Linux内存–管理和碎片 本系列有如下几篇
[Linux 内存问题汇总](/2020/01/15/Linux 内存问题汇总/)
Linux内存–PageCache
Linux内存–管理和碎片
Linux内存–HugePage
Linux内存–零拷贝
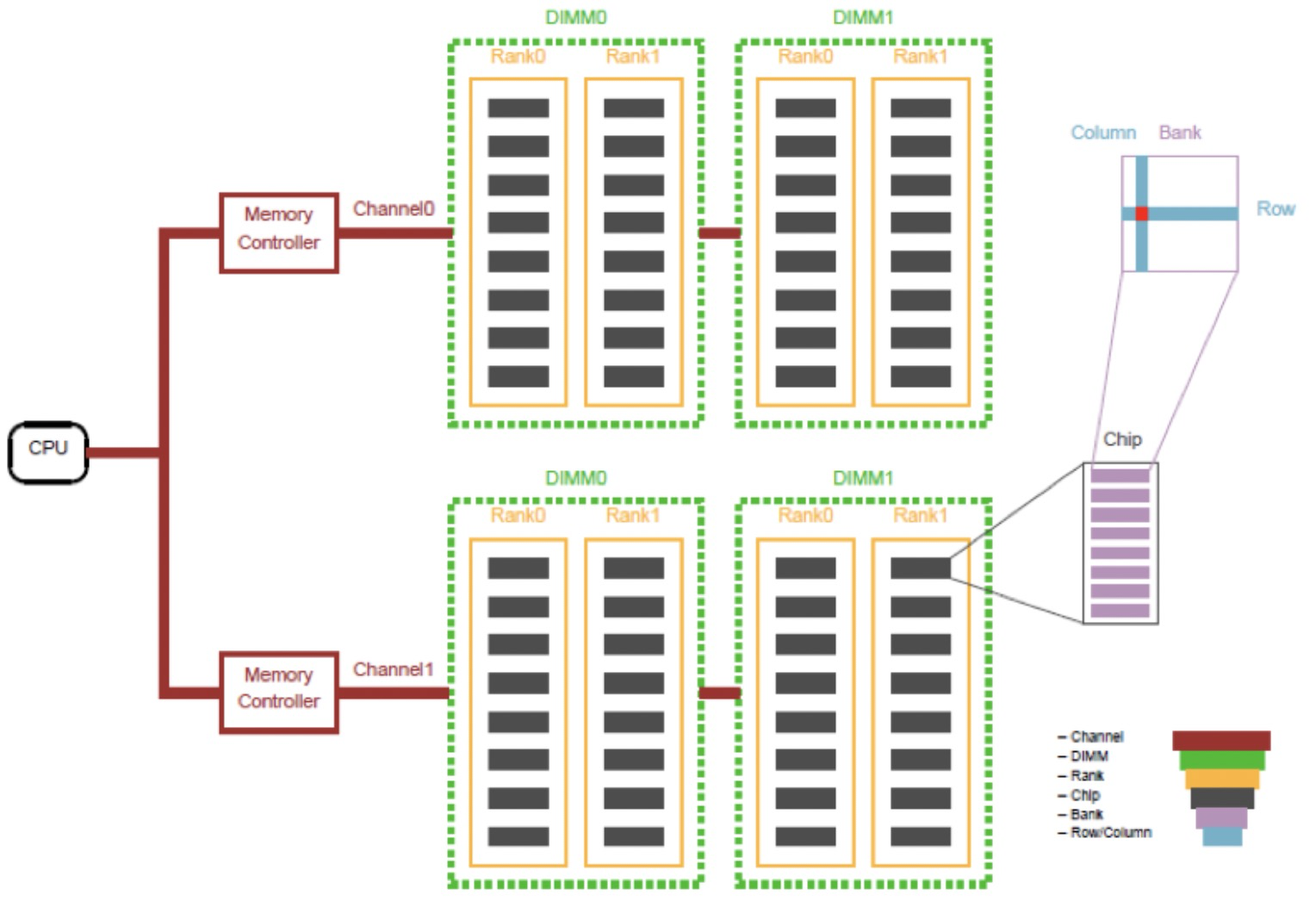
物理结构分析 内存从物理结构上面分为:Channel > DIMM(对应物理上售卖的内存条) >Rank > Chip > Bank > Row/Column。
Chip就是DRAM芯片,一个chip里面会有很多bank。每个bank就是数据存储的实体,相当于一个二维矩阵,只要声明了column和row就可以从每个bank中取出8bit的数据。
具体可以看如下图,一个通道Channel可以是一个DIMM也可以是两个DIMM,甚至3个DIMM,图中是2个DIMM。
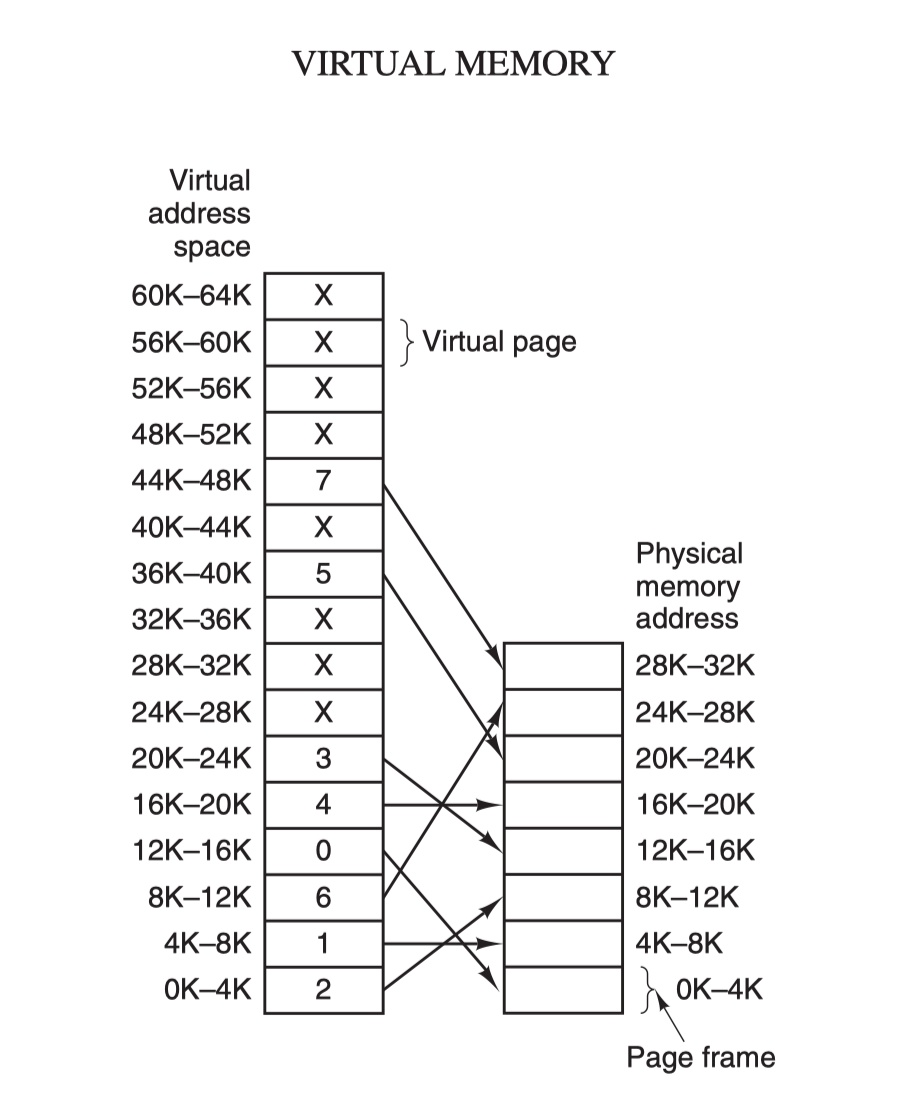
虚拟内存和物理内存 进程所操作的内存是一个虚拟内存,由OS来将这块虚拟内存映射到实际的物理内存上,这样做的好处是每个进程可以独占 128T 内存,任意地使用,系统上还运行了哪些进程已经与我们完全没有关系了(不需要考虑和其它进程之间的地址会冲突)。为变量和函数分配地址的活,我们交给链接器去自动安排就可以了。这一切都是因为虚拟内存能够提供内存地址空间的隔离,极大地扩展了可用空间。
操作系统管理着这种映射关系,所以你在写代码的时候,就不用再操心物理内存的使用情况了,你看到的内存就是虚拟内存。无论一个进程占用的内存资源有多大,在任一时刻,它需要的物理内存都是很少的。在这个推论的基础上,CPU 为每个进程只需要保留很少的物理内存就可以保证进程的正常执行了。
当程序中使用 malloc 等分配内存的接口时会将内存从待分配状态变成已分配状态,此时这块分配好的内存还没有真正映射到对应的物理内存上,这块内存就是未映射状态,因为它并没有被映射到相应的物理内存,直到对该块内存进行读写时,操作系统才会真正地为它分配物理内存。然后这个页面才能成为正常页面。
i7 处理器的页表也是存储在内存页里的,每个页表项都是 4 字节。所以,人们就将 1024 个页表项组成一张页表。这样一张页表的大小就刚好是 4K,占据一个内存页,这样就更加方便管理。而且,当前市场上主流的处理器也都选择将页大小定为 4K。
虚拟地址在计算机体系结构里可以评为特优的一项技术;超线程、流水线、多发射只是优;cache则只是良好(成本高)
CPU 如何找到真实地址
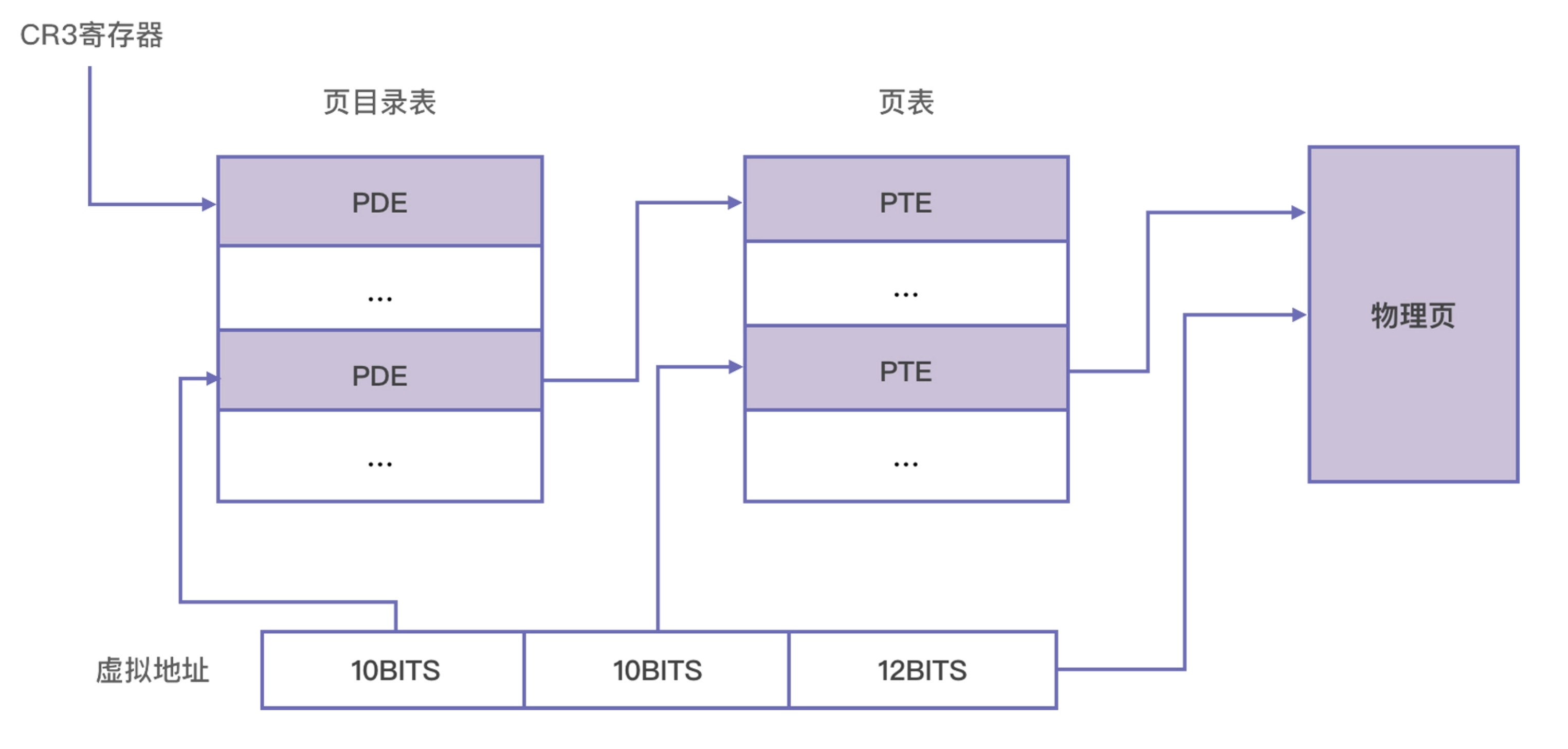
第一步是确定页目录基址。每个 CPU 都有一个页目录基址寄存器,最高级页表的基地址就存在这个寄存器里。在 X86 上,这个寄存器是 CR3。每一次计算物理地址时,MMU 都会从 CR3 寄存器中取出页目录所在的物理地址。
第二步是定位页目录项(PDE)。一个 32 位的虚拟地址可以拆成 10 位,10 位和 12 位三段,上一步找到的页目录表基址加上高 10 位的值乘以 4,就是页目录项的位置。这是因为,一个页目录项正好是 4 字节,所以 1024 个页目录项共占据 4096 字节,刚好组成一页,而 1024 个页目录项需要 10 位进行编码。这样,我们就可以通过最高 10 位找到该地址所对应的 PDE 了。
第三步是定位页表项(PTE)。页目录项里记录着页表的位置,CPU 通过页目录项找到页表的位置以后,再用中间 10 位计算页表中的偏移,可以找到该虚拟地址所对应的页表项了。页表项也是 4 字节的,所以一页之内刚好也是 1024 项,用 10 位进行编码。所以计算公式与上一步相似,用页表基址加上中间 10 位乘以 4,可以得到页表项的地址。
最后一步是确定真实的物理地址。上一步 CPU 已经找到页表项了,这里存储着物理地址,这才真正找到该虚拟地址所对应的物理页。虚拟地址的低 12 位,刚好可以对一页内的所有字节进行编码,所以我们用低 12 位来代表页内偏移。计算的公式是物理页的地址直接加上低 12 位。
前面我们分析的是 32 位操作系统,那对于 64 位机器是不是有点不同呢?在 64 位的机器上,使用了 48 位的虚拟地址,所以它需要使用 4 级页表。它的结构与 32 位的 3 级页表是相似的,只是多了一级页目录,定位的过程也从 32 位的 4 步变成了 5 步。
8086最开始是按不同的作用将内存分为代码段、数据段等,386开始按页开始管理内存(混合有按段管理)。 现代的操作系统都是采用段式管理来做基本的权限管理,而对于内存的分配、回收、调度都是依赖页式管理。
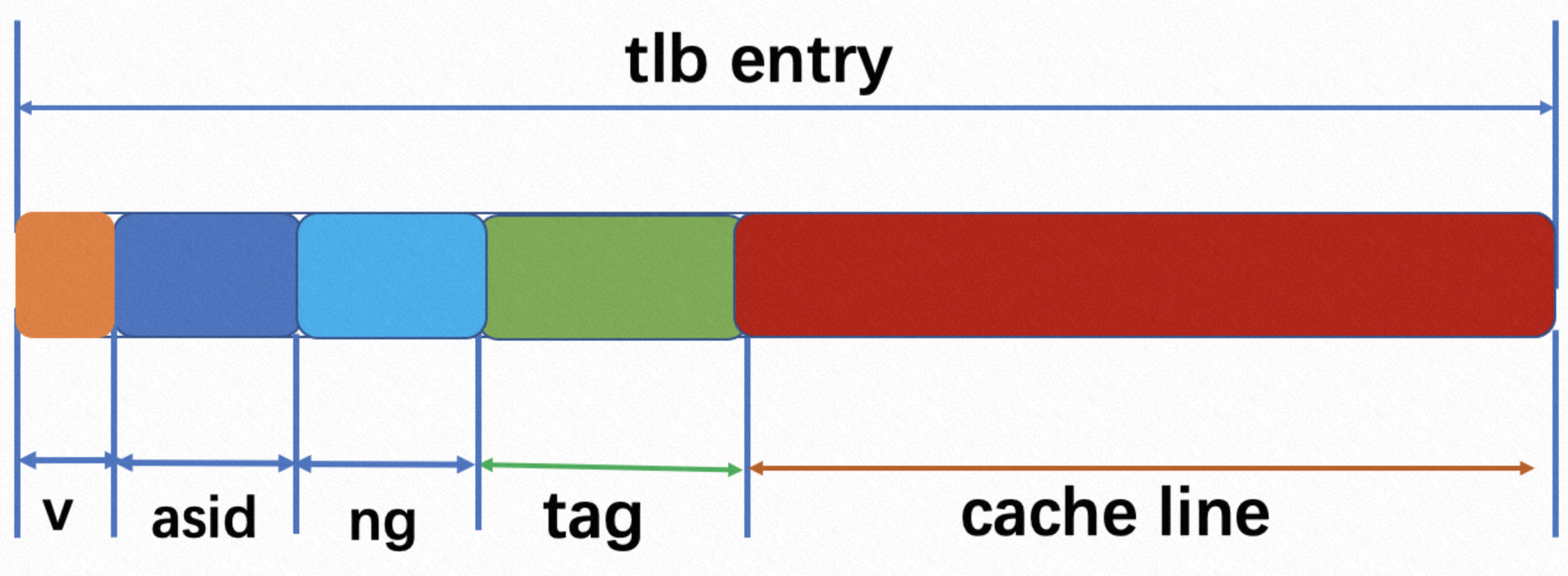
tlb:从各级cache里分配的一块专用空间,用来存放页表(虚拟地址和物理地址的对应关系)–存放在CPU cache里的索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #x86info -c Monitor/Mwait: min/max line size 64/64, ecx bit 0 support, enumeration extension SVM: revision 1, 32768 ASIDs Address Size: 48 bits virtual, 48 bits physical The physical package has 96 of 32768 possible cores implemented. L1 Data TLB (1G): Fully associative. 64 entries. L1 Instruction TLB (1G): Fully associative. 64 entries. L1 Data TLB (2M/4M): Fully associative. 64 entries. L1 Instruction TLB (2M/4M): Fully associative. 64 entries. L1 Data TLB (4K): Fully associative. 64 entries. L1 Instruction TLB (4K): Fully associative. 64 entries. L1 Data cache: Size: 32Kb 8-way associative. lines per tag=1 line size=64 bytes. L1 Instruction cache: Size: 32Kb 8-way associative. lines per tag=1 line size=64 bytes. L2 Data TLB (1G): Fully associative. 64 entries. L2 Instruction TLB (1G): Disabled. 0 entries. L2 Data TLB (2M/4M): 4-way associative. 2048 entries. L2 Instruction TLB (2M/4M): 2-way associative. 512 entries. L2 Data TLB (4K): 8-way associative. 2048 entries. L2 Instruction TLB (4K): 4-way associative. 512 entries. L2 cache: Size: 512Kb 8-way associative. lines per tag=1 line size=64 bytes. running at an estimated 2.55GHz
