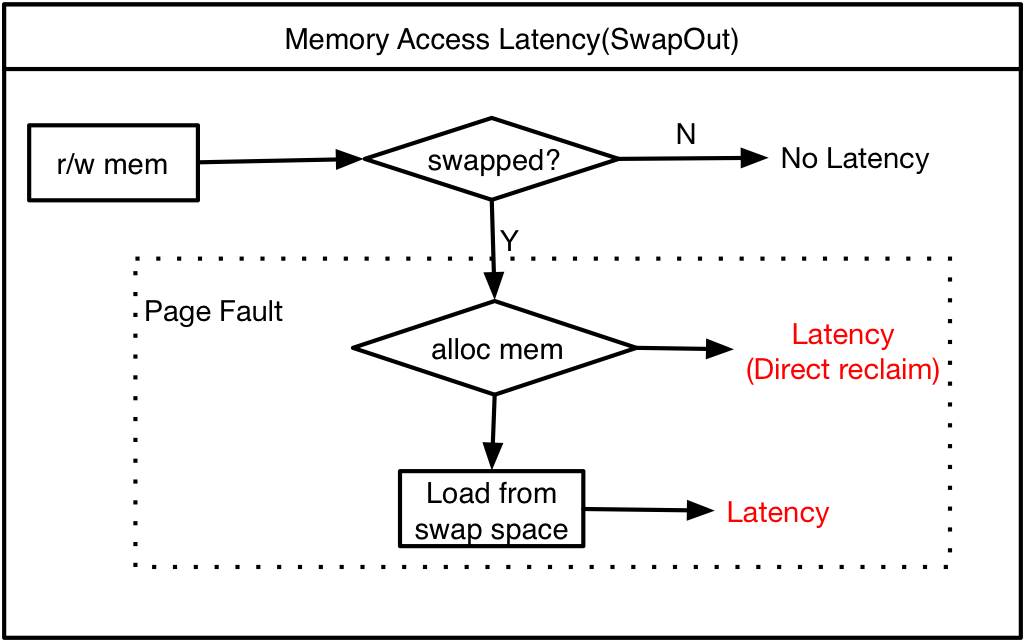
min 和 low的区别
- min下的内存是保留给内核使用的;当到达min,会触发内存的direct reclaim (vm.min_free_kbytes)
- low水位比min高一些,当内存可用量小于low的时候,会触发 kswapd回收内存,当kswapd慢慢的将内存 回收到high水位,就开始继续睡眠
内存回收方式
内存回收方式有两种,主要对应low ,min
- kswapd reclaim : 达到low水位线时执行 – 异步(实际还有,只是比较危险了,后台kswapd会回收,不会卡顿应用)
- direct reclaim : 达到min水位线时执行 – 同步
为了减少缺页中断,首先就要保证我们有足够的内存可以使用。由于Linux会尽可能多的使用free的内存,运行很久的应用free的内存是很少的。下面的图中,紫色表示已经使用的内存,白色表示尚未分配的内存。当我们的内存使用达到水位的low值的时候,kswapd就会开始回收工作,而一旦内存分配超过了min,就会进行内存的直接回收。
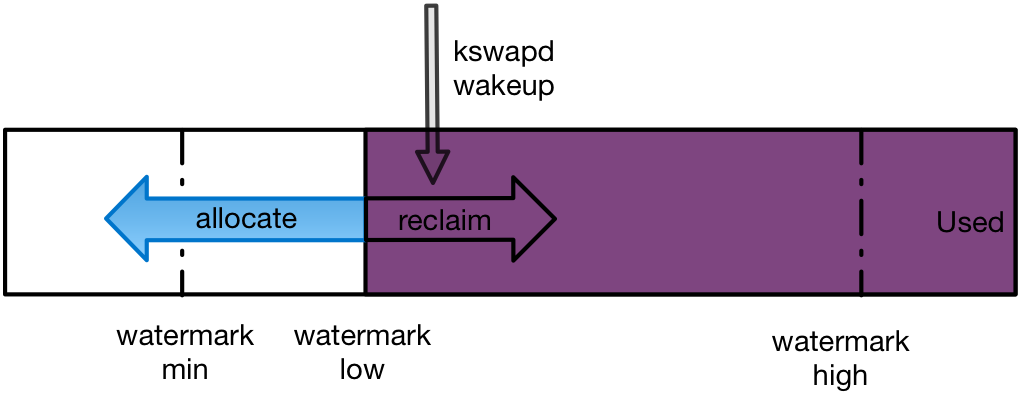
