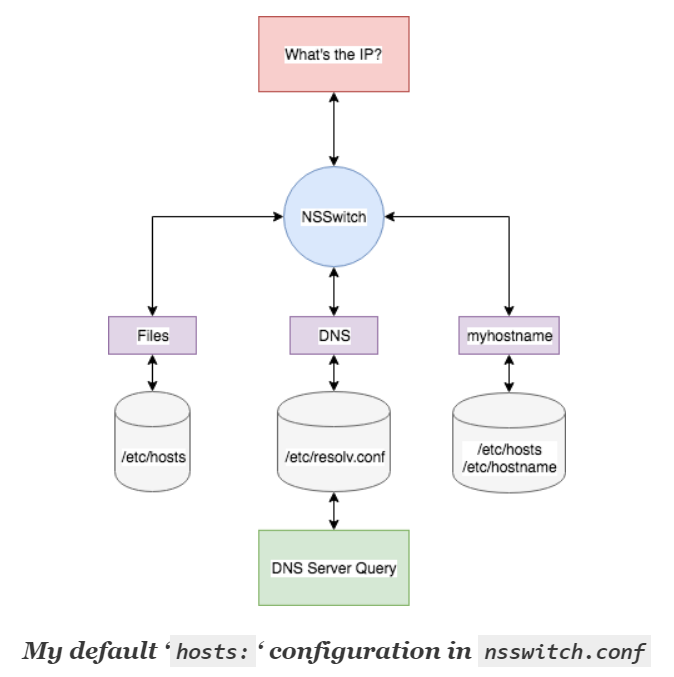
微博备份
微博备份
原因:2022 10月的时候微博被封杀了,之前的重点内容做下备份,评论、转发就没有了
马克思是搞阶级斗争的;列宁是搞革命的;对的,他们就是没有能力治国、搞经济。你见过哪个唯马、列独尊的制度下搞好了的?改革前我们也没搞好,后来有了邓放弃阶级斗争,提出白猫黑猫、科学是第一生产力,放弃马和列的那套阶级斗争,才迎来40年的发展。到了江这里他自评做了三件大事,其中两件是:将邓小平理论写入党章(不要搞斗争,好好搞经济大家都有饭吃),另外就是三个代表,团结一切力量和阶层,尤其是科学(臭老九),真正地让党从斗争转入了治国的轨道上,从此也就不应该有那么多敌对势力了
nginx sys CPU消耗到95%这个是非常不正常的,似乎测试的是短连接,那么惊群问题很严重。打开reuseport看看(listen 80 reuseport;)我测试8163CPU单core压index页面能到7万 QPS,期待定制系统比nginx性能好。反过来想你的Gateway用了70% US CPU在和nginx 5%的US比(bypass的话忽略这句)
经常被问到Apple M1的购买建议,以及M1和Intel 12代谁强,于是我跑到Apple官网查了下,发现性价比超高的一款M1,如图1
M1 Pro都是10+16核的(图二),突然出来一个8+14核不太正常,就两个核的差异再搞条生长线一起生产良品率都不高,并且10核中有很多次品,比如坏掉了1C还剩下9C你扔掉还是?于是聪明的工程师设计的时候就做好了软开关,台积电下线后检测出略微坏的就尽量当8c卖,提升总的良品率降低成本,所以你看看这款的差价其实买到就是赚到.
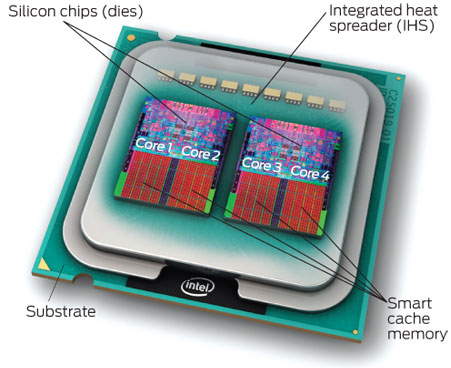
说回芯片成本,Die(裸片,一般大拇指指甲大,你买到的都是封装后的火柴盒大)越大良品率越低成本越高如图三(发热控制另说),Intel也一直这么干,如图四,拿出大拇指感受下Die的大小,注意里面L3的大小,现在的CPU cache大小超过了Die一半的面积了,下次说这个。
Intel 无论哪代的I5、I7、I9基本都是一条生产线在玩关核的把戏,Die的面积都是 215.25 mm²,详细参数参考这里https://en.wikichip.org/wiki/intel/core_i5/i5-12600k ,如图5,把I9放到显微镜下看到如图6
购买建议如图8
N年前我刚加入一家公司几个月,有一个客户购买了我们的产品上线后金额对不上(1类生产事故),于是经理带着我们几个技术去现场看看是什么原因,路上经理说你们不要有什么心理压力,我不懂技术但是我过去就是帮助你们挨骂的,我好好跪在客户那你们好好安心解决问题。
问题大概就是客户代码在一段事务中,但是提交到后端我们的服务上后前对不上了,客户认为我们产品事务有问题。
到了现场客户不让下载他们代码,只能人肉趴在他们指定的机器上用眼睛看问题在哪里,看了三天大家非常沮丧地回来了,自然产品被下线,客户直接用MySQL了,但是三天后一个振奋人心的消息传过来了:金额还是对不上 ……
于是我们再度派出技术人员帮他们看为什么(这次客户配合度高了很多),最后有个同事提了一嘴tcpdump抓个包看看,到底应用代码有没有set autocommit=0, 半个小时后传来喜讯用户代码发出的就是autocommit=1,说明用户代码的事务配置没生效。
最后查出来配置文件中有中文注释,而生产环境机器不支持中文出现了乱码,导致事务没有生效!
事情还没完,当我听到这个结果后恨不得实际抽自己,tcpdump咱也会用,怎么当时就没想到呢!于是后来我天天看tcpdump、分析网络包,有段时间最开心的是在酒店看书了。一个月后写了几篇文章放在公司内网,再然后公司内部各个团队开始拿着各种问题找过来,我的case也越来越多,结果呢我内心自我认为阿满老师去了西半球后是不是东半球抓包我最牛了 :)
有一次产品调用是这样的 1->2->3->4->5->6 产品5是我们的,1说性能上不去,rt太大,扯了两天皮,然后说5有问题,于是我到5上抓了个包,明确告诉他们5的rt是多少,压力还没有到5这里来,另外按照我抓包结果的rt分析,5的能力是20万,现在还不到1万,瓶颈在1-5之间,后来我上1/2/3/4用 netstat 分别看下网络状态发现1-2之间网络到了瓶颈(2回包给1的时候大量的包no ack),不要怀疑netstat真有这么强大,只是你不会看而已。如图三 2上的9108服务端口给1发回结果的时候1那边迟迟不给ack。其实这个case用好工具只是很小的一点,关键的是我能抓包分析出rt,然后从rt推断出系统的能力(别说全链路监控之类的,有时候还得拼刺刀),进而快速定位到瓶颈
现在我们的产品文档必备一份tcpdump、tshark(wireshark命令行版本)救急命令箱,有时候让客户复制粘贴执行后给我们某个结果,好多问题不再是问题了,如图1/2
网络这个卡点是在一个复杂、长链路的系统中非常关键的点,大家都认网络数据(抓包数据),可信度比日志高多了,除了鹰眼之类的全链路监控外,可以在Kernel的网络模块中插入代码记下网络收包、回包的时间点(大概20-30行代码),然后监控系统分析内核吐出来的日志形成监控数据。这样一个不侵入应用、0代码实现的完美监控就有了,其实不算完美,因为这种做法只能监控到同步请求一来一回的RT。当然对我们来说就够了,上线后好多次都是通过这个系统进行完美甩锅(快速发现问题)
一次听风扇声音来定位性能瓶颈
问题描述背景
在一次POC测试过程中,测试机构提供了两台Intel压力机来压我们的集群
- 压力机1:两路共72core intel 5XXX系列 CPU,主频2.2GHz, 128G内存
- 压力机2:四路共196core intel 8XXX系列 CPU,主频2.5GHz, 256G内存 (8系列比5系列 CPU的性能要好、要贵)
从CPU硬件指标来看压力机2都是碾压压力机1,但是实际测试是压力机2只能跑到接近压力机1的能力,两台机器CPU基本都跑满,并且都是压测进程消耗了90%以上的CPU,内核态消耗不到5%CPU
所以问题就是为什么196core没打过72core,关键是CPU都还用完了
机器在客户环境缺网络、缺各种工具(连perf都没有),于是只能趴在机箱上听风扇声音,两台机器都听了1分钟,我觉察到了问题,196core机器的CPU风扇声音更小,说明196core的CPU出工不出力,大概是流水线在频繁地Stall。
知识点:通过top看到CPU在运行,但是在芯片内可不一定是真正在running。比如执行一条指令,需要读取数据,如果数据没在cache中那么需要到内存中取进来,这个时候CPU就会休息(放电、降温),这个就叫Stall
于是做了个读写内存的带宽和时延测试,得到如下数据:
72core机器, 本路时延1.1,跨路时延1.4,因为是2路所以有50%的概率跨路,性能下降30%,查到内存条速度2900
196core机器,本路时延1.2,跨路时延1.85,因为是4路所以有75%的概率跨路,性能下降50%,查到内存条速度2100
赶快给196core机器换上2900的内存条速度一下子就上去了,同时这多路服务器不能这么用,要在每一路上起一个实例,不要让内存跨路访问,速度又是几十个个点的提升
面试官为什么喜欢问算法题(算法岗除外):本质就是对招人方成本最低!