TLB(Translation Lookaside Buffer) Cache用于缓存少量热点内存地址的mapping关系。TLB和L1一样每个core独享,由于制造成本和工艺的限制,响应时间需要控制在CPU Cycle级别的Cache容量只能存储几十个对象。那么TLB Cache在应对大量热点数据Virual Address转换的时候就显得捉襟见肘了。我们来算下按照标准的Linux页大小(page size) 4K,一个能缓存64元素的TLB Cache只能涵盖4K*64 = 256K的热点数据的内存地址,显然离理想非常遥远的。于是Huge Page就产生了。
These are typical performance levels of a TLB :
Size: 12 bits – 4,096 entries
Hit time: 0.5 – 1 clock cycle
Miss penalty: 10 – 100 clock cycles
Miss rate: 0.01 – 1% (20–40% for sparse/graph applications)
TLB也分为iTLB和dTLB, 分别顶在L1i和L1d前面(比L1更小更快,每个core独享tlb)
以intel x86为例,一个cpu也就32到64个tlb, 超出这个范畴,就得去查页表。 每个型号的cpu都不一样,需要查看spec
进程分配到的不是内存的实际物理地址,而是一个经过映射后的虚拟地址,这么做的原因是为了让每个应用可以独享完整的虚拟地址,而不需要每个进程互相考虑使用内存的协调。
但是虚拟地址到物理地址的映射需要巨大的映射空间,如何用更少的内存消耗来管理庞大的内存(如果没有分级,4G内存对应着4MB的索引空间,一级比如使用4K就够了,多个二级使总共用4M,但是这4M大部分时候不用提前分配),Linux通过四级表项来做虚拟地址到物理地址的映射,这样4Kb就能管理256T内存,4级映射是时间换空间的典型案例。不过一般而言一个进程是远远用不了256T内存的,那么这四级映射大部分时候都是没必要的,所以实际用不了那么大的PageTable。
虚拟内存的核心原理 是:为每个程序设置一段”连续”的虚拟地址空间,把这个地址空间分割成多个具有连续地址范围的页 (page),并把这些页和物理内存做映射,在程序运行期间动态映射到物理内存。当程序引用到一段在物理内存的地址空间时,由硬件立刻执行必要的映射;而当程序引用到一段不在物理内存中的地址空间时,由操作系统负责将缺失的部分装入物理内存并重新执行失败的指令:
在 内存管理单元(Memory Management Unit,MMU)进行地址转换时,如果页表项的 “在/不在” 位是 0,则表示该页面并没有映射到真实的物理页框,则会引发一个 缺页中断 ,CPU 陷入操作系统内核,接着操作系统就会通过页面置换算法选择一个页面将其换出 (swap),以便为即将调入的新页面腾出位置,如果要换出的页面的页表项里的修改位已经被设置过,也就是被更新过,则这是一个脏页 (dirty page),需要写回磁盘更新改页面在磁盘上的副本,如果该页面是”干净”的,也就是没有被修改过,则直接用调入的新页面覆盖掉被换出的旧页面即可。
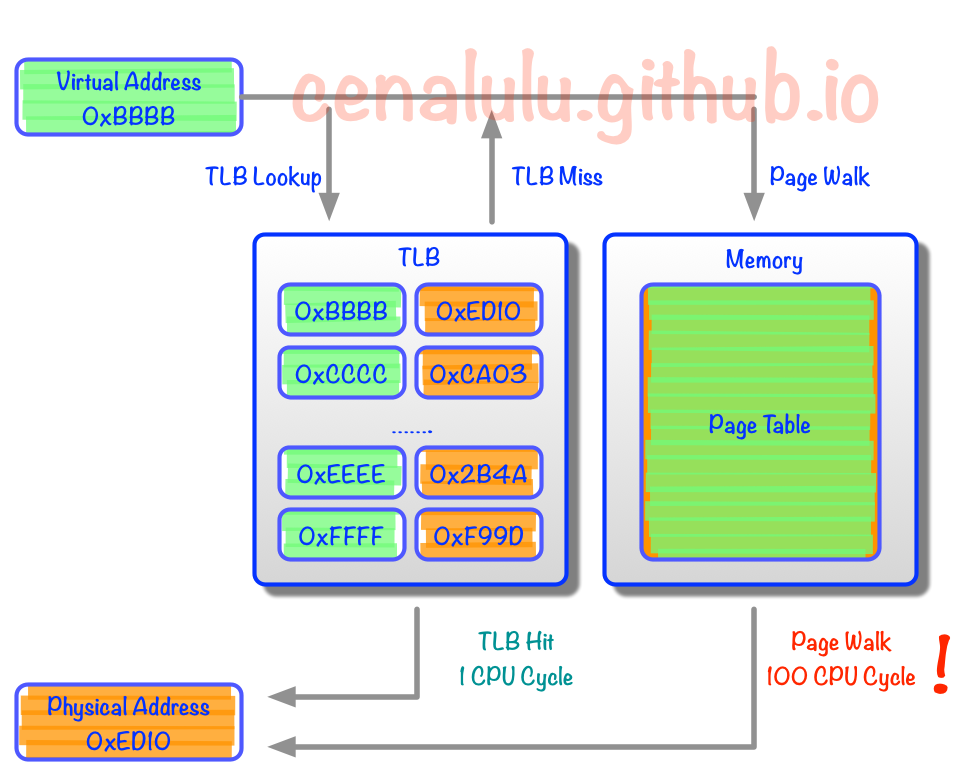
还需要了解的一个概念是转换检测缓冲器(Translation Lookaside Buffer,TLB,每个core一个TLB,类似L1 cache) ,也叫快表,是用来加速虚拟地址映射的,因为虚拟内存的分页机制,页表一般是保存内存中的一块固定的存储区,导致进程通过 MMU 访问内存比直接访问内存多了一次内存访问,性能至少下降一半,因此需要引入加速机制,即 TLB 快表,TLB 可以简单地理解成页表的高速缓存,保存了最高频被访问的页表项,由于一般是硬件实现的,因此速度极快,MMU 收到虚拟地址时一般会先通过硬件 TLB 查询对应的页表号,若命中且该页表项的访问操作合法,则直接从 TLB 取出对应的物理页框号返回,若不命中则穿透到内存页表里查询,并且会用这个从内存页表里查询到最新页表项替换到现有 TLB 里的其中一个,以备下次缓存命中。
如果没有TLB那么每一次内存映射都需要查表四次然后才是一次真正的内存访问,代价比较高。
有了TLB之后,CPU访问某个虚拟内存地址的过程如下
CPU产生一个虚拟地址
MMU从TLB中获取页表,翻译成物理地址
MMU把物理地址发送给L1/L2/L3/内存
L1/L2/L3/内存将地址对应数据返回给CPU
由于第2步是类似于寄存器的访问速度,所以如果TLB能命中,则虚拟地址到物理地址的时间开销几乎可以忽 略。tlab miss比较高的话开启内存大页对性能是有提升的,但是会有一定的内存浪费。
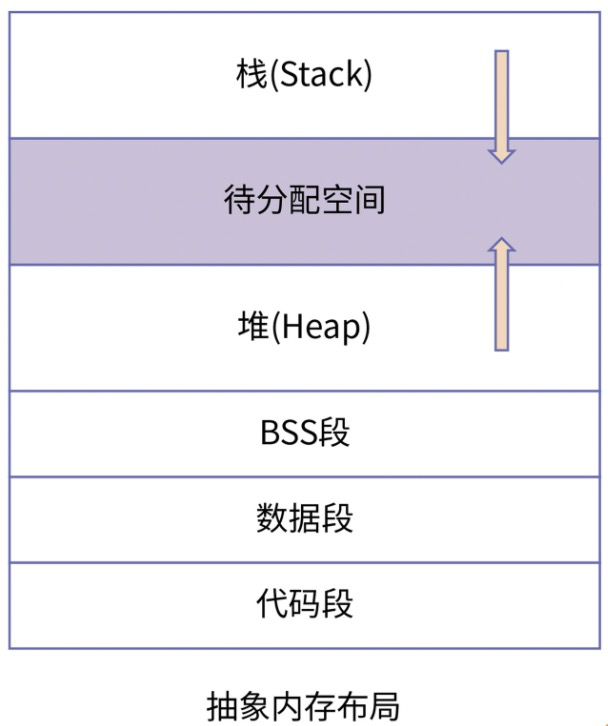
内存布局
代码段:CPU 运行一个程序,实质就是在顺序执行该程序的机器码。一个程序的机器码会被组织到同一个地方。
数据段:程序在运行过程中必然要操作数据。这其中,对于有初值的变量,它的初始值会存放在程序的二进制文件中,而且,这些数据部分也会被装载到内存中,即程序的数据段。数据段存放的是程序中已经初始化且不为 0 的全局变量和静态变量。
BSS 段: 对于未初始化的全局变量和静态变量,因为编译器知道它们的初始值都是 0,因此便不需要再在程序的二进制映像中存放这么多 0 了,只需要记录他们的大小即可,这便是BSS段 。BSS 段这个缩写名字是 Block Started by Symbol,但很多人可能更喜欢把它记作 Better Save Space 的缩写。
堆是程序员可以自由申请的空间,当我们在写程序时要保存数据,优先会选择堆;
栈是函数执行时的活跃记录,这将是我们下一节课要重点分析的内容。
数据段和 BSS 段里存放的数据也只能是部分数据,主要是全局变量和静态变量,但程序在运行过程中,仍然需要记录大量的临时变量,以及运行时生成的变量,这里就需要新的内存区域了,即程序的堆空间跟栈空间。与代码段以及数据段不同的是,堆和栈并不是从磁盘中加载,它们都是由程序在运行的过程中申请,在程序运行结束后释放。
总的来说,一个程序想要运行起来所需要的几块基本内存区域:代码段、数据段、BSS 段、堆空间和栈空间。下面就是内存布局的示意图:
其它内存形态:
存放加载的共享库的内存空间:如果一个进程依赖共享库,那对应的,该共享库的代码段、数据段、BSS 段也需要被加载到这个进程的地址空间中。
共享内存段:我们可以通过系统调用映射一块匿名区域作为共享内存,用来进行进程间通信。
内存映射文件:我们也可以将磁盘的文件映射到内存中,用来进行文件编辑或者是类似共享内存的方式进行进程通信。
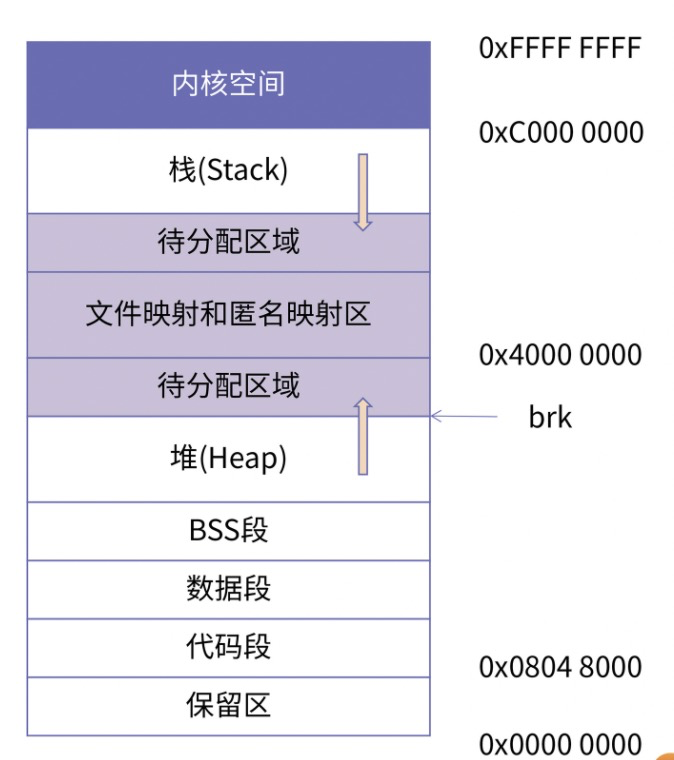
32位 x86机器下,通过 cat /proc/pid/maps 看到的进程所使用的内存分配空间:
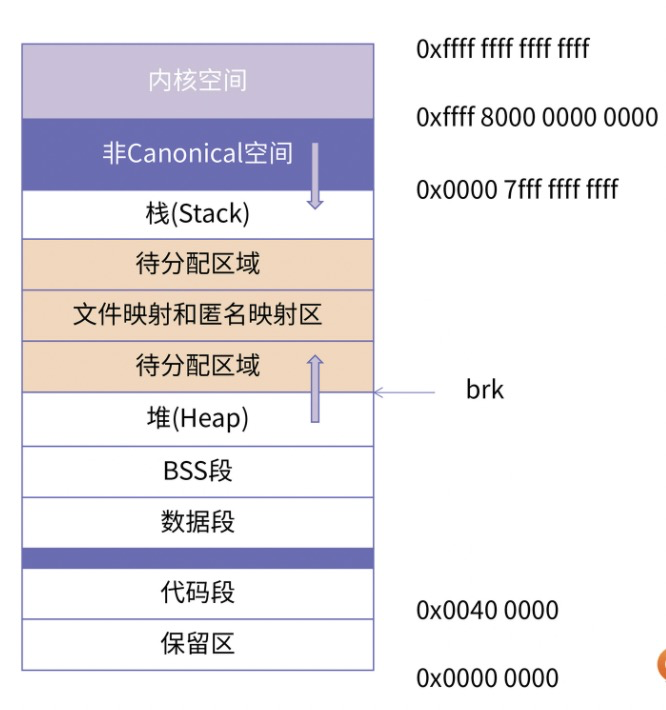
64位 x86机器下,通过 cat /proc/pid/maps 看到的进程所使用的内存分配空间:
目前的 64 系统下的寻址空间是 2^48(太多用不完,高16位为Canonical空间),即 256TB。而且根据 canonical address 的划分,地址空间天然地被分割成两个区间,分别是 0x0 - 0x00007fffffffffff 和 0xffff800000000000 - 0xffffffffffffffff。这样就直接将低 128T 的空间划分为用户空间,高 128T 划分为内核空间。