针对这种情况,需要采用预留内存的手段,系统参数vm.extra_free_kbytes就是用来做这个事情的。这个参数设置了系统预留给应用的内存,可以避免紧急需要内存时发生内存回收不及时导致的高延迟。从下面图中可以看到,通过vm.extra_free_kbytes的设置,预留内存可以让内存的申请处在一个安全的水位。需要注意的是,因为内核的优化,在3.10以上的内核版本这个参数已经被取消。
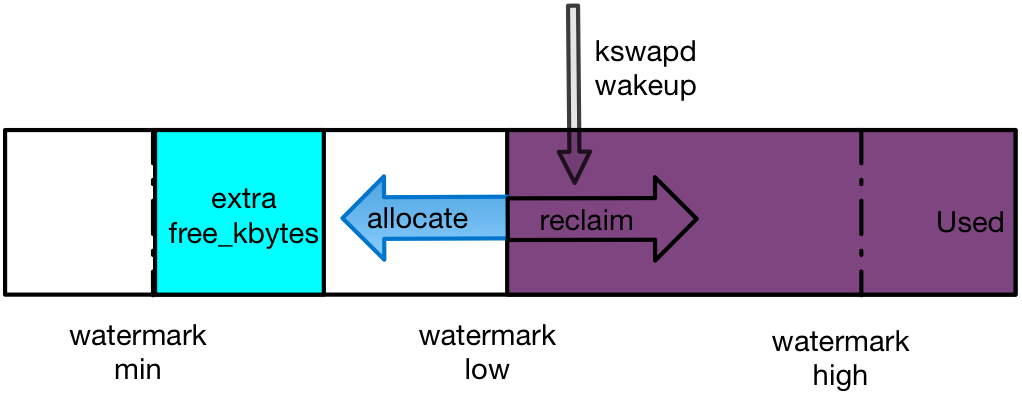
三个watermark的计算方法:
watermark[min] = vm.min_free_kbytes换算为page单位即可,假设为vm.min_free_kbytes。
watermark[low] = watermark[min] * 5 / 4
watermark[high] = watermark[min] * 3 / 2
比如默认 vm.min_free_kbytes = 65536是64K,很容易导致应用的毛刺,可以适当改大
或者禁止: vm.swappiness 来避免swapped来减少延迟
direct IO