面试官和候选人很难在大部分技术点上match,也就是候选人擅长的面试官问不出深浅;面试官擅长的候选人不一定懂问了也白问。这个时候上来几道力扣算法题最轻松了,只要认识字的面试官都能看出来候选人会不会,当然面试官也没法追问候选人是刷题了还是真现场想出来的(真正现场想出来的应该不会超过5%吧),一般不敢追问怕被反杀:( 因为面试官也是背的答案
这个成本低的本质则是面试官水平不行、或者面试官想偷懒。
什么样的面试官想偷懒?一上来让你自我介绍,然后闷头看简历的,基本都是没做任何准备趁着你自我介绍的时间赶紧看两眼你的简历。好的面试官会提前看简历,针对性地准备好几个问题,然后上来只需要寒暄几句暖场一下从简历上擅长的技术或者项目开始问(最好从简单的,让候选人先把气场打开)。
为什么好的面试官不多呢?成本太高,准备好问题、读完你的博客结果电话一通候选人不感兴趣 :) 慢慢地大家都开始往节省成本的方向靠近
好的面试行为:
- 提前看几遍简历,针对性地准备好问题
- 简历有博客的,去博客中看看
- 上来寒暄下,从候选人最熟悉的地方开始发问
- 针对一些技术点问到候选人答不出来,这样能看出候选人的深浅
- 场景式面试法,什么场景下、问题是什么、做了什么(如何做)、得到了什么结果
- 候选人表示不太熟悉的就不要追问了
江湖大佬无招胜有招的故事(如何在不懂领域解决问题起来胜过该领域的工程师)
这位同学从chinaren出道,跟着王兴一块创业5Q,5Q在学校靠鸡腿打下大片市场和校内网竞争,最后被陈一舟的校内收购(据说被收购后5Q的好多技术都走了,最后王兴硬是呆在校内网把合约上的所有钱都拿到了–收购合约的钱都是分期付款)。
在我们公司负责技术(所有解决不了的问题都找他),这位同学让我最佩服的解决问题的能力,好多问题其实他也不一定就擅长,但是他就是有本事通过man、Help、Google不停地验证尝试、分析就把一个不熟悉的问题给解决了,这是我最羡慕的能力。
案例:应用刚启动连接到MySQL数据库的时候比较慢,但又不是慢查询,对这个问题有如下几种解决方案:
- 这位同学的解决办法是通过tcpdump来分析网络通讯包,看具体卡在哪个步骤,把这个问题硬生生地给找到了。
- 如果是专业的DBA可能会通过show processlist 看具体连接在做什么,比如看到这些连接状态是 authentication 状态,然后再通过Google或者对这个状态的理解知道创建连接的时候MySQL需要反查IP、域名这里比较耗时,通过配置参数 skip-name-resolve 跳过去就好了。
- 如果是MySQL的老司机,一上来就知道 skip-name-resolve 这个参数要改改默认值。
在我眼里这三种方式都解决了问题,最后一种最快但是纯靠积累和经验,换个问题也许就不灵了;第一种方式是最牛逼和通用的,只需要最少的业务知识+方法论就可以更普遍地解决各种问题。
每次碰到问题我尽量让他在我的电脑上来操作,解决后我再自己复盘,通过history调出他的所有操作记录,看他在我的电脑上用Google搜了哪些关键字,然后一个个去学习分析他每个动作,去想他为什么搜这个关键字,复盘完还有不懂的再到他面前跟他面对面的讨论他为什么要这么做,指导他这么做的知识和逻辑又是什么(这个动作没有任何难度吧,你照着做就是了,实际我发现绝对不会有10%的同学会去分析history的,而我则是通过history 搞到了各种黑科技 :) )。
感觉这个实现还是不对,padding只对齐了尾巴不让合别人共享一个cache line,但是没法避免前面和别人对齐跨cache line。即使后面对齐也不对,用一个rp而不是8个就能对齐到64,刚好一个cache_line,正确做法得和Disruptor一样前后夹击对齐 https://plantegg.github.io/2021/05/16/CPU_Cache_Line和性能/
一语惊醒梦中人的感觉最爽,我是做了10年性能优化后碰到了一次醍醐灌顶般的醒悟
这之后,无数次只需要看一眼服务的RT、CPU状态就能很快给出服务的极限QPS是多少。
这个原理最简单的总结就是:QPS和延时的乘积是常量(复杂版总结如图1);其次如图2
当别人给我压测结果数据(并发、QPS、RT)的时候大多我一眼就能看出来数据错了,比如打压力5分钟,然后给了一个5分钟的平均QPS,我一推算QPS不对,再让业务仔细一查原来是5分钟前面有3分钟热身,真正完整压力2分钟,但是QPS给了5分钟的!