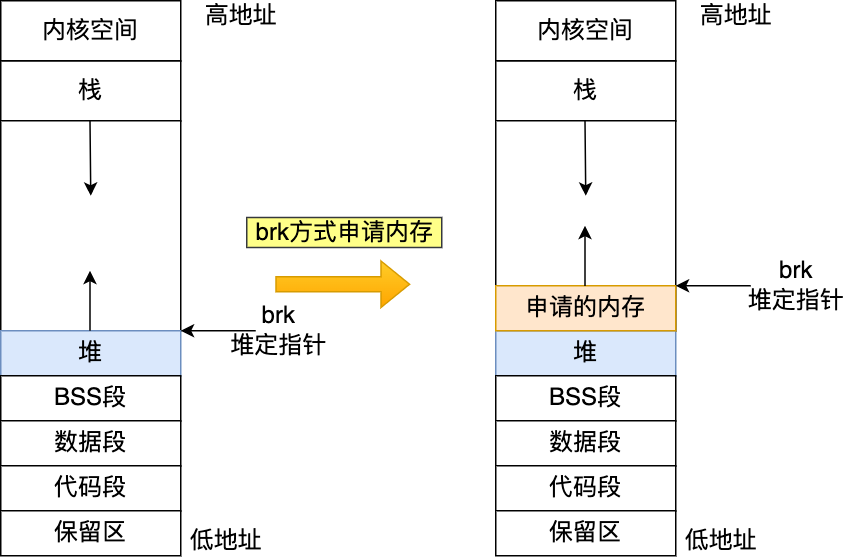
brk:内核维护指向堆的顶部
Java程序对应的maps:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 #cat /proc/14011/maps 00400000-00401000 r-xp 00000000 08:03 3935494 /opt/taobao/install/ajdk-8.3.6_fp9-b30/bin/java 00600000-00601000 rw-p 00000000 08:03 3935494 /opt/taobao/install/ajdk-8.3.6_fp9-b30/bin/java ed400000-1001e0000 rw-p 00000000 00:00 0 1001e0000-140000000 ---p 00000000 00:00 0 7f86e8000000-7f8a7fc00000 rw-p 00000000 00:00 0 .. 7f8aaecfa000-7f8aaeff8000 rw-p 00000000 00:00 0 7f8aaeff8000-7f8aaf000000 r-xp 00000000 08:03 3935973 /opt/taobao/install/ajdk-8.3.6_fp9-b30/jre/lib/amd64/libmanagement.so 7f8aaf000000-7f8aaf1ff000 ---p 00008000 08:03 3935973 /opt/taobao/install/ajdk-8.3.6_fp9-b30/jre/lib/amd64/libmanagement.so 7f8aaf1ff000-7f8aaf200000 rw-p 00007000 08:03 3935973 /opt/taobao/install/ajdk-8.3.6_fp9-b30/jre/lib/amd64/libmanagement.so .. 7f8ad8cea000-7f8ad8cec000 r--s 00004000 08:05 7078938 /home/admin/drds-worker/lib/netty-handler-proxy-4.1.17.Final.jar 7f8ad8cec000-7f8ad8cf5000 r--s 0006f000 08:05 7078952 /home/admin/drds-worker/lib/log4j-1.2.17.jar 7f8ad8cf5000-7f8ad8cf7000 r--s 00005000 08:05 7078960 /home/admin/drds-worker/lib/objenesis-1.0.jar 7f8ad8cf7000-7f8ad8cff000 r--s 0004b000 08:05 7078929 /home/admin/drds-worker/lib/spring-aop-3.2.18.RELEASE.jar 7f8ad8cff000-7f8ad8d00000 ---p 00000000 00:00 0 7f8ad8d00000-7f8ad9000000 rw-p 00000000 00:00 0 7f8ad90e3000-7f8ad90ef000 r--s 000b6000 08:05 7079066 /home/admin/drds-worker/lib/transmittable-thread-local-2.5.1.jar 7f8ad9dd8000-7f8ad9dfe000 r--s 0026f000 08:05 7078997 /home/admin/drds-worker/lib/druid-1.1.7-preview_12.jar 7f8ad9dfe000-7f8ad9dff000 ---p 00000000 00:00 0 7f8ad9dff000-7f8ad9eff000 rw-p 00000000 00:00 0 7f8ad9eff000-7f8ad9f00000 ---p 00000000 00:00 0 7f8ad9f00000-7f8ada200000 rw-p 00000000 00:00 0 7f8ada200000-7f8ada202000 r--s 00003000 08:05 7078944 /home/admin/drds-worker/lib/liberate-rest-1.0.2.jar 7f8ada202000-7f8ada206000 r--s 00036000 08:05 7078912 /home/admin/drds-worker/lib/jackson-core-lgpl-1.9.6.jar 7f8ada289000-7f8ada28b000 r--s 00001000 08:05 7078998 /home/admin/drds-worker/lib/opencensus-contrib-grpc-metrics-0.10.0.jar 7f8ada2b5000-7f8ada2b9000 r--s 0003a000 08:05 7079099 /home/admin/drds-worker/lib/tddl-repo-mysql-5.2.7-2-EXTEND-HOTMAPPING-SNAPSHOT.jar 7f8ada2b9000-7f8ada2c6000 r--s 0007d000 08:05 7078982 /home/admin/drds-worker/lib/grpc-core-1.9.0.jar 7f8ada2c6000-7f8ada2d6000 r--s 00149000 08:05 7079000 /home/admin/drds-worker/lib/protobuf-java-3.5.1.jar 7f8ada2d6000-7f8ada2db000 r--s 0002b000 08:05 7078927 /home/admin/drds-worker/lib/tddl-net-5.2.7-2-EXTEND-HOTMAPPING-SNAPSHOT.jar 7f8ada2db000-7f8ada2e0000 r--s 0002a000 08:05 7078939 /home/admin/drds-worker/lib/grpc-netty-1.9.0.jar 7f8ada2e0000-7f8ada2ff000 r--s 00150000 08:05 7078965 /home/admin/drds-worker/lib/mockito-core-1.9.5.jar 7f8ada2ff000-7f8ada300000 ---p 00000000 00:00 0 7f8ada300000-7f8ada600000 rw-p 00000000 00:00 0 7f8ada600000-7f8ada601000 r--s 00003000 08:05 7079089 /home/admin/drds-worker/lib/ushura-1.0.jar 7f8ae9ba2000-7f8ae9baa000 r-xp 00000000 08:03 3935984 /opt/taobao/install/ajdk-8.3.6_fp9-b30/jre/lib/amd64/libzip.so 7f8ae9baa000-7f8ae9da9000 ---p 00008000 08:03 3935984 /opt/taobao/install/ajdk-8.3.6_fp9-b30/jre/lib/amd64/libzip.so 