活久见,TCP连接互串了
活久见,TCP连接互串了
背景
应用每过一段时间总是会抛出几个连接异常的错误,需要查明原因。
排查后发现是TCP连接互串了,这个案例实在是很珍惜,所以记录一下。
抓包
业务结构: 应用->MySQL(10.112.61.163)
在 应用 机器上抓包这个异常连接如下(3269为MySQL服务端口):
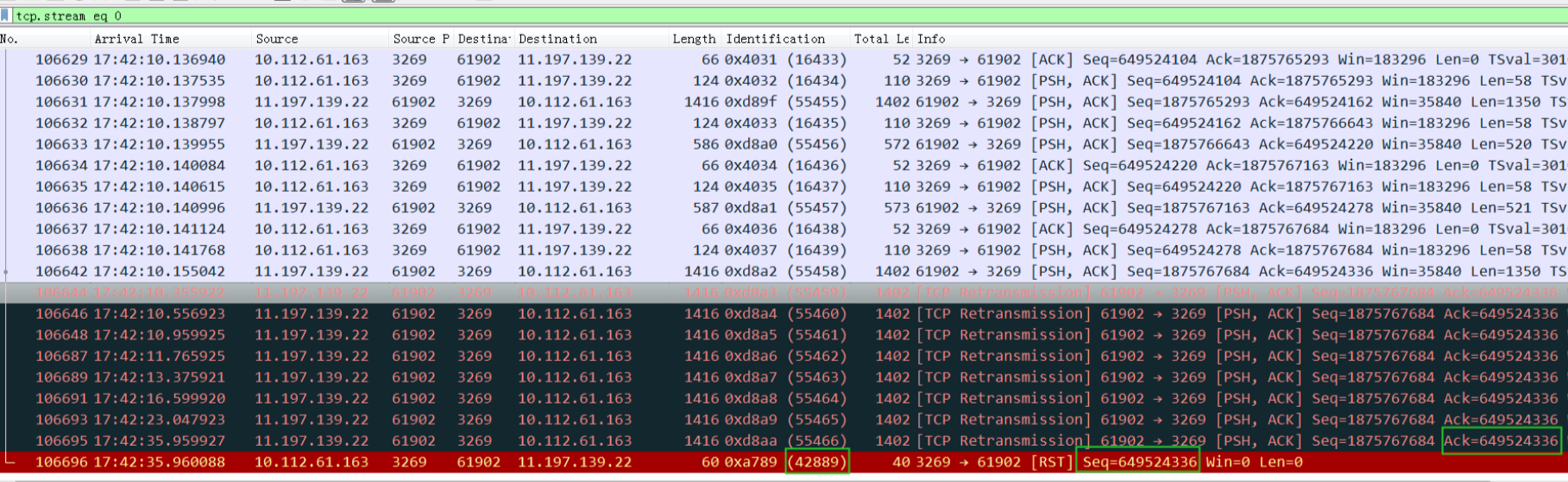
粗一看没啥奇怪的,就是应用发查询给3269,但是一直没收到3269的ack,所以一直重传。这里唯一的解释就是网络不通。最后MySQL的3269还回复了一个rst,这个rst的id是42889,引起了我的好奇,跟前面的16439不连贯,正常应该是16440才对。(请记住上图中的绿框中的数字)
于是我过滤了一下端口61902上的所有包:
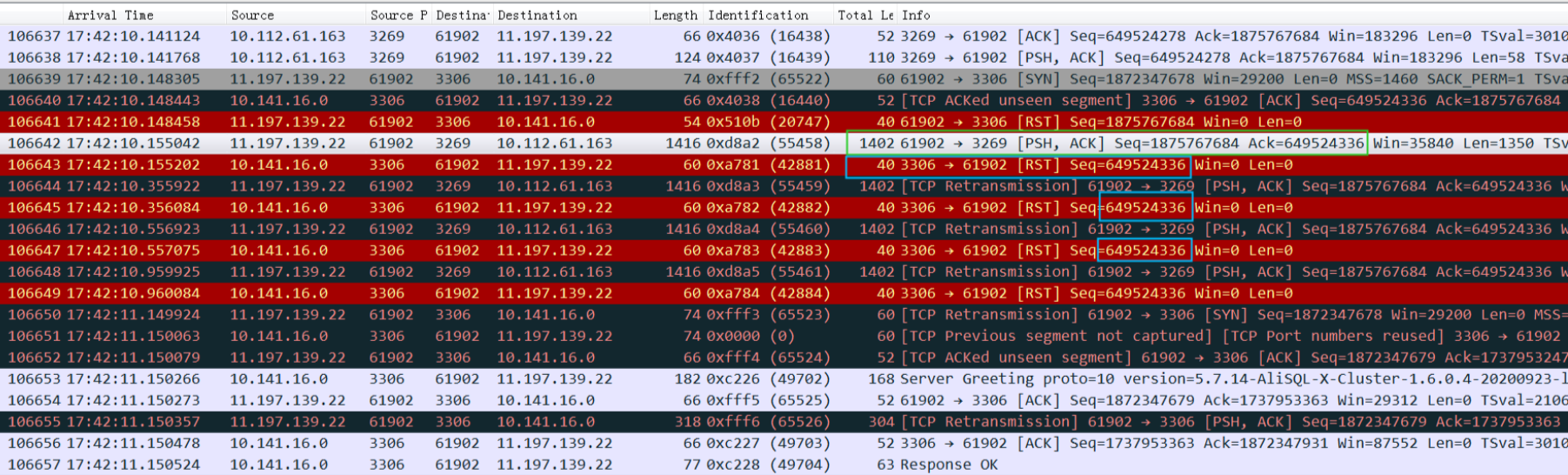
可以看到绿框中的查询从61902端口发给3269后,很奇怪居然收到了一个来自别的IP+3306端口的reset,这个包对这个连接来说自然是不认识(这个连接只接受3269的回包),就扔掉了。但是也没收到3269的ack,所以只能不停地重传,然后每次都收到3306的reset,reset包的seq、id都能和上图的绿框对应上。
明明他们应该是两个连接:
61902->10.141.16.0:3306
61902->10.112.61.163:3269
他们虽然用的本地ip端口(61902)是一样的, 但是根据四元组不一样,还是不同的TCP连接,所以应该是不会互相干扰的。但是实际看起来seq、id都重复了,不会有这么巧,非常像是TCP互串了。
分析原因
10.141.16.0 这个ip看起来像是lvs的ip,查了一下系统,果然是lvs,然后这个lvs 后面的rs就是10.112.61.163
那么这个连结构就是10.141.16.0:3306:
应用 -> lvs(10.141.16.0:3306)-> 10.112.61.163:3269 跟应用直接连MySQL是一回事了
所以这里的疑问就变成了:10.141.16.0 这个IP的3306端口为啥能知道 10.112.61.163:3269端口的seq和id,也许是TCP连接串了
接着往下排查
先打个岔,分析下这里的LVS的原理
这里使用的是 full NAT模型(full NetWork Address Translation-全部网络地址转换)
基本流程(类似NAT):
- client发出请求(sip 200.200.200.2 dip 200.200.200.1)
- 请求包到达lvs,lvs修改请求包为**(sip 200.200.200.1, dip rip)** 注意这里sip/dip都被修改了
- 请求包到达rs, rs回复(sip rip,dip 200.200.200.1)
- 这个回复包的目的IP是VIP(不像NAT中是 cip),所以LVS和RS不在一个vlan通过IP路由也能到达lvs
