为什么这么多CLOSE_WAIT
为什么这么多CLOSE_WAIT
案例1:服务响应慢,经常连不上
应用发布新版本上线后,业务同学发现业务端口上的TCP连接处于CLOSE_WAIT状态的数量有积压,多的时候能堆积到几万个,有时候应用无法响应了
这个案例目标:怎么样才能获取举三反一的秘籍, 普通人为什么要案例来深化对理论知识的理解。
检查机器状态
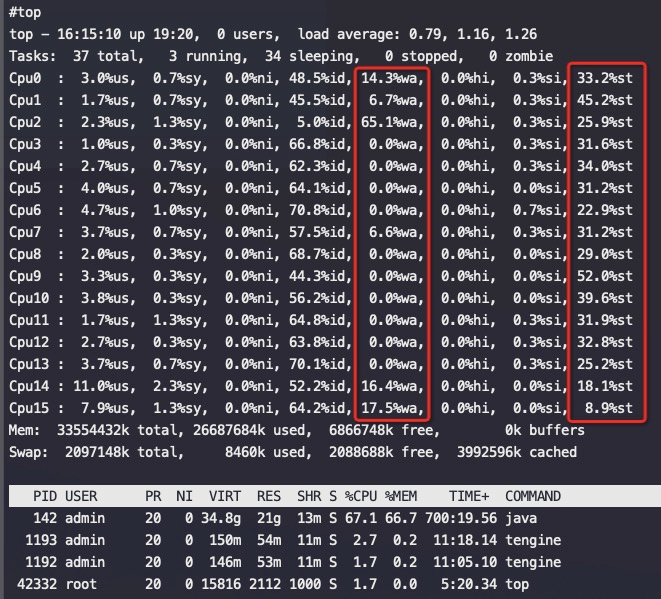
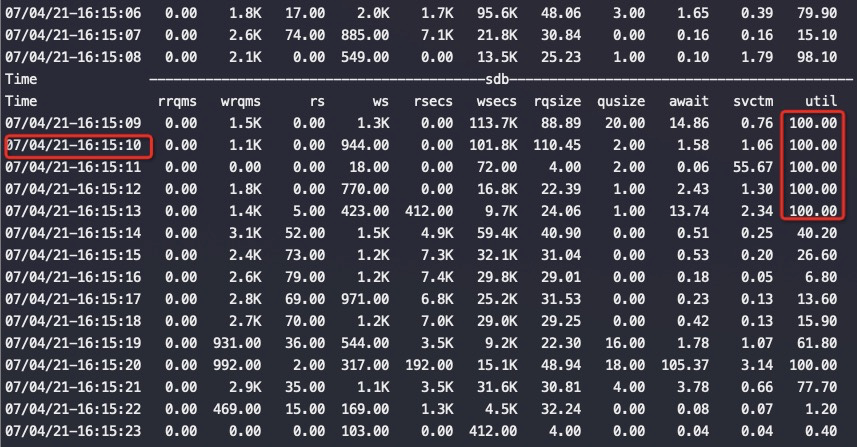
从上述两个图中可以看到磁盘 sdb压力非常大,util经常会到 100%,这个时候对应地从top中也可以看到cpu wait%很高(这个ECS cpu本来竞争很激烈),st%一直非常高,所以整体留给应用的CPU不多,碰上磁盘缓慢的话,这时如果业务写日志是同步刷盘那么就会导致程序卡顿严重。
实际看到FGC的时间也是正常状态下的10倍了。
再看看实际上应用同步写日志到磁盘比较猛,平均20-30M,高的时候能到200M每秒。如果输出的时候磁盘卡住了那么就整个卡死了
1 | dstat |
磁盘util 100%和CLOSE_WAIT 强相关,也和理论比较符合,CLOSE_WAIT 就是连接被动关闭端的应用没调 socket.close
