MySQL线程池卡顿重现
MySQL线程池卡顿重现
by @wych42
起因
为了激励大家多动手少空想,我在推特发起了白嫖我的知识星球活动:
白嫖我星球的机会来了,总有人说贵、没有优惠券,这次直接来一个完全100%免费的机会,要求: 在MySQL的基础上重现某个线程池卡的现象,给出可复制的重现过程。就是因为某个线程池满了导致落到这个池里的查询一定都慢,否则都快。 不愿意出钱就动手吧
感谢推友王鱼翅同学,以下是他的教科书级的细致重现,你复制粘贴就能和他一样重现了
这个案例的重要性
这个现象对应我们年度四大案例之一,如下图左下角
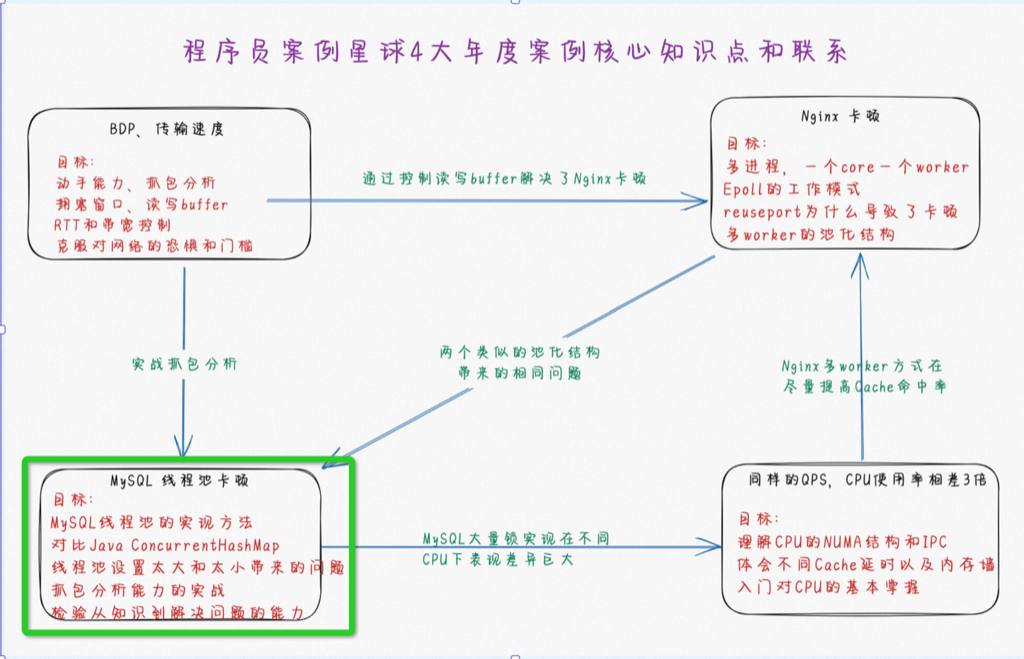
重现后请思考:
- MySQL为什么要将多个线程分成小池子,小池子肯定容易局部资源不足
- Nginx 一个连接固定在一个worker上,那么同样多个Worker也会有不均衡(有的worker很闲,有的很卡)
- 动手实验一下将多个小池子改成一个大线程池会怎么样
- Java ConcurrentHashMap为什么能够高性能
由 @wych42 重现
原因分析
根据 USE 分析套路。看到服务端执行快,但是整体RT慢的现象,大概率是中间哪个位置有排队。根据文章里的描述,原因是在thread pool group中出现了排队。
排队的主要原因是服务端拒绝创建新的thread(worker),导致新进来的SQL需要等待前面的执行完成。那么就需要重点分析thread(worker)的创建过程和约束条件。根据文章和文档的说明,重点在thread_pool_size, thread_pool_oversubscribe, thread_pool_max_threads, thread_pool_stall_limit这几个参数上。
跟据文档分析和实际执行结果,这几个参数在MySQL不同的发型版中的行为逻辑是不尽相同的。核心差异在对创建新worker的限制条件上,后面复现也会根据两个发型版的特点分别执行。
mariadb
- 通常情况下,新worker由listener worker创建
- 当timer worker检测到thread group 有stall时,可能会选择创建一个新的worker
- worker的数量上限由thread_pool_max_threads限制
- thread_pool_oversubscribe约束的是被额外创建出来的worker,在执行完任务后,最多能保留active状态的数量
To clarify, the thread_pool_oversubscribe system variable does not play any part in the creation of new worker threads. The thread_pool_oversubscribe system variable is only used to determine how many worker threads should remain active in a thread group, once a thread group is already oversubscribed due to stalls.
