Linux内存--HugePage
Linux内存–HugePage
本系列有如下几篇
[Linux 内存问题汇总](/2020/01/15/Linux 内存问题汇总/)
/proc/buddyinfo
/proc/buddyinfo记录了内存的详细碎片情况。
1 | #cat /proc/buddyinfo |
Normal行的第二列表示: 643847*2^1*Page_Size(4K) ; 第三列表示: 357451*2^2*Page_Size(4K) ,高阶内存指的是2^3及更大的内存块。
应用申请大块连续内存(高阶内存,一般之4阶及以上, 也就是64K以上–2^4*4K)时,容易导致卡顿。这是因为大块连续内存确实系统需要触发回收或者碎片整理,需要一定的时间。
slabtop和/proc/slabinfo
slabtop和/proc/slabinfo 查看cached使用情况 主要是:pagecache(页面缓存), dentries(目录缓存), inodes
关于hugetlb
This is an entry in the TLB that points to a HugePage (a large/big page larger than regular 4K and predefined in size). HugePages are implemented via hugetlb entries, i.e. we can say that a HugePage is handled by a “hugetlb page entry”. The ‘hugetlb” term is also (and mostly) used synonymously with a HugePage.
hugetlb 是TLB中指向HugePage的一个entry(通常大于4k或预定义页面大小)。 HugePage 通过hugetlb entries来实现,也可以理解为HugePage 是hugetlb page entry的一个句柄。
Linux下的大页分为两种类型:标准大页(Huge Pages)和透明大页(Transparent Huge Pages)
标准大页管理是预分配的方式,而透明大页管理则是动态分配的方式
目前透明大页与传统HugePages联用会出现一些问题,导致性能问题和系统重启。Oracle 建议禁用透明大页(Transparent Huge Pages)
hugetlbfs比THP要好,开thp的机器碎片化严重(不开THP会有更严重的碎片化问题),最后和没开THP一样 https://www.atatech.org/articles/152660
Linux 中的 HugePages 都被锁定在内存中,所以哪怕是在系统内存不足时,它们也不会被 Swap 到磁盘上,这也就能从根源上杜绝了重要内存被频繁换入和换出的可能。
Transparent Hugepages are similar to standard HugePages. However, while standard HugePages allocate memory at startup, Transparent Hugepages memory uses the khugepaged thread in the kernel to allocate memory dynamically during runtime, using swappable HugePages.
HugePage要求OS启动的时候提前分配出来,管理难度比较大,所以Enterprise Linux 6增加了一层抽象层来动态创建管理HugePage,这就是THP,而这个THP对应用透明,由khugepaged thread在后台动态将小页组成大页给应用使用,这里会遇上碎片问题导致需要compact才能得到大页,应用感知到的就是SYS CPU飙高,应用卡顿了。
虽然 HugePages 的开启大都需要开发或者运维工程师的额外配置,但是在应用程序中启用 HugePages 却可以在以下几个方面降低内存页面的管理开销:
- 更大的内存页能够减少内存中的页表层级,这不仅可以降低页表的内存占用,也能降低从虚拟内存到物理内存转换的性能损耗;
- 更大的内存页意味着更高的缓存命中率,CPU 有更高的几率可以直接在 TLB(Translation lookaside buffer)中获取对应的物理地址;
- 更大的内存页可以减少获取大内存的次数,使用 HugePages 每次可以获取 2MB 的内存,是 4KB 的默认页效率的 512 倍;
HugePage
为什么需要Huge Page 了解CPU Cache大致架构的话,一定听过TLB Cache。Linux系统中,对程序可见的,可使用的内存地址是Virtual Address。每个程序的内存地址都是从0开始的。而实际的数据访问是要通过Physical Address进行的。因此,每次内存操作,CPU都需要从page table中把Virtual Address翻译成对应的Physical Address,那么对于大量内存密集型程序来说page table的查找就会成为程序的瓶颈。
所以现代CPU中就出现了TLB(Translation Lookaside Buffer) Cache用于缓存少量热点内存地址的mapping关系。然而由于制造成本和工艺的限制,响应时间需要控制在CPU Cycle级别的Cache容量只能存储几十个对象。那么TLB Cache在应对大量热点数据Virual Address转换的时候就显得捉襟见肘了。我们来算下按照标准的Linux页大小(page size) 4K,一个能缓存64元素的TLB Cache只能涵盖4K*64 = 256K的热点数据的内存地址,显然离理想非常遥远的。于是Huge Page就产生了。