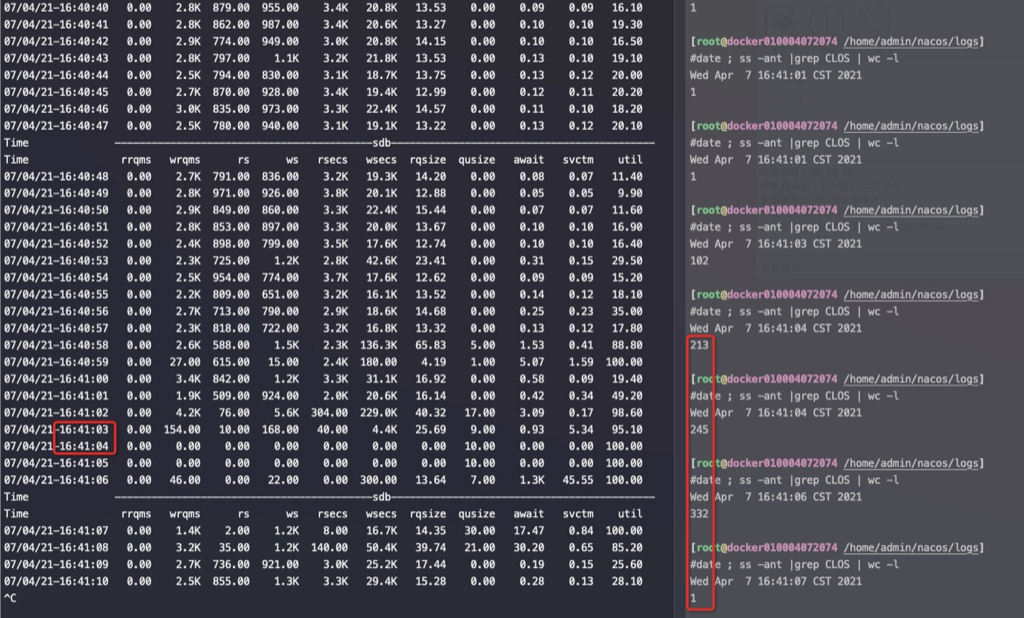
原因推断:
1)新发布的代码需要消耗更多的CPU,代码增加了新的逻辑 //这只是一个微小的诱因
2)机器本身资源(CPU /IO)很紧张 这两个条件下导致应用响应缓慢。 目前看到的稳定重现条件就是重启一个业务节点,重启会触发业务节点之间重新同步数据,以及重新推送很多数据到客户端的新连接上,这两件事情都会让应用CPU占用飙升响应缓慢,响应慢了之后会导致更多的心跳失效进一步加剧数据同步,然后就雪崩恶化了。最后表现就是看到系统卡死了,也就是 tcp buffer 中的数据也不读走、连接也不 close,连接大量堆积在 close_wait状态
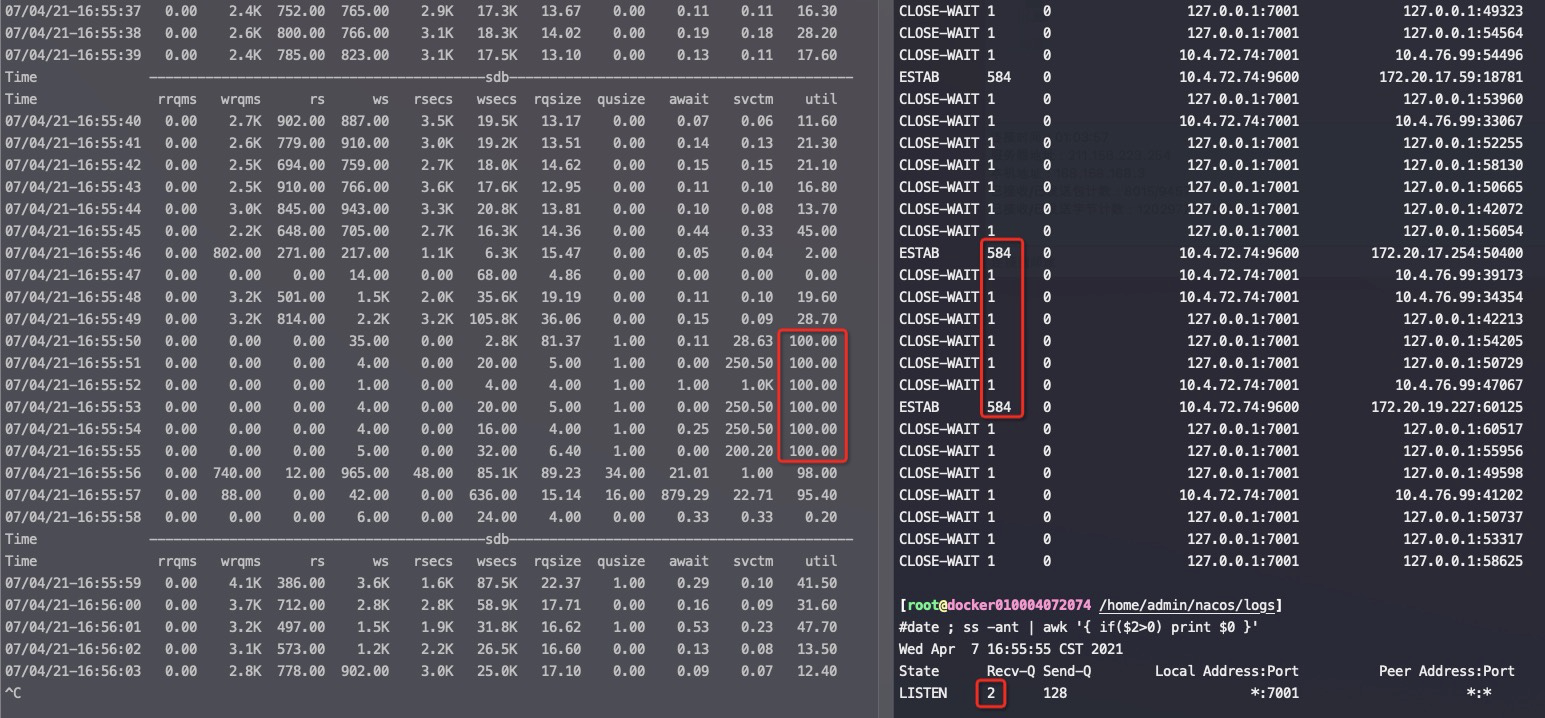
CLOSE_WAIT的原因分析
先看TCP连接状态图
这是网络、书本上凡是描述TCP状态一定会出现的状态图,理论上看这个图能解决任何TCP状态问题。
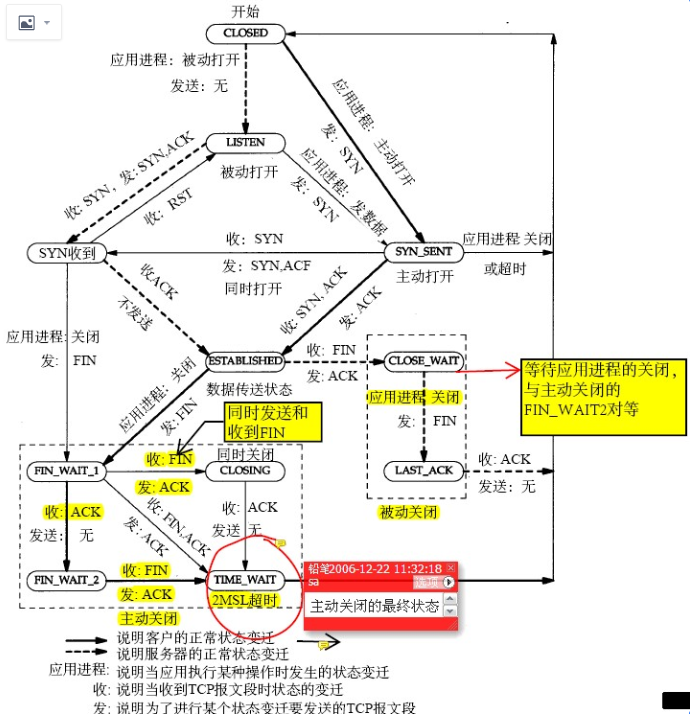
反复看这个图的右下部分的CLOSE_WAIT ,从这个图里可以得到如下结论:
CLOSE_WAIT 是被动关闭端在等待应用进程的关闭
基本上这一结论要能帮助解决所有CLOSE_WAIT相关的问题,如果不能说明对这个知识点理解的不够。
案例1结论
机器超卖严重、IO卡顿,导致应用线程卡顿,来不及调用 socket.close()
案例2:server端大量close_wait
用实际案例来检查自己对CLOSE_WAIT 理论(CLOSE_WAIT是被动关闭端在等待应用进程的关闭)的掌握 – 能不能用这个结论来解决实际问题。同时也可以看看自己从知识到问题的推理能力(跟前面的知识效率呼应一下)。
问题描述:
服务端出现大量CLOSE_WAIT ,并且个数正好 等于 somaxconn(调整somaxconn大小后 CLOSE_WAIT 也会跟着变成一样的值)
根据这个描述先不要往下看,自己推理分析下可能的原因。
我的推理如下:
从这里看起来,client跟server成功建立了 somaxconn个连接(somaxconn小于backlog,所以accept queue只有这么大),但是应用没有accept这些连接(连接建立三次握手不需要应用参与),导致这些连接一直在accept queue中。但是这些连接的状态已经是ESTABLISHED了,也就是client可以发送数据了,数据发送到server 后OS ack了,并放在os的tcp buffer中,应用一直没有accept也就没法读取数据。client 于是发送fin(可能是超时、也可能是简单发送数据任务完成了得结束连接),这时 Server上这个连接变成了CLOSE_WAIT .