- lvs修改sip为vip, dip为cip,修改后的回复包(sip 200.200.200.1,dip 200.200.200.2)发给client
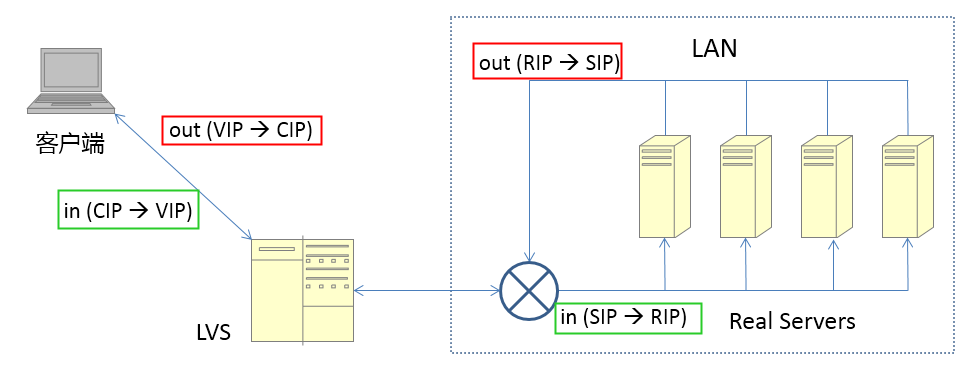
注意上图中绿色的进包和红色的出包他们的地址变化
本来这个模型下都是正常的,但是为了Real Server能拿到client ip,也就是Real Server记录来源ip的时候希望记录的是client ip而不是LVS ip。这个时候LVS会将client ip放在tcp的options里面,然后在RealServer机器的内核里面将options中的client ip取出替换掉 lvs ip。所以Real Server上感知到的对端ip就是client ip。
回包的时候RealServer上的内核模块同样将目标地址从client ip改成lvs ip,同时将client ip放入options中。
回到问题
看完理论,再来分析这两个连接的行为
fulnat模式下连接经过lvs到达mysql后,mysql上看到的连接信息是,cip+port,也就是在MySQL上的连接
**lvs-ip:port -> 10.112.61.163:3269 被修改成了 **client-ip:61902 **-> 10.112.61.163:3269
那么跟不走LVS的连接:
client-ip:61902 -> 10.112.61.163:3269 (直连) 完全重复了。
MySQL端看到的两个连接四元组一模一样了:
10.112.61.163:3269 -> client-ip:61902 (走LVS,本来应该是lvs ip的,但是被替换成了client ip)
10.112.61.163:3269 -> client-ip:61902 (直连)
这个时候应用端看到的还是两个连接:
client-ip:61902 -> 10.141.16.0:3306 (走LVS)
client-ip:61902 -> 10.112.61.163:3269 (直连)
总结下,也就是这个连接经过LVS转换后在服务端(MYSQL)跟直连MySQL的连接四元组完全重复了,也就是MySQL会认为这两个连接就是同一个连接,所以必然出问题了
这个时候用 netstat 看到的应该是两个连接(vtoa 没有替换), 一个是client->rs, 一个是lvs->rs, 内核层面看到的还是两个连接, 只是get_peername接口被toa hook修改后, 两个连接返回的srcip是同一个
实际两个连接建立的情况:
和mysqlserver的61902是04:22建起来的,和lvs的61902端口 是42:10建起来的,和lvs的61902建起来之后马上就出问题了
问题出现的条件
- fulnat模式的LVS,RS上装有ip转换模块(RS上会将LVS ip还原成client ip)