7f8ae9da9000-7f8ae9daa000 rw-p 00007000 08:03 3935984 /opt/taobao/install/ajdk-8.3.6_fp9-b30/jre/lib/amd64/libzip.so 7f8ae9daa000-7f8ae9db6000 r-xp 00000000 08:03 1837851 /usr/lib64/libnss_files-2.17.so;614d5f07 (deleted) 7f8ae9db6000-7f8ae9fb5000 ---p 0000c000 08:03 1837851 /usr/lib64/libnss_files-2.17.so;614d5f07 (deleted) 7f8ae9fb5000-7f8ae9fb6000 r--p 0000b000 08:03 1837851 /usr/lib64/libnss_files-2.17.so;614d5f07 (deleted) 7f8ae9fb6000-7f8ae9fb7000 rw-p 0000c000 08:03 1837851 /usr/lib64/libnss_files-2.17.so;614d5f07 (deleted) 7f8ae9fb7000-7f8ae9fbd000 rw-p 00000000 00:00 0 7f8ae9fbd000-7f8ae9fe7000 r-xp 00000000 08:03 3935961 /opt/taobao/install/ajdk-8.3.6_fp9-b30/jre/lib/amd64/libjava.so 7f8aebc03000-7f8aebc05000 r--s 00008000 08:05 7079098 /home/admin/drds-worker/lib/grpc-stub-1.9.0.jar 7f8aebc05000-7f8aebc07000 r--s 00020000 08:05 7078930 /home/admin/drds-worker/lib/tddl-group-5.2.7-2-EXTEND-HOTMAPPING-SNAPSHOT.jar 7f8aebc07000-7f8aebc1f000 r--s 001af000 08:05 7079085 /home/admin/drds-worker/lib/aspectjweaver-1.8.5.jar 7f8aebc1f000-7f8aebc20000 ---p 00000000 00:00 0 7f8aebc20000-7f8aebd20000 rw-p 00000000 00:00 0 7f8aebd20000-7f8aebd35000 r-xp 00000000 08:03 1837234 /usr/lib64/libgcc_s-4.8.5-20150702.so.1 7f8aebd35000-7f8aebf34000 ---p 00015000 08:03 1837234 /usr/lib64/libgcc_s-4.8.5-20150702.so.1 7f8aebf34000-7f8aebf35000 r--p 00014000 08:03 1837234 /usr/lib64/libgcc_s-4.8.5-20150702.so.1 7f8aebf35000-7f8aebf36000 rw-p 00015000 08:03 1837234 /usr/lib64/libgcc_s-4.8.5-20150702.so.1 7f8aebf36000-7f8aec037000 r-xp 00000000 08:03 1837579 /usr/lib64/libm-2.17.so;614d5f07 (deleted) 7f8aec037000-7f8aec236000 ---p 00101000 08:03 1837579 /usr/lib64/libm-2.17.so;614d5f07 (deleted) 7f8aeca17000-7f8aeca18000 rw-p 0000d000 08:03 3936057 /opt/taobao/install/ajdk-8.3.6_fp9-b30/lib/amd64/jli/libjli.so 7f8aeca18000-7f8aeca2d000 r-xp 00000000 08:03 1836998 /usr/lib64/libz.so.1.2.7 7f8aeca2d000-7f8aecc2c000 ---p 00015000 08:03 1836998 /usr/lib64/libz.so.1.2.7 7f8aecc2c000-7f8aecc2d000 r--p 00014000 08:03 1836998 /usr/lib64/libz.so.1.2.7 7f8aecc2d000-7f8aecc2e000 rw-p 00015000 08:03 1836998 /usr/lib64/libz.so.1.2.7 7f8aecc2e000-7f8aecc45000 r-xp 00000000 08:03 1836993 /usr/lib64/libpthread-2.17.so;614d5f07 (deleted) 7f8aecc45000-7f8aece44000 ---p 00017000 08:03 1836993 /usr/lib64/libpthread-2.17.so;614d5f07 (deleted) 7f8aece44000-7f8aece45000 r--p 00016000 08:03 1836993 /usr/lib64/libpthread-2.17.so;614d5f07 (deleted) 7f8aece45000-7f8aece46000 rw-p 00017000 08:03 1836993 /usr/lib64/libpthread-2.17.so;614d5f07 (deleted) 7f8aece46000-7f8aece4a000 rw-p 00000000 00:00 0 7f8aece4a000-7f8aecea1000 r-xp 00000000 08:03 3936059 /opt/taobao/install/ajdk-8.3.6_fp9-b30/lib/amd64/libjemalloc.so.2 7f8aecea1000-7f8aed0a0000 ---p 00057000 08:03 3936059 /opt/taobao/install/ajdk-8.3.6_fp9-b30/lib/amd64/libjemalloc.so.2 7f8aed0a0000-7f8aed0a3000 rw-p 00056000 08:03 3936059 /opt/taobao/install/ajdk-8.3.6_fp9-b30/lib/amd64/libjemalloc.so.2 7f8aed0a3000-7f8aed0b5000 rw-p 00000000 00:00 0 7f8aed0b5000-7f8aed0d7000 r-xp 00000000 08:03 1837788 /usr/lib64/ld-2.17.so;614d5f07 (deleted) 7f8aed0d7000-7f8aed0dc000 r--s 00038000 08:05 7079012 /home/admin/drds-worker/lib/org.osgi.core-4.2.0.jar 7f8aed0dc000-7f8aed0e1000 r--s 00038000 08:05 7079018 /home/admin/drds-worker/lib/commons-beanutils-1.9.3.jar 7f8aed0e1000-7f8aed0e3000 r--s 00001000 08:05 7079033 /home/admin/drds-worker/lib/j2objc-annotations-1.1.jar 7f8aed0e3000-7f8aed0e8000 r--s 00017000 08:05 7079056 /home/admin/drds-worker/lib/hibernate-jpa-2.1-api-1.0.0.Final.jar 7f8aed1be000-7f8aed1c6000 rw-s 00000000 08:04 393222 /tmp/hsperfdata_admin/14011 7f8aed1c6000-7f8aed1ca000 ---p 00000000 00:00 0 7f8aed1ca000-7f8aed2cd000 rw-p 00000000 00:00 0 7f8aed2cd000-7f8aed2ce000 r--s 00005000 08:05 7079029 /home/admin/drds-worker/lib/jersey-apache-connector-2.26.jar 7f8aed2ce000-7f8aed2d1000 r--s 0000a000 08:05 7079027 /home/admin/drds-worker/lib/metrics-jvm-1.7.4.jar 7f8aed2d1000-7f8aed2d3000 r--s 00006000 08:05 7078961 /home/admin/drds-worker/lib/tddl-client-5.2.7-2-EXTEND-HOTMAPPING-SNAPSHOT.jar 7f8aed2d3000-7f8aed2d4000 rw-p 00000000 00:00 0 7f8aed2d4000-7f8aed2d5000 r--p 00000000 00:00 0 7f8aed2d5000-7f8aed2d6000 rw-p 00000000 00:00 0 7f8aed2d6000-7f8aed2d7000 r--p 00021000 08:03 1837788 /usr/lib64/ld-2.17.so;614d5f07 (deleted) 7f8aed2d7000-7f8aed2d8000 rw-p 00022000 08:03 1837788 /usr/lib64/ld-2.17.so;614d5f07 (deleted) 7f8aed2d8000-7f8aed2d9000 rw-p 00000000 00:00 0 7fff087e0000-7fff08801000 rw-p 00000000 00:00 0 [stack] 7fff089c2000-7fff089c4000 r-xp 00000000 00:00 0 [vdso] ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
内存管理和使用 malloc()分配内存时:
如果用户分配的内存小于 128 KB,则通过 brk() 申请内存–在堆顶分配;
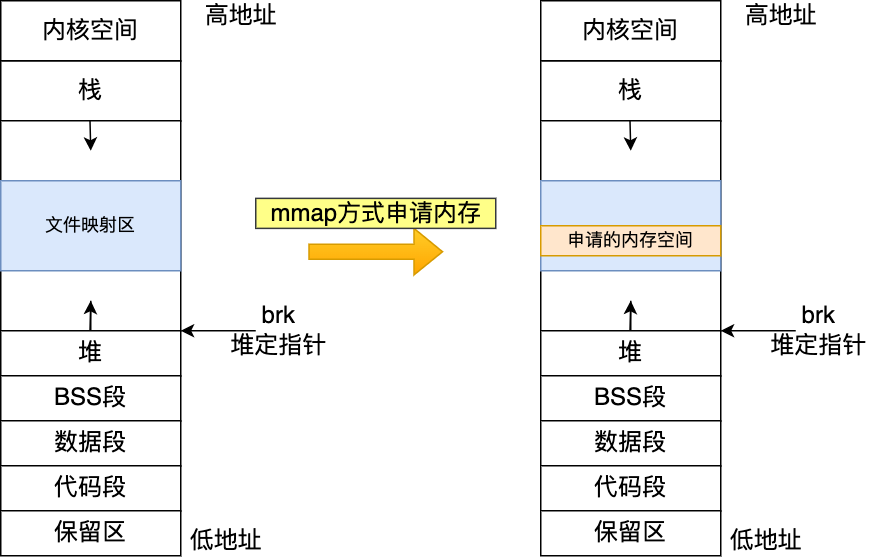
如果用户分配的内存大于 128 KB,则通过 mmap() 申请内存–从文件映射区域分配;
对于 「malloc 申请的内存,free 释放内存会归还给操作系统吗?」:
malloc 通过 brk() 方式申请的内存,free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用 –小内存分配避免反复调用系统操作导致上下文切换,缺点是没回收容易导致内存碎片进而浪费内存。brk分配出来的内存在maps中显示有heap字样;
malloc 通过 mmap() 方式申请的内存,free 释放内存的时候,会把内存归还给操作系统,内存得到真正的释放 。并且mmap分配的虚拟内存都是缺页状态的。
malloc和mmap glibc中的malloc/free 负责向内核批发内存(不需要每次分配都真正地去调用内核态来分配),分配好的内存按大小分成不同的桶,每次malloc的时候实际到对应的桶上摘取对应的块(slab)就好,用完free的时候挂回去。
mmap映射内存
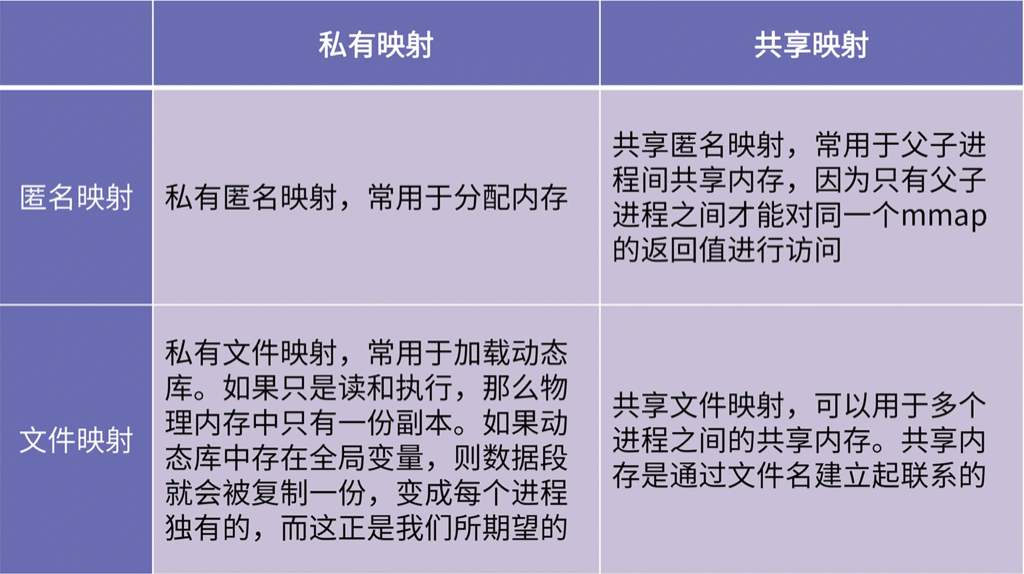
私有匿名映射常用于分配内存,也就是申请堆内存
分桶式内存管理比简单算法无论是在算法效率方面,还是在碎片控制方面都有很大的提升。但它的缺陷也很明显:区域内部的使用率不够高和动态扩展能力不够好。例如,4 字节的区域提前消耗完了,但 8 字节的空闲区域还有很多,此时就会面临两难选择,如果直接分配 8 字节的区域,则区域内部浪费就比较多,如果不分配,则明明还有空闲区域,却无法成功分配。
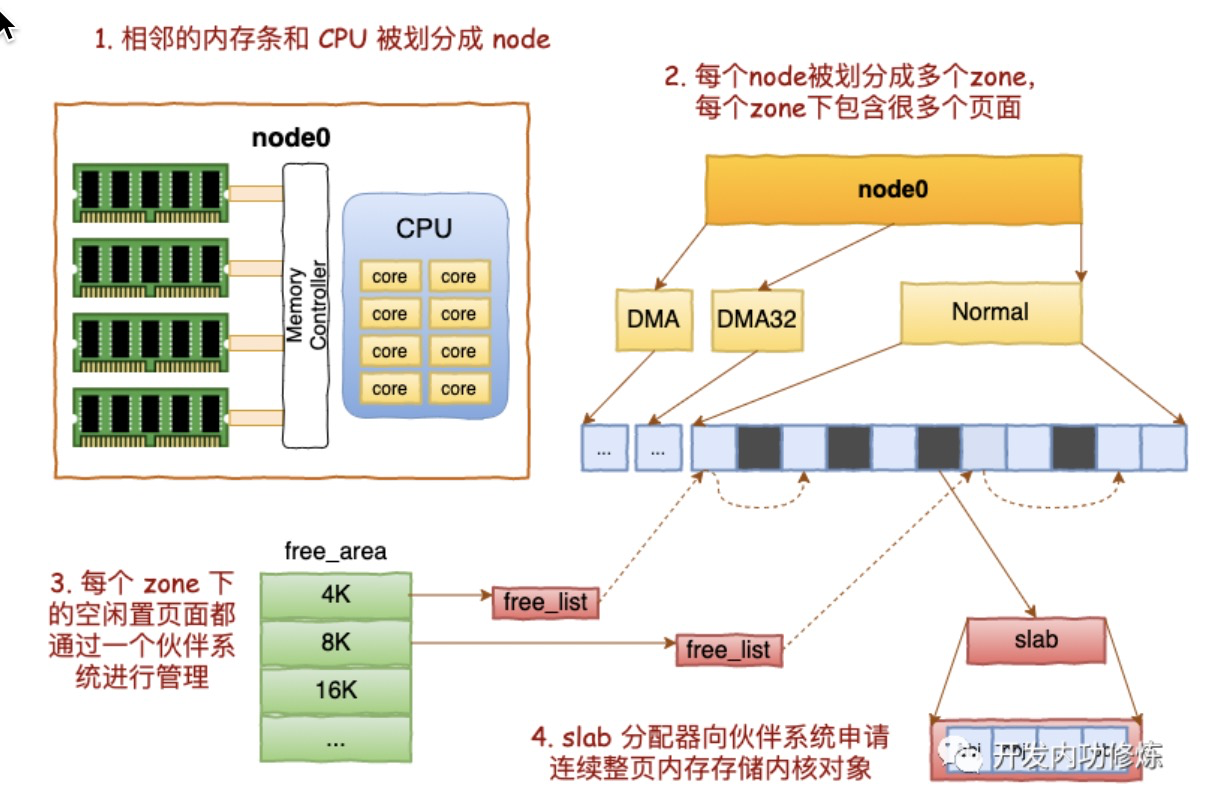
为了解决以上问题所以搞了buddy
node->zone->buddy->slab
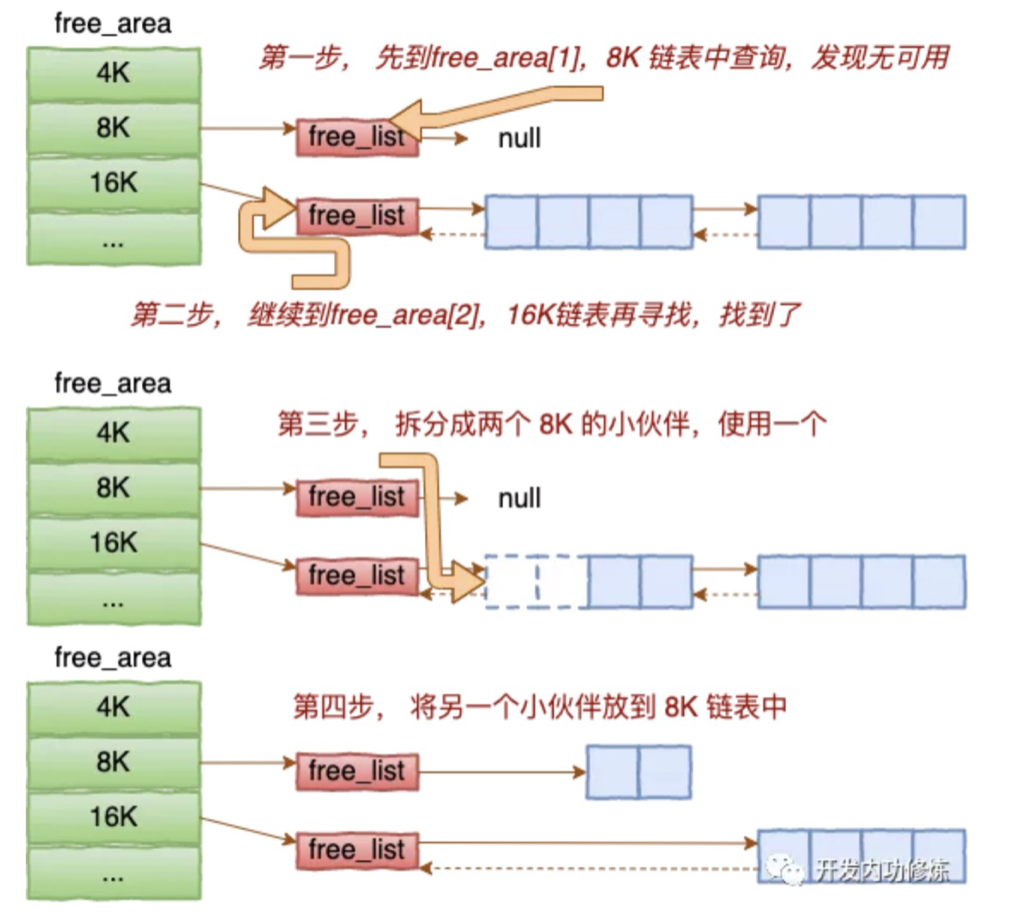
假如需要分配一块 4 字节大小的空间,但是在 4 字节的 free list 上找不到空闲区域,系统就会往上找,假如 8 字节和 16 字节的 free list 中也没有空闲区域,就会一直向上找到 32 字节的 free list。
伙伴系统不会直接把 32 的空闲区域分配出去,因为这样做的话,会带来巨大的浪费。它会先把 32 字节分成两个 16 字节,把后边一个挂入到 16 字节的 free list 中。然后继续拆分前一半。前一半继续拆成两个 8 字节,再把后一半挂入到 8 字节的 free list,最后,把前一半 8 字节拿去分配,当然这里也要继续拆分成两个 4 字节的空闲区域,其中一个用于本次 malloc 分配,另一个则挂入到 4 字节的 free list。分配后的内存的状态如下所示:
The zones are :
DMA is the low 16 MBytes of memory. At this point it exists for historical reasons; once upon what is now a long time ago, there was hardware that could only do DMA into this area of physical memory.DMA32 exists only in 64-bit Linux; it is the low 4 GBytes of memory, more or less. It exists because the transition to large memory 64-bit machines has created a class of hardware that can only do DMA to the low 4 GBytes of memory.(This is where people mutter about everything old being new again.)NormalHighMem exists only on 32-bit Linux; it is all RAM above 896 MB, including RAM above 4 GB on sufficiently large machines.