也就是从开始到结束这些连接都在 accept queue中,没有被应用 accept,很快他们又因为client 发送 fin 包变成了CLOSE_WAIT ,所以始终看到的是服务端出现大量 CLOSE_WAIT 并且个数正好等于somaxconn(调整somaxconn后 CLOSE_WAIT 也会跟着变成一样的值)。
如下图所示,在连接进入accept queue后状态就是ESTABLISED了,也就是可以正常收发数据和fin了。client是感知不到 server是否accept()了,只是发了数据后server的 OS 代为保存在OS的TCP buffer中,因为应用没来取自然在CLOSE_WAIT 后应用也没有close(),所以一直维持CLOSE_WAIT 。
得检查server 应用为什么没有accept。
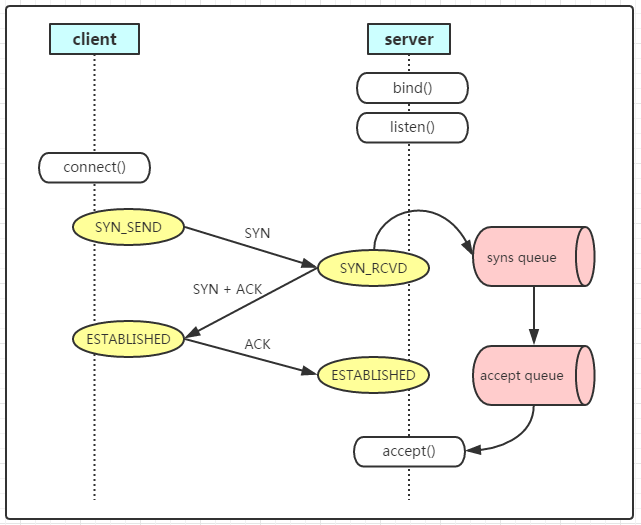
如上是老司机的思路靠经验缺省了一些理论推理,缺省还是对理论理解不够, 这个分析抓住了 大量CLOSE_WAIT 个数正好 等于somaxconn(调整somaxconn后 CLOSE_WAIT 也会跟着变成一样的值)但是没有抓住 CLOSE_WAIT 背后的核心原因
更简单的推理
如果没有任何实战经验,只看上面的状态图的学霸应该是这样推理的:
看到server上有大量的CLOSE_WAIT说明 client主动断开了连接,server的OS收到client 发的fin,并回复了ack,这个过程不需要应用感知,进而连接从ESTABLISHED进入CLOSE_WAIT,此时在等待server上的应用调用close连关闭连接(处理完所有收发数据后才会调close()) —- 结论:server上的应用一直卡着没有调close().
CLOSE_WAIT 状态拆解
通常,CLOSE_WAIT 状态在服务器停留时间很短,如果你发现大量的 CLOSE_WAIT 状态,那么就意味着被动关闭的一方没有及时发出 FIN 包,一般有如下几种可能:
- 程序问题:如果代码层面忘记了 close 相应的 socket 连接,那么自然不会发出 FIN 包,从而导致 CLOSE_WAIT 累积;或者代码不严谨,出现死循环之类的问题,导致即便后面写了 close 也永远执行不到。
- 响应太慢或者超时设置过小:如果连接双方不和谐,一方不耐烦直接 timeout,另一方却还在忙于耗时逻辑,就会导致 close 被延后。响应太慢是首要问题,不过换个角度看,也可能是 timeout 设置过小。
- BACKLOG 太大:此处的 backlog 不是 syn backlog,而是 accept 的 backlog,如果 backlog 太大的话,设想突然遭遇大访问量的话,即便响应速度不慢,也可能出现来不及消费的情况,导致多余的请求还在队列里就被对方关闭了。
如果你通过「netstat -ant」或者「ss -ant」命令发现了很多 CLOSE_WAIT 连接,请注意结果中的「Recv-Q」和「Local Address」字段,通常「Recv-Q」会不为空,它表示应用还没来得及接收数据,而「Local Address」表示哪个地址和端口有问题,我们可以通过「lsof -i:
如果是我们自己写的一些程序,比如用 HttpClient 自定义的蜘蛛,那么八九不离十是程序问题,如果是一些使用广泛的程序,比如 Tomcat 之类的,那么更可能是响应速度太慢或者 timeout 设置太小或者 BACKLOG 设置过大导致的故障。
看完这段 CLOSE_WAIT 更具体深入点的分析后再来分析上面的案例看看,能否推导得到正确的结论。
一些疑问
连接都没有被accept(), client端就能发送数据了?