percona
percona的行为更符合原文章里的说明:
- 如果线程执行超过时间 thread_pool_stall_limit 的值,会被任务stalled,会创建一个新的线程执行排队的任务
- thread_pool_oversubscribe 约束了每个thread group的线程数上限。
尝试复现
思路
并发向DB发起请求,观察客户端耗时,这些请求应当符合这些条件:
- 可控的并发数量:以对比数据库服务端不同参数值的情况
- 有稳定的、相同的服务端执行耗时:以对比客户端在不同场景下的耗时
- 对服务端的硬件压力较小:避免因为并发不同时,因IO、CPU资源占用,影响服务端执行耗时
综合考虑使用 select sleep(2); 作为测试SQL。并发控制使用下面的golang代码实现。
再控制数据库服务端参数,运行同一个并发程序进行对比,mariadb和percona分析执行运行过程:
复现执行
mariadb
由上面分析可以,mariadb 中造成排队的约束是thread_pool_max_threads。
执行方案
- DB配置
1 | | thread_pool_max_threads | 6 | |
- 执行SQL
select sleep(2) - 执行并发:8
预期结果: 6个SQL执行的客户端观察耗时为2s;2个SQL为4s
若调整 thread_pool_max_threads=8,则8个SQL的执行客户端观察耗时都为2s
执行结果
- thread_pool_max_threads=6;concurrency=8
1 | go run ./main.go |
- thread_pool_max_threads=8;concurrency=8
1 | go run ./main.go |
均符合预期。
percona
由上面分析可以,percona中造成排队的约束是thread_pool_oversubscribe。
执行方案
- DB配置: thread_pool_max_threads设置一个较大的值,以排除影响。
1 | | thread_pool_max_threads | 1000 | |
- 执行SQL
select sleep(2) - 执行并发:8
预期结果: 客户端观察到的耗时分四个批次输出,每个批次2个SQL,耗时分别为2s,4s,6s,8s.
若调整 thread_pool_oversubscribe=2,则三个批次输出,分别为3条SQL耗时均为2s,3条SQL耗时均为4s,2条SQL耗时均为6s
执行结果
- thread_pool_oversubscribe=1,concurrency=8
1 | go run ./main.go |
- thread_pool_oversubscribe=2,concurrency=8
1 | go run ./main.go |
均符合预期。
real-world 模拟(percona)版本
现实场景中,很少会有大批量的2s在SQL在生产环境执行(限互联网业务),上述的分析过程能否在真实场景中验证呢?尝试用一个执行200ms的SQL来模拟下:
- DB配置: thread_pool_max_threads设置一个较大的值,以排除影响。
1 | | thread_pool_max_threads | 1000 | |
- 执行SQL
select sleep(0.2) - 执行并发:10
从执行结果中可以看到,只有第一条SQL按照预期的时间执行完成了。
从抓包结果中可以看到,所有SQL几乎是同时发出。观察最慢的一条SQL,但是从客户端发包到服务端响应包发出的耗时,与客户端观察到的耗时也能对应上。
可以验证上述分析过程。
1 | 2023/05/16 14:47:47 taskId:task_1 exec cost : 239.34925ms |


复现文章中部分线程池卡的现象
配置两个线程池,在其中一个线程池上,通过select sleep()较长时间模拟线程池被慢SQL或者大量任务堵塞的情况,具体配置方案如下:
- thread_pool_size=2: 保留两个线程池,验证一个卡顿,一个不卡
- thread_pool_oversubscribe=1: 允许多创建一个线程,每个线程池中可以同时运行1+1=2个线程
- thread_pool_max_threads=2: 每个线程池的线程数量上限,为thread_pool_oversubscribe的配置约束加一个硬限制,每个线程池中最多允许运行2个线程
操作步骤如下:
- 通过mysql client在终端发起链接,通过
show processlist语句获取到链接Id, 该链接会分配到 id%2 的线程池中。 - 用偶数id的链接验证卡顿线程池,用奇数id的链接验证不卡的线程池,链接情况如下:
1 | show processlist; |
- 在 id=404, id=406的链接上,执行
select sleep(30),再到 id=410 的链接上执行select 1,预计select 'slow'会直接卡顿约30s再执行完成。 - 同时,在id=405的链接上,反复执行
select 'fast',都可以很快执行完成。
执行结果:
- id=410 上的语句执行约25s返回结果(终端操作手速影响导致了5s误差),语句执行时数据库实例输出报错日志,提示线程不足:
2023-05-16T11:27:09.997916Z 406 [ERROR] [MY-000000] [Server] Threadpool could not create additional thread to handle queries, because the number of allowed threads was reached. Increasing ‘thread_pool_max_threads’ parameter can help in this situation. If ‘admin_port’ parameter is set, you can still connect to the database with superuser account (it must be TCP connection using admin_port as TCP port) and troubleshoot the situation. A likely cause of pool blocks are clients that lock resources for long time. ‘show processlist’ or ‘show engine innodb status’ can give additional hints.
