#./mlc Intel(R) Memory Latency Checker - v3.9 Measuring idle latencies (in ns)... Numa node Numa node 0 0 145.8 //多次测试稳定都是145纳秒
Measuring Peak Injection Memory Bandwidths for the system Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec) Using all the threads from each core if Hyper-threading is enabled Using traffic with the following read-write ratios ALL Reads : 110598.7 3:1 Reads-Writes : 93408.5 2:1 Reads-Writes : 89249.5 1:1 Reads-Writes : 64137.3 Stream-triad like: 77310.4
Measuring Memory Bandwidths between nodes within system Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec) Using all the threads from each core if Hyper-threading is enabled Using Read-only traffic type Numa node Numa node 0 0 110598.4
Measuring Loaded Latencies for the system Using all the threads from each core if Hyper-threading is enabled Using Read-only traffic type Inject Latency Bandwidth Delay (ns) MB/sec ========================== 00000 506.00 111483.5 00002 505.74 112576.9 00008 505.87 112644.3 00015 508.96 112643.6 00050 574.36 112701.5
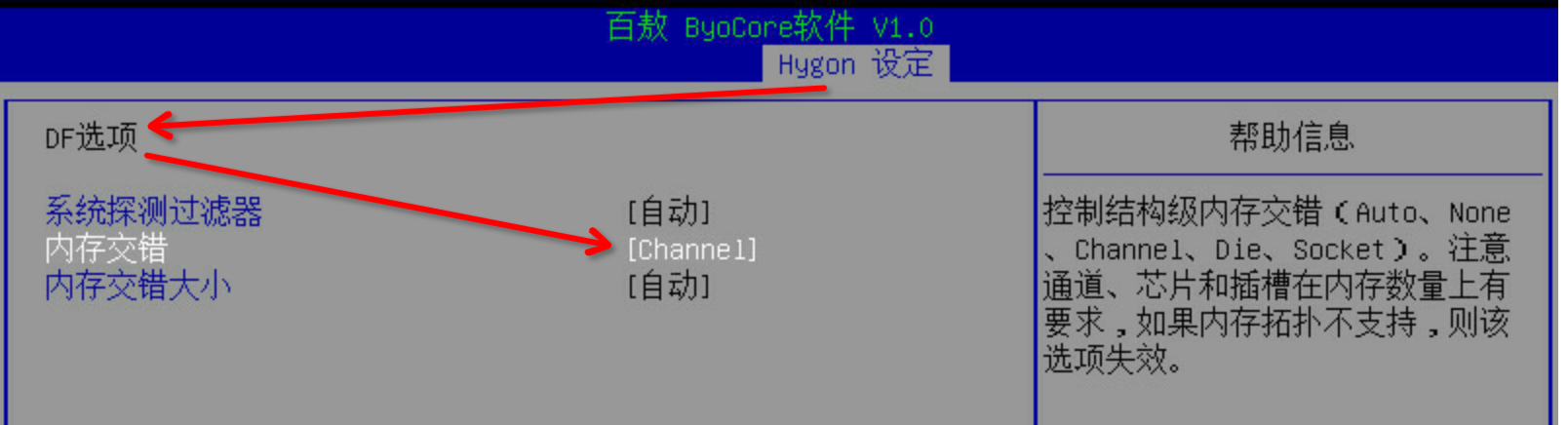
当两个参数都为 on 时的mlc 测试结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
#./mlc Intel(R) Memory Latency Checker - v3.9 Measuring idle latencies (in ns)... Numa node Numa node 0 1 0 81.6 145.9 1 144.9 81.2
Measuring Peak Injection Memory Bandwidths for the system Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec) Using all the threads from each core if Hyper-threading is enabled Using traffic with the following read-write ratios ALL Reads : 227204.2 3:1 Reads-Writes : 212432.5 2:1 Reads-Writes : 210423.3 1:1 Reads-Writes : 196677.2 Stream-triad like: 189691.4