如果QPS和延时同时下降那么一定是并发过来的压力不够了。
我见到99%的性能压测就像洞房的处男一顿乱鼓捣,只会不停地加并发,从来没有停下来计算一个并发的QPS是多少、对应的RT是多少、US CPU是多少,最佳并发压力是多少。
而我的做法是:1)用很少的线程压,收集RT、QPS、CPU数据;2)计算得到总QPS、最佳并发线程;3)用计算所得的并发数打压力
理解了下面两张图顶极客时间上所有性能优化的课程(我就在那些课程上找过一些错误数据),胜过你看一堆的性能优化书籍 :)
这也是以一挡一百的知识点,搞懂就打通一个领域
来说一次教科书式徒手全链路性能分析过程
强调徒手是缺少工具、监控的时候不能抱怨、不能甩锅,经理不听
强调全链路是不纠缠某段代码、业务逻辑的问题,而是需要找到问题瓶颈在哪个环节上
场景描述
某客户通过PTS(一个打压力工具)来压选号业务(HTTP服务在9108端口上),一个HTTP请求对应一次select seq-id 和 一次insert
PTS端看到RT900ms+,QPS大概5万(期望20万), 数据库代理服务 rt 5ms,QPS 10万+
调用链路:
pts发起压力 -> 5个eip -> slb -> app(300个容器运行tomcat监听9108端口上) -> slb -> 数据库代理服务集群 -> RDS集群
问题
性能不达标,怀疑数据库代理服务或者RDS性能不行,作为数据库需要自证清白,所以从RDS和数据库代理服务开始分析问题在哪里。
app业务方也尝试过增加app容器对性能没啥提升,所以怀疑问题在数据库上
分析过程
这里缺各个环节的RT监控,所以定位不了哪个环节瓶颈了
先到app服务上抓到数据库代理服务上的包,快速确认下从app到后端有没有瓶颈,如图1
重点在如何分析图1的数据,我从图1可以得到 数据库代理服务 RT是 15ms,也就是单连接的TPS是1000/15=70, 实际一条连接一秒钟才给后面发20个请求。
所以结论是后端能扛40万 QPS,压力没有从app服务打给后端
继续在app上抓包,这次抓服务端口9108的响应时间(如图2),分析如图1,结论是压力根本就没有打到9108上
临门一脚得结论
如图三,netstat 一看就知道问题在app服务前面,总结在图4
这次只是在各种监控缺乏的场景下,如何借助各种工具来有理有据地甩锅,其实核心理论在图1的分析过程,也是能力的体现,这后面是对并发、RT、QPS的理解
性能问题最好别找我,找我我能把你们卷飞了
我们的服务一般都在链路的最末端,也是最容易被责问性能不行的(正常)
所以无数次项目需要证明你行
我一般都能徒手透过5/6个中间环节一直打到发压力端。
有一次压力机用了12台,总QPS 总是无法逾越10000(上下波动),链路上各种加机器扩容,但是都无法突破10000 QPS
链路上所有环节的工程师都说自己的服务没有问题
于是我从最后端撸到发压力机器,发现每台压力机器的port range是10000-60000,也就是5万可用端口,12台总共60万可用端口,测试用的短连接,一个端口默认是60秒timewait,那么TPS就是 60万除以60秒,正好10000 QPS。
完美的1000 QPS,你说问题简单不,就是很简单,改成长连接就好了
比如这个case:https://weibo.com/1667773473/Lrl2vzX0Z
性能优化是最能体现全栈能力的
曾经有一次紧急被派过去优化一个项目,3天将性能提升了10倍
1 | - docker bridge网络性能问题和网络中断si不均衡 (优化后:500->1000TPS) |
前面从500到3000是比较容易的,优化起来效果很明显,主要是把CPU从SI、SY赶到US的过程,当然各种工具配合使用要熟练,过程如图1、图2(动图)、图3
当然最有意思的是优化后放到生产环境压测就又不行了,这个时候经理投来不信任的眼神,你丫忽悠我啊
吹了一天牛逼说是从500翻了6倍,然后生产环境一验证,白瞎!
线上最大的差别就是会调用第三方服务,但是第三方服务监控显示rt很小、也没啥压力(又到了扯皮时间)
于是我设计如下三个场景证明问题在中间链路上:
- 压测的时候在业务机器 ping 依赖第三方服务的机器;
- 将一台业务机器从负载均衡上拿下来(没有压力),ping 依赖第三方服务的机器;
- 从公网上非我们机房的机器 ping 依赖第三方服务的机器;
这个时候奇怪的事情发现了,压力一上来场景1、2的两台机器ping 依赖第三方服务的机器的rt都从30ms上升到100-150ms,场景1 的rt上升可以理解,但是场景2的rt上升不应该,同时场景3中ping依赖第三方服务的机器在压力测试的情况下rt一直很稳定(说明压力下依赖第三方服务的机器没有问题),到此确认问题在我们到依赖第三方服务机房的链路上有瓶颈,而且问题在我们机房出口扛不住这么大的压力。于是从上海Passport的团队找到北京Passport的PE团队,确认在我们调用依赖第三方服务的出口上使用了snat,PE到snat机器上看到snat只能使用单核,而且对应的单核早就100%的CPU了,因为之前一直没有这么大的压力所以这个问题一直存在只是没有被发现。
于是PE去掉snat,再压的话 TPS稳定在3000左右
这个优化最戏剧性的就是在上线后因为snat导致性能不行的证明问题,链路很长、团队很多,直接说不是自己的问题是没有意义的,关键是要如何在一个长链路中证明不是自己的问题,并且定位问题在哪里
教科书和实践很容易脱节
比如讲DNS出问题总是喜欢谈到DNS的递归解析,这些是DNS工程是需要关心的,但是对程序员来说更重要的是DNS在我的服务器上是怎么一个解析流程,解析不了再发给DNS服务器,但是在发给DNS服务器之前出问题是需要程序员兜底的。比如域名不能ping通,但是nslookup能通;
这方面就很少有教科书、文章来讲了。
比如讲到LVS总是告诉你那LVS的几种模式,但是没有从技术的原理上讲通LVS是怎么样在不同的模式下工作的,从而得到他们的优缺点,教科书一上来就把优缺点告诉你,没有带你推导他们的背后原因!
再比如讲LVS负载均衡原理一上来就是那10种负载均衡算法,但是现实中我们经常碰到的是:咦,这个负载均衡算法为什么导致了我的服务负载这么不均衡!
也就是教科书部分重点喜欢大而全的总结,实践希望我们揪住重点彻底掌握
教科书不负责跨界,实践需要我们跨界
来说一个知识上降维打击(学习)的案例
大多程序员对LVS的几种转发模式有点晕菜,但时不时又要涉及一下,晕菜是看着似乎懂但是没有真的懂,一用就发懵
实际上如果你要是理解了RFC1180,然后从包的流转,当包在LVS上被LVS修改并继续路由的时候,你要理解LVS对包做了什么修改、为什么要做这个修改、这种修改必须要求的场景(将来部署的缺陷)、作了修改后包怎么到达后端的Real Server,你就彻底理解了这些转发模式,同时优缺点也了如指掌。
这个时候再让你就某个应用特点来设计一个新的LVS代理转发模式就很容易了
RFC1180的威力 https://weibo.com/1667773473/LpXXUpLj2
用RFC 1180的逻辑来理解LVS https://plantegg.github.io/2019/06/20/就是要你懂负载均衡--lvs和转发模式/
大家一起切磋下如何解读性能测试数据
比如这个测试报告显示某个产品性能比Nginx好3倍,并且有详细的测试环境、数据比较:https://xie.infoq.cn/article/a25a30a1f190e7c6a41c4580f
所以问题是你仔细看完整个测试数据报告后,你觉得测试数据有问题吗?我想告诉大家的是这个数据测试不对,然后你要分析哪里不对了
理解超线程是掌握CPU相关知识非常重要的一个抓手、也超级实用
超线程(Hyper-Threading)原理
一个物理核还可以进一步分成几个逻辑核,来执行多个控制流程,这样可以进一步提高并行程度,这一技术就叫超线程,有时叫做 simultaneous multi-threading(SMT)。
超线程技术主要的出发点是,当处理器在运行一个线程,执行指令代码时,很多时候处理器并不会使用到全部的计算能力,部分计算能力就会处于空闲状态。而超线程技术就是通过多线程来进一步“压榨”处理器。pipeline进入stalled状态就可以切到其它超线程上
举个例子,如果一个线程运行过程中,必须要等到一些数据加载到缓存中以后才能继续执行,此时 CPU 就可以切换到另一个线程,去执行其他指令,而不用去处于空闲状态,等待当前线程的数据加载完毕。通常,一个传统的处理器在线程之间切换,可能需要几万个时钟周期。而一个具有 HT 超线程技术的处理器只需要 1 个时钟周期。因此就大大减小了线程之间切换的成本,从而最大限度地让处理器满负荷运转。
ARM芯片基本不做超线程,另外请思考为什么有了应用层的多线程切换还需要CPU层面的超线程?