每个zone下很多pages(大小为4K),buddy就是这些Pages的组织管理者
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 # cat /proc/zoneinfo |grep Node -A10 Node 0, zone DMA pages free 3972 min 0 low 0 high 0 scanned 0 spanned 4095 present 3993 managed 3972 nr_free_pages 3972 nr_alloc_batch 0 -- Node 0, zone DMA32 pages free 361132 min 30 low 37 high 45 scanned 0 spanned 1044480 present 430773 managed 361133 nr_free_pages 361132 nr_alloc_batch 8 -- Node 0, zone Normal pages free 96017308 min 16864 low 21080 high 25296 scanned 0 spanned 200736768 present 200736768 managed 197571780 nr_free_pages 96017308 nr_alloc_batch 3807 # free -g total used free shared buff/cache available Mem: 755 150 367 3 236 589 Swap: 0 0 0
每个页面大小是4K,很容易可以计算出每个 zone 的大小。比如对于上面 Node0 的 Normal, 197571780 * 4K/(1024*1024) = 753 GB。
dmidecode 可以查看到服务器上插着的所有内存条,也可以看到它是和哪个CPU直接连接的。每一个CPU以及和他直连的内存条组成了一个 node(节点)
/proc/buddyinfo /proc/buddyinfo记录了可用内存 的情况。
Normal那行之后的第二列表示: 643847*2^1*Page_Size(4K) ; 第三列表示: 357451*2^2*Page_Size(4K) ,高阶内存指的是2^3及更大的内存块。
应用申请大块连续内存(高阶内存,一般之4阶及以上, 也就是64K以上–2^4*4K)时,容易导致卡顿。这是因为大块连续内存确实系统需要触发回收或者碎片整理,需要一定的时间。
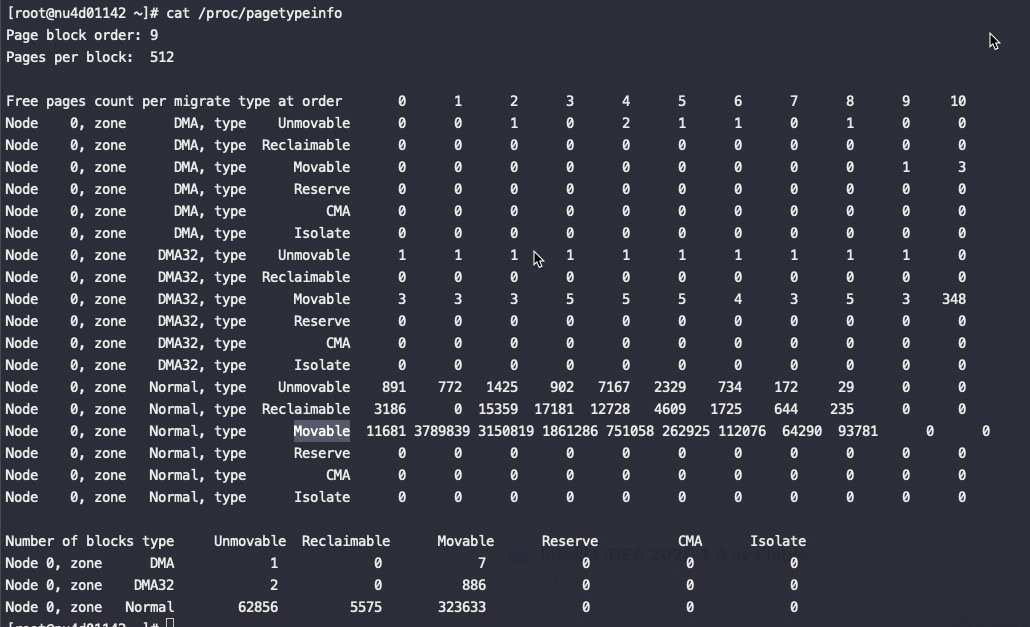
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 #cat /proc/buddyinfo Node 0, zone DMA 1 1 1 0 2 1 1 0 1 1 3 Node 0, zone DMA32 2 5 3 6 2 0 4 4 2 2 404 Node 0, zone Normal 243430 643847 357451 32531 9508 6159 3917 2960 17172 2633 22854 如果是多node机器: #cat /proc/buddyinfo Node 0, zone DMA 4 6 3 2 3 3 1 1 2 3 1 Node 0, zone DMA32 1607 1619 1552 1520 1370 1065 827 576 284 105 13 Node 0, zone Normal 38337 145731 222145 199776 151452 91969 38086 10037 1762 104 1 Node 1, zone Normal 21521 147637 299185 245533 172451 81459 19451 7198 579 3 0 Node 2, zone Normal 68427 538670 446906 229138 123555 62539 21161 4407 1122 166 274 Node 3, zone Normal 27353 54601 114355 123568 101892 79098 48610 21036 5021 475 6 Node 4, zone Normal 45802 42758 8573 184548 148397 70540 20772 4147 381 148 109 Node 5, zone Normal 19514 39583 140493 167901 134774 61888 22998 6326 457 32 0 Node 6, zone Normal 104493 378362 355158 93138 12928 2248 1019 663 172 40 121 Node 7, zone Normal 34185 256886 249560 95547 54526 51022 28180 9757 2038 1351 280 [root@hygon8 15:50 /root] #numactl -H available: 8 nodes (0-7) node 0 cpus: 0 1 2 3 4 5 6 7 64 65 66 67 68 69 70 71 node 0 size: 64083 MB node 0 free: 49838 MB node 1 cpus: 8 9 10 11 12 13 14 15 72 73 74 75 76 77 78 79 node 1 size: 64480 MB node 1 free: 43596 MB node 2 cpus: 16 17 18 19 20 21 22 23 80 81 82 83 84 85 86 87 node 2 size: 64507 MB node 2 free: 44216 MB node 3 cpus: 24 25 26 27 28 29 30 31 88 89 90 91 92 93 94 95 node 3 size: 64507 MB node 3 free: 51095 MB node 4 cpus: 32 33 34 35 36 37 38 39 96 97 98 99 100 101 102 103 node 4 size: 64507 MB node 4 free: 32877 MB node 5 cpus: 40 41 42 43 44 45 46 47 104 105 106 107 108 109 110 111 node 5 size: 64507 MB node 5 free: 33430 MB node 6 cpus: 48 49 50 51 52 53 54 55 112 113 114 115 116 117 118 119 node 6 size: 64507 MB node 6 free: 14233 MB node 7 cpus: 56 57 58 59 60 61 62 63 120 121 122 123 124 125 126 127 node 7 size: 63483 MB node 7 free: 36577 MB node distances: node 0 1 2 3 4 5 6 7 0: 10 16 16 16 28 28 22 28 1: 16 10 16 16 28 28 28 22 2: 16 16 10 16 22 28 28 28 3: 16 16 16 10 28 22 28 28 4: 28 28 22 28 10 16 16 16 5: 28 28 28 22 16 10 16 16 6: 22 28 28 28 16 16 10 16 7: 28 22 28 28 16 16 16 10 [root@hygon8 15:51 /root] #cat /proc/pagetypeinfo Page block order: 9 Pages per block: 512 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 0, zone DMA, type Unmovable 1 2 1 1 3 2 0 0 1 0 0 Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 3 1 Node 0, zone DMA, type Reclaimable 3 4 2 1 0 1 1 1 1 0 0 Node 0, zone DMA, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone DMA32, type Unmovable 151 164 162 165 140 78 19 8 0 0 0 Node 0, zone DMA32, type Movable 1435 1430 1374 1335 1214 974 798 563 281 98 12 Node 0, zone DMA32, type Reclaimable 21 25 16 20 16 13 10 5 3 7 1 Node 0, zone DMA32, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone Normal, type Unmovable 4849 6607 4133 1629 654 121 15 3 0 0 0 Node 0, zone Normal, type Movable 21088 >100000 >100000 >100000 >100000 90231 37197 9379 1552 83 1 Node 0, zone Normal, type Reclaimable 153 139 3012 3113 2437 1617 874 655 210 21 0 Node 0, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate Node 0, zone DMA 1 6 1 0 0 Node 0, zone DMA32 27 974 15 0 0 Node 0, zone Normal 856 30173 709 0 0 Page block order: 9 Pages per block: 512 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 1, zone Normal, type Unmovable 842 2898 2495 1316 490 102 23 1 2 0 0 Node 1, zone Normal, type Movable 22484 >100000 >100000 >100000 >100000 80084 18922 6889 48 4 0 Node 1, zone Normal, type Reclaimable 1 2022 3850 3534 2582 1273 506 308 529 0 0 Node 1, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 1, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate Node 1, zone Normal 810 31221 737 0 0 Page block order: 9 Pages per block: 512 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 2, zone Normal, type Unmovable 2833 6802 3888 1636 329 3 1 2 0 0 0 Node 2, zone Normal, type Movable 72017 >100000 >100000 >100000 >100000 61710 20764 4242 841 55 239 Node 2, zone Normal, type Reclaimable 114 8 2056 2221 1544 826 396 163 281 111 35 Node 2, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 2, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate Node 2, zone Normal 1066 31063 639 0 0 Page block order: 9 Pages per block: 512 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 