海光CPU 海光物理机CPU相关信息 总共有16台如下的海光服务器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 64 On-line CPU(s) list: 0-63 Thread(s) per core: 2 //每个物理core有两个超线程 Core(s) per socket: 16 //每路16个物理core Socket(s): 2 //2路 NUMA node(s): 4 Vendor ID: HygonGenuine CPU family: 24 Model: 1 Model name: Hygon C86 5280 16-core Processor Stepping: 1 CPU MHz: 2455.552 CPU max MHz: 2500.0000 CPU min MHz: 1600.0000 BogoMIPS: 4999.26 Virtualization: AMD-V L1d cache: 32K L1i cache: 64K L2 cache: 512K L3 cache: 8192K NUMA node0 CPU(s): 0-7,32-39 NUMA node1 CPU(s): 8-15,40-47 NUMA node2 CPU(s): 16-23,48-55 NUMA node3 CPU(s): 24-31,56-63 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate sme ssbd sev ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 MySQLeed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca #numactl -H available: 4 nodes (0-3) node 0 cpus: 0 1 2 3 4 5 6 7 32 33 34 35 36 37 38 39 node 0 size: 128854 MB node 0 free: 89350 MB node 1 cpus: 8 9 10 11 12 13 14 15 40 41 42 43 44 45 46 47 node 1 size: 129019 MB node 1 free: 89326 MB node 2 cpus: 16 17 18 19 20 21 22 23 48 49 50 51 52 53 54 55 node 2 size: 128965 MB node 2 free: 86542 MB node 3 cpus: 24 25 26 27 28 29 30 31 56 57 58 59 60 61 62 63 node 3 size: 129020 MB node 3 free: 98227 MB node distances: node 0 1 2 3 0: 10 16 28 22 1: 16 10 22 28 2: 28 22 10 16 3: 22 28 16 10
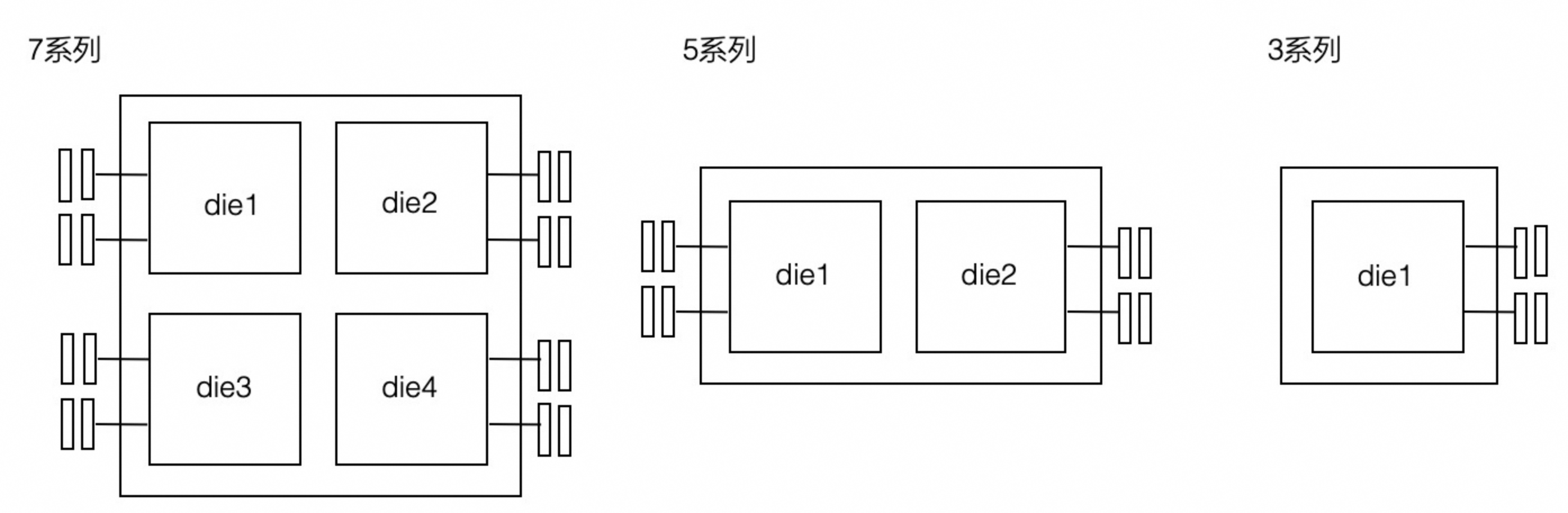
AMD Zen 架构的CPU是胶水核,也就是把两个die拼一块封装成一块CPU,所以一块CPU内跨die之间延迟还是很高的。
