十年后数据库还是不敢拥抱NUMA?
十年后数据库还是不敢拥抱NUMA?
在2010年前后MySQL、PG、Oracle数据库在使用NUMA的时候碰到了性能问题,流传最广的这篇 MySQL – The MySQL “swap insanity” problem and the effects of the NUMA architecture 描述了性能问题的原因(文章中把原因找错了)以及解决方案:关闭NUMA。 实际这个原因是kernel实现的一个低级bug,这个Bug在2014年修复了,但是修复这么多年后仍然以讹传讹,这篇文章希望正本清源、扭转错误的认识。
背景
最近在做一次性能测试的时候发现MySQL实例有一个奇怪现象,在128core的物理机上运行三个MySQL实例,每个实例分别绑定32个物理core,绑定顺序就是第一个0-31、第二个32-63、第三个64-95,实际运行结果让人大跌眼镜,如下图
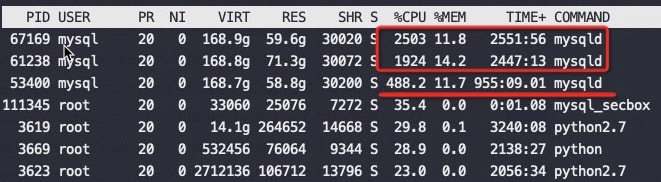
从CPU消耗来看差异巨大,高的实例CPU用到了2500%,低的才488%,差了5倍。但是神奇的是他们的QPS一样,执行的SQL也是一样
所有MySQL实例流量一样
那么问题来了为什么在同样的机器上、同样的流量下CPU使用率差了这么多? 换句话来问就是CPU使用率高就有效率吗?
这台物理机CPU 信息
1 | #lscpu |
原因分析
先来看这两个MySQL 进程的Perf数据
1 | #第二个 MySQL IPC只有第三个的30%多点,这就是为什么CPU高这么多,但是QPS差不多 |
从上面可以看到 IPC 差异巨大0.04 VS 0.14 ,也就是第一个MySQL的CPU效率很低,我们看到的CPU running实际是CPU在等待(stall)。
CPU的实际信息
找到同一个机型,但是NUMA开着的查了一下:
1 | #lscpu |
这告诉我们实际上这个机器有16个NUMA,跨NUMA访问内存肯定比访问本NUMA内的要慢几倍。
关于NUMA
如下图,是一个Intel Xeon E5 CPU的架构信息,左右两边的大红框分别是两个NUMA,每个NUMA的core访问直接插在自己红环上的内存必然很快,如果访问插在其它NUMA上的内存还要走两个红环之间上下的黑色箭头线路,所以要慢很多。
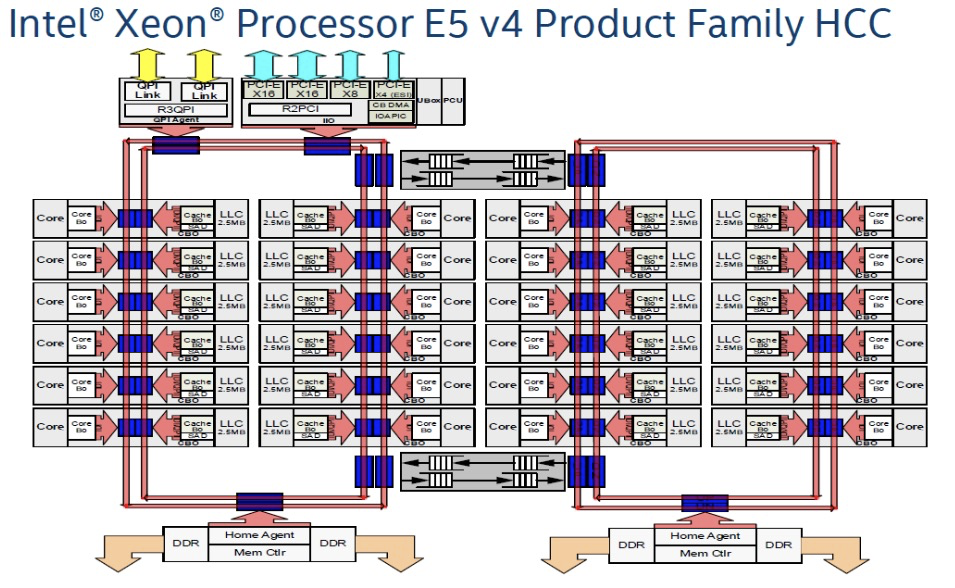