Huge pages require contiguous areas of memory, so allocating them at boot is the most reliable method since memory has not yet become fragmented. To do so, add the following parameters to the kernel boot command line:
Huge pages kernel options
hugepages
Defines the number of persistent huge pages configured in the kernel at boot time. The default value is
0. It is only possible to allocate (or deallocate) huge pages if there are sufficient physically contiguous free pages in the system. Pages reserved by this parameter cannot be used for other purposes.Default size huge pages can be dynamically allocated or deallocated by changing the value of the
/proc/sys/vm/nr_hugepagesfile.In a NUMA system, huge pages assigned with this parameter are divided equally between nodes. You can assign huge pages to specific nodes at runtime by changing the value of the node’s
/sys/devices/system/node/node_id/hugepages/hugepages-1048576kB/nr_hugepagesfile.For more information, read the relevant kernel documentation, which is installed in
/usr/share/doc/kernel-doc-kernel_version/Documentation/vm/hugetlbpage.txtby default. This documentation is available only if the kernel-doc package is installed.hugepagesz
Defines the size of persistent huge pages configured in the kernel at boot time. Valid values are 2 MB and 1 GB. The default value is 2 MB.
default_hugepagesz
Defines the default size of persistent huge pages configured in the kernel at boot time. Valid values are 2 MB and 1 GB. The default value is 2 MB.
应用程序想要利用大页优势,需要通过hugetlb文件系统来使用标准大页。操作步骤
1.预留大页
echo 20 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
2.挂载hugetlb文件系统
mount hugetlbfs /mnt/huge -t hugetlbfs
3.映射hugetbl文件
fd = open(“/mnt/huge/test.txt”, O_CREAT|O_RDWR);
addr = mmap(0, MAP_LENGTH, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
4.hugepage统计信息
通过hugepage提供的sysfs接口,可以了解大页使用情况
HugePages_Total: 预先分配的大页数量
HugePages_Free:空闲大页数量
HugePages_Rsvd: mmap申请大页数量(还没有产生缺页)
HugePages_Surp: 多分配的大页数量(由nr_overcommit_hugepages决定)
5 hugpage优缺点
缺点:
1.需要提前预估大页使用量,并且预留的大页不能被其他内存分配接口使用。
2.兼容性不好,应用使用标准大页,需要对代码进行重构才能有效的使用标准大页。
优点:因为内存是预留的,缺页延时非常小
针对Hugepage的不足,内核又衍生出了THP大页(Transparent Huge pages)
工具
1 | yum install libhugetlbfs-utils -y |
大页和 MySQL 性能 case
MySQL的页都是16K, 当查询的行不在内存中时需要按照16K为单位从磁盘读取页,而文件系统中的页是4k,也就是一次数据库请求需要有4次磁盘IO,如过查询比较随机,每次只需要一个页中的几行数据,存在很大的读放大。
那么我们是否可以把MySQL的页设置为4K来减少读放大呢?