- client端正好重用一个相同的本地端口分别和RS以及LVS建立了两个连接
这个时候这两个连接在MySQL端就会变成一个,然后两个连接的内容互串,必然导致rst
这个问题还挺有意思的,估计没几个程序员一辈子能碰上一次。推荐另外一个好玩的连接:如何创建一个自己连自己的TCP连接
在很多容器场景也容易出现同样的问题,比如同时暴露 Nodeport 和 Loadbalance IP
其他场景
比如在 HA 场景下,需要通过直连节点去做心跳检查(B链路);同时又要走A链路去跨机房检测,这两个链路下连接的目标IP一直、端口不一样,但是经过转换后都是MySQL-Server+3306端口,容易出现两条连接转换后变成一条连接

参考资料
https://idea.popcount.org/2014-04-03-bind-before-connect/
另一种形式的tcp连接互串,新连接重用了time_wait的port,导致命中lvs内核表中的维护的旧连接发给了老的realserver
类似场景汇总
1 | 下面罗列所有会导致这种问题的场景。 |
附录一篇 k8s 场景下的同样的问题:
[GOAWAY Chance——客户端连接丢失始末](https://robinhood.com/us/en/newsroom/goaway-chance-chronicles-of-client-connection-lo
st/)
作者: Eric Ngo
编辑: Nick Turner 与 Sujith Katakam
发布日期: 2024 年 5 月 23 日
分布式系统本已十分复杂,而各系统之间的交互更是如此。Kubernetes 就是这样一个典型——其采用率正在快速上升。随着
我们向集群中引入越来越多的组件(也带来了更多的复杂性),理解变更所产生的下游影响变得愈加困难。在 Robinhood
的软件平台团队,我们作为 Kubernetes 从业者,必须深入排查那些由最细微的配置变更所引发的系统问题。在这篇博客中
,我们将回顾一个近期的案例——我们深入钻研了内核设置、NLB 配置和开源代码,最终定位了一个看似无害的 Kubernetes
API Server 配置项所导致的连接问题。
问题
使用 client-go 的 Kubernetes 客户端在连接 API Server 时,默认使用 HTTP/2。HTTP/2 利用持久 TCP
连接和”流”(stream)的概念,将多个 HTTP 请求复用到同一条 TCP 连接上。相较于 HTTP 1.1 每次请求都需要重新建立
TCP 与 TLS 握手,HTTP/2 通过减少 RTT 实现了更高的性能。
然而我们观察到一个现象:由于这些长期存活的持久连接,API Server 之间的负载出现了不均衡。这会导致某些 API
Server 承受不成比例的负载,并对系统可靠性产生级联影响。当我们对控制平面节点执行滚动更新时——这是更新控制平面
