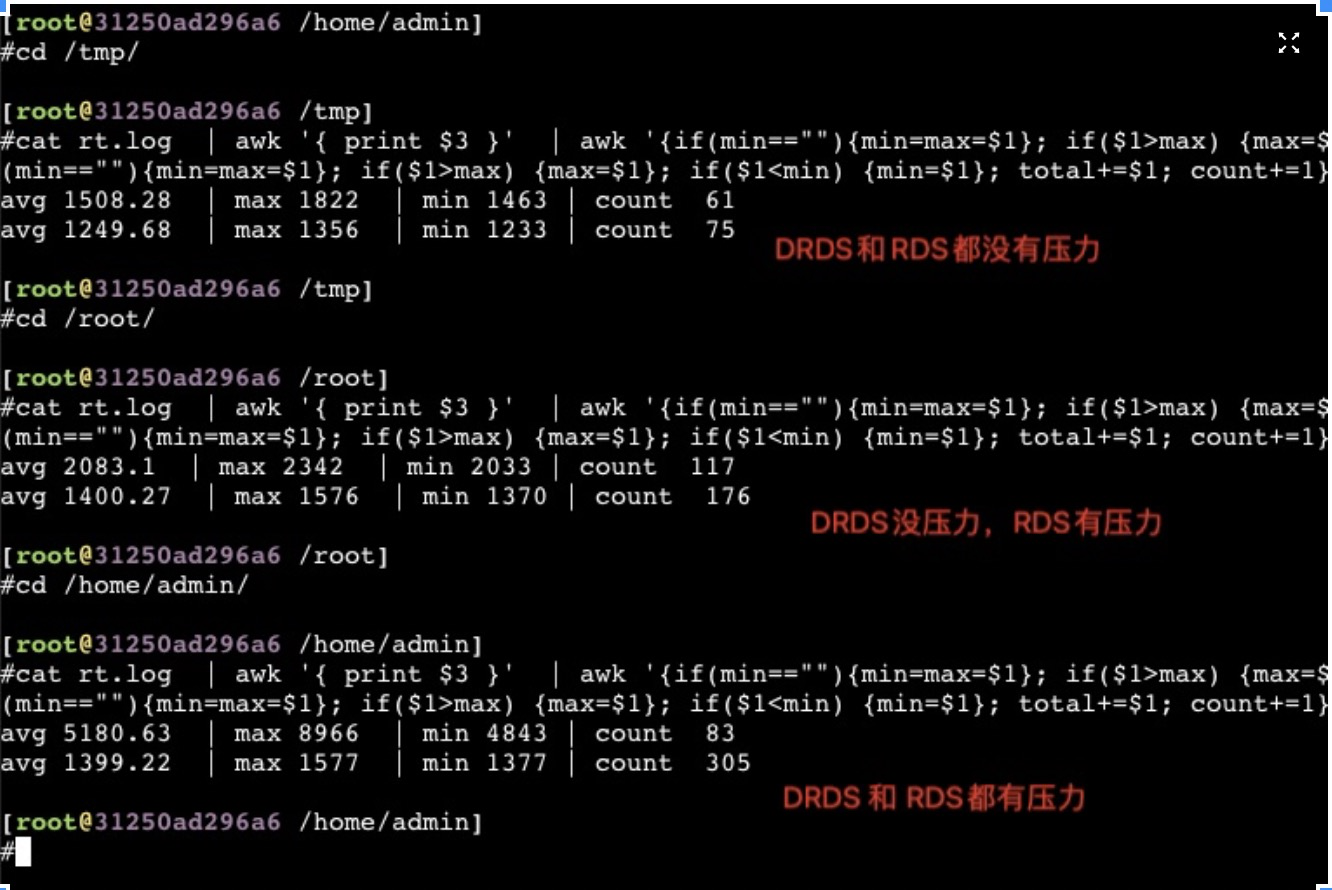
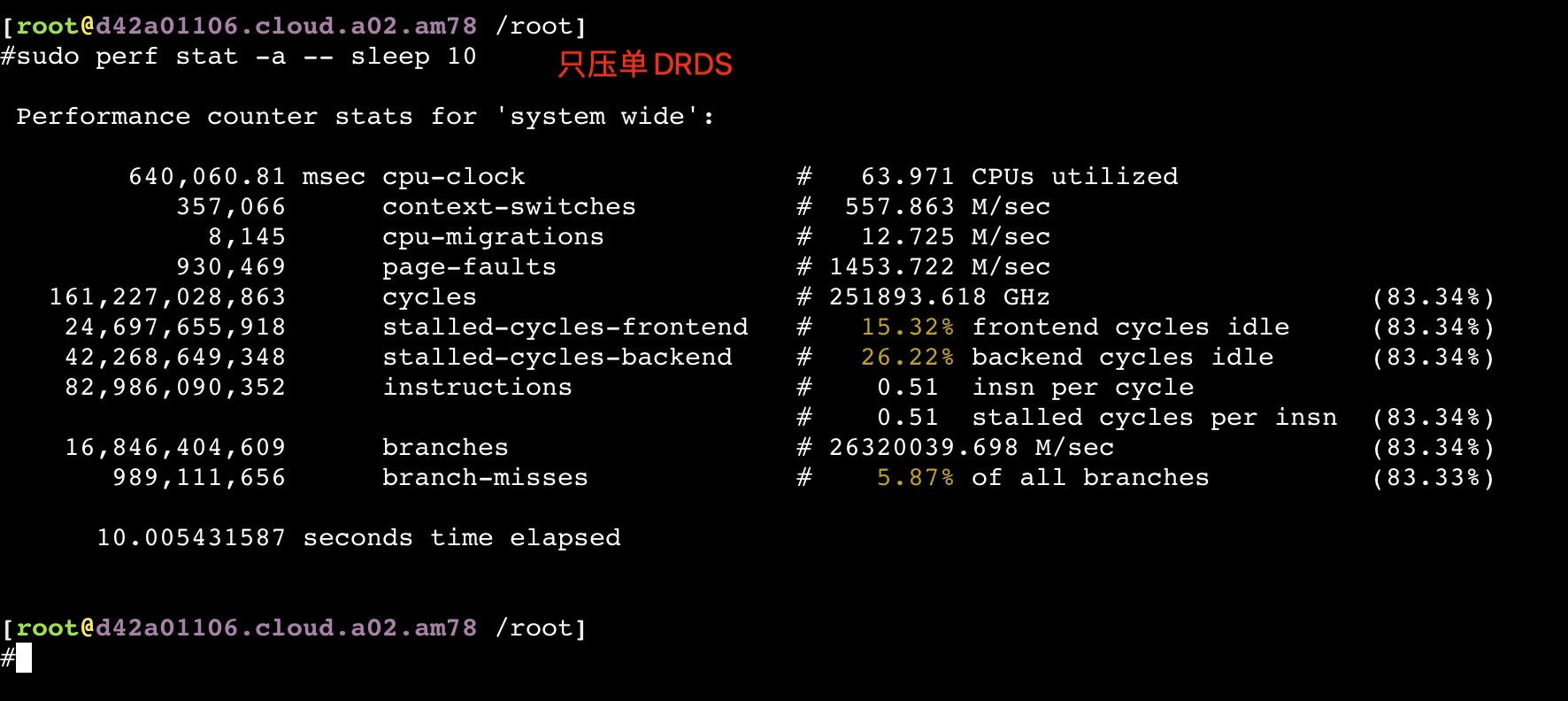
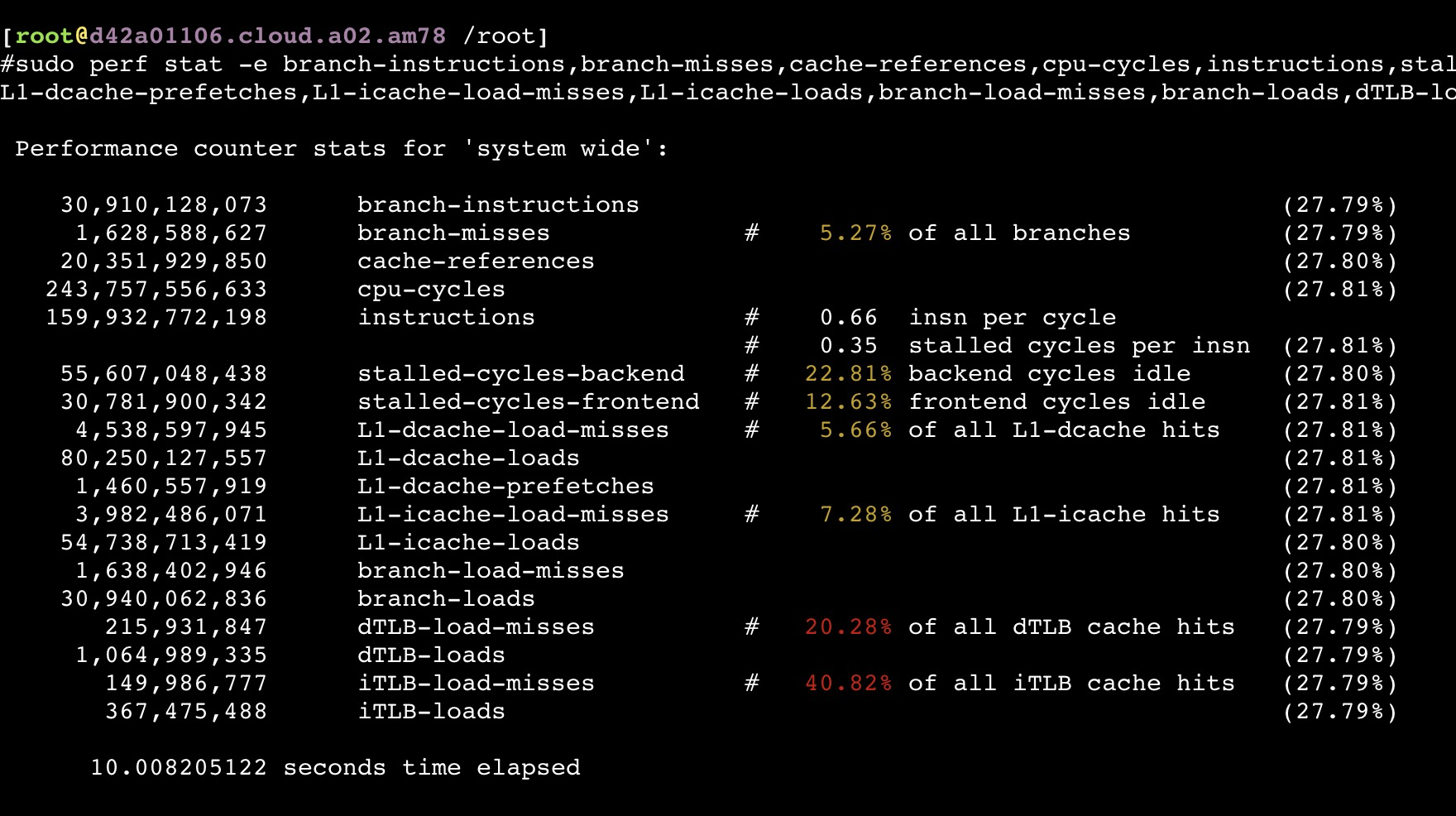
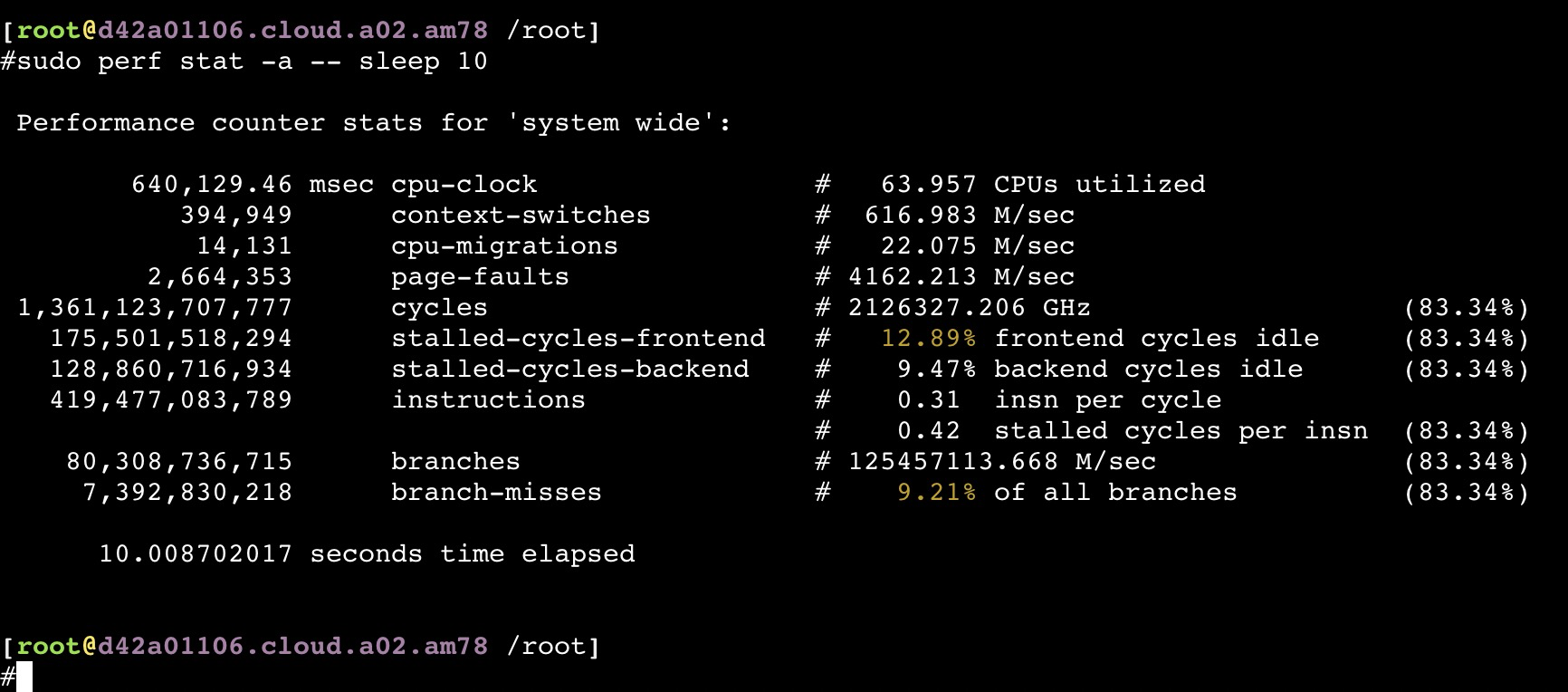
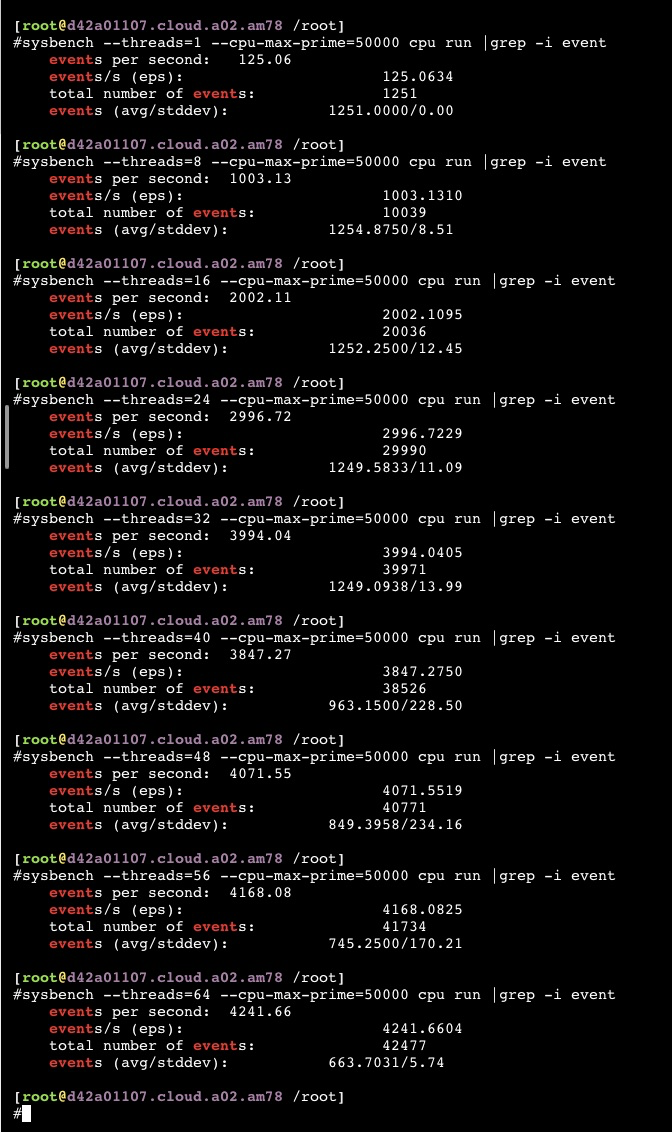