在5.7里收益不大,因为每次IO存在 fil_system 的锁,导致IO的并发上不去
8.0中总算优化了这个场景,测试细节可以参考这篇
16K VS 4K 性能对比(4K接近翻倍)
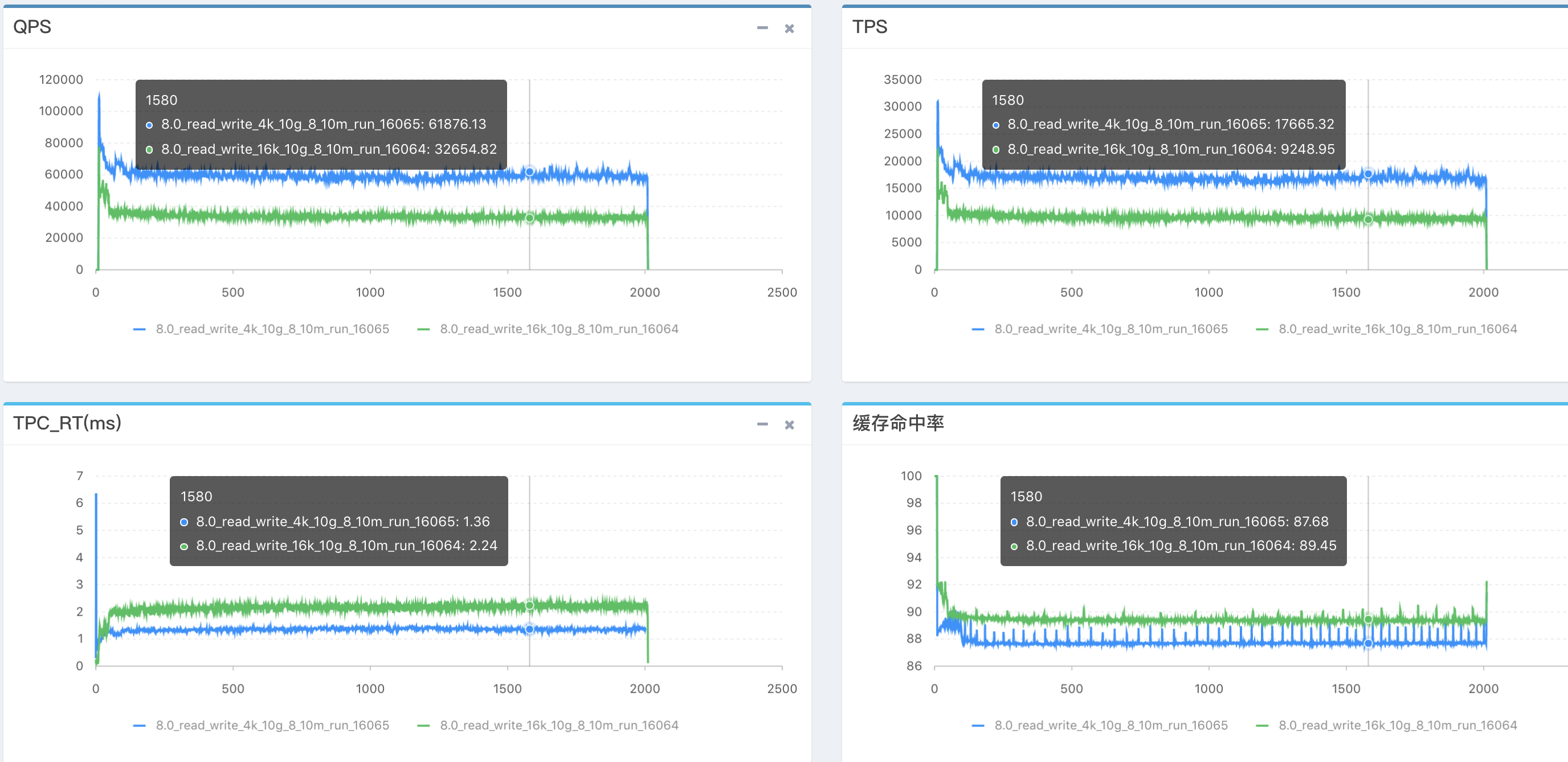
4K会带来的问题:顺序insert慢了10%(因为fsync更多了);DDL更慢;二级索引更多的场景下4K性能较差;大BP下,刷脏代价大。
HugePage 带来的问题
CPU对同一个Page抢占增多
对于写操作密集型的应用,Huge Page会大大增加Cache写冲突的发生概率。由于CPU独立Cache部分的写一致性用的是MESI协议,写冲突就意味:
- 通过CPU间的总线进行通讯,造成总线繁忙
- 同时也降低了CPU执行效率。
- CPU本地Cache频繁失效
类比到数据库就相当于,原来一把用来保护10行数据的锁,现在用来锁1000行数据了。必然这把锁在线程之间的争抢概率要大大增加。
连续数据需要跨CPU读取
Page太大,更容易造成Page跨Numa/CPU 分布。
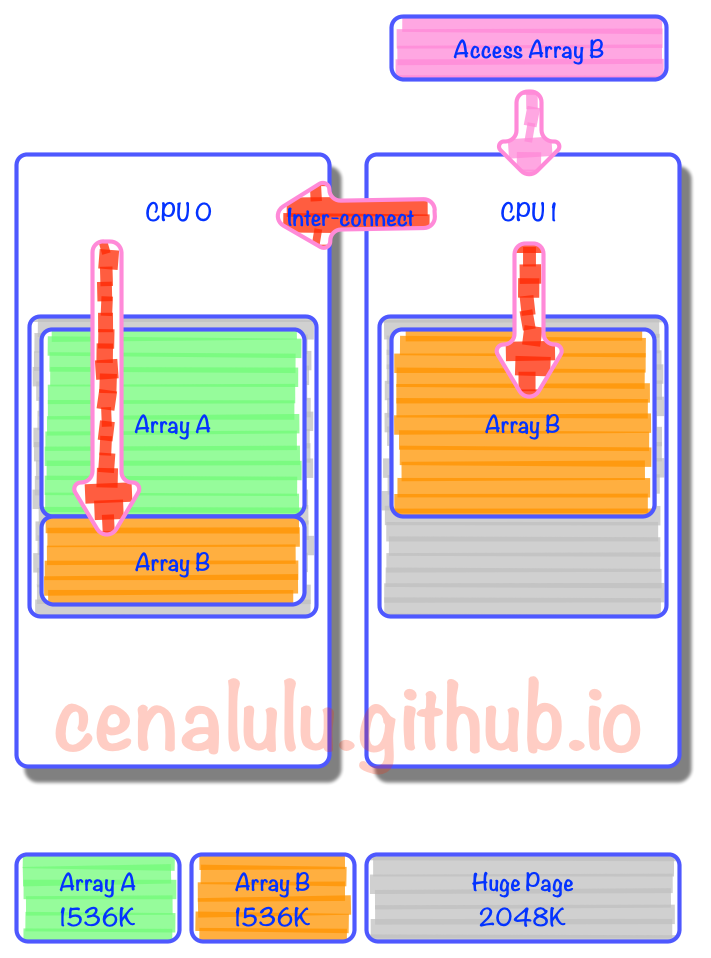
从下图我们可以看到,原本在4K小页上可以连续分配,并因为较高命中率而在同一个CPU上实现locality的数据。到了Huge Page的情况下,就有一部分数据为了填充统一程序中上次内存分配留下的空间,而被迫分布在了两个页上。而在所在Huge Page中占比较小的那部分数据,由于在计算CPU亲和力的时候权重小,自然就被附着到了其他CPU上。那么就会造成:本该以热点形式存在于CPU2 L1或者L2 Cache上的数据,不得不通过CPU inter-connect去remote CPU获取数据。 假设我们连续申明两个数组,Array A和Array B大小都是1536K。内存分配时由于第一个Page的2M没有用满,因此Array B就被拆成了两份,分割在了两个Page里。而由于内存的亲和配置,一个分配在Zone 0,而另一个在Zone 1。那么当某个线程需要访问Array B时就不得不通过代价较大的Inter-Connect去获取另外一部分数据。
Java进程开启HugePage
从perf数据来看压满后tlab miss比较高,得想办法降低这个值
修改JVM启动参数
JVM启动参数增加如下三个(-XX:LargePageSizeInBytes=2m, 这个一定要,有些资料没提这个,在我的JDK8.0环境必须要):