3, zone Normal, type Unmovable 2508 6171 3802 1502 365 93 30 1 2 0 0 Node 3, zone Normal, type Movable 23396 48450 >100000 >100000 99802 77850 47910 20587 4796 428 5 Node 3, zone Normal, type Reclaimable 10 0 609 2111 1726 1155 670 448 223 46 1 Node 3, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 3, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate Node 3, zone Normal 768 31425 575 0 0 Page block order: 9 Pages per block: 512 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 4, zone Normal, type Unmovable 3817 3739 1716 992 261 39 4 1 0 0 1 Node 4, zone Normal, type Movable 27857 39138 6875 >100000 >100000 70501 20752 4115 362 49 104 Node 4, zone Normal, type Reclaimable 1 8 3 5 0 0 16 31 19 97 4 Node 4, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 4, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate Node 4, zone Normal 712 31706 350 0 0 Page block order: 9 Pages per block: 512 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 5, zone Normal, type Unmovable 4875 4728 3165 1202 464 67 3 0 0 0 0 Node 5, zone Normal, type Movable 18382 34874 >100000 >100000 >100000 61296 22711 6235 348 32 0 Node 5, zone Normal, type Reclaimable 16 0 1 7 2 525 284 91 109 0 0 Node 5, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 5, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate Node 5, zone Normal 736 31716 316 0 0 Page block order: 9 Pages per block: 512 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 6, zone Normal, type Unmovable 10489 6842 2821 434 257 22 1 1 1 3 0 Node 6, zone Normal, type Movable 90841 >100000 >100000 92129 11336 1526 704 552 141 34 118 Node 6, zone Normal, type Reclaimable 434 41 0 576 1338 700 314 110 30 5 3 Node 6, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 6, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate Node 6, zone Normal 807 31686 275 0 0 Page block order: 9 Pages per block: 512 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 7, zone Normal, type Unmovable 1516 1894 2285 908 633 121 16 7 4 2 0 Node 7, zone Normal, type Movable 18209 >100000 >100000 93283 52811 50349 27973 9703 2026 1341 248 Node 7, zone Normal, type Reclaimable 0 1 0 1341 1082 552 191 47 8 8 32 Node 7, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0 Node 7, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate Node 7, zone Normal 1262 31265 241 0 0
/proc/pagetypeinfo cat /proc/pagetypeinfo, 你可以看到当前系统里伙伴系统里各个尺寸的可用连续内存块数量。unmovable pages是不可以被迁移的,比如slab等kmem都不可以被迁移,因为内核里面对这些内存很多情况下是通过指针来访问的,而不是通过页表,如果迁移的话,就会导致原来的指针访问出错。
当迁移类型为 Unmovable 的页面都聚集在 order < 3 时,说明内核 slab 碎片化严重
alloc_pages分配内存的时候就到上面对应大小的free_area的链表上寻找可用连续页面。alloc_pages是怎么工作的呢?我们举个简单的小例子。假如要申请8K-连续两个页框的内存。为了描述方便,我们先暂时忽略UNMOVEABLE、RELCLAIMABLE等不同类型
基于伙伴系统的内存分配中,有可能需要将大块内存拆分成两个小伙伴。在释放中,可能会将两个小伙伴合并再次组成更大块的连续内存。
伙伴系统中的伙伴指的是两个内存块,大小相同,地址连续,同属于一个大块区域。
对于应用来说基本分配单位是4K(开启大页后一般是2M),对于内核来说4K有点浪费。所以内核又专门给自己定制了一个更精细的内存管理系统slab。
slab 对于内核运行中实际使用的对象来说,多大的对象都有。有的对象有1K多,但有的对象只有几百、甚至几十个字节。如果都直接分配一个 4K的页面 来存储的话也太浪费了,所以伙伴系统并不能直接使用。
在伙伴系统之上,内核又给自己搞了一个专用的内存分配器, 叫slab 。
这个分配器最大的特点就是,一个slab内只分配特定大小、甚至是特定的对象。这样当一个对象释放内存后,另一个同类对象可以直接使用这块内存。通过这种办法极大地降低了碎片发生的几率。
1 2 3 4 #cat /proc/meminfo Slab: 102076 kB SReclaimable: 70816 kB SUnreclaim: 31260 kB
Slab 内核通过slab分配管理的内存总数。
SReclaimable 内核通过slab分配的可回收的内存(例如dentry),通过echo 2 > /proc/sys/vm/drop_caches回收。
SUnreclaim 内核通过slab分配的不可回收的内存。
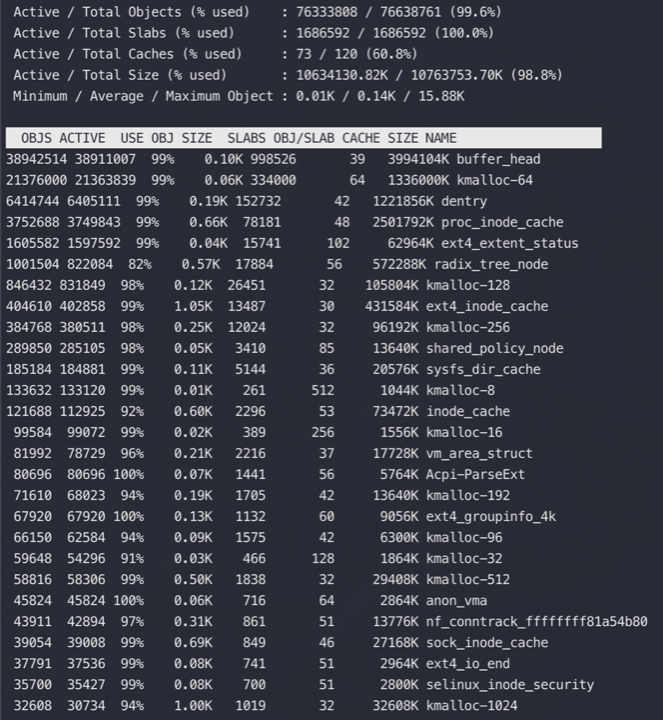
kmem cache slabtop和/proc/slabinfo 查看cached使用情况 主要是:pagecache(页面缓存), dentries(目录缓存), inodes
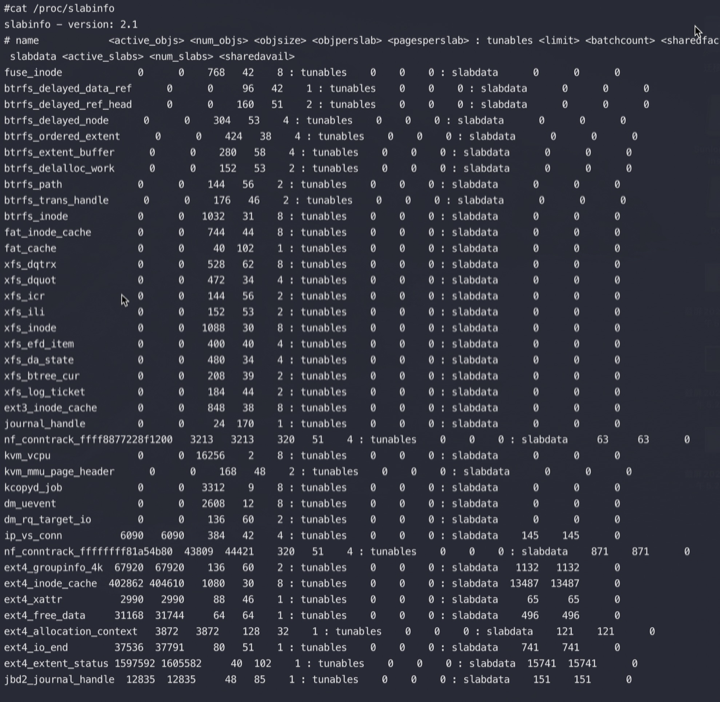
通过查看 /proc/slabinfo 我们可以查看到所有的 kmem cache。
slabtop 按占用内存从大往小进行排列。用来分析 slab 内存开销。
无论是 /proc/slabinfo,还是 slabtop 命令的输出。里面都包含了每个 cache 中 slab的如下几个关键属性。
比如如下TCP slabinfo中可以看到每个slab占用8(pagesperslab)个Page(8*4096=32768),每个对象的大小是1984(objsize),每个slab存放了16(objperslab)个对象. 那么1984 *16=31744,现在的空间基本用完,剩下接近1K,又放不下一个1984大小的对象,算是额外开销了。
1 2 3 4 #cat /proc/slabinfo |grep -E "active_objs|TCP" # name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail> tw_sock_TCP 5372 5728 256 32 2 : tunables 0 0 0 : slabdata 179 179 0 TCP 6090 6144 1984 16 8 : tunables 0 0 0 : slabdata 384 384 0
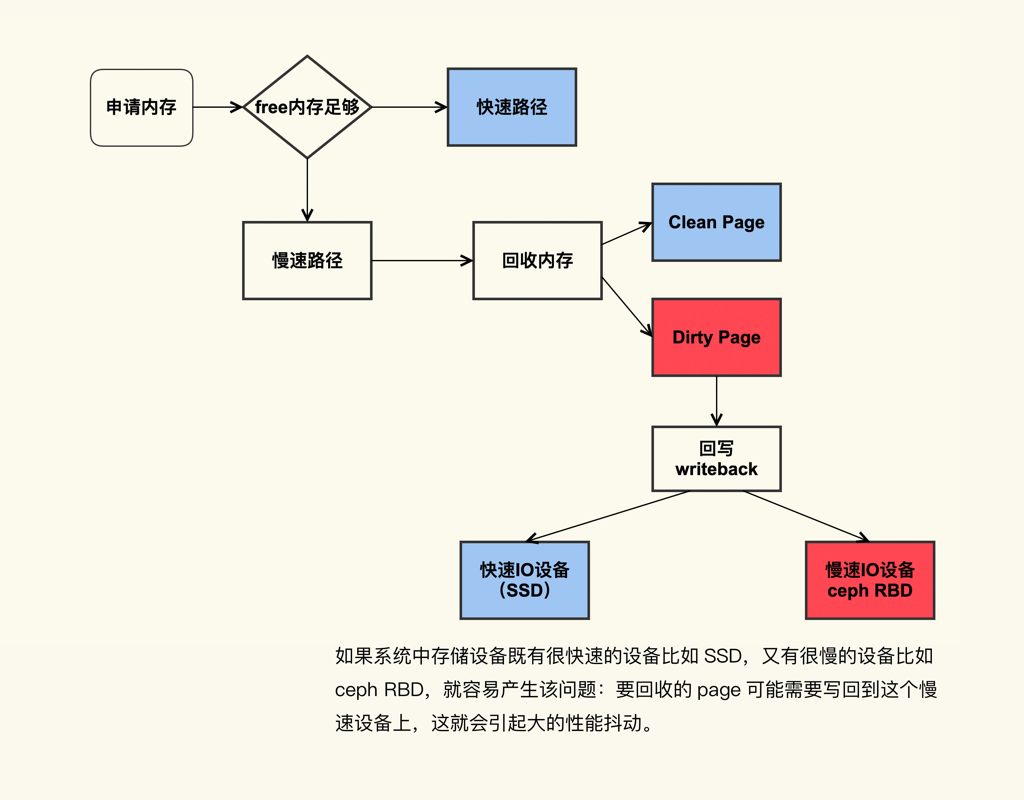
内存分配和延迟 内存不够、脏页太多、碎片太多,都会导致分配失败,从而触发回收,导致卡顿。
系统中脏页过多引起 load 飙高 直接回收过程中,如果存在较多脏页就可能涉及在回收过程中进行回写,这可能会造成非常大的延迟,而且因为这个过程本身是阻塞式的,所以又可能进一步导致系统中处于 D 状态的进程数增多,最终的表现就是系统的 load 值很高。
可以通过 sar -r 来观察系统中的脏页个数:
1 2 3 4 5 6 $ sar -r 1 07:30:01 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty 09:20:01 PM 5681588 2137312 27.34 0 1807432 193016 2.47 534416 1310876 4 09:30:01 PM 5677564 2141336 27.39 0 1807500 204084 2.61 539192 1310884 20 09:40:01 PM 5679516 2139384 27.36 0 1807508 196696 2.52 536528 1310888 20 09:50:01 PM 5679548 2139352 27.36 0 1807516 196624 2.51 536152 1310892 24
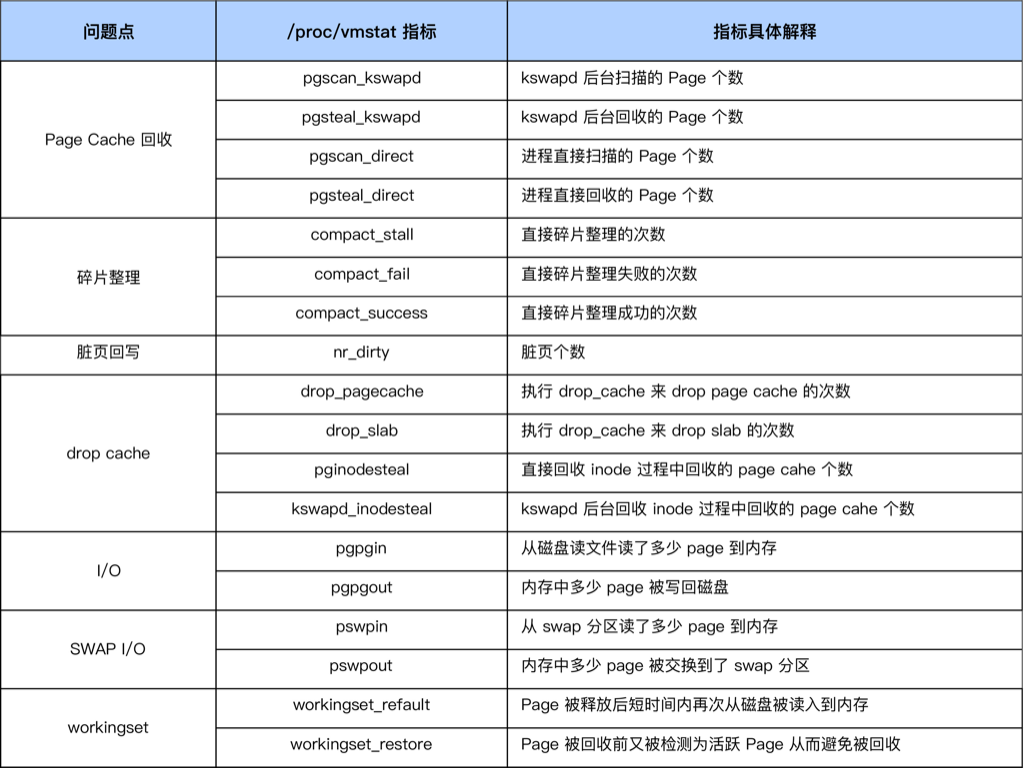
kbdirty 就是系统中的脏页大小,它同样也是对 /proc/vmstat 中 nr_dirty 的解析。你可以通过调小如下设置来将系统脏页个数控制在一个合理范围:
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
至于这些值调整大多少比较合适,也是因系统和业务的不同而异,我的建议也是一边调整一边观察,将这些值调整到业务可以容忍的程度就可以了,即在调整后需要观察业务的服务质量 (SLA),要确保 SLA 在可接受范围内。调整的效果你可以通过 /proc/vmstat 来查看:
1 2 3 #grep "nr_dirty_" /proc/vmstat nr_dirty_threshold 3071708 nr_dirty_background_threshold 1023902
在4.20的内核并且sar 的版本为12.3.3可以看到PSI(Pressure-Stall Information)
1 2 some avg10=45.49 avg60=10.23 avg300=5.41 total=76464318 full avg10=40.87 avg60=9.05 avg300=4.29 total=58141082
你需要重点关注 avg10 这一列,它表示最近 10s 内存的平均压力情况,如果它很大(比如大于 40)那 load 飙高大概率是由于内存压力,尤其是 Page Cache 的压力引起的。
容器中的内存回收
kswapd线程(每个node一个kswapd进程,负责本node)回收内存时,可以先对脏页进行回写(writeback)再进行回收,而直接内存回收只回收干净页。也叫同步回收.