组件或修改配置时的常规操作——这种不均衡现象尤为明显。
为了解决客户端”粘性”问题,我们决定配置 Kubernetes API Server 的 –goaway-chance 参数。该参数在 k8s 1.18
中引入,是一个 API Server HTTP 过滤器,它以一定概率向 HTTP/2 客户端发送 RST_STREAM,强制客户端在新建立的 TCP
连接上重新发起请求。通过启用此设置,我们实现了显著改善的连接均衡和负载分发。
在将 –goaway-chance 推送到预生产环境后,我们开始偶发性地观察到集群中出现节点被标记为 NotReady 的现象。
node ip-10-241-33-82.us-west-2.compute.internal hasn’t been updated for 40.956376745s. Last Ready is: …
进一步检查后,我们发现是 kube-controller-manager 在将节点标记为不健康。每个节点上的 kubelet 负责更新节点的
kube-node-lease,这是一种心跳机制,用于表明节点能否与 API Server 正常通信。kube-controller-manager
运行一个名为 node_lifecycle_controller 的控制循环,负责在节点未能及时续约 kube-node-lease 时更新其 Ready
状态条件。默认情况下,kubelet 每隔 renewInterval(10 秒)更新一次 Lease 对象,而 kube-controller-manager
则检查 Lease 是否在 nodeMonitorGracePeriod(40 秒)内完成了续约。
因此,当收到少量节点报告为 NotReady 时,可能有两种原因:少数节点确实不健康(kubelet 无法执行心跳),或者
kube-controller-manager 的 lease informer 未能接收到更新。
检查了某个被标记为不健康节点的 kubelet 日志和心跳更新审计日志后,我们很快排除了 kubelet
的嫌疑。于是我们将注意力集中到 kube-controller-manager 上,发现了一条颇为奇特的日志:
W1215 09:45:02.898142 1 reflector.go:441] k8s.io/client-go/informers/factory.go:134: watch of
*v1.Lease ended with: an error on the server (“unable to decode an event from the watch stream: http2:
client connection lost”) has prevented the request from succeeding
client connection lost 是什么意思,它又是如何导致 informer 超过 40 秒未收到任何更新的呢?