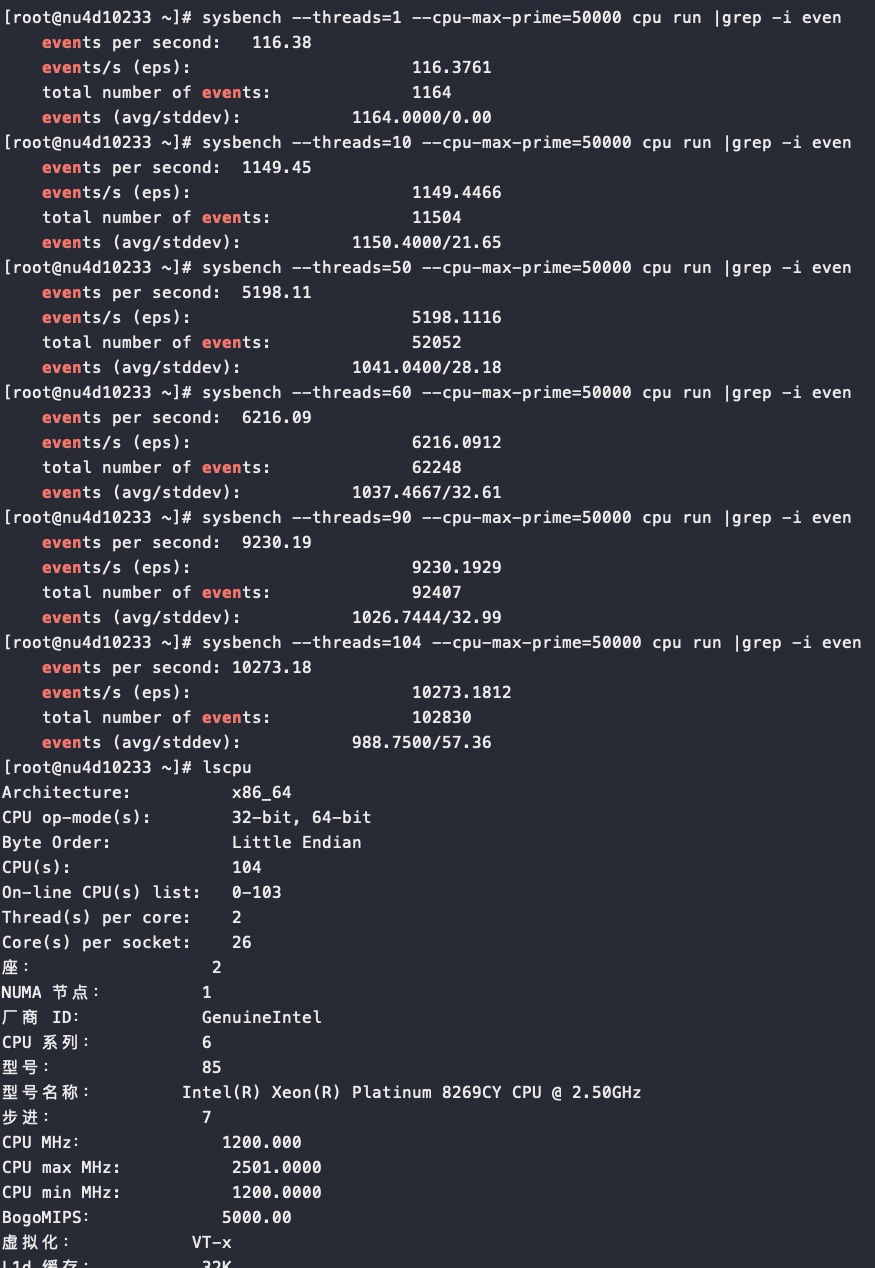
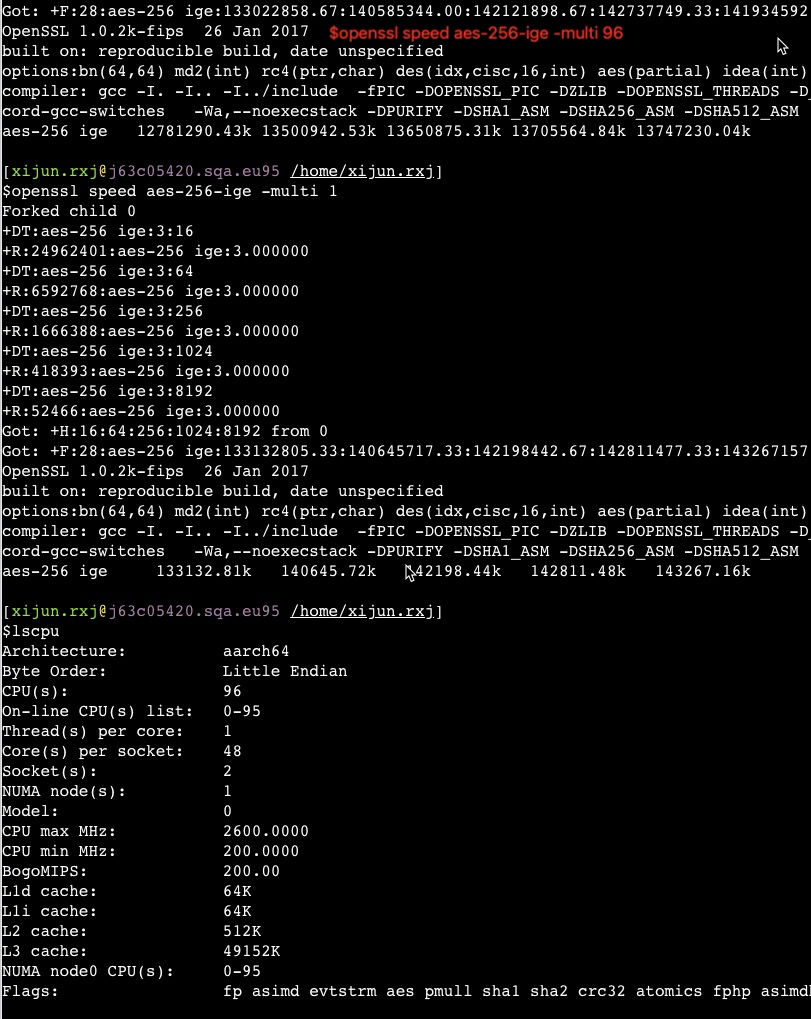
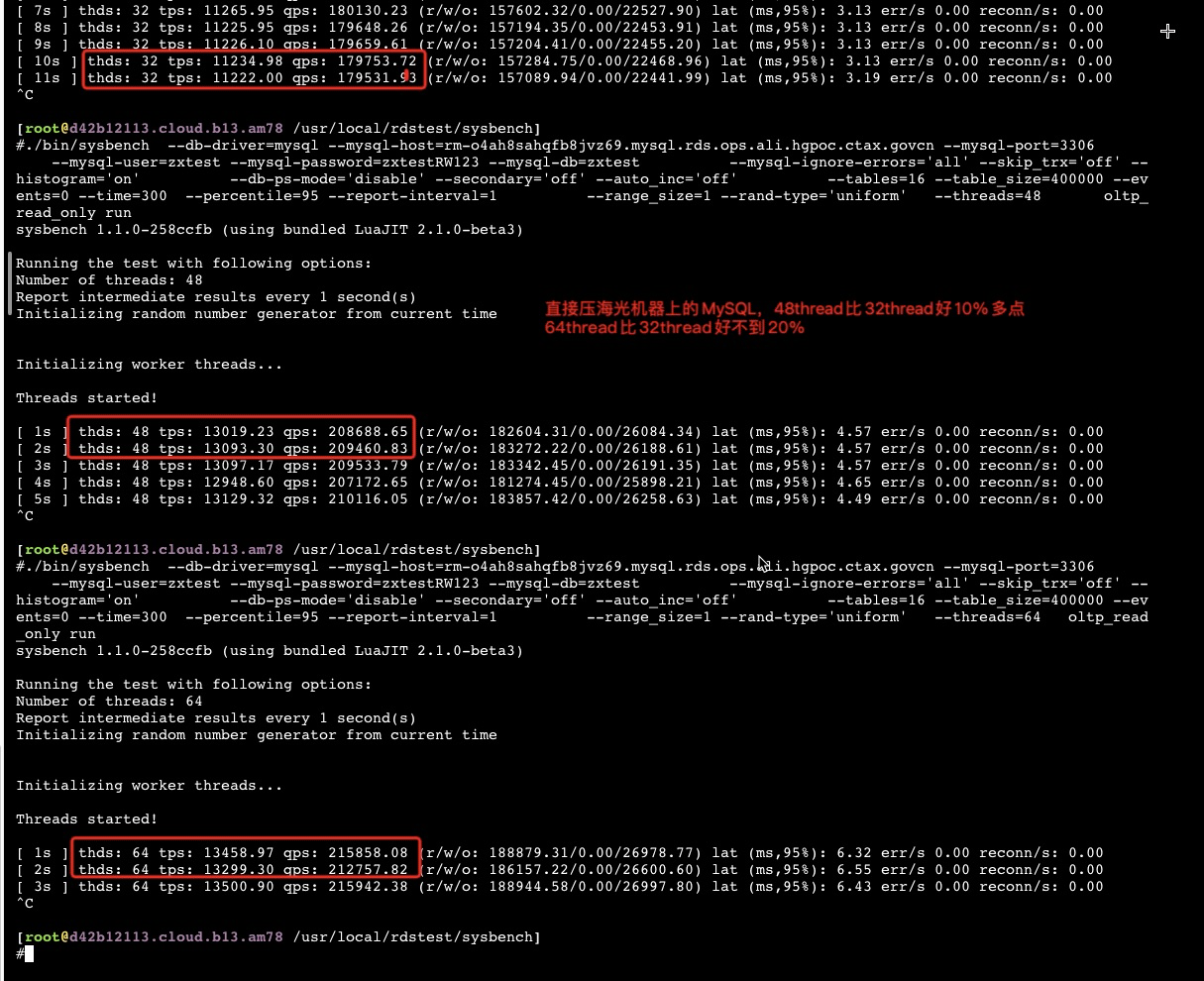
从以上截图,可以看到关键的 insn per cycle 能到0.51和0.66(这个数值越大性能越好)
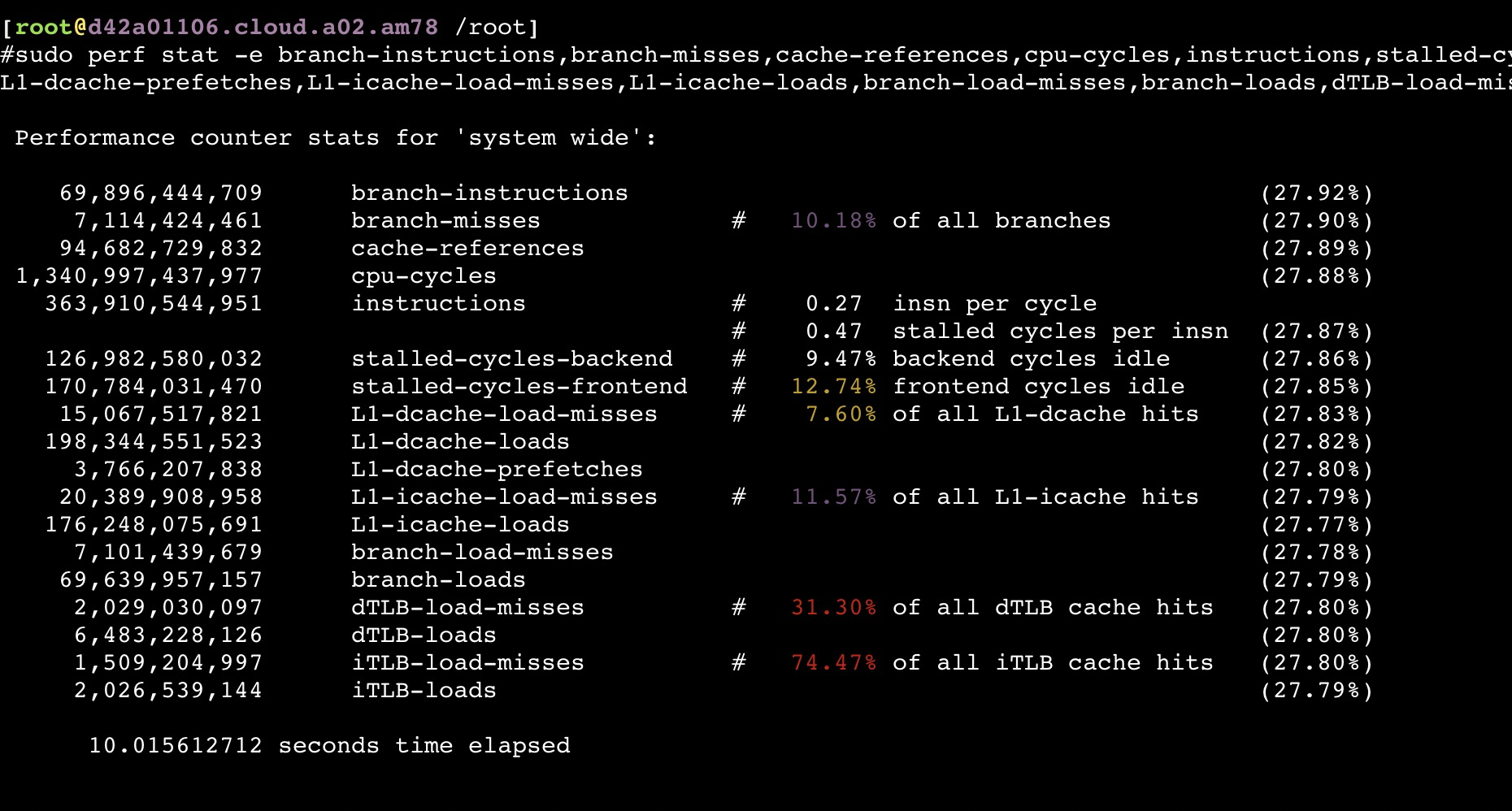