实际测试Intel的E5-2682(对应V42机型)和8269(对应V62机型) 的CPU跨Socket(这两块CPU内部不再是上图的红环Bus,而是改用了Mesh Bus一个Die就是一个NUMA,服务器有两路,也就是一个Socket就是一个NUMA),也就是跨NUMA访问内存的延迟是本Node延迟的将近2倍。测试工具从这里下载
1 | //E5-2682 |
开启NUMA会优先就近使用内存,在本NUMA上的内存不够的时候可以选择回收本地的PageCache还是到其它NUMA 上分配内存,这是可以通过Linux参数 zone_reclaim_mode 来配置的,默认是到其它NUMA上分配内存,也就是跟关闭NUMA是一样的。
这个架构距离是物理上就存在的不是你在BIOS里关闭了NUMA差异就消除了,我更愿意认为在BIOS里关掉NUMA只是掩耳盗铃。
以上理论告诉我们:也就是在开启NUMA和 zone_reclaim_mode 默认在内存不够的如果去其它NUMA上分配内存,比关闭NUMA要快很多而没有任何害处。
UMA和NUMA对比
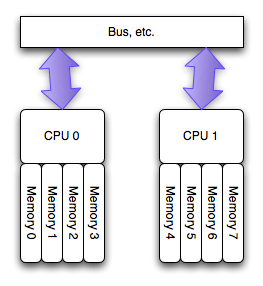
The SMP/UMA architecture
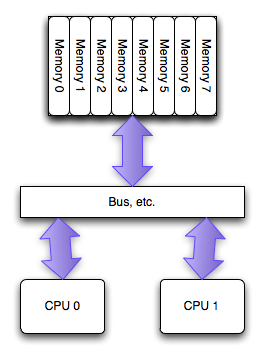
The NUMA architecture
Modern multiprocessor systems mix these basic architectures as seen in the following diagram:
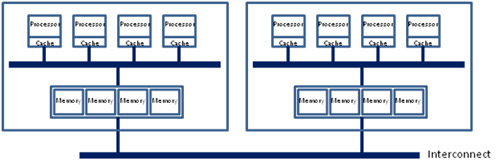
In this complex hierarchical scheme, processors are grouped by their physical location on one or the other multi-core CPU package or “node.” Processors within a node share access to memory modules as per the UMA shared memory architecture. At the same time, they may also access memory from the remote node using a shared interconnect, but with slower performance as per the NUMA shared memory architecture.