直接内存回收是在当前进程的上下文中进行的,要等内存回收完成才能继续尝试进行分配,所以是阻塞了当前进程的执行,会导致响应延迟增加
如果是在容器里,也就是在某个子memory cgroup 中,那么在分配内存后,还有一个记账(charge)的步骤,就是要把这次分配的内存页记在某个memory cgroup的账上,这样才能控制这个容器里的进程所能使用的内存数量。
在开源社区的linux代码中,如果charge 失败,也就是说,当新分配的内存加上原先的usage超过了limit,就会触发内存回收,try_to_free_mem_cgroup_pages,这个也是同步回收,等同于直接内存回收(发生在当前进程的上下文忠),所以会对应用的响应造成影响(表现为卡顿)。
碎片化 内存碎片严重的话会导致系统hang很久(回收、压缩内存)
尽量让系统的free多一点(比例高一点)可以调整 vm.min_free_kbytes(128G 以内 2G,256G以内 4G/8G), 线上机器直接修改vm.min_free_kbytes会触发回收,导致系统hang住 https://www.atatech.org/articles/163233 https://www.atatech.org/articles/97130
每个zone都有自己的min low high,如下,但是单位是page, 计算案例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #cat /proc/zoneinfo |grep "Node" Node 0, zone DMA Node 0, zone DMA32 Node 0, zone Normal Node 1, zone Normal #cat /proc/zoneinfo |grep "Node 0, zone" -A10 Node 0, zone DMA pages free 3975 min 20 low 25 high 30 scanned 0 spanned 4095 present 3996 managed 3975 nr_free_pages 3975 nr_alloc_batch 5 -- Node 0, zone DMA32 pages free 382873 min 2335 low 2918 high 3502 scanned 0 spanned 1044480 present 513024 managed 450639 nr_free_pages 382873 nr_alloc_batch 584 -- Node 0, zone Normal pages free 11105097 min 61463 low 76828 high 92194 scanned 0 spanned 12058624 present 12058624 managed 11859912 nr_free_pages 11105097 nr_alloc_batch 12344 low = 5/4 * min high = 3/2 * min #T=min;sum=0;for i in `cat /proc/zoneinfo |grep $T | awk '{print $NF}'`;do sum=`echo "$sum+$i" |bc`;done;sum=`echo "$sum*4/1024" |bc`;echo "sum=${sum} MB" sum=499 MB #T=low;sum=0;for i in `cat /proc/zoneinfo |grep $T | awk '{print $NF}'`;do sum=`echo "$sum+$i" |bc`;done;sum=`echo "$sum*4/1024" |bc`;echo "sum=${sum} MB" sum=624 MB #T=high;sum=0;for i in `cat /proc/zoneinfo |grep $T | awk '{print $NF}'`;do sum=`echo "$sum+$i" |bc`;done;sum=`echo "$sum*4/1024" |bc`;echo "sum=${sum} MB" sum=802 MB
内存碎片化导致rt升高的诊断 判定方法如下:
运行 sar -B 观察 pgscand/s,其含义为每秒发生的直接内存回收次数,当在一段时间内持续大于 0 时,则应继续执行后续步骤进行排查;
运行 cat /sys/kernel/debug/extfrag/extfrag_index 观察内存碎片指数,重点关注 order >= 3 的碎片指数,当接近 1.000 时,表示碎片化严重,当接近 0 时表示内存不足;
运行 cat /proc/buddyinfo, cat /proc/pagetypeinfo 查看内存碎片情况, 指标含义参考 ,同样关注 order >= 3 的剩余页面数量,pagetypeinfo 相比 buddyinfo 展示的信息更详细一些,根据迁移类型 (伙伴系统通过迁移类型实现反碎片化)进行分组,需要注意的是,当迁移类型为 Unmovable 的页面都聚集在 order < 3 时,说明内核 slab 碎片化严重 ,我们需要结合其他工具来排查具体原因,在本文就不做过多介绍了;
对于 CentOS 7.6 等支持 BPF 的 kernel 也可以运行我们研发的 drsnoop ,compactsnoop 工具对延迟进行定量分析,使用方法和解读方式请参考对应文档;
(Opt) 使用 ftrace 抓取 mm_page_alloc_extfrag 事件,观察因内存碎片从备用迁移类型“盗取”页面的信息。
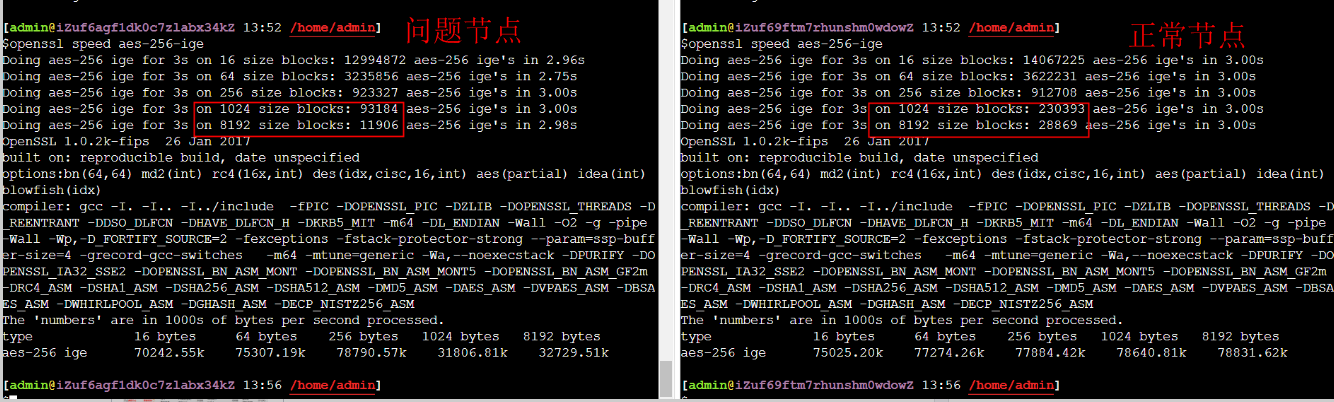
一个阿里云ECS 因为宿主机碎片导致性能衰退的案例 LVS后面三个RS在同样压力流量下,其中一个节点CPU非常高,通过top看起来是所有操作都很慢,像是CPU被降频了一样,但是直接跑CPU Prime性能又没有问题
原因:ECS所在的宿主机内存碎片比较严重,导致分配到的内存主要是4K Page,在ECS中大页场景下会慢很多
通过 openssl speed aes-256-ige 能稳定重现 在大块的加密上慢很多
小块上性能一致,这也就是为什么算Prime性能没问题。导致慢只涉及到大块内存分配的场景,这里需要映射到宿主机,但是碎片多分配慢导致了问题。
如果reboot ECS的话实际只是就地重启ECS,仍然使用的reboot前分配好的宿主机内存,不会解决问题。重启ECS中的进程也不会解决问题,只有将ECS迁移到别的物理机(也就是通过控制台重启,会重新选择物理机)才有可能解决这个问题。
或者购买新的ECS机型(比如第6代之后ECS)能避免这个问题。
ECS内部没法查看到这个碎片,只能在宿主机上通过命令查看大页情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 有问题NC上buddyinfo信息 $cat /proc/buddyinfo Node 0, zone DMA 1 1 0 0 2 1 1 0 1 1 3 Node 0, zone DMA32 23 23 17 15 13 9 8 8 4 3 367 Node 0, zone Normal 295291 298652 286048 266597 218191 156837 93156 45930 25856 0 0 最新建的vm,大页不多 $sudo cat /proc/9550/smaps |grep AnonHuge |awk '{sum+=$2}END{print sum}' 210944 ------------------------ 第一台正常ECS所在的NC $cat /proc/buddyinfo Node 0, zone DMA 1 1 0 0 2 1 1 0 1 1 3 Node 0, zone DMA32 7 5 5 9 8 4 6 10 5 5 366 Node 0, zone Normal 203242 217888 184465 176280 148612 102122 55787 26642 24824 0 0 早期的vm,大页充足 $sudo cat /proc/87369/smaps |grep AnonHuge |awk '{sum+=$2}END{print sum}' 8275968 近期的vm,大页不够 $sudo cat /proc/22081/smaps |grep AnonHuge |awk '{sum+=$2}END{print sum}' 251904 $sudo cat /proc/44073/smaps |grep AnonHuge |awk '{sum+=$2}END{print sum}' 10240
内存使用分析 pmap 1 2 3 4 5 6 7 8 9 10 11 12 13 pmap -x 24282 | less 24282: /usr/sbin/rsyslogd -n Address Kbytes RSS Dirty Mode Mapping 000055ce1a99f000 596 580 0 r-x-- rsyslogd 000055ce1ac34000 12 12 12 r---- rsyslogd 000055ce1ac37000 28 28 28 rw--- rsyslogd 000055ce1ac3e000 4 4 4 rw--- [ anon ] 000055ce1c1f1000 364 204 204 rw--- [ anon ] 00007fff8b5a4000 132 20 20 rw--- [ stack ] 00007fff8b5e6000 12 0 0 r---- [ anon ] 00007fff8b5e9000 8 4 0 r-x-- [ anon ] ---------------- ------- ------- ------- total kB 620060 17252 3304
Address:占用内存的文件的内存起始地址。
Kbytes:占用内存的字节数。
RSS:实际占用内存大小。
Dirty:脏页大小。
Mapping:占用内存的文件,[anon] 为已分配的内存,[stack] 为程序堆栈
/proc/pid/ /proc/[pid]/ 下面与进程内存相关的文件主要有maps , smaps, status。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 创建1000 个线程,ss为2M java -XX:NativeMemoryTracking=detail -Xms10g -Xmx10g -Xmn5g -XX:ReservedCodeCacheSize=512m -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:MaxDirectMemorySize=1g -Xss2048K ThreadPoolExample 分析结果: #jcmd 81849 VM.native_memory summary 81849 :Native Memory Tracking: Total: reserved=14737064KB, committed=13157168KB - Java Heap (reserved=10485760KB, committed=10485760KB) (mmap: reserved=10485760KB, committed=10485760KB) - Class (reserved=1102016KB, committed=50112KB) (classes #416 ) (malloc=45248KB #1420 ) (mmap: reserved=1056768KB, committed=4864KB) - Thread (reserved=2134883KB, committed=2134883KB) (thread #1070 ) (stack: reserved=2128820KB, committed=2128820KB) (malloc=3500KB #5390 ) (arena=2563KB #2138 ) - Code (reserved=532612KB, committed=4620KB) (malloc=132KB #528 ) (mmap: reserved=532480KB, committed=4488KB) - GC (reserved=430421KB, committed=430421KB) (malloc=50737KB #235 ) (mmap: reserved=379684KB, committed=379684KB) - Compiler (reserved=137KB, committed=137KB) (malloc=6KB #53 ) (arena=131KB #3 ) - Internal (reserved=48901KB, committed=48901KB) (malloc=48869KB #14030 ) (mmap: reserved=32KB, committed=32KB) - Symbol (reserved=1479KB, committed=1479KB) (malloc=959KB #110 ) (arena=520KB #1 ) - Native Memory Tracking (reserved=608KB, committed=608KB) (malloc=193KB #2556 ) (tracking overhead=415KB) - Arena Chunk (reserved=248KB, committed=248KB) (malloc=248KB)
We can see two types of memory:
Reserved — the size which is guaranteed to be available by a host’s OS (but still not allocated and cannot be accessed by JVM) — it’s just a promiseCommitted — already taken, accessible, and allocated by JVM
page fault 内核给用户态申请的内存,默认都只是一段虚拟地址空间而已,并没有分配真正的物理内存。在第一次读写的时候才触发物理内存的分配,这个过程叫做page fault。那么,为了访问到真正的物理内存,page fault的时候,就需要更新对应的page table了。
参考资料 https://www.atatech.org/articles/66885
https://cloud.tencent.com/developer/article/1087455
https://www.cnblogs.com/xiaolincoding/p/13719610.html
rsyslog占用内存高
https://sunsea.im/rsyslogd-systemd-journald-high-memory-solution.html
鸟哥 journald 介绍
说出来你可能不信,内核这家伙在内存的使用上给自己开了个小灶!
socket 与 slab dentry