-XX:+UseLargePages -XX:LargePageSizeInBytes=2m -XX:+UseHugeTLBFS
修改机器系统配置
设置HugePage的大小
cat /proc/sys/vm/nr_hugepages
nr_hugepages设置多大参考如下计算方法:
If you are using the option
-XX:+UseSHMor-XX:+UseHugeTLBFS, then specify the number of large pages. In the following example, 3 GB of a 4 GB system are reserved for large pages (assuming a large page size of 2048kB, then 3 GB = 3 * 1024 MB = 3072 MB = 3072 * 1024 kB = 3145728 kB and 3145728 kB / 2048 kB = 1536):echo 1536 > /proc/sys/vm/nr_hugepages
透明大页是没有办法减少系统tlab,tlab是对应于进程的,系统分给进程的透明大页还是由物理上的4K page组成。
对于c++来说,他malloc经常会散落得全地址都是,因为会触发各种mmap,冷热区域。所以THP和hugepage都可能导致大量内存被浪费了,进而导致内存紧张,性能下滑。jvm的连续内存布局,加上gc会使得内存密度很紧凑。THP的问题是,他是逻辑页,不是物理页,tlb依旧要N份,所以他的收益来自page fault减少,是一次性的收益。
hugepage的在减少page_fault上和thp效果一样第二个作用是,他只需要一份TLB了,hugepage是真正的大页内存,thp是逻辑上的,物理上还是需要很多小的page。
如果TLB miss,则可能需要额外三次内存读取操作才能将线性地址翻译为物理地址。
code_hugepage 代码大页
代码大页特性主要为大代码段业务服务,可以降低程序的iTLB miss,从而提升程序性能。针对倚天这一类跨numa访存开销大的芯片有比较好的性能提升效果
1 | // 1 表示仅打开二进制和动态库大页 2 仅打开可执行匿名大页 3 相当于1+2,0 表示关闭 |