如果同时压物理机上的所有服务节点
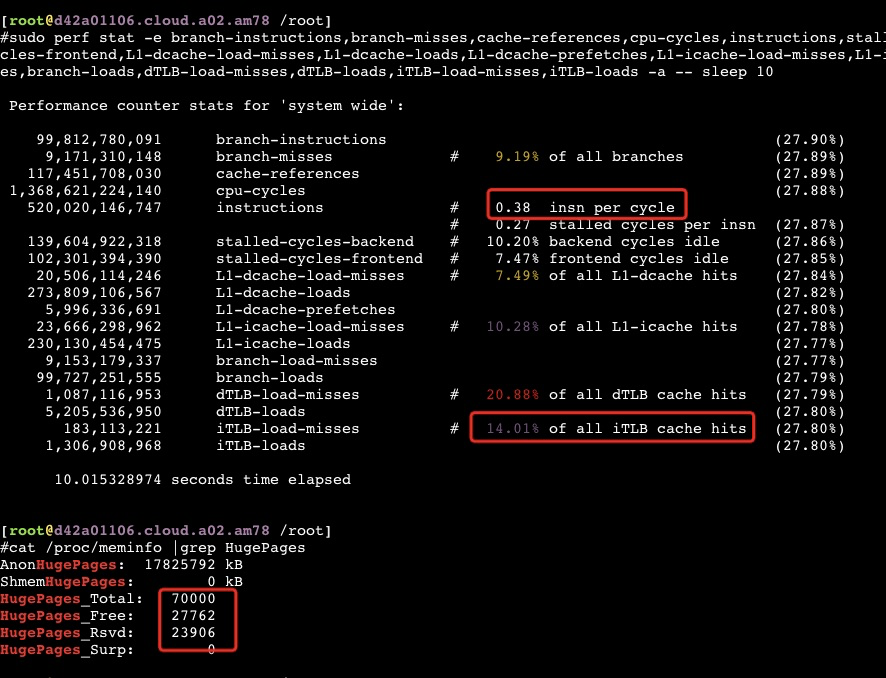
从以上截图,可以看到关键的 insn per cycle 能降到了0.27和0.31(这个数值越大性能越好),基本相当于单压的5折
通过 perf list 找出所有Hardware event,然后对他们进行perf:
1