客户端连接丢失(Client Connection Lost)
还记得 HTTP/2 使用持久 TCP 连接这一点。由于是互联网,客户端与服务器之间可能发生各种各样的情况。因此,HTTP/2
允许通过健康检查来检测远端是否存在问题。在 Kubernetes 的 golang
客户端库(k8s.io/client-go)中,这些健康检查由 net/http2 库以 HTTP/2 ping 的形式执行。
// closes the client connection immediately. In-flight requests are interrupted.
func (cc *ClientConn) closeForLostPing() {
err := errors.New(“http2: client connection lost”)
if f := cc.t.CountError; f != nil {
f(“conn_close_lost_ping”)
}
cc.closeForError(err)
}
这些 ping 会在连接上超过 ReadIdleTimeout 秒未收到任何帧后触发。超过 PingTimeout 秒后,连接将被关闭。
// ReadIdleTimeout 是在连接上未收到任何帧后,
// 使用 ping 帧执行健康检查的超时时间。
// 注意,ping 响应也被视为已收到帧,
// 因此如果连接上没有其他流量,
// 健康检查将每隔 ReadIdleTimeout 间隔执行一次。
// 如果为零,则不执行健康检查。
ReadIdleTimeout time.Duration
// PingTimeout 是在未收到 Ping 响应时关闭连接的超时时间。
// 默认为 15 秒。
PingTimeout time.Duration
Kubernetes 默认的传输配置将 ReadIdleTimeout 设为 30 秒,PingTimeout 设为 15 秒。
func readIdleTimeoutSeconds() int {
ret := 30
if s := os.Getenv(“HTTP2_READ_IDLE_TIMEOUT_SECONDS”); len(s) > 0 {
i, err := strconv.Atoi(s)
if err != nil {
klog.Warningf(“Illegal HTTP2_READ_IDLE_TIMEOUT_SECONDS(%q): %v.”+
“ Default value %d is used”, s, err, ret)
return ret
}
ret = i
}
return ret
}
func pingTimeoutSeconds() int {
ret := 15
if s := os.Getenv(“HTTP2_PING_TIMEOUT_SECONDS”); len(s) > 0 {
i, err := strconv.Atoi(s)
if err != nil {
klog.Warningf(“Illegal HTTP2_PING_TIMEOUT_SECONDS(%q): %v.”+
“ Default value %d is used”, s, err, ret)
return ret
}
ret = i
}
return ret
}
readIdleTimeout 与 pingTimeout 之和为 45 秒,这可以解释为什么 lease informer 会超过 40
秒未收到任何更新,从而导致 kube-controller-manager 认为节点已超过 40 秒的 leaseDuration
未续约,进而将节点标记为 NotReady。但问题依然存在:连接为何会挂起 45 秒?
我们的环境
NLB
每个集群都有一个 NLB 对 API Server 的连接进行负载均衡。这些 NLB 配置了客户端 IP 保留(client-ip
preservation)和跨 AZ 负载均衡(cross zone load balancing)。启用客户端 IP 保留,是为了让通过 NLB
的并发连接数能够超过 NLB 约 65000 个的临时端口范围限制。启用跨 AZ
负载均衡,则是为了提升可靠性并增强对部分控制平面故障的抗风险能力。
API Server 与 kube-controller-manager
我们使用 kOps(一款 Kubernetes 集群管理工具)来引导集群的创建。每个集群有 5
个控制平面节点。kube-controller-manager、kube-scheduler
等所有控制平面组件都运行在控制平面节点上,并配置为通过 NLB 与 API Server 通信。
节点
我们的节点配置了 net.ipv4.tcp_tw_reuse = 1,这允许处于 TIME_WAIT
状态的套接字被复用,以及将端口复用到不同的目标。只要连接的五元组(协议、源 IP、源端口、目标
IP、目标端口)不同,使内核能够区分新旧连接,未绑定的端口就可以被复用。
了解了环境后,我们来看如何复现这个问题。
复现过程
原生集群
最初,我们认为问题仅由 goaway-chance 引起,于是尝试创建一个原生集群来复现——其中 kube-controller-manager 通过
localhost 直接与 API Server 通信,网络路径如下:
设置 goaway-chance 后,我们无法复现该问题。我们的原生集群与生产集群环境的唯一区别,是控制平面组件通过 NLB
路由到 API Server。因此我们决定在测试环境中也加入一个 NLB。
参考配置
以下是所用 IP 的配置情况:
NLB 由以下各可用区的实例提供支持。注意,由于启用了跨 AZ 负载均衡,每个 NLB 实例都可以访问任意 API Server
目标。
┌──────────────┬────────────┐
│ NLB IP │ NLB 可用区 │
├──────────────┼────────────┤
│ 10.98.35.159 │ us-west-2a │
├──────────────┼────────────┤