是否启用代码大页,可以查看/proc//smaps中FilePmdMapped字段可确定是否使用了代码大页。 扫描进程代码大页使用数量(单位KB):
1 | cat /proc/<pid>/smaps | grep FilePmdMapped | awk '{sum+=$2}END{print"Sum= ",sum}' |
THP
Linux kernel在2.6.38内核增加了Transparent Huge Pages (THP)特性 ,支持大内存页(2MB)分配,默认开启。当开启时可以降低fork子进程的速度,但fork之后,每个内存页从原来4KB变为2MB,会大幅增加重写期间父进程内存消耗。同时每次写命令引起的复制内存页单位放大了512倍,会拖慢写操作的执行时间,导致大量写操作慢查询。例如简单的incr命令也会出现在慢查询中。因此Redis日志中建议将此特性进行禁用。
THP 的目的是用一个页表项来映射更大的内存(大页),这样可以减少 Page Fault,因为需要的页数少了。当然,这也会提升 TLB(Translation Lookaside Buffer,由存储器管理单元用于改进虚拟地址到物理地址的转译速度) 命中率,因为需要的页表项也少了。如果进程要访问的数据都在这个大页中,那么这个大页就会很热,会被缓存在 Cache 中。而大页对应的页表项也会出现在 TLB 中,从上一讲的存储层次我们可以知道,这有助于性能提升。但是反过来,假设应用程序的数据局部性比较差,它在短时间内要访问的数据很随机地位于不同的大页上,那么大页的优势就会消失。
大页在使用的时候需要清理512个4K页面,再返回给用户,这里的清理动作可能会导致卡顿。另外碎片化严重的时候触发内存整理造成卡顿
大页分配: 在缺页处理函数__handle_mm_fault中判断是否使用大页 大页生成: 主要通过在分配大页内存时是否带__GFP_DIRECT_RECLAIM 标志来控制大页的生成.
1.异步生成大页: 在缺页处理中,把需要异步生成大页的VMA注册到链表,内核态线程khugepaged 动态为vma分配大页(内存回收,内存归整)
2.madvise系统调用只是给VMA加了VM_HUGEPAGE,用来标记这段虚拟地址需要使用大页

THP 原理
大页分配: 在缺页处理函数__handle_mm_fault中判断是否使用大页 大页生成: 主要通过在分配大页内存时是否带__GFP_DIRECT_RECLAIM 标志来控制大页的生成.