对比测试Intel NUMA 性能
对如下Intel CPU进行一些测试,在开启NUMA的情况下
1 | #lscpu |
我在这个64core的物理机上运行一个MySQL 实例,先将MySQL进程绑定在0-63core,0-31core,以及0-15,32-47上
用sysbench对一亿条记录跑点查,数据都加载到内存中了:
- 绑0-63core qps 不到8万,总cpu跑到5000%,降低并发的话qps能到11万;
- 如果绑0-31core qps 12万,总cpu跑到3200%,IPC 0.29;
- 如果绑同一个numa下的32core,qps飙到27万,总CPU跑到3200% IPC: 0.42;
- 绑0-15个物理core,qps能到17万,绑32-47也是一样的效果;
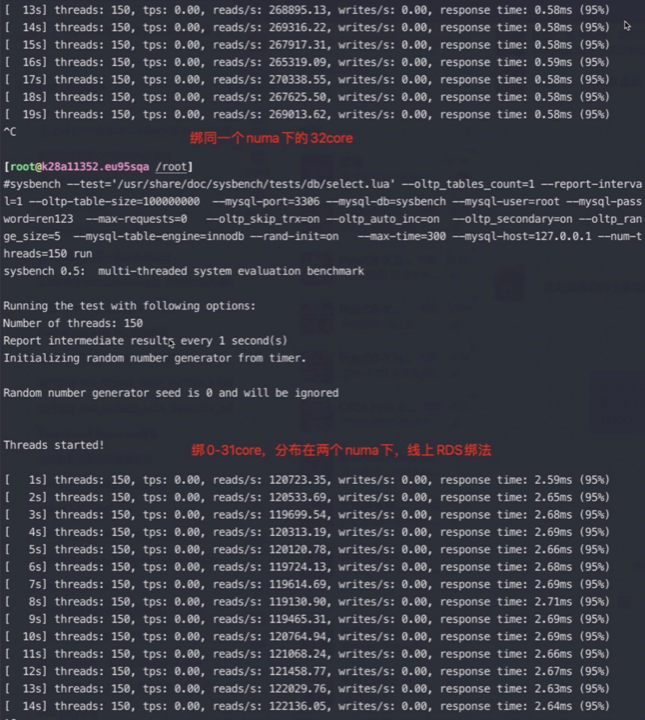
从这个数据看起来即使Intel在只有两个NUMA的情况下跨性能差异也有2倍,可见正确的绑核方法收益巨大,尤其是在刷榜的情况下, NUMA更多性能差异应该会更大。
说明前面的理论是正确的。
来看看不同绑核情况下node之间的带宽利用情况:
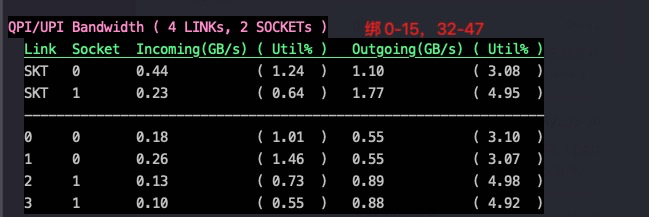
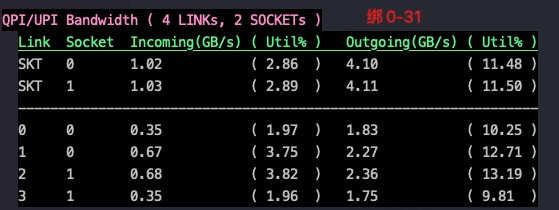
实际在不开NUMA的同样CPU上,进行以上各种绑核测试,测试结果也完全一样。
如果比较读写混合场景的话肯定会因为写锁导致CPU跑起来,最终的性能差异也不会这么大,但是绑在同一个NUMA下的性能肯定要好,IPC也会高一些。具体好多少取决于锁的竞争程度。
为什么集团内外所有物理机都把NUMA关掉了呢?
10年前几乎所有的运维都会多多少少被NUMA坑害过,让我们看看究竟有多少种在NUMA上栽的方式:
- MySQL – The MySQL “swap insanity” problem and the effects of the NUMA architecture
- PostgreSQL – PostgreSQL, NUMA and zone reclaim mode on linux
- Oracle – Non-Uniform Memory Access (NUMA) architecture with Oracle database by examples
- Java – Optimizing Linux Memory Management for Low-latency / High-throughput Databases
最有名的是这篇 MySQL – The MySQL “swap insanity” problem and the effects of the NUMA architecture
我总结下这篇2010年的文章说的是啥:
- 如果本NUMA内存不够的时候,Linux会优先回收PageCache内存,即使其它NUMA还有内存
- 回收PageCache经常会造成系统卡顿,这个卡顿不能接受
所以文章给出的解决方案就是(三选一):
- 关掉NUMA
- 或者启动MySQL的时候指定不分NUMA,比如:/usr/bin/numactl –interleave all $cmd
- 或者启动MySQL的时候先回收所有PageCache
我想这就是这么多人在上面栽了跟头,所以干脆一不做二不休干脆关了NUMA 一了百了。
但真的NUMA有这么糟糕?或者说Linux Kernel有这么笨,默认优先去回收PageCache吗?