超线程(Hyper-Threading)物理实现: 在CPU内部增加寄存器等硬件设施,但是ALU、译码器等关键单元还是共享。在一个物理 CPU 核心内部,会有双份的 PC 寄存器、指令寄存器乃至条件码寄存器。超线程的目的,是在一个线程 A 的指令,在流水线里停顿的时候,让另外一个线程去执行指令。因为这个时候,CPU 的译码器和 ALU 就空出来了,那么另外一个线程 B,就可以拿来干自己需要的事情。这个线程 B 可没有对于线程 A 里面指令的关联和依赖。
CPU超线程设计过程中会引入5%的硬件,但是有30%的提升(经验值,场景不一样效果不一样,MySQL/Hadoop业务经验是提升35%),这是引入超线程的理论基础。如果是一个core 4个HT的话提升会是 50%
这两年到处收集各种CPU,然后测试他们的性能
发现不同厂家CPU相同频率性能差异极大(单核)
在数据库场景下测试下来CPU的性能基本基本和内存延时正相关
谁家把延时做得低性能就好
如图1 core:120 490.402 表示120号core访问0号内存延时490,core:0 149.976 表示0号core访问0号内存延时149(差异巨大)
20年前Intel为了搞多核,开始将两个Die封装成一块CPU售卖
如图1,两个Die 上共4个core,然后封装成一块CPU
这被大家瞧不起,说是胶水核,因为1/2和3/4间延时很大
后来Intel再也不搞胶水核了,现在一个Intel的Die能放下几十个core,延时都很低
不过AMD则依靠胶水核要翻身了
如图2,这块CPU上AMD用了8+1个Die才放下去32core,性能延时都很好
便宜到人人说香
其实这两条路线这两家都能搞,但是Intel那个路线就是太贵
而AMD这种搞法恰好很适合云计算(拆开售卖)
不信你去各家云平台看看他们的价格差距
CPU中的cache变迁历史
80486(1989), 8K的L1 cache第一次被集成在CPU中,图1
80686(1995) ,L2被放入到CPU的Package上,但是是一个独立的Die,可以看到L2大小和一个Die差不多,图2
以酷睿为例,现在的CPU集成了L1/L2/L3等各级CACHE,CACHE面积能占到CPU的一半,图3
从上图可以看到L3的大小快到die的一半,L1/L2由每个core独享,L3是所有core共享,3级CACHE总面积跟所有core差不多大了。
最近这些年Cache上基本也没什么大的花样了
折腾cache都是为了解决内存延时问题(内存墙),或者说内存的延时配不上CPU的速度了(越来越大),图4
之前的好几条微博写了很多网络问题、学习方法等
我试着把他们总结起来写了篇《程序员如何学习和构建网络知识体系》
核心是从程序员实用、常碰到问题出发,提炼出相关的核心知识点,然后串联起来
里面每一个知识点都是碰到了具体问题
先是去解决,解决后再分析、总结、提炼。
比如网络为什么不通,还有哪些原因会导致不通,这个原因在不同Linux内核版本下会有什么不一样吗?
以后这种问题有没有快速定位工具、手段
比如网络传输慢的时候,定性定量分析RT的影响、Buffer的影响、BDP如何打满等
这种总结性的文章一般都比较务虚,所以每一个务虚的地方我放了一个案例
总共写了大概10篇相关案例来反过来证明务虚的话语
希望对你有所帮助
链接地址:https://plantegg.github.io/2020/05/24/程序员如何学习和构建网络知识体系/
程序员面试考算法(非算法岗)和考 拧魔方 差别大不大?
视频网站各种魔方手法总结,学一学都会
letcode各种算法总结也是非常完善
这两都能让面试官好好休息一下,有标准答案,对一下就行
不要抱怨招进来的人为啥水、干不了活
还不是letcode总结得好、八股文总结得好
之前的好几条微博写了很多网络问题、学习方法等
我试着把他们总结起来写了篇《程序员如何学习和构建网络知识体系》
核心是从程序员实用、常碰到问题出发,提炼出相关的核心知识点,然后串联起来
里面每一个知识点都是碰到了具体问题
先是去解决,解决后再分析、总结、提炼。
比如网络为什么不通,还有哪些原因会导致不通,这个原因在不同Linux内核版本下会有什么不一样吗?
以后这种问题有没有快速定位工具、手段
比如网络传输慢的时候,定性定量分析RT的影响、Buffer的影响、BDP如何打满等
这种总结性的文章一般都比较务虚,所以每一个务虚的地方我放了一个案例
总共找了大概10篇相关案例来反过来证明务虚的话语
希望对你有所帮助
链接地址:https://plantegg.github.io/2020/05/24/程序员如何学习和构建网络知识体系/
造新词、新概念是个很有意思的事情
大多时候能够化腐朽为神奇,一下子让大家都通透、凝聚、共识
听起来还很高深、高端,这就导致很多人为了高深、高端而造新词
这在很多大厂非常流行,搞好了四两拨千斤
但很多时候也会把简单事情复杂化、搞得神神叨叨,这就是为了造词而造词
比如WEB3是个啥,你看各个百科的解释是有点蒙逼
但是如果告诉你WEB3背后的存储就是区块链,区块链就是一个大DB
更简单点说WEB3就是一张大Excel表格,把大家的信息都放在这张表格里
别的网站都能来读取,这就是WEB3描绘的网站间数据共享
但是WEB3太模糊了,表达不了背后的本质,明显是为了操作往WEB2上套(区块链、比特币已经没人爱上钩了)
长链路性能压测之瞎几把压典范
1->2->3->4—->N
1使劲加并发打压力,但是QPS非常小,1-N每个环节的工程师都说自己没有问题
关键是每个环节的理由是:我的CPU、网络都很闲,没有压力。我基本没见过说自己RT稳定的!
然后长时间扯皮、互相甩锅,在我看来这些甩锅没有一点技术含量,真的是在甩锅,这些人都没入门。
这里本末倒置了,你要证明自己没问题必须说加压后自己的RT没增加,而不是说CPU、网络很闲
这里CPU是过程,RT才是我们要的结果(不要质疑别人的CPU高,先质疑RT高–或者说RT上升快)。
展开下:性能优化目的是提升QPS也就是降低RT,CPU、内存、网络等等都是不关键的要素,最关键的结果就是RT
因为并发一定的情况下QPS和RT是反比关系
记住这句话:长链路性能压测先追着RT跑而不是追着CPU、内存等资源跑
写了这么多增删改查,你会对JDBC驱动了如指掌吗(仅限Java+MySQL技术栈)?
我碰到几个厉害的程序员一个增删改查下去业务代码如何与MySQL互动一清二楚,业务上有了bug、性能有了小问题
大概率半个小时就给你分析得明明白白
但是90%以上的程序员即使天天增删改查,却对JDBC驱动一直是盲人摸象,今天这里看个参数明天那里优化下、明天那里鼓捣下
不成系统,碰到硬扎问题还是只能瞎试、求人
比如什么是JDBC流式驱动,有些程序员被一个大查询把内存怼爆了,才想起来优化,然后网上抄个参数好像问题解决了,但是怎么很多情况下反而慢了,经常timeout了;
比如预编译优化以为加上useServerPrepStmts=true就可以了,测试也性能好了,但他妈的上线后发现性能反而差了
建强的初衷是什么?肯定不是为了保护淘宝、百度、腾讯以及锅内互联网。
建强的事实结果导致了锅内互联网的繁荣吗?这没法证伪和证实。
那么现在事实上锅内互联网这么繁荣了,强能拿掉吗?
你可以随意使用汉字不被限流河蟹吗?这些汉字有依据不能使用吗?