1.异步生成大页: 在缺页处理中,把需要异步生成大页的VMA注册到链表,内核态线程khugepaged 动态为vma分配大页(内存回收,内存归整)
2.madvise系统调用只是给VMA加了VM_HUGEPAGE,用来标记这段虚拟地址需要使用大页
THP 对redis、mongodb 这种cache类推荐关闭,对drds这种java应用最好打开
1 | #cat /sys/kernel/mm/transparent_hugepage/enabled |
在透明大页功能打开时,造成系统性能下降的主要原因可能是 khugepaged 守护进程。该进程会在(它认为)系统空闲时启动,扫描系统中剩余的空闲内存,并将普通 4k 页转换为大页。该操作会在内存路径中加锁,而该守护进程可能会在错误的时间启动扫描和转换大页的操作,从而影响应用性能。
此外,当缺页异常(page faults)增多时,透明大页会和普通 4k 页一样,产生同步内存压缩(direct compaction)操作,以节省内存。该操作是一个同步的内存整理操作,如果应用程序会短时间分配大量内存,内存压缩操作很可能会被触发,从而会对系统性能造成风险。https://yq.aliyun.com/articles/712830
1 | #查看系统级别的 THP 使用情况,执行下列命令: |
/proc/sys/vm/nr_hugepages 中存储的数据就是大页面的数量,虽然在默认情况下它的值都是 0,不过我们可以通过更改该文件的内容申请或者释放操作系统中的大页:
1 | $ echo 1 > /proc/sys/vm/nr_hugepages |
THP和perf
thp on后比off性能稳定好 10-15%,开启THP最显著的指标是 iTLB命中率显著提升了
1 | //on 419+E5-2682, thp never |
MySQL 场景下代码大页对性能的影响
不只是数据可以用HugePage,代码段也可以开启HugePage, 无论在x86还是arm(arm下提升更明显)下,都可以得到大页优于透明大页,透明大页优于正常的4K page
收益:代码大页 > anon THP > 4k
arm下,对32core机器用32并发的sysbench来对比,代码大页带来的性能提升大概有11%,iTLB miss下降了10倍左右。