│ 10.98.66.200 │ us-west-2b │
├──────────────┼────────────┤
│ 10.98.98.50 │ us-west-2c │
└──────────────┴────────────┘
由于我们只关心 kube-controller-manager 与 kube-apiserver 之间的交互,相关实例如下:
┌─────────────────┬─────────────────────────────────────────┐
│ 控制平面主机 IP │ 运行进程 │
├─────────────────┼─────────────────────────────────────────┤
│ 10.98.102.166 │ kube-controller-manager, kube-apiserver │
├─────────────────┼─────────────────────────────────────────┤
│ 10.98.72.61 │ kube-apiserver │
└─────────────────┴─────────────────────────────────────────┘
通过 NLB 通信
我们通过设置 –master 参数,将 kube-controller-manager 配置为与 NLB 通信,很快就复现了 client connection
lost 问题。但 NLB 与 client connection lost 有什么关系呢?
为了更好地理解 net/http 包底层的行为,并了解 TCP 连接的状态,我们采取了以下措施:
- 设置 GODEBUG=http2debug=2 以开启详细的 HTTP/2 日志并输出帧转储;
- 在 kube-controller-manager 的 manifest 的环境变量中,添加 key 为 GODEBUG、value 为 http2debug=2 的配置。
这样我们就可以将 net/http2 的活动与 TCP 抓包进行关联,从而精确定位问题中的 TCP 流并加以分析。
分析 HTTP/2 调试日志
启用 http2debug 日志后,我们捕获到了一次 client connection lost 发生时的 HTTP/2 活动:
{“log”:”I0125 01:56:38.494896 1 log.go:184] http2: Framer 0xc00151c1c0: read DATA stream=5 len=2535 …
{“log”:”I0125 01:56:38.494946 1 log.go:184] http2: Framer 0xc00151c1c0: wrote WINDOW_UPDATE stream=5 len=4
incr=5066\n”,…}
{“log”:”I0125 01:57:08.495926 1 log.go:184] http2: Framer 0xc00151c1c0: wrote PING len=8
ping="x\x85ex\xc5*\xd1\xd5"\n”,…}
{“log”:”I0125 01:57:23.496850 1 log.go:184] http2: Framer 0xc00151c1c0: wrote RST_STREAM stream=5 len=4
ErrCode=CANCEL\n”,…}
{“log”:”I0125 01:57:23.496896 1 log.go:184] http2: Framer 0xc00151c1c0: wrote RST_STREAM stream=1 len=4
ErrCode=CANCEL\n”,…}
{“log”:”W0125 01:57:23.496885 1 reflector.go:441] k8s.io/client-go/informers/factory.go:134: watch of
*v1.Pod ended with: an error on the server ("unable to decode an event from the watch stream: http2: client
connection lost") has prevented the request from succeeding\n”,…}
在 1:56:38,负责单条 TCP 连接上请求复用的 framer 0xc00151c1c0 从服务器读取了一些数据并执行了
WINDOW_UPDATE。此后连接在 readIdleTimeout(30 秒)内未收到任何更新,于是客户端向服务器写入了一个
PING。又过了 pingTimeout(15 秒),客户端最终写入了 RST_STREAM 终止流,并记录了 client connection lost。
kube-controller-manager TCP 抓包分析
分析 10.98.102.166:42852 <> 10.98.66.200:443
在一次 client connection lost 发生期间,我们进行了数据包捕获,找到了一条与 http2 调试日志高度吻合的 TCP
流(tcp.stream eq 1110)。我们看到 KCM 主机 10.98.102.166 正在与 NLB 之一 10.98.66.200 通信。
我们看到在 15:56:38 收到了一个帧,30 秒后,客户端 10.98.102.166 在 15:57:08 发送了
PING。看起来有响应返回,但仔细查看报文后发现,第 138783 帧的确认号(acknowledgement number)与第 138772
帧的序列号(Sequence number)并不匹配。在 15:57:23 经过 15 秒的 pingTimeout 后,我们看到客户端发送了
RST_STREAM,随后连接关闭。
继续分析该流的其余部分,发现了一些可疑之处:
出现了 TCP 端口号被复用(tcp port number reused)的警告。同一端口是否还有其他流在使用?