一个体制内、媒体多年工作者(靠采访、写字为生)被全网封杀确实是灭顶之灾,封杀三年后远遁他乡,尝试过妥协解封,没有结果。
终于没有希望回来后,
可以在那些不存在的网站讲讲CCTV的一些潜规则
X86有个有意思的指令:pause, 调用这个指令进程啥也不干,就是休息N个时钟周期,这个时候CPU可以省电、避免切换到其它进程导致上下文切换、也可以调度给超线程。一般抢锁失败会pause一下,比如内核中到处的spin。–这是原理
Intel Broadwell架构(比如 E5 至强5代)及之前的CPU都是pause一次休息10个时钟周期,Skylake架构之后这个pause一次休息时钟周期从10调到了140,整整增加了14倍啊,带来的后果是灾难性的(因为很多软件是不会测试、考虑这么细致的)如图1
比如MySQL使用innodb_spin_wait_delay控制spin lock等待时间(底层会调用这个pause指令),跑在Broadwell CPU上等待时间时间从innodb_spin_wait_delay5010个时钟周期(6微秒)。如果跑在Skylake上spin一次休息innodb_spin_wait_delay50140个时钟周期(84微秒,我相信没有几个DBA会根据CPU型号去调整参数吧–有的话请私聊我,交个朋友),后果就是MySQL在高并发场景下TPS拉胯的厉害,如图2
这是我第一次感受CPU对程序的影响,后来的事前面的微博都写过了 http://t.cn/A6XHRiYl ,每一次被现实鞭打后得知耻而后勇[二哈]
你看程序员啥都没做,但是锅在你头上
图1这张图让我学习到了特别多的东西:
1)为了成本把坏掉了一个核四核芯片关掉2个核(红圈所示),当2核卖(i3/i5/i7/i9 就是这么来的)
2)右下角告诉我这块CPU 芯片是177平方毫米,没概念就拿出你的大拇指看看,大概是这么大,再有人吹牛逼说他们的芯片多牛逼,先看看那块芯片的大小你就知道成本高了多少,基本主流的PC芯片都是 200以内,服务器略大点
3)这块芯片去掉四个核后,还有一半的面积(成本)用在了cache上,也就是现在的芯片cache成本基本和核的成本差不多了,要花掉你一半的钱在上面,他们很珍贵
4)PC芯片GPU占用面积(成本)也不小
图1 也叫Die(裸片),就是台积电加工完成后的东西,得再做封装后变成火柴盒字大小你能买到的CPU实物(如图三)
结合图二,这是一个封装后的AMD CPU,在云计算时代我挺看好这种模式的,AMD把一块CPU一个Die切割成了9个Die 来加工然后用胶水黏在一起卖(真他妈便宜),关键是性能还和Intel差不多,然后拿到云上本来也得切割成小的ECS售卖,所以感觉Intel真浪费!–你去各家云上看看AMD虚拟机卖得就是便宜
Die的大小成本到底差了多少呢? 加工Die最关键的是良品率,Die越大良品率越低(你想想显示器大小和坏点的关系)。如图4,这是个Die大小对良品率影响的计算案例(最外面那个圆盘就是我们所说的晶圆,台积电就是把一块大晶圆加工成多个小的CPU 芯片),一般良品率超过50%就是个不错的成绩了
你要是反复吃透这篇博文的话基本对CPU的理解算是入门了,如果没就要把图一供起来反复看
软设置定制内存大小的故事
有一次我们有一台1T内存,CPU4个NUMA Node的物理机,但是不符合使用要求,内存太大,规定只能用512G内存。机器借过来的不能撕毁标签
第一次尝试,在Linux OS grub启动参数中设置 mem=512G,起来后果然只剩下512G内存了。但是跑下来性能不够好,如图1,相当于拿掉了红框里的内存,右边的core要跑很远才能用上左边的512G内存,自然性能不好了。
第二次尝试,在Linux OS grub启动参数中按numa node设置每个node内存为128G(4个合起来512G,关键字 memmap),这基本是完美方案,性能也和1024G时一样好
不过意外发生在某次的国产CPU上,我们用方案二,另外一个团队直接拆机箱把内存,把我们打垮了
读中学的时候我有个同学对物理很感兴趣,天天拿着一本奥赛的书,晚自习逮到物理老师就问,开始的时候物理老师还挺有耐心的,老师不会的会回去研究下再跟这个同学交流
可实际上吧每次物理考试这个同学也就及格水平(班里处于中游),但是挡不住自己的热情,一学期下来物理老师看到他就躲,晚自习教室门口瞄一眼就赶紧闪,最后这同学也没考上大学,你想想物理是他最拿手的科目了只是中游水平。
他这些竞赛书我也拿过来翻过,题目都看不懂,只好绕着跑。
后来工作后认识个朋友,自学编程,一上来迷上了《计算机程序设计艺术》,三大本都买回来了,天天琢磨算法,CRUD也搞不好、计算机基础知识也不太懂,就这样自学了1年多后跑北京找工作,结果找了半年一个正经工作也没有,后来去了广州就没消息了。也怪我不应该告诉他有这书的,同样这书我也看不懂。
这种人大家身边也许都有,有热情但是就是不能脚踏实地,没有那么高的能力非要摸尖尖。大部分民科都是这种吧
它力压超线程成为冯诺依曼计算机体系下唯一的特优设计、它降低了程序运行性能但是程序员依然如痴如醉地离不开它、它究竟是如何拳打超线程脚踩cache成为计算机体系的最优设计的?它就是虚拟内存
一个月前的微博总是被屏蔽,周末终于知道是哪个词了(放在最后说),突然感觉挺无聊的,不想多写了
-——
高中的学校门口时候亲眼见过一个“民科”
一个老爷子,摆了几张大白布,上面全是各种公式,说是证明了哥德巴赫猜想(记不太清了,大概是那几个世界难题),现在想想我们学校没有数学牛人啊,这种“民科”–这也是后来形容这类人提出的名词,现在主要集中在中科院数学研究所门口了,算是找对地方了。
不过这种“民科”特别单纯、自娱自乐,也没啥不好,跟你玩王者荣耀、魔方、刷letcode差别不大。
https://weibo.com/1667773473/LwlKNtfZp 这条我本意不是要说民科。痴迷奥数和《计算机程序设计艺术》也不是民科,准确来说是不务实,重要的基础和工作相关的技术还没掌握好,在明确目标面前非要走“邪路”。
这样的例子还有很多,比如很多文章讲TCP各种拥塞算法条条是道,可是我们工作中需要用到这些吗?你TCP握手、断开还有点迷糊,就痴迷这些不恰当;
再比如好多书讲cache_line 的tag、组一套一套的,但是cache_line的本质、如何发现False sharing等偏实践的还没搞懂呢。
还有人每天都要化一两小时刷几道letcode, 你也知道用不上、面试官也知道用不上,但是大家就是痴迷拿到题一气呵成没有bug。其实都是背好了而已,真要考就先看思路、然后wei代码能表达出来就可以了。
其实这里讲的是取舍和重点问题。
说这些总的意思是优先尽量从实践出发多学天天能用上的知识,借用 jjhou 老师20年前很有名的一句:勿在浮沙筑高台(出自 程序员 杂志 @蒋涛CSDN )
最后希望大家不用为了工作疲于奔命,闲暇至于为了怡情、喜欢可以多看奥数、TAOCP(高级享受)
-——-
false sharing 的中文是min敢词
高中的学校门口时候亲眼见过一个“民科” 一个老爷子,摆了几张大白布,上面全是各种公式,说是证明了哥德巴赫猜想(记不太清了,大概是那几个世界难题),现在想想我们学校没有数学牛人啊,这种“民科”–这也是后来形容这类人提出的名词,现在主要集中在中科院数学研究所门口了,算是找对地方了,也许是有钱有闲买票容易了。
不过这种“民科”特别单纯、自娱自乐,也没啥不好,跟你玩王者荣耀、魔方、刷letcode差别不大。 http://t.cn/A6XrYUzm 这条我本意不是要说民科。痴迷奥数和《计算机程序设计艺术》也不是民科,准确来说是不务实,重要的基础和工作相关的技术还没掌握好,在明确目标面前非要走“邪路”。 这样的例子还有很多,比如很多文章讲TCP各种拥塞算法条条是道,可是我们工作中需要用到这些吗?你TCP握手、断开还有点迷糊,就痴迷这些不恰当; 再比如好多书讲cache_line 的tag、组一套一套的,但是cache_line的本质、如何发现False sharing等偏实践的还没搞懂呢。 还有人每天都要化一两小时刷几道letcode, 你也知道用不上、面试官也知道用不上,但是大家就是痴迷拿到题一气呵成没有bug。其实都是背好了而已,真要考就先看思路、然后伪代码能表达出来就可以了。 其实这里讲的是取舍和重点问题。 说这些总的意思是优先尽量从实践出发多学天天能用上的知识,借用 jjhou 老师20年前很有名的一句:勿在浮沙筑高台( 出自 程序员 杂志 @蒋涛CSDN ) 最后希望大家不用为了工作疲于奔命,闲暇至于为了怡情、喜欢可以多看奥数、TAOCP(高级享受)
10年前P10大佬无招胜有招的故事
JBoss启动失败,没有太多错误信息,唯一有一行LogFactory.release的warning日志
对这个问题,如果熟悉JBoss启动流程那么很容易排查(套路熟练),如果不熟悉JBoss怎么办呢。大佬虽然对JBoss不熟但是对btrace无比熟练,所以从trace这个warning入手一步步trace出来启动流程堆栈
然后追踪到listenerStart,再然后trace到Exception,继续通过trace dump到Excepiton内容是因为jar加载冲突了,再加上 启动参数上增加-XX:+TraceClassLoading就能知道具体冲突的版本
你看一套流程下来考的是btrace无比熟练,跟我之前讲的抓包一样。抓包、strace、btrace
啊,P10还查问题?嗯10年前P10也要弄脏双手干活的,现在P8就不用了
最后讲个故事,有次别人面试我,问我TCP的close_wait 是为啥,我答偏了,在这之前我写过两篇如图2一样关于close_wait的文章
为什么操作系统有了多进程调度能力之后,CPU还在一个物理core上搞两个线程来分享这一个物理core呢(超线程)?