7260 系列的hygon CPU(关掉了超线程)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian Address sizes: 43 bits physical, 48 bits virtual CPU(s): 48 On-line CPU(s) list: 0-47 Thread(s) per core: 1 Core(s) per socket: 24 Socket(s): 2 NUMA node(s): 8 Vendor ID: HygonGenuine CPU family: 24 Model: 1 Model name: Hygon C86 7260 24-core Processor Stepping: 1 Frequency boost: enabled CPU MHz: 1065.890 CPU max MHz: 2200.0000 CPU min MHz: 1200.0000 BogoMIPS: 4399.38 Virtualization: AMD-V L1d cache: 1.5 MiB L1i cache: 3 MiB L2 cache: 24 MiB L3 cache: 128 MiB NUMA node0 CPU(s): 0-5 NUMA node1 CPU(s): 6-11 NUMA node2 CPU(s): 12-17 NUMA node3 CPU(s): 18-23 NUMA node4 CPU(s): 24-29 NUMA node5 CPU(s): 30-35 NUMA node6 CPU(s): 36-41 NUMA node7 CPU(s): 42-47
7280
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian Address sizes: 43 bits physical, 48 bits virtual CPU(s): 128 On-line CPU(s) list: 0-127 Thread(s) per core: 2 Core(s) per socket: 32 Socket(s): 2 NUMA node(s): 8 Vendor ID: HygonGenuine CPU family: 24 Model: 1 Model name: Hygon C86 7280 32-core Processor Stepping: 1 CPU MHz: 2313.699 BogoMIPS: 3999.47 Virtualization: AMD-V L1d cache: 2 MiB L1i cache: 4 MiB L2 cache: 32 MiB L3 cache: 128 MiB NUMA node0 CPU(s): 0-7,64-71 NUMA node1 CPU(s): 8-15,72-79 NUMA node2 CPU(s): 16-23,80-87 NUMA node3 CPU(s): 24-31,88-95 NUMA node4 CPU(s): 32-39,96-103 NUMA node5 CPU(s): 40-47,104-111 NUMA node6 CPU(s): 48-55,112-119 NUMA node7 CPU(s): 56-63,120-127
64 个 core 的分配策略 1 2 3 4 5 physical core processor 0 0~15 0~15 1 0~15 16~31 0 0~15 32~47 1 0~15 48~63