绕过page cache,直接读写硬盘
cache回收
系统内存大体可分为三块,应用程序使用内存、系统Cache 使用内存(包括page cache、buffer,内核slab 等)和Free 内存。
应用程序使用内存:应用使用都是虚拟内存,应用申请内存时只是分配了地址空间,并未真正分配出物理内存,等到应用真正访问内存时会触发内核的缺页中断,这时候才真正的分配出物理内存,映射到用户的地址空间,因此应用使用内存是不需要连续的,内核有机制将非连续的物理映射到连续的进程地址空间中(mmu),缺页中断申请的物理内存,内核优先给低阶碎内存。
系统Cache 使用内存:使用的也是虚拟内存,申请机制与应用程序相同。
Free 内存,未被使用的物理内存,这部分内存以4k 页的形式被管理在内核伙伴算法结构中,相邻的2^n 个物理页会被伙伴算法组织到一起,形成一块连续物理内存,所谓的阶内存就是这里的n (0<= n <=10),高阶内存指的就是一块连续的物理内存,在OSS 的场景中,如果3阶内存个数比较小的情况下,如果系统有吞吐burst 就会触发Drop cache 情况。
echo 1/2/3 >/proc/sys/vm/drop_caches
查看回收后:
cat /proc/meminfo
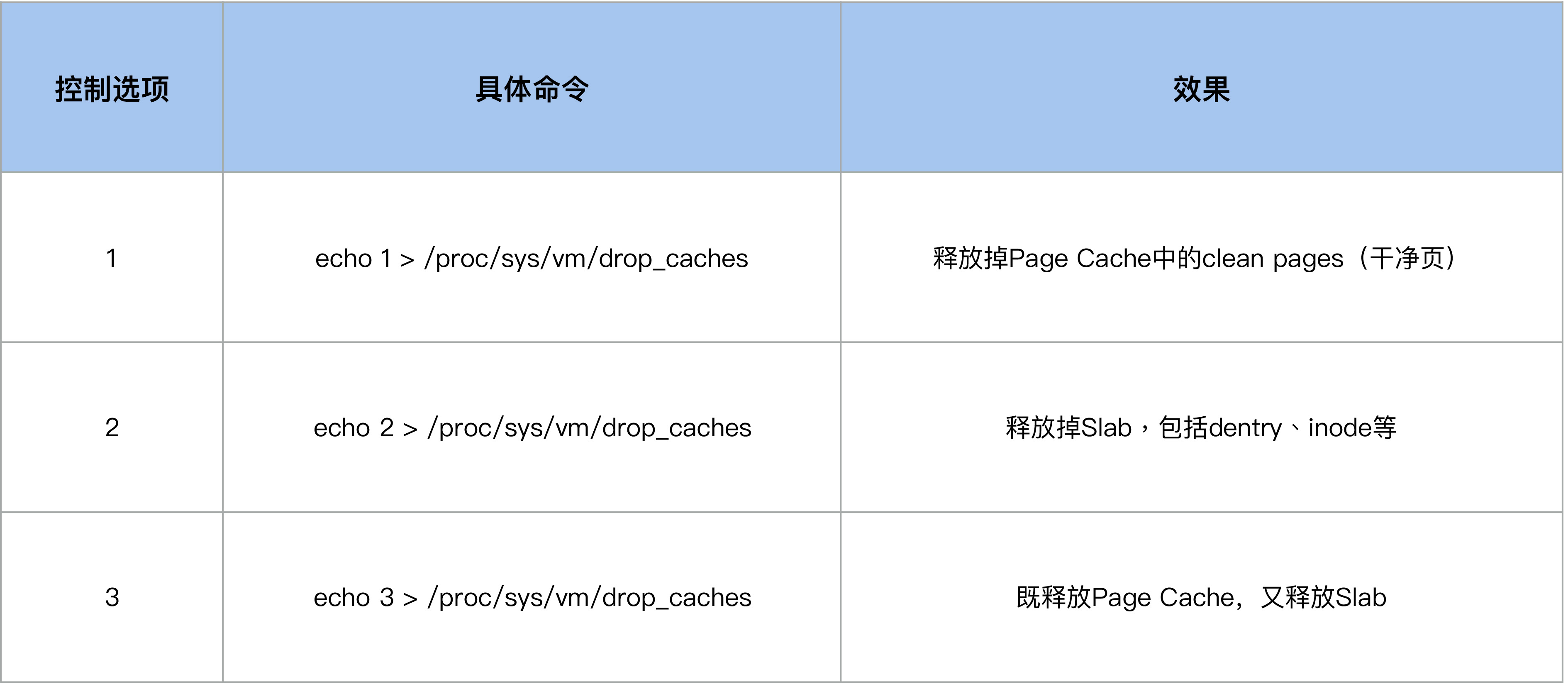
当我们执行 echo 2 来 drop slab 的时候,它也会把 Page Cache(inode可能会有对应的pagecache,inode释放后对应的pagecache也释放了)给 drop 掉
在系统内存紧张的时候,运维人员或者开发人员会想要通过 drop_caches 的方式来释放一些内存,但是由于他们清楚 Page Cache 被释放掉会影响业务性能,所以就期望只去 drop slab 而不去 drop pagecache。于是很多人这个时候就运行 echo 2 > /proc/sys/vm/drop_caches,但是结果却出乎了他们的意料:Page Cache 也被释放掉了,业务性能产生了明显的下降。
查看 drop_caches 是否执行过释放:
1 | $ grep drop /proc/vmstat |
在内存紧张的时候会触发内存回收,内存回收会尝试去回收 reclaimable(可以被回收的)内存,这部分内存既包含 Page Cache 又包含 reclaimable kernel memory(比如 slab)。inode被回收后可以通过 grep inodesteal /proc/vmstat 观察到