Linux Kernel对NUMA内存的使用
实际我们使用NUMA的时候期望是:优先使用本NUMA上的内存,如果本NUMA不够了不要优先回收PageCache而是优先使用其它NUMA上的内存。
zone_reclaim_mode
事实上Linux识别到NUMA架构后,默认的内存分配方案就是:优先尝试在请求线程当前所处的CPU的Local内存上分配空间。如果local内存不足,优先淘汰local内存中无用的Page(Inactive,Unmapped)。然后才到其它NUMA上分配内存。
intel 芯片跨node延迟远低于其他家,所以跨node性能损耗不大
zone_reclaim_mode,它用来管理当一个内存区域(zone)内部的内存耗尽时,是从其内部进行内存回收还是可以从其他zone进行回收的选项:
zone_reclaim_mode:
Zone_reclaim_mode allows someone to set more or less aggressive approaches to
reclaim memory when a zone runs out of memory. If it is set to zero then no
zone reclaim occurs. Allocations will be satisfied from other zones / nodes
in the system.
zone_reclaim_mode的四个参数值的意义分别是:
0 = Allocate from all nodes before reclaiming memory
1 = Reclaim memory from local node vs allocating from next node
2 = Zone reclaim writes dirty pages out
4 = Zone reclaim swaps pages
1 | # cat /proc/sys/vm/zone_reclaim_mode |
我查了2.6.32以及4.19.91内核的机器 zone_reclaim_mode 都是默认0 ,也就是kernel会:优先使用本NUMA上的内存,如果本NUMA不够了不要优先回收PageCache而是优先使用其它NUMA上的内存。这也是我们想要的