sudo perf stat -e branch-instructions,branch-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-prefetches,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads -a -- `pidof java`
If you are using the option -XX:+UseSHM or -XX:+UseHugeTLBFS, then specify the number of large pages. In the following example, 3 GB of a 4 GB system are reserved for large pages (assuming a large page size of 2048kB, then 3 GB = 3 * 1024 MB = 3072 MB = 3072 * 1024 kB = 3145728 kB and 3145728 kB / 2048 kB = 1536):
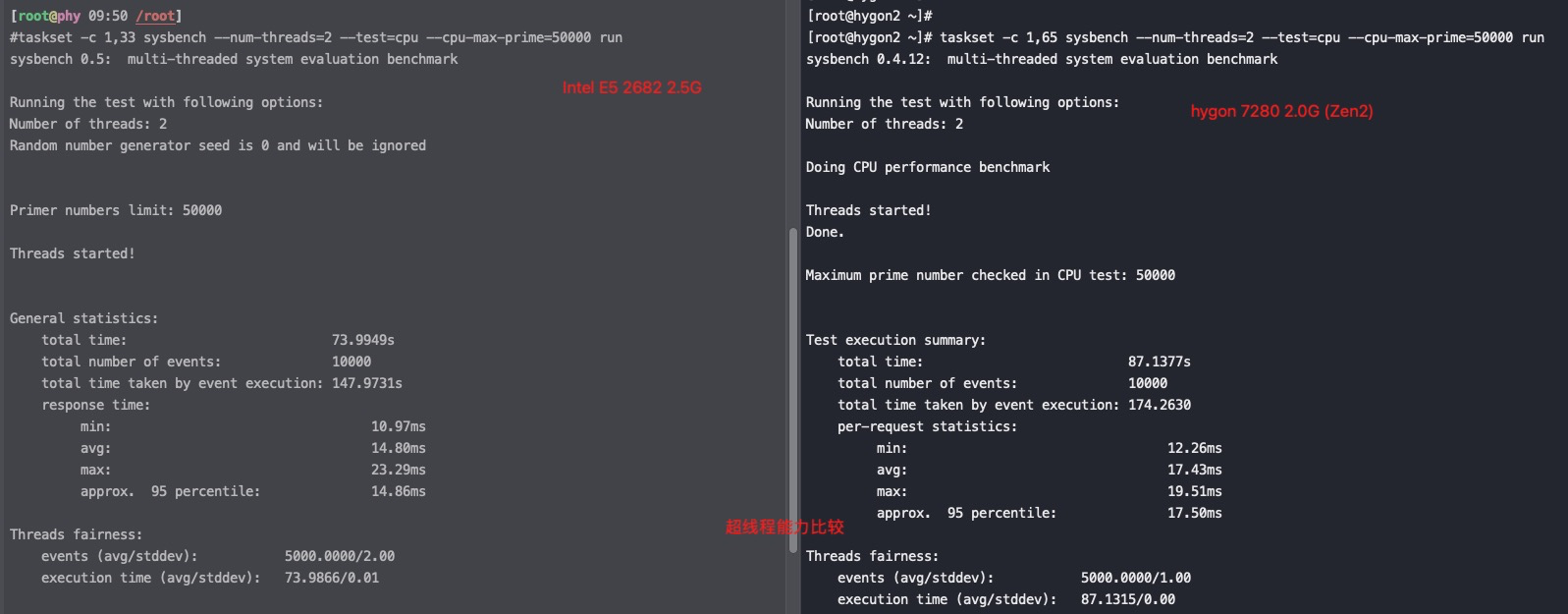
#taskset -c 1,53 /usr/bin/sysbench --num-threads=2 --test=cpu --cpu-max-prime=50000 run sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options: Number of threads: 2 Random number generator seed is 0 and will be ignored
Primer numbers limit: 50000
Threads started!