操作系统多进程调度有两个目的:1)让计算机拥有多任务能力;2)一个线程卡顿(比如读文件、网络)时切换到另外一个线程,高效使用CPU。目的2和超线程目标是一致的但不重叠
关键在于一次超线程切换只需要几个时钟周期,而一次操作系统的多线程、进程调度需要大几千个时钟周期,对CPU来说这种切换太慢了,没法充分利用CPU
据说4线程的CPU一直在评估设计中(90%的场景下,即使2个超线程也只跑满CPU流水线的一半能力)
业务代码必须插入安全团队的XSS扫描等代码,这个扫描代码每次在扫描结束的时候抛出 EOFException 然后自己catch,然后结束。用异常来控制业务流程,每次都 fillInStackTrace 然后自己悄悄吃掉,外部啥也感知不到,但是性能降低了30%。这样的同事多给我来几打
重新翻了公司10年前的经典案例排查过程,用10年后的姿势水平看当时的过程十分曲折。
现在看都是非常直白的知识点:比如JVM YGC耗时只和存活对象数有关和新生代大小无关(结果我看到10年前的工程师反复试验得到了这个结论);比如TCP全连接队列是否爆了用 ss 看下就知道了没必要netty代码分析来去(10年前花了3天时间也搞定了)– 他们都厉害在没有知识也能解决问题![[中国赞]](/images/951413iMgBlog/2018new_zhongguozan_org.png) ,比我厉害1万倍
,比我厉害1万倍
财新网等媒体眼中的著名专家 @逮獭科技 曾说过:
我觉得这个是时代的变化,每一代人中的佼佼者,其知识系统在下一代人看都平平;二战之后真正开挂的是全球的教育产业,几何级数膨胀受教育人口,而且,知识更迭很快,能追上前沿很不容易
程序员领域很卷很大一部分原因除了知识会过期还有很大一部分知识门槛变低了!我们的知识在下一代人眼里之所以平平无奇就是这些知识很快会变成八股文了,就像一个培训班训练出来的学生一样,可以解题拿高分,但是一旦出来一个新题型就嗝屁了
完整清晰地解决一个你所面临的新问题就像冲塔,一个人自己冲是最难的,别人冲完后告诉你攻略(八股文,就变成经验了)就容易多了,这是无招胜有招(真学霸),刷题多的都是假学霸;同样靠刷题面试牛逼的不一定是真学霸,问题出在了面试官分辨能力上。
信息流下几点经验分享下
看到一篇好文章后把整个博客都看下,挑你擅长的先看,快速确认博客内容深度以及是否适合你;
看到好微博也是,话痨的就算了,有些人连评论都懒得开就开始问!
公众号重点看看开号前面半年发的内容,一般都是干货,后面大多都是带货、为了发而发
不要沉迷信息流,多翻翻箱底的经典文章,他们能沉淀下来相对更有实力。我就发现新同学基本不太关心老文章,总是追求新的,你看我前一阵还在翻公司10多年前的案例
有疑问的先放狗搜一下再提问
看到一张好图片可以先搜图,然后根据图片能给你搜出来一大堆好文章(好文章配图一般也不差)
专门给微博用户的:不要在评论里 @**笔记 实在想,就转发 @**笔记, 不至于打扰别人
一个有意思的想法
每一代人中的佼佼者,其知识系统在下一代人看都平平。大概是因为完整清晰地解决一个你所面临的新问题就像冲塔,一个人自己冲是最难的,别人冲完后告诉你攻略(八股文,就变成经验了)就容易多了,第一个解决问题并沉淀的是牛人,让问题成为知识
这样让后面的普通资质的人也有了牛人的知识和“能力”,随着这种牛人沉淀下来的死知识越来越多,后面的人只需要掌握更多的死知识,但是失去了更多的单独冲塔的机会。当然每个时期的牛人还是存在的,只是牛人里面掺入的沙子越来越多了,你看互联网行业人人大佬、人人专家。
面试也是靠刷题、背八股文,刷题就是典型的牛人把思路方法放那里了,普通人还需要花上1/2周来消化,消化后面试效果比牛人还牛(熟练啊),面试官也甄别不了
结果会怎么样呢……
讲一个诈骗程序员的案例
程序员都喜欢注册域名,如果注册域名并在公安注册后,过几年域名到期了(大概率),这个时候有专门的流氓公司
他们会抢注域名,然后在这个域名下放一些热门盗版电影(不涉黄),这个时候他们的另一个公司(拥有电影版权的公司)出来取证了
接下来就是去法院告你盗版要求赔偿,在公安那里这个域名的所有人还是你(或贵司)从法律流程上来说完美无缺,你一定会输掉官司,这个时候流氓公司就等着你和解割地赔款
他们有专门的团队把整个过程流程化、低成本化
如果你们有废弃的域名记得注销ICP备案,如果是大厂更要记得这事,大厂赔得更多
以前主要是分析TCP协议,HTTP 接触得少,这几天补了一把,只能说wireshark对HTTP解析做得太好了. 比如以前我说抓包发现一个请求15ms,然来这个数据wireshark帮我们解析好了,MySQL协议的解析就没那么友好
我常用又不多见的命令(参数)
用curl调试sock5代理:curl -x socks5h://localhost:8001 www.不存在的网站.com/
nc走sock5转发: ProxyCommand /usr/bin/nc -X 5 -x 127.0.0.1:13659 %h %p //连github时
wget不存在的网站:wget -Y on -e “http_proxy=http://[HTTP_HOST]:[HTTP_PORT]“ http://不存在的网站.com/其中:[HTTP_HOST]和[HTTP_PORT]是http proxy的ADDRESS和PORT。
curl指定本地端口连远程(这样抓包只抓这个端口):curl –local-port
nc测试udp能否通(比如overlay网络、dns):nc -v -u -z -w 3 1.1.1.1 53
awk分组统计分析平均值:awk ‘{ sum[$1]+=$2; count[$1]+=1 ;} END { for (key in count) { printf “time= %s \t count=%s \t avg=%.6f \n”, key, count[key], sum[key]/count[key] } }’
将最近多少天的md笔记发表到博客:find $srcDir -maxdepth 1 -type f -mtime -$1 -name “*.md” -not -name “template.md” -not -name “temp.md” -exec cp “{}” ./source/_posts/ ; //改改可以用户备份本地最近修改的文件、配置
将博客上的大图压小(节省博客流量):find img_small -size +1024k -type f -exec sips -Z 1024 {} ;
检查用户使用的是长、短连接(别被用户的描述坑了):netstat -ato
发起ping 风暴:ping -f
测试网络MTU:ping -M