x86下,性能提升只有大概3-5%之间,iTLB miss下降了1.5-3倍左右。
TLAB miss高的案例
程序运行久了之后会变慢大概10%
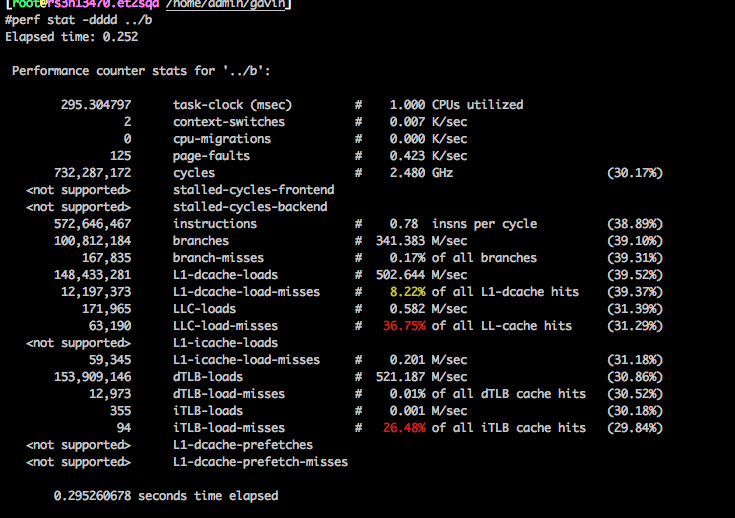
刚开始运行的时候perf各项数据:
长时间运行后:
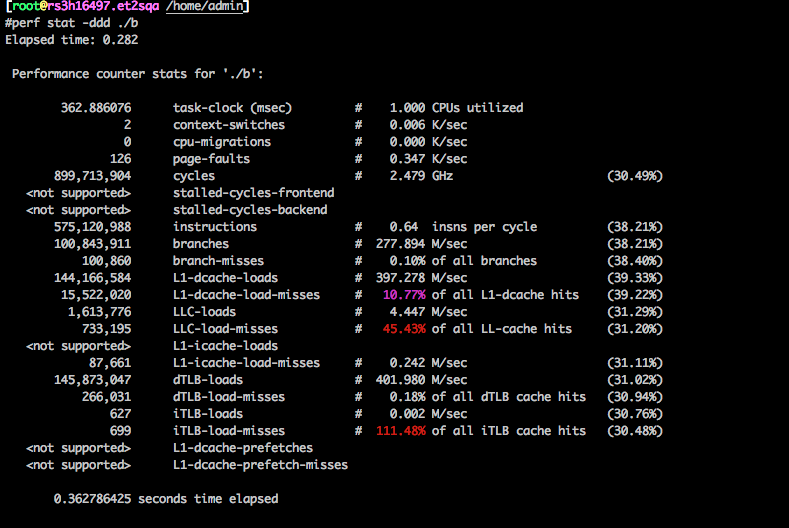
内存的利用以页为单位,当时分析认为,在此4k连续的基础上,页的碎片不应该对64 byte align的cache有什么影响。当时guest和host都没有开THP。
既然无法理解这个结果,那就只有按部就班的查看内核执行路径上各个函数的差别了,祭出ftrace:
1 | echo kerel_func_name1 > /sys/kernel/debug/tracing/set_ftrace_filter |
在CPU#20上执行代码:
taskset -c 20 ./b
代码执行完后:
1 | echo 0 > /sys/kernel/debug/tracing/function_profile_enabled |
这个时候就会打印出在各个函数上花费的时间,比如:
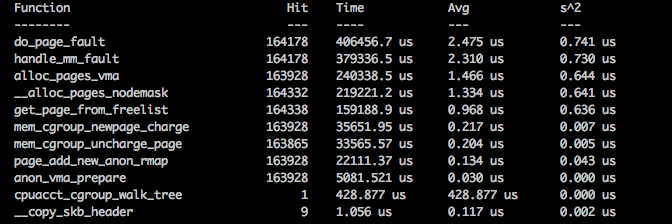
经过调试后,逐步定位到主要时间差距在 __mem_cgroup_commit_charge() (58%).
在阅读代码的过程中,注意到当前内核使能了CONFIG_SPARSEMEM_VMEMMAP=y
原因就是机器运行久了之后内存碎片化严重,导致TLAB Miss严重。
解决:开启THP后,性能稳定
碎片化
内存碎片严重的话会导致系统hang很久(回收、压缩内存)
尽量让系统的free多一点(比例高一点)可以调整 vm.min_free_kbytes(128G 以内 2G,256G以内 4G/8G), 线上机器直接修改vm.min_free_kbytes会触发回收,导致系统hang住 https://www.atatech.org/articles/163233 https://www.atatech.org/articles/97130
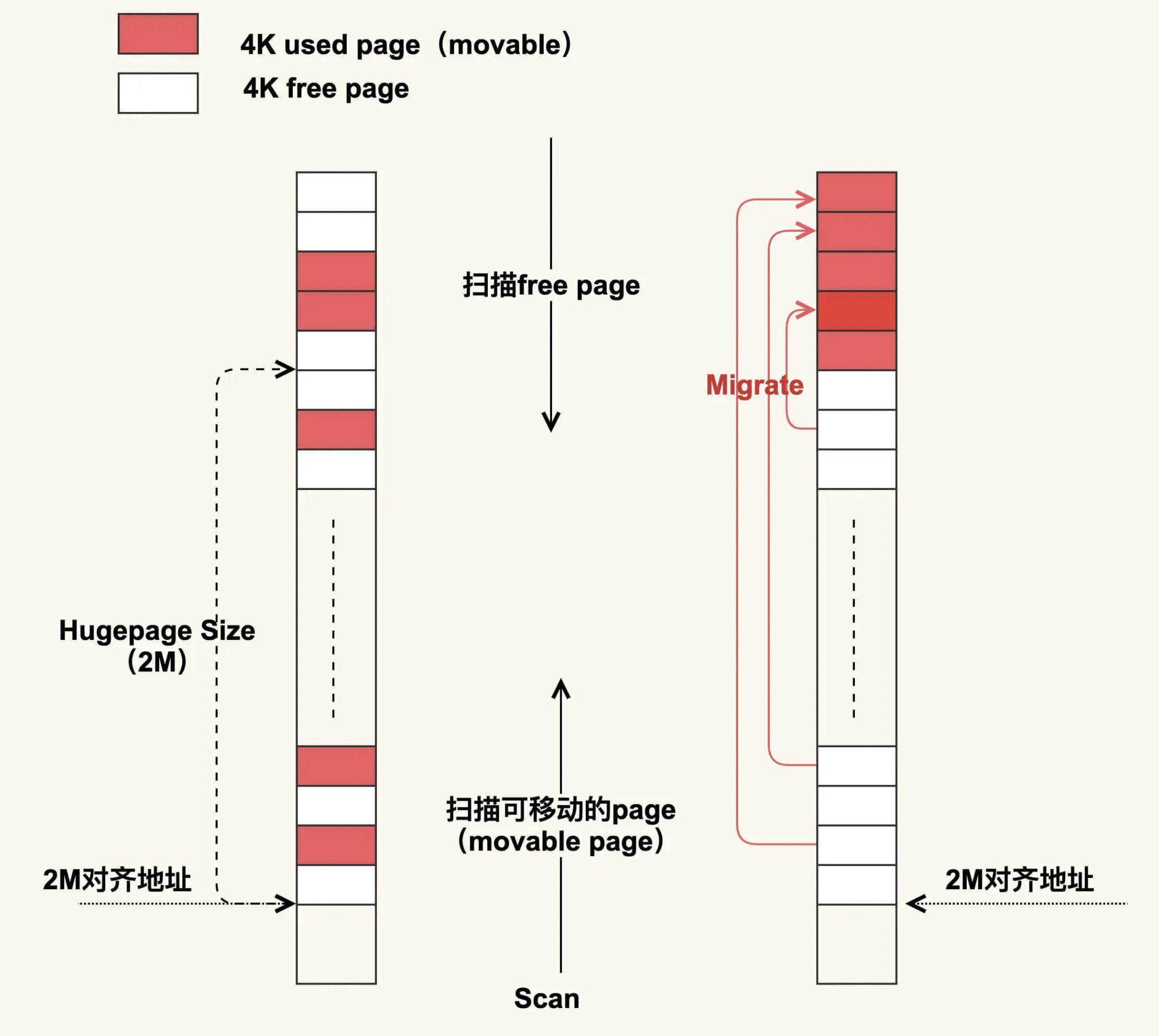