分析 10.98.102.166:42852 <> 10.98.98.50:443
我们看到了另一条 TCP 流,客户端 10.98.102.166 正在使用与前面相同的端口 42852,与另一个 NLB 10.98.98.50
通信(目标端口 443)。注意,由于我们的节点设置了 tcp_tw_reuse = 1,只要五元组字段(协议、源 IP、源端口、目标
IP、目标端口)不同,端口就允许被复用。这看起来是正常的,但这条流是否也存在异常呢?
这条流同样出现了相同的症状:在 15:56:08 最后一次收到数据,30 秒后的 15:56:38 发送
PING,在多次重传失败后,最终于 15:56:53 发送 RST_STREAM 并终止连接。这条流同样收到了前面提到的 client
connection lost 错误。接下来,让我们以端口 42852 为单位,过滤出所有相关流。
以端口 42852 为维度的全局分析
找到了!看来在 10.98.102.166:42852 <> 10.98.98.50:443 这条连接断开的同时,客户端尝试复用端口 42852 与另一个
NLB 10.98.66.200 建立新连接。在第 36711 帧,客户端发送了 SYN。然而,由于服务器认为旧连接仍然存在,它返回的是
Challenge ACK 而非 SYN-ACK。客户端随即发送了 TCP RST
报文,彻底断开了双端的连接并完全重置了连接状态。此后,客户端 10.98.102.166:42852 得以成功与 NLB
10.98.66.200:443 完成 TCP 三次握手。
这究竟是怎么回事?
让我们简要回顾一下 NLB 在这里的行为。NLB 是一种四层(TCP/IP
层)负载均衡器,接收连接并在客户端与服务器之间充当代理。
我们为 API Server 前置的 NLB 启用了一项名为客户端 IP 保留的功能。该功能实质上是将 TCP 数据包的源 IP
和端口替换为发送方的真实 IP 和端口,而不是 NLB 自身的。这使目标端能够接受更多连接,同时保留了 IP
信息,便于追踪和审计等用途。除客户端 IP 保留外,我们还启用了跨 AZ 负载均衡,允许 NLB 路由至任意后端目标。
这意味着:从客户端视角来看,即便路由到不同的 NLB IP(且复用同一端口),NLB
背后的目标节点也可能是同一台主机。从服务器视角来看,它会在一条已建立的 socket 上收到一个新的连接请求,并发送
Challenge ACK,这将触发连接重置(RST)。
在这个具体案例中,客户端(10.98.102.166)复用了同一端口(42852),经过不同的 NLB(10.98.98.50:443 和
10.98.66.200:443),但最终都落到了同一个目标(10.98.72.61:443)。这就解释了:为什么在使用相同端口向
10.98.66.200 建立第二条连接时,我们收到了 Challenge ACK;以及为何在发送 RST 报文后,发往 10.98.98.50
的原始连接被切断,而发往 10.98.66.200 的新连接则得以建立。
完整流程如下:
最初,kube-controller-manager 和 kube-apiserver 的 socket 状态均为空。kube-controller-manager 首先以五元组
(tcp, 10.98.102.166, 42852, 10.98.98.50, 443) 建立了一条 socket 连接。NLB 将该连接路由至 API Server
10.98.72.61,其”连接表”中记录了 socket 状态 (tcp, 10.98.102.166, 42852, 10.98.72.61, 443)。