海光bios配置 1 2 3 4 5 6 在grub.conf里面加入noibrs noibpb nopti nospectre_v2 nospectre_v1 l1tf=off nospec_store_bypass_disable no_stf_barrier mds=off tsx=on tsx_async_abort=off mitigations=off iommu.passthrough=1;持久化ip;挂盘参数defaults,noatime,nodiratime,lazytime,delalloc,nobarrier,data=writeback(因为后面步骤要重启,把一些OS优化也先做了) 2. bios设置里面 配置 Hygon 设定 --- DF选项 --- 内存交错 --- Channel --- NB选项 --- 关闭iommu 打开CPB 风扇模式设置为高性能模式
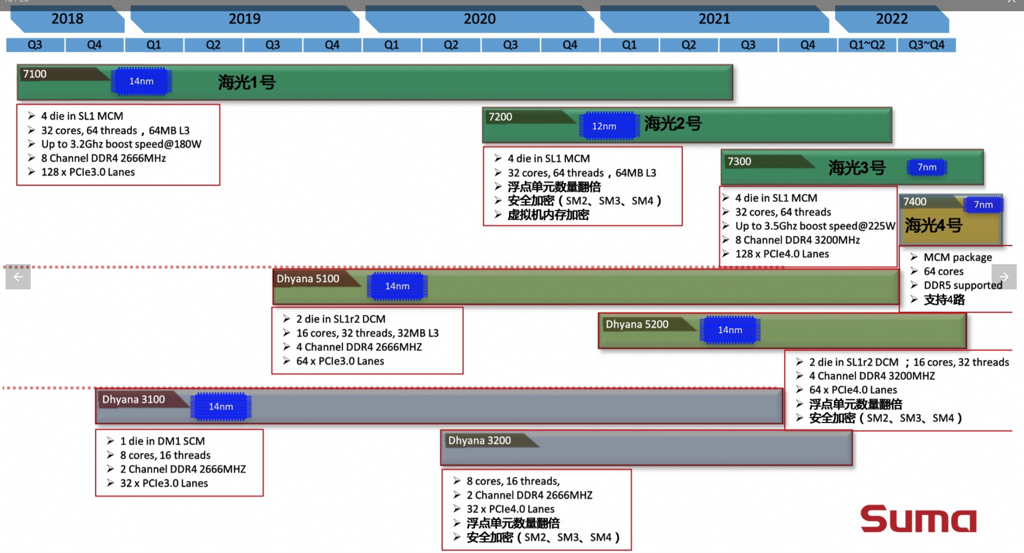
海光简介 公司成立于2016年3月,当前送测处理器为其第一代1.0版本的7185对标处理器为Intel的E5-2680V4,其服务器样机为曙光H620-G30。
海光CPU的命名规则:
其后续roadmap如下图
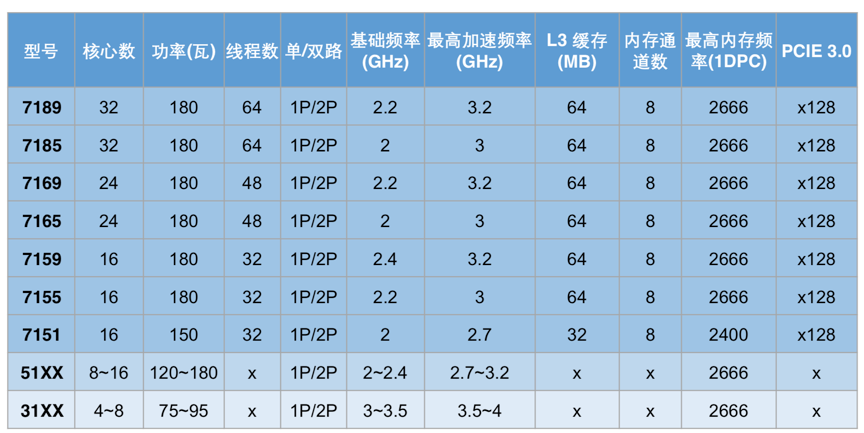
海光其产品规格如下,产品相对密集,但是产品之间差异化很小,频率总体接近。
AMD授权Zen IP给海光的操作是先成立合资公司,授权给合资公司基于Zen 研发新的 CPU,而且转让给中国的所有信息都符合美国出口法规**。**天津海光和AMD成立的合资公司可以修改AMD的CPU核,变相享有X86授权,而海光公司可以通过购买合资公司研发的CPU核,开发服务器CPU,不过仅仅局限于中国市场。
AMD与国内公司A成立合资公司B,合资公司B由AMD控股,负责开发CPU核(其实就是拿AMD现成的内核),然后公司A购买合资公司B开发的CPU核,以此为基础开发CPU,最终实现ARM卖IP核的翻版。
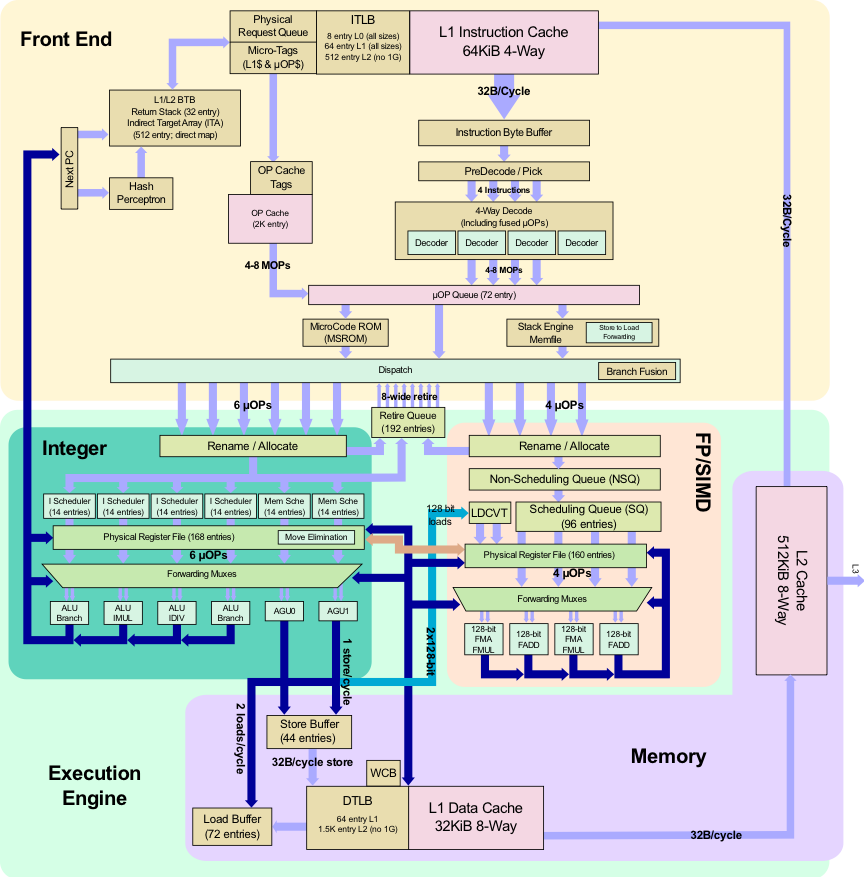
海光与AMD 的 Ryzen/EPYC 比较 由于在 Zen 1 的基础上进行了大量的修改,海光 CPU 可以不用简单地称之为换壳 AMD 处理器了。但其性能相比同代原版 CPU 略差:整数性能基本相同,浮点性能显著降低——普通指令吞吐量只有基准水平的一半。海光 CPU 的随机数生成机制也被修改,加密引擎已被替换,不再对常见的 AES 指令进行加速,但覆盖了其他面向国内安全性的指令如 SM2、SM3 和 SM4。
相同 与 AMD 的 Ryzen/EPYC 相比,海光处理器究竟有哪些不同?总体而言,核心布局是相同的,缓存大小、TLB 大小和端口分配都相同,在基础级别上两者没有差异。CPU 仍然是 64KB 四路 L1 指令缓存,32KB 八路 L1 数据缓存,512KB 八路 L2 缓存以及 8MB 十六路 L3 缓存,与 Zen 1 核心完全相同。
不同 加密方式变化**
在 Linux 内核升级中有关加密变化的信息已经明示。这些更新围绕 AMD 虚拟化功能(SEV)的安全加密进行。通常对于 EPYC 处理器来说,SEV 由 AMD 定义的加密协议控制,在这种情况下为 RSA、ECDSA、ECDH、SHA 和 AES。
但在海光 Dhyana 处理器中,SEV 被设计为使用 SM2、SM3 和 SM4 算法。在更新中有关 SM2 的部分声明道,这种算法基于椭圆曲线加密法,且需要其他私钥/公钥交换;SM3 是一种哈希算法,类似于 SHA-256;而 SM4 是类似于 AES-128 的分组密码算法。为支持这些算法所需的额外功能,其他指令也被加入到了 Linux 内核中。在说明文件中指出,这些算法已在 Hygon Dhyana Plus 处理器上成功进行测试,也已在 AMD 的 EPYC CPU 上成功测试。