Kernel文档也告诉大家默认就是0,但是为什么会出现优先回收了PageCache呢?
查看kernel提交记录
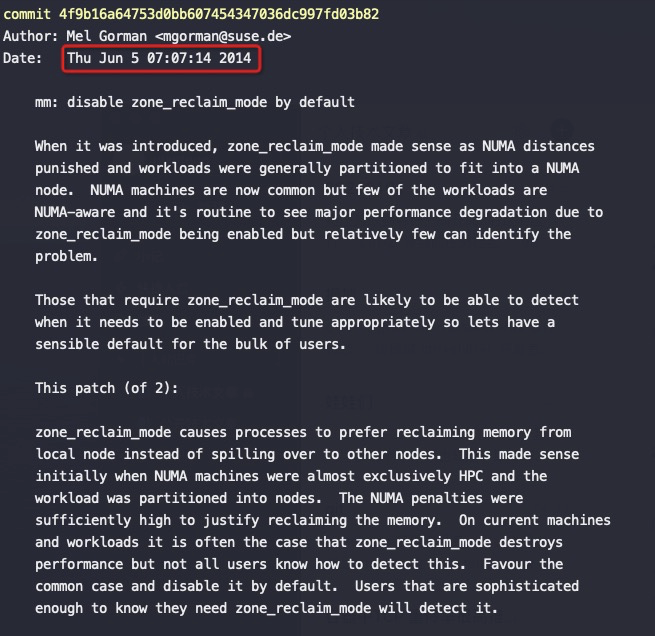
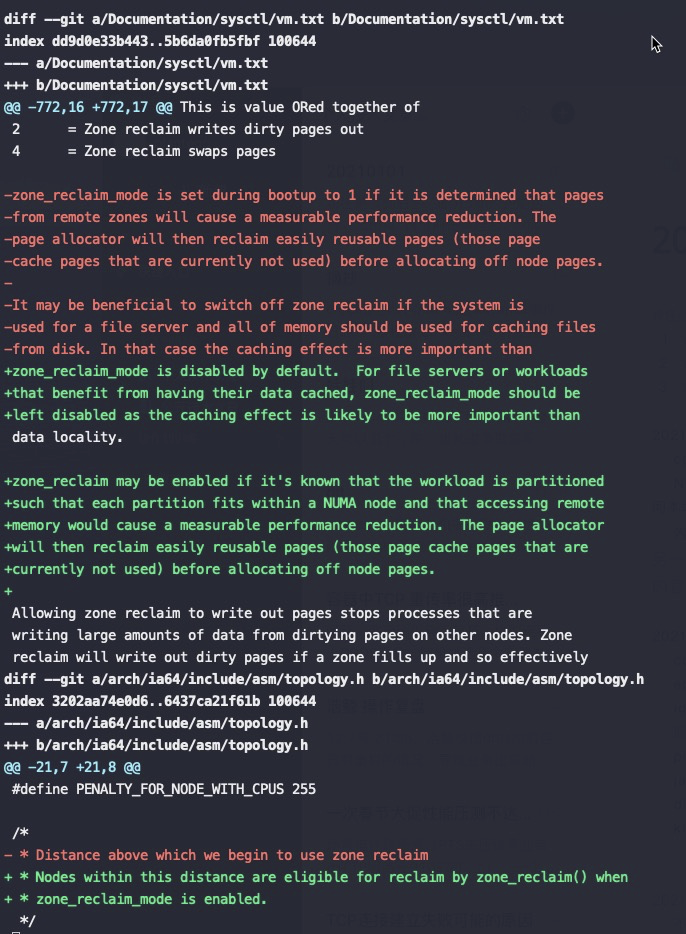
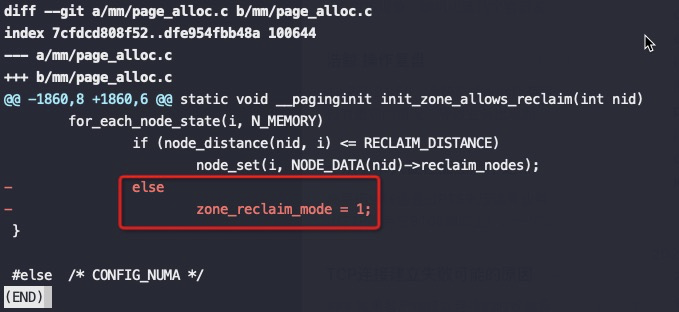
关键是上图红框中的代码,node distance比较大(也就是开启了NUMA的话),强制将 zone_reclaim_mode设为1,这是2014年提交的代码,将这个强制设为1的逻辑去掉了。
这也就是为什么之前大佬们碰到NUMA问题后尝试修改 zone_reclaim_mode 没有效果,也就是2014年前只要开启了NUMA就强制线回收PageCache,即使设置zone_reclaim_mode也没有意义,真是个可怕的Bug。
验证一下zone_reclaim_mode 0是生效的
内核版本:3.10.0-327.ali2017.alios7.x86_64
测试方法
先将一个160G的文件加载到内存里,然后再用代码分配64G的内存出来使用。
单个NUMA node的内存为256G,本身用掉了60G,加上这次的160G的PageCache,和之前的一些其他PageCache,总的 PageCache用了179G,那么这个node总内存还剩256G-60G-179G,
如果这个时候再分配64G内存的话,本node肯定不够了,我们来看在 zone_reclaim_mode=0 的时候是优先回收PageCache还是分配了到另外一个NUMA node(这个NUMA node 有240G以上的内存空闲)
测试过程
分配64G内存
1 | #taskset -c 0 ./alloc 64 |
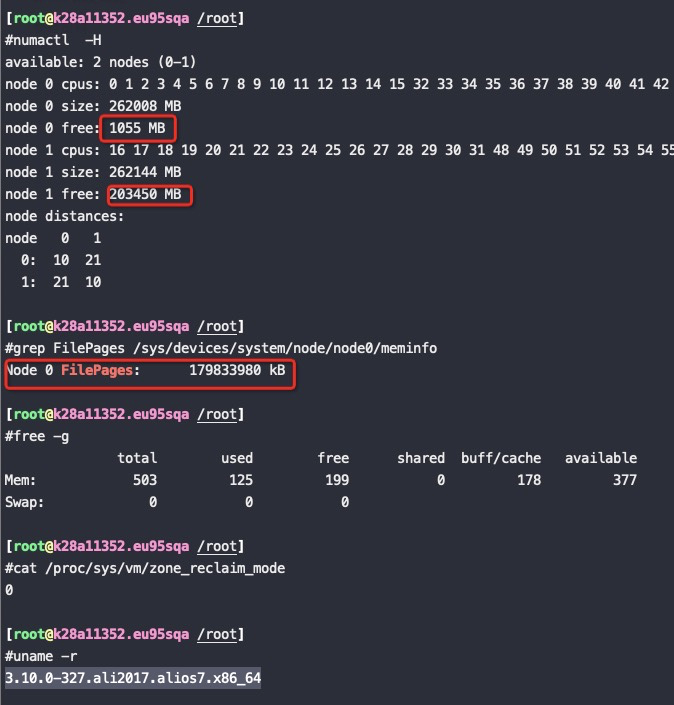
从如上截图来看,再分配64G内存的时候即使node0不够了也没有回收node0上的PageCache,而是将内存跨NUMA分配到了node1上,符合预期!