kswapd_inodesteal 是指在 kswapd 回收的过程中,因为回收 inode 而释放的 pagecache page 个数;
pginodesteal 是指 kswapd 之外其他线程在回收过程中,因为回收 inode 而释放的 pagecache page 个数;
Page回收–缺页中断
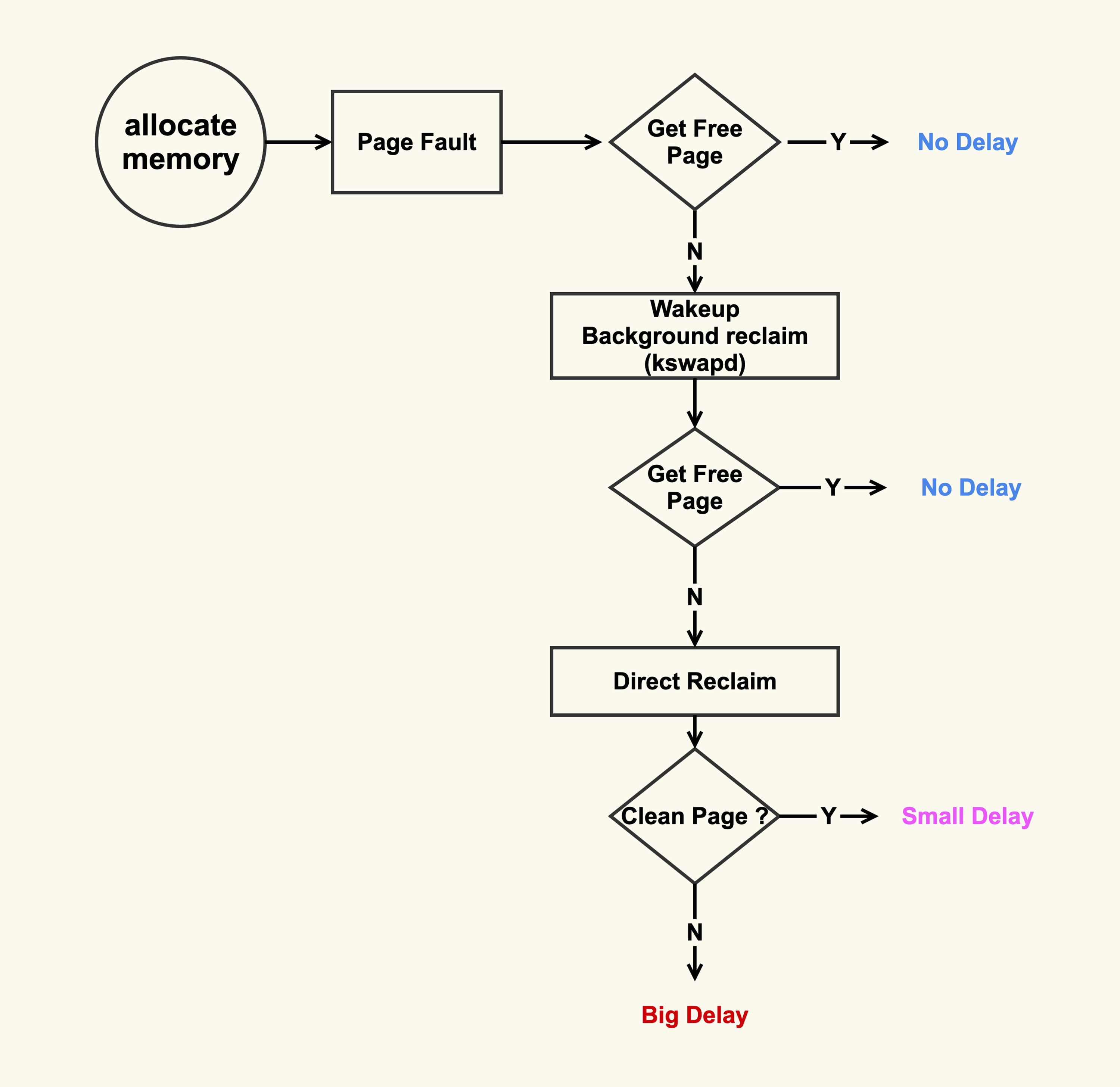
从图里你可以看到,在开始内存回收后,首先进行后台异步回收(上图中蓝色标记的地方),这不会引起进程的延迟;如果后台异步回收跟不上进程内存申请的速度,就会开始同步阻塞回收,导致延迟(上图中红色和粉色标记的地方,这就是引起 load 高的地址 – Sys CPU 使用率飙升/Sys load 飙升)。
那么,针对直接内存回收引起 load 飙高或者业务 RT 抖动的问题,一个解决方案就是及早地触发后台回收来避免应用程序进行直接内存回收,那具体要怎么做呢?
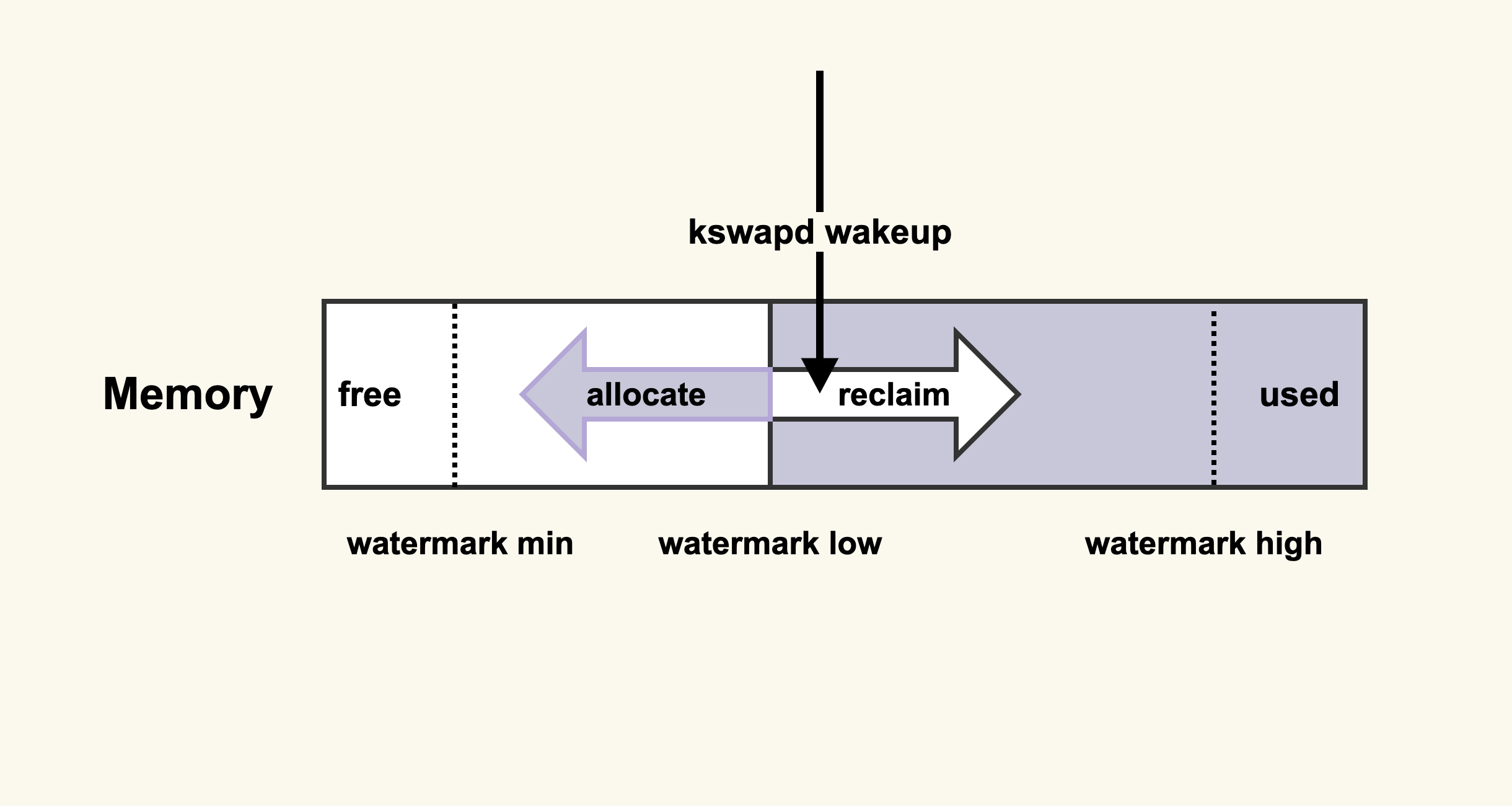
它的意思是:当内存水位低于 watermark low 时,就会唤醒 kswapd 进行后台回收,然后 kswapd 会一直回收到 watermark high。
那么,我们可以增大 min_free_kbytes 这个配置选项来及早地触发后台回收,该选项最终控制的是内存回收水位,不过,内存回收水位是内核里面非常细节性的知识点,我们可以先不去讨论。
对于大于等于 128G 的系统而言,将 min_free_kbytes 设置为 4G 比较合理,这是我们在处理很多这种问题时总结出来的一个经验值,既不造成较多的内存浪费,又能避免掉绝大多数的直接内存回收。
该值的设置和总的物理内存并没有一个严格对应的关系,我们在前面也说过,如果配置不当会引起一些副作用,所以在调整该值之前,我的建议是:你可以渐进式地增大该值,比如先调整为 1G,观察 sar -B 中 pgscand 是否还有不为 0 的情况;如果存在不为 0 的情况,继续增加到 2G,再次观察是否还有不为 0 的情况来决定是否增大,以此类推。
sar -B : Report paging statistics.
pgscand/s Number of pages scanned directly per second.