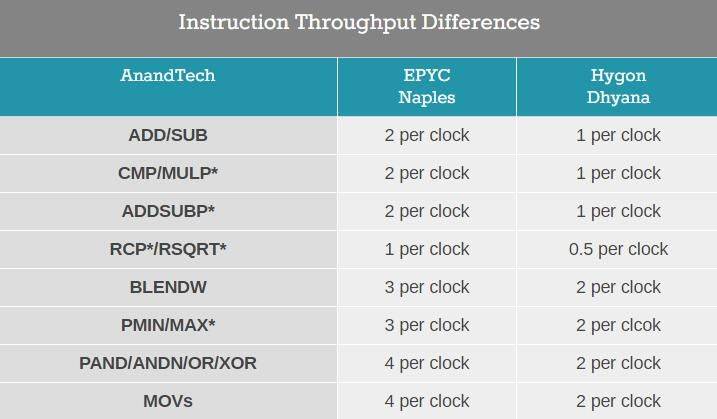
此外,海光与 AMD 原版芯片最大的设计区别在于吞吐 量,尽管整数性能相同,但海光芯片对于某些浮点指令并未做流水线处理,这意味着吞吐量和延迟都减小了:
这些对于最基础的任务来说也会有所影响,降低吞吐量的设计会让 CPU 在并行计算时性能受限。另外一个最大的变化,以及 Dhyana 与服务器版的「Dhyana Plus」版本之间的不同在于随机数生成的能力。
Openjdk 对海光的支持 https://github.com/openjdk/jdk/commit/d03cf75344fccba375881f0dab4ad169254e650c
https://bugs.openjdk.org/browse/JDK-8222090
https://github.com/dragonwell-project/dragonwell11/pull/517
比较不同 NUMA 方式 bios on and os cmdline off 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 lscpu 架构: x86_64 CPU 运行模式: 32-bit, 64-bit 字节序: Little Endian Address sizes: 43 bits physical, 48 bits virtual CPU: 96 在线 CPU 列表: 0-95 每个核的线程数: 2 每个座的核数: 24 座: 2 NUMA 节点: 1 厂商 ID: HygonGenuine CPU 系列: 24 型号: 1 型号名称: Hygon C86 7260 24-core Processor 步进: 1 Frequency boost: enabled CPU MHz: 1603.426 CPU 最大 MHz: 2200.0000 CPU 最小 MHz: 1200.0000 BogoMIPS: 4399.55 虚拟化: AMD-V L1d 缓存: 1.5 MiB L1i 缓存: 3 MiB L2 缓存: 24 MiB L3 缓存: 128 MiB NUMA 节点0 CPU: 0-95 # uname -r 4.19.90-23.8.v2101.ky10.x86_64
测试命令和结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 //以下多个测试方式的结果一样 for i in $(seq 0 6 47); do echo core:$i; taskset -c $i ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1 for i in $(seq 0 6 47); do echo core:$i; numactl -C $i -m 0 ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1 cat lat.log |grep -E "core:|64.0000" core:0 64.00000 270.555 core:6 64.00000 231.677 core:12 64.00000 268.527 core:18 64.00000 268.878 core:24 64.00000 158.644 core:30 64.00000 159.796 core:36 64.00000 162.938 core:42 64.00000 112.052 //不绑核会一直慢,因为刚好内存在高地址,程序大概率在低core上运行 for i