答:是的。只要这个连接在OS看来是ESTABLISHED的了就可以,因为握手、接收数据都是由内核完成的,内核收到数据后会先将数据放在内核的tcp buffer中,然后os回复ack。另外三次握手之后client端是没法知道server端是否accept()了。
CLOSE_WAIT与accept queue有关系吗?
答:没有关系。只是本案例中因为open files不够了,影响了应用accept(), 导致accept queue满了,同时因为即使应用不accept(三次握手后,server端是否accept client端无法感知),client也能发送数据和发 fin断连接,这些响应都是os来负责,跟上层应用没关系,连接从握手到ESTABLISHED再到CLOSE_WAIT都不需要fd,也不需要应用参与。CLOSE_WAIT只跟应用不调 close() 有关系。
CLOSE_WAIT与accept queue为什么刚好一致并且联动了?
答:这里他们的数量刚好一致是因为所有新建连接都没有accept,堵在queue中。同时client发现问题后把所有连接都fin了,也就是所有queue中的连接从来没有被accept过,但是他们都是ESTABLISHED,过一阵子之后client端发了fin所以所有accept queue中的连接又变成了 CLOSE_WAIT, 所以二者刚好一致并且联动了
CLOSE_WAIT与TIME_WAIT
- 简单说就是CLOSE_WAIT出现在被动断开连接端,一般过多就不太正常;
- TIME_WAIT出现在主动断开连接端,是正常现象,多出现在短连接场景下
openfiles 和 accept()的关系是?
答:accept()的时候才会创建文件句柄,消耗openfiles
一个连接如果在accept queue中了,但是还没有被应用 accept,那么这个时候在server上看这个连接的状态他是ESTABLISHED的吗?
答:是
如果server的os参数 open files到了上限(就是os没法打开新的文件句柄了)会导致这个accept queue中的连接一直没法被accept对吗?
答:对
如果通过gdb attach 应用进程,故意让进程 accept,这个时候client还能连上应用吗?
答: 能,这个时候在client和server两边看到的连接状态都是 ESTABLISHED,只是Server上的全连接队列占用加1。连接握手并切换到ESTABLISHED状态都是由OS来负责的,应用不参与,ESTABLISHED后应用才能accept,进而收发数据。也就是能放入到全连接队列里面的连接肯定都是 ESTABLISHED 状态的了
接着上面的问题,如果新连接继续连接进而全连接队列满了呢?
答:那就连不上了,server端的OS因为全连接队列满了直接扔掉第一个syn握手包,这个时候连接在client端是SYN_SENT,Server端没有这个连接,这是因为syn到server端就直接被OS drop 了。
1 | //如下图,本机测试,只有一个client端发起的syn_send, 3306的server端没有任何连接 |
能进入到accept queue中的连接都是 ESTABLISHED,不管用户态有没有accept,用户态accept后队列大小减1
如果一个连接握手成功进入到accept queue但是应用accept前被对方RESET了呢?
答: 如果此时收到对方的RESET了,那么OS会释放这个连接。但是内核认为所有 listen 到的连接, 必须要 accept 走, 因为用户有权利知道有过这么一个连接存在过。所以OS不会到全连接队列拿掉这个连接,全连接队列数量也不会减1,直到应用accept这个连接,然后read/write才发现这个连接断开了,报communication failure异常
什么时候连接状态变成 ESTABLISHED
三次握手成功就变成 ESTABLISHED 了,不需要用户态来accept,如果握手第三步的时候OS发现全连接队列满了,这时OS会扔掉这个第三次握手ack,并重传握手第二步的syn+ack, 在OS端这个连接还是 SYN_RECV 状态的,但是client端是 ESTABLISHED状态的了。
这是在4000(tearbase)端口上全连接队列没满,但是应用不再accept了,nc用12346端口去连4000(tearbase)端口的结果
1 | # netstat -at |grep ":12346 " |
这是在4000(tearbase)端口上全连接队列满掉后,nc用12346端口去连4000(tearbase)端口的结果
1 | # netstat -at |grep ":12346 " |