General statistics: total time: 48.5571s total number of events: 10000 total time taken by event execution: 97.0944s response time: min: 8.29ms avg: 9.71ms max: 20.88ms approx. 95 percentile: 9.71ms
Threads fairness: events (avg/stddev): 5000.0000/2.00 execution time (avg/stddev): 48.5472/0.01
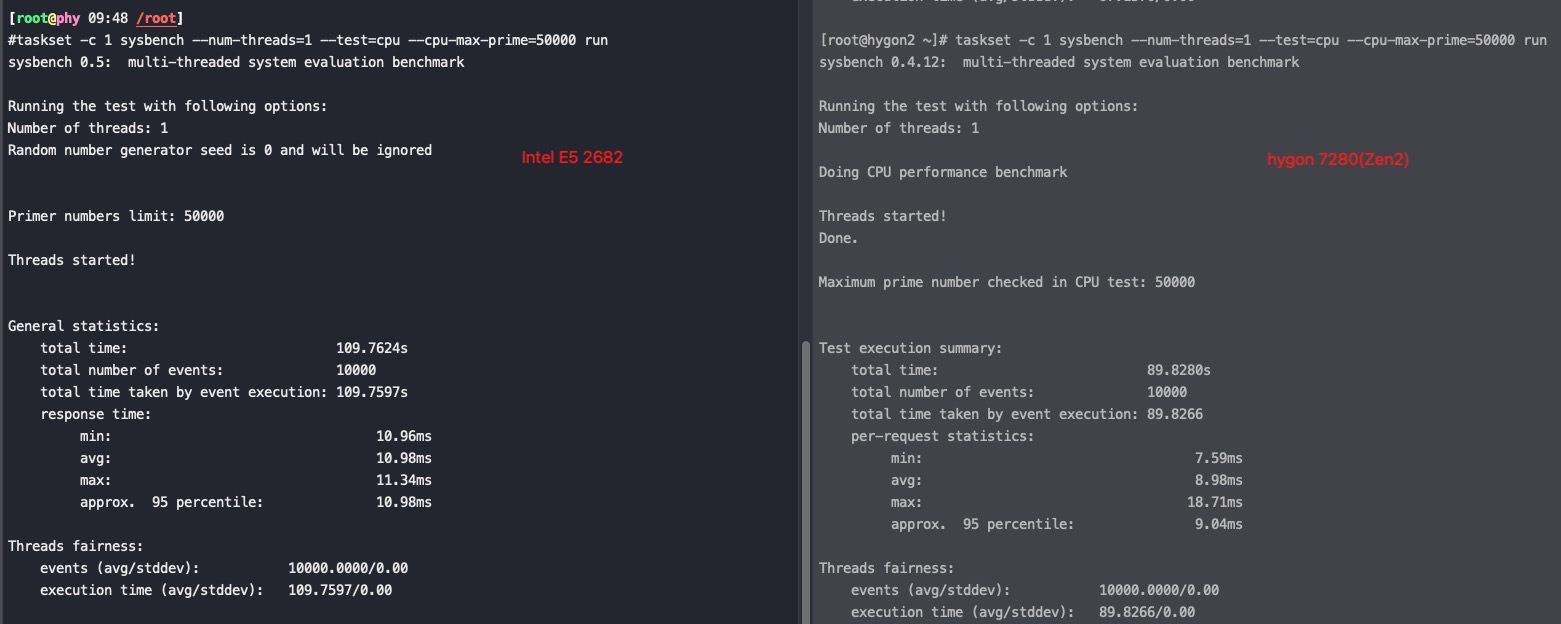
#taskset -c 1 /usr/bin/sysbench --num-threads=1 --test=cpu --cpu-max-prime=50000 run sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options: Number of threads: 1 Random number generator seed is 0 and will be ignored
Primer numbers limit: 50000
Threads started!
General statistics: total time: 83.2642s total number of events: 10000 total time taken by event execution: 83.2625s response time: min: 8.27ms avg: 8.33ms max: 10.03ms approx. 95 percentile: 8.36ms
Threads fairness: events (avg/stddev): 10000.0000/0.00 execution time (avg/stddev): 83.2625/0.00
#lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 104 On-line CPU(s) list: 0-103 Thread(s) per core: 2 Core(s) per socket: 26 Socket(s): 2 NUMA node(s): 2 Vendor ID: GenuineIntel CPU family: 6 Model: 85 Model name: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz Stepping: 7 CPU MHz: 3200.097 CPU max MHz: 3800.0000 CPU min MHz: 1200.0000 BogoMIPS: 4998.89 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 1024K L3 cache: 36608K NUMA node0 CPU(s): 0-25,52-77 NUMA node1 CPU(s): 26-51,78-103 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch ida arat epb invpcid_single pln pts dtherm spec_ctrl ibpb_support tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt avx512f avx512dq rdseed adx smap clflushopt avx512cdavx512bw avx512vl xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local cat_l3 mba