in $(seq 0 6 47); do echo core:$i; numactl -C $i -m 0 ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1 #cat lat.log |grep -E "core:|64.0000" core:0 64.00000 267.904 core:6 64.00000 266.112 core:12 64.00000 265.657 core:18 64.00000 266.033 core:24 64.00000 269.574 core:30 64.00000 269.640 core:36 64.00000 269.639 core:42 64.00000 266.373
如果绑核,看起来还是能识别距离远近,但是需要同时绑内存,默认绑核不绑核内存达不到就近分配
内置分配默认从高地址开始,所以core 0总是最慢的。
不绑核的话内存默认是在高地址,程序大概率远程访问内存,所以极慢
bios off 测试命令和结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 //以下三个命令结果一致 for i in $(seq 0 6 47); do echo core:$i; taskset -c $i ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1 for i in $(seq 0 6 47); do echo core:$i; numactl -C $i -m 0 ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1 for i in $(seq 0 6 47); do echo core:$i; ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1 cat lat.log |grep -E "core:|64.0000" core:0 64.00000 197.570 core:6 64.00000 204.362 core:12 64.00000 198.356 core:18 64.00000 197.049 core:24 64.00000 202.469 core:30 64.00000 199.367 core:36 64.00000 197.790 core:42 64.00000 197.757
rt稳定在200,之所以不符合短板原理是测试中多次取平均导致的,慢的还是慢,有的在近有的在远的地址,但平均值稳定
交错编址的时候不会把一个cacheline拆分到多个node下的内存条上
测试结果和OS的启动参数是否numa=off无关
bios off后没有机会识别内存远近,也就是反复循环分配内存不可能一直分配到本node内
bios on and os on 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian Address sizes: 43 bits physical, 48 bits virtual CPU(s): 48 On-line CPU(s) list: 0-47 Thread(s) per core: 1 Core(s) per socket: 24 Socket(s): 2 NUMA node(s): 8 Vendor ID: HygonGenuine CPU family: 24 Model: 1 Model name: Hygon C86 7260 24-core