释放这64G内存后,如下图可以看到node0回收了25G,剩下的39G都是在node1上: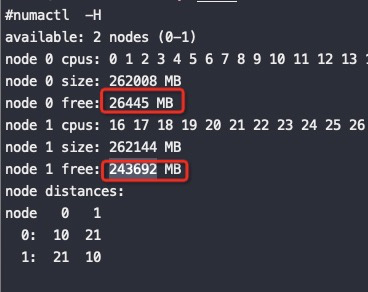
将 /proc/sys/vm/zone_reclaim_mode 改成 1 继续同样的测试
可以看到zone_reclaim_mode 改成 1,node0内存不够了也没有分配node1上的内存,而是从PageCache回收了40G内存,整个分配64G内存的过程也比不回收PageCache慢了12秒,这12秒就是额外的卡顿
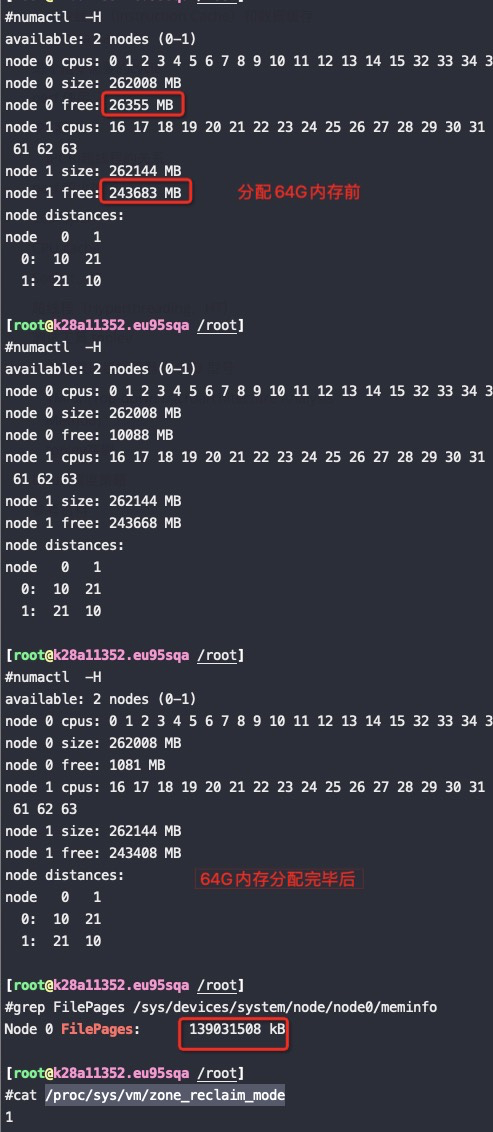
测试结论:从这个测试可以看到NUMA 在内存使用上不会优先回收 PageCache 了
innodb_numa_interleave
从5.7开始,mysql增加了对NUMA的无感知:innodb_numa_interleave,也就是在开了NUMA的机器上,使用内错交错来分配内存,相当于使用上关掉 NUMA
For the
innodb_numa_interleaveoption to be available, MySQL must be compiled on a NUMA-enabled Linux system.