- id=405链接上的执行都行快。可参考下面抓包截图。
抓包结果:
id=410 上的阻塞SQL,可以看到:
- 三条语句在3s内接连发出,但是由于线程池阻塞,
select 'slow'原本应该很快返回结果,被卡住 - 在30s时,第一个
select sleep(30)语句执行完成,空出的线程立刻执行了select 'slow'并返回结果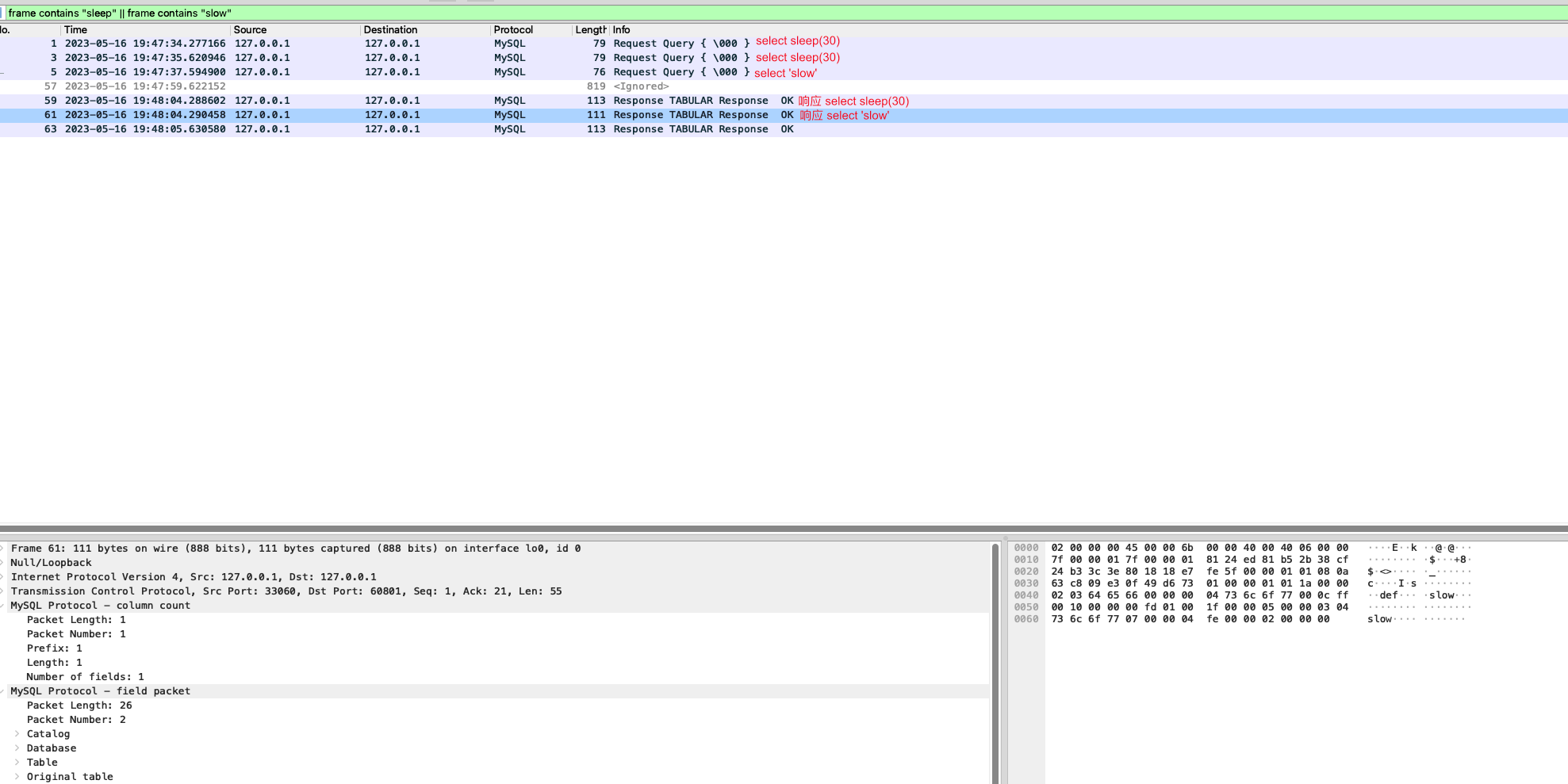
id=405链接上的执行结果可以看到,每条语句执行都很快。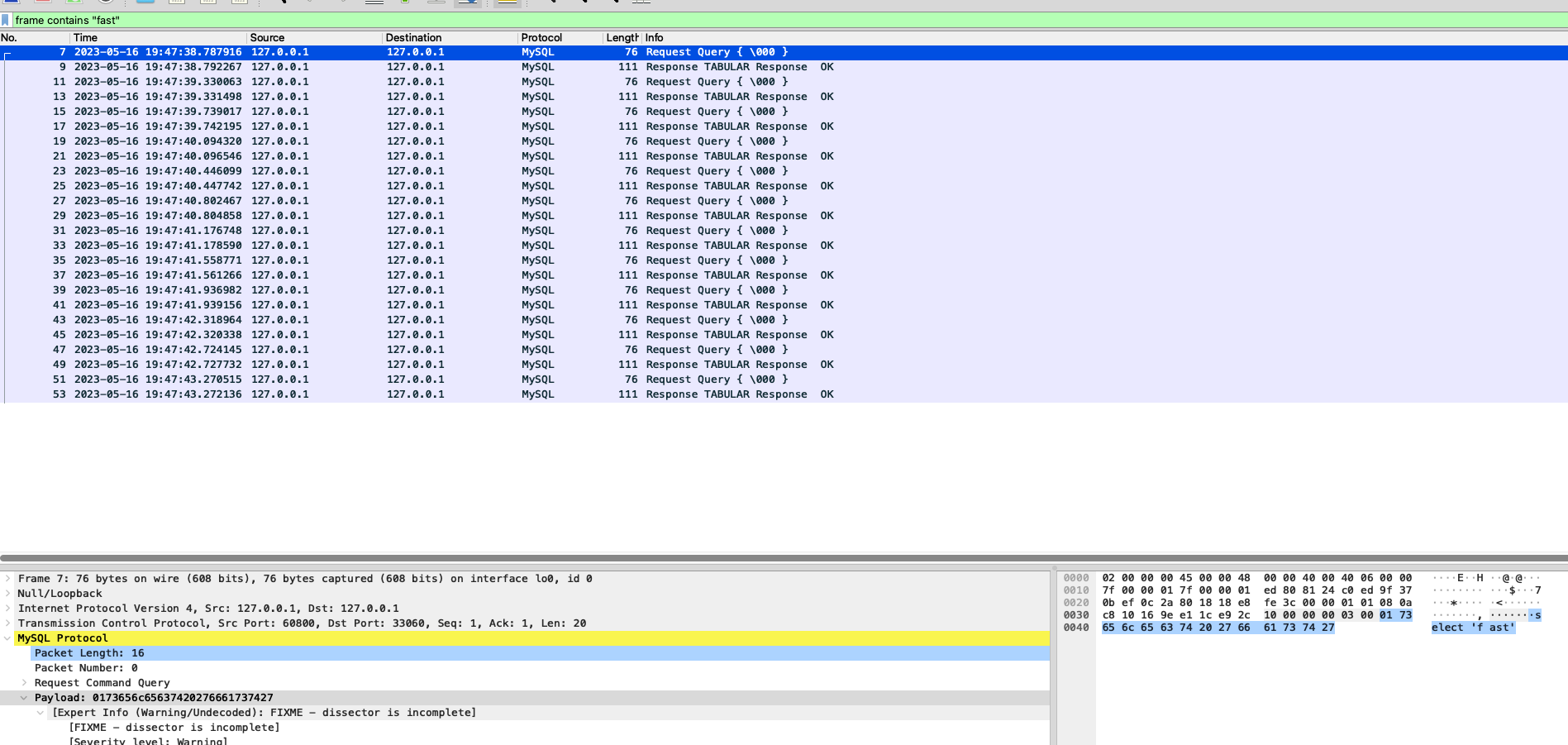
参数合理值/已知参数的容量评估
percona 的默认配置中,thread_pool_size=核心数,thread_pool_oversubscribe=3.假设在一台 16core 的服务器上运行percona,默认配置下最多可以有 16*(1+3)=64个worker同时接受请求。也就是最大可并行处理的SQL数量为 64 个。
假设同时有65个执行耗时为10ms的SQL到达服务端,理论上,会有一个进入排队。排查网络、解析等阶段,在客户端观察到的64个SQL执行耗时10ms,1个SQL执行耗时约20ms。这也会导致耗时监控中出现毛刺、耗时分布不符合正态分布。
反之,根据硬件配置、查询的量、耗时等特点,也可以推算合理的参数值。
附录
过程回顾
阶段一 确定原因