Processor Stepping: 1 Frequency boost: enabled CPU MHz: 1069.030 CPU max MHz: 2200.0000 CPU min MHz: 1200.0000 BogoMIPS: 4399.35 Virtualization: AMD-V L1d cache: 1.5 MiB L1i cache: 3 MiB L2 cache: 24 MiB L3 cache: 128 MiB NUMA node0 CPU(s): 0-5 NUMA node1 CPU(s): 6-11 NUMA node2 CPU(s): 12-17 NUMA node3 CPU(s): 18-23 NUMA node4 CPU(s): 24-29 NUMA node5 CPU(s): 30-35 NUMA node6 CPU(s): 36-41 NUMA node7 CPU(s): 42-47
测试命令和参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 for i in $(seq 0 6 47); do echo core:$i; numactl -C $i -m 0 ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1 # cat lat.log |grep -E "core:|64.0000" core:0 64.00000 113.048 core:6 64.00000 167.637 core:12 64.00000 164.398 core:18 64.00000 163.328 core:24 64.00000 277.176 core:30 64.00000 277.157 core:36 64.00000 226.747 core:42 64.00000 278.472 绑核不绑内存或者不绑核运行结果是一样的 for i in $(seq 0 6 47); do echo core:$i; taskset -c $i ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1 for i in $(seq 0 6 47); do echo core:$i; taskset -c $i ./bin/lat_mem_rd -W 5 -N 5 -t 64M; done >lat.log 2>&1 #cat lat.log |grep -E "core:|64.0000" core:0 64.00000 112.990 core:6 64.00000 113.358 core:12 64.00000 114.146 core:18 64.00000 112.288 core:24 64.00000 114.103 core:30 64.00000 113.331 core:36 64.00000 114.151 core:42 64.00000 113.117
结论
只要是bios numa off后用 lat_mem_rd 测试的 rt 是一个大规模次数后的平均值,但是远近内存问题仍然存在,会导致抖动和卡顿
如果 bios numa on,但是 OS numa off,绑核的话会分别看到不同核访问内存差异极大
如果 bios numa on,同时 OS numa on,这种情况绑核后会出现完美就近访问,性能最佳
默认地址分配从高地址开始,如果numa off 那么core 0 最慢;如果 numa on 且绑核会一直快;如果 numa on 但是不绑核,多次测试也是一直快