不久后,客户端收到 GOAWAY,复用端口 42852 建立了一条新连接,五元组变为 (tcp, 10.98.102.166, 42852,
10.98.66.200, 443)——注意这是相同的客户端 IP,但是不同的 NLB IP。NLB
尝试将该连接路由至同一目标。此时,由于启用了客户端 IP 保留,kube API Server
发现连接表中已存在该连接(因为端口复用导致客户端端口相同)。在一条已建立的连接中途收到 SYN 后,它发送了
Challenge ACK。当客户端发回 RST 时,服务器彻底重置了客户端 IP 与端口对 10.98.102.166:42852
的连接状态,完全切断了原始连接,并允许以相同的客户端端口建立新连接。
为了更完整地说明,我们再次复现了该问题,并在服务器端进行了 tcpdump 抓包,精确捕获到了我们所推断的过程:
服务器在一条 TCP 流中途收到了一个序列号/确认号异常的 SYN。它回应了 Challenge ACK,客户端随后回复了
RST,将服务器端的 TCP 连接彻底切断。
总结: 启用了客户端 IP 保留与跨 AZ 负载均衡,节点设置了 tcp_tw_reuse=1,同一客户端(相同的源 IP
和源端口)通过不同的 NLB IP 路由后,落到了同一目标(相同的目标 IP
和目标端口)。这导致负载均衡目标节点在已建立的 TCP 连接上收到了意外的 SYN,并发送了 Challenge
ACK;客户端回复 RST,将服务器端的连接切断。这使现有的长连接 HTTP/2 流(例如 informer Watch 连接)在超时 45
秒后收到 client connection lost 错误。
NLB 官方文档
但这不就是 NLB 的 bug 吗?其实,这与其说是 bug,不如说是 NLB 启用客户端 IP 保留与跨 AZ
负载均衡后的一个既定特性。正如 AWS 在其 NLB “要求和注意事项”中所述:
当启用客户端 IP 保留时,不支持 NAT 回路(也称为 hairpinning)。启用后,当客户端或其前端的 NAT
设备在同时连接多个负载均衡器节点时使用相同的源 IP 地址和源端口,您可能会遇到与目标节点上的 socket 复用相关的
TCP/IP 连接限制。如果负载均衡器将这些连接路由到同一目标,目标节点会认为它们来自相同的源
socket,从而导致连接错误。如果发生这种情况,客户端可以重试(如果连接失败)或重新连接(如果连接中断)。您可以
通过增加源端临时端口数或增加负载均衡器目标数来减少此类连接错误。也可以通过禁用客户端 IP 保留或禁用跨 AZ
负载均衡来完全避免此类连接错误。
这里主要有两种考量:
- 禁用客户端 IP 保留——代价是将并发连接数限制在约 65000 个临时端口范围之内;
- 禁用跨 AZ 负载均衡——这将防止不同的负载均衡实例将连接路由到同一后端。
考虑到 –goaway-chance 的使用场景,我们决定将其值设得足够低,使端口复用的触发概率低于 1%。
在测试过程中,我们还遇到了上面提到的 NLB 回路超时问题——当 NLB 目标节点本身也是客户端时(即源 IP == 目标
IP),可能会使数据包失效。我们的解决方案是:在 kube-apiserver 的 GOAWAY 过滤器中忽略特定的
userAgent,以避免在重新连接时触发这种回路超时。
总结
在处理分布式系统时,变更往往会产生意想不到的影响。对我们这些管理这些系统的人来说,熟悉工具并敢于深入挖掘那些
尚不理解的行为,至关重要。这样的机会在我的 Robinhood 团队中时常出现。如果你对 Kubernetes
充满热情、热爱深入钻研,欢迎申请加入!我们目前正在招聘一名高级软件工程师加入我们的容器编排团队。
特别感谢我的队友 Nick Turner、Madhu CS 和 Palash Agrawal 的全力支持!