带时间戳的ping: ping -D 114.114.114.114 | awk ‘{ if(gsub(/[|]/, “”, $1)) $1=strftime(“[%F %T]”, $1); print}’
算是小抄,大多时候都是man、放狗可以获取,还有很多下次放
很多知识没啥用,但是逼格高,网上讲得多
比如拥塞算法,那个算法能搞明白的没几个,程序员基本不需要懂,最多最多就是sysctl配置换一下。程序员要的是打满带宽、延迟低、不丢包
还有cache line 分组编码,我们程序员要的是cache line不发生False sharing,多给我几个Disruptor如何做、Netty如果做的案例就完美了,比如Netty里面的代码实现全错了这么多年也没啥大事,还有程序员继续在错误的代码上,继续提交仍然是错误的patch,还没合并了 https://weibo.com/1667773473/LrEKR1lIL
比如说起DNS,现在的资料主要是将服务器怎么递归解析域名,程序员一脸懵逼,你就告诉我域名解析是我配置的问题(出在本机)还是发走后服务器解析不了(可以call 运维支撑),比如本机能ping但是不能nslookup 又是怎么回事?本机配置问题、lookup流程可以给程序员多讲讲,这里程序员可以兜底,出了本机就得运维啥的来支撑了。程序员要的是这种 https://plantegg.github.io/2019/01/09/nslookup-OK-but-ping-fail/
还有刷算法题,面试造火箭入职拧螺丝,大多指的这种。现在保守估计99%的letcode算法都用不上,95%的程序员不需要写心的算法,也就是现在的工具箱里螺丝刀这么多、这么好用了,你居然要面试让程序员如何设计一个新的螺丝刀?关键是贵司也不是螺丝刀工厂啊。最后说新员工能力不行
我是真没想到985毕业还非要说等额本金比等额本息的利息少!
首先两者的利率是一样的,你还多少利息=借钱数*利率(按月算吧,就可以去掉时间变量了)
这几个变量一样利息就一样,之所以等额本金给你感觉还利息少是因为你从第二个月开始欠的本金少了(不是还款方式导致的利息差异),欠的本金少了是因为你每个月还得多。
你借100万,每个月还1万,假设一个月这100万欠款的利息是5000,那么下个月你只欠99.5万了,下个月只需要还99.5万一个月的利息。–这是核心逻辑
顺便说下现在信用卡、套路贷就是用的这种方式打插边球让你以为利率低(不敢直接宣传利率是多少),比如1万块分期账单分10期,每期还1050,让你以为利息一个月 50块(按1万本金算一年利率折合6%),总利息也确实只还了 500块,但是你想想最后一个月你只欠他1000本金,但是仍然还了50块利息,也就是1000块年息600块(12*50),也就是年利率 60%,妥妥的高利贷
#程序员的螺丝刀# nc(netcat)
测试udp端口的连通性(比如dns、比如overlay服务),如图1
nc -l -u 4789
文件上传下载,下载有更方便的:python -m SimpleHTTPServer 8080 (如果要上传呢,如果没有python呢)
nc 也可以的:nc -l -p 8210 > demo.txt (server上),client端上传:nc dest_ip 8210 < demo.txt
打洞,我的ssh配置里面无数的nc转发,用ssl加密,然后nc代理
#程序员的螺丝刀# netstat
netstat -o 查看keepalive、重传
netstat -t 查看收包(自身)慢,还是发包走后对方慢
强大的丢包统计,保命的命令:netstat -s |egrep -i “drop|route|overflow|filter|retran|fails|listen”
tcp队列是否溢出:netstat -s | egrep “listen|LISTEN”
通过netstat -s来观察IPReversePathFilter 是否导致了网络不通
tc你说没听过,好吧,ping、netcat总归是耳熟能详了吧,你会用吗?
给大家一些具体的数字
用ab压Nginx的index.html页面数据对比(软中断在0核上, 软中断队列都设为1, nginx version: nginx/1.21.0, 测试中所有场景Nginx 把CPU全部吃满)
用了两台Intel服务器,同一台E5-2682 开关NUMA对比(对比NUMA的差异),另外一台是 intel 8163,看看芯片之间能力差异
结论:
1)单物理核TPS能到82000,8163 比2682 提升了60%
2)开NUMA有5%的提升
3)超线程能提升 50% 左右的性能(开NUMA后提升了30%)
4)但就内存延时来比8163的内存延时其实较2682改进不大,内存时延发展一直追不上 CPU 的速度(图中蓝色线是2682、橙色是8163,灰色是8269)
以后别动不动就吊打Nginx,我只测试到一个Server在一堆限定的场景下比Nginx好了5%。
| E5-2682 NUMA on | E5-2682 off | 8163 off (2 ab 压) | |
|---|---|---|---|
| 1号单核 | 49991 us:37% 0.96 IPC | 45722 us:35% 0.90 IPC | 82720 us:36% 1.27 IPC |
| HT(1/33) | 65469 us:31% 0.65 IPC | 62734 us:37% 0.65 IPC | 120100 us:38% 0.92 IPC |
| 0号单核 | 29881 us:27% si:29% 0.90 IPC | 28551 us:28% si:27% 0.88 IPC | 65615 us:32% si:17% 1.20IPC |
#程序员的螺丝刀# tc(traffic control)
模拟丢包率、设置时延等等简直太香了。我不知道不会用的程序员是怎么搞的
延时设置:
give packets from eth0 a delay of 2ms
bash$ tc qdisc add dev eth0 root netem delay 2ms
change the delay to 300ms
bash$ tc qdisc change dev eth0 root netem delay 3ms
display eth0 delay setting
bash$ tc qdisc show dev eth0
stop the delay
bash$ tc qdisc del dev eth0 root
设置1%丢包率
tc qdisc add dev eth0 root netem loss 1%
高级版,指定ip和端口延时,见图片
智商过滤器:0)等额本金比等额本息更合算;1)相互宝好不好;2)如何看待中医中药,中成药、中药注射剂好不好?