当开启了 innodb_numa_interleave 的话在为innodb buffer pool分配内存的时候将 NUMA memory policy 设置为 MPOL_INTERLEAVE 分配完后再设置回 MPOL_DEFAULT(OS默认内存分配行为,也就是zone_reclaim_mode指定的行为)。
innodb_numa_interleave参数是为innodb更精细化地分配innodb buffer pool 而增加的。很典型地innodb_numa_interleave为on只是更好地规避了前面所说的zone_reclaim_mode的kernel bug,修复后这个参数没有意义了。
AUTOMATIC NUMA BALANCING
RedHat 7默认会自动让内存或者进程就近迁移,让内存和CPU距离更近以达到最好的效果
Automatic NUMA balancing improves the performance of applications running on NUMA hardware systems. It is enabled by default on Red Hat Enterprise Linux 7 systems.
An application will generally perform best when the threads of its processes are accessing memory on the same NUMA node as the threads are scheduled. Automatic NUMA balancing moves tasks (which can be threads or processes) closer to the memory they are accessing. It also moves application data to memory closer to the tasks that reference it. This is all done automatically by the kernel when automatic NUMA balancing is active.
对应参数
1 | cat /proc/sys/kernel/numa_balancing shows 1 |
监控
查找相应的内存和调度器事件
1 | perf stat -e sched:sched_stick_numa,sched:sched_move_numa,sched:sched_swap_numa,migrate:mm_migrate_pages,minor-faults -p 7191 |
总结
- 放弃对NUMA的偏见吧,优先回收 PageCache 这个Bug早已修复了
- 按NUMA绑定core收益巨大,即使只有两个NUMA的intel芯片,也有一倍以上的性能提升,在飞腾等其他芯片上收益更大
- 没必要自欺欺人关掉NUMA了
- RDS这样独占物理机的服务可以做到按NUMA来绑定core,收益可观
- ECS售卖如果能够精确地按NUMA绑核的话性能,超卖比能高很多
- 在刷tpcc数据的时候更应该开NUMA和正确绑核
我个人一直对集团所有机器默认关闭NUMA耿耿于怀,因为定制的物理机(BIOS也是定制的)BIOS默认就是关闭NUMA的,装机还得一台台手工打开(跪了,几十万台啊),算是理清了来龙去脉。因为一个kernel的bug让大家对NUMA一直有偏见,即使14年已经修复了,大家还是以讹传讹,没必要。
关于cpu为什么高但是没有产出的原因是因为CPU流水线长期stall,导致很低的IPC,所以性能自然上不去,可以看这篇文章
其他同学测试的结论:
- Hadoop离线作业在 Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz 24 cores/socket * 2, Turbo Off 下打开NUMA后性能提升8%
一些其它不好解释的现象:
- 增加少量跨NUMA 的core进来时能增加QPS的,但是随着跨NUMA core越来越多(总core也越来越多)QPS反而会达到一个峰值后下降—效率低的core多了,抢走任务,执行得慢
- 压12-19和8-15同样8core,不跨NUMA的8-15性能只好5%左右(87873 VS 92801) — 难以解释
- 由1、2所知在测试少量core的时候跨NUMA性能下降体现不出来
- 在压0-31core的时候,如果运行 perf这个时候QPS反而会增加(13万上升到15万)— 抢走了一些CPU资源,让某个地方竞争反而减小了
- 综上在我个人理解是core越多的时候UPI压力到了瓶颈,才会出现加core性能反而下降
系列文章
[CPU 性能和Cache Line](/2021/05/16/CPU Cache Line 和性能/)
[Perf IPC以及CPU性能](/2021/05/16/Perf IPC以及CPU利用率/)
[Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的](/2019/12/16/Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的/)
参考资料
https://informixdba.wordpress.com/2015/10/16/zone-reclaim-mode/
https://queue.acm.org/detail.cfm?id=2513149
NUMA DEEP DIVE PART 1: FROM UMA TO NUMA 这是一个系列,都很干货,值得推荐
https://15721.courses.cs.cmu.edu/spring2016/papers/p743-leis.pdf Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age 论文给出了很多numa-aware下的bandwidth、latency数据,以及对THC-H的影响