看到文章时,基本确认问题根源在执行线程(worker)不够,导致排队,出于以下几点分析:
- 开头提到的 USE 分析套路,结合排查过类似问题(非SQL)的经验
- 看到文章作者调大thread_pool_oversubscribe便解决问题, 结合文章中对该参数作用的文档引用,基本可以确定
阶段二 走上弯路
尝试复现时,要先启动一个DB实例,便查询文档该参数如何在配置文件中配置,查了MySQL的文档,似乎只在enterprise版本中才有该配置项,便转头去看mariadb的配置说明(这一步给走弯路埋下了伏笔)。
用docker在本地启动了mariadb实例(thread_pool_size=2 thread_pool_oversubscribe=1)
先尝试用 select sleep(30) 模拟阻塞,用 sysbench 模拟正常流量,结果失败:
- 正常流量中有慢的,但是整体还符合正态分布,没有出现都卡的情况。
- 加大了
select sleep(30)查询的并发量,现象同上。
又翻阅了一些文档,看到DB在调度时,对不同类型的SQL调度优先级会有所区别,类似sleep这种啥也不干的SQL,会不会被降低调度优先级,才导致了没有复现呢?(走上了弯路)
尝试人工制造慢查询:
- 用 sysbench 制造百万量级的表
- 执行 offset limit 的排序查询,并且不走索引
复现结果仍不满意:
- 整体耗时上升了,出现几笔长尾的耗时特别长的请求
- 但是整体仍然符合正态分布
此时分析了下,整体耗时上升是人工制造的慢查询,占用了过多IO和CPU资源,影响了sysbench SQL执行的效率。
阶段三 柳岸花明
回头又仔细看了下 mariadb关于线程池的文档,注意到文档中提到 thread_pool_oversubscribe 不决定同时有多少线程池被创建出来并执行任务,这个行为逻辑与文章中作者引用的并不相同。
又去查看了另一个MySQL发行版 percona 的文档,对该配置的行为描述与文章中的相符,基本就确定前面复现失败的原因了。
确定了前面提到的复现思路:用有稳定服务端执行耗时、并且不消耗大量硬件资源的SQL,用可控的并发进行模拟流量,到具体执行时:
- SQL就用
select sleep(N) - 可控的并发就用 golang写个小脚本(事后看直接在终端手动操作也是可以的,不过写个脚本也不费事就是了)
mariadb 启动命令和配置
1 | mkdir mariadb |
percona 启动命令和配置
1 | mkdir percona |
注:Mac M1启动percona时,需要在 docker run 后面添加 --platform linux/x86_64 参数。(percona 未提供arm架构的image)
其他人的重现和分析
https://lotabout.me/2023/Verification-of-Percona-Thread-Pool-Behavior/ 从源代码debug上来分析