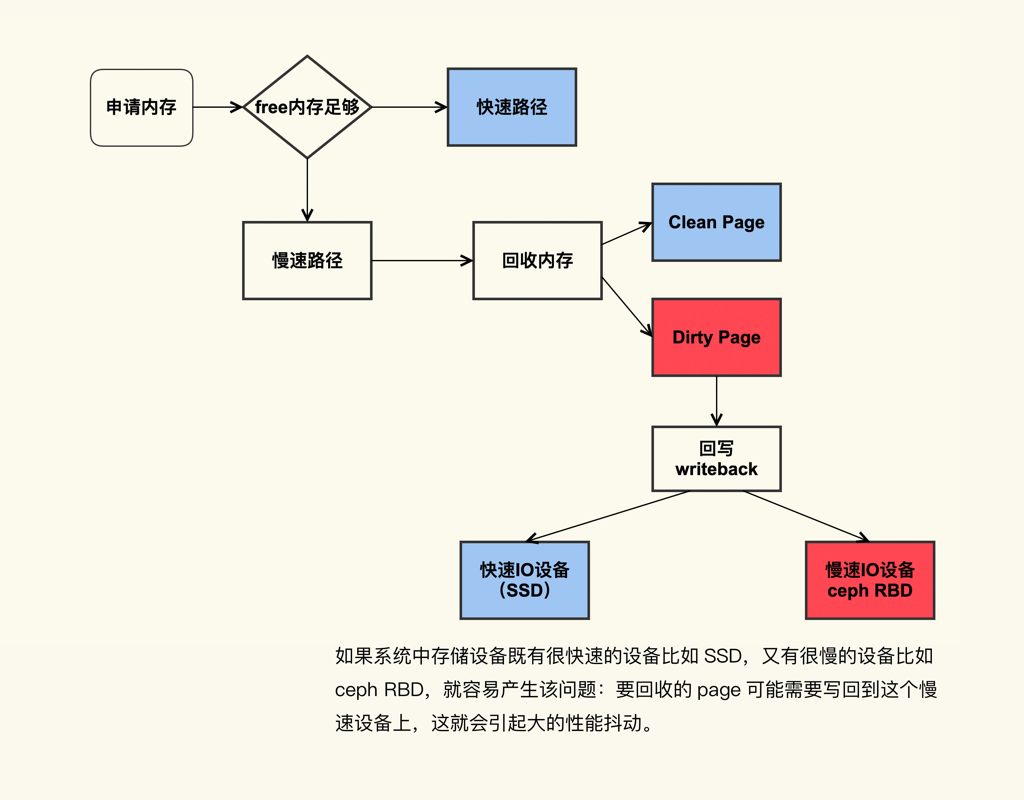
系统中脏页过多引起 load 飙高
直接回收过程中,如果存在较多脏页就可能涉及在回收过程中进行回写,这可能会造成非常大的延迟,而且因为这个过程本身是阻塞式的,所以又可能进一步导致系统中处于 D 状态的进程数增多,最终的表现就是系统的 load 值很高。
可以通过 sar -r 来观察系统中的脏页个数:
1 | $ sar -r 1 |
kbdirty 就是系统中的脏页大小,它同样也是对 /proc/vmstat 中 nr_dirty 的解析。你可以通过调小如下设置来将系统脏页个数控制在一个合理范围:
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
至于这些值调整大多少比较合适,也是因系统和业务的不同而异,我的建议也是一边调整一边观察,将这些值调整到业务可以容忍的程度就可以了,即在调整后需要观察业务的服务质量 (SLA),要确保 SLA 在可接受范围内。调整的效果可以通过 /proc/vmstat 来查看:
1 | #grep "nr_dirty_" /proc/vmstat |
在4.20的内核并且sar 的版本为12.3.3可以看到PSI(Pressure-Stall Information)