compact: 在进行 compcation 时,线程会从前往后扫描已使用的 movable page,然后从后往前扫描 free page,扫描结束后会把这些 movable page 给迁移到 free page 里,最终规整出一个 2M 的连续物理内存,这样 THP 就可以成功申请内存了。
一次THP compact堆栈:
1 | java R running task 0 144305 144271 0x00000080 |
查看pagetypeinfo
1 | #cat /proc/pagetypeinfo |
每个zone都有自己的min low high,如下,但是单位是page, 计算案例:
1 | [root@jiangyi01.sqa.zmf /home/ahao.mah] |
内存碎片化导致rt升高的诊断
判定方法如下:
- 运行 sar -B 观察 pgscand/s,其含义为每秒发生的直接内存回收次数,当在一段时间内持续大于 0 时,则应继续执行后续步骤进行排查;
- 运行
cat /sys/kernel/debug/extfrag/extfrag_index观察内存碎片指数,重点关注 order >= 3 的碎片指数,当接近 1.000 时,表示碎片化严重,当接近 0 时表示内存不足; - 运行
cat /proc/buddyinfo, cat /proc/pagetypeinfo查看内存碎片情况, 指标含义参考 (https://man7.org/linux/man-pages/man5/proc.5.html),同样关注 order >= 3 的剩余页面数量,pagetypeinfo 相比 buddyinfo 展示的信息更详细一些,根据迁移类型 (伙伴系统通过迁移类型实现反碎片化)进行分组,需要注意的是,当迁移类型为 Unmovable 的页面都聚集在 order < 3 时,说明内核 slab 碎片化严重,我们需要结合其他工具来排查具体原因,在本文就不做过多介绍了; - 对于 CentOS 7.6 等支持 BPF 的 kernel 也可以运行我们研发的 drsnoop,compactsnoop 工具对延迟进行定量分析,使用方法和解读方式请参考对应文档;
- (Opt) 使用 ftrace 抓取 mm_page_alloc_extfrag 事件,观察因内存碎片从备用迁移类型“盗取”页面的信息。
参考资料
https://www.atatech.org/articles/66885