长期有耐心放到程序员身上也一样管用,进到好的公司、碰到好的领路人、赶上各种案例都是小概率事件,但是保证自己抓住机会的能力。
比如身边有高人,就好好多学习,哪怕是干点累活脏活(你要认为被PUA就无救了);
看到好的文章就把整个博客都翻翻;
碰到奇怪的问题要像平头哥一样死咬不放,多问几个为什么,搞清楚所有背后的未解之谜(每一个未解之谜都是你的一个盲点);
多学点实用的,少在公司搞些花架子,本事才是自己的(有些技术文章一看就是水文,各种框架图、结构图);
少把自己绑死在特定的技术上,尤其是公司自己发明的特殊轮子上。
最后时间才是最重要的,刚毕业急不来,长期有耐心。你看到的那些只是特别优秀–机会好、平台好、智商高……等中间的一例,大多都是跟你一样的普通人,不要过于焦虑
鸡汤
Do More, Do Better, Do exercise(口号和实践)
有个 Nginx 间歇性卡死的分析案例我追着看了三年,作者三年后也进步一更新的最根本的原因和优美的fix方法,简直太过瘾了。三年前就找到原因了,以及很多很多疑问点,剩下两三个小疑问,三年后终于也填补完美了。可惜不能分享。比如卡死的那个阶段所有 rt 都不对了容易导致分析跑偏
想搞个案例分析集,要求案例典型普适性强,代表基础组件基本原理等知识。分析手段尽量通用,重现容易的更好,分析过程一定要逻辑合理每个疑问都能回答清晰。有没有想要贡献案例的同学?这种案例搞清楚一个基本能横扫一个领域,比如上一条说的Nginx案例就让我这个从没用过Nginx的人学会了 惊群、epoll条件触发等之类的知识点 #拍案惊奇# 案例首先会去掉敏感信息,然后在分享过的同学之间内部共享,然后再开放。如果你们在网上看过已经发布过的案例更好,我先去学习下
趁着热点写下iptables+ipset的组合拳
如果有1万个白名单IP/CIDR, 往iptables里写1万条规则不现实也严重影响性能,这个时候可以把1万个ip、CIDR放到一个ipset里面,然后再在iptables里添加一条规则就可以了。动态增删白名单只需要动态修改ipset就可以了,iptables规则不需要修改
案例:
#timeout 259200是集合内新增的IP有三天的寿命
ipset create myset hash:net timeout 259200 //myset 还是空的
ipset add myset 100.1.2.0/24 //从set中增加ip段,也可以是一个ip,可以反复添加不同ip
//iptables 添加规则,对myset里面的所有ip访问端口1234 放行
iptables -N white_rule
iptables -A white_rule -m set –match-set myset src -p tcp –dport 1234 -j ACCEPT
限制:要求对所有ip规则一样才适用
#程序员的螺丝刀# wget
wget –limit-rate=2.5k 限制下载速度,进行测试, 挺有用的,比如你想模拟网络慢的场景下会不会出现什么问题;让 数据堆在接收窗口、发送窗口里面也很好玩;这个时候抓包看看输出的时候在干啥就更有意思了
用 Wget 的递归方式下载整个网站:wget –random-wait -r -p -e robots=off -U Mozilla www.example.com
7.0.0.0/8,11.0.0.0/8,21.0.0.0/8,22.0.0.0/8,30.0.0.0/8 这些虽然不像192.168一样是私网地址,但是常被大家用来做内部地址,这是因为公网上只有美国国防部使用,所以不会和公网上冲突
全链路性能分析套路:
1) 先看监控,有各种鹰眼、狼眼最好;
2) 没有的话就要徒手上了,先要权限,只要每个节点有权限就好搞了,按着 https://www.weibo.com/1667773473/Lsb7CkVed 这里的方法徒手撸,从客户端一直撸到最后面的数据库;
3)如果没有权限是最悲惨的,一般外包都没权限,但是又要干活,比如我。那么就只能用 ping 到处围着蹭蹭,不进去,谁让你是外包没有权限的,参考这三个案例 https://www.weibo.com/1667773473/LAjwUldTr 和https://www.weibo.com/1667773473/LzYwyaIB4 下面这个是cloudflare的(高手的做法都差不多)https://www.weibo.com/1667773473/LAJ5mnp7b
4)最后啥都没有肯定要有钱,出钱找我就行(案例典型可以不要钱)
感觉推上的技术氛围更浓厚啊,这个要超赞,图一这个问题居然讨论这么热闹。默认500个time_wait确实是四元组要唯一(6万个可用端口除以120等于500),如果是探活一个服务的话src_ip dest_ip dest_port固定了,只剩下src_port可变,反过来说探活120秒一般不会超过500次,所以应该是够的。探活一般是connect,也就是随机选择(其实不是随机,有算法的)src_port, 所以是500. 如果创建 socket 的时候做了bind也就是写死src_port了那就120秒只能有一个time_wait. 当然还可以是图三 reuse time_wait
贴个文章:https://plantegg.github.io/2020/11/30/一台机器上最多能创建多少个TCP连接/
https://15721.courses.cs.cmu.edu/spring2016/papers/p743-leis.pdf 这篇2014年的论文给了一个很牛逼的结论,通过 morsel-driver 和 numa-aware 对TPC-H性能有数量级的提升,按理这个数据很牛逼了,但是我好奇为啥没有大规模上生产呢?
但是文章中对 numa-aware的理解还是很赞的,一般搞数据库的理解这些算是跨行业,有点难度很正常。论文里都给了非常专业的数据和理解。
其实论文不应该把morsel-driver和numa-aware混到一起,最后不知道是谁的功劳
https://plantegg.github.io/2017/01/01/top_linux_commands/
#拍案惊奇# 我最喜欢的Nginx卡顿案例终于整理完毕
简述就是:总有耗时任务造成worker进程卡死,就是某个任务总是总用worker,导致worker没法响应新连接(用户感知连不上Nginx)、没法更新woker计时(导致nginx日志时间失真,排查麻烦)、普通正在处理的请求也变成了慢请求。
涉及到:TCP连接、Nginx进程模型、惊群、边缘触发和条件触发、网络buffer等,真是一个让我爱不释手的case,这几天我都不想上班只想好好把玩
类似的案例可以参考:
Why does one NGINX worker take all the load?
The story of one latency spike
但比我这个案例有趣性差得太远了
作为极客时间的企业用户(所有课程随便看,但是我看的不算多)来给你们推荐几个课程。MySQL45讲,趣谈网络一定是值得推荐的;网络案例也可以看看(不想花钱就看我的博客网络部分,嘿嘿其实比这课要好);芯片那个有兴趣可以看看,算是比较偏门了。
其实企业用户超级不值当,包年性质,过期了就不能看了,还不如买下来的,不推荐购买企业用户。
要想省钱3/5个人组团,每个人买3-5门课,然后互相学习
还行吧,2个小时把一个系统优化性能翻了一倍,主要还是CPU、网络都比较了解,容易出成绩
优化前 800MB
1 开numa
1.2GB
2 使用irqbalance,自动将irq 绑定到对应的位置的numa 核心
1.6GB
3 软件绑核,各绑定到2 个相邻的核心。将CPU 和numa 分开。
2.0GB
4 更改网卡中断队列数。
2.6GB
内核 TCP 协议栈 bug 导致应用卡死的 case:http://t.cn/A6SYWIsh 还得会看包,就不用走这么多弯路了,教训总结得不够[微笑],kernel上的修复patch:github.com/torvalds/linux/commit/b617158dc096709d8600c53b6052144d12b89fab (5月引入的bug:http://t.cn/A6SYHu9W 7月修复)
为啥 Databricks 不直接follow kernel而是follow ubuntu,吃二手消息呢?
redhat对这个 bug的描述:http://t.cn/A6SYQ29h
图三中 红色代码为了修 CVE-2019-11478 添加的,引入了这个卡死 的bug,绿色部分增加了更严格的条件又修复了卡死的 bug
双网卡下的 kubernetes 集群:1)控制面走外网网卡;2)flannel等overlay走内网网卡
实现:
控制面指定外网网卡ip:kubeadm init –control-plane-endpoint 192.168.0.21:6443
Flannel yaml配置中指定网卡:–iface=enp33s0f0
默认路由选择外网网卡
比较不忍看到大多新同事刚一进来被丢到了错误的位置上,新同事还不敢拒绝。第一种是要面对新公司一大坨内部产品和术语,没有人带,这种太不人道;第二种因为错配而要面对新技术领域,大体还是能 Google 到,不过对他们压力太大,这种我一般会带一次,再多也没精力,毕竟跨了团队;几个月下来新同事肯定觉得被 PUA了