1 | some avg10=45.49 avg60=10.23 avg300=5.41 total=76464318 |
重点关注 avg10 这一列,它表示最近 10s 内存的平均压力情况,如果它很大(比如大于 40)那 load 飙高大概率是由于内存压力,尤其是 Page Cache 的压力引起的。
通过tracepoint分析内存卡顿问题
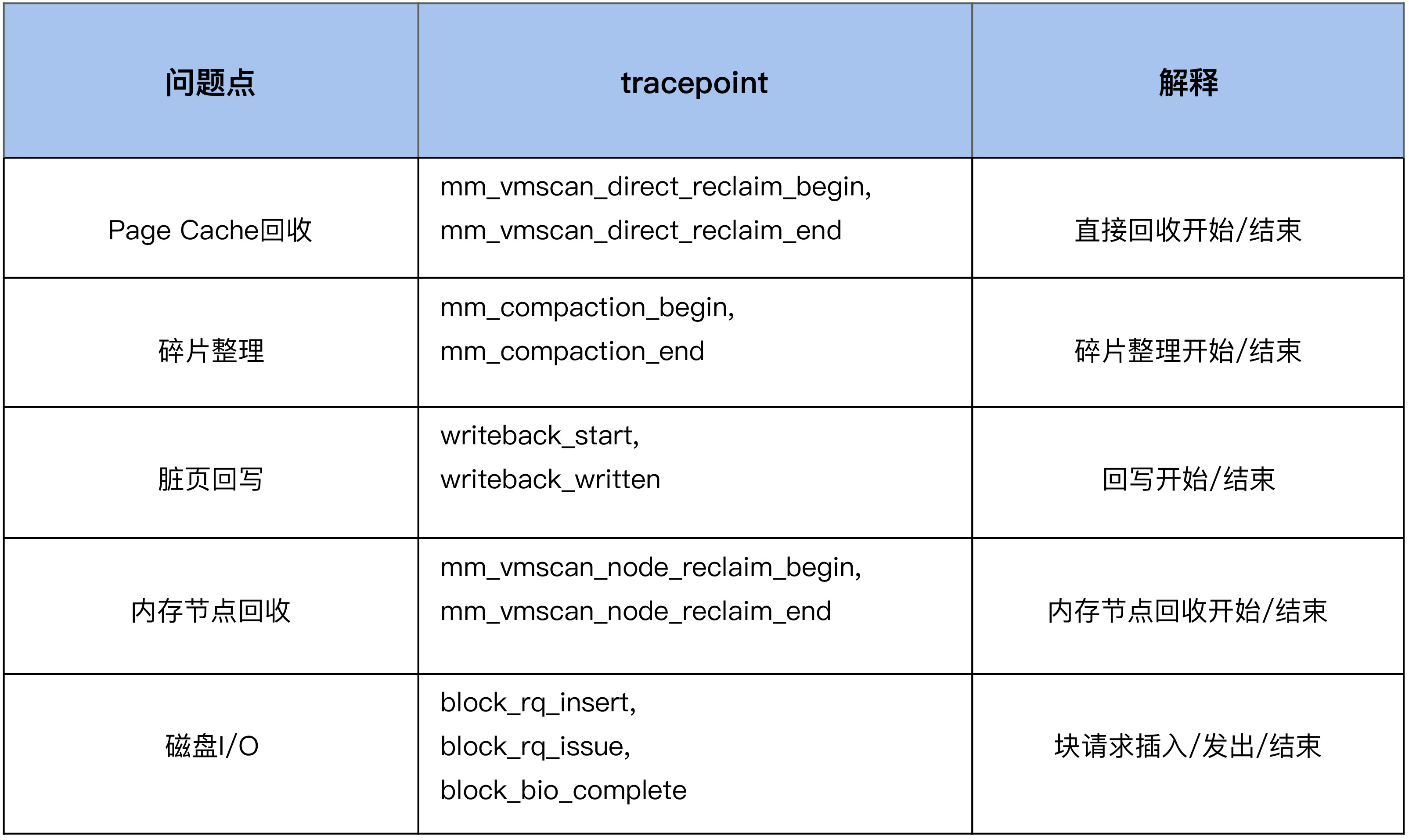
我们继续以内存规整 (memory compaction) 为例,来看下如何利用 tracepoint 来对它进行观察:
1 | #首先来使能compcation相关的一些tracepoing |
从这个例子中的信息里,我们可以看到是 49355 这个进程触发了 compaction,begin 和 end 这两个 tracepoint 触发的时间戳相减,就可以得到 compaction 给业务带来的延迟,我们可以计算出这一次的延迟为 17ms。
或者用 perf script 脚本来分析, 基于 bcc(eBPF) 写的direct reclaim snoop来观察进程因为 direct reclaim 而导致的延迟。
参考资料
https://www